* [PATCH 01/28] drm/sched: Reverse drm_sched_rq_init arguments
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 8:55 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 02/28] drm/sched: Add some scheduling quality unit tests Tvrtko Ursulin
` (27 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
Helper operates on the run queue so lets make that the primary argument.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/scheduler/sched_main.c | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 46119aacb809..8b8c55b25762 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -174,13 +174,13 @@ void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
/**
* drm_sched_rq_init - initialize a given run queue struct
*
+ * @rq: scheduler run queue
* @sched: scheduler instance to associate with this run queue
- * @rq: scheduler run queue
*
* Initializes a scheduler runqueue.
*/
-static void drm_sched_rq_init(struct drm_gpu_scheduler *sched,
- struct drm_sched_rq *rq)
+static void drm_sched_rq_init(struct drm_sched_rq *rq,
+ struct drm_gpu_scheduler *sched)
{
spin_lock_init(&rq->lock);
INIT_LIST_HEAD(&rq->entities);
@@ -1353,7 +1353,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
if (!sched->sched_rq[i])
goto Out_unroll;
- drm_sched_rq_init(sched, sched->sched_rq[i]);
+ drm_sched_rq_init(sched->sched_rq[i], sched);
}
init_waitqueue_head(&sched->job_scheduled);
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 01/28] drm/sched: Reverse drm_sched_rq_init arguments
2025-10-08 8:53 ` [PATCH 01/28] drm/sched: Reverse drm_sched_rq_init arguments Tvrtko Ursulin
@ 2025-10-10 8:55 ` Philipp Stanner
2025-10-10 9:46 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 8:55 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> Helper operates on the run queue so lets make that the primary argument.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> ---
> drivers/gpu/drm/scheduler/sched_main.c | 8 ++++----
> 1 file changed, 4 insertions(+), 4 deletions(-)
That's a new patch from the RFC, isn't it?
And it's a general code improvement that is not related to CFS. I think
I mentioned it a few times already that a series is easier to review
and workflows are simplified if generic-improvement patches are
branched out and sent separately.
I thought you had agreed with that?
P.
>
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index 46119aacb809..8b8c55b25762 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -174,13 +174,13 @@ void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> /**
> * drm_sched_rq_init - initialize a given run queue struct
> *
> + * @rq: scheduler run queue
> * @sched: scheduler instance to associate with this run queue
> - * @rq: scheduler run queue
> *
> * Initializes a scheduler runqueue.
> */
> -static void drm_sched_rq_init(struct drm_gpu_scheduler *sched,
> - struct drm_sched_rq *rq)
> +static void drm_sched_rq_init(struct drm_sched_rq *rq,
> + struct drm_gpu_scheduler *sched)
> {
> spin_lock_init(&rq->lock);
> INIT_LIST_HEAD(&rq->entities);
> @@ -1353,7 +1353,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
> if (!sched->sched_rq[i])
> goto Out_unroll;
> - drm_sched_rq_init(sched, sched->sched_rq[i]);
> + drm_sched_rq_init(sched->sched_rq[i], sched);
> }
>
> init_waitqueue_head(&sched->job_scheduled);
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 01/28] drm/sched: Reverse drm_sched_rq_init arguments
2025-10-10 8:55 ` Philipp Stanner
@ 2025-10-10 9:46 ` Tvrtko Ursulin
2025-10-10 10:36 ` Philipp Stanner
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-10 9:46 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 10/10/2025 09:55, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> Helper operates on the run queue so lets make that the primary argument.
>>
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> ---
>> drivers/gpu/drm/scheduler/sched_main.c | 8 ++++----
>> 1 file changed, 4 insertions(+), 4 deletions(-)
>
> That's a new patch from the RFC, isn't it?
>
> And it's a general code improvement that is not related to CFS. I think
> I mentioned it a few times already that a series is easier to review
> and workflows are simplified if generic-improvement patches are
> branched out and sent separately.
>
> I thought you had agreed with that?
Hm not sure. My workflow is definitely easier if this work is a single
unit throughout.
Anyway, with this change it still far from consistency, so how much of
an improvement it brings is open to debate. The general idea is that
functions in sched_rq.c operate on sched_rq, which is the first
argument, and by the end of the series the second argument disappears:
void drm_sched_rq_init(struct drm_sched_rq *rq)
{
spin_lock_init(&rq->lock);
INIT_LIST_HEAD(&rq->entities);
rq->rb_tree_root = RB_ROOT_CACHED;
rq->head_prio = -1;
}
int drm_sched_init(struct drm_gpu_scheduler *sched, const struct
drm_sched_init_args *args)
{
...
drm_sched_rq_init(&sched->rq);
But again, even at that point the code base is still not fully
consistent in this respect aka needs more work. Not least you recently
asked to rename drm_sched_rq_select_entity(rq) to
drm_sched_select_entity(sched). So maybe you disagree with this patch
completely and would prefer drm_sched_rq_init(sched). I don't know.
Anyway, if you r-b it is trivial to send separately and merge. Or if you
disapprove I will just drop this patch and rebase.
Regards,
Tvrtko
>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>> index 46119aacb809..8b8c55b25762 100644
>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>> @@ -174,13 +174,13 @@ void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>> /**
>> * drm_sched_rq_init - initialize a given run queue struct
>> *
>> + * @rq: scheduler run queue
>> * @sched: scheduler instance to associate with this run queue
>> - * @rq: scheduler run queue
>> *
>> * Initializes a scheduler runqueue.
>> */
>> -static void drm_sched_rq_init(struct drm_gpu_scheduler *sched,
>> - struct drm_sched_rq *rq)
>> +static void drm_sched_rq_init(struct drm_sched_rq *rq,
>> + struct drm_gpu_scheduler *sched)
>> {
>> spin_lock_init(&rq->lock);
>> INIT_LIST_HEAD(&rq->entities);
>> @@ -1353,7 +1353,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>> sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
>> if (!sched->sched_rq[i])
>> goto Out_unroll;
>> - drm_sched_rq_init(sched, sched->sched_rq[i]);
>> + drm_sched_rq_init(sched->sched_rq[i], sched);
>> }
>>
>> init_waitqueue_head(&sched->job_scheduled);
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 01/28] drm/sched: Reverse drm_sched_rq_init arguments
2025-10-10 9:46 ` Tvrtko Ursulin
@ 2025-10-10 10:36 ` Philipp Stanner
2025-10-11 13:21 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 10:36 UTC (permalink / raw)
To: Tvrtko Ursulin, phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On Fri, 2025-10-10 at 10:46 +0100, Tvrtko Ursulin wrote:
>
> On 10/10/2025 09:55, Philipp Stanner wrote:
> > On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> > > Helper operates on the run queue so lets make that the primary argument.
> > >
> > > Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> > > Cc: Christian König <christian.koenig@amd.com>
> > > Cc: Danilo Krummrich <dakr@kernel.org>
> > > Cc: Matthew Brost <matthew.brost@intel.com>
> > > Cc: Philipp Stanner <phasta@kernel.org>
> > > ---
> > > drivers/gpu/drm/scheduler/sched_main.c | 8 ++++----
> > > 1 file changed, 4 insertions(+), 4 deletions(-)
> >
> > That's a new patch from the RFC, isn't it?
> >
> > And it's a general code improvement that is not related to CFS. I think
> > I mentioned it a few times already that a series is easier to review
> > and workflows are simplified if generic-improvement patches are
> > branched out and sent separately.
> >
> > I thought you had agreed with that?
>
> Hm not sure. My workflow is definitely easier if this work is a single
> unit throughout.
>
> Anyway, with this change it still far from consistency, so how much of
> an improvement it brings is open to debate. The general idea is that
> functions in sched_rq.c operate on sched_rq, which is the first
> argument, and by the end of the series the second argument disappears:
>
> void drm_sched_rq_init(struct drm_sched_rq *rq)
> {
> spin_lock_init(&rq->lock);
> INIT_LIST_HEAD(&rq->entities);
> rq->rb_tree_root = RB_ROOT_CACHED;
> rq->head_prio = -1;
> }
>
> int drm_sched_init(struct drm_gpu_scheduler *sched, const struct
> drm_sched_init_args *args)
> {
> ...
> drm_sched_rq_init(&sched->rq);
>
> But again, even at that point the code base is still not fully
> consistent in this respect aka needs more work. Not least you recently
> asked to rename drm_sched_rq_select_entity(rq) to
> drm_sched_select_entity(sched). So maybe you disagree with this patch
> completely and would prefer drm_sched_rq_init(sched). I don't know.
> Anyway, if you r-b it is trivial to send separately and merge. Or if you
> disapprove I will just drop this patch and rebase.
I think it's best to drop it for now and address such things in a
separate series one day for style and consistency changes which
hopefully sets it completely straight.
I had something like that on my list, too, for all the docstrings which
are inconsistent.
P.
>
> Regards,
>
> Tvrtko
>
> > > diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> > > index 46119aacb809..8b8c55b25762 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_main.c
> > > +++ b/drivers/gpu/drm/scheduler/sched_main.c
> > > @@ -174,13 +174,13 @@ void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > /**
> > > * drm_sched_rq_init - initialize a given run queue struct
> > > *
> > > + * @rq: scheduler run queue
> > > * @sched: scheduler instance to associate with this run queue
> > > - * @rq: scheduler run queue
> > > *
> > > * Initializes a scheduler runqueue.
> > > */
> > > -static void drm_sched_rq_init(struct drm_gpu_scheduler *sched,
> > > - struct drm_sched_rq *rq)
> > > +static void drm_sched_rq_init(struct drm_sched_rq *rq,
> > > + struct drm_gpu_scheduler *sched)
> > > {
> > > spin_lock_init(&rq->lock);
> > > INIT_LIST_HEAD(&rq->entities);
> > > @@ -1353,7 +1353,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> > > sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
> > > if (!sched->sched_rq[i])
> > > goto Out_unroll;
> > > - drm_sched_rq_init(sched, sched->sched_rq[i]);
> > > + drm_sched_rq_init(sched->sched_rq[i], sched);
> > > }
> > >
> > > init_waitqueue_head(&sched->job_scheduled);
> >
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 01/28] drm/sched: Reverse drm_sched_rq_init arguments
2025-10-10 10:36 ` Philipp Stanner
@ 2025-10-11 13:21 ` Tvrtko Ursulin
0 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-11 13:21 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 10/10/2025 11:36, Philipp Stanner wrote:
> On Fri, 2025-10-10 at 10:46 +0100, Tvrtko Ursulin wrote:
>>
>> On 10/10/2025 09:55, Philipp Stanner wrote:
>>> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>>>> Helper operates on the run queue so lets make that the primary argument.
>>>>
>>>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>>>> Cc: Christian König <christian.koenig@amd.com>
>>>> Cc: Danilo Krummrich <dakr@kernel.org>
>>>> Cc: Matthew Brost <matthew.brost@intel.com>
>>>> Cc: Philipp Stanner <phasta@kernel.org>
>>>> ---
>>>> drivers/gpu/drm/scheduler/sched_main.c | 8 ++++----
>>>> 1 file changed, 4 insertions(+), 4 deletions(-)
>>>
>>> That's a new patch from the RFC, isn't it?
>>>
>>> And it's a general code improvement that is not related to CFS. I think
>>> I mentioned it a few times already that a series is easier to review
>>> and workflows are simplified if generic-improvement patches are
>>> branched out and sent separately.
>>>
>>> I thought you had agreed with that?
>>
>> Hm not sure. My workflow is definitely easier if this work is a single
>> unit throughout.
>>
>> Anyway, with this change it still far from consistency, so how much of
>> an improvement it brings is open to debate. The general idea is that
>> functions in sched_rq.c operate on sched_rq, which is the first
>> argument, and by the end of the series the second argument disappears:
>>
>> void drm_sched_rq_init(struct drm_sched_rq *rq)
>> {
>> spin_lock_init(&rq->lock);
>> INIT_LIST_HEAD(&rq->entities);
>> rq->rb_tree_root = RB_ROOT_CACHED;
>> rq->head_prio = -1;
>> }
>>
>> int drm_sched_init(struct drm_gpu_scheduler *sched, const struct
>> drm_sched_init_args *args)
>> {
>> ...
>> drm_sched_rq_init(&sched->rq);
>>
>> But again, even at that point the code base is still not fully
>> consistent in this respect aka needs more work. Not least you recently
>> asked to rename drm_sched_rq_select_entity(rq) to
>> drm_sched_select_entity(sched). So maybe you disagree with this patch
>> completely and would prefer drm_sched_rq_init(sched). I don't know.
>> Anyway, if you r-b it is trivial to send separately and merge. Or if you
>> disapprove I will just drop this patch and rebase.
>
> I think it's best to drop it for now and address such things in a
> separate series one day for style and consistency changes which
> hopefully sets it completely straight.
Okay dropped.
Regards,
Tvrtko
>
> I had something like that on my list, too, for all the docstrings which
> are inconsistent.
>
>
> P.
>
>>
>> Regards,
>>
>> Tvrtko
>>
>>>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>>>> index 46119aacb809..8b8c55b25762 100644
>>>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>>>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>>>> @@ -174,13 +174,13 @@ void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>> /**
>>>> * drm_sched_rq_init - initialize a given run queue struct
>>>> *
>>>> + * @rq: scheduler run queue
>>>> * @sched: scheduler instance to associate with this run queue
>>>> - * @rq: scheduler run queue
>>>> *
>>>> * Initializes a scheduler runqueue.
>>>> */
>>>> -static void drm_sched_rq_init(struct drm_gpu_scheduler *sched,
>>>> - struct drm_sched_rq *rq)
>>>> +static void drm_sched_rq_init(struct drm_sched_rq *rq,
>>>> + struct drm_gpu_scheduler *sched)
>>>> {
>>>> spin_lock_init(&rq->lock);
>>>> INIT_LIST_HEAD(&rq->entities);
>>>> @@ -1353,7 +1353,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>>>> sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
>>>> if (!sched->sched_rq[i])
>>>> goto Out_unroll;
>>>> - drm_sched_rq_init(sched, sched->sched_rq[i]);
>>>> + drm_sched_rq_init(sched->sched_rq[i], sched);
>>>> }
>>>>
>>>> init_waitqueue_head(&sched->job_scheduled);
>>>
>>
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 02/28] drm/sched: Add some scheduling quality unit tests
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 01/28] drm/sched: Reverse drm_sched_rq_init arguments Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 9:38 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 03/28] drm/sched: Add some more " Tvrtko Ursulin
` (26 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner,
Pierre-Eric Pelloux-Prayer
To make evaluating different scheduling policies easier (no need for
external benchmarks) and perfectly repeatable, lets add some synthetic
workloads built upon mock scheduler unit test infrastructure.
Focus is on two parallel clients (two threads) submitting different job
patterns and logging their progress and some overall metrics. This is
repeated for both scheduler credit limit 1 and 2.
Example test output:
Normal and low:
pct1 cps1 qd1; pct2 cps2 qd2
+ 0ms: 0 0 0; 0 0 0
+ 104ms: 100 1240 112; 100 1240 125
+ 209ms: 100 0 99; 100 0 125
+ 313ms: 100 0 86; 100 0 125
+ 419ms: 100 0 73; 100 0 125
+ 524ms: 100 0 60; 100 0 125
+ 628ms: 100 0 47; 100 0 125
+ 731ms: 100 0 34; 100 0 125
+ 836ms: 100 0 21; 100 0 125
+ 939ms: 100 0 8; 100 0 125
+ 1043ms: ; 100 0 120
+ 1147ms: ; 100 0 107
+ 1252ms: ; 100 0 94
+ 1355ms: ; 100 0 81
+ 1459ms: ; 100 0 68
+ 1563ms: ; 100 0 55
+ 1667ms: ; 100 0 42
+ 1771ms: ; 100 0 29
+ 1875ms: ; 100 0 16
+ 1979ms: ; 100 0 3
0: prio=normal sync=0 elapsed_ms=1015ms (ideal_ms=1000ms) cycle_time(min,avg,max)=134,222,978 us latency_time(min,avg,max)=134,222,978
us
1: prio=low sync=0 elapsed_ms=2009ms (ideal_ms=1000ms) cycle_time(min,avg,max)=134,215,806 us latency_time(min,avg,max)=134,215,806 us
There we have two clients represented in the two respective columns, with
their progress logged roughly every 100 milliseconds. The metrics are:
- pct - Percentage progress of the job submit part
- cps - Cycles per second
- qd - Queue depth - number of submitted unfinished jobs
The cycles per second metric is inherent to the fact that workload
patterns are a data driven cycling sequence of:
- Submit 1..N jobs
- Wait for Nth job to finish (optional)
- Sleep (optional)
- Repeat from start
In this particular example we have a normal priority and a low priority
clients both spamming the scheduler with 8ms jobs with no sync and no
sleeping. Hence they build a very deep queues and we can see how the low
priority client is completely starved until the normal finishes.
Note that the PCT and CPS metrics are irrelevant for "unsync" clients
since they manage to complete all of their cycles instantaneously.
A different example would be:
Heavy and interactive:
pct1 cps1 qd1; pct2 cps2 qd2
+ 0ms: 0 0 0; 0 0 0
+ 106ms: 5 40 3; 5 40 0
+ 209ms: 9 40 0; 9 40 0
+ 314ms: 14 50 3; 14 50 0
+ 417ms: 18 40 0; 18 40 0
+ 522ms: 23 50 3; 23 50 0
+ 625ms: 27 40 0; 27 40 1
+ 729ms: 32 50 0; 32 50 0
+ 833ms: 36 40 1; 36 40 0
+ 937ms: 40 40 0; 40 40 0
+ 1041ms: 45 50 0; 45 50 0
+ 1146ms: 49 40 1; 49 40 1
+ 1249ms: 54 50 0; 54 50 0
+ 1353ms: 58 40 1; 58 40 0
+ 1457ms: 62 40 0; 62 40 1
+ 1561ms: 67 50 0; 67 50 0
+ 1665ms: 71 40 1; 71 40 0
+ 1772ms: 76 50 0; 76 50 0
+ 1877ms: 80 40 1; 80 40 0
+ 1981ms: 84 40 0; 84 40 0
+ 2085ms: 89 50 0; 89 50 0
+ 2189ms: 93 40 1; 93 40 0
+ 2293ms: 97 40 0; 97 40 1
In this case client one is submitting 3x 2.5ms jobs, waiting for the 3rd
and then sleeping for 2.5ms (in effect causing 75% GPU load, minus the
overheads). Second client is submitting 1ms jobs, waiting for each to
finish and sleeping for 9ms (effective 10% GPU load). Here we can see
the PCT and CPS reflecting real progress.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
Acked-by: Christian König <christian.koenig@amd.com>
---
drivers/gpu/drm/scheduler/tests/Makefile | 3 +-
.../gpu/drm/scheduler/tests/tests_scheduler.c | 694 ++++++++++++++++++
2 files changed, 696 insertions(+), 1 deletion(-)
create mode 100644 drivers/gpu/drm/scheduler/tests/tests_scheduler.c
diff --git a/drivers/gpu/drm/scheduler/tests/Makefile b/drivers/gpu/drm/scheduler/tests/Makefile
index 5bf707bad373..9ec185fbbc15 100644
--- a/drivers/gpu/drm/scheduler/tests/Makefile
+++ b/drivers/gpu/drm/scheduler/tests/Makefile
@@ -2,6 +2,7 @@
drm-sched-tests-y := \
mock_scheduler.o \
- tests_basic.o
+ tests_basic.o \
+ tests_scheduler.o
obj-$(CONFIG_DRM_SCHED_KUNIT_TEST) += drm-sched-tests.o
diff --git a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
new file mode 100644
index 000000000000..c66c151a66d2
--- /dev/null
+++ b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
@@ -0,0 +1,694 @@
+// SPDX-License-Identifier: GPL-2.0
+/* Copyright (c) 2025 Valve Corporation */
+
+#include <linux/delay.h>
+#include <linux/kthread.h>
+#include <linux/ktime.h>
+#include <linux/math64.h>
+
+#include "sched_tests.h"
+
+/*
+ * DRM scheduler scheduler tests exercise load balancing decisions ie. entity
+ * selection logic.
+ */
+
+static int drm_sched_scheduler_init(struct kunit *test)
+{
+ struct drm_mock_scheduler *sched;
+
+ sched = drm_mock_sched_new(test, MAX_SCHEDULE_TIMEOUT);
+ sched->base.credit_limit = 1;
+
+ test->priv = sched;
+
+ return 0;
+}
+
+static int drm_sched_scheduler_init2(struct kunit *test)
+{
+ struct drm_mock_scheduler *sched;
+
+ sched = drm_mock_sched_new(test, MAX_SCHEDULE_TIMEOUT);
+ sched->base.credit_limit = 2;
+
+ test->priv = sched;
+
+ return 0;
+}
+
+static void drm_sched_scheduler_exit(struct kunit *test)
+{
+ struct drm_mock_scheduler *sched = test->priv;
+
+ drm_mock_sched_fini(sched);
+}
+
+static void drm_sched_scheduler_queue_overhead(struct kunit *test)
+{
+ struct drm_mock_scheduler *sched = test->priv;
+ struct drm_mock_sched_entity *entity;
+ const unsigned int job_us = 1000;
+ const unsigned int jobs = 1000;
+ const unsigned int total_us = jobs * job_us;
+ struct drm_mock_sched_job *job, *first;
+ ktime_t start, end;
+ bool done;
+ int i;
+
+ /*
+ * Deep queue job at a time processing (single credit).
+ *
+ * This measures the overhead of picking and processing a job at a time
+ * by comparing the ideal total "GPU" time of all submitted jobs versus
+ * the time actually taken.
+ */
+
+ KUNIT_ASSERT_EQ(test, sched->base.credit_limit, 1);
+
+ entity = drm_mock_sched_entity_new(test,
+ DRM_SCHED_PRIORITY_NORMAL,
+ sched);
+
+ for (i = 0; i <= jobs; i++) {
+ job = drm_mock_sched_job_new(test, entity);
+ if (i == 0)
+ first = job; /* Extra first job blocks the queue */
+ else
+ drm_mock_sched_job_set_duration_us(job, job_us);
+ drm_mock_sched_job_submit(job);
+ }
+
+ done = drm_mock_sched_job_wait_scheduled(first, HZ);
+ KUNIT_ASSERT_TRUE(test, done);
+
+ start = ktime_get();
+ i = drm_mock_sched_advance(sched, 1); /* Release the queue */
+ KUNIT_ASSERT_EQ(test, i, 1);
+
+ /* Wait with a safe margin to avoid every failing. */
+ done = drm_mock_sched_job_wait_finished(job,
+ usecs_to_jiffies(total_us) * 5);
+ end = ktime_get();
+ KUNIT_ASSERT_TRUE(test, done);
+
+ pr_info("Expected %uus, actual %lldus\n",
+ total_us,
+ ktime_to_us(ktime_sub(end, start)));
+
+ drm_mock_sched_entity_free(entity);
+}
+
+static void drm_sched_scheduler_ping_pong(struct kunit *test)
+{
+ struct drm_mock_sched_job *job, *first, *prev = NULL;
+ struct drm_mock_scheduler *sched = test->priv;
+ struct drm_mock_sched_entity *entity[2];
+ const unsigned int job_us = 1000;
+ const unsigned int jobs = 1000;
+ const unsigned int total_us = jobs * job_us;
+ ktime_t start, end;
+ bool done;
+ int i;
+
+ /*
+ * Two entitites in inter-dependency chain.
+ *
+ * This measures the overhead of picking and processing a job at a time,
+ * where each job depends on the previous one from the diffferent
+ * entity, by comparing the ideal total "GPU" time of all submitted jobs
+ * versus the time actually taken.
+ */
+
+ KUNIT_ASSERT_EQ(test, sched->base.credit_limit, 1);
+
+ for (i = 0; i < ARRAY_SIZE(entity); i++)
+ entity[i] = drm_mock_sched_entity_new(test,
+ DRM_SCHED_PRIORITY_NORMAL,
+ sched);
+
+ for (i = 0; i <= jobs; i++) {
+ job = drm_mock_sched_job_new(test, entity[i & 1]);
+ if (i == 0)
+ first = job; /* Extra first job blocks the queue */
+ else
+ drm_mock_sched_job_set_duration_us(job, job_us);
+ if (prev)
+ drm_sched_job_add_dependency(&job->base,
+ dma_fence_get(&prev->base.s_fence->finished));
+ drm_mock_sched_job_submit(job);
+ prev = job;
+ }
+
+ done = drm_mock_sched_job_wait_scheduled(first, HZ);
+ KUNIT_ASSERT_TRUE(test, done);
+
+ start = ktime_get();
+ i = drm_mock_sched_advance(sched, 1); /* Release the queue */
+ KUNIT_ASSERT_EQ(test, i, 1);
+
+ /* Wait with a safe margin to avoid every failing. */
+ done = drm_mock_sched_job_wait_finished(job,
+ usecs_to_jiffies(total_us) * 5);
+ end = ktime_get();
+ KUNIT_ASSERT_TRUE(test, done);
+
+ pr_info("Expected %uus, actual %lldus\n",
+ total_us,
+ ktime_to_us(ktime_sub(end, start)));
+
+ for (i = 0; i < ARRAY_SIZE(entity); i++)
+ drm_mock_sched_entity_free(entity[i]);
+}
+
+static struct kunit_case drm_sched_scheduler_overhead_tests[] = {
+ KUNIT_CASE_SLOW(drm_sched_scheduler_queue_overhead),
+ KUNIT_CASE_SLOW(drm_sched_scheduler_ping_pong),
+ {}
+};
+
+static struct kunit_suite drm_sched_scheduler_overhead = {
+ .name = "drm_sched_scheduler_overhead_tests",
+ .init = drm_sched_scheduler_init,
+ .exit = drm_sched_scheduler_exit,
+ .test_cases = drm_sched_scheduler_overhead_tests,
+};
+
+/*
+ * struct drm_sched_client_params - describe a workload emitted from a client
+ *
+ * A simulated client will create an entity with a scheduling @priority and emit
+ * jobs in a loop where each iteration will consist of:
+ *
+ * 1. Submit @job_cnt jobs, each with a set duration of @job_us.
+ * 2. If @sync is true wait for last submitted job to finish.
+ * 3. Sleep for @wait_us micro-seconds.
+ * 4. Repeat.
+ */
+struct drm_sched_client_params {
+ enum drm_sched_priority priority;
+ unsigned int job_cnt;
+ unsigned int job_us;
+ bool sync;
+ unsigned int wait_us;
+};
+
+struct drm_sched_test_params {
+ const char *description;
+ struct drm_sched_client_params client[2];
+};
+
+static const struct drm_sched_test_params drm_sched_cases[] = {
+ {
+ .description = "Normal and normal",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 8000,
+ .wait_us = 0,
+ .sync = false,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 8000,
+ .wait_us = 0,
+ .sync = false,
+ },
+ },
+ {
+ .description = "Normal and low",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 8000,
+ .wait_us = 0,
+ .sync = false,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_LOW,
+ .job_cnt = 1,
+ .job_us = 8000,
+ .wait_us = 0,
+ .sync = false,
+ },
+ },
+ {
+ .description = "High and normal",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_HIGH,
+ .job_cnt = 1,
+ .job_us = 8000,
+ .wait_us = 0,
+ .sync = false,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 8000,
+ .wait_us = 0,
+ .sync = false,
+ },
+ },
+ {
+ .description = "High and low",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_HIGH,
+ .job_cnt = 1,
+ .job_us = 8000,
+ .wait_us = 0,
+ .sync = false,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_LOW,
+ .job_cnt = 1,
+ .job_us = 8000,
+ .wait_us = 0,
+ .sync = false,
+ },
+ },
+ {
+ .description = "50 and 50",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 1500,
+ .wait_us = 1500,
+ .sync = true,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 2500,
+ .wait_us = 2500,
+ .sync = true,
+ },
+ },
+ {
+ .description = "50 and 50 low",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 1500,
+ .wait_us = 1500,
+ .sync = true,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_LOW,
+ .job_cnt = 1,
+ .job_us = 2500,
+ .wait_us = 2500,
+ .sync = true,
+ },
+ },
+ {
+ .description = "50 high and 50",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_HIGH,
+ .job_cnt = 1,
+ .job_us = 1500,
+ .wait_us = 1500,
+ .sync = true,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 2500,
+ .wait_us = 2500,
+ .sync = true,
+ },
+ },
+ {
+ .description = "Low hog and interactive",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_LOW,
+ .job_cnt = 3,
+ .job_us = 2500,
+ .wait_us = 500,
+ .sync = false,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 500,
+ .wait_us = 10000,
+ .sync = true,
+ },
+ },
+ {
+ .description = "Heavy and interactive",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 3,
+ .job_us = 2500,
+ .wait_us = 2500,
+ .sync = true,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 1000,
+ .wait_us = 9000,
+ .sync = true,
+ },
+ },
+ {
+ .description = "Very heavy and interactive",
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 4,
+ .job_us = 50000,
+ .wait_us = 1,
+ .sync = true,
+ },
+ .client[1] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 1,
+ .job_us = 1000,
+ .wait_us = 9000,
+ .sync = true,
+ },
+ },
+};
+
+static void
+drm_sched_desc(const struct drm_sched_test_params *params, char *desc)
+{
+ strscpy(desc, params->description, KUNIT_PARAM_DESC_SIZE);
+}
+
+KUNIT_ARRAY_PARAM(drm_sched_scheduler_two_clients,
+ drm_sched_cases,
+ drm_sched_desc);
+
+/*
+ * struct test_client_stats - track client stats
+ *
+ * For each client executing a simulated workload we track some timings for
+ * which we are interested in the minimum of all iterations (@min_us), maximum
+ * (@max_us) and the overall total for all iterations (@tot_us).
+ */
+struct test_client_stats {
+ unsigned int min_us;
+ unsigned int max_us;
+ unsigned long tot_us;
+};
+
+/*
+ * struct test_client - a simulated userspace client submitting scheduler work
+ *
+ * Each client executing a simulated workload is represented by one of these.
+ *
+ * Each of them instantiates a scheduling @entity and executes a workloads as
+ * defined in @params. Based on those @params the theoretical execution time of
+ * the client is calculated as @ideal_duration, while the actual wall time is
+ * tracked in @duration (calculated based on the @start and @end client time-
+ * stamps).
+ *
+ * Numerical @id is assigned to each for logging purposes.
+ *
+ * @worker and @work are used to provide an independent execution context from
+ * which scheduler jobs are submitted.
+ *
+ * During execution statistics on how long it took to submit and execute one
+ * iteration (whether or not synchronous) is kept in @cycle_time, while
+ * @latency_time tracks the @cycle_time minus the ideal duration of the one
+ * cycle.
+ *
+ * Once the client has completed the set number of iterations it will write the
+ * completion status into @done.
+ */
+struct test_client {
+ struct kunit *test; /* Backpointer to the kunit test. */
+
+ struct drm_mock_sched_entity *entity;
+
+ struct kthread_worker *worker;
+ struct kthread_work work;
+
+ unsigned int id;
+ ktime_t duration;
+
+ struct drm_sched_client_params params;
+
+ ktime_t ideal_duration;
+ unsigned int cycles;
+ unsigned int cycle;
+ ktime_t start;
+ ktime_t end;
+ bool done;
+
+ struct test_client_stats cycle_time;
+ struct test_client_stats latency_time;
+};
+
+static void
+update_stats(struct test_client_stats *stats, unsigned int us)
+{
+ if (us > stats->max_us)
+ stats->max_us = us;
+ if (us < stats->min_us)
+ stats->min_us = us;
+ stats->tot_us += us;
+}
+
+static unsigned int
+get_stats_avg(struct test_client_stats *stats, unsigned int cycles)
+{
+ return div_u64(stats->tot_us, cycles);
+}
+
+static void drm_sched_client_work(struct kthread_work *work)
+{
+ struct test_client *client = container_of(work, typeof(*client), work);
+ const long sync_wait = MAX_SCHEDULE_TIMEOUT;
+ unsigned int cycle, work_us, period_us;
+ struct drm_mock_sched_job *job = NULL;
+
+ work_us = client->params.job_cnt * client->params.job_us;
+ period_us = work_us + client->params.wait_us;
+ client->cycles =
+ DIV_ROUND_UP((unsigned int)ktime_to_us(client->duration),
+ period_us);
+ client->ideal_duration = us_to_ktime(client->cycles * period_us);
+
+ client->start = ktime_get();
+
+ for (cycle = 0; cycle < client->cycles; cycle++) {
+ ktime_t cycle_time;
+ unsigned int batch;
+ unsigned long us;
+
+ if (READ_ONCE(client->done))
+ break;
+
+ cycle_time = ktime_get();
+ for (batch = 0; batch < client->params.job_cnt; batch++) {
+ job = drm_mock_sched_job_new(client->test,
+ client->entity);
+ drm_mock_sched_job_set_duration_us(job,
+ client->params.job_us);
+ drm_mock_sched_job_submit(job);
+ }
+
+ if (client->params.sync)
+ drm_mock_sched_job_wait_finished(job, sync_wait);
+
+ cycle_time = ktime_sub(ktime_get(), cycle_time);
+ us = ktime_to_us(cycle_time);
+ update_stats(&client->cycle_time, us);
+ if (ktime_to_us(cycle_time) >= (long)work_us)
+ us = ktime_to_us(cycle_time) - work_us;
+ else if (WARN_ON_ONCE(client->params.sync)) /* GPU job took less than expected. */
+ us = 0;
+ update_stats(&client->latency_time, us);
+ WRITE_ONCE(client->cycle, cycle);
+
+ if (READ_ONCE(client->done))
+ break;
+
+ if (client->params.wait_us)
+ fsleep(client->params.wait_us);
+ else if (!client->params.sync)
+ cond_resched(); /* Do not hog the CPU if fully async. */
+ }
+
+ client->done = drm_mock_sched_job_wait_finished(job, sync_wait);
+ client->end = ktime_get();
+}
+
+static const char *prio_str(enum drm_sched_priority prio)
+{
+ switch (prio) {
+ case DRM_SCHED_PRIORITY_KERNEL:
+ return "kernel";
+ case DRM_SCHED_PRIORITY_LOW:
+ return "low";
+ case DRM_SCHED_PRIORITY_NORMAL:
+ return "normal";
+ case DRM_SCHED_PRIORITY_HIGH:
+ return "high";
+ default:
+ return "???";
+ }
+}
+
+static bool client_done(struct test_client *client)
+{
+ return READ_ONCE(client->done); /* READ_ONCE to document lockless read from a loop. */
+}
+
+static void drm_sched_scheduler_two_clients_test(struct kunit *test)
+{
+ const struct drm_sched_test_params *params = test->param_value;
+ struct drm_mock_scheduler *sched = test->priv;
+ struct test_client client[2] = { };
+ unsigned int prev_cycle[2] = { };
+ unsigned int i, j;
+ ktime_t start;
+
+ /*
+ * Same job stream from two clients.
+ */
+
+ for (i = 0; i < ARRAY_SIZE(client); i++)
+ client[i].entity =
+ drm_mock_sched_entity_new(test,
+ params->client[i].priority,
+ sched);
+
+ for (i = 0; i < ARRAY_SIZE(client); i++) {
+ client[i].test = test;
+ client[i].id = i;
+ client[i].duration = ms_to_ktime(1000);
+ client[i].params = params->client[i];
+ client[i].cycle_time.min_us = ~0U;
+ client[i].latency_time.min_us = ~0U;
+ client[i].worker =
+ kthread_create_worker(0, "%s-%u", __func__, i);
+ if (IS_ERR(client[i].worker)) {
+ for (j = 0; j < i; j++)
+ kthread_destroy_worker(client[j].worker);
+ KUNIT_FAIL(test, "Failed to create worker!\n");
+ }
+
+ kthread_init_work(&client[i].work, drm_sched_client_work);
+ }
+
+ for (i = 0; i < ARRAY_SIZE(client); i++)
+ kthread_queue_work(client[i].worker, &client[i].work);
+
+ /*
+ * The clients (workers) can be a mix of async (deep submission queue),
+ * sync (one job at a time), or something in between. Therefore it is
+ * difficult to display a single metric representing their progress.
+ *
+ * Each struct drm_sched_client_params describes the actual submission
+ * pattern which happens in the following steps:
+ * 1. Submit N jobs
+ * 2. Wait for last submitted job to finish
+ * 3. Sleep for U micro-seconds
+ * 4. Goto 1. for C cycles
+ *
+ * Where number of cycles is calculated to match the target client
+ * duration from the respective struct drm_sched_test_params.
+ *
+ * To asses scheduling behaviour what we output for both clients is:
+ * - pct: Percentage progress of the jobs submitted
+ * - cps: "Cycles" per second (where one cycle is one complete
+ * iteration from the above)
+ * - qd: Number of outstanding jobs in the client/entity
+ */
+
+ start = ktime_get();
+ pr_info("%s:\n\t pct1 cps1 qd1; pct2 cps2 qd2\n",
+ params->description);
+ while (!client_done(&client[0]) || !client_done(&client[1])) {
+ const unsigned int period_ms = 100;
+ const unsigned int frequency = 1000 / period_ms;
+ unsigned int pct[2], qd[2], cycle[2], cps[2];
+
+ for (i = 0; i < ARRAY_SIZE(client); i++) {
+ qd[i] = spsc_queue_count(&client[i].entity->base.job_queue);
+ cycle[i] = READ_ONCE(client[i].cycle);
+ cps[i] = DIV_ROUND_UP(100 * frequency *
+ (cycle[i] - prev_cycle[i]),
+ 100);
+ if (client[i].cycles)
+ pct[i] = DIV_ROUND_UP(100 * (1 + cycle[i]),
+ client[i].cycles);
+ else
+ pct[i] = 0;
+ prev_cycle[i] = cycle[i];
+ }
+
+ if (client_done(&client[0]))
+ pr_info("\t+%6lldms: ; %3u %5u %4u\n",
+ ktime_to_ms(ktime_sub(ktime_get(), start)),
+ pct[1], cps[1], qd[1]);
+ else if (client_done(&client[1]))
+ pr_info("\t+%6lldms: %3u %5u %4u;\n",
+ ktime_to_ms(ktime_sub(ktime_get(), start)),
+ pct[0], cps[0], qd[0]);
+ else
+ pr_info("\t+%6lldms: %3u %5u %4u; %3u %5u %4u\n",
+ ktime_to_ms(ktime_sub(ktime_get(), start)),
+ pct[0], cps[0], qd[0],
+ pct[1], cps[1], qd[1]);
+
+ msleep(period_ms);
+ }
+
+ for (i = 0; i < ARRAY_SIZE(client); i++) {
+ kthread_flush_work(&client[i].work);
+ kthread_destroy_worker(client[i].worker);
+ }
+
+ for (i = 0; i < ARRAY_SIZE(client); i++)
+ KUNIT_ASSERT_TRUE(test, client[i].done);
+
+ for (i = 0; i < ARRAY_SIZE(client); i++) {
+ pr_info(" %u: prio=%s sync=%u elapsed_ms=%lldms (ideal_ms=%lldms) cycle_time(min,avg,max)=%u,%u,%u us latency_time(min,avg,max)=%u,%u,%u us",
+ i,
+ prio_str(params->client[i].priority),
+ params->client[i].sync,
+ ktime_to_ms(ktime_sub(client[i].end, client[i].start)),
+ ktime_to_ms(client[i].ideal_duration),
+ client[i].cycle_time.min_us,
+ get_stats_avg(&client[i].cycle_time, client[i].cycles),
+ client[i].cycle_time.max_us,
+ client[i].latency_time.min_us,
+ get_stats_avg(&client[i].latency_time, client[i].cycles),
+ client[i].latency_time.max_us);
+ drm_mock_sched_entity_free(client[i].entity);
+ }
+}
+
+static const struct kunit_attributes drm_sched_scheduler_two_clients_attr = {
+ .speed = KUNIT_SPEED_SLOW,
+};
+
+static struct kunit_case drm_sched_scheduler_two_clients_tests[] = {
+ KUNIT_CASE_PARAM_ATTR(drm_sched_scheduler_two_clients_test,
+ drm_sched_scheduler_two_clients_gen_params,
+ drm_sched_scheduler_two_clients_attr),
+ {}
+};
+
+static struct kunit_suite drm_sched_scheduler_two_clients1 = {
+ .name = "drm_sched_scheduler_two_clients_one_credit_tests",
+ .init = drm_sched_scheduler_init,
+ .exit = drm_sched_scheduler_exit,
+ .test_cases = drm_sched_scheduler_two_clients_tests,
+};
+
+static struct kunit_suite drm_sched_scheduler_two_clients2 = {
+ .name = "drm_sched_scheduler_two_clients_two_credits_tests",
+ .init = drm_sched_scheduler_init2,
+ .exit = drm_sched_scheduler_exit,
+ .test_cases = drm_sched_scheduler_two_clients_tests,
+};
+
+kunit_test_suites(&drm_sched_scheduler_overhead,
+ &drm_sched_scheduler_two_clients1,
+ &drm_sched_scheduler_two_clients2);
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 02/28] drm/sched: Add some scheduling quality unit tests
2025-10-08 8:53 ` [PATCH 02/28] drm/sched: Add some scheduling quality unit tests Tvrtko Ursulin
@ 2025-10-10 9:38 ` Philipp Stanner
2025-10-11 13:09 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 9:38 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner, Pierre-Eric Pelloux-Prayer
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> To make evaluating different scheduling policies easier (no need for
> external benchmarks) and perfectly repeatable, lets add some synthetic
> workloads built upon mock scheduler unit test infrastructure.
>
> Focus is on two parallel clients (two threads) submitting different job
> patterns and logging their progress and some overall metrics. This is
> repeated for both scheduler credit limit 1 and 2.
>
> Example test output:
>
> Normal and low:
> pct1 cps1 qd1; pct2 cps2 qd2
> + 0ms: 0 0 0; 0 0 0
> + 104ms: 100 1240 112; 100 1240 125
> + 209ms: 100 0 99; 100 0 125
> + 313ms: 100 0 86; 100 0 125
> + 419ms: 100 0 73; 100 0 125
> + 524ms: 100 0 60; 100 0 125
> + 628ms: 100 0 47; 100 0 125
> + 731ms: 100 0 34; 100 0 125
> + 836ms: 100 0 21; 100 0 125
> + 939ms: 100 0 8; 100 0 125
> + 1043ms: ; 100 0 120
> + 1147ms: ; 100 0 107
> + 1252ms: ; 100 0 94
> + 1355ms: ; 100 0 81
> + 1459ms: ; 100 0 68
> + 1563ms: ; 100 0 55
> + 1667ms: ; 100 0 42
> + 1771ms: ; 100 0 29
> + 1875ms: ; 100 0 16
> + 1979ms: ; 100 0 3
> 0: prio=normal sync=0 elapsed_ms=1015ms (ideal_ms=1000ms) cycle_time(min,avg,max)=134,222,978 us latency_time(min,avg,max)=134,222,978
> us
> 1: prio=low sync=0 elapsed_ms=2009ms (ideal_ms=1000ms) cycle_time(min,avg,max)=134,215,806 us latency_time(min,avg,max)=134,215,806 us
>
> There we have two clients represented in the two respective columns, with
> their progress logged roughly every 100 milliseconds. The metrics are:
>
> - pct - Percentage progress of the job submit part
> - cps - Cycles per second
> - qd - Queue depth - number of submitted unfinished jobs
Could make sense to print a legend above the test table, couldn't it?
So new users don't have to search in the code what the output means.
>
> The cycles per second metric is inherent to the fact that workload
> patterns are a data driven cycling sequence of:
>
> - Submit 1..N jobs
> - Wait for Nth job to finish (optional)
> - Sleep (optional)
> - Repeat from start
>
> In this particular example we have a normal priority and a low priority
> clients both spamming the scheduler with 8ms jobs with no sync and no
s/clients/client
> sleeping. Hence they build a very deep queues and we can see how the low
s/a//
> priority client is completely starved until the normal finishes.
>
> Note that the PCT and CPS metrics are irrelevant for "unsync" clients
> since they manage to complete all of their cycles instantaneously.
>
> A different example would be:
>
> Heavy and interactive:
> pct1 cps1 qd1; pct2 cps2 qd2
> + 0ms: 0 0 0; 0 0 0
> + 106ms: 5 40 3; 5 40 0
> + 209ms: 9 40 0; 9 40 0
> + 314ms: 14 50 3; 14 50 0
> + 417ms: 18 40 0; 18 40 0
> + 522ms: 23 50 3; 23 50 0
> + 625ms: 27 40 0; 27 40 1
> + 729ms: 32 50 0; 32 50 0
> + 833ms: 36 40 1; 36 40 0
> + 937ms: 40 40 0; 40 40 0
> + 1041ms: 45 50 0; 45 50 0
> + 1146ms: 49 40 1; 49 40 1
> + 1249ms: 54 50 0; 54 50 0
> + 1353ms: 58 40 1; 58 40 0
> + 1457ms: 62 40 0; 62 40 1
> + 1561ms: 67 50 0; 67 50 0
> + 1665ms: 71 40 1; 71 40 0
> + 1772ms: 76 50 0; 76 50 0
> + 1877ms: 80 40 1; 80 40 0
> + 1981ms: 84 40 0; 84 40 0
> + 2085ms: 89 50 0; 89 50 0
> + 2189ms: 93 40 1; 93 40 0
> + 2293ms: 97 40 0; 97 40 1
>
> In this case client one is submitting 3x 2.5ms jobs, waiting for the 3rd
> and then sleeping for 2.5ms (in effect causing 75% GPU load, minus the
> overheads). Second client is submitting 1ms jobs, waiting for each to
> finish and sleeping for 9ms (effective 10% GPU load). Here we can see
> the PCT and CPS reflecting real progress.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
> Acked-by: Christian König <christian.koenig@amd.com>
> ---
> drivers/gpu/drm/scheduler/tests/Makefile | 3 +-
> .../gpu/drm/scheduler/tests/tests_scheduler.c | 694 ++++++++++++++++++
> 2 files changed, 696 insertions(+), 1 deletion(-)
> create mode 100644 drivers/gpu/drm/scheduler/tests/tests_scheduler.c
>
> diff --git a/drivers/gpu/drm/scheduler/tests/Makefile b/drivers/gpu/drm/scheduler/tests/Makefile
> index 5bf707bad373..9ec185fbbc15 100644
> --- a/drivers/gpu/drm/scheduler/tests/Makefile
> +++ b/drivers/gpu/drm/scheduler/tests/Makefile
> @@ -2,6 +2,7 @@
>
> drm-sched-tests-y := \
> mock_scheduler.o \
> - tests_basic.o
> + tests_basic.o \
> + tests_scheduler.o
>
> obj-$(CONFIG_DRM_SCHED_KUNIT_TEST) += drm-sched-tests.o
> diff --git a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
> new file mode 100644
> index 000000000000..c66c151a66d2
> --- /dev/null
> +++ b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
> @@ -0,0 +1,694 @@
> +// SPDX-License-Identifier: GPL-2.0
> +/* Copyright (c) 2025 Valve Corporation */
> +
> +#include <linux/delay.h>
> +#include <linux/kthread.h>
> +#include <linux/ktime.h>
> +#include <linux/math64.h>
> +
> +#include "sched_tests.h"
> +
> +/*
> + * DRM scheduler scheduler tests exercise load balancing decisions ie. entity
> + * selection logic.
> + */
> +
> +static int drm_sched_scheduler_init(struct kunit *test)
> +{
> + struct drm_mock_scheduler *sched;
> +
> + sched = drm_mock_sched_new(test, MAX_SCHEDULE_TIMEOUT);
> + sched->base.credit_limit = 1;
> +
> + test->priv = sched;
> +
> + return 0;
> +}
> +
> +static int drm_sched_scheduler_init2(struct kunit *test)
> +{
> + struct drm_mock_scheduler *sched;
> +
> + sched = drm_mock_sched_new(test, MAX_SCHEDULE_TIMEOUT);
> + sched->base.credit_limit = 2;
> +
> + test->priv = sched;
> +
> + return 0;
> +}
> +
> +static void drm_sched_scheduler_exit(struct kunit *test)
> +{
> + struct drm_mock_scheduler *sched = test->priv;
> +
> + drm_mock_sched_fini(sched);
> +}
> +
> +static void drm_sched_scheduler_queue_overhead(struct kunit *test)
> +{
> + struct drm_mock_scheduler *sched = test->priv;
> + struct drm_mock_sched_entity *entity;
> + const unsigned int job_us = 1000;
> + const unsigned int jobs = 1000;
> + const unsigned int total_us = jobs * job_us;
> + struct drm_mock_sched_job *job, *first;
> + ktime_t start, end;
> + bool done;
> + int i;
> +
> + /*
> + * Deep queue job at a time processing (single credit).
> + *
> + * This measures the overhead of picking and processing a job at a time
> + * by comparing the ideal total "GPU" time of all submitted jobs versus
> + * the time actually taken.
> + */
> +
> + KUNIT_ASSERT_EQ(test, sched->base.credit_limit, 1);
> +
> + entity = drm_mock_sched_entity_new(test,
> + DRM_SCHED_PRIORITY_NORMAL,
> + sched);
> +
> + for (i = 0; i <= jobs; i++) {
> + job = drm_mock_sched_job_new(test, entity);
> + if (i == 0)
> + first = job; /* Extra first job blocks the queue */
> + else
> + drm_mock_sched_job_set_duration_us(job, job_us);
> + drm_mock_sched_job_submit(job);
> + }
> +
> + done = drm_mock_sched_job_wait_scheduled(first, HZ);
> + KUNIT_ASSERT_TRUE(test, done);
> +
> + start = ktime_get();
> + i = drm_mock_sched_advance(sched, 1); /* Release the queue */
> + KUNIT_ASSERT_EQ(test, i, 1);
> +
> + /* Wait with a safe margin to avoid every failing. */
> + done = drm_mock_sched_job_wait_finished(job,
> + usecs_to_jiffies(total_us) * 5);
> + end = ktime_get();
> + KUNIT_ASSERT_TRUE(test, done);
> +
> + pr_info("Expected %uus, actual %lldus\n",
> + total_us,
> + ktime_to_us(ktime_sub(end, start)));
> +
> + drm_mock_sched_entity_free(entity);
> +}
> +
> +static void drm_sched_scheduler_ping_pong(struct kunit *test)
> +{
> + struct drm_mock_sched_job *job, *first, *prev = NULL;
> + struct drm_mock_scheduler *sched = test->priv;
> + struct drm_mock_sched_entity *entity[2];
> + const unsigned int job_us = 1000;
> + const unsigned int jobs = 1000;
> + const unsigned int total_us = jobs * job_us;
> + ktime_t start, end;
> + bool done;
> + int i;
> +
> + /*
> + * Two entitites in inter-dependency chain.
> + *
> + * This measures the overhead of picking and processing a job at a time,
> + * where each job depends on the previous one from the diffferent
> + * entity, by comparing the ideal total "GPU" time of all submitted jobs
> + * versus the time actually taken.
> + */
> +
> + KUNIT_ASSERT_EQ(test, sched->base.credit_limit, 1);
> +
> + for (i = 0; i < ARRAY_SIZE(entity); i++)
> + entity[i] = drm_mock_sched_entity_new(test,
> + DRM_SCHED_PRIORITY_NORMAL,
> + sched);
> +
> + for (i = 0; i <= jobs; i++) {
> + job = drm_mock_sched_job_new(test, entity[i & 1]);
> + if (i == 0)
> + first = job; /* Extra first job blocks the queue */
> + else
> + drm_mock_sched_job_set_duration_us(job, job_us);
> + if (prev)
> + drm_sched_job_add_dependency(&job->base,
> + dma_fence_get(&prev->base.s_fence->finished));
> + drm_mock_sched_job_submit(job);
> + prev = job;
> + }
> +
> + done = drm_mock_sched_job_wait_scheduled(first, HZ);
> + KUNIT_ASSERT_TRUE(test, done);
> +
> + start = ktime_get();
> + i = drm_mock_sched_advance(sched, 1); /* Release the queue */
> + KUNIT_ASSERT_EQ(test, i, 1);
> +
> + /* Wait with a safe margin to avoid every failing. */
> + done = drm_mock_sched_job_wait_finished(job,
> + usecs_to_jiffies(total_us) * 5);
> + end = ktime_get();
> + KUNIT_ASSERT_TRUE(test, done);
> +
> + pr_info("Expected %uus, actual %lldus\n",
> + total_us,
> + ktime_to_us(ktime_sub(end, start)));
> +
> + for (i = 0; i < ARRAY_SIZE(entity); i++)
> + drm_mock_sched_entity_free(entity[i]);
> +}
> +
> +static struct kunit_case drm_sched_scheduler_overhead_tests[] = {
> + KUNIT_CASE_SLOW(drm_sched_scheduler_queue_overhead),
> + KUNIT_CASE_SLOW(drm_sched_scheduler_ping_pong),
> + {}
> +};
> +
> +static struct kunit_suite drm_sched_scheduler_overhead = {
> + .name = "drm_sched_scheduler_overhead_tests",
> + .init = drm_sched_scheduler_init,
> + .exit = drm_sched_scheduler_exit,
> + .test_cases = drm_sched_scheduler_overhead_tests,
> +};
> +
> +/*
> + * struct drm_sched_client_params - describe a workload emitted from a client
> + *
> + * A simulated client will create an entity with a scheduling @priority and emit
> + * jobs in a loop where each iteration will consist of:
> + *
> + * 1. Submit @job_cnt jobs, each with a set duration of @job_us.
> + * 2. If @sync is true wait for last submitted job to finish.
> + * 3. Sleep for @wait_us micro-seconds.
> + * 4. Repeat.
> + */
> +struct drm_sched_client_params {
> + enum drm_sched_priority priority;
> + unsigned int job_cnt;
> + unsigned int job_us;
> + bool sync;
> + unsigned int wait_us;
> +};
> +
> +struct drm_sched_test_params {
> + const char *description;
> + struct drm_sched_client_params client[2];
> +};
> +
> +static const struct drm_sched_test_params drm_sched_cases[] = {
> + {
> + .description = "Normal and normal",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 8000,
> + .wait_us = 0,
> + .sync = false,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 8000,
> + .wait_us = 0,
> + .sync = false,
> + },
> + },
> + {
> + .description = "Normal and low",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 8000,
> + .wait_us = 0,
> + .sync = false,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_LOW,
> + .job_cnt = 1,
> + .job_us = 8000,
> + .wait_us = 0,
> + .sync = false,
> + },
> + },
> + {
> + .description = "High and normal",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_HIGH,
> + .job_cnt = 1,
> + .job_us = 8000,
> + .wait_us = 0,
> + .sync = false,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 8000,
> + .wait_us = 0,
> + .sync = false,
> + },
> + },
> + {
> + .description = "High and low",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_HIGH,
> + .job_cnt = 1,
> + .job_us = 8000,
> + .wait_us = 0,
> + .sync = false,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_LOW,
> + .job_cnt = 1,
> + .job_us = 8000,
> + .wait_us = 0,
> + .sync = false,
> + },
> + },
> + {
> + .description = "50 and 50",
I still think that this should have a more obvious description.
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 1500,
> + .wait_us = 1500,
> + .sync = true,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 2500,
> + .wait_us = 2500,
> + .sync = true,
> + },
> + },
> + {
> + .description = "50 and 50 low",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 1500,
> + .wait_us = 1500,
> + .sync = true,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_LOW,
> + .job_cnt = 1,
> + .job_us = 2500,
> + .wait_us = 2500,
> + .sync = true,
> + },
> + },
> + {
> + .description = "50 high and 50",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_HIGH,
> + .job_cnt = 1,
> + .job_us = 1500,
> + .wait_us = 1500,
> + .sync = true,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 2500,
> + .wait_us = 2500,
> + .sync = true,
> + },
> + },
> + {
> + .description = "Low hog and interactive",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_LOW,
> + .job_cnt = 3,
> + .job_us = 2500,
> + .wait_us = 500,
> + .sync = false,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 500,
> + .wait_us = 10000,
> + .sync = true,
> + },
> + },
> + {
> + .description = "Heavy and interactive",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 3,
> + .job_us = 2500,
> + .wait_us = 2500,
> + .sync = true,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 1000,
> + .wait_us = 9000,
> + .sync = true,
> + },
> + },
> + {
> + .description = "Very heavy and interactive",
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 4,
> + .job_us = 50000,
> + .wait_us = 1,
> + .sync = true,
> + },
> + .client[1] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 1,
> + .job_us = 1000,
> + .wait_us = 9000,
> + .sync = true,
> + },
> + },
> +};
> +
> +static void
> +drm_sched_desc(const struct drm_sched_test_params *params, char *desc)
> +{
> + strscpy(desc, params->description, KUNIT_PARAM_DESC_SIZE);
> +}
> +
> +KUNIT_ARRAY_PARAM(drm_sched_scheduler_two_clients,
> + drm_sched_cases,
> + drm_sched_desc);
> +
> +/*
> + * struct test_client_stats - track client stats
> + *
> + * For each client executing a simulated workload we track some timings for
> + * which we are interested in the minimum of all iterations (@min_us), maximum
> + * (@max_us) and the overall total for all iterations (@tot_us).
> + */
> +struct test_client_stats {
> + unsigned int min_us;
> + unsigned int max_us;
> + unsigned long tot_us;
> +};
> +
> +/*
> + * struct test_client - a simulated userspace client submitting scheduler work
> + *
> + * Each client executing a simulated workload is represented by one of these.
> + *
> + * Each of them instantiates a scheduling @entity and executes a workloads as
> + * defined in @params. Based on those @params the theoretical execution time of
> + * the client is calculated as @ideal_duration, while the actual wall time is
> + * tracked in @duration (calculated based on the @start and @end client time-
> + * stamps).
> + *
> + * Numerical @id is assigned to each for logging purposes.
> + *
> + * @worker and @work are used to provide an independent execution context from
> + * which scheduler jobs are submitted.
> + *
> + * During execution statistics on how long it took to submit and execute one
> + * iteration (whether or not synchronous) is kept in @cycle_time, while
> + * @latency_time tracks the @cycle_time minus the ideal duration of the one
> + * cycle.
> + *
> + * Once the client has completed the set number of iterations it will write the
> + * completion status into @done.
> + */
> +struct test_client {
> + struct kunit *test; /* Backpointer to the kunit test. */
> +
> + struct drm_mock_sched_entity *entity;
> +
> + struct kthread_worker *worker;
> + struct kthread_work work;
The formatting here is strange / differs from below.
P.
> +
> + unsigned int id;
> + ktime_t duration;
> +
> + struct drm_sched_client_params params;
> +
> + ktime_t ideal_duration;
> + unsigned int cycles;
> + unsigned int cycle;
> + ktime_t start;
> + ktime_t end;
> + bool done;
> +
> + struct test_client_stats cycle_time;
> + struct test_client_stats latency_time;
> +};
> +
> +static void
> +update_stats(struct test_client_stats *stats, unsigned int us)
> +{
> + if (us > stats->max_us)
> + stats->max_us = us;
> + if (us < stats->min_us)
> + stats->min_us = us;
> + stats->tot_us += us;
> +}
> +
> +static unsigned int
> +get_stats_avg(struct test_client_stats *stats, unsigned int cycles)
> +{
> + return div_u64(stats->tot_us, cycles);
> +}
> +
> +static void drm_sched_client_work(struct kthread_work *work)
> +{
> + struct test_client *client = container_of(work, typeof(*client), work);
> + const long sync_wait = MAX_SCHEDULE_TIMEOUT;
> + unsigned int cycle, work_us, period_us;
> + struct drm_mock_sched_job *job = NULL;
> +
> + work_us = client->params.job_cnt * client->params.job_us;
> + period_us = work_us + client->params.wait_us;
> + client->cycles =
> + DIV_ROUND_UP((unsigned int)ktime_to_us(client->duration),
> + period_us);
> + client->ideal_duration = us_to_ktime(client->cycles * period_us);
> +
> + client->start = ktime_get();
> +
> + for (cycle = 0; cycle < client->cycles; cycle++) {
> + ktime_t cycle_time;
> + unsigned int batch;
> + unsigned long us;
> +
> + if (READ_ONCE(client->done))
> + break;
> +
> + cycle_time = ktime_get();
> + for (batch = 0; batch < client->params.job_cnt; batch++) {
> + job = drm_mock_sched_job_new(client->test,
> + client->entity);
> + drm_mock_sched_job_set_duration_us(job,
> + client->params.job_us);
> + drm_mock_sched_job_submit(job);
> + }
> +
> + if (client->params.sync)
> + drm_mock_sched_job_wait_finished(job, sync_wait);
> +
> + cycle_time = ktime_sub(ktime_get(), cycle_time);
> + us = ktime_to_us(cycle_time);
> + update_stats(&client->cycle_time, us);
> + if (ktime_to_us(cycle_time) >= (long)work_us)
> + us = ktime_to_us(cycle_time) - work_us;
> + else if (WARN_ON_ONCE(client->params.sync)) /* GPU job took less than expected. */
> + us = 0;
> + update_stats(&client->latency_time, us);
> + WRITE_ONCE(client->cycle, cycle);
> +
> + if (READ_ONCE(client->done))
> + break;
> +
> + if (client->params.wait_us)
> + fsleep(client->params.wait_us);
> + else if (!client->params.sync)
> + cond_resched(); /* Do not hog the CPU if fully async. */
> + }
> +
> + client->done = drm_mock_sched_job_wait_finished(job, sync_wait);
> + client->end = ktime_get();
> +}
> +
> +static const char *prio_str(enum drm_sched_priority prio)
> +{
> + switch (prio) {
> + case DRM_SCHED_PRIORITY_KERNEL:
> + return "kernel";
> + case DRM_SCHED_PRIORITY_LOW:
> + return "low";
> + case DRM_SCHED_PRIORITY_NORMAL:
> + return "normal";
> + case DRM_SCHED_PRIORITY_HIGH:
> + return "high";
> + default:
> + return "???";
> + }
> +}
> +
> +static bool client_done(struct test_client *client)
> +{
> + return READ_ONCE(client->done); /* READ_ONCE to document lockless read from a loop. */
> +}
> +
> +static void drm_sched_scheduler_two_clients_test(struct kunit *test)
> +{
> + const struct drm_sched_test_params *params = test->param_value;
> + struct drm_mock_scheduler *sched = test->priv;
> + struct test_client client[2] = { };
> + unsigned int prev_cycle[2] = { };
> + unsigned int i, j;
> + ktime_t start;
> +
> + /*
> + * Same job stream from two clients.
> + */
> +
> + for (i = 0; i < ARRAY_SIZE(client); i++)
> + client[i].entity =
> + drm_mock_sched_entity_new(test,
> + params->client[i].priority,
> + sched);
> +
> + for (i = 0; i < ARRAY_SIZE(client); i++) {
> + client[i].test = test;
> + client[i].id = i;
> + client[i].duration = ms_to_ktime(1000);
> + client[i].params = params->client[i];
> + client[i].cycle_time.min_us = ~0U;
> + client[i].latency_time.min_us = ~0U;
> + client[i].worker =
> + kthread_create_worker(0, "%s-%u", __func__, i);
> + if (IS_ERR(client[i].worker)) {
> + for (j = 0; j < i; j++)
> + kthread_destroy_worker(client[j].worker);
> + KUNIT_FAIL(test, "Failed to create worker!\n");
> + }
> +
> + kthread_init_work(&client[i].work, drm_sched_client_work);
> + }
> +
> + for (i = 0; i < ARRAY_SIZE(client); i++)
> + kthread_queue_work(client[i].worker, &client[i].work);
> +
> + /*
> + * The clients (workers) can be a mix of async (deep submission queue),
> + * sync (one job at a time), or something in between. Therefore it is
> + * difficult to display a single metric representing their progress.
> + *
> + * Each struct drm_sched_client_params describes the actual submission
> + * pattern which happens in the following steps:
> + * 1. Submit N jobs
> + * 2. Wait for last submitted job to finish
> + * 3. Sleep for U micro-seconds
> + * 4. Goto 1. for C cycles
> + *
> + * Where number of cycles is calculated to match the target client
> + * duration from the respective struct drm_sched_test_params.
> + *
> + * To asses scheduling behaviour what we output for both clients is:
> + * - pct: Percentage progress of the jobs submitted
> + * - cps: "Cycles" per second (where one cycle is one complete
> + * iteration from the above)
> + * - qd: Number of outstanding jobs in the client/entity
> + */
> +
> + start = ktime_get();
> + pr_info("%s:\n\t pct1 cps1 qd1; pct2 cps2 qd2\n",
> + params->description);
> + while (!client_done(&client[0]) || !client_done(&client[1])) {
> + const unsigned int period_ms = 100;
> + const unsigned int frequency = 1000 / period_ms;
> + unsigned int pct[2], qd[2], cycle[2], cps[2];
> +
> + for (i = 0; i < ARRAY_SIZE(client); i++) {
> + qd[i] = spsc_queue_count(&client[i].entity->base.job_queue);
> + cycle[i] = READ_ONCE(client[i].cycle);
> + cps[i] = DIV_ROUND_UP(100 * frequency *
> + (cycle[i] - prev_cycle[i]),
> + 100);
> + if (client[i].cycles)
> + pct[i] = DIV_ROUND_UP(100 * (1 + cycle[i]),
> + client[i].cycles);
> + else
> + pct[i] = 0;
> + prev_cycle[i] = cycle[i];
> + }
> +
> + if (client_done(&client[0]))
> + pr_info("\t+%6lldms: ; %3u %5u %4u\n",
> + ktime_to_ms(ktime_sub(ktime_get(), start)),
> + pct[1], cps[1], qd[1]);
> + else if (client_done(&client[1]))
> + pr_info("\t+%6lldms: %3u %5u %4u;\n",
> + ktime_to_ms(ktime_sub(ktime_get(), start)),
> + pct[0], cps[0], qd[0]);
> + else
> + pr_info("\t+%6lldms: %3u %5u %4u; %3u %5u %4u\n",
> + ktime_to_ms(ktime_sub(ktime_get(), start)),
> + pct[0], cps[0], qd[0],
> + pct[1], cps[1], qd[1]);
> +
> + msleep(period_ms);
> + }
> +
> + for (i = 0; i < ARRAY_SIZE(client); i++) {
> + kthread_flush_work(&client[i].work);
> + kthread_destroy_worker(client[i].worker);
> + }
> +
> + for (i = 0; i < ARRAY_SIZE(client); i++)
> + KUNIT_ASSERT_TRUE(test, client[i].done);
> +
> + for (i = 0; i < ARRAY_SIZE(client); i++) {
> + pr_info(" %u: prio=%s sync=%u elapsed_ms=%lldms (ideal_ms=%lldms) cycle_time(min,avg,max)=%u,%u,%u us latency_time(min,avg,max)=%u,%u,%u us",
> + i,
> + prio_str(params->client[i].priority),
> + params->client[i].sync,
> + ktime_to_ms(ktime_sub(client[i].end, client[i].start)),
> + ktime_to_ms(client[i].ideal_duration),
> + client[i].cycle_time.min_us,
> + get_stats_avg(&client[i].cycle_time, client[i].cycles),
> + client[i].cycle_time.max_us,
> + client[i].latency_time.min_us,
> + get_stats_avg(&client[i].latency_time, client[i].cycles),
> + client[i].latency_time.max_us);
> + drm_mock_sched_entity_free(client[i].entity);
> + }
> +}
> +
> +static const struct kunit_attributes drm_sched_scheduler_two_clients_attr = {
> + .speed = KUNIT_SPEED_SLOW,
> +};
> +
> +static struct kunit_case drm_sched_scheduler_two_clients_tests[] = {
> + KUNIT_CASE_PARAM_ATTR(drm_sched_scheduler_two_clients_test,
> + drm_sched_scheduler_two_clients_gen_params,
> + drm_sched_scheduler_two_clients_attr),
> + {}
> +};
> +
> +static struct kunit_suite drm_sched_scheduler_two_clients1 = {
> + .name = "drm_sched_scheduler_two_clients_one_credit_tests",
> + .init = drm_sched_scheduler_init,
> + .exit = drm_sched_scheduler_exit,
> + .test_cases = drm_sched_scheduler_two_clients_tests,
> +};
> +
> +static struct kunit_suite drm_sched_scheduler_two_clients2 = {
> + .name = "drm_sched_scheduler_two_clients_two_credits_tests",
> + .init = drm_sched_scheduler_init2,
> + .exit = drm_sched_scheduler_exit,
> + .test_cases = drm_sched_scheduler_two_clients_tests,
> +};
> +
> +kunit_test_suites(&drm_sched_scheduler_overhead,
> + &drm_sched_scheduler_two_clients1,
> + &drm_sched_scheduler_two_clients2);
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 02/28] drm/sched: Add some scheduling quality unit tests
2025-10-10 9:38 ` Philipp Stanner
@ 2025-10-11 13:09 ` Tvrtko Ursulin
0 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-11 13:09 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Pierre-Eric Pelloux-Prayer
On 10/10/2025 10:38, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> To make evaluating different scheduling policies easier (no need for
>> external benchmarks) and perfectly repeatable, lets add some synthetic
>> workloads built upon mock scheduler unit test infrastructure.
>>
>> Focus is on two parallel clients (two threads) submitting different job
>> patterns and logging their progress and some overall metrics. This is
>> repeated for both scheduler credit limit 1 and 2.
>>
>> Example test output:
>>
>> Normal and low:
>> pct1 cps1 qd1; pct2 cps2 qd2
>> + 0ms: 0 0 0; 0 0 0
>> + 104ms: 100 1240 112; 100 1240 125
>> + 209ms: 100 0 99; 100 0 125
>> + 313ms: 100 0 86; 100 0 125
>> + 419ms: 100 0 73; 100 0 125
>> + 524ms: 100 0 60; 100 0 125
>> + 628ms: 100 0 47; 100 0 125
>> + 731ms: 100 0 34; 100 0 125
>> + 836ms: 100 0 21; 100 0 125
>> + 939ms: 100 0 8; 100 0 125
>> + 1043ms: ; 100 0 120
>> + 1147ms: ; 100 0 107
>> + 1252ms: ; 100 0 94
>> + 1355ms: ; 100 0 81
>> + 1459ms: ; 100 0 68
>> + 1563ms: ; 100 0 55
>> + 1667ms: ; 100 0 42
>> + 1771ms: ; 100 0 29
>> + 1875ms: ; 100 0 16
>> + 1979ms: ; 100 0 3
>> 0: prio=normal sync=0 elapsed_ms=1015ms (ideal_ms=1000ms) cycle_time(min,avg,max)=134,222,978 us latency_time(min,avg,max)=134,222,978
>> us
>> 1: prio=low sync=0 elapsed_ms=2009ms (ideal_ms=1000ms) cycle_time(min,avg,max)=134,215,806 us latency_time(min,avg,max)=134,215,806 us
>>
>> There we have two clients represented in the two respective columns, with
>> their progress logged roughly every 100 milliseconds. The metrics are:
>>
>> - pct - Percentage progress of the job submit part
>> - cps - Cycles per second
>> - qd - Queue depth - number of submitted unfinished jobs
>
> Could make sense to print a legend above the test table, couldn't it?
> So new users don't have to search in the code what the output means.
Done.
>> The cycles per second metric is inherent to the fact that workload
>> patterns are a data driven cycling sequence of:
>>
>> - Submit 1..N jobs
>> - Wait for Nth job to finish (optional)
>> - Sleep (optional)
>> - Repeat from start
>>
>> In this particular example we have a normal priority and a low priority
>> clients both spamming the scheduler with 8ms jobs with no sync and no
>
> s/clients/client
>
>> sleeping. Hence they build a very deep queues and we can see how the low
>
> s/a//
Done and done.
>> priority client is completely starved until the normal finishes.
>>
>> Note that the PCT and CPS metrics are irrelevant for "unsync" clients
>> since they manage to complete all of their cycles instantaneously.
>>
>> A different example would be:
>>
>> Heavy and interactive:
>> pct1 cps1 qd1; pct2 cps2 qd2
>> + 0ms: 0 0 0; 0 0 0
>> + 106ms: 5 40 3; 5 40 0
>> + 209ms: 9 40 0; 9 40 0
>> + 314ms: 14 50 3; 14 50 0
>> + 417ms: 18 40 0; 18 40 0
>> + 522ms: 23 50 3; 23 50 0
>> + 625ms: 27 40 0; 27 40 1
>> + 729ms: 32 50 0; 32 50 0
>> + 833ms: 36 40 1; 36 40 0
>> + 937ms: 40 40 0; 40 40 0
>> + 1041ms: 45 50 0; 45 50 0
>> + 1146ms: 49 40 1; 49 40 1
>> + 1249ms: 54 50 0; 54 50 0
>> + 1353ms: 58 40 1; 58 40 0
>> + 1457ms: 62 40 0; 62 40 1
>> + 1561ms: 67 50 0; 67 50 0
>> + 1665ms: 71 40 1; 71 40 0
>> + 1772ms: 76 50 0; 76 50 0
>> + 1877ms: 80 40 1; 80 40 0
>> + 1981ms: 84 40 0; 84 40 0
>> + 2085ms: 89 50 0; 89 50 0
>> + 2189ms: 93 40 1; 93 40 0
>> + 2293ms: 97 40 0; 97 40 1
>>
>> In this case client one is submitting 3x 2.5ms jobs, waiting for the 3rd
>> and then sleeping for 2.5ms (in effect causing 75% GPU load, minus the
>> overheads). Second client is submitting 1ms jobs, waiting for each to
>> finish and sleeping for 9ms (effective 10% GPU load). Here we can see
>> the PCT and CPS reflecting real progress.
>>
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
>> Acked-by: Christian König <christian.koenig@amd.com>
>> ---
>> drivers/gpu/drm/scheduler/tests/Makefile | 3 +-
>> .../gpu/drm/scheduler/tests/tests_scheduler.c | 694 ++++++++++++++++++
>> 2 files changed, 696 insertions(+), 1 deletion(-)
>> create mode 100644 drivers/gpu/drm/scheduler/tests/tests_scheduler.c
>>
>> diff --git a/drivers/gpu/drm/scheduler/tests/Makefile b/drivers/gpu/drm/scheduler/tests/Makefile
>> index 5bf707bad373..9ec185fbbc15 100644
>> --- a/drivers/gpu/drm/scheduler/tests/Makefile
>> +++ b/drivers/gpu/drm/scheduler/tests/Makefile
>> @@ -2,6 +2,7 @@
>>
>> drm-sched-tests-y := \
>> mock_scheduler.o \
>> - tests_basic.o
>> + tests_basic.o \
>> + tests_scheduler.o
>>
>> obj-$(CONFIG_DRM_SCHED_KUNIT_TEST) += drm-sched-tests.o
>> diff --git a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
>> new file mode 100644
>> index 000000000000..c66c151a66d2
>> --- /dev/null
>> +++ b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
>> @@ -0,0 +1,694 @@
>> +// SPDX-License-Identifier: GPL-2.0
>> +/* Copyright (c) 2025 Valve Corporation */
>> +
>> +#include <linux/delay.h>
>> +#include <linux/kthread.h>
>> +#include <linux/ktime.h>
>> +#include <linux/math64.h>
>> +
>> +#include "sched_tests.h"
>> +
>> +/*
>> + * DRM scheduler scheduler tests exercise load balancing decisions ie. entity
>> + * selection logic.
>> + */
>> +
>> +static int drm_sched_scheduler_init(struct kunit *test)
>> +{
>> + struct drm_mock_scheduler *sched;
>> +
>> + sched = drm_mock_sched_new(test, MAX_SCHEDULE_TIMEOUT);
>> + sched->base.credit_limit = 1;
>> +
>> + test->priv = sched;
>> +
>> + return 0;
>> +}
>> +
>> +static int drm_sched_scheduler_init2(struct kunit *test)
>> +{
>> + struct drm_mock_scheduler *sched;
>> +
>> + sched = drm_mock_sched_new(test, MAX_SCHEDULE_TIMEOUT);
>> + sched->base.credit_limit = 2;
>> +
>> + test->priv = sched;
>> +
>> + return 0;
>> +}
>> +
>> +static void drm_sched_scheduler_exit(struct kunit *test)
>> +{
>> + struct drm_mock_scheduler *sched = test->priv;
>> +
>> + drm_mock_sched_fini(sched);
>> +}
>> +
>> +static void drm_sched_scheduler_queue_overhead(struct kunit *test)
>> +{
>> + struct drm_mock_scheduler *sched = test->priv;
>> + struct drm_mock_sched_entity *entity;
>> + const unsigned int job_us = 1000;
>> + const unsigned int jobs = 1000;
>> + const unsigned int total_us = jobs * job_us;
>> + struct drm_mock_sched_job *job, *first;
>> + ktime_t start, end;
>> + bool done;
>> + int i;
>> +
>> + /*
>> + * Deep queue job at a time processing (single credit).
>> + *
>> + * This measures the overhead of picking and processing a job at a time
>> + * by comparing the ideal total "GPU" time of all submitted jobs versus
>> + * the time actually taken.
>> + */
>> +
>> + KUNIT_ASSERT_EQ(test, sched->base.credit_limit, 1);
>> +
>> + entity = drm_mock_sched_entity_new(test,
>> + DRM_SCHED_PRIORITY_NORMAL,
>> + sched);
>> +
>> + for (i = 0; i <= jobs; i++) {
>> + job = drm_mock_sched_job_new(test, entity);
>> + if (i == 0)
>> + first = job; /* Extra first job blocks the queue */
>> + else
>> + drm_mock_sched_job_set_duration_us(job, job_us);
>> + drm_mock_sched_job_submit(job);
>> + }
>> +
>> + done = drm_mock_sched_job_wait_scheduled(first, HZ);
>> + KUNIT_ASSERT_TRUE(test, done);
>> +
>> + start = ktime_get();
>> + i = drm_mock_sched_advance(sched, 1); /* Release the queue */
>> + KUNIT_ASSERT_EQ(test, i, 1);
>> +
>> + /* Wait with a safe margin to avoid every failing. */
>> + done = drm_mock_sched_job_wait_finished(job,
>> + usecs_to_jiffies(total_us) * 5);
>> + end = ktime_get();
>> + KUNIT_ASSERT_TRUE(test, done);
>> +
>> + pr_info("Expected %uus, actual %lldus\n",
>> + total_us,
>> + ktime_to_us(ktime_sub(end, start)));
>> +
>> + drm_mock_sched_entity_free(entity);
>> +}
>> +
>> +static void drm_sched_scheduler_ping_pong(struct kunit *test)
>> +{
>> + struct drm_mock_sched_job *job, *first, *prev = NULL;
>> + struct drm_mock_scheduler *sched = test->priv;
>> + struct drm_mock_sched_entity *entity[2];
>> + const unsigned int job_us = 1000;
>> + const unsigned int jobs = 1000;
>> + const unsigned int total_us = jobs * job_us;
>> + ktime_t start, end;
>> + bool done;
>> + int i;
>> +
>> + /*
>> + * Two entitites in inter-dependency chain.
>> + *
>> + * This measures the overhead of picking and processing a job at a time,
>> + * where each job depends on the previous one from the diffferent
>> + * entity, by comparing the ideal total "GPU" time of all submitted jobs
>> + * versus the time actually taken.
>> + */
>> +
>> + KUNIT_ASSERT_EQ(test, sched->base.credit_limit, 1);
>> +
>> + for (i = 0; i < ARRAY_SIZE(entity); i++)
>> + entity[i] = drm_mock_sched_entity_new(test,
>> + DRM_SCHED_PRIORITY_NORMAL,
>> + sched);
>> +
>> + for (i = 0; i <= jobs; i++) {
>> + job = drm_mock_sched_job_new(test, entity[i & 1]);
>> + if (i == 0)
>> + first = job; /* Extra first job blocks the queue */
>> + else
>> + drm_mock_sched_job_set_duration_us(job, job_us);
>> + if (prev)
>> + drm_sched_job_add_dependency(&job->base,
>> + dma_fence_get(&prev->base.s_fence->finished));
>> + drm_mock_sched_job_submit(job);
>> + prev = job;
>> + }
>> +
>> + done = drm_mock_sched_job_wait_scheduled(first, HZ);
>> + KUNIT_ASSERT_TRUE(test, done);
>> +
>> + start = ktime_get();
>> + i = drm_mock_sched_advance(sched, 1); /* Release the queue */
>> + KUNIT_ASSERT_EQ(test, i, 1);
>> +
>> + /* Wait with a safe margin to avoid every failing. */
>> + done = drm_mock_sched_job_wait_finished(job,
>> + usecs_to_jiffies(total_us) * 5);
>> + end = ktime_get();
>> + KUNIT_ASSERT_TRUE(test, done);
>> +
>> + pr_info("Expected %uus, actual %lldus\n",
>> + total_us,
>> + ktime_to_us(ktime_sub(end, start)));
>> +
>> + for (i = 0; i < ARRAY_SIZE(entity); i++)
>> + drm_mock_sched_entity_free(entity[i]);
>> +}
>> +
>> +static struct kunit_case drm_sched_scheduler_overhead_tests[] = {
>> + KUNIT_CASE_SLOW(drm_sched_scheduler_queue_overhead),
>> + KUNIT_CASE_SLOW(drm_sched_scheduler_ping_pong),
>> + {}
>> +};
>> +
>> +static struct kunit_suite drm_sched_scheduler_overhead = {
>> + .name = "drm_sched_scheduler_overhead_tests",
>> + .init = drm_sched_scheduler_init,
>> + .exit = drm_sched_scheduler_exit,
>> + .test_cases = drm_sched_scheduler_overhead_tests,
>> +};
>> +
>> +/*
>> + * struct drm_sched_client_params - describe a workload emitted from a client
>> + *
>> + * A simulated client will create an entity with a scheduling @priority and emit
>> + * jobs in a loop where each iteration will consist of:
>> + *
>> + * 1. Submit @job_cnt jobs, each with a set duration of @job_us.
>> + * 2. If @sync is true wait for last submitted job to finish.
>> + * 3. Sleep for @wait_us micro-seconds.
>> + * 4. Repeat.
>> + */
>> +struct drm_sched_client_params {
>> + enum drm_sched_priority priority;
>> + unsigned int job_cnt;
>> + unsigned int job_us;
>> + bool sync;
>> + unsigned int wait_us;
>> +};
>> +
>> +struct drm_sched_test_params {
>> + const char *description;
>> + struct drm_sched_client_params client[2];
>> +};
>> +
>> +static const struct drm_sched_test_params drm_sched_cases[] = {
>> + {
>> + .description = "Normal and normal",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 8000,
>> + .wait_us = 0,
>> + .sync = false,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 8000,
>> + .wait_us = 0,
>> + .sync = false,
>> + },
>> + },
>> + {
>> + .description = "Normal and low",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 8000,
>> + .wait_us = 0,
>> + .sync = false,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_LOW,
>> + .job_cnt = 1,
>> + .job_us = 8000,
>> + .wait_us = 0,
>> + .sync = false,
>> + },
>> + },
>> + {
>> + .description = "High and normal",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_HIGH,
>> + .job_cnt = 1,
>> + .job_us = 8000,
>> + .wait_us = 0,
>> + .sync = false,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 8000,
>> + .wait_us = 0,
>> + .sync = false,
>> + },
>> + },
>> + {
>> + .description = "High and low",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_HIGH,
>> + .job_cnt = 1,
>> + .job_us = 8000,
>> + .wait_us = 0,
>> + .sync = false,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_LOW,
>> + .job_cnt = 1,
>> + .job_us = 8000,
>> + .wait_us = 0,
>> + .sync = false,
>> + },
>> + },
>> + {
>> + .description = "50 and 50",
>
> I still think that this should have a more obvious description.
Renamed to "50% and 50%". And all other tests which mention
low/normal/high I qualified with "priority" in all cases (ie. "Normal
priority and low priority").
>
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 1500,
>> + .wait_us = 1500,
>> + .sync = true,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 2500,
>> + .wait_us = 2500,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "50 and 50 low",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 1500,
>> + .wait_us = 1500,
>> + .sync = true,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_LOW,
>> + .job_cnt = 1,
>> + .job_us = 2500,
>> + .wait_us = 2500,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "50 high and 50",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_HIGH,
>> + .job_cnt = 1,
>> + .job_us = 1500,
>> + .wait_us = 1500,
>> + .sync = true,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 2500,
>> + .wait_us = 2500,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "Low hog and interactive",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_LOW,
>> + .job_cnt = 3,
>> + .job_us = 2500,
>> + .wait_us = 500,
>> + .sync = false,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 500,
>> + .wait_us = 10000,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "Heavy and interactive",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 3,
>> + .job_us = 2500,
>> + .wait_us = 2500,
>> + .sync = true,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 1000,
>> + .wait_us = 9000,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "Very heavy and interactive",
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 4,
>> + .job_us = 50000,
>> + .wait_us = 1,
>> + .sync = true,
>> + },
>> + .client[1] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 1,
>> + .job_us = 1000,
>> + .wait_us = 9000,
>> + .sync = true,
>> + },
>> + },
>> +};
>> +
>> +static void
>> +drm_sched_desc(const struct drm_sched_test_params *params, char *desc)
>> +{
>> + strscpy(desc, params->description, KUNIT_PARAM_DESC_SIZE);
>> +}
>> +
>> +KUNIT_ARRAY_PARAM(drm_sched_scheduler_two_clients,
>> + drm_sched_cases,
>> + drm_sched_desc);
>> +
>> +/*
>> + * struct test_client_stats - track client stats
>> + *
>> + * For each client executing a simulated workload we track some timings for
>> + * which we are interested in the minimum of all iterations (@min_us), maximum
>> + * (@max_us) and the overall total for all iterations (@tot_us).
>> + */
>> +struct test_client_stats {
>> + unsigned int min_us;
>> + unsigned int max_us;
>> + unsigned long tot_us;
>> +};
>> +
>> +/*
>> + * struct test_client - a simulated userspace client submitting scheduler work
>> + *
>> + * Each client executing a simulated workload is represented by one of these.
>> + *
>> + * Each of them instantiates a scheduling @entity and executes a workloads as
>> + * defined in @params. Based on those @params the theoretical execution time of
>> + * the client is calculated as @ideal_duration, while the actual wall time is
>> + * tracked in @duration (calculated based on the @start and @end client time-
>> + * stamps).
>> + *
>> + * Numerical @id is assigned to each for logging purposes.
>> + *
>> + * @worker and @work are used to provide an independent execution context from
>> + * which scheduler jobs are submitted.
>> + *
>> + * During execution statistics on how long it took to submit and execute one
>> + * iteration (whether or not synchronous) is kept in @cycle_time, while
>> + * @latency_time tracks the @cycle_time minus the ideal duration of the one
>> + * cycle.
>> + *
>> + * Once the client has completed the set number of iterations it will write the
>> + * completion status into @done.
>> + */
>> +struct test_client {
>> + struct kunit *test; /* Backpointer to the kunit test. */
>> +
>> + struct drm_mock_sched_entity *entity;
>> +
>> + struct kthread_worker *worker;
>> + struct kthread_work work;
>
> The formatting here is strange / differs from below.
Done something about this.
Regards,
Tvrtko
>
>
> P.
>
>> +
>> + unsigned int id;
>> + ktime_t duration;
>> +
>> + struct drm_sched_client_params params;
>> +
>> + ktime_t ideal_duration;
>> + unsigned int cycles;
>> + unsigned int cycle;
>> + ktime_t start;
>> + ktime_t end;
>> + bool done;
>> +
>> + struct test_client_stats cycle_time;
>> + struct test_client_stats latency_time;
>> +};
>> +
>> +static void
>> +update_stats(struct test_client_stats *stats, unsigned int us)
>> +{
>> + if (us > stats->max_us)
>> + stats->max_us = us;
>> + if (us < stats->min_us)
>> + stats->min_us = us;
>> + stats->tot_us += us;
>> +}
>> +
>> +static unsigned int
>> +get_stats_avg(struct test_client_stats *stats, unsigned int cycles)
>> +{
>> + return div_u64(stats->tot_us, cycles);
>> +}
>> +
>> +static void drm_sched_client_work(struct kthread_work *work)
>> +{
>> + struct test_client *client = container_of(work, typeof(*client), work);
>> + const long sync_wait = MAX_SCHEDULE_TIMEOUT;
>> + unsigned int cycle, work_us, period_us;
>> + struct drm_mock_sched_job *job = NULL;
>> +
>> + work_us = client->params.job_cnt * client->params.job_us;
>> + period_us = work_us + client->params.wait_us;
>> + client->cycles =
>> + DIV_ROUND_UP((unsigned int)ktime_to_us(client->duration),
>> + period_us);
>> + client->ideal_duration = us_to_ktime(client->cycles * period_us);
>> +
>> + client->start = ktime_get();
>> +
>> + for (cycle = 0; cycle < client->cycles; cycle++) {
>> + ktime_t cycle_time;
>> + unsigned int batch;
>> + unsigned long us;
>> +
>> + if (READ_ONCE(client->done))
>> + break;
>> +
>> + cycle_time = ktime_get();
>> + for (batch = 0; batch < client->params.job_cnt; batch++) {
>> + job = drm_mock_sched_job_new(client->test,
>> + client->entity);
>> + drm_mock_sched_job_set_duration_us(job,
>> + client->params.job_us);
>> + drm_mock_sched_job_submit(job);
>> + }
>> +
>> + if (client->params.sync)
>> + drm_mock_sched_job_wait_finished(job, sync_wait);
>> +
>> + cycle_time = ktime_sub(ktime_get(), cycle_time);
>> + us = ktime_to_us(cycle_time);
>> + update_stats(&client->cycle_time, us);
>> + if (ktime_to_us(cycle_time) >= (long)work_us)
>> + us = ktime_to_us(cycle_time) - work_us;
>> + else if (WARN_ON_ONCE(client->params.sync)) /* GPU job took less than expected. */
>> + us = 0;
>> + update_stats(&client->latency_time, us);
>> + WRITE_ONCE(client->cycle, cycle);
>> +
>> + if (READ_ONCE(client->done))
>> + break;
>> +
>> + if (client->params.wait_us)
>> + fsleep(client->params.wait_us);
>> + else if (!client->params.sync)
>> + cond_resched(); /* Do not hog the CPU if fully async. */
>> + }
>> +
>> + client->done = drm_mock_sched_job_wait_finished(job, sync_wait);
>> + client->end = ktime_get();
>> +}
>> +
>> +static const char *prio_str(enum drm_sched_priority prio)
>> +{
>> + switch (prio) {
>> + case DRM_SCHED_PRIORITY_KERNEL:
>> + return "kernel";
>> + case DRM_SCHED_PRIORITY_LOW:
>> + return "low";
>> + case DRM_SCHED_PRIORITY_NORMAL:
>> + return "normal";
>> + case DRM_SCHED_PRIORITY_HIGH:
>> + return "high";
>> + default:
>> + return "???";
>> + }
>> +}
>> +
>> +static bool client_done(struct test_client *client)
>> +{
>> + return READ_ONCE(client->done); /* READ_ONCE to document lockless read from a loop. */
>> +}
>> +
>> +static void drm_sched_scheduler_two_clients_test(struct kunit *test)
>> +{
>> + const struct drm_sched_test_params *params = test->param_value;
>> + struct drm_mock_scheduler *sched = test->priv;
>> + struct test_client client[2] = { };
>> + unsigned int prev_cycle[2] = { };
>> + unsigned int i, j;
>> + ktime_t start;
>> +
>> + /*
>> + * Same job stream from two clients.
>> + */
>> +
>> + for (i = 0; i < ARRAY_SIZE(client); i++)
>> + client[i].entity =
>> + drm_mock_sched_entity_new(test,
>> + params->client[i].priority,
>> + sched);
>> +
>> + for (i = 0; i < ARRAY_SIZE(client); i++) {
>> + client[i].test = test;
>> + client[i].id = i;
>> + client[i].duration = ms_to_ktime(1000);
>> + client[i].params = params->client[i];
>> + client[i].cycle_time.min_us = ~0U;
>> + client[i].latency_time.min_us = ~0U;
>> + client[i].worker =
>> + kthread_create_worker(0, "%s-%u", __func__, i);
>> + if (IS_ERR(client[i].worker)) {
>> + for (j = 0; j < i; j++)
>> + kthread_destroy_worker(client[j].worker);
>> + KUNIT_FAIL(test, "Failed to create worker!\n");
>> + }
>> +
>> + kthread_init_work(&client[i].work, drm_sched_client_work);
>> + }
>> +
>> + for (i = 0; i < ARRAY_SIZE(client); i++)
>> + kthread_queue_work(client[i].worker, &client[i].work);
>> +
>> + /*
>> + * The clients (workers) can be a mix of async (deep submission queue),
>> + * sync (one job at a time), or something in between. Therefore it is
>> + * difficult to display a single metric representing their progress.
>> + *
>> + * Each struct drm_sched_client_params describes the actual submission
>> + * pattern which happens in the following steps:
>> + * 1. Submit N jobs
>> + * 2. Wait for last submitted job to finish
>> + * 3. Sleep for U micro-seconds
>> + * 4. Goto 1. for C cycles
>> + *
>> + * Where number of cycles is calculated to match the target client
>> + * duration from the respective struct drm_sched_test_params.
>> + *
>> + * To asses scheduling behaviour what we output for both clients is:
>> + * - pct: Percentage progress of the jobs submitted
>> + * - cps: "Cycles" per second (where one cycle is one complete
>> + * iteration from the above)
>> + * - qd: Number of outstanding jobs in the client/entity
>> + */
>> +
>> + start = ktime_get();
>> + pr_info("%s:\n\t pct1 cps1 qd1; pct2 cps2 qd2\n",
>> + params->description);
>> + while (!client_done(&client[0]) || !client_done(&client[1])) {
>> + const unsigned int period_ms = 100;
>> + const unsigned int frequency = 1000 / period_ms;
>> + unsigned int pct[2], qd[2], cycle[2], cps[2];
>> +
>> + for (i = 0; i < ARRAY_SIZE(client); i++) {
>> + qd[i] = spsc_queue_count(&client[i].entity->base.job_queue);
>> + cycle[i] = READ_ONCE(client[i].cycle);
>> + cps[i] = DIV_ROUND_UP(100 * frequency *
>> + (cycle[i] - prev_cycle[i]),
>> + 100);
>> + if (client[i].cycles)
>> + pct[i] = DIV_ROUND_UP(100 * (1 + cycle[i]),
>> + client[i].cycles);
>> + else
>> + pct[i] = 0;
>> + prev_cycle[i] = cycle[i];
>> + }
>> +
>> + if (client_done(&client[0]))
>> + pr_info("\t+%6lldms: ; %3u %5u %4u\n",
>> + ktime_to_ms(ktime_sub(ktime_get(), start)),
>> + pct[1], cps[1], qd[1]);
>> + else if (client_done(&client[1]))
>> + pr_info("\t+%6lldms: %3u %5u %4u;\n",
>> + ktime_to_ms(ktime_sub(ktime_get(), start)),
>> + pct[0], cps[0], qd[0]);
>> + else
>> + pr_info("\t+%6lldms: %3u %5u %4u; %3u %5u %4u\n",
>> + ktime_to_ms(ktime_sub(ktime_get(), start)),
>> + pct[0], cps[0], qd[0],
>> + pct[1], cps[1], qd[1]);
>> +
>> + msleep(period_ms);
>> + }
>> +
>> + for (i = 0; i < ARRAY_SIZE(client); i++) {
>> + kthread_flush_work(&client[i].work);
>> + kthread_destroy_worker(client[i].worker);
>> + }
>> +
>> + for (i = 0; i < ARRAY_SIZE(client); i++)
>> + KUNIT_ASSERT_TRUE(test, client[i].done);
>> +
>> + for (i = 0; i < ARRAY_SIZE(client); i++) {
>> + pr_info(" %u: prio=%s sync=%u elapsed_ms=%lldms (ideal_ms=%lldms) cycle_time(min,avg,max)=%u,%u,%u us latency_time(min,avg,max)=%u,%u,%u us",
>> + i,
>> + prio_str(params->client[i].priority),
>> + params->client[i].sync,
>> + ktime_to_ms(ktime_sub(client[i].end, client[i].start)),
>> + ktime_to_ms(client[i].ideal_duration),
>> + client[i].cycle_time.min_us,
>> + get_stats_avg(&client[i].cycle_time, client[i].cycles),
>> + client[i].cycle_time.max_us,
>> + client[i].latency_time.min_us,
>> + get_stats_avg(&client[i].latency_time, client[i].cycles),
>> + client[i].latency_time.max_us);
>> + drm_mock_sched_entity_free(client[i].entity);
>> + }
>> +}
>> +
>> +static const struct kunit_attributes drm_sched_scheduler_two_clients_attr = {
>> + .speed = KUNIT_SPEED_SLOW,
>> +};
>> +
>> +static struct kunit_case drm_sched_scheduler_two_clients_tests[] = {
>> + KUNIT_CASE_PARAM_ATTR(drm_sched_scheduler_two_clients_test,
>> + drm_sched_scheduler_two_clients_gen_params,
>> + drm_sched_scheduler_two_clients_attr),
>> + {}
>> +};
>> +
>> +static struct kunit_suite drm_sched_scheduler_two_clients1 = {
>> + .name = "drm_sched_scheduler_two_clients_one_credit_tests",
>> + .init = drm_sched_scheduler_init,
>> + .exit = drm_sched_scheduler_exit,
>> + .test_cases = drm_sched_scheduler_two_clients_tests,
>> +};
>> +
>> +static struct kunit_suite drm_sched_scheduler_two_clients2 = {
>> + .name = "drm_sched_scheduler_two_clients_two_credits_tests",
>> + .init = drm_sched_scheduler_init2,
>> + .exit = drm_sched_scheduler_exit,
>> + .test_cases = drm_sched_scheduler_two_clients_tests,
>> +};
>> +
>> +kunit_test_suites(&drm_sched_scheduler_overhead,
>> + &drm_sched_scheduler_two_clients1,
>> + &drm_sched_scheduler_two_clients2);
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 03/28] drm/sched: Add some more scheduling quality unit tests
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 01/28] drm/sched: Reverse drm_sched_rq_init arguments Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 02/28] drm/sched: Add some scheduling quality unit tests Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 9:48 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 04/28] drm/sched: Implement RR via FIFO Tvrtko Ursulin
` (25 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner,
Pierre-Eric Pelloux-Prayer
This time round we explore the rate of submitted job queue processing
with multiple identical parallel clients.
Example test output:
3 clients:
t cycle: min avg max : ...
+ 0ms 0 0 0 : 0 0 0
+ 102ms 2 2 2 : 2 2 2
+ 208ms 5 6 6 : 6 5 5
+ 310ms 8 9 9 : 9 9 8
...
+ 2616ms 82 83 83 : 83 83 82
+ 2717ms 83 83 83 : 83 83 83
avg_max_min_delta(x100)=60
Every 100ms for the duration of the test test logs how many jobs each
client had completed, prefixed by minimum, average and maximum numbers.
When finished overall average delta between max and min is output as a
rough indicator to scheduling fairness.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
Acked-by: Christian König <christian.koenig@amd.com>
---
.../gpu/drm/scheduler/tests/tests_scheduler.c | 186 +++++++++++++++++-
1 file changed, 185 insertions(+), 1 deletion(-)
diff --git a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
index c66c151a66d2..77b02c5e8d52 100644
--- a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
+++ b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
@@ -195,6 +195,7 @@ struct drm_sched_client_params {
struct drm_sched_test_params {
const char *description;
+ unsigned int num_clients;
struct drm_sched_client_params client[2];
};
@@ -689,6 +690,189 @@ static struct kunit_suite drm_sched_scheduler_two_clients2 = {
.test_cases = drm_sched_scheduler_two_clients_tests,
};
+
+static const struct drm_sched_test_params drm_sched_many_cases[] = {
+ {
+ .description = "2 clients",
+ .num_clients = 2,
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 4,
+ .job_us = 1000,
+ .wait_us = 0,
+ .sync = true,
+ },
+ },
+ {
+ .description = "3 clients",
+ .num_clients = 3,
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 4,
+ .job_us = 1000,
+ .wait_us = 0,
+ .sync = true,
+ },
+ },
+ {
+ .description = "7 clients",
+ .num_clients = 7,
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 4,
+ .job_us = 1000,
+ .wait_us = 0,
+ .sync = true,
+ },
+ },
+ {
+ .description = "13 clients",
+ .num_clients = 13,
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 4,
+ .job_us = 1000,
+ .wait_us = 0,
+ .sync = true,
+ },
+ },
+ {
+ .description = "31 clients",
+ .num_clients = 31,
+ .client[0] = {
+ .priority = DRM_SCHED_PRIORITY_NORMAL,
+ .job_cnt = 2,
+ .job_us = 1000,
+ .wait_us = 0,
+ .sync = true,
+ },
+ },
+};
+
+KUNIT_ARRAY_PARAM(drm_sched_scheduler_many_clients,
+ drm_sched_many_cases,
+ drm_sched_desc);
+
+static void drm_sched_scheduler_many_clients_test(struct kunit *test)
+{
+ const struct drm_sched_test_params *params = test->param_value;
+ struct drm_mock_scheduler *sched = test->priv;
+ const unsigned int clients = params->num_clients;
+ unsigned int i, j, delta_total = 0, loops = 0;
+ struct test_client *client;
+ unsigned int *prev_cycle;
+ ktime_t start;
+ char *buf;
+
+ /*
+ * Many clients with deep-ish async queues.
+ */
+
+ buf = kunit_kmalloc(test, PAGE_SIZE, GFP_KERNEL);
+ client = kunit_kcalloc(test, clients, sizeof(*client), GFP_KERNEL);
+ prev_cycle = kunit_kcalloc(test, clients, sizeof(*prev_cycle),
+ GFP_KERNEL);
+
+ for (i = 0; i < clients; i++)
+ client[i].entity =
+ drm_mock_sched_entity_new(test,
+ DRM_SCHED_PRIORITY_NORMAL,
+ sched);
+
+ for (i = 0; i < clients; i++) {
+ client[i].test = test;
+ client[i].id = i;
+ client[i].params = params->client[0];
+ client[i].duration = ms_to_ktime(1000 / clients);
+ client[i].cycle_time.min_us = ~0U;
+ client[i].latency_time.min_us = ~0U;
+ client[i].worker =
+ kthread_create_worker(0, "%s-%u", __func__, i);
+ if (IS_ERR(client[i].worker)) {
+ for (j = 0; j < i; j++)
+ kthread_destroy_worker(client[j].worker);
+ KUNIT_FAIL(test, "Failed to create worker!\n");
+ }
+
+ kthread_init_work(&client[i].work, drm_sched_client_work);
+ }
+
+ for (i = 0; i < clients; i++)
+ kthread_queue_work(client[i].worker, &client[i].work);
+
+ start = ktime_get();
+ pr_info("%u clients:\n\tt\t\tcycle:\t min avg max : ...\n", clients);
+ for (;;) {
+ unsigned int min = ~0;
+ unsigned int max = 0;
+ unsigned int total = 0;
+ bool done = true;
+ char pbuf[16];
+
+ memset(buf, 0, PAGE_SIZE);
+ for (i = 0; i < clients; i++) {
+ unsigned int cycle, cycles;
+
+ cycle = READ_ONCE(client[i].cycle);
+ cycles = READ_ONCE(client[i].cycles);
+
+ snprintf(pbuf, sizeof(pbuf), " %3d", cycle);
+ strncat(buf, pbuf, PAGE_SIZE);
+
+ total += cycle;
+ if (cycle < min)
+ min = cycle;
+ if (cycle > max)
+ max = cycle;
+
+ if (!min || (cycle + 1) < cycles)
+ done = false;
+ }
+
+ loops++;
+ delta_total += max - min;
+
+ pr_info("\t+%6lldms\t\t %3u %3u %3u :%s\n",
+ ktime_to_ms(ktime_sub(ktime_get(), start)),
+ min, DIV_ROUND_UP(total, clients), max, buf);
+
+ if (done)
+ break;
+
+ msleep(100);
+ }
+
+ pr_info(" avg_max_min_delta(x100)=%u\n",
+ loops ? DIV_ROUND_UP(delta_total * 100, loops) : 0);
+
+ for (i = 0; i < clients; i++) {
+ kthread_flush_work(&client[i].work);
+ kthread_destroy_worker(client[i].worker);
+ }
+
+ for (i = 0; i < clients; i++)
+ drm_mock_sched_entity_free(client[i].entity);
+}
+
+static const struct kunit_attributes drm_sched_scheduler_many_clients_attr = {
+ .speed = KUNIT_SPEED_SLOW,
+};
+
+static struct kunit_case drm_sched_scheduler_many_clients_tests[] = {
+ KUNIT_CASE_PARAM_ATTR(drm_sched_scheduler_many_clients_test,
+ drm_sched_scheduler_many_clients_gen_params,
+ drm_sched_scheduler_many_clients_attr),
+ {}
+};
+
+static struct kunit_suite drm_sched_scheduler_many_clients = {
+ .name = "drm_sched_scheduler_many_clients_tests",
+ .init = drm_sched_scheduler_init2,
+ .exit = drm_sched_scheduler_exit,
+ .test_cases = drm_sched_scheduler_many_clients_tests,
+};
+
kunit_test_suites(&drm_sched_scheduler_overhead,
&drm_sched_scheduler_two_clients1,
- &drm_sched_scheduler_two_clients2);
+ &drm_sched_scheduler_two_clients2,
+ &drm_sched_scheduler_many_clients);
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 03/28] drm/sched: Add some more scheduling quality unit tests
2025-10-08 8:53 ` [PATCH 03/28] drm/sched: Add some more " Tvrtko Ursulin
@ 2025-10-10 9:48 ` Philipp Stanner
2025-10-11 13:21 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 9:48 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner, Pierre-Eric Pelloux-Prayer
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> This time round we explore the rate of submitted job queue processing
> with multiple identical parallel clients.
>
> Example test output:
>
> 3 clients:
> t cycle: min avg max : ...
> + 0ms 0 0 0 : 0 0 0
> + 102ms 2 2 2 : 2 2 2
> + 208ms 5 6 6 : 6 5 5
> + 310ms 8 9 9 : 9 9 8
> ...
> + 2616ms 82 83 83 : 83 83 82
> + 2717ms 83 83 83 : 83 83 83
> avg_max_min_delta(x100)=60
>
> Every 100ms for the duration of the test test logs how many jobs each
> client had completed, prefixed by minimum, average and maximum numbers.
> When finished overall average delta between max and min is output as a
> rough indicator to scheduling fairness.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
> Acked-by: Christian König <christian.koenig@amd.com>
> ---
> .../gpu/drm/scheduler/tests/tests_scheduler.c | 186 +++++++++++++++++-
> 1 file changed, 185 insertions(+), 1 deletion(-)
>
> diff --git a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
> index c66c151a66d2..77b02c5e8d52 100644
> --- a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
> +++ b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
> @@ -195,6 +195,7 @@ struct drm_sched_client_params {
>
> struct drm_sched_test_params {
> const char *description;
> + unsigned int num_clients;
> struct drm_sched_client_params client[2];
> };
>
> @@ -689,6 +690,189 @@ static struct kunit_suite drm_sched_scheduler_two_clients2 = {
> .test_cases = drm_sched_scheduler_two_clients_tests,
> };
>
> +
> +static const struct drm_sched_test_params drm_sched_many_cases[] = {
> + {
> + .description = "2 clients",
> + .num_clients = 2,
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 4,
> + .job_us = 1000,
> + .wait_us = 0,
> + .sync = true,
> + },
> + },
> + {
> + .description = "3 clients",
> + .num_clients = 3,
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 4,
> + .job_us = 1000,
> + .wait_us = 0,
> + .sync = true,
> + },
> + },
> + {
> + .description = "7 clients",
> + .num_clients = 7,
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 4,
> + .job_us = 1000,
> + .wait_us = 0,
> + .sync = true,
> + },
> + },
> + {
> + .description = "13 clients",
> + .num_clients = 13,
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 4,
> + .job_us = 1000,
> + .wait_us = 0,
> + .sync = true,
> + },
> + },
> + {
> + .description = "31 clients",
> + .num_clients = 31,
> + .client[0] = {
> + .priority = DRM_SCHED_PRIORITY_NORMAL,
> + .job_cnt = 2,
> + .job_us = 1000,
> + .wait_us = 0,
> + .sync = true,
> + },
> + },
> +};
> +
> +KUNIT_ARRAY_PARAM(drm_sched_scheduler_many_clients,
> + drm_sched_many_cases,
> + drm_sched_desc);
> +
> +static void drm_sched_scheduler_many_clients_test(struct kunit *test)
> +{
> + const struct drm_sched_test_params *params = test->param_value;
> + struct drm_mock_scheduler *sched = test->priv;
> + const unsigned int clients = params->num_clients;
> + unsigned int i, j, delta_total = 0, loops = 0;
> + struct test_client *client;
> + unsigned int *prev_cycle;
> + ktime_t start;
> + char *buf;
> +
> + /*
> + * Many clients with deep-ish async queues.
> + */
> +
> + buf = kunit_kmalloc(test, PAGE_SIZE, GFP_KERNEL);
> + client = kunit_kcalloc(test, clients, sizeof(*client), GFP_KERNEL);
> + prev_cycle = kunit_kcalloc(test, clients, sizeof(*prev_cycle),
> + GFP_KERNEL);
No error handling necessary??
> +
> + for (i = 0; i < clients; i++)
> + client[i].entity =
> + drm_mock_sched_entity_new(test,
> + DRM_SCHED_PRIORITY_NORMAL,
> + sched);
> +
> + for (i = 0; i < clients; i++) {
> + client[i].test = test;
> + client[i].id = i;
> + client[i].params = params->client[0];
> + client[i].duration = ms_to_ktime(1000 / clients);
> + client[i].cycle_time.min_us = ~0U;
> + client[i].latency_time.min_us = ~0U;
> + client[i].worker =
> + kthread_create_worker(0, "%s-%u", __func__, i);
> + if (IS_ERR(client[i].worker)) {
> + for (j = 0; j < i; j++)
> + kthread_destroy_worker(client[j].worker);
> + KUNIT_FAIL(test, "Failed to create worker!\n");
> + }
> +
> + kthread_init_work(&client[i].work, drm_sched_client_work);
> + }
> +
> + for (i = 0; i < clients; i++)
> + kthread_queue_work(client[i].worker, &client[i].work);
> +
> + start = ktime_get();
> + pr_info("%u clients:\n\tt\t\tcycle:\t min avg max : ...\n", clients);
> + for (;;) {
> + unsigned int min = ~0;
Why is min initialized to UINT_MAX?
> + unsigned int max = 0;
> + unsigned int total = 0;
> + bool done = true;
> + char pbuf[16];
> +
> + memset(buf, 0, PAGE_SIZE);
> + for (i = 0; i < clients; i++) {
> + unsigned int cycle, cycles;
> +
> + cycle = READ_ONCE(client[i].cycle);
> + cycles = READ_ONCE(client[i].cycles);
I think I had asked why READ_ONCE is necessary. It's not super obvious.
P.
> +
> + snprintf(pbuf, sizeof(pbuf), " %3d", cycle);
> + strncat(buf, pbuf, PAGE_SIZE);
> +
> + total += cycle;
> + if (cycle < min)
> + min = cycle;
> + if (cycle > max)
> + max = cycle;
> +
> + if (!min || (cycle + 1) < cycles)
> + done = false;
> + }
> +
> + loops++;
> + delta_total += max - min;
> +
> + pr_info("\t+%6lldms\t\t %3u %3u %3u :%s\n",
> + ktime_to_ms(ktime_sub(ktime_get(), start)),
> + min, DIV_ROUND_UP(total, clients), max, buf);
> +
> + if (done)
> + break;
> +
> + msleep(100);
> + }
> +
> + pr_info(" avg_max_min_delta(x100)=%u\n",
> + loops ? DIV_ROUND_UP(delta_total * 100, loops) : 0);
> +
> + for (i = 0; i < clients; i++) {
> + kthread_flush_work(&client[i].work);
> + kthread_destroy_worker(client[i].worker);
> + }
> +
> + for (i = 0; i < clients; i++)
> + drm_mock_sched_entity_free(client[i].entity);
> +}
> +
> +static const struct kunit_attributes drm_sched_scheduler_many_clients_attr = {
> + .speed = KUNIT_SPEED_SLOW,
> +};
> +
> +static struct kunit_case drm_sched_scheduler_many_clients_tests[] = {
> + KUNIT_CASE_PARAM_ATTR(drm_sched_scheduler_many_clients_test,
> + drm_sched_scheduler_many_clients_gen_params,
> + drm_sched_scheduler_many_clients_attr),
> + {}
> +};
> +
> +static struct kunit_suite drm_sched_scheduler_many_clients = {
> + .name = "drm_sched_scheduler_many_clients_tests",
> + .init = drm_sched_scheduler_init2,
> + .exit = drm_sched_scheduler_exit,
> + .test_cases = drm_sched_scheduler_many_clients_tests,
> +};
> +
> kunit_test_suites(&drm_sched_scheduler_overhead,
> &drm_sched_scheduler_two_clients1,
> - &drm_sched_scheduler_two_clients2);
> + &drm_sched_scheduler_two_clients2,
> + &drm_sched_scheduler_many_clients);
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 03/28] drm/sched: Add some more scheduling quality unit tests
2025-10-10 9:48 ` Philipp Stanner
@ 2025-10-11 13:21 ` Tvrtko Ursulin
0 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-11 13:21 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Pierre-Eric Pelloux-Prayer
On 10/10/2025 10:48, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> This time round we explore the rate of submitted job queue processing
>> with multiple identical parallel clients.
>>
>> Example test output:
>>
>> 3 clients:
>> t cycle: min avg max : ...
>> + 0ms 0 0 0 : 0 0 0
>> + 102ms 2 2 2 : 2 2 2
>> + 208ms 5 6 6 : 6 5 5
>> + 310ms 8 9 9 : 9 9 8
>> ...
>> + 2616ms 82 83 83 : 83 83 82
>> + 2717ms 83 83 83 : 83 83 83
>> avg_max_min_delta(x100)=60
>>
>> Every 100ms for the duration of the test test logs how many jobs each
>> client had completed, prefixed by minimum, average and maximum numbers.
>> When finished overall average delta between max and min is output as a
>> rough indicator to scheduling fairness.
>>
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
>> Acked-by: Christian König <christian.koenig@amd.com>
>> ---
>> .../gpu/drm/scheduler/tests/tests_scheduler.c | 186 +++++++++++++++++-
>> 1 file changed, 185 insertions(+), 1 deletion(-)
>>
>> diff --git a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
>> index c66c151a66d2..77b02c5e8d52 100644
>> --- a/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
>> +++ b/drivers/gpu/drm/scheduler/tests/tests_scheduler.c
>> @@ -195,6 +195,7 @@ struct drm_sched_client_params {
>>
>> struct drm_sched_test_params {
>> const char *description;
>> + unsigned int num_clients;
>> struct drm_sched_client_params client[2];
>> };
>>
>> @@ -689,6 +690,189 @@ static struct kunit_suite drm_sched_scheduler_two_clients2 = {
>> .test_cases = drm_sched_scheduler_two_clients_tests,
>> };
>>
>> +
>> +static const struct drm_sched_test_params drm_sched_many_cases[] = {
>> + {
>> + .description = "2 clients",
>> + .num_clients = 2,
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 4,
>> + .job_us = 1000,
>> + .wait_us = 0,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "3 clients",
>> + .num_clients = 3,
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 4,
>> + .job_us = 1000,
>> + .wait_us = 0,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "7 clients",
>> + .num_clients = 7,
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 4,
>> + .job_us = 1000,
>> + .wait_us = 0,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "13 clients",
>> + .num_clients = 13,
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 4,
>> + .job_us = 1000,
>> + .wait_us = 0,
>> + .sync = true,
>> + },
>> + },
>> + {
>> + .description = "31 clients",
>> + .num_clients = 31,
>> + .client[0] = {
>> + .priority = DRM_SCHED_PRIORITY_NORMAL,
>> + .job_cnt = 2,
>> + .job_us = 1000,
>> + .wait_us = 0,
>> + .sync = true,
>> + },
>> + },
>> +};
>> +
>> +KUNIT_ARRAY_PARAM(drm_sched_scheduler_many_clients,
>> + drm_sched_many_cases,
>> + drm_sched_desc);
>> +
>> +static void drm_sched_scheduler_many_clients_test(struct kunit *test)
>> +{
>> + const struct drm_sched_test_params *params = test->param_value;
>> + struct drm_mock_scheduler *sched = test->priv;
>> + const unsigned int clients = params->num_clients;
>> + unsigned int i, j, delta_total = 0, loops = 0;
>> + struct test_client *client;
>> + unsigned int *prev_cycle;
>> + ktime_t start;
>> + char *buf;
>> +
>> + /*
>> + * Many clients with deep-ish async queues.
>> + */
>> +
>> + buf = kunit_kmalloc(test, PAGE_SIZE, GFP_KERNEL);
>> + client = kunit_kcalloc(test, clients, sizeof(*client), GFP_KERNEL);
>> + prev_cycle = kunit_kcalloc(test, clients, sizeof(*prev_cycle),
>> + GFP_KERNEL);
>
> No error handling necessary??
Ha, fixed. I probably got confused thinking kunit does it for us.
>> +
>> + for (i = 0; i < clients; i++)
>> + client[i].entity =
>> + drm_mock_sched_entity_new(test,
>> + DRM_SCHED_PRIORITY_NORMAL,
>> + sched);
>> +
>> + for (i = 0; i < clients; i++) {
>> + client[i].test = test;
>> + client[i].id = i;
>> + client[i].params = params->client[0];
>> + client[i].duration = ms_to_ktime(1000 / clients);
>> + client[i].cycle_time.min_us = ~0U;
>> + client[i].latency_time.min_us = ~0U;
>> + client[i].worker =
>> + kthread_create_worker(0, "%s-%u", __func__, i);
>> + if (IS_ERR(client[i].worker)) {
>> + for (j = 0; j < i; j++)
>> + kthread_destroy_worker(client[j].worker);
>> + KUNIT_FAIL(test, "Failed to create worker!\n");
>> + }
>> +
>> + kthread_init_work(&client[i].work, drm_sched_client_work);
>> + }
>> +
>> + for (i = 0; i < clients; i++)
>> + kthread_queue_work(client[i].worker, &client[i].work);
>> +
>> + start = ktime_get();
>> + pr_info("%u clients:\n\tt\t\tcycle:\t min avg max : ...\n", clients);
>> + for (;;) {
>> + unsigned int min = ~0;
>
> Why is min initialized to UINT_MAX?
So that "if (val < min) min = val" works.
>> + unsigned int max = 0;
>> + unsigned int total = 0;
>> + bool done = true;
>> + char pbuf[16];
>> +
>> + memset(buf, 0, PAGE_SIZE);
>> + for (i = 0; i < clients; i++) {
>> + unsigned int cycle, cycles;
>> +
>> + cycle = READ_ONCE(client[i].cycle);
>> + cycles = READ_ONCE(client[i].cycles);
>
> I think I had asked why READ_ONCE is necessary. It's not super obvious.
Those values are updated in a different thread, and even though I don't
think compiler can omit those with the kernel settings, I like to use
READ_ONCE/WRITE_ONCE pairs for documentation. I added a comment.
Regards,
Tvrtko
>
>
> P.
>
>> +
>> + snprintf(pbuf, sizeof(pbuf), " %3d", cycle);
>> + strncat(buf, pbuf, PAGE_SIZE);
>> +
>> + total += cycle;
>> + if (cycle < min)
>> + min = cycle;
>> + if (cycle > max)
>> + max = cycle;
>> +
>> + if (!min || (cycle + 1) < cycles)
>> + done = false;
>> + }
>> +
>> + loops++;
>> + delta_total += max - min;
>> +
>> + pr_info("\t+%6lldms\t\t %3u %3u %3u :%s\n",
>> + ktime_to_ms(ktime_sub(ktime_get(), start)),
>> + min, DIV_ROUND_UP(total, clients), max, buf);
>> +
>> + if (done)
>> + break;
>> +
>> + msleep(100);
>> + }
>> +
>> + pr_info(" avg_max_min_delta(x100)=%u\n",
>> + loops ? DIV_ROUND_UP(delta_total * 100, loops) : 0);
>> +
>> + for (i = 0; i < clients; i++) {
>> + kthread_flush_work(&client[i].work);
>> + kthread_destroy_worker(client[i].worker);
>> + }
>> +
>> + for (i = 0; i < clients; i++)
>> + drm_mock_sched_entity_free(client[i].entity);
>> +}
>> +
>> +static const struct kunit_attributes drm_sched_scheduler_many_clients_attr = {
>> + .speed = KUNIT_SPEED_SLOW,
>> +};
>> +
>> +static struct kunit_case drm_sched_scheduler_many_clients_tests[] = {
>> + KUNIT_CASE_PARAM_ATTR(drm_sched_scheduler_many_clients_test,
>> + drm_sched_scheduler_many_clients_gen_params,
>> + drm_sched_scheduler_many_clients_attr),
>> + {}
>> +};
>> +
>> +static struct kunit_suite drm_sched_scheduler_many_clients = {
>> + .name = "drm_sched_scheduler_many_clients_tests",
>> + .init = drm_sched_scheduler_init2,
>> + .exit = drm_sched_scheduler_exit,
>> + .test_cases = drm_sched_scheduler_many_clients_tests,
>> +};
>> +
>> kunit_test_suites(&drm_sched_scheduler_overhead,
>> &drm_sched_scheduler_two_clients1,
>> - &drm_sched_scheduler_two_clients2);
>> + &drm_sched_scheduler_two_clients2,
>> + &drm_sched_scheduler_many_clients);
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 04/28] drm/sched: Implement RR via FIFO
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (2 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 03/28] drm/sched: Add some more " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 10:18 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 05/28] drm/sched: Consolidate entity run queue management Tvrtko Ursulin
` (24 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
Round-robin being the non-default policy and unclear how much it is used,
we can notice that it can be implemented using the FIFO data structures if
we only invent a fake submit timestamp which is monotonically increasing
inside drm_sched_rq instances.
So instead of remembering which was the last entity the scheduler worker
picked we can simply bump the picked one to the bottom of the tree, which
ensures round-robin behaviour between all active queued jobs.
If the picked job was the last from a given entity, we remember the
assigned fake timestamp and use it to re-insert the job once it re-joins
the queue. This ensures job neither overtakes all already queued jobs,
neither it goes last. Instead it keeps the position after the currently
queued jobs and before the ones which haven't yet been queued at the point
the entity left the queue.
Advantage is that we can consolidate to a single code path and remove a
bunch of code. Downside is round-robin mode now needs to lock on the job
pop path but that should not be visible.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/scheduler/sched_entity.c | 51 ++++++++++------
drivers/gpu/drm/scheduler/sched_main.c | 76 ++----------------------
include/drm/gpu_scheduler.h | 16 +++--
3 files changed, 51 insertions(+), 92 deletions(-)
diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
index 5a4697f636f2..4852006f2308 100644
--- a/drivers/gpu/drm/scheduler/sched_entity.c
+++ b/drivers/gpu/drm/scheduler/sched_entity.c
@@ -456,9 +456,24 @@ drm_sched_job_dependency(struct drm_sched_job *job,
return NULL;
}
+static ktime_t
+drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
+{
+ ktime_t ts;
+
+ lockdep_assert_held(&entity->lock);
+ lockdep_assert_held(&rq->lock);
+
+ ts = ktime_add_ns(rq->rr_ts, 1);
+ entity->rr_ts = ts;
+ rq->rr_ts = ts;
+
+ return ts;
+}
+
struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
{
- struct drm_sched_job *sched_job;
+ struct drm_sched_job *sched_job, *next_job;
sched_job = drm_sched_entity_queue_peek(entity);
if (!sched_job)
@@ -491,21 +506,21 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
* Update the entity's location in the min heap according to
* the timestamp of the next job, if any.
*/
- if (drm_sched_policy == DRM_SCHED_POLICY_FIFO) {
- struct drm_sched_job *next;
+ next_job = drm_sched_entity_queue_peek(entity);
+ if (next_job) {
+ struct drm_sched_rq *rq;
+ ktime_t ts;
- next = drm_sched_entity_queue_peek(entity);
- if (next) {
- struct drm_sched_rq *rq;
-
- spin_lock(&entity->lock);
- rq = entity->rq;
- spin_lock(&rq->lock);
- drm_sched_rq_update_fifo_locked(entity, rq,
- next->submit_ts);
- spin_unlock(&rq->lock);
- spin_unlock(&entity->lock);
- }
+ spin_lock(&entity->lock);
+ rq = entity->rq;
+ spin_lock(&rq->lock);
+ if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
+ ts = next_job->submit_ts;
+ else
+ ts = drm_sched_rq_get_rr_ts(rq, entity);
+ drm_sched_rq_update_fifo_locked(entity, rq, ts);
+ spin_unlock(&rq->lock);
+ spin_unlock(&entity->lock);
}
/* Jobs and entities might have different lifecycles. Since we're
@@ -612,9 +627,9 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
spin_lock(&rq->lock);
drm_sched_rq_add_entity(rq, entity);
-
- if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
- drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
+ if (drm_sched_policy == DRM_SCHED_POLICY_RR)
+ submit_ts = entity->rr_ts;
+ drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
spin_unlock(&rq->lock);
spin_unlock(&entity->lock);
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 8b8c55b25762..8e62541b439a 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -185,7 +185,6 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
spin_lock_init(&rq->lock);
INIT_LIST_HEAD(&rq->entities);
rq->rb_tree_root = RB_ROOT_CACHED;
- rq->current_entity = NULL;
rq->sched = sched;
}
@@ -231,74 +230,13 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
atomic_dec(rq->sched->score);
list_del_init(&entity->list);
- if (rq->current_entity == entity)
- rq->current_entity = NULL;
-
- if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
- drm_sched_rq_remove_fifo_locked(entity, rq);
+ drm_sched_rq_remove_fifo_locked(entity, rq);
spin_unlock(&rq->lock);
}
/**
- * drm_sched_rq_select_entity_rr - Select an entity which could provide a job to run
- *
- * @sched: the gpu scheduler
- * @rq: scheduler run queue to check.
- *
- * Try to find the next ready entity.
- *
- * Return an entity if one is found; return an error-pointer (!NULL) if an
- * entity was ready, but the scheduler had insufficient credits to accommodate
- * its job; return NULL, if no ready entity was found.
- */
-static struct drm_sched_entity *
-drm_sched_rq_select_entity_rr(struct drm_gpu_scheduler *sched,
- struct drm_sched_rq *rq)
-{
- struct drm_sched_entity *entity;
-
- spin_lock(&rq->lock);
-
- entity = rq->current_entity;
- if (entity) {
- list_for_each_entry_continue(entity, &rq->entities, list) {
- if (drm_sched_entity_is_ready(entity))
- goto found;
- }
- }
-
- list_for_each_entry(entity, &rq->entities, list) {
- if (drm_sched_entity_is_ready(entity))
- goto found;
-
- if (entity == rq->current_entity)
- break;
- }
-
- spin_unlock(&rq->lock);
-
- return NULL;
-
-found:
- if (!drm_sched_can_queue(sched, entity)) {
- /*
- * If scheduler cannot take more jobs signal the caller to not
- * consider lower priority queues.
- */
- entity = ERR_PTR(-ENOSPC);
- } else {
- rq->current_entity = entity;
- reinit_completion(&entity->entity_idle);
- }
-
- spin_unlock(&rq->lock);
-
- return entity;
-}
-
-/**
- * drm_sched_rq_select_entity_fifo - Select an entity which provides a job to run
+ * drm_sched_rq_select_entity - Select an entity which provides a job to run
*
* @sched: the gpu scheduler
* @rq: scheduler run queue to check.
@@ -310,8 +248,8 @@ drm_sched_rq_select_entity_rr(struct drm_gpu_scheduler *sched,
* its job; return NULL, if no ready entity was found.
*/
static struct drm_sched_entity *
-drm_sched_rq_select_entity_fifo(struct drm_gpu_scheduler *sched,
- struct drm_sched_rq *rq)
+drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
+ struct drm_sched_rq *rq)
{
struct rb_node *rb;
@@ -1093,15 +1031,13 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched)
static struct drm_sched_entity *
drm_sched_select_entity(struct drm_gpu_scheduler *sched)
{
- struct drm_sched_entity *entity;
+ struct drm_sched_entity *entity = NULL;
int i;
/* Start with the highest priority.
*/
for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
- entity = drm_sched_policy == DRM_SCHED_POLICY_FIFO ?
- drm_sched_rq_select_entity_fifo(sched, sched->sched_rq[i]) :
- drm_sched_rq_select_entity_rr(sched, sched->sched_rq[i]);
+ entity = drm_sched_rq_select_entity(sched, sched->sched_rq[i]);
if (entity)
break;
}
diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
index fb88301b3c45..8992393ed200 100644
--- a/include/drm/gpu_scheduler.h
+++ b/include/drm/gpu_scheduler.h
@@ -94,7 +94,8 @@ struct drm_sched_entity {
* @lock:
*
* Lock protecting the run-queue (@rq) to which this entity belongs,
- * @priority and the list of schedulers (@sched_list, @num_sched_list).
+ * @priority, the list of schedulers (@sched_list, @num_sched_list) and
+ * the @rr_ts field.
*/
spinlock_t lock;
@@ -142,6 +143,13 @@ struct drm_sched_entity {
*/
enum drm_sched_priority priority;
+ /**
+ * @rr_ts:
+ *
+ * Fake timestamp of the last popped job from the entity.
+ */
+ ktime_t rr_ts;
+
/**
* @job_queue: the list of jobs of this entity.
*/
@@ -239,8 +247,8 @@ struct drm_sched_entity {
* struct drm_sched_rq - queue of entities to be scheduled.
*
* @sched: the scheduler to which this rq belongs to.
- * @lock: protects @entities, @rb_tree_root and @current_entity.
- * @current_entity: the entity which is to be scheduled.
+ * @lock: protects @entities, @rb_tree_root and @rr_ts.
+ * @rr_ts: monotonically incrementing fake timestamp for RR mode
* @entities: list of the entities to be scheduled.
* @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
*
@@ -253,7 +261,7 @@ struct drm_sched_rq {
spinlock_t lock;
/* Following members are protected by the @lock: */
- struct drm_sched_entity *current_entity;
+ ktime_t rr_ts;
struct list_head entities;
struct rb_root_cached rb_tree_root;
};
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 04/28] drm/sched: Implement RR via FIFO
2025-10-08 8:53 ` [PATCH 04/28] drm/sched: Implement RR via FIFO Tvrtko Ursulin
@ 2025-10-10 10:18 ` Philipp Stanner
2025-10-11 13:30 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 10:18 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> Round-robin being the non-default policy and unclear how much it is used,
> we can notice that it can be implemented using the FIFO data structures if
> we only invent a fake submit timestamp which is monotonically increasing
> inside drm_sched_rq instances.
>
> So instead of remembering which was the last entity the scheduler worker
> picked we can simply bump the picked one to the bottom of the tree, which
> ensures round-robin behaviour between all active queued jobs.
>
> If the picked job was the last from a given entity, we remember the
> assigned fake timestamp and use it to re-insert the job once it re-joins
> the queue. This ensures job neither overtakes all already queued jobs,
s/job/the job
> neither it goes last. Instead it keeps the position after the currently
> queued jobs and before the ones which haven't yet been queued at the point
> the entity left the queue.
I think I got how it works. If you want you can phrase it a bit more
direct that the "last_entity" field is only needed for RR.
>
> Advantage is that we can consolidate to a single code path and remove a
> bunch of code. Downside is round-robin mode now needs to lock on the job
> pop path but that should not be visible.
s/visible/have a measurable performance impact
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> ---
> drivers/gpu/drm/scheduler/sched_entity.c | 51 ++++++++++------
> drivers/gpu/drm/scheduler/sched_main.c | 76 ++----------------------
> include/drm/gpu_scheduler.h | 16 +++--
> 3 files changed, 51 insertions(+), 92 deletions(-)
>
> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> index 5a4697f636f2..4852006f2308 100644
> --- a/drivers/gpu/drm/scheduler/sched_entity.c
> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> @@ -456,9 +456,24 @@ drm_sched_job_dependency(struct drm_sched_job *job,
> return NULL;
> }
>
> +static ktime_t
> +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> +{
> + ktime_t ts;
> +
> + lockdep_assert_held(&entity->lock);
> + lockdep_assert_held(&rq->lock);
> +
> + ts = ktime_add_ns(rq->rr_ts, 1);
> + entity->rr_ts = ts;
> + rq->rr_ts = ts;
This also updates / set the time stamp. Any idea for a better function
name?
> +
> + return ts;
> +}
> +
> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> {
> - struct drm_sched_job *sched_job;
> + struct drm_sched_job *sched_job, *next_job;
>
> sched_job = drm_sched_entity_queue_peek(entity);
> if (!sched_job)
> @@ -491,21 +506,21 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> * Update the entity's location in the min heap according to
> * the timestamp of the next job, if any.
> */
> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO) {
> - struct drm_sched_job *next;
> + next_job = drm_sched_entity_queue_peek(entity);
> + if (next_job) {
> + struct drm_sched_rq *rq;
> + ktime_t ts;
>
> - next = drm_sched_entity_queue_peek(entity);
> - if (next) {
> - struct drm_sched_rq *rq;
> -
> - spin_lock(&entity->lock);
> - rq = entity->rq;
> - spin_lock(&rq->lock);
> - drm_sched_rq_update_fifo_locked(entity, rq,
> - next->submit_ts);
> - spin_unlock(&rq->lock);
> - spin_unlock(&entity->lock);
> - }
> + spin_lock(&entity->lock);
> + rq = entity->rq;
> + spin_lock(&rq->lock);
> + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> + ts = next_job->submit_ts;
> + else
> + ts = drm_sched_rq_get_rr_ts(rq, entity);
> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> + spin_unlock(&rq->lock);
> + spin_unlock(&entity->lock);
> }
>
> /* Jobs and entities might have different lifecycles. Since we're
> @@ -612,9 +627,9 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
>
> spin_lock(&rq->lock);
> drm_sched_rq_add_entity(rq, entity);
> -
> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
> + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> + submit_ts = entity->rr_ts;
> + drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
>
> spin_unlock(&rq->lock);
> spin_unlock(&entity->lock);
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index 8b8c55b25762..8e62541b439a 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -185,7 +185,6 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
> spin_lock_init(&rq->lock);
> INIT_LIST_HEAD(&rq->entities);
> rq->rb_tree_root = RB_ROOT_CACHED;
> - rq->current_entity = NULL;
> rq->sched = sched;
> }
>
> @@ -231,74 +230,13 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> atomic_dec(rq->sched->score);
> list_del_init(&entity->list);
>
> - if (rq->current_entity == entity)
> - rq->current_entity = NULL;
> -
> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> - drm_sched_rq_remove_fifo_locked(entity, rq);
> + drm_sched_rq_remove_fifo_locked(entity, rq);
>
> spin_unlock(&rq->lock);
> }
>
> /**
> - * drm_sched_rq_select_entity_rr - Select an entity which could provide a job to run
> - *
> - * @sched: the gpu scheduler
> - * @rq: scheduler run queue to check.
> - *
> - * Try to find the next ready entity.
> - *
> - * Return an entity if one is found; return an error-pointer (!NULL) if an
> - * entity was ready, but the scheduler had insufficient credits to accommodate
> - * its job; return NULL, if no ready entity was found.
> - */
> -static struct drm_sched_entity *
> -drm_sched_rq_select_entity_rr(struct drm_gpu_scheduler *sched,
> - struct drm_sched_rq *rq)
> -{
> - struct drm_sched_entity *entity;
> -
> - spin_lock(&rq->lock);
> -
> - entity = rq->current_entity;
> - if (entity) {
> - list_for_each_entry_continue(entity, &rq->entities, list) {
> - if (drm_sched_entity_is_ready(entity))
> - goto found;
> - }
> - }
> -
> - list_for_each_entry(entity, &rq->entities, list) {
> - if (drm_sched_entity_is_ready(entity))
> - goto found;
> -
> - if (entity == rq->current_entity)
> - break;
> - }
> -
> - spin_unlock(&rq->lock);
> -
> - return NULL;
> -
> -found:
> - if (!drm_sched_can_queue(sched, entity)) {
> - /*
> - * If scheduler cannot take more jobs signal the caller to not
> - * consider lower priority queues.
> - */
> - entity = ERR_PTR(-ENOSPC);
> - } else {
> - rq->current_entity = entity;
> - reinit_completion(&entity->entity_idle);
> - }
> -
> - spin_unlock(&rq->lock);
> -
> - return entity;
> -}
> -
> -/**
> - * drm_sched_rq_select_entity_fifo - Select an entity which provides a job to run
> + * drm_sched_rq_select_entity - Select an entity which provides a job to run
> *
> * @sched: the gpu scheduler
> * @rq: scheduler run queue to check.
> @@ -310,8 +248,8 @@ drm_sched_rq_select_entity_rr(struct drm_gpu_scheduler *sched,
> * its job; return NULL, if no ready entity was found.
> */
> static struct drm_sched_entity *
> -drm_sched_rq_select_entity_fifo(struct drm_gpu_scheduler *sched,
> - struct drm_sched_rq *rq)
> +drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
> + struct drm_sched_rq *rq)
> {
> struct rb_node *rb;
>
> @@ -1093,15 +1031,13 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched)
> static struct drm_sched_entity *
> drm_sched_select_entity(struct drm_gpu_scheduler *sched)
> {
> - struct drm_sched_entity *entity;
> + struct drm_sched_entity *entity = NULL;
> int i;
>
> /* Start with the highest priority.
> */
> for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> - entity = drm_sched_policy == DRM_SCHED_POLICY_FIFO ?
> - drm_sched_rq_select_entity_fifo(sched, sched->sched_rq[i]) :
> - drm_sched_rq_select_entity_rr(sched, sched->sched_rq[i]);
> + entity = drm_sched_rq_select_entity(sched, sched->sched_rq[i]);
> if (entity)
> break;
> }
> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> index fb88301b3c45..8992393ed200 100644
> --- a/include/drm/gpu_scheduler.h
> +++ b/include/drm/gpu_scheduler.h
> @@ -94,7 +94,8 @@ struct drm_sched_entity {
> * @lock:
> *
> * Lock protecting the run-queue (@rq) to which this entity belongs,
> - * @priority and the list of schedulers (@sched_list, @num_sched_list).
> + * @priority, the list of schedulers (@sched_list, @num_sched_list) and
> + * the @rr_ts field.
> */
> spinlock_t lock;
>
> @@ -142,6 +143,13 @@ struct drm_sched_entity {
> */
> enum drm_sched_priority priority;
>
> + /**
> + * @rr_ts:
> + *
> + * Fake timestamp of the last popped job from the entity.
> + */
> + ktime_t rr_ts;
> +
> /**
> * @job_queue: the list of jobs of this entity.
> */
> @@ -239,8 +247,8 @@ struct drm_sched_entity {
> * struct drm_sched_rq - queue of entities to be scheduled.
> *
> * @sched: the scheduler to which this rq belongs to.
> - * @lock: protects @entities, @rb_tree_root and @current_entity.
> - * @current_entity: the entity which is to be scheduled.
> + * @lock: protects @entities, @rb_tree_root and @rr_ts.
> + * @rr_ts: monotonically incrementing fake timestamp for RR mode
nit: add a full stop '.', as most other docu lines have one
> * @entities: list of the entities to be scheduled.
> * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
> *
> @@ -253,7 +261,7 @@ struct drm_sched_rq {
>
> spinlock_t lock;
> /* Following members are protected by the @lock: */
> - struct drm_sched_entity *current_entity;
> + ktime_t rr_ts;
> struct list_head entities;
> struct rb_root_cached rb_tree_root;
> };
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 04/28] drm/sched: Implement RR via FIFO
2025-10-10 10:18 ` Philipp Stanner
@ 2025-10-11 13:30 ` Tvrtko Ursulin
2025-10-14 6:40 ` Philipp Stanner
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-11 13:30 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 10/10/2025 11:18, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> Round-robin being the non-default policy and unclear how much it is used,
>> we can notice that it can be implemented using the FIFO data structures if
>> we only invent a fake submit timestamp which is monotonically increasing
>> inside drm_sched_rq instances.
>>
>> So instead of remembering which was the last entity the scheduler worker
>> picked we can simply bump the picked one to the bottom of the tree, which
>> ensures round-robin behaviour between all active queued jobs.
>>
>> If the picked job was the last from a given entity, we remember the
>> assigned fake timestamp and use it to re-insert the job once it re-joins
>> the queue. This ensures job neither overtakes all already queued jobs,
>
> s/job/the job
Done.
>
>> neither it goes last. Instead it keeps the position after the currently
>> queued jobs and before the ones which haven't yet been queued at the point
>> the entity left the queue.
>
> I think I got how it works. If you want you can phrase it a bit more
> direct that the "last_entity" field is only needed for RR.
I assume you mean rq->current_entity. I chose not to mention that since
it only got replaced with rq->rr_ts. So I think focusing only on the
code removal (the next paragraph) is clearer.
>> Advantage is that we can consolidate to a single code path and remove a
>> bunch of code. Downside is round-robin mode now needs to lock on the job
>> pop path but that should not be visible.
>
> s/visible/have a measurable performance impact
Done.
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> ---
>> drivers/gpu/drm/scheduler/sched_entity.c | 51 ++++++++++------
>> drivers/gpu/drm/scheduler/sched_main.c | 76 ++----------------------
>> include/drm/gpu_scheduler.h | 16 +++--
>> 3 files changed, 51 insertions(+), 92 deletions(-)
>>
>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>> index 5a4697f636f2..4852006f2308 100644
>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>> @@ -456,9 +456,24 @@ drm_sched_job_dependency(struct drm_sched_job *job,
>> return NULL;
>> }
>>
>> +static ktime_t
>> +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
>> +{
>> + ktime_t ts;
>> +
>> + lockdep_assert_held(&entity->lock);
>> + lockdep_assert_held(&rq->lock);
>> +
>> + ts = ktime_add_ns(rq->rr_ts, 1);
>> + entity->rr_ts = ts;
>> + rq->rr_ts = ts;
>
> This also updates / set the time stamp. Any idea for a better function
> name?
I renamed it to drm_sched_rq_next_rr_ts() wit the rationale that there
is more "prior art" for "next" in function names to change some internal
state.
>> +
>> + return ts;
>> +}
>> +
>> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>> {
>> - struct drm_sched_job *sched_job;
>> + struct drm_sched_job *sched_job, *next_job;
>>
>> sched_job = drm_sched_entity_queue_peek(entity);
>> if (!sched_job)
>> @@ -491,21 +506,21 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>> * Update the entity's location in the min heap according to
>> * the timestamp of the next job, if any.
>> */
>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO) {
>> - struct drm_sched_job *next;
>> + next_job = drm_sched_entity_queue_peek(entity);
>> + if (next_job) {
>> + struct drm_sched_rq *rq;
>> + ktime_t ts;
>>
>> - next = drm_sched_entity_queue_peek(entity);
>> - if (next) {
>> - struct drm_sched_rq *rq;
>> -
>> - spin_lock(&entity->lock);
>> - rq = entity->rq;
>> - spin_lock(&rq->lock);
>> - drm_sched_rq_update_fifo_locked(entity, rq,
>> - next->submit_ts);
>> - spin_unlock(&rq->lock);
>> - spin_unlock(&entity->lock);
>> - }
>> + spin_lock(&entity->lock);
>> + rq = entity->rq;
>> + spin_lock(&rq->lock);
>> + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>> + ts = next_job->submit_ts;
>> + else
>> + ts = drm_sched_rq_get_rr_ts(rq, entity);
>> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
>> + spin_unlock(&rq->lock);
>> + spin_unlock(&entity->lock);
>> }
>>
>> /* Jobs and entities might have different lifecycles. Since we're
>> @@ -612,9 +627,9 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
>>
>> spin_lock(&rq->lock);
>> drm_sched_rq_add_entity(rq, entity);
>> -
>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>> - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
>> + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>> + submit_ts = entity->rr_ts;
>> + drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
>>
>> spin_unlock(&rq->lock);
>> spin_unlock(&entity->lock);
>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>> index 8b8c55b25762..8e62541b439a 100644
>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>> @@ -185,7 +185,6 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
>> spin_lock_init(&rq->lock);
>> INIT_LIST_HEAD(&rq->entities);
>> rq->rb_tree_root = RB_ROOT_CACHED;
>> - rq->current_entity = NULL;
>> rq->sched = sched;
>> }
>>
>> @@ -231,74 +230,13 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
>> atomic_dec(rq->sched->score);
>> list_del_init(&entity->list);
>>
>> - if (rq->current_entity == entity)
>> - rq->current_entity = NULL;
>> -
>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>> - drm_sched_rq_remove_fifo_locked(entity, rq);
>> + drm_sched_rq_remove_fifo_locked(entity, rq);
>>
>> spin_unlock(&rq->lock);
>> }
>>
>> /**
>> - * drm_sched_rq_select_entity_rr - Select an entity which could provide a job to run
>> - *
>> - * @sched: the gpu scheduler
>> - * @rq: scheduler run queue to check.
>> - *
>> - * Try to find the next ready entity.
>> - *
>> - * Return an entity if one is found; return an error-pointer (!NULL) if an
>> - * entity was ready, but the scheduler had insufficient credits to accommodate
>> - * its job; return NULL, if no ready entity was found.
>> - */
>> -static struct drm_sched_entity *
>> -drm_sched_rq_select_entity_rr(struct drm_gpu_scheduler *sched,
>> - struct drm_sched_rq *rq)
>> -{
>> - struct drm_sched_entity *entity;
>> -
>> - spin_lock(&rq->lock);
>> -
>> - entity = rq->current_entity;
>> - if (entity) {
>> - list_for_each_entry_continue(entity, &rq->entities, list) {
>> - if (drm_sched_entity_is_ready(entity))
>> - goto found;
>> - }
>> - }
>> -
>> - list_for_each_entry(entity, &rq->entities, list) {
>> - if (drm_sched_entity_is_ready(entity))
>> - goto found;
>> -
>> - if (entity == rq->current_entity)
>> - break;
>> - }
>> -
>> - spin_unlock(&rq->lock);
>> -
>> - return NULL;
>> -
>> -found:
>> - if (!drm_sched_can_queue(sched, entity)) {
>> - /*
>> - * If scheduler cannot take more jobs signal the caller to not
>> - * consider lower priority queues.
>> - */
>> - entity = ERR_PTR(-ENOSPC);
>> - } else {
>> - rq->current_entity = entity;
>> - reinit_completion(&entity->entity_idle);
>> - }
>> -
>> - spin_unlock(&rq->lock);
>> -
>> - return entity;
>> -}
>> -
>> -/**
>> - * drm_sched_rq_select_entity_fifo - Select an entity which provides a job to run
>> + * drm_sched_rq_select_entity - Select an entity which provides a job to run
>> *
>> * @sched: the gpu scheduler
>> * @rq: scheduler run queue to check.
>> @@ -310,8 +248,8 @@ drm_sched_rq_select_entity_rr(struct drm_gpu_scheduler *sched,
>> * its job; return NULL, if no ready entity was found.
>> */
>> static struct drm_sched_entity *
>> -drm_sched_rq_select_entity_fifo(struct drm_gpu_scheduler *sched,
>> - struct drm_sched_rq *rq)
>> +drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
>> + struct drm_sched_rq *rq)
>> {
>> struct rb_node *rb;
>>
>> @@ -1093,15 +1031,13 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched)
>> static struct drm_sched_entity *
>> drm_sched_select_entity(struct drm_gpu_scheduler *sched)
>> {
>> - struct drm_sched_entity *entity;
>> + struct drm_sched_entity *entity = NULL;
>> int i;
>>
>> /* Start with the highest priority.
>> */
>> for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>> - entity = drm_sched_policy == DRM_SCHED_POLICY_FIFO ?
>> - drm_sched_rq_select_entity_fifo(sched, sched->sched_rq[i]) :
>> - drm_sched_rq_select_entity_rr(sched, sched->sched_rq[i]);
>> + entity = drm_sched_rq_select_entity(sched, sched->sched_rq[i]);
>> if (entity)
>> break;
>> }
>> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
>> index fb88301b3c45..8992393ed200 100644
>> --- a/include/drm/gpu_scheduler.h
>> +++ b/include/drm/gpu_scheduler.h
>> @@ -94,7 +94,8 @@ struct drm_sched_entity {
>> * @lock:
>> *
>> * Lock protecting the run-queue (@rq) to which this entity belongs,
>> - * @priority and the list of schedulers (@sched_list, @num_sched_list).
>> + * @priority, the list of schedulers (@sched_list, @num_sched_list) and
>> + * the @rr_ts field.
>> */
>> spinlock_t lock;
>>
>> @@ -142,6 +143,13 @@ struct drm_sched_entity {
>> */
>> enum drm_sched_priority priority;
>>
>> + /**
>> + * @rr_ts:
>> + *
>> + * Fake timestamp of the last popped job from the entity.
>> + */
>> + ktime_t rr_ts;
>> +
>> /**
>> * @job_queue: the list of jobs of this entity.
>> */
>> @@ -239,8 +247,8 @@ struct drm_sched_entity {
>> * struct drm_sched_rq - queue of entities to be scheduled.
>> *
>> * @sched: the scheduler to which this rq belongs to.
>> - * @lock: protects @entities, @rb_tree_root and @current_entity.
>> - * @current_entity: the entity which is to be scheduled.
>> + * @lock: protects @entities, @rb_tree_root and @rr_ts.
>> + * @rr_ts: monotonically incrementing fake timestamp for RR mode
>
> nit: add a full stop '.', as most other docu lines have one
Done.
Regards,
Tvrtko
>> * @entities: list of the entities to be scheduled.
>> * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
>> *
>> @@ -253,7 +261,7 @@ struct drm_sched_rq {
>>
>> spinlock_t lock;
>> /* Following members are protected by the @lock: */
>> - struct drm_sched_entity *current_entity;
>> + ktime_t rr_ts;
>> struct list_head entities;
>> struct rb_root_cached rb_tree_root;
>> };
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 04/28] drm/sched: Implement RR via FIFO
2025-10-11 13:30 ` Tvrtko Ursulin
@ 2025-10-14 6:40 ` Philipp Stanner
0 siblings, 0 replies; 76+ messages in thread
From: Philipp Stanner @ 2025-10-14 6:40 UTC (permalink / raw)
To: Tvrtko Ursulin, phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On Sat, 2025-10-11 at 14:30 +0100, Tvrtko Ursulin wrote:
>
> On 10/10/2025 11:18, Philipp Stanner wrote:
> > On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> > > Round-robin being the non-default policy and unclear how much it is used,
> > > we can notice that it can be implemented using the FIFO data structures if
> > > we only invent a fake submit timestamp which is monotonically increasing
> > > inside drm_sched_rq instances.
> > >
> > > So instead of remembering which was the last entity the scheduler worker
> > > picked we can simply bump the picked one to the bottom of the tree, which
> > > ensures round-robin behaviour between all active queued jobs.
> > >
> > > If the picked job was the last from a given entity, we remember the
> > > assigned fake timestamp and use it to re-insert the job once it re-joins
> > > the queue. This ensures job neither overtakes all already queued jobs,
> >
> > s/job/the job
>
> Done.
>
> >
> > > neither it goes last. Instead it keeps the position after the currently
> > > queued jobs and before the ones which haven't yet been queued at the point
> > > the entity left the queue.
> >
> > I think I got how it works. If you want you can phrase it a bit more
> > direct that the "last_entity" field is only needed for RR.
>
> I assume you mean rq->current_entity. I chose not to mention that since
> it only got replaced with rq->rr_ts. So I think focusing only on the
> code removal (the next paragraph) is clearer.
OK, fine by me.
Thx
P.
> > > Advantage is that we can consolidate to a single code path and remove a
> > > bunch of code. Downside is round-robin mode now needs to lock on the job
> > > pop path but that should not be visible.
> >
> > s/visible/have a measurable performance impact
> Done.
> > > Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> > > Cc: Christian König <christian.koenig@amd.com>
> > > Cc: Danilo Krummrich <dakr@kernel.org>
> > > Cc: Matthew Brost <matthew.brost@intel.com>
> > > Cc: Philipp Stanner <phasta@kernel.org>
> > > ---
> > > drivers/gpu/drm/scheduler/sched_entity.c | 51 ++++++++++------
> > > drivers/gpu/drm/scheduler/sched_main.c | 76 ++----------------------
> > > include/drm/gpu_scheduler.h | 16 +++--
> > > 3 files changed, 51 insertions(+), 92 deletions(-)
> > >
> > > diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> > > index 5a4697f636f2..4852006f2308 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_entity.c
> > > +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> > > @@ -456,9 +456,24 @@ drm_sched_job_dependency(struct drm_sched_job *job,
> > > return NULL;
> > > }
> > >
> > > +static ktime_t
> > > +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> > > +{
> > > + ktime_t ts;
> > > +
> > > + lockdep_assert_held(&entity->lock);
> > > + lockdep_assert_held(&rq->lock);
> > > +
> > > + ts = ktime_add_ns(rq->rr_ts, 1);
> > > + entity->rr_ts = ts;
> > > + rq->rr_ts = ts;
> >
> > This also updates / set the time stamp. Any idea for a better function
> > name?
>
> I renamed it to drm_sched_rq_next_rr_ts() wit the rationale that there
> is more "prior art" for "next" in function names to change some internal
> state.
>
> > > +
> > > + return ts;
> > > +}
> > > +
> > > struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> > > {
> > > - struct drm_sched_job *sched_job;
> > > + struct drm_sched_job *sched_job, *next_job;
> > >
> > > sched_job = drm_sched_entity_queue_peek(entity);
> > > if (!sched_job)
> > > @@ -491,21 +506,21 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> > > * Update the entity's location in the min heap according to
> > > * the timestamp of the next job, if any.
> > > */
> > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO) {
> > > - struct drm_sched_job *next;
> > > + next_job = drm_sched_entity_queue_peek(entity);
> > > + if (next_job) {
> > > + struct drm_sched_rq *rq;
> > > + ktime_t ts;
> > >
> > > - next = drm_sched_entity_queue_peek(entity);
> > > - if (next) {
> > > - struct drm_sched_rq *rq;
> > > -
> > > - spin_lock(&entity->lock);
> > > - rq = entity->rq;
> > > - spin_lock(&rq->lock);
> > > - drm_sched_rq_update_fifo_locked(entity, rq,
> > > - next->submit_ts);
> > > - spin_unlock(&rq->lock);
> > > - spin_unlock(&entity->lock);
> > > - }
> > > + spin_lock(&entity->lock);
> > > + rq = entity->rq;
> > > + spin_lock(&rq->lock);
> > > + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > + ts = next_job->submit_ts;
> > > + else
> > > + ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > + spin_unlock(&rq->lock);
> > > + spin_unlock(&entity->lock);
> > > }
> > >
> > > /* Jobs and entities might have different lifecycles. Since we're
> > > @@ -612,9 +627,9 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
> > >
> > > spin_lock(&rq->lock);
> > > drm_sched_rq_add_entity(rq, entity);
> > > -
> > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
> > > + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > + submit_ts = entity->rr_ts;
> > > + drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
> > >
> > > spin_unlock(&rq->lock);
> > > spin_unlock(&entity->lock);
> > > diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> > > index 8b8c55b25762..8e62541b439a 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_main.c
> > > +++ b/drivers/gpu/drm/scheduler/sched_main.c
> > > @@ -185,7 +185,6 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
> > > spin_lock_init(&rq->lock);
> > > INIT_LIST_HEAD(&rq->entities);
> > > rq->rb_tree_root = RB_ROOT_CACHED;
> > > - rq->current_entity = NULL;
> > > rq->sched = sched;
> > > }
> > >
> > > @@ -231,74 +230,13 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> > > atomic_dec(rq->sched->score);
> > > list_del_init(&entity->list);
> > >
> > > - if (rq->current_entity == entity)
> > > - rq->current_entity = NULL;
> > > -
> > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > - drm_sched_rq_remove_fifo_locked(entity, rq);
> > > + drm_sched_rq_remove_fifo_locked(entity, rq);
> > >
> > > spin_unlock(&rq->lock);
> > > }
> > >
> > > /**
> > > - * drm_sched_rq_select_entity_rr - Select an entity which could provide a job to run
> > > - *
> > > - * @sched: the gpu scheduler
> > > - * @rq: scheduler run queue to check.
> > > - *
> > > - * Try to find the next ready entity.
> > > - *
> > > - * Return an entity if one is found; return an error-pointer (!NULL) if an
> > > - * entity was ready, but the scheduler had insufficient credits to accommodate
> > > - * its job; return NULL, if no ready entity was found.
> > > - */
> > > -static struct drm_sched_entity *
> > > -drm_sched_rq_select_entity_rr(struct drm_gpu_scheduler *sched,
> > > - struct drm_sched_rq *rq)
> > > -{
> > > - struct drm_sched_entity *entity;
> > > -
> > > - spin_lock(&rq->lock);
> > > -
> > > - entity = rq->current_entity;
> > > - if (entity) {
> > > - list_for_each_entry_continue(entity, &rq->entities, list) {
> > > - if (drm_sched_entity_is_ready(entity))
> > > - goto found;
> > > - }
> > > - }
> > > -
> > > - list_for_each_entry(entity, &rq->entities, list) {
> > > - if (drm_sched_entity_is_ready(entity))
> > > - goto found;
> > > -
> > > - if (entity == rq->current_entity)
> > > - break;
> > > - }
> > > -
> > > - spin_unlock(&rq->lock);
> > > -
> > > - return NULL;
> > > -
> > > -found:
> > > - if (!drm_sched_can_queue(sched, entity)) {
> > > - /*
> > > - * If scheduler cannot take more jobs signal the caller to not
> > > - * consider lower priority queues.
> > > - */
> > > - entity = ERR_PTR(-ENOSPC);
> > > - } else {
> > > - rq->current_entity = entity;
> > > - reinit_completion(&entity->entity_idle);
> > > - }
> > > -
> > > - spin_unlock(&rq->lock);
> > > -
> > > - return entity;
> > > -}
> > > -
> > > -/**
> > > - * drm_sched_rq_select_entity_fifo - Select an entity which provides a job to run
> > > + * drm_sched_rq_select_entity - Select an entity which provides a job to run
> > > *
> > > * @sched: the gpu scheduler
> > > * @rq: scheduler run queue to check.
> > > @@ -310,8 +248,8 @@ drm_sched_rq_select_entity_rr(struct drm_gpu_scheduler *sched,
> > > * its job; return NULL, if no ready entity was found.
> > > */
> > > static struct drm_sched_entity *
> > > -drm_sched_rq_select_entity_fifo(struct drm_gpu_scheduler *sched,
> > > - struct drm_sched_rq *rq)
> > > +drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
> > > + struct drm_sched_rq *rq)
> > > {
> > > struct rb_node *rb;
> > >
> > > @@ -1093,15 +1031,13 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched)
> > > static struct drm_sched_entity *
> > > drm_sched_select_entity(struct drm_gpu_scheduler *sched)
> > > {
> > > - struct drm_sched_entity *entity;
> > > + struct drm_sched_entity *entity = NULL;
> > > int i;
> > >
> > > /* Start with the highest priority.
> > > */
> > > for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> > > - entity = drm_sched_policy == DRM_SCHED_POLICY_FIFO ?
> > > - drm_sched_rq_select_entity_fifo(sched, sched->sched_rq[i]) :
> > > - drm_sched_rq_select_entity_rr(sched, sched->sched_rq[i]);
> > > + entity = drm_sched_rq_select_entity(sched, sched->sched_rq[i]);
> > > if (entity)
> > > break;
> > > }
> > > diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> > > index fb88301b3c45..8992393ed200 100644
> > > --- a/include/drm/gpu_scheduler.h
> > > +++ b/include/drm/gpu_scheduler.h
> > > @@ -94,7 +94,8 @@ struct drm_sched_entity {
> > > * @lock:
> > > *
> > > * Lock protecting the run-queue (@rq) to which this entity belongs,
> > > - * @priority and the list of schedulers (@sched_list, @num_sched_list).
> > > + * @priority, the list of schedulers (@sched_list, @num_sched_list) and
> > > + * the @rr_ts field.
> > > */
> > > spinlock_t lock;
> > >
> > > @@ -142,6 +143,13 @@ struct drm_sched_entity {
> > > */
> > > enum drm_sched_priority priority;
> > >
> > > + /**
> > > + * @rr_ts:
> > > + *
> > > + * Fake timestamp of the last popped job from the entity.
> > > + */
> > > + ktime_t rr_ts;
> > > +
> > > /**
> > > * @job_queue: the list of jobs of this entity.
> > > */
> > > @@ -239,8 +247,8 @@ struct drm_sched_entity {
> > > * struct drm_sched_rq - queue of entities to be scheduled.
> > > *
> > > * @sched: the scheduler to which this rq belongs to.
> > > - * @lock: protects @entities, @rb_tree_root and @current_entity.
> > > - * @current_entity: the entity which is to be scheduled.
> > > + * @lock: protects @entities, @rb_tree_root and @rr_ts.
> > > + * @rr_ts: monotonically incrementing fake timestamp for RR mode
> >
> > nit: add a full stop '.', as most other docu lines have one
>
> Done.
>
> Regards,
>
> Tvrtko
> > > * @entities: list of the entities to be scheduled.
> > > * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
> > > *
> > > @@ -253,7 +261,7 @@ struct drm_sched_rq {
> > >
> > > spinlock_t lock;
> > > /* Following members are protected by the @lock: */
> > > - struct drm_sched_entity *current_entity;
> > > + ktime_t rr_ts;
> > > struct list_head entities;
> > > struct rb_root_cached rb_tree_root;
> > > };
> >
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 05/28] drm/sched: Consolidate entity run queue management
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (3 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 04/28] drm/sched: Implement RR via FIFO Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 10:49 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 06/28] drm/sched: Move run queue related code into a separate file Tvrtko Ursulin
` (23 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
Move the code dealing with entities entering and exiting run queues to
helpers to logically separate it from jobs entering and exiting entities.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/scheduler/sched_entity.c | 64 ++-------------
drivers/gpu/drm/scheduler/sched_internal.h | 8 +-
drivers/gpu/drm/scheduler/sched_main.c | 95 +++++++++++++++++++---
3 files changed, 91 insertions(+), 76 deletions(-)
diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
index 4852006f2308..7a0a52ba87bf 100644
--- a/drivers/gpu/drm/scheduler/sched_entity.c
+++ b/drivers/gpu/drm/scheduler/sched_entity.c
@@ -456,24 +456,9 @@ drm_sched_job_dependency(struct drm_sched_job *job,
return NULL;
}
-static ktime_t
-drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
-{
- ktime_t ts;
-
- lockdep_assert_held(&entity->lock);
- lockdep_assert_held(&rq->lock);
-
- ts = ktime_add_ns(rq->rr_ts, 1);
- entity->rr_ts = ts;
- rq->rr_ts = ts;
-
- return ts;
-}
-
struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
{
- struct drm_sched_job *sched_job, *next_job;
+ struct drm_sched_job *sched_job;
sched_job = drm_sched_entity_queue_peek(entity);
if (!sched_job)
@@ -502,26 +487,7 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
spsc_queue_pop(&entity->job_queue);
- /*
- * Update the entity's location in the min heap according to
- * the timestamp of the next job, if any.
- */
- next_job = drm_sched_entity_queue_peek(entity);
- if (next_job) {
- struct drm_sched_rq *rq;
- ktime_t ts;
-
- spin_lock(&entity->lock);
- rq = entity->rq;
- spin_lock(&rq->lock);
- if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
- ts = next_job->submit_ts;
- else
- ts = drm_sched_rq_get_rr_ts(rq, entity);
- drm_sched_rq_update_fifo_locked(entity, rq, ts);
- spin_unlock(&rq->lock);
- spin_unlock(&entity->lock);
- }
+ drm_sched_rq_pop_entity(entity);
/* Jobs and entities might have different lifecycles. Since we're
* removing the job from the entities queue, set the jobs entity pointer
@@ -611,30 +577,10 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
/* first job wakes up scheduler */
if (first) {
struct drm_gpu_scheduler *sched;
- struct drm_sched_rq *rq;
- /* Add the entity to the run queue */
- spin_lock(&entity->lock);
- if (entity->stopped) {
- spin_unlock(&entity->lock);
-
- DRM_ERROR("Trying to push to a killed entity\n");
- return;
- }
-
- rq = entity->rq;
- sched = rq->sched;
-
- spin_lock(&rq->lock);
- drm_sched_rq_add_entity(rq, entity);
- if (drm_sched_policy == DRM_SCHED_POLICY_RR)
- submit_ts = entity->rr_ts;
- drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
-
- spin_unlock(&rq->lock);
- spin_unlock(&entity->lock);
-
- drm_sched_wakeup(sched);
+ sched = drm_sched_rq_add_entity(entity, submit_ts);
+ if (sched)
+ drm_sched_wakeup(sched);
}
}
EXPORT_SYMBOL(drm_sched_entity_push_job);
diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
index 7ea5a6736f98..8269c5392a82 100644
--- a/drivers/gpu/drm/scheduler/sched_internal.h
+++ b/drivers/gpu/drm/scheduler/sched_internal.h
@@ -12,13 +12,11 @@ extern int drm_sched_policy;
void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
-void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
- struct drm_sched_entity *entity);
+struct drm_gpu_scheduler *
+drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
struct drm_sched_entity *entity);
-
-void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
- struct drm_sched_rq *rq, ktime_t ts);
+void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 8e62541b439a..e5d02c28665c 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -151,9 +151,9 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
}
}
-void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
- struct drm_sched_rq *rq,
- ktime_t ts)
+static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
+ struct drm_sched_rq *rq,
+ ktime_t ts)
{
/*
* Both locks need to be grabbed, one to protect from entity->rq change
@@ -191,22 +191,45 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
/**
* drm_sched_rq_add_entity - add an entity
*
- * @rq: scheduler run queue
* @entity: scheduler entity
+ * @ts: submission timestamp
*
* Adds a scheduler entity to the run queue.
+ *
+ * Returns a DRM scheduler pre-selected to handle this entity.
*/
-void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
- struct drm_sched_entity *entity)
+struct drm_gpu_scheduler *
+drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
{
- lockdep_assert_held(&entity->lock);
- lockdep_assert_held(&rq->lock);
+ struct drm_gpu_scheduler *sched;
+ struct drm_sched_rq *rq;
- if (!list_empty(&entity->list))
- return;
+ /* Add the entity to the run queue */
+ spin_lock(&entity->lock);
+ if (entity->stopped) {
+ spin_unlock(&entity->lock);
- atomic_inc(rq->sched->score);
- list_add_tail(&entity->list, &rq->entities);
+ DRM_ERROR("Trying to push to a killed entity\n");
+ return NULL;
+ }
+
+ rq = entity->rq;
+ spin_lock(&rq->lock);
+ sched = rq->sched;
+
+ if (list_empty(&entity->list)) {
+ atomic_inc(sched->score);
+ list_add_tail(&entity->list, &rq->entities);
+ }
+
+ if (drm_sched_policy == DRM_SCHED_POLICY_RR)
+ ts = entity->rr_ts;
+ drm_sched_rq_update_fifo_locked(entity, rq, ts);
+
+ spin_unlock(&rq->lock);
+ spin_unlock(&entity->lock);
+
+ return sched;
}
/**
@@ -235,6 +258,54 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
spin_unlock(&rq->lock);
}
+static ktime_t
+drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
+{
+ ktime_t ts;
+
+ lockdep_assert_held(&entity->lock);
+ lockdep_assert_held(&rq->lock);
+
+ ts = ktime_add_ns(rq->rr_ts, 1);
+ entity->rr_ts = ts;
+ rq->rr_ts = ts;
+
+ return ts;
+}
+
+/**
+ * drm_sched_rq_pop_entity - pops an entity
+ *
+ * @entity: scheduler entity
+ *
+ * To be called every time after a job is popped from the entity.
+ */
+void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
+{
+ struct drm_sched_job *next_job;
+ struct drm_sched_rq *rq;
+ ktime_t ts;
+
+ /*
+ * Update the entity's location in the min heap according to
+ * the timestamp of the next job, if any.
+ */
+ next_job = drm_sched_entity_queue_peek(entity);
+ if (!next_job)
+ return;
+
+ spin_lock(&entity->lock);
+ rq = entity->rq;
+ spin_lock(&rq->lock);
+ if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
+ ts = next_job->submit_ts;
+ else
+ ts = drm_sched_rq_get_rr_ts(rq, entity);
+ drm_sched_rq_update_fifo_locked(entity, rq, ts);
+ spin_unlock(&rq->lock);
+ spin_unlock(&entity->lock);
+}
+
/**
* drm_sched_rq_select_entity - Select an entity which provides a job to run
*
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 05/28] drm/sched: Consolidate entity run queue management
2025-10-08 8:53 ` [PATCH 05/28] drm/sched: Consolidate entity run queue management Tvrtko Ursulin
@ 2025-10-10 10:49 ` Philipp Stanner
2025-10-11 14:19 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 10:49 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> Move the code dealing with entities entering and exiting run queues to
> helpers to logically separate it from jobs entering and exiting entities.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> ---
> drivers/gpu/drm/scheduler/sched_entity.c | 64 ++-------------
> drivers/gpu/drm/scheduler/sched_internal.h | 8 +-
> drivers/gpu/drm/scheduler/sched_main.c | 95 +++++++++++++++++++---
> 3 files changed, 91 insertions(+), 76 deletions(-)
>
> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> index 4852006f2308..7a0a52ba87bf 100644
> --- a/drivers/gpu/drm/scheduler/sched_entity.c
> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> @@ -456,24 +456,9 @@ drm_sched_job_dependency(struct drm_sched_job *job,
> return NULL;
> }
>
> -static ktime_t
> -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> -{
> - ktime_t ts;
> -
> - lockdep_assert_held(&entity->lock);
> - lockdep_assert_held(&rq->lock);
> -
> - ts = ktime_add_ns(rq->rr_ts, 1);
> - entity->rr_ts = ts;
> - rq->rr_ts = ts;
> -
> - return ts;
> -}
> -
> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> {
> - struct drm_sched_job *sched_job, *next_job;
> + struct drm_sched_job *sched_job;
`next_job` has been added in a previous job. Have you tried whether
patch-order can be reversed?
Just asking; I don't want to cause unnecessary work here
>
> sched_job = drm_sched_entity_queue_peek(entity);
> if (!sched_job)
> @@ -502,26 +487,7 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>
> spsc_queue_pop(&entity->job_queue);
>
> - /*
> - * Update the entity's location in the min heap according to
> - * the timestamp of the next job, if any.
> - */
> - next_job = drm_sched_entity_queue_peek(entity);
> - if (next_job) {
> - struct drm_sched_rq *rq;
> - ktime_t ts;
> -
> - spin_lock(&entity->lock);
> - rq = entity->rq;
> - spin_lock(&rq->lock);
> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> - ts = next_job->submit_ts;
> - else
> - ts = drm_sched_rq_get_rr_ts(rq, entity);
> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
> - spin_unlock(&rq->lock);
> - spin_unlock(&entity->lock);
> - }
> + drm_sched_rq_pop_entity(entity);
>
> /* Jobs and entities might have different lifecycles. Since we're
> * removing the job from the entities queue, set the jobs entity pointer
> @@ -611,30 +577,10 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
> /* first job wakes up scheduler */
> if (first) {
> struct drm_gpu_scheduler *sched;
> - struct drm_sched_rq *rq;
>
> - /* Add the entity to the run queue */
> - spin_lock(&entity->lock);
> - if (entity->stopped) {
> - spin_unlock(&entity->lock);
> -
> - DRM_ERROR("Trying to push to a killed entity\n");
> - return;
> - }
> -
> - rq = entity->rq;
> - sched = rq->sched;
> -
> - spin_lock(&rq->lock);
> - drm_sched_rq_add_entity(rq, entity);
> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> - submit_ts = entity->rr_ts;
> - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
> -
> - spin_unlock(&rq->lock);
> - spin_unlock(&entity->lock);
> -
> - drm_sched_wakeup(sched);
> + sched = drm_sched_rq_add_entity(entity, submit_ts);
> + if (sched)
> + drm_sched_wakeup(sched);
> }
> }
> EXPORT_SYMBOL(drm_sched_entity_push_job);
> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> index 7ea5a6736f98..8269c5392a82 100644
> --- a/drivers/gpu/drm/scheduler/sched_internal.h
> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> @@ -12,13 +12,11 @@ extern int drm_sched_policy;
>
> void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
>
> -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
> - struct drm_sched_entity *entity);
> +struct drm_gpu_scheduler *
> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
> void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> struct drm_sched_entity *entity);
> -
> -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> - struct drm_sched_rq *rq, ktime_t ts);
> +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
>
> void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index 8e62541b439a..e5d02c28665c 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -151,9 +151,9 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> }
> }
>
> -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> - struct drm_sched_rq *rq,
> - ktime_t ts)
> +static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> + struct drm_sched_rq *rq,
> + ktime_t ts)
> {
> /*
> * Both locks need to be grabbed, one to protect from entity->rq change
> @@ -191,22 +191,45 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
> /**
> * drm_sched_rq_add_entity - add an entity
> *
> - * @rq: scheduler run queue
> * @entity: scheduler entity
> + * @ts: submission timestamp
> *
> * Adds a scheduler entity to the run queue.
> + *
> + * Returns a DRM scheduler pre-selected to handle this entity.
> */
> -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
> - struct drm_sched_entity *entity)
> +struct drm_gpu_scheduler *
> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> {
I'm not sure if it's a good idea to have the scheduler returned from
that function. That doesn't make a whole lot of sense semantically.
At the very least the function's docstring, maybe even its name, should
be adjusted to detail why this makes sense. The commit message, too.
It's not trivially understood.
I think I get why it's being done, but writing it down black on white
gives us something to grasp.
Sth like "adds an entity to a runqueue, selects to appropriate
scheduler and returns it for the purpose of XYZ"
> - lockdep_assert_held(&entity->lock);
> - lockdep_assert_held(&rq->lock);
> + struct drm_gpu_scheduler *sched;
> + struct drm_sched_rq *rq;
>
> - if (!list_empty(&entity->list))
> - return;
> + /* Add the entity to the run queue */
> + spin_lock(&entity->lock);
> + if (entity->stopped) {
> + spin_unlock(&entity->lock);
>
> - atomic_inc(rq->sched->score);
> - list_add_tail(&entity->list, &rq->entities);
> + DRM_ERROR("Trying to push to a killed entity\n");
> + return NULL;
> + }
> +
> + rq = entity->rq;
> + spin_lock(&rq->lock);
> + sched = rq->sched;
> +
> + if (list_empty(&entity->list)) {
> + atomic_inc(sched->score);
> + list_add_tail(&entity->list, &rq->entities);
> + }
> +
> + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> + ts = entity->rr_ts;
> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> +
> + spin_unlock(&rq->lock);
> + spin_unlock(&entity->lock);
> +
> + return sched;
> }
>
> /**
> @@ -235,6 +258,54 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> spin_unlock(&rq->lock);
> }
>
> +static ktime_t
> +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> +{
> + ktime_t ts;
> +
> + lockdep_assert_held(&entity->lock);
> + lockdep_assert_held(&rq->lock);
> +
> + ts = ktime_add_ns(rq->rr_ts, 1);
> + entity->rr_ts = ts;
> + rq->rr_ts = ts;
I mentioned that pattern in a previous patch. "get_rr_ts" doesn't
appear like an obvious name since you're actually setting data here.
P.
> +
> + return ts;
> +}
> +
> +/**
> + * drm_sched_rq_pop_entity - pops an entity
> + *
> + * @entity: scheduler entity
> + *
> + * To be called every time after a job is popped from the entity.
> + */
> +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> +{
> + struct drm_sched_job *next_job;
> + struct drm_sched_rq *rq;
> + ktime_t ts;
> +
> + /*
> + * Update the entity's location in the min heap according to
> + * the timestamp of the next job, if any.
> + */
> + next_job = drm_sched_entity_queue_peek(entity);
> + if (!next_job)
> + return;
> +
> + spin_lock(&entity->lock);
> + rq = entity->rq;
> + spin_lock(&rq->lock);
> + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> + ts = next_job->submit_ts;
> + else
> + ts = drm_sched_rq_get_rr_ts(rq, entity);
> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> + spin_unlock(&rq->lock);
> + spin_unlock(&entity->lock);
> +}
> +
> /**
> * drm_sched_rq_select_entity - Select an entity which provides a job to run
> *
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 05/28] drm/sched: Consolidate entity run queue management
2025-10-10 10:49 ` Philipp Stanner
@ 2025-10-11 14:19 ` Tvrtko Ursulin
2025-10-14 6:53 ` Philipp Stanner
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-11 14:19 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 10/10/2025 11:49, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> Move the code dealing with entities entering and exiting run queues to
>> helpers to logically separate it from jobs entering and exiting entities.
>>
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> ---
>> drivers/gpu/drm/scheduler/sched_entity.c | 64 ++-------------
>> drivers/gpu/drm/scheduler/sched_internal.h | 8 +-
>> drivers/gpu/drm/scheduler/sched_main.c | 95 +++++++++++++++++++---
>> 3 files changed, 91 insertions(+), 76 deletions(-)
>>
>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>> index 4852006f2308..7a0a52ba87bf 100644
>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>> @@ -456,24 +456,9 @@ drm_sched_job_dependency(struct drm_sched_job *job,
>> return NULL;
>> }
>>
>> -static ktime_t
>> -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
>> -{
>> - ktime_t ts;
>> -
>> - lockdep_assert_held(&entity->lock);
>> - lockdep_assert_held(&rq->lock);
>> -
>> - ts = ktime_add_ns(rq->rr_ts, 1);
>> - entity->rr_ts = ts;
>> - rq->rr_ts = ts;
>> -
>> - return ts;
>> -}
>> -
>> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>> {
>> - struct drm_sched_job *sched_job, *next_job;
>> + struct drm_sched_job *sched_job;
>
> `next_job` has been added in a previous job. Have you tried whether
> patch-order can be reversed?
>
> Just asking; I don't want to cause unnecessary work here
You are correct that there would be some knock on effect on a few other
patches in the series but it is definitely doable. Because for certain
argument can be made it would be logical to have it like that. Both this
patch and "drm/sched: Move run queue related code into a separate file"
would be then moved ahead of "drm/sched: Implement RR via FIFO". If you
prefer it like that I can reshuffle no problem.
>>
>> sched_job = drm_sched_entity_queue_peek(entity);
>> if (!sched_job)
>> @@ -502,26 +487,7 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>>
>> spsc_queue_pop(&entity->job_queue);
>>
>> - /*
>> - * Update the entity's location in the min heap according to
>> - * the timestamp of the next job, if any.
>> - */
>> - next_job = drm_sched_entity_queue_peek(entity);
>> - if (next_job) {
>> - struct drm_sched_rq *rq;
>> - ktime_t ts;
>> -
>> - spin_lock(&entity->lock);
>> - rq = entity->rq;
>> - spin_lock(&rq->lock);
>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>> - ts = next_job->submit_ts;
>> - else
>> - ts = drm_sched_rq_get_rr_ts(rq, entity);
>> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
>> - spin_unlock(&rq->lock);
>> - spin_unlock(&entity->lock);
>> - }
>> + drm_sched_rq_pop_entity(entity);
>>
>> /* Jobs and entities might have different lifecycles. Since we're
>> * removing the job from the entities queue, set the jobs entity pointer
>> @@ -611,30 +577,10 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
>> /* first job wakes up scheduler */
>> if (first) {
>> struct drm_gpu_scheduler *sched;
>> - struct drm_sched_rq *rq;
>>
>> - /* Add the entity to the run queue */
>> - spin_lock(&entity->lock);
>> - if (entity->stopped) {
>> - spin_unlock(&entity->lock);
>> -
>> - DRM_ERROR("Trying to push to a killed entity\n");
>> - return;
>> - }
>> -
>> - rq = entity->rq;
>> - sched = rq->sched;
>> -
>> - spin_lock(&rq->lock);
>> - drm_sched_rq_add_entity(rq, entity);
>> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>> - submit_ts = entity->rr_ts;
>> - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
>> -
>> - spin_unlock(&rq->lock);
>> - spin_unlock(&entity->lock);
>> -
>> - drm_sched_wakeup(sched);
>> + sched = drm_sched_rq_add_entity(entity, submit_ts);
>> + if (sched)
>> + drm_sched_wakeup(sched);
>> }
>> }
>> EXPORT_SYMBOL(drm_sched_entity_push_job);
>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>> index 7ea5a6736f98..8269c5392a82 100644
>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>> @@ -12,13 +12,11 @@ extern int drm_sched_policy;
>>
>> void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
>>
>> -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
>> - struct drm_sched_entity *entity);
>> +struct drm_gpu_scheduler *
>> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
>> void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
>> struct drm_sched_entity *entity);
>> -
>> -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>> - struct drm_sched_rq *rq, ktime_t ts);
>> +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
>>
>> void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
>> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>> index 8e62541b439a..e5d02c28665c 100644
>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>> @@ -151,9 +151,9 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>> }
>> }
>>
>> -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>> - struct drm_sched_rq *rq,
>> - ktime_t ts)
>> +static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>> + struct drm_sched_rq *rq,
>> + ktime_t ts)
>> {
>> /*
>> * Both locks need to be grabbed, one to protect from entity->rq change
>> @@ -191,22 +191,45 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
>> /**
>> * drm_sched_rq_add_entity - add an entity
>> *
>> - * @rq: scheduler run queue
>> * @entity: scheduler entity
>> + * @ts: submission timestamp
>> *
>> * Adds a scheduler entity to the run queue.
>> + *
>> + * Returns a DRM scheduler pre-selected to handle this entity.
>> */
>> -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
>> - struct drm_sched_entity *entity)
>> +struct drm_gpu_scheduler *
>> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
>> {
>
> I'm not sure if it's a good idea to have the scheduler returned from
> that function. That doesn't make a whole lot of sense semantically.
>
> At the very least the function's docstring, maybe even its name, should
> be adjusted to detail why this makes sense. The commit message, too.
> It's not trivially understood.
>
> I think I get why it's being done, but writing it down black on white
> gives us something to grasp.
>
> Sth like "adds an entity to a runqueue, selects to appropriate
> scheduler and returns it for the purpose of XYZ"
Yeah. Remeber your unlocked rq access slide and the discussion around it?
Currently we have this:
drm_sched_entity_push_job()
{
...
spin_lock(&entity->lock);
...
rq = entity->rq;
sched = rq->sched;
...
spin_unlock(&rq->lock);
spin_unlock(&entity->lock);
drm_sched_wakeup(sched);
Ie. we know entity->rq and rq->sched are guaranteed to be stable and
present at this point because job is already in the queue and
drm_sched_entity_select_rq() guarantees that.
In this patch I moved all this block into drm_sched_rq_add_entity() but
I wanted to leave drm_sched_wakeup() outside. Because I thought it is
not the job of the run queue handling, and semantically the logic was
"only once added to the entity we know the rq and scheduler for
certain". That would open the door for future improvements and late
rq/scheduler selection.
But now I think it is premature and it would be better I simply move the
wakekup inside drm_sched_rq_add_entity() together with all the rest.
Does that sound like a plan for now?
Regards,
Tvrtko
>
>> - lockdep_assert_held(&entity->lock);
>> - lockdep_assert_held(&rq->lock);
>> + struct drm_gpu_scheduler *sched;
>> + struct drm_sched_rq *rq;
>>
>> - if (!list_empty(&entity->list))
>> - return;
>> + /* Add the entity to the run queue */
>> + spin_lock(&entity->lock);
>> + if (entity->stopped) {
>> + spin_unlock(&entity->lock);
>>
>> - atomic_inc(rq->sched->score);
>> - list_add_tail(&entity->list, &rq->entities);
>> + DRM_ERROR("Trying to push to a killed entity\n");
>> + return NULL;
>> + }
>> +
>> + rq = entity->rq;
>> + spin_lock(&rq->lock);
>> + sched = rq->sched;
>> +
>> + if (list_empty(&entity->list)) {
>> + atomic_inc(sched->score);
>> + list_add_tail(&entity->list, &rq->entities);
>> + }
>> +
>> + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>> + ts = entity->rr_ts;
>> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
>> +
>> + spin_unlock(&rq->lock);
>> + spin_unlock(&entity->lock);
>> +
>> + return sched;
>> }
>>
>> /**
>> @@ -235,6 +258,54 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
>> spin_unlock(&rq->lock);
>> }
>>
>> +static ktime_t
>> +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
>> +{
>> + ktime_t ts;
>> +
>> + lockdep_assert_held(&entity->lock);
>> + lockdep_assert_held(&rq->lock);
>> +
>> + ts = ktime_add_ns(rq->rr_ts, 1);
>> + entity->rr_ts = ts;
>> + rq->rr_ts = ts;
>
> I mentioned that pattern in a previous patch. "get_rr_ts" doesn't
> appear like an obvious name since you're actually setting data here.
>
> P.
>
>> +
>> + return ts;
>> +}
>> +
>> +/**
>> + * drm_sched_rq_pop_entity - pops an entity
>> + *
>> + * @entity: scheduler entity
>> + *
>> + * To be called every time after a job is popped from the entity.
>> + */
>> +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>> +{
>> + struct drm_sched_job *next_job;
>> + struct drm_sched_rq *rq;
>> + ktime_t ts;
>> +
>> + /*
>> + * Update the entity's location in the min heap according to
>> + * the timestamp of the next job, if any.
>> + */
>> + next_job = drm_sched_entity_queue_peek(entity);
>> + if (!next_job)
>> + return;
>> +
>> + spin_lock(&entity->lock);
>> + rq = entity->rq;
>> + spin_lock(&rq->lock);
>> + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>> + ts = next_job->submit_ts;
>> + else
>> + ts = drm_sched_rq_get_rr_ts(rq, entity);
>> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
>> + spin_unlock(&rq->lock);
>> + spin_unlock(&entity->lock);
>> +}
>> +
>> /**
>> * drm_sched_rq_select_entity - Select an entity which provides a job to run
>> *
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 05/28] drm/sched: Consolidate entity run queue management
2025-10-11 14:19 ` Tvrtko Ursulin
@ 2025-10-14 6:53 ` Philipp Stanner
2025-10-14 7:26 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-14 6:53 UTC (permalink / raw)
To: Tvrtko Ursulin, phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On Sat, 2025-10-11 at 15:19 +0100, Tvrtko Ursulin wrote:
>
> On 10/10/2025 11:49, Philipp Stanner wrote:
> > On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> > > Move the code dealing with entities entering and exiting run queues to
> > > helpers to logically separate it from jobs entering and exiting entities.
> > >
> > > Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> > > Cc: Christian König <christian.koenig@amd.com>
> > > Cc: Danilo Krummrich <dakr@kernel.org>
> > > Cc: Matthew Brost <matthew.brost@intel.com>
> > > Cc: Philipp Stanner <phasta@kernel.org>
> > > ---
> > > drivers/gpu/drm/scheduler/sched_entity.c | 64 ++-------------
> > > drivers/gpu/drm/scheduler/sched_internal.h | 8 +-
> > > drivers/gpu/drm/scheduler/sched_main.c | 95 +++++++++++++++++++---
> > > 3 files changed, 91 insertions(+), 76 deletions(-)
> > >
> > > diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> > > index 4852006f2308..7a0a52ba87bf 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_entity.c
> > > +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> > > @@ -456,24 +456,9 @@ drm_sched_job_dependency(struct drm_sched_job *job,
> > > return NULL;
> > > }
> > >
> > > -static ktime_t
> > > -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> > > -{
> > > - ktime_t ts;
> > > -
> > > - lockdep_assert_held(&entity->lock);
> > > - lockdep_assert_held(&rq->lock);
> > > -
> > > - ts = ktime_add_ns(rq->rr_ts, 1);
> > > - entity->rr_ts = ts;
> > > - rq->rr_ts = ts;
> > > -
> > > - return ts;
> > > -}
> > > -
> > > struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> > > {
> > > - struct drm_sched_job *sched_job, *next_job;
> > > + struct drm_sched_job *sched_job;
> >
> > `next_job` has been added in a previous job. Have you tried whether
> > patch-order can be reversed?
> >
> > Just asking; I don't want to cause unnecessary work here
>
> You are correct that there would be some knock on effect on a few other
> patches in the series but it is definitely doable. Because for certain
> argument can be made it would be logical to have it like that. Both this
> patch and "drm/sched: Move run queue related code into a separate file"
> would be then moved ahead of "drm/sched: Implement RR via FIFO". If you
> prefer it like that I can reshuffle no problem.
I mean, it seems to make the overall git diff smaller, which is nice?
If you don't see a significant reason against it, I'd say it's a good
idea.
>
> > >
> > > sched_job = drm_sched_entity_queue_peek(entity);
> > > if (!sched_job)
> > > @@ -502,26 +487,7 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> > >
> > > spsc_queue_pop(&entity->job_queue);
> > >
> > > - /*
> > > - * Update the entity's location in the min heap according to
> > > - * the timestamp of the next job, if any.
> > > - */
> > > - next_job = drm_sched_entity_queue_peek(entity);
> > > - if (next_job) {
> > > - struct drm_sched_rq *rq;
> > > - ktime_t ts;
> > > -
> > > - spin_lock(&entity->lock);
> > > - rq = entity->rq;
> > > - spin_lock(&rq->lock);
> > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > - ts = next_job->submit_ts;
> > > - else
> > > - ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > - drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > - spin_unlock(&rq->lock);
> > > - spin_unlock(&entity->lock);
> > > - }
> > > + drm_sched_rq_pop_entity(entity);
> > >
> > > /* Jobs and entities might have different lifecycles. Since we're
> > > * removing the job from the entities queue, set the jobs entity pointer
> > > @@ -611,30 +577,10 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
> > > /* first job wakes up scheduler */
> > > if (first) {
> > > struct drm_gpu_scheduler *sched;
> > > - struct drm_sched_rq *rq;
> > >
> > > - /* Add the entity to the run queue */
> > > - spin_lock(&entity->lock);
> > > - if (entity->stopped) {
> > > - spin_unlock(&entity->lock);
> > > -
> > > - DRM_ERROR("Trying to push to a killed entity\n");
> > > - return;
> > > - }
> > > -
> > > - rq = entity->rq;
> > > - sched = rq->sched;
> > > -
> > > - spin_lock(&rq->lock);
> > > - drm_sched_rq_add_entity(rq, entity);
> > > - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > - submit_ts = entity->rr_ts;
> > > - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
> > > -
> > > - spin_unlock(&rq->lock);
> > > - spin_unlock(&entity->lock);
> > > -
> > > - drm_sched_wakeup(sched);
> > > + sched = drm_sched_rq_add_entity(entity, submit_ts);
> > > + if (sched)
> > > + drm_sched_wakeup(sched);
> > > }
> > > }
> > > EXPORT_SYMBOL(drm_sched_entity_push_job);
> > > diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> > > index 7ea5a6736f98..8269c5392a82 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_internal.h
> > > +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> > > @@ -12,13 +12,11 @@ extern int drm_sched_policy;
> > >
> > > void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
> > >
> > > -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
> > > - struct drm_sched_entity *entity);
> > > +struct drm_gpu_scheduler *
> > > +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
> > > void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> > > struct drm_sched_entity *entity);
> > > -
> > > -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > - struct drm_sched_rq *rq, ktime_t ts);
> > > +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
> > >
> > > void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
> > > struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
> > > diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> > > index 8e62541b439a..e5d02c28665c 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_main.c
> > > +++ b/drivers/gpu/drm/scheduler/sched_main.c
> > > @@ -151,9 +151,9 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > }
> > > }
> > >
> > > -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > - struct drm_sched_rq *rq,
> > > - ktime_t ts)
> > > +static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > + struct drm_sched_rq *rq,
> > > + ktime_t ts)
> > > {
> > > /*
> > > * Both locks need to be grabbed, one to protect from entity->rq change
> > > @@ -191,22 +191,45 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
> > > /**
> > > * drm_sched_rq_add_entity - add an entity
> > > *
> > > - * @rq: scheduler run queue
> > > * @entity: scheduler entity
> > > + * @ts: submission timestamp
> > > *
> > > * Adds a scheduler entity to the run queue.
> > > + *
> > > + * Returns a DRM scheduler pre-selected to handle this entity.
> > > */
> > > -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
> > > - struct drm_sched_entity *entity)
> > > +struct drm_gpu_scheduler *
> > > +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> > > {
> >
> > I'm not sure if it's a good idea to have the scheduler returned from
> > that function. That doesn't make a whole lot of sense semantically.
> >
> > At the very least the function's docstring, maybe even its name, should
> > be adjusted to detail why this makes sense. The commit message, too.
> > It's not trivially understood.
> >
> > I think I get why it's being done, but writing it down black on white
> > gives us something to grasp.
> >
> > Sth like "adds an entity to a runqueue, selects to appropriate
> > scheduler and returns it for the purpose of XYZ"
>
> Yeah. Remeber your unlocked rq access slide and the discussion around it?
Sure. Is that related, though? The slide was about many readers being
totally unlocked. The current drm_sched_entity_push_job() locks readers
correctly if I'm not mistaken.
>
> Currently we have this:
>
> drm_sched_entity_push_job()
> {
> ...
> spin_lock(&entity->lock);
> ...
> rq = entity->rq;
> sched = rq->sched;
> ...
> spin_unlock(&rq->lock);
> spin_unlock(&entity->lock);
>
> drm_sched_wakeup(sched);
>
> Ie. we know entity->rq and rq->sched are guaranteed to be stable and
> present at this point because job is already in the queue and
> drm_sched_entity_select_rq() guarantees that.
>
> In this patch I moved all this block into drm_sched_rq_add_entity() but
> I wanted to leave drm_sched_wakeup() outside. Because I thought it is
> not the job of the run queue handling, and semantically the logic was
> "only once added to the entity we know the rq and scheduler for
> certain". That would open the door for future improvements and late
> rq/scheduler selection.
>
> But now I think it is premature and it would be better I simply move the
> wakekup inside drm_sched_rq_add_entity() together with all the rest.
>
> Does that sound like a plan for now?
Hmmm. What I'm wondering most about if it really is a good idea to have
drm_sched_wakeup() in rq_add_entity().
Do you think that makes semantically more sense than just reading:
drm_sched_entity_push_job()
{
foo
bar
more_foo
/* New job was added. Right time to wake up scheduler. */
drm_sched_wakeup();
I think both can make sense, but the above / current version seems to
make more sense to me.
P.
>
> Regards,
>
> Tvrtko
>
> >
> > > - lockdep_assert_held(&entity->lock);
> > > - lockdep_assert_held(&rq->lock);
> > > + struct drm_gpu_scheduler *sched;
> > > + struct drm_sched_rq *rq;
> > >
> > > - if (!list_empty(&entity->list))
> > > - return;
> > > + /* Add the entity to the run queue */
> > > + spin_lock(&entity->lock);
> > > + if (entity->stopped) {
> > > + spin_unlock(&entity->lock);
> > >
> > > - atomic_inc(rq->sched->score);
> > > - list_add_tail(&entity->list, &rq->entities);
> > > + DRM_ERROR("Trying to push to a killed entity\n");
> > > + return NULL;
> > > + }
> > > +
> > > + rq = entity->rq;
> > > + spin_lock(&rq->lock);
> > > + sched = rq->sched;
> > > +
> > > + if (list_empty(&entity->list)) {
> > > + atomic_inc(sched->score);
> > > + list_add_tail(&entity->list, &rq->entities);
> > > + }
> > > +
> > > + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > + ts = entity->rr_ts;
> > > + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > +
> > > + spin_unlock(&rq->lock);
> > > + spin_unlock(&entity->lock);
> > > +
> > > + return sched;
> > > }
> > >
> > > /**
> > > @@ -235,6 +258,54 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> > > spin_unlock(&rq->lock);
> > > }
> > >
> > > +static ktime_t
> > > +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> > > +{
> > > + ktime_t ts;
> > > +
> > > + lockdep_assert_held(&entity->lock);
> > > + lockdep_assert_held(&rq->lock);
> > > +
> > > + ts = ktime_add_ns(rq->rr_ts, 1);
> > > + entity->rr_ts = ts;
> > > + rq->rr_ts = ts;
> >
> > I mentioned that pattern in a previous patch. "get_rr_ts" doesn't
> > appear like an obvious name since you're actually setting data here.
> >
> > P.
> >
> > > +
> > > + return ts;
> > > +}
> > > +
> > > +/**
> > > + * drm_sched_rq_pop_entity - pops an entity
> > > + *
> > > + * @entity: scheduler entity
> > > + *
> > > + * To be called every time after a job is popped from the entity.
> > > + */
> > > +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> > > +{
> > > + struct drm_sched_job *next_job;
> > > + struct drm_sched_rq *rq;
> > > + ktime_t ts;
> > > +
> > > + /*
> > > + * Update the entity's location in the min heap according to
> > > + * the timestamp of the next job, if any.
> > > + */
> > > + next_job = drm_sched_entity_queue_peek(entity);
> > > + if (!next_job)
> > > + return;
> > > +
> > > + spin_lock(&entity->lock);
> > > + rq = entity->rq;
> > > + spin_lock(&rq->lock);
> > > + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > + ts = next_job->submit_ts;
> > > + else
> > > + ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > + spin_unlock(&rq->lock);
> > > + spin_unlock(&entity->lock);
> > > +}
> > > +
> > > /**
> > > * drm_sched_rq_select_entity - Select an entity which provides a job to run
> > > *
> >
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 05/28] drm/sched: Consolidate entity run queue management
2025-10-14 6:53 ` Philipp Stanner
@ 2025-10-14 7:26 ` Tvrtko Ursulin
2025-10-14 8:52 ` Philipp Stanner
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-14 7:26 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 14/10/2025 07:53, Philipp Stanner wrote:
> On Sat, 2025-10-11 at 15:19 +0100, Tvrtko Ursulin wrote:
>>
>> On 10/10/2025 11:49, Philipp Stanner wrote:
>>> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>>>> Move the code dealing with entities entering and exiting run queues to
>>>> helpers to logically separate it from jobs entering and exiting entities.
>>>>
>>>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>>>> Cc: Christian König <christian.koenig@amd.com>
>>>> Cc: Danilo Krummrich <dakr@kernel.org>
>>>> Cc: Matthew Brost <matthew.brost@intel.com>
>>>> Cc: Philipp Stanner <phasta@kernel.org>
>>>> ---
>>>> drivers/gpu/drm/scheduler/sched_entity.c | 64 ++-------------
>>>> drivers/gpu/drm/scheduler/sched_internal.h | 8 +-
>>>> drivers/gpu/drm/scheduler/sched_main.c | 95 +++++++++++++++++++---
>>>> 3 files changed, 91 insertions(+), 76 deletions(-)
>>>>
>>>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>>>> index 4852006f2308..7a0a52ba87bf 100644
>>>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>>>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>>>> @@ -456,24 +456,9 @@ drm_sched_job_dependency(struct drm_sched_job *job,
>>>> return NULL;
>>>> }
>>>>
>>>> -static ktime_t
>>>> -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
>>>> -{
>>>> - ktime_t ts;
>>>> -
>>>> - lockdep_assert_held(&entity->lock);
>>>> - lockdep_assert_held(&rq->lock);
>>>> -
>>>> - ts = ktime_add_ns(rq->rr_ts, 1);
>>>> - entity->rr_ts = ts;
>>>> - rq->rr_ts = ts;
>>>> -
>>>> - return ts;
>>>> -}
>>>> -
>>>> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>>>> {
>>>> - struct drm_sched_job *sched_job, *next_job;
>>>> + struct drm_sched_job *sched_job;
>>>
>>> `next_job` has been added in a previous job. Have you tried whether
>>> patch-order can be reversed?
>>>
>>> Just asking; I don't want to cause unnecessary work here
>>
>> You are correct that there would be some knock on effect on a few other
>> patches in the series but it is definitely doable. Because for certain
>> argument can be made it would be logical to have it like that. Both this
>> patch and "drm/sched: Move run queue related code into a separate file"
>> would be then moved ahead of "drm/sched: Implement RR via FIFO". If you
>> prefer it like that I can reshuffle no problem.
>
> I mean, it seems to make the overall git diff smaller, which is nice?
>
> If you don't see a significant reason against it, I'd say it's a good
> idea.
Okay deal. It isn't anything significant, just re-ordering patches with
compile testing patches to ensure every step still builds.
>>>>
>>>> sched_job = drm_sched_entity_queue_peek(entity);
>>>> if (!sched_job)
>>>> @@ -502,26 +487,7 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>>>>
>>>> spsc_queue_pop(&entity->job_queue);
>>>>
>>>> - /*
>>>> - * Update the entity's location in the min heap according to
>>>> - * the timestamp of the next job, if any.
>>>> - */
>>>> - next_job = drm_sched_entity_queue_peek(entity);
>>>> - if (next_job) {
>>>> - struct drm_sched_rq *rq;
>>>> - ktime_t ts;
>>>> -
>>>> - spin_lock(&entity->lock);
>>>> - rq = entity->rq;
>>>> - spin_lock(&rq->lock);
>>>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>>>> - ts = next_job->submit_ts;
>>>> - else
>>>> - ts = drm_sched_rq_get_rr_ts(rq, entity);
>>>> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>>> - spin_unlock(&rq->lock);
>>>> - spin_unlock(&entity->lock);
>>>> - }
>>>> + drm_sched_rq_pop_entity(entity);
>>>>
>>>> /* Jobs and entities might have different lifecycles. Since we're
>>>> * removing the job from the entities queue, set the jobs entity pointer
>>>> @@ -611,30 +577,10 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
>>>> /* first job wakes up scheduler */
>>>> if (first) {
>>>> struct drm_gpu_scheduler *sched;
>>>> - struct drm_sched_rq *rq;
>>>>
>>>> - /* Add the entity to the run queue */
>>>> - spin_lock(&entity->lock);
>>>> - if (entity->stopped) {
>>>> - spin_unlock(&entity->lock);
>>>> -
>>>> - DRM_ERROR("Trying to push to a killed entity\n");
>>>> - return;
>>>> - }
>>>> -
>>>> - rq = entity->rq;
>>>> - sched = rq->sched;
>>>> -
>>>> - spin_lock(&rq->lock);
>>>> - drm_sched_rq_add_entity(rq, entity);
>>>> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>>>> - submit_ts = entity->rr_ts;
>>>> - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
>>>> -
>>>> - spin_unlock(&rq->lock);
>>>> - spin_unlock(&entity->lock);
>>>> -
>>>> - drm_sched_wakeup(sched);
>>>> + sched = drm_sched_rq_add_entity(entity, submit_ts);
>>>> + if (sched)
>>>> + drm_sched_wakeup(sched);
>>>> }
>>>> }
>>>> EXPORT_SYMBOL(drm_sched_entity_push_job);
>>>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>>>> index 7ea5a6736f98..8269c5392a82 100644
>>>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>>>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>>>> @@ -12,13 +12,11 @@ extern int drm_sched_policy;
>>>>
>>>> void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
>>>>
>>>> -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
>>>> - struct drm_sched_entity *entity);
>>>> +struct drm_gpu_scheduler *
>>>> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
>>>> void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
>>>> struct drm_sched_entity *entity);
>>>> -
>>>> -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>> - struct drm_sched_rq *rq, ktime_t ts);
>>>> +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
>>>>
>>>> void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
>>>> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
>>>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>>>> index 8e62541b439a..e5d02c28665c 100644
>>>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>>>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>>>> @@ -151,9 +151,9 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>>>> }
>>>> }
>>>>
>>>> -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>> - struct drm_sched_rq *rq,
>>>> - ktime_t ts)
>>>> +static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>> + struct drm_sched_rq *rq,
>>>> + ktime_t ts)
>>>> {
>>>> /*
>>>> * Both locks need to be grabbed, one to protect from entity->rq change
>>>> @@ -191,22 +191,45 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
>>>> /**
>>>> * drm_sched_rq_add_entity - add an entity
>>>> *
>>>> - * @rq: scheduler run queue
>>>> * @entity: scheduler entity
>>>> + * @ts: submission timestamp
>>>> *
>>>> * Adds a scheduler entity to the run queue.
>>>> + *
>>>> + * Returns a DRM scheduler pre-selected to handle this entity.
>>>> */
>>>> -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
>>>> - struct drm_sched_entity *entity)
>>>> +struct drm_gpu_scheduler *
>>>> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
>>>> {
>>>
>>> I'm not sure if it's a good idea to have the scheduler returned from
>>> that function. That doesn't make a whole lot of sense semantically.
>>>
>>> At the very least the function's docstring, maybe even its name, should
>>> be adjusted to detail why this makes sense. The commit message, too.
>>> It's not trivially understood.
>>>
>>> I think I get why it's being done, but writing it down black on white
>>> gives us something to grasp.
>>>
>>> Sth like "adds an entity to a runqueue, selects to appropriate
>>> scheduler and returns it for the purpose of XYZ"
>>
>> Yeah. Remeber your unlocked rq access slide and the discussion around it?
>
> Sure. Is that related, though? The slide was about many readers being
> totally unlocked. The current drm_sched_entity_push_job() locks readers
> correctly if I'm not mistaken.
>
>>
>> Currently we have this:
>>
>> drm_sched_entity_push_job()
>> {
>> ...
>> spin_lock(&entity->lock);
>> ...
>> rq = entity->rq;
>> sched = rq->sched;
>> ...
>> spin_unlock(&rq->lock);
>> spin_unlock(&entity->lock);
>>
>> drm_sched_wakeup(sched);
>>
>> Ie. we know entity->rq and rq->sched are guaranteed to be stable and
>> present at this point because job is already in the queue and
>> drm_sched_entity_select_rq() guarantees that.
>>
>> In this patch I moved all this block into drm_sched_rq_add_entity() but
>> I wanted to leave drm_sched_wakeup() outside. Because I thought it is
>> not the job of the run queue handling, and semantically the logic was
>> "only once added to the entity we know the rq and scheduler for
>> certain". That would open the door for future improvements and late
>> rq/scheduler selection.
>>
>> But now I think it is premature and it would be better I simply move the
>> wakekup inside drm_sched_rq_add_entity() together with all the rest.
>>
>> Does that sound like a plan for now?
>
> Hmmm. What I'm wondering most about if it really is a good idea to have
> drm_sched_wakeup() in rq_add_entity().
>
> Do you think that makes semantically more sense than just reading:
>
> drm_sched_entity_push_job()
> {
> foo
> bar
> more_foo
>
> /* New job was added. Right time to wake up scheduler. */
> drm_sched_wakeup();
Problem here always is you need a sched pointer so question is simply
how and where to get it.
> I think both can make sense, but the above / current version seems to
> make more sense to me.
Current as in this patch or current as in the upstream codebase?
In all cases the knowledge it is safe to use sched after unlocking is
implicit.
I see only two options:
current)
drm_sched_entity_push_job()
{
...
spin_unlock(&rq->lock);
spin_unlock(&entity->lock);
drm_sched_wakeup(sched);
a)
drm_sched_entity_push_job()
{
...
sched = drm_sched_rq_add_entity(entity, submit_ts);
if (sched)
drm_sched_wakeup(sched);
b)
drm_sched_rq_add_entity()
{
...
spin_unlock(&rq->lock);
spin_unlock(&entity->lock);
drm_sched_wakeup(sched);
drm_sched_entity_push_job()
{
...
drm_sched_rq_add_entity(entity, submit_ts);
b) is the same as today, a) perhaps a bit premature. Which do you prefer?
Regards,
Tvrtko
>>>> - lockdep_assert_held(&entity->lock);
>>>> - lockdep_assert_held(&rq->lock);
>>>> + struct drm_gpu_scheduler *sched;
>>>> + struct drm_sched_rq *rq;
>>>>
>>>> - if (!list_empty(&entity->list))
>>>> - return;
>>>> + /* Add the entity to the run queue */
>>>> + spin_lock(&entity->lock);
>>>> + if (entity->stopped) {
>>>> + spin_unlock(&entity->lock);
>>>>
>>>> - atomic_inc(rq->sched->score);
>>>> - list_add_tail(&entity->list, &rq->entities);
>>>> + DRM_ERROR("Trying to push to a killed entity\n");
>>>> + return NULL;
>>>> + }
>>>> +
>>>> + rq = entity->rq;
>>>> + spin_lock(&rq->lock);
>>>> + sched = rq->sched;
>>>> +
>>>> + if (list_empty(&entity->list)) {
>>>> + atomic_inc(sched->score);
>>>> + list_add_tail(&entity->list, &rq->entities);
>>>> + }
>>>> +
>>>> + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>>>> + ts = entity->rr_ts;
>>>> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>>> +
>>>> + spin_unlock(&rq->lock);
>>>> + spin_unlock(&entity->lock);
>>>> +
>>>> + return sched;
>>>> }
>>>>
>>>> /**
>>>> @@ -235,6 +258,54 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
>>>> spin_unlock(&rq->lock);
>>>> }
>>>>
>>>> +static ktime_t
>>>> +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
>>>> +{
>>>> + ktime_t ts;
>>>> +
>>>> + lockdep_assert_held(&entity->lock);
>>>> + lockdep_assert_held(&rq->lock);
>>>> +
>>>> + ts = ktime_add_ns(rq->rr_ts, 1);
>>>> + entity->rr_ts = ts;
>>>> + rq->rr_ts = ts;
>>>
>>> I mentioned that pattern in a previous patch. "get_rr_ts" doesn't
>>> appear like an obvious name since you're actually setting data here.
>>>
>>> P.
>>>
>>>> +
>>>> + return ts;
>>>> +}
>>>> +
>>>> +/**
>>>> + * drm_sched_rq_pop_entity - pops an entity
>>>> + *
>>>> + * @entity: scheduler entity
>>>> + *
>>>> + * To be called every time after a job is popped from the entity.
>>>> + */
>>>> +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>>>> +{
>>>> + struct drm_sched_job *next_job;
>>>> + struct drm_sched_rq *rq;
>>>> + ktime_t ts;
>>>> +
>>>> + /*
>>>> + * Update the entity's location in the min heap according to
>>>> + * the timestamp of the next job, if any.
>>>> + */
>>>> + next_job = drm_sched_entity_queue_peek(entity);
>>>> + if (!next_job)
>>>> + return;
>>>> +
>>>> + spin_lock(&entity->lock);
>>>> + rq = entity->rq;
>>>> + spin_lock(&rq->lock);
>>>> + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>>>> + ts = next_job->submit_ts;
>>>> + else
>>>> + ts = drm_sched_rq_get_rr_ts(rq, entity);
>>>> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>>> + spin_unlock(&rq->lock);
>>>> + spin_unlock(&entity->lock);
>>>> +}
>>>> +
>>>> /**
>>>> * drm_sched_rq_select_entity - Select an entity which provides a job to run
>>>> *
>>>
>>
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 05/28] drm/sched: Consolidate entity run queue management
2025-10-14 7:26 ` Tvrtko Ursulin
@ 2025-10-14 8:52 ` Philipp Stanner
2025-10-14 10:04 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-14 8:52 UTC (permalink / raw)
To: Tvrtko Ursulin, phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On Tue, 2025-10-14 at 08:26 +0100, Tvrtko Ursulin wrote:
>
> On 14/10/2025 07:53, Philipp Stanner wrote:
> > On Sat, 2025-10-11 at 15:19 +0100, Tvrtko Ursulin wrote:
> > >
> > > On 10/10/2025 11:49, Philipp Stanner wrote:
> > > > On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> > > > > Move the code dealing with entities entering and exiting run queues to
> > > > > helpers to logically separate it from jobs entering and exiting entities.
> > > > >
> > > > > Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> > > > > Cc: Christian König <christian.koenig@amd.com>
> > > > > Cc: Danilo Krummrich <dakr@kernel.org>
> > > > > Cc: Matthew Brost <matthew.brost@intel.com>
> > > > > Cc: Philipp Stanner <phasta@kernel.org>
> > > > > ---
> > > > > drivers/gpu/drm/scheduler/sched_entity.c | 64 ++-------------
> > > > > drivers/gpu/drm/scheduler/sched_internal.h | 8 +-
> > > > > drivers/gpu/drm/scheduler/sched_main.c | 95 +++++++++++++++++++---
> > > > > 3 files changed, 91 insertions(+), 76 deletions(-)
> > > > >
> > > > > diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > index 4852006f2308..7a0a52ba87bf 100644
> > > > > --- a/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > @@ -456,24 +456,9 @@ drm_sched_job_dependency(struct drm_sched_job *job,
> > > > > return NULL;
> > > > > }
> > > > >
> > > > > -static ktime_t
> > > > > -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> > > > > -{
> > > > > - ktime_t ts;
> > > > > -
> > > > > - lockdep_assert_held(&entity->lock);
> > > > > - lockdep_assert_held(&rq->lock);
> > > > > -
> > > > > - ts = ktime_add_ns(rq->rr_ts, 1);
> > > > > - entity->rr_ts = ts;
> > > > > - rq->rr_ts = ts;
> > > > > -
> > > > > - return ts;
> > > > > -}
> > > > > -
> > > > > struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> > > > > {
> > > > > - struct drm_sched_job *sched_job, *next_job;
> > > > > + struct drm_sched_job *sched_job;
> > > >
> > > > `next_job` has been added in a previous job. Have you tried whether
> > > > patch-order can be reversed?
> > > >
> > > > Just asking; I don't want to cause unnecessary work here
> > >
> > > You are correct that there would be some knock on effect on a few other
> > > patches in the series but it is definitely doable. Because for certain
> > > argument can be made it would be logical to have it like that. Both this
> > > patch and "drm/sched: Move run queue related code into a separate file"
> > > would be then moved ahead of "drm/sched: Implement RR via FIFO". If you
> > > prefer it like that I can reshuffle no problem.
> >
> > I mean, it seems to make the overall git diff smaller, which is nice?
> >
> > If you don't see a significant reason against it, I'd say it's a good
> > idea.
>
> Okay deal. It isn't anything significant, just re-ordering patches with
> compile testing patches to ensure every step still builds.
> > > > >
> > > > > sched_job = drm_sched_entity_queue_peek(entity);
> > > > > if (!sched_job)
> > > > > @@ -502,26 +487,7 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> > > > >
> > > > > spsc_queue_pop(&entity->job_queue);
> > > > >
> > > > > - /*
> > > > > - * Update the entity's location in the min heap according to
> > > > > - * the timestamp of the next job, if any.
> > > > > - */
> > > > > - next_job = drm_sched_entity_queue_peek(entity);
> > > > > - if (next_job) {
> > > > > - struct drm_sched_rq *rq;
> > > > > - ktime_t ts;
> > > > > -
> > > > > - spin_lock(&entity->lock);
> > > > > - rq = entity->rq;
> > > > > - spin_lock(&rq->lock);
> > > > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > > > - ts = next_job->submit_ts;
> > > > > - else
> > > > > - ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > > > - drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > > > - spin_unlock(&rq->lock);
> > > > > - spin_unlock(&entity->lock);
> > > > > - }
> > > > > + drm_sched_rq_pop_entity(entity);
> > > > >
> > > > > /* Jobs and entities might have different lifecycles. Since we're
> > > > > * removing the job from the entities queue, set the jobs entity pointer
> > > > > @@ -611,30 +577,10 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
> > > > > /* first job wakes up scheduler */
> > > > > if (first) {
> > > > > struct drm_gpu_scheduler *sched;
> > > > > - struct drm_sched_rq *rq;
> > > > >
> > > > > - /* Add the entity to the run queue */
> > > > > - spin_lock(&entity->lock);
> > > > > - if (entity->stopped) {
> > > > > - spin_unlock(&entity->lock);
> > > > > -
> > > > > - DRM_ERROR("Trying to push to a killed entity\n");
> > > > > - return;
> > > > > - }
> > > > > -
> > > > > - rq = entity->rq;
> > > > > - sched = rq->sched;
> > > > > -
> > > > > - spin_lock(&rq->lock);
> > > > > - drm_sched_rq_add_entity(rq, entity);
> > > > > - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > > > - submit_ts = entity->rr_ts;
> > > > > - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
> > > > > -
> > > > > - spin_unlock(&rq->lock);
> > > > > - spin_unlock(&entity->lock);
> > > > > -
> > > > > - drm_sched_wakeup(sched);
> > > > > + sched = drm_sched_rq_add_entity(entity, submit_ts);
> > > > > + if (sched)
> > > > > + drm_sched_wakeup(sched);
> > > > > }
> > > > > }
> > > > > EXPORT_SYMBOL(drm_sched_entity_push_job);
> > > > > diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > index 7ea5a6736f98..8269c5392a82 100644
> > > > > --- a/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > @@ -12,13 +12,11 @@ extern int drm_sched_policy;
> > > > >
> > > > > void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
> > > > >
> > > > > -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
> > > > > - struct drm_sched_entity *entity);
> > > > > +struct drm_gpu_scheduler *
> > > > > +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
> > > > > void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> > > > > struct drm_sched_entity *entity);
> > > > > -
> > > > > -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > > > - struct drm_sched_rq *rq, ktime_t ts);
> > > > > +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
> > > > >
> > > > > void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
> > > > > struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
> > > > > diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> > > > > index 8e62541b439a..e5d02c28665c 100644
> > > > > --- a/drivers/gpu/drm/scheduler/sched_main.c
> > > > > +++ b/drivers/gpu/drm/scheduler/sched_main.c
> > > > > @@ -151,9 +151,9 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > > > }
> > > > > }
> > > > >
> > > > > -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > > > - struct drm_sched_rq *rq,
> > > > > - ktime_t ts)
> > > > > +static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > > > + struct drm_sched_rq *rq,
> > > > > + ktime_t ts)
> > > > > {
> > > > > /*
> > > > > * Both locks need to be grabbed, one to protect from entity->rq change
> > > > > @@ -191,22 +191,45 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
> > > > > /**
> > > > > * drm_sched_rq_add_entity - add an entity
> > > > > *
> > > > > - * @rq: scheduler run queue
> > > > > * @entity: scheduler entity
> > > > > + * @ts: submission timestamp
> > > > > *
> > > > > * Adds a scheduler entity to the run queue.
> > > > > + *
> > > > > + * Returns a DRM scheduler pre-selected to handle this entity.
> > > > > */
> > > > > -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
> > > > > - struct drm_sched_entity *entity)
> > > > > +struct drm_gpu_scheduler *
> > > > > +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> > > > > {
> > > >
> > > > I'm not sure if it's a good idea to have the scheduler returned from
> > > > that function. That doesn't make a whole lot of sense semantically.
> > > >
> > > > At the very least the function's docstring, maybe even its name, should
> > > > be adjusted to detail why this makes sense. The commit message, too.
> > > > It's not trivially understood.
> > > >
> > > > I think I get why it's being done, but writing it down black on white
> > > > gives us something to grasp.
> > > >
> > > > Sth like "adds an entity to a runqueue, selects to appropriate
> > > > scheduler and returns it for the purpose of XYZ"
> > >
> > > Yeah. Remeber your unlocked rq access slide and the discussion around it?
> >
> > Sure. Is that related, though? The slide was about many readers being
> > totally unlocked. The current drm_sched_entity_push_job() locks readers
> > correctly if I'm not mistaken.
> >
> > >
> > > Currently we have this:
> > >
> > > drm_sched_entity_push_job()
> > > {
> > > ...
> > > spin_lock(&entity->lock);
> > > ...
> > > rq = entity->rq;
> > > sched = rq->sched;
> > > ...
> > > spin_unlock(&rq->lock);
> > > spin_unlock(&entity->lock);
> > >
> > > drm_sched_wakeup(sched);
> > >
> > > Ie. we know entity->rq and rq->sched are guaranteed to be stable and
> > > present at this point because job is already in the queue and
> > > drm_sched_entity_select_rq() guarantees that.
> > >
> > > In this patch I moved all this block into drm_sched_rq_add_entity() but
> > > I wanted to leave drm_sched_wakeup() outside. Because I thought it is
> > > not the job of the run queue handling, and semantically the logic was
> > > "only once added to the entity we know the rq and scheduler for
> > > certain". That would open the door for future improvements and late
> > > rq/scheduler selection.
> > >
> > > But now I think it is premature and it would be better I simply move the
> > > wakekup inside drm_sched_rq_add_entity() together with all the rest.
> > >
> > > Does that sound like a plan for now?
> >
> > Hmmm. What I'm wondering most about if it really is a good idea to have
> > drm_sched_wakeup() in rq_add_entity().
> >
> > Do you think that makes semantically more sense than just reading:
> >
> > drm_sched_entity_push_job()
> > {
> > foo
> > bar
> > more_foo
> >
> > /* New job was added. Right time to wake up scheduler. */
> > drm_sched_wakeup();
>
> Problem here always is you need a sched pointer so question is simply
> how and where to get it.
>
> > I think both can make sense, but the above / current version seems to
> > make more sense to me.
>
> Current as in this patch or current as in the upstream codebase?
>
> In all cases the knowledge it is safe to use sched after unlocking is
> implicit.
>
> I see only two options:
>
> current)
>
> drm_sched_entity_push_job()
> {
> ...
> spin_unlock(&rq->lock);
> spin_unlock(&entity->lock);
>
> drm_sched_wakeup(sched);
>
> a)
>
> drm_sched_entity_push_job()
> {
> ...
> sched = drm_sched_rq_add_entity(entity, submit_ts);
> if (sched)
> drm_sched_wakeup(sched);
>
> b)
>
> drm_sched_rq_add_entity()
> {
> ...
> spin_unlock(&rq->lock);
> spin_unlock(&entity->lock);
>
> drm_sched_wakeup(sched);
>
>
> drm_sched_entity_push_job()
> {
> ...
> drm_sched_rq_add_entity(entity, submit_ts);
>
>
> b) is the same as today, a) perhaps a bit premature. Which do you prefer?
Alright, I looked through everything now.
The thing is just that I believe that it's a semantically confusing and
unclean concept of having drm_sched_rq_add_entity() return a scheduler
– except for when the entity is stopped. Then "there is no scheduler"
actually means "there is a scheduler, but that entity is stopped"
In an ideal world:
a) drm_sched_entity_push_job() wakes up the scheduler (as in your code,
and as in the current mainline code) and
b) drm_sched_entity_push_job() is the one who checks whether the entity
is stopped. rq_add_entity() should just, well, add an entity to a
runqueue.
Option b) then would need locks again and could race. So that's not so
cool.
Possible solutions I can see is:
1. Have drm_sched_rq_add_entity() return an ERR_PTR instead of NULL.
2. Rename rq_add_entity()
3. Potentially leave it as is? I guess that doesn't work for your rq-
simplification?
Option 1 would almost be my preference. What do you think?
P.
>
> Regards,
>
> Tvrtko
>
> > > > > - lockdep_assert_held(&entity->lock);
> > > > > - lockdep_assert_held(&rq->lock);
> > > > > + struct drm_gpu_scheduler *sched;
> > > > > + struct drm_sched_rq *rq;
> > > > >
> > > > > - if (!list_empty(&entity->list))
> > > > > - return;
> > > > > + /* Add the entity to the run queue */
> > > > > + spin_lock(&entity->lock);
> > > > > + if (entity->stopped) {
> > > > > + spin_unlock(&entity->lock);
> > > > >
> > > > > - atomic_inc(rq->sched->score);
> > > > > - list_add_tail(&entity->list, &rq->entities);
> > > > > + DRM_ERROR("Trying to push to a killed entity\n");
> > > > > + return NULL;
> > > > > + }
> > > > > +
> > > > > + rq = entity->rq;
> > > > > + spin_lock(&rq->lock);
> > > > > + sched = rq->sched;
> > > > > +
> > > > > + if (list_empty(&entity->list)) {
> > > > > + atomic_inc(sched->score);
> > > > > + list_add_tail(&entity->list, &rq->entities);
> > > > > + }
> > > > > +
> > > > > + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > > > + ts = entity->rr_ts;
> > > > > + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > > > +
> > > > > + spin_unlock(&rq->lock);
> > > > > + spin_unlock(&entity->lock);
> > > > > +
> > > > > + return sched;
> > > > > }
> > > > >
> > > > > /**
> > > > > @@ -235,6 +258,54 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> > > > > spin_unlock(&rq->lock);
> > > > > }
> > > > >
> > > > > +static ktime_t
> > > > > +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> > > > > +{
> > > > > + ktime_t ts;
> > > > > +
> > > > > + lockdep_assert_held(&entity->lock);
> > > > > + lockdep_assert_held(&rq->lock);
> > > > > +
> > > > > + ts = ktime_add_ns(rq->rr_ts, 1);
> > > > > + entity->rr_ts = ts;
> > > > > + rq->rr_ts = ts;
> > > >
> > > > I mentioned that pattern in a previous patch. "get_rr_ts" doesn't
> > > > appear like an obvious name since you're actually setting data here.
> > > >
> > > > P.
> > > >
> > > > > +
> > > > > + return ts;
> > > > > +}
> > > > > +
> > > > > +/**
> > > > > + * drm_sched_rq_pop_entity - pops an entity
> > > > > + *
> > > > > + * @entity: scheduler entity
> > > > > + *
> > > > > + * To be called every time after a job is popped from the entity.
> > > > > + */
> > > > > +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> > > > > +{
> > > > > + struct drm_sched_job *next_job;
> > > > > + struct drm_sched_rq *rq;
> > > > > + ktime_t ts;
> > > > > +
> > > > > + /*
> > > > > + * Update the entity's location in the min heap according to
> > > > > + * the timestamp of the next job, if any.
> > > > > + */
> > > > > + next_job = drm_sched_entity_queue_peek(entity);
> > > > > + if (!next_job)
> > > > > + return;
> > > > > +
> > > > > + spin_lock(&entity->lock);
> > > > > + rq = entity->rq;
> > > > > + spin_lock(&rq->lock);
> > > > > + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > > > + ts = next_job->submit_ts;
> > > > > + else
> > > > > + ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > > > + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > > > + spin_unlock(&rq->lock);
> > > > > + spin_unlock(&entity->lock);
> > > > > +}
> > > > > +
> > > > > /**
> > > > > * drm_sched_rq_select_entity - Select an entity which provides a job to run
> > > > > *
> > > >
> > >
> >
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 05/28] drm/sched: Consolidate entity run queue management
2025-10-14 8:52 ` Philipp Stanner
@ 2025-10-14 10:04 ` Tvrtko Ursulin
2025-10-14 11:23 ` Philipp Stanner
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-14 10:04 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 14/10/2025 09:52, Philipp Stanner wrote:
> On Tue, 2025-10-14 at 08:26 +0100, Tvrtko Ursulin wrote:
>>
>> On 14/10/2025 07:53, Philipp Stanner wrote:
>>> On Sat, 2025-10-11 at 15:19 +0100, Tvrtko Ursulin wrote:
>>>>
>>>> On 10/10/2025 11:49, Philipp Stanner wrote:
>>>>> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>>>>>> Move the code dealing with entities entering and exiting run queues to
>>>>>> helpers to logically separate it from jobs entering and exiting entities.
>>>>>>
>>>>>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>>>>>> Cc: Christian König <christian.koenig@amd.com>
>>>>>> Cc: Danilo Krummrich <dakr@kernel.org>
>>>>>> Cc: Matthew Brost <matthew.brost@intel.com>
>>>>>> Cc: Philipp Stanner <phasta@kernel.org>
>>>>>> ---
>>>>>> drivers/gpu/drm/scheduler/sched_entity.c | 64 ++-------------
>>>>>> drivers/gpu/drm/scheduler/sched_internal.h | 8 +-
>>>>>> drivers/gpu/drm/scheduler/sched_main.c | 95 +++++++++++++++++++---
>>>>>> 3 files changed, 91 insertions(+), 76 deletions(-)
>>>>>>
>>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>>>>>> index 4852006f2308..7a0a52ba87bf 100644
>>>>>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>>>>>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>>>>>> @@ -456,24 +456,9 @@ drm_sched_job_dependency(struct drm_sched_job *job,
>>>>>> return NULL;
>>>>>> }
>>>>>>
>>>>>> -static ktime_t
>>>>>> -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
>>>>>> -{
>>>>>> - ktime_t ts;
>>>>>> -
>>>>>> - lockdep_assert_held(&entity->lock);
>>>>>> - lockdep_assert_held(&rq->lock);
>>>>>> -
>>>>>> - ts = ktime_add_ns(rq->rr_ts, 1);
>>>>>> - entity->rr_ts = ts;
>>>>>> - rq->rr_ts = ts;
>>>>>> -
>>>>>> - return ts;
>>>>>> -}
>>>>>> -
>>>>>> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>>>>>> {
>>>>>> - struct drm_sched_job *sched_job, *next_job;
>>>>>> + struct drm_sched_job *sched_job;
>>>>>
>>>>> `next_job` has been added in a previous job. Have you tried whether
>>>>> patch-order can be reversed?
>>>>>
>>>>> Just asking; I don't want to cause unnecessary work here
>>>>
>>>> You are correct that there would be some knock on effect on a few other
>>>> patches in the series but it is definitely doable. Because for certain
>>>> argument can be made it would be logical to have it like that. Both this
>>>> patch and "drm/sched: Move run queue related code into a separate file"
>>>> would be then moved ahead of "drm/sched: Implement RR via FIFO". If you
>>>> prefer it like that I can reshuffle no problem.
>>>
>>> I mean, it seems to make the overall git diff smaller, which is nice?
>>>
>>> If you don't see a significant reason against it, I'd say it's a good
>>> idea.
>>
>> Okay deal. It isn't anything significant, just re-ordering patches with
>> compile testing patches to ensure every step still builds.
Completed locally.
>>>>>>
>>>>>> sched_job = drm_sched_entity_queue_peek(entity);
>>>>>> if (!sched_job)
>>>>>> @@ -502,26 +487,7 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
>>>>>>
>>>>>> spsc_queue_pop(&entity->job_queue);
>>>>>>
>>>>>> - /*
>>>>>> - * Update the entity's location in the min heap according to
>>>>>> - * the timestamp of the next job, if any.
>>>>>> - */
>>>>>> - next_job = drm_sched_entity_queue_peek(entity);
>>>>>> - if (next_job) {
>>>>>> - struct drm_sched_rq *rq;
>>>>>> - ktime_t ts;
>>>>>> -
>>>>>> - spin_lock(&entity->lock);
>>>>>> - rq = entity->rq;
>>>>>> - spin_lock(&rq->lock);
>>>>>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>>>>>> - ts = next_job->submit_ts;
>>>>>> - else
>>>>>> - ts = drm_sched_rq_get_rr_ts(rq, entity);
>>>>>> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>>>>> - spin_unlock(&rq->lock);
>>>>>> - spin_unlock(&entity->lock);
>>>>>> - }
>>>>>> + drm_sched_rq_pop_entity(entity);
>>>>>>
>>>>>> /* Jobs and entities might have different lifecycles. Since we're
>>>>>> * removing the job from the entities queue, set the jobs entity pointer
>>>>>> @@ -611,30 +577,10 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
>>>>>> /* first job wakes up scheduler */
>>>>>> if (first) {
>>>>>> struct drm_gpu_scheduler *sched;
>>>>>> - struct drm_sched_rq *rq;
>>>>>>
>>>>>> - /* Add the entity to the run queue */
>>>>>> - spin_lock(&entity->lock);
>>>>>> - if (entity->stopped) {
>>>>>> - spin_unlock(&entity->lock);
>>>>>> -
>>>>>> - DRM_ERROR("Trying to push to a killed entity\n");
>>>>>> - return;
>>>>>> - }
>>>>>> -
>>>>>> - rq = entity->rq;
>>>>>> - sched = rq->sched;
>>>>>> -
>>>>>> - spin_lock(&rq->lock);
>>>>>> - drm_sched_rq_add_entity(rq, entity);
>>>>>> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>>>>>> - submit_ts = entity->rr_ts;
>>>>>> - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
>>>>>> -
>>>>>> - spin_unlock(&rq->lock);
>>>>>> - spin_unlock(&entity->lock);
>>>>>> -
>>>>>> - drm_sched_wakeup(sched);
>>>>>> + sched = drm_sched_rq_add_entity(entity, submit_ts);
>>>>>> + if (sched)
>>>>>> + drm_sched_wakeup(sched);
>>>>>> }
>>>>>> }
>>>>>> EXPORT_SYMBOL(drm_sched_entity_push_job);
>>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>>>>>> index 7ea5a6736f98..8269c5392a82 100644
>>>>>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>>>>>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>>>>>> @@ -12,13 +12,11 @@ extern int drm_sched_policy;
>>>>>>
>>>>>> void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
>>>>>>
>>>>>> -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
>>>>>> - struct drm_sched_entity *entity);
>>>>>> +struct drm_gpu_scheduler *
>>>>>> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
>>>>>> void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
>>>>>> struct drm_sched_entity *entity);
>>>>>> -
>>>>>> -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>>>> - struct drm_sched_rq *rq, ktime_t ts);
>>>>>> +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
>>>>>>
>>>>>> void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
>>>>>> struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
>>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>>>>>> index 8e62541b439a..e5d02c28665c 100644
>>>>>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>>>>>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>>>>>> @@ -151,9 +151,9 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>>>>>> }
>>>>>> }
>>>>>>
>>>>>> -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>>>> - struct drm_sched_rq *rq,
>>>>>> - ktime_t ts)
>>>>>> +static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>>>> + struct drm_sched_rq *rq,
>>>>>> + ktime_t ts)
>>>>>> {
>>>>>> /*
>>>>>> * Both locks need to be grabbed, one to protect from entity->rq change
>>>>>> @@ -191,22 +191,45 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
>>>>>> /**
>>>>>> * drm_sched_rq_add_entity - add an entity
>>>>>> *
>>>>>> - * @rq: scheduler run queue
>>>>>> * @entity: scheduler entity
>>>>>> + * @ts: submission timestamp
>>>>>> *
>>>>>> * Adds a scheduler entity to the run queue.
>>>>>> + *
>>>>>> + * Returns a DRM scheduler pre-selected to handle this entity.
>>>>>> */
>>>>>> -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
>>>>>> - struct drm_sched_entity *entity)
>>>>>> +struct drm_gpu_scheduler *
>>>>>> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
>>>>>> {
>>>>>
>>>>> I'm not sure if it's a good idea to have the scheduler returned from
>>>>> that function. That doesn't make a whole lot of sense semantically.
>>>>>
>>>>> At the very least the function's docstring, maybe even its name, should
>>>>> be adjusted to detail why this makes sense. The commit message, too.
>>>>> It's not trivially understood.
>>>>>
>>>>> I think I get why it's being done, but writing it down black on white
>>>>> gives us something to grasp.
>>>>>
>>>>> Sth like "adds an entity to a runqueue, selects to appropriate
>>>>> scheduler and returns it for the purpose of XYZ"
>>>>
>>>> Yeah. Remeber your unlocked rq access slide and the discussion around it?
>>>
>>> Sure. Is that related, though? The slide was about many readers being
>>> totally unlocked. The current drm_sched_entity_push_job() locks readers
>>> correctly if I'm not mistaken.
>>>
>>>>
>>>> Currently we have this:
>>>>
>>>> drm_sched_entity_push_job()
>>>> {
>>>> ...
>>>> spin_lock(&entity->lock);
>>>> ...
>>>> rq = entity->rq;
>>>> sched = rq->sched;
>>>> ...
>>>> spin_unlock(&rq->lock);
>>>> spin_unlock(&entity->lock);
>>>>
>>>> drm_sched_wakeup(sched);
>>>>
>>>> Ie. we know entity->rq and rq->sched are guaranteed to be stable and
>>>> present at this point because job is already in the queue and
>>>> drm_sched_entity_select_rq() guarantees that.
>>>>
>>>> In this patch I moved all this block into drm_sched_rq_add_entity() but
>>>> I wanted to leave drm_sched_wakeup() outside. Because I thought it is
>>>> not the job of the run queue handling, and semantically the logic was
>>>> "only once added to the entity we know the rq and scheduler for
>>>> certain". That would open the door for future improvements and late
>>>> rq/scheduler selection.
>>>>
>>>> But now I think it is premature and it would be better I simply move the
>>>> wakekup inside drm_sched_rq_add_entity() together with all the rest.
>>>>
>>>> Does that sound like a plan for now?
>>>
>>> Hmmm. What I'm wondering most about if it really is a good idea to have
>>> drm_sched_wakeup() in rq_add_entity().
>>>
>>> Do you think that makes semantically more sense than just reading:
>>>
>>> drm_sched_entity_push_job()
>>> {
>>> foo
>>> bar
>>> more_foo
>>>
>>> /* New job was added. Right time to wake up scheduler. */
>>> drm_sched_wakeup();
>>
>> Problem here always is you need a sched pointer so question is simply
>> how and where to get it.
>>
>>> I think both can make sense, but the above / current version seems to
>>> make more sense to me.
>>
>> Current as in this patch or current as in the upstream codebase?
>>
>> In all cases the knowledge it is safe to use sched after unlocking is
>> implicit.
>>
>> I see only two options:
>>
>> current)
>>
>> drm_sched_entity_push_job()
>> {
>> ...
>> spin_unlock(&rq->lock);
>> spin_unlock(&entity->lock);
>>
>> drm_sched_wakeup(sched);
>>
>> a)
>>
>> drm_sched_entity_push_job()
>> {
>> ...
>> sched = drm_sched_rq_add_entity(entity, submit_ts);
>> if (sched)
>> drm_sched_wakeup(sched);
>>
>> b)
>>
>> drm_sched_rq_add_entity()
>> {
>> ...
>> spin_unlock(&rq->lock);
>> spin_unlock(&entity->lock);
>>
>> drm_sched_wakeup(sched);
>>
>>
>> drm_sched_entity_push_job()
>> {
>> ...
>> drm_sched_rq_add_entity(entity, submit_ts);
>>
>>
>> b) is the same as today, a) perhaps a bit premature. Which do you prefer?
>
> Alright, I looked through everything now.
>
> The thing is just that I believe that it's a semantically confusing and
> unclean concept of having drm_sched_rq_add_entity() return a scheduler
> – except for when the entity is stopped. Then "there is no scheduler"
> actually means "there is a scheduler, but that entity is stopped"
>
> In an ideal world:
>
> a) drm_sched_entity_push_job() wakes up the scheduler (as in your code,
> and as in the current mainline code) and
>
> b) drm_sched_entity_push_job() is the one who checks whether the entity
> is stopped. rq_add_entity() should just, well, add an entity to a
> runqueue.
>
> Option b) then would need locks again and could race. So that's not so
> cool.
>
> Possible solutions I can see is:
>
> 1. Have drm_sched_rq_add_entity() return an ERR_PTR instead of NULL.
Maybe I am misunderstanding the idea, but what would be the benefit of
this option?
To clarify, I have:
drm_sched_rq_add_entity()
{
...
if (entity->stopped) {
...
return NULL;
drm_sched_entity_push_job()
{
...
sched = drm_sched_rq_add_entity(entity);
if (sched)
drm_sched_wakeup(sched);
And you propose:
drm_sched_rq_add_entity()
{
...
if (entity->stopped) {
...
return ERR_PTR(-ESOMETHING);
drm_sched_entity_push_job()
{
...
sched = drm_sched_rq_add_entity(entity);
if (!IS_ERR(sched))
drm_sched_wakeup(sched);
?
> 2. Rename rq_add_entity()
You mean to something signify it is also doing the wakeup? Or simply
drm_sched_rq_add_first_entity()?
> 3. Potentially leave it as is? I guess that doesn't work for your rq-
> simplification?
Leave drm_sched_wakeup in push job? Yeah that doesn't work for moving
the rq handling into own helpers.
> Option 1 would almost be my preference. What do you think?
Lets see if I understand the option 1. I am fine with that one as
described, and also with option 2.
Regards,
Tvrtko
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 05/28] drm/sched: Consolidate entity run queue management
2025-10-14 10:04 ` Tvrtko Ursulin
@ 2025-10-14 11:23 ` Philipp Stanner
0 siblings, 0 replies; 76+ messages in thread
From: Philipp Stanner @ 2025-10-14 11:23 UTC (permalink / raw)
To: Tvrtko Ursulin, phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On Tue, 2025-10-14 at 11:04 +0100, Tvrtko Ursulin wrote:
>
> On 14/10/2025 09:52, Philipp Stanner wrote:
> > On Tue, 2025-10-14 at 08:26 +0100, Tvrtko Ursulin wrote:
> > >
> > > On 14/10/2025 07:53, Philipp Stanner wrote:
> > > > On Sat, 2025-10-11 at 15:19 +0100, Tvrtko Ursulin wrote:
> > > > >
> > > > > On 10/10/2025 11:49, Philipp Stanner wrote:
> > > > > > On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> > > > > > > Move the code dealing with entities entering and exiting run queues to
> > > > > > > helpers to logically separate it from jobs entering and exiting entities.
> > > > > > >
> > > > > > > Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> > > > > > > Cc: Christian König <christian.koenig@amd.com>
> > > > > > > Cc: Danilo Krummrich <dakr@kernel.org>
> > > > > > > Cc: Matthew Brost <matthew.brost@intel.com>
> > > > > > > Cc: Philipp Stanner <phasta@kernel.org>
> > > > > > > ---
> > > > > > > drivers/gpu/drm/scheduler/sched_entity.c | 64 ++-------------
> > > > > > > drivers/gpu/drm/scheduler/sched_internal.h | 8 +-
> > > > > > > drivers/gpu/drm/scheduler/sched_main.c | 95 +++++++++++++++++++---
> > > > > > > 3 files changed, 91 insertions(+), 76 deletions(-)
> > > > > > >
> > > > > > > diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > > > index 4852006f2308..7a0a52ba87bf 100644
> > > > > > > --- a/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > > > +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > > > @@ -456,24 +456,9 @@ drm_sched_job_dependency(struct drm_sched_job *job,
> > > > > > > return NULL;
> > > > > > > }
> > > > > > >
> > > > > > > -static ktime_t
> > > > > > > -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> > > > > > > -{
> > > > > > > - ktime_t ts;
> > > > > > > -
> > > > > > > - lockdep_assert_held(&entity->lock);
> > > > > > > - lockdep_assert_held(&rq->lock);
> > > > > > > -
> > > > > > > - ts = ktime_add_ns(rq->rr_ts, 1);
> > > > > > > - entity->rr_ts = ts;
> > > > > > > - rq->rr_ts = ts;
> > > > > > > -
> > > > > > > - return ts;
> > > > > > > -}
> > > > > > > -
> > > > > > > struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> > > > > > > {
> > > > > > > - struct drm_sched_job *sched_job, *next_job;
> > > > > > > + struct drm_sched_job *sched_job;
> > > > > >
> > > > > > `next_job` has been added in a previous job. Have you tried whether
> > > > > > patch-order can be reversed?
> > > > > >
> > > > > > Just asking; I don't want to cause unnecessary work here
> > > > >
> > > > > You are correct that there would be some knock on effect on a few other
> > > > > patches in the series but it is definitely doable. Because for certain
> > > > > argument can be made it would be logical to have it like that. Both this
> > > > > patch and "drm/sched: Move run queue related code into a separate file"
> > > > > would be then moved ahead of "drm/sched: Implement RR via FIFO". If you
> > > > > prefer it like that I can reshuffle no problem.
> > > >
> > > > I mean, it seems to make the overall git diff smaller, which is nice?
> > > >
> > > > If you don't see a significant reason against it, I'd say it's a good
> > > > idea.
> > >
> > > Okay deal. It isn't anything significant, just re-ordering patches with
> > > compile testing patches to ensure every step still builds.
>
> Completed locally.
>
> > > > > > >
> > > > > > > sched_job = drm_sched_entity_queue_peek(entity);
> > > > > > > if (!sched_job)
> > > > > > > @@ -502,26 +487,7 @@ struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity)
> > > > > > >
> > > > > > > spsc_queue_pop(&entity->job_queue);
> > > > > > >
> > > > > > > - /*
> > > > > > > - * Update the entity's location in the min heap according to
> > > > > > > - * the timestamp of the next job, if any.
> > > > > > > - */
> > > > > > > - next_job = drm_sched_entity_queue_peek(entity);
> > > > > > > - if (next_job) {
> > > > > > > - struct drm_sched_rq *rq;
> > > > > > > - ktime_t ts;
> > > > > > > -
> > > > > > > - spin_lock(&entity->lock);
> > > > > > > - rq = entity->rq;
> > > > > > > - spin_lock(&rq->lock);
> > > > > > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > > > > > - ts = next_job->submit_ts;
> > > > > > > - else
> > > > > > > - ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > > > > > - drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > > > > > - spin_unlock(&rq->lock);
> > > > > > > - spin_unlock(&entity->lock);
> > > > > > > - }
> > > > > > > + drm_sched_rq_pop_entity(entity);
> > > > > > >
> > > > > > > /* Jobs and entities might have different lifecycles. Since we're
> > > > > > > * removing the job from the entities queue, set the jobs entity pointer
> > > > > > > @@ -611,30 +577,10 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
> > > > > > > /* first job wakes up scheduler */
> > > > > > > if (first) {
> > > > > > > struct drm_gpu_scheduler *sched;
> > > > > > > - struct drm_sched_rq *rq;
> > > > > > >
> > > > > > > - /* Add the entity to the run queue */
> > > > > > > - spin_lock(&entity->lock);
> > > > > > > - if (entity->stopped) {
> > > > > > > - spin_unlock(&entity->lock);
> > > > > > > -
> > > > > > > - DRM_ERROR("Trying to push to a killed entity\n");
> > > > > > > - return;
> > > > > > > - }
> > > > > > > -
> > > > > > > - rq = entity->rq;
> > > > > > > - sched = rq->sched;
> > > > > > > -
> > > > > > > - spin_lock(&rq->lock);
> > > > > > > - drm_sched_rq_add_entity(rq, entity);
> > > > > > > - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > > > > > - submit_ts = entity->rr_ts;
> > > > > > > - drm_sched_rq_update_fifo_locked(entity, rq, submit_ts);
> > > > > > > -
> > > > > > > - spin_unlock(&rq->lock);
> > > > > > > - spin_unlock(&entity->lock);
> > > > > > > -
> > > > > > > - drm_sched_wakeup(sched);
> > > > > > > + sched = drm_sched_rq_add_entity(entity, submit_ts);
> > > > > > > + if (sched)
> > > > > > > + drm_sched_wakeup(sched);
> > > > > > > }
> > > > > > > }
> > > > > > > EXPORT_SYMBOL(drm_sched_entity_push_job);
> > > > > > > diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > > > index 7ea5a6736f98..8269c5392a82 100644
> > > > > > > --- a/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > > > +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > > > @@ -12,13 +12,11 @@ extern int drm_sched_policy;
> > > > > > >
> > > > > > > void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
> > > > > > >
> > > > > > > -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
> > > > > > > - struct drm_sched_entity *entity);
> > > > > > > +struct drm_gpu_scheduler *
> > > > > > > +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
> > > > > > > void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> > > > > > > struct drm_sched_entity *entity);
> > > > > > > -
> > > > > > > -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > > > > > - struct drm_sched_rq *rq, ktime_t ts);
> > > > > > > +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
> > > > > > >
> > > > > > > void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
> > > > > > > struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
> > > > > > > diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> > > > > > > index 8e62541b439a..e5d02c28665c 100644
> > > > > > > --- a/drivers/gpu/drm/scheduler/sched_main.c
> > > > > > > +++ b/drivers/gpu/drm/scheduler/sched_main.c
> > > > > > > @@ -151,9 +151,9 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > > > > > }
> > > > > > > }
> > > > > > >
> > > > > > > -void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > > > > > - struct drm_sched_rq *rq,
> > > > > > > - ktime_t ts)
> > > > > > > +static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > > > > > + struct drm_sched_rq *rq,
> > > > > > > + ktime_t ts)
> > > > > > > {
> > > > > > > /*
> > > > > > > * Both locks need to be grabbed, one to protect from entity->rq change
> > > > > > > @@ -191,22 +191,45 @@ static void drm_sched_rq_init(struct drm_sched_rq *rq,
> > > > > > > /**
> > > > > > > * drm_sched_rq_add_entity - add an entity
> > > > > > > *
> > > > > > > - * @rq: scheduler run queue
> > > > > > > * @entity: scheduler entity
> > > > > > > + * @ts: submission timestamp
> > > > > > > *
> > > > > > > * Adds a scheduler entity to the run queue.
> > > > > > > + *
> > > > > > > + * Returns a DRM scheduler pre-selected to handle this entity.
> > > > > > > */
> > > > > > > -void drm_sched_rq_add_entity(struct drm_sched_rq *rq,
> > > > > > > - struct drm_sched_entity *entity)
> > > > > > > +struct drm_gpu_scheduler *
> > > > > > > +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> > > > > > > {
> > > > > >
> > > > > > I'm not sure if it's a good idea to have the scheduler returned from
> > > > > > that function. That doesn't make a whole lot of sense semantically.
> > > > > >
> > > > > > At the very least the function's docstring, maybe even its name, should
> > > > > > be adjusted to detail why this makes sense. The commit message, too.
> > > > > > It's not trivially understood.
> > > > > >
> > > > > > I think I get why it's being done, but writing it down black on white
> > > > > > gives us something to grasp.
> > > > > >
> > > > > > Sth like "adds an entity to a runqueue, selects to appropriate
> > > > > > scheduler and returns it for the purpose of XYZ"
> > > > >
> > > > > Yeah. Remeber your unlocked rq access slide and the discussion around it?
> > > >
> > > > Sure. Is that related, though? The slide was about many readers being
> > > > totally unlocked. The current drm_sched_entity_push_job() locks readers
> > > > correctly if I'm not mistaken.
> > > >
> > > > >
> > > > > Currently we have this:
> > > > >
> > > > > drm_sched_entity_push_job()
> > > > > {
> > > > > ...
> > > > > spin_lock(&entity->lock);
> > > > > ...
> > > > > rq = entity->rq;
> > > > > sched = rq->sched;
> > > > > ...
> > > > > spin_unlock(&rq->lock);
> > > > > spin_unlock(&entity->lock);
> > > > >
> > > > > drm_sched_wakeup(sched);
> > > > >
> > > > > Ie. we know entity->rq and rq->sched are guaranteed to be stable and
> > > > > present at this point because job is already in the queue and
> > > > > drm_sched_entity_select_rq() guarantees that.
> > > > >
> > > > > In this patch I moved all this block into drm_sched_rq_add_entity() but
> > > > > I wanted to leave drm_sched_wakeup() outside. Because I thought it is
> > > > > not the job of the run queue handling, and semantically the logic was
> > > > > "only once added to the entity we know the rq and scheduler for
> > > > > certain". That would open the door for future improvements and late
> > > > > rq/scheduler selection.
> > > > >
> > > > > But now I think it is premature and it would be better I simply move the
> > > > > wakekup inside drm_sched_rq_add_entity() together with all the rest.
> > > > >
> > > > > Does that sound like a plan for now?
> > > >
> > > > Hmmm. What I'm wondering most about if it really is a good idea to have
> > > > drm_sched_wakeup() in rq_add_entity().
> > > >
> > > > Do you think that makes semantically more sense than just reading:
> > > >
> > > > drm_sched_entity_push_job()
> > > > {
> > > > foo
> > > > bar
> > > > more_foo
> > > >
> > > > /* New job was added. Right time to wake up scheduler. */
> > > > drm_sched_wakeup();
> > >
> > > Problem here always is you need a sched pointer so question is simply
> > > how and where to get it.
> > >
> > > > I think both can make sense, but the above / current version seems to
> > > > make more sense to me.
> > >
> > > Current as in this patch or current as in the upstream codebase?
> > >
> > > In all cases the knowledge it is safe to use sched after unlocking is
> > > implicit.
> > >
> > > I see only two options:
> > >
> > > current)
> > >
> > > drm_sched_entity_push_job()
> > > {
> > > ...
> > > spin_unlock(&rq->lock);
> > > spin_unlock(&entity->lock);
> > >
> > > drm_sched_wakeup(sched);
> > >
> > > a)
> > >
> > > drm_sched_entity_push_job()
> > > {
> > > ...
> > > sched = drm_sched_rq_add_entity(entity, submit_ts);
> > > if (sched)
> > > drm_sched_wakeup(sched);
> > >
> > > b)
> > >
> > > drm_sched_rq_add_entity()
> > > {
> > > ...
> > > spin_unlock(&rq->lock);
> > > spin_unlock(&entity->lock);
> > >
> > > drm_sched_wakeup(sched);
> > >
> > >
> > > drm_sched_entity_push_job()
> > > {
> > > ...
> > > drm_sched_rq_add_entity(entity, submit_ts);
> > >
> > >
> > > b) is the same as today, a) perhaps a bit premature. Which do you prefer?
> >
> > Alright, I looked through everything now.
> >
> > The thing is just that I believe that it's a semantically confusing and
> > unclean concept of having drm_sched_rq_add_entity() return a scheduler
> > – except for when the entity is stopped. Then "there is no scheduler"
> > actually means "there is a scheduler, but that entity is stopped"
> >
> > In an ideal world:
> >
> > a) drm_sched_entity_push_job() wakes up the scheduler (as in your code,
> > and as in the current mainline code) and
> >
> > b) drm_sched_entity_push_job() is the one who checks whether the entity
> > is stopped. rq_add_entity() should just, well, add an entity to a
> > runqueue.
> >
> > Option b) then would need locks again and could race. So that's not so
> > cool.
> >
> > Possible solutions I can see is:
> >
> > 1. Have drm_sched_rq_add_entity() return an ERR_PTR instead of NULL.
>
> Maybe I am misunderstanding the idea, but what would be the benefit of
> this option?
>
> To clarify, I have:
>
> drm_sched_rq_add_entity()
> {
> ...
> if (entity->stopped) {
> ...
> return NULL;
>
> drm_sched_entity_push_job()
> {
> ...
> sched = drm_sched_rq_add_entity(entity);
> if (sched)
> drm_sched_wakeup(sched);
>
> And you propose:
>
> drm_sched_rq_add_entity()
> {
> ...
> if (entity->stopped) {
> ...
> return ERR_PTR(-ESOMETHING);
>
> drm_sched_entity_push_job()
> {
> ...
> sched = drm_sched_rq_add_entity(entity);
> if (!IS_ERR(sched))
> drm_sched_wakeup(sched);
>
>
> ?
Let's phrase it differently:
My issue is that
sched = func()
if (!sched) {
reads as "there is no scheduler". Whereas it should read as "there was
an error adding the entity".
How about this:
int drm_sched_entity_push_job(struct sched *scheddy)
{
if (stopped)
return -ENODEV; /* or other code, IDK */
*scheddy = XYZ;
…
ret = rq_add_entity(rq, entity, &sched)
if (ret == 0)
drm_sched_wakeup(sched);
Opinions? Matthew, Danilo, Christian?
:)
:(
P.
>
> > 2. Rename rq_add_entity()
>
> You mean to something signify it is also doing the wakeup? Or simply
> drm_sched_rq_add_first_entity()?
>
> > 3. Potentially leave it as is? I guess that doesn't work for your rq-
> > simplification?
>
> Leave drm_sched_wakeup in push job? Yeah that doesn't work for moving
> the rq handling into own helpers.
> > Option 1 would almost be my preference. What do you think?
>
> Lets see if I understand the option 1. I am fine with that one as
> described, and also with option 2.
>
> Regards,
>
> Tvrtko
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 06/28] drm/sched: Move run queue related code into a separate file
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (4 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 05/28] drm/sched: Consolidate entity run queue management Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 22:49 ` Matthew Brost
2025-10-08 8:53 ` [PATCH 07/28] drm/sched: Free all finished jobs at once Tvrtko Ursulin
` (22 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
Lets move all the code dealing with struct drm_sched_rq into a separate
compilation unit. Advantage being sched_main.c is left with a clearer set
of responsibilities.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/scheduler/Makefile | 2 +-
drivers/gpu/drm/scheduler/sched_internal.h | 7 +
drivers/gpu/drm/scheduler/sched_main.c | 218 +-------------------
drivers/gpu/drm/scheduler/sched_rq.c | 222 +++++++++++++++++++++
4 files changed, 232 insertions(+), 217 deletions(-)
create mode 100644 drivers/gpu/drm/scheduler/sched_rq.c
diff --git a/drivers/gpu/drm/scheduler/Makefile b/drivers/gpu/drm/scheduler/Makefile
index 6e13e4c63e9d..74e75eff6df5 100644
--- a/drivers/gpu/drm/scheduler/Makefile
+++ b/drivers/gpu/drm/scheduler/Makefile
@@ -20,7 +20,7 @@
# OTHER DEALINGS IN THE SOFTWARE.
#
#
-gpu-sched-y := sched_main.o sched_fence.o sched_entity.o
+gpu-sched-y := sched_main.o sched_fence.o sched_entity.o sched_rq.o
obj-$(CONFIG_DRM_SCHED) += gpu-sched.o
diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
index 8269c5392a82..5a8984e057e5 100644
--- a/drivers/gpu/drm/scheduler/sched_internal.h
+++ b/drivers/gpu/drm/scheduler/sched_internal.h
@@ -10,8 +10,15 @@ extern int drm_sched_policy;
#define DRM_SCHED_POLICY_RR 0
#define DRM_SCHED_POLICY_FIFO 1
+bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
+ struct drm_sched_entity *entity);
void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
+void drm_sched_rq_init(struct drm_sched_rq *rq,
+ struct drm_gpu_scheduler *sched);
+struct drm_sched_entity *
+drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
+ struct drm_sched_rq *rq);
struct drm_gpu_scheduler *
drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index e5d02c28665c..41bfee6b1777 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -112,8 +112,8 @@ static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
* Return true if we can push at least one more job from @entity, false
* otherwise.
*/
-static bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
- struct drm_sched_entity *entity)
+bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
+ struct drm_sched_entity *entity)
{
struct drm_sched_job *s_job;
@@ -133,220 +133,6 @@ static bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
return drm_sched_available_credits(sched) >= s_job->credits;
}
-static __always_inline bool drm_sched_entity_compare_before(struct rb_node *a,
- const struct rb_node *b)
-{
- struct drm_sched_entity *ent_a = rb_entry((a), struct drm_sched_entity, rb_tree_node);
- struct drm_sched_entity *ent_b = rb_entry((b), struct drm_sched_entity, rb_tree_node);
-
- return ktime_before(ent_a->oldest_job_waiting, ent_b->oldest_job_waiting);
-}
-
-static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
- struct drm_sched_rq *rq)
-{
- if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
- rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
- RB_CLEAR_NODE(&entity->rb_tree_node);
- }
-}
-
-static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
- struct drm_sched_rq *rq,
- ktime_t ts)
-{
- /*
- * Both locks need to be grabbed, one to protect from entity->rq change
- * for entity from within concurrent drm_sched_entity_select_rq and the
- * other to update the rb tree structure.
- */
- lockdep_assert_held(&entity->lock);
- lockdep_assert_held(&rq->lock);
-
- drm_sched_rq_remove_fifo_locked(entity, rq);
-
- entity->oldest_job_waiting = ts;
-
- rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
- drm_sched_entity_compare_before);
-}
-
-/**
- * drm_sched_rq_init - initialize a given run queue struct
- *
- * @rq: scheduler run queue
- * @sched: scheduler instance to associate with this run queue
- *
- * Initializes a scheduler runqueue.
- */
-static void drm_sched_rq_init(struct drm_sched_rq *rq,
- struct drm_gpu_scheduler *sched)
-{
- spin_lock_init(&rq->lock);
- INIT_LIST_HEAD(&rq->entities);
- rq->rb_tree_root = RB_ROOT_CACHED;
- rq->sched = sched;
-}
-
-/**
- * drm_sched_rq_add_entity - add an entity
- *
- * @entity: scheduler entity
- * @ts: submission timestamp
- *
- * Adds a scheduler entity to the run queue.
- *
- * Returns a DRM scheduler pre-selected to handle this entity.
- */
-struct drm_gpu_scheduler *
-drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
-{
- struct drm_gpu_scheduler *sched;
- struct drm_sched_rq *rq;
-
- /* Add the entity to the run queue */
- spin_lock(&entity->lock);
- if (entity->stopped) {
- spin_unlock(&entity->lock);
-
- DRM_ERROR("Trying to push to a killed entity\n");
- return NULL;
- }
-
- rq = entity->rq;
- spin_lock(&rq->lock);
- sched = rq->sched;
-
- if (list_empty(&entity->list)) {
- atomic_inc(sched->score);
- list_add_tail(&entity->list, &rq->entities);
- }
-
- if (drm_sched_policy == DRM_SCHED_POLICY_RR)
- ts = entity->rr_ts;
- drm_sched_rq_update_fifo_locked(entity, rq, ts);
-
- spin_unlock(&rq->lock);
- spin_unlock(&entity->lock);
-
- return sched;
-}
-
-/**
- * drm_sched_rq_remove_entity - remove an entity
- *
- * @rq: scheduler run queue
- * @entity: scheduler entity
- *
- * Removes a scheduler entity from the run queue.
- */
-void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
- struct drm_sched_entity *entity)
-{
- lockdep_assert_held(&entity->lock);
-
- if (list_empty(&entity->list))
- return;
-
- spin_lock(&rq->lock);
-
- atomic_dec(rq->sched->score);
- list_del_init(&entity->list);
-
- drm_sched_rq_remove_fifo_locked(entity, rq);
-
- spin_unlock(&rq->lock);
-}
-
-static ktime_t
-drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
-{
- ktime_t ts;
-
- lockdep_assert_held(&entity->lock);
- lockdep_assert_held(&rq->lock);
-
- ts = ktime_add_ns(rq->rr_ts, 1);
- entity->rr_ts = ts;
- rq->rr_ts = ts;
-
- return ts;
-}
-
-/**
- * drm_sched_rq_pop_entity - pops an entity
- *
- * @entity: scheduler entity
- *
- * To be called every time after a job is popped from the entity.
- */
-void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
-{
- struct drm_sched_job *next_job;
- struct drm_sched_rq *rq;
- ktime_t ts;
-
- /*
- * Update the entity's location in the min heap according to
- * the timestamp of the next job, if any.
- */
- next_job = drm_sched_entity_queue_peek(entity);
- if (!next_job)
- return;
-
- spin_lock(&entity->lock);
- rq = entity->rq;
- spin_lock(&rq->lock);
- if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
- ts = next_job->submit_ts;
- else
- ts = drm_sched_rq_get_rr_ts(rq, entity);
- drm_sched_rq_update_fifo_locked(entity, rq, ts);
- spin_unlock(&rq->lock);
- spin_unlock(&entity->lock);
-}
-
-/**
- * drm_sched_rq_select_entity - Select an entity which provides a job to run
- *
- * @sched: the gpu scheduler
- * @rq: scheduler run queue to check.
- *
- * Find oldest waiting ready entity.
- *
- * Return an entity if one is found; return an error-pointer (!NULL) if an
- * entity was ready, but the scheduler had insufficient credits to accommodate
- * its job; return NULL, if no ready entity was found.
- */
-static struct drm_sched_entity *
-drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
- struct drm_sched_rq *rq)
-{
- struct rb_node *rb;
-
- spin_lock(&rq->lock);
- for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
- struct drm_sched_entity *entity;
-
- entity = rb_entry(rb, struct drm_sched_entity, rb_tree_node);
- if (drm_sched_entity_is_ready(entity)) {
- /* If we can't queue yet, preserve the current entity in
- * terms of fairness.
- */
- if (!drm_sched_can_queue(sched, entity)) {
- spin_unlock(&rq->lock);
- return ERR_PTR(-ENOSPC);
- }
-
- reinit_completion(&entity->entity_idle);
- break;
- }
- }
- spin_unlock(&rq->lock);
-
- return rb ? rb_entry(rb, struct drm_sched_entity, rb_tree_node) : NULL;
-}
-
/**
* drm_sched_run_job_queue - enqueue run-job work
* @sched: scheduler instance
diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
new file mode 100644
index 000000000000..75cbca53b3d3
--- /dev/null
+++ b/drivers/gpu/drm/scheduler/sched_rq.c
@@ -0,0 +1,222 @@
+#include <linux/rbtree.h>
+
+#include <drm/drm_print.h>
+#include <drm/gpu_scheduler.h>
+
+#include "sched_internal.h"
+
+static __always_inline bool
+drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
+{
+ struct drm_sched_entity *ea =
+ rb_entry((a), struct drm_sched_entity, rb_tree_node);
+ struct drm_sched_entity *eb =
+ rb_entry((b), struct drm_sched_entity, rb_tree_node);
+
+ return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
+}
+
+static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
+ struct drm_sched_rq *rq)
+{
+ if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
+ rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
+ RB_CLEAR_NODE(&entity->rb_tree_node);
+ }
+}
+
+static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
+ struct drm_sched_rq *rq,
+ ktime_t ts)
+{
+ /*
+ * Both locks need to be grabbed, one to protect from entity->rq change
+ * for entity from within concurrent drm_sched_entity_select_rq and the
+ * other to update the rb tree structure.
+ */
+ lockdep_assert_held(&entity->lock);
+ lockdep_assert_held(&rq->lock);
+
+ drm_sched_rq_remove_fifo_locked(entity, rq);
+
+ entity->oldest_job_waiting = ts;
+
+ rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
+ drm_sched_entity_compare_before);
+}
+
+/**
+ * drm_sched_rq_init - initialize a given run queue struct
+ *
+ * @rq: scheduler run queue
+ * @sched: scheduler instance to associate with this run queue
+ *
+ * Initializes a scheduler runqueue.
+ */
+void drm_sched_rq_init(struct drm_sched_rq *rq,
+ struct drm_gpu_scheduler *sched)
+{
+ spin_lock_init(&rq->lock);
+ INIT_LIST_HEAD(&rq->entities);
+ rq->rb_tree_root = RB_ROOT_CACHED;
+ rq->sched = sched;
+}
+
+/**
+ * drm_sched_rq_add_entity - add an entity
+ *
+ * @entity: scheduler entity
+ * @ts: submission timestamp
+ *
+ * Adds a scheduler entity to the run queue.
+ *
+ * Returns a DRM scheduler pre-selected to handle this entity.
+ */
+struct drm_gpu_scheduler *
+drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
+{
+ struct drm_gpu_scheduler *sched;
+ struct drm_sched_rq *rq;
+
+ /* Add the entity to the run queue */
+ spin_lock(&entity->lock);
+ if (entity->stopped) {
+ spin_unlock(&entity->lock);
+
+ DRM_ERROR("Trying to push to a killed entity\n");
+ return NULL;
+ }
+
+ rq = entity->rq;
+ spin_lock(&rq->lock);
+ sched = rq->sched;
+
+ if (list_empty(&entity->list)) {
+ atomic_inc(sched->score);
+ list_add_tail(&entity->list, &rq->entities);
+ }
+
+ if (drm_sched_policy == DRM_SCHED_POLICY_RR)
+ ts = entity->rr_ts;
+ drm_sched_rq_update_fifo_locked(entity, rq, ts);
+
+ spin_unlock(&rq->lock);
+ spin_unlock(&entity->lock);
+
+ return sched;
+}
+
+/**
+ * drm_sched_rq_remove_entity - remove an entity
+ *
+ * @rq: scheduler run queue
+ * @entity: scheduler entity
+ *
+ * Removes a scheduler entity from the run queue.
+ */
+void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
+ struct drm_sched_entity *entity)
+{
+ lockdep_assert_held(&entity->lock);
+
+ if (list_empty(&entity->list))
+ return;
+
+ spin_lock(&rq->lock);
+
+ atomic_dec(rq->sched->score);
+ list_del_init(&entity->list);
+
+ drm_sched_rq_remove_fifo_locked(entity, rq);
+
+ spin_unlock(&rq->lock);
+}
+
+static ktime_t
+drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
+{
+ ktime_t ts;
+
+ lockdep_assert_held(&entity->lock);
+ lockdep_assert_held(&rq->lock);
+
+ ts = ktime_add_ns(rq->rr_ts, 1);
+ entity->rr_ts = ts;
+ rq->rr_ts = ts;
+
+ return ts;
+}
+
+/**
+ * drm_sched_rq_pop_entity - pops an entity
+ *
+ * @entity: scheduler entity
+ *
+ * To be called every time after a job is popped from the entity.
+ */
+void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
+{
+ struct drm_sched_job *next_job;
+ struct drm_sched_rq *rq;
+ ktime_t ts;
+
+ /*
+ * Update the entity's location in the min heap according to
+ * the timestamp of the next job, if any.
+ */
+ next_job = drm_sched_entity_queue_peek(entity);
+ if (!next_job)
+ return;
+
+ spin_lock(&entity->lock);
+ rq = entity->rq;
+ spin_lock(&rq->lock);
+ if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
+ ts = next_job->submit_ts;
+ else
+ ts = drm_sched_rq_get_rr_ts(rq, entity);
+ drm_sched_rq_update_fifo_locked(entity, rq, ts);
+ spin_unlock(&rq->lock);
+ spin_unlock(&entity->lock);
+}
+
+/**
+ * drm_sched_rq_select_entity - Select an entity which provides a job to run
+ *
+ * @sched: the gpu scheduler
+ * @rq: scheduler run queue to check.
+ *
+ * Find oldest waiting ready entity.
+ *
+ * Return an entity if one is found; return an error-pointer (!NULL) if an
+ * entity was ready, but the scheduler had insufficient credits to accommodate
+ * its job; return NULL, if no ready entity was found.
+ */
+struct drm_sched_entity *
+drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
+ struct drm_sched_rq *rq)
+{
+ struct rb_node *rb;
+
+ spin_lock(&rq->lock);
+ for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
+ struct drm_sched_entity *entity;
+
+ entity = rb_entry(rb, struct drm_sched_entity, rb_tree_node);
+ if (drm_sched_entity_is_ready(entity)) {
+ /* If we can't queue yet, preserve the current entity in
+ * terms of fairness.
+ */
+ if (!drm_sched_can_queue(sched, entity)) {
+ spin_unlock(&rq->lock);
+ return ERR_PTR(-ENOSPC);
+ }
+
+ reinit_completion(&entity->entity_idle);
+ break;
+ }
+ }
+ spin_unlock(&rq->lock);
+
+ return rb ? rb_entry(rb, struct drm_sched_entity, rb_tree_node) : NULL;
+}
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 06/28] drm/sched: Move run queue related code into a separate file
2025-10-08 8:53 ` [PATCH 06/28] drm/sched: Move run queue related code into a separate file Tvrtko Ursulin
@ 2025-10-08 22:49 ` Matthew Brost
0 siblings, 0 replies; 76+ messages in thread
From: Matthew Brost @ 2025-10-08 22:49 UTC (permalink / raw)
To: Tvrtko Ursulin
Cc: amd-gfx, dri-devel, kernel-dev, Christian König,
Danilo Krummrich, Philipp Stanner
On Wed, Oct 08, 2025 at 09:53:37AM +0100, Tvrtko Ursulin wrote:
> Lets move all the code dealing with struct drm_sched_rq into a separate
> compilation unit. Advantage being sched_main.c is left with a clearer set
> of responsibilities.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
Reviewed-by: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> ---
> drivers/gpu/drm/scheduler/Makefile | 2 +-
> drivers/gpu/drm/scheduler/sched_internal.h | 7 +
> drivers/gpu/drm/scheduler/sched_main.c | 218 +-------------------
> drivers/gpu/drm/scheduler/sched_rq.c | 222 +++++++++++++++++++++
> 4 files changed, 232 insertions(+), 217 deletions(-)
> create mode 100644 drivers/gpu/drm/scheduler/sched_rq.c
>
> diff --git a/drivers/gpu/drm/scheduler/Makefile b/drivers/gpu/drm/scheduler/Makefile
> index 6e13e4c63e9d..74e75eff6df5 100644
> --- a/drivers/gpu/drm/scheduler/Makefile
> +++ b/drivers/gpu/drm/scheduler/Makefile
> @@ -20,7 +20,7 @@
> # OTHER DEALINGS IN THE SOFTWARE.
> #
> #
> -gpu-sched-y := sched_main.o sched_fence.o sched_entity.o
> +gpu-sched-y := sched_main.o sched_fence.o sched_entity.o sched_rq.o
>
> obj-$(CONFIG_DRM_SCHED) += gpu-sched.o
>
> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> index 8269c5392a82..5a8984e057e5 100644
> --- a/drivers/gpu/drm/scheduler/sched_internal.h
> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> @@ -10,8 +10,15 @@ extern int drm_sched_policy;
> #define DRM_SCHED_POLICY_RR 0
> #define DRM_SCHED_POLICY_FIFO 1
>
> +bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> + struct drm_sched_entity *entity);
> void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
>
> +void drm_sched_rq_init(struct drm_sched_rq *rq,
> + struct drm_gpu_scheduler *sched);
> +struct drm_sched_entity *
> +drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
> + struct drm_sched_rq *rq);
> struct drm_gpu_scheduler *
> drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
> void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index e5d02c28665c..41bfee6b1777 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -112,8 +112,8 @@ static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
> * Return true if we can push at least one more job from @entity, false
> * otherwise.
> */
> -static bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> - struct drm_sched_entity *entity)
> +bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> + struct drm_sched_entity *entity)
> {
> struct drm_sched_job *s_job;
>
> @@ -133,220 +133,6 @@ static bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> return drm_sched_available_credits(sched) >= s_job->credits;
> }
>
> -static __always_inline bool drm_sched_entity_compare_before(struct rb_node *a,
> - const struct rb_node *b)
> -{
> - struct drm_sched_entity *ent_a = rb_entry((a), struct drm_sched_entity, rb_tree_node);
> - struct drm_sched_entity *ent_b = rb_entry((b), struct drm_sched_entity, rb_tree_node);
> -
> - return ktime_before(ent_a->oldest_job_waiting, ent_b->oldest_job_waiting);
> -}
> -
> -static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> - struct drm_sched_rq *rq)
> -{
> - if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
> - rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
> - RB_CLEAR_NODE(&entity->rb_tree_node);
> - }
> -}
> -
> -static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> - struct drm_sched_rq *rq,
> - ktime_t ts)
> -{
> - /*
> - * Both locks need to be grabbed, one to protect from entity->rq change
> - * for entity from within concurrent drm_sched_entity_select_rq and the
> - * other to update the rb tree structure.
> - */
> - lockdep_assert_held(&entity->lock);
> - lockdep_assert_held(&rq->lock);
> -
> - drm_sched_rq_remove_fifo_locked(entity, rq);
> -
> - entity->oldest_job_waiting = ts;
> -
> - rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
> - drm_sched_entity_compare_before);
> -}
> -
> -/**
> - * drm_sched_rq_init - initialize a given run queue struct
> - *
> - * @rq: scheduler run queue
> - * @sched: scheduler instance to associate with this run queue
> - *
> - * Initializes a scheduler runqueue.
> - */
> -static void drm_sched_rq_init(struct drm_sched_rq *rq,
> - struct drm_gpu_scheduler *sched)
> -{
> - spin_lock_init(&rq->lock);
> - INIT_LIST_HEAD(&rq->entities);
> - rq->rb_tree_root = RB_ROOT_CACHED;
> - rq->sched = sched;
> -}
> -
> -/**
> - * drm_sched_rq_add_entity - add an entity
> - *
> - * @entity: scheduler entity
> - * @ts: submission timestamp
> - *
> - * Adds a scheduler entity to the run queue.
> - *
> - * Returns a DRM scheduler pre-selected to handle this entity.
> - */
> -struct drm_gpu_scheduler *
> -drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> -{
> - struct drm_gpu_scheduler *sched;
> - struct drm_sched_rq *rq;
> -
> - /* Add the entity to the run queue */
> - spin_lock(&entity->lock);
> - if (entity->stopped) {
> - spin_unlock(&entity->lock);
> -
> - DRM_ERROR("Trying to push to a killed entity\n");
> - return NULL;
> - }
> -
> - rq = entity->rq;
> - spin_lock(&rq->lock);
> - sched = rq->sched;
> -
> - if (list_empty(&entity->list)) {
> - atomic_inc(sched->score);
> - list_add_tail(&entity->list, &rq->entities);
> - }
> -
> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> - ts = entity->rr_ts;
> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
> -
> - spin_unlock(&rq->lock);
> - spin_unlock(&entity->lock);
> -
> - return sched;
> -}
> -
> -/**
> - * drm_sched_rq_remove_entity - remove an entity
> - *
> - * @rq: scheduler run queue
> - * @entity: scheduler entity
> - *
> - * Removes a scheduler entity from the run queue.
> - */
> -void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> - struct drm_sched_entity *entity)
> -{
> - lockdep_assert_held(&entity->lock);
> -
> - if (list_empty(&entity->list))
> - return;
> -
> - spin_lock(&rq->lock);
> -
> - atomic_dec(rq->sched->score);
> - list_del_init(&entity->list);
> -
> - drm_sched_rq_remove_fifo_locked(entity, rq);
> -
> - spin_unlock(&rq->lock);
> -}
> -
> -static ktime_t
> -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> -{
> - ktime_t ts;
> -
> - lockdep_assert_held(&entity->lock);
> - lockdep_assert_held(&rq->lock);
> -
> - ts = ktime_add_ns(rq->rr_ts, 1);
> - entity->rr_ts = ts;
> - rq->rr_ts = ts;
> -
> - return ts;
> -}
> -
> -/**
> - * drm_sched_rq_pop_entity - pops an entity
> - *
> - * @entity: scheduler entity
> - *
> - * To be called every time after a job is popped from the entity.
> - */
> -void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> -{
> - struct drm_sched_job *next_job;
> - struct drm_sched_rq *rq;
> - ktime_t ts;
> -
> - /*
> - * Update the entity's location in the min heap according to
> - * the timestamp of the next job, if any.
> - */
> - next_job = drm_sched_entity_queue_peek(entity);
> - if (!next_job)
> - return;
> -
> - spin_lock(&entity->lock);
> - rq = entity->rq;
> - spin_lock(&rq->lock);
> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> - ts = next_job->submit_ts;
> - else
> - ts = drm_sched_rq_get_rr_ts(rq, entity);
> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
> - spin_unlock(&rq->lock);
> - spin_unlock(&entity->lock);
> -}
> -
> -/**
> - * drm_sched_rq_select_entity - Select an entity which provides a job to run
> - *
> - * @sched: the gpu scheduler
> - * @rq: scheduler run queue to check.
> - *
> - * Find oldest waiting ready entity.
> - *
> - * Return an entity if one is found; return an error-pointer (!NULL) if an
> - * entity was ready, but the scheduler had insufficient credits to accommodate
> - * its job; return NULL, if no ready entity was found.
> - */
> -static struct drm_sched_entity *
> -drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
> - struct drm_sched_rq *rq)
> -{
> - struct rb_node *rb;
> -
> - spin_lock(&rq->lock);
> - for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
> - struct drm_sched_entity *entity;
> -
> - entity = rb_entry(rb, struct drm_sched_entity, rb_tree_node);
> - if (drm_sched_entity_is_ready(entity)) {
> - /* If we can't queue yet, preserve the current entity in
> - * terms of fairness.
> - */
> - if (!drm_sched_can_queue(sched, entity)) {
> - spin_unlock(&rq->lock);
> - return ERR_PTR(-ENOSPC);
> - }
> -
> - reinit_completion(&entity->entity_idle);
> - break;
> - }
> - }
> - spin_unlock(&rq->lock);
> -
> - return rb ? rb_entry(rb, struct drm_sched_entity, rb_tree_node) : NULL;
> -}
> -
> /**
> * drm_sched_run_job_queue - enqueue run-job work
> * @sched: scheduler instance
> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
> new file mode 100644
> index 000000000000..75cbca53b3d3
> --- /dev/null
> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
> @@ -0,0 +1,222 @@
> +#include <linux/rbtree.h>
> +
> +#include <drm/drm_print.h>
> +#include <drm/gpu_scheduler.h>
> +
> +#include "sched_internal.h"
> +
> +static __always_inline bool
> +drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
> +{
> + struct drm_sched_entity *ea =
> + rb_entry((a), struct drm_sched_entity, rb_tree_node);
> + struct drm_sched_entity *eb =
> + rb_entry((b), struct drm_sched_entity, rb_tree_node);
> +
> + return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
> +}
> +
> +static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> + struct drm_sched_rq *rq)
> +{
> + if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
> + rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
> + RB_CLEAR_NODE(&entity->rb_tree_node);
> + }
> +}
> +
> +static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> + struct drm_sched_rq *rq,
> + ktime_t ts)
> +{
> + /*
> + * Both locks need to be grabbed, one to protect from entity->rq change
> + * for entity from within concurrent drm_sched_entity_select_rq and the
> + * other to update the rb tree structure.
> + */
> + lockdep_assert_held(&entity->lock);
> + lockdep_assert_held(&rq->lock);
> +
> + drm_sched_rq_remove_fifo_locked(entity, rq);
> +
> + entity->oldest_job_waiting = ts;
> +
> + rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
> + drm_sched_entity_compare_before);
> +}
> +
> +/**
> + * drm_sched_rq_init - initialize a given run queue struct
> + *
> + * @rq: scheduler run queue
> + * @sched: scheduler instance to associate with this run queue
> + *
> + * Initializes a scheduler runqueue.
> + */
> +void drm_sched_rq_init(struct drm_sched_rq *rq,
> + struct drm_gpu_scheduler *sched)
> +{
> + spin_lock_init(&rq->lock);
> + INIT_LIST_HEAD(&rq->entities);
> + rq->rb_tree_root = RB_ROOT_CACHED;
> + rq->sched = sched;
> +}
> +
> +/**
> + * drm_sched_rq_add_entity - add an entity
> + *
> + * @entity: scheduler entity
> + * @ts: submission timestamp
> + *
> + * Adds a scheduler entity to the run queue.
> + *
> + * Returns a DRM scheduler pre-selected to handle this entity.
> + */
> +struct drm_gpu_scheduler *
> +drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> +{
> + struct drm_gpu_scheduler *sched;
> + struct drm_sched_rq *rq;
> +
> + /* Add the entity to the run queue */
> + spin_lock(&entity->lock);
> + if (entity->stopped) {
> + spin_unlock(&entity->lock);
> +
> + DRM_ERROR("Trying to push to a killed entity\n");
> + return NULL;
> + }
> +
> + rq = entity->rq;
> + spin_lock(&rq->lock);
> + sched = rq->sched;
> +
> + if (list_empty(&entity->list)) {
> + atomic_inc(sched->score);
> + list_add_tail(&entity->list, &rq->entities);
> + }
> +
> + if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> + ts = entity->rr_ts;
> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> +
> + spin_unlock(&rq->lock);
> + spin_unlock(&entity->lock);
> +
> + return sched;
> +}
> +
> +/**
> + * drm_sched_rq_remove_entity - remove an entity
> + *
> + * @rq: scheduler run queue
> + * @entity: scheduler entity
> + *
> + * Removes a scheduler entity from the run queue.
> + */
> +void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> + struct drm_sched_entity *entity)
> +{
> + lockdep_assert_held(&entity->lock);
> +
> + if (list_empty(&entity->list))
> + return;
> +
> + spin_lock(&rq->lock);
> +
> + atomic_dec(rq->sched->score);
> + list_del_init(&entity->list);
> +
> + drm_sched_rq_remove_fifo_locked(entity, rq);
> +
> + spin_unlock(&rq->lock);
> +}
> +
> +static ktime_t
> +drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> +{
> + ktime_t ts;
> +
> + lockdep_assert_held(&entity->lock);
> + lockdep_assert_held(&rq->lock);
> +
> + ts = ktime_add_ns(rq->rr_ts, 1);
> + entity->rr_ts = ts;
> + rq->rr_ts = ts;
> +
> + return ts;
> +}
> +
> +/**
> + * drm_sched_rq_pop_entity - pops an entity
> + *
> + * @entity: scheduler entity
> + *
> + * To be called every time after a job is popped from the entity.
> + */
> +void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> +{
> + struct drm_sched_job *next_job;
> + struct drm_sched_rq *rq;
> + ktime_t ts;
> +
> + /*
> + * Update the entity's location in the min heap according to
> + * the timestamp of the next job, if any.
> + */
> + next_job = drm_sched_entity_queue_peek(entity);
> + if (!next_job)
> + return;
> +
> + spin_lock(&entity->lock);
> + rq = entity->rq;
> + spin_lock(&rq->lock);
> + if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> + ts = next_job->submit_ts;
> + else
> + ts = drm_sched_rq_get_rr_ts(rq, entity);
> + drm_sched_rq_update_fifo_locked(entity, rq, ts);
> + spin_unlock(&rq->lock);
> + spin_unlock(&entity->lock);
> +}
> +
> +/**
> + * drm_sched_rq_select_entity - Select an entity which provides a job to run
> + *
> + * @sched: the gpu scheduler
> + * @rq: scheduler run queue to check.
> + *
> + * Find oldest waiting ready entity.
> + *
> + * Return an entity if one is found; return an error-pointer (!NULL) if an
> + * entity was ready, but the scheduler had insufficient credits to accommodate
> + * its job; return NULL, if no ready entity was found.
> + */
> +struct drm_sched_entity *
> +drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
> + struct drm_sched_rq *rq)
> +{
> + struct rb_node *rb;
> +
> + spin_lock(&rq->lock);
> + for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
> + struct drm_sched_entity *entity;
> +
> + entity = rb_entry(rb, struct drm_sched_entity, rb_tree_node);
> + if (drm_sched_entity_is_ready(entity)) {
> + /* If we can't queue yet, preserve the current entity in
> + * terms of fairness.
> + */
> + if (!drm_sched_can_queue(sched, entity)) {
> + spin_unlock(&rq->lock);
> + return ERR_PTR(-ENOSPC);
> + }
> +
> + reinit_completion(&entity->entity_idle);
> + break;
> + }
> + }
> + spin_unlock(&rq->lock);
> +
> + return rb ? rb_entry(rb, struct drm_sched_entity, rb_tree_node) : NULL;
> +}
> --
> 2.48.0
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 07/28] drm/sched: Free all finished jobs at once
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (5 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 06/28] drm/sched: Move run queue related code into a separate file Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 22:48 ` Matthew Brost
2025-10-08 8:53 ` [PATCH 08/28] drm/sched: Account entity GPU time Tvrtko Ursulin
` (21 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
To implement fair scheduling we will need as accurate as possible view
into per entity GPU time utilisation. Because sched fence execution time
are only adjusted for accuracy in the free worker we need to process
completed jobs as soon as possible so the metric is most up to date when
view from the submission side of things.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/scheduler/sched_main.c | 13 ++-----------
1 file changed, 2 insertions(+), 11 deletions(-)
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 41bfee6b1777..41e076fdcb0d 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -906,7 +906,6 @@ drm_sched_select_entity(struct drm_gpu_scheduler *sched)
* drm_sched_get_finished_job - fetch the next finished job to be destroyed
*
* @sched: scheduler instance
- * @have_more: are there more finished jobs on the list
*
* Informs the caller through @have_more whether there are more finished jobs
* besides the returned one.
@@ -915,7 +914,7 @@ drm_sched_select_entity(struct drm_gpu_scheduler *sched)
* ready for it to be destroyed.
*/
static struct drm_sched_job *
-drm_sched_get_finished_job(struct drm_gpu_scheduler *sched, bool *have_more)
+drm_sched_get_finished_job(struct drm_gpu_scheduler *sched)
{
struct drm_sched_job *job, *next;
@@ -930,7 +929,6 @@ drm_sched_get_finished_job(struct drm_gpu_scheduler *sched, bool *have_more)
/* cancel this job's TO timer */
cancel_delayed_work(&sched->work_tdr);
- *have_more = false;
next = list_first_entry_or_null(&sched->pending_list,
typeof(*next), list);
if (next) {
@@ -940,8 +938,6 @@ drm_sched_get_finished_job(struct drm_gpu_scheduler *sched, bool *have_more)
next->s_fence->scheduled.timestamp =
dma_fence_timestamp(&job->s_fence->finished);
- *have_more = dma_fence_is_signaled(&next->s_fence->finished);
-
/* start TO timer for next job */
drm_sched_start_timeout(sched);
}
@@ -1000,14 +996,9 @@ static void drm_sched_free_job_work(struct work_struct *w)
struct drm_gpu_scheduler *sched =
container_of(w, struct drm_gpu_scheduler, work_free_job);
struct drm_sched_job *job;
- bool have_more;
- job = drm_sched_get_finished_job(sched, &have_more);
- if (job) {
+ while ((job = drm_sched_get_finished_job(sched)))
sched->ops->free_job(job);
- if (have_more)
- drm_sched_run_free_queue(sched);
- }
drm_sched_run_job_queue(sched);
}
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 07/28] drm/sched: Free all finished jobs at once
2025-10-08 8:53 ` [PATCH 07/28] drm/sched: Free all finished jobs at once Tvrtko Ursulin
@ 2025-10-08 22:48 ` Matthew Brost
0 siblings, 0 replies; 76+ messages in thread
From: Matthew Brost @ 2025-10-08 22:48 UTC (permalink / raw)
To: Tvrtko Ursulin
Cc: amd-gfx, dri-devel, kernel-dev, Christian König,
Danilo Krummrich, Philipp Stanner
On Wed, Oct 08, 2025 at 09:53:38AM +0100, Tvrtko Ursulin wrote:
> To implement fair scheduling we will need as accurate as possible view
> into per entity GPU time utilisation. Because sched fence execution time
> are only adjusted for accuracy in the free worker we need to process
> completed jobs as soon as possible so the metric is most up to date when
> view from the submission side of things.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
Reviewed-by: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> ---
> drivers/gpu/drm/scheduler/sched_main.c | 13 ++-----------
> 1 file changed, 2 insertions(+), 11 deletions(-)
>
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index 41bfee6b1777..41e076fdcb0d 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -906,7 +906,6 @@ drm_sched_select_entity(struct drm_gpu_scheduler *sched)
> * drm_sched_get_finished_job - fetch the next finished job to be destroyed
> *
> * @sched: scheduler instance
> - * @have_more: are there more finished jobs on the list
> *
> * Informs the caller through @have_more whether there are more finished jobs
> * besides the returned one.
> @@ -915,7 +914,7 @@ drm_sched_select_entity(struct drm_gpu_scheduler *sched)
> * ready for it to be destroyed.
> */
> static struct drm_sched_job *
> -drm_sched_get_finished_job(struct drm_gpu_scheduler *sched, bool *have_more)
> +drm_sched_get_finished_job(struct drm_gpu_scheduler *sched)
> {
> struct drm_sched_job *job, *next;
>
> @@ -930,7 +929,6 @@ drm_sched_get_finished_job(struct drm_gpu_scheduler *sched, bool *have_more)
> /* cancel this job's TO timer */
> cancel_delayed_work(&sched->work_tdr);
>
> - *have_more = false;
> next = list_first_entry_or_null(&sched->pending_list,
> typeof(*next), list);
> if (next) {
> @@ -940,8 +938,6 @@ drm_sched_get_finished_job(struct drm_gpu_scheduler *sched, bool *have_more)
> next->s_fence->scheduled.timestamp =
> dma_fence_timestamp(&job->s_fence->finished);
>
> - *have_more = dma_fence_is_signaled(&next->s_fence->finished);
> -
> /* start TO timer for next job */
> drm_sched_start_timeout(sched);
> }
> @@ -1000,14 +996,9 @@ static void drm_sched_free_job_work(struct work_struct *w)
> struct drm_gpu_scheduler *sched =
> container_of(w, struct drm_gpu_scheduler, work_free_job);
> struct drm_sched_job *job;
> - bool have_more;
>
> - job = drm_sched_get_finished_job(sched, &have_more);
> - if (job) {
> + while ((job = drm_sched_get_finished_job(sched)))
> sched->ops->free_job(job);
> - if (have_more)
> - drm_sched_run_free_queue(sched);
> - }
>
> drm_sched_run_job_queue(sched);
> }
> --
> 2.48.0
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 08/28] drm/sched: Account entity GPU time
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (6 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 07/28] drm/sched: Free all finished jobs at once Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 12:22 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 09/28] drm/sched: Remove idle entity from tree Tvrtko Ursulin
` (20 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
To implement fair scheduling we need a view into the GPU time consumed by
entities. Problem we have is that jobs and entities objects have decoupled
lifetimes, where at the point we have a view into accurate GPU time, we
cannot link back to the entity any longer.
Solve this by adding a light weight entity stats object which is reference
counted by both entity and the job and hence can safely be used from
either side.
With that, the only other thing we need is to add a helper for adding the
job's GPU time into the respective entity stats object, and call it once
the accurate GPU time has been calculated.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/scheduler/sched_entity.c | 39 ++++++++++++
drivers/gpu/drm/scheduler/sched_internal.h | 71 ++++++++++++++++++++++
drivers/gpu/drm/scheduler/sched_main.c | 6 +-
include/drm/gpu_scheduler.h | 12 ++++
4 files changed, 127 insertions(+), 1 deletion(-)
diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
index 7a0a52ba87bf..04ce8b7d436b 100644
--- a/drivers/gpu/drm/scheduler/sched_entity.c
+++ b/drivers/gpu/drm/scheduler/sched_entity.c
@@ -32,6 +32,39 @@
#include "gpu_scheduler_trace.h"
+
+/**
+ * drm_sched_entity_stats_release - Entity stats kref release function
+ *
+ * @kref: Entity stats embedded kref pointer
+ */
+void drm_sched_entity_stats_release(struct kref *kref)
+{
+ struct drm_sched_entity_stats *stats =
+ container_of(kref, typeof(*stats), kref);
+
+ kfree(stats);
+}
+
+/**
+ * drm_sched_entity_stats_alloc - Allocate a new struct drm_sched_entity_stats object
+ *
+ * Returns: Pointer to newly allocated struct drm_sched_entity_stats object.
+ */
+static struct drm_sched_entity_stats *drm_sched_entity_stats_alloc(void)
+{
+ struct drm_sched_entity_stats *stats;
+
+ stats = kzalloc(sizeof(*stats), GFP_KERNEL);
+ if (!stats)
+ return NULL;
+
+ kref_init(&stats->kref);
+ spin_lock_init(&stats->lock);
+
+ return stats;
+}
+
/**
* drm_sched_entity_init - Init a context entity used by scheduler when
* submit to HW ring.
@@ -65,6 +98,11 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
return -EINVAL;
memset(entity, 0, sizeof(struct drm_sched_entity));
+
+ entity->stats = drm_sched_entity_stats_alloc();
+ if (!entity->stats)
+ return -ENOMEM;
+
INIT_LIST_HEAD(&entity->list);
entity->rq = NULL;
entity->guilty = guilty;
@@ -338,6 +376,7 @@ void drm_sched_entity_fini(struct drm_sched_entity *entity)
dma_fence_put(rcu_dereference_check(entity->last_scheduled, true));
RCU_INIT_POINTER(entity->last_scheduled, NULL);
+ drm_sched_entity_stats_put(entity->stats);
}
EXPORT_SYMBOL(drm_sched_entity_fini);
diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
index 5a8984e057e5..1132a771aa37 100644
--- a/drivers/gpu/drm/scheduler/sched_internal.h
+++ b/drivers/gpu/drm/scheduler/sched_internal.h
@@ -3,6 +3,27 @@
#ifndef _DRM_GPU_SCHEDULER_INTERNAL_H_
#define _DRM_GPU_SCHEDULER_INTERNAL_H_
+#include <linux/ktime.h>
+#include <linux/kref.h>
+#include <linux/spinlock.h>
+
+/**
+ * struct drm_sched_entity_stats - execution stats for an entity.
+ *
+ * Because jobs and entities have decoupled lifetimes, ie. we cannot access the
+ * entity once the job is completed and we know how much time it took on the
+ * GPU, we need to track these stats in a separate object which is then
+ * reference counted by both entities and jobs.
+ *
+ * @kref: reference count for the object.
+ * @lock: lock guarding the @runtime updates.
+ * @runtime: time entity spent on the GPU.
+ */
+struct drm_sched_entity_stats {
+ struct kref kref;
+ spinlock_t lock;
+ ktime_t runtime;
+};
/* Used to choose between FIFO and RR job-scheduling */
extern int drm_sched_policy;
@@ -93,4 +114,54 @@ drm_sched_entity_is_ready(struct drm_sched_entity *entity)
return true;
}
+void drm_sched_entity_stats_release(struct kref *kref);
+
+/**
+ * drm_sched_entity_stats_get - Obtain a reference count on struct drm_sched_entity_stats object
+ *
+ * @stats: struct drm_sched_entity_stats pointer
+ *
+ * Returns: struct drm_sched_entity_stats pointer
+ */
+static inline struct drm_sched_entity_stats *
+drm_sched_entity_stats_get(struct drm_sched_entity_stats *stats)
+{
+ kref_get(&stats->kref);
+
+ return stats;
+}
+
+/**
+ * drm_sched_entity_stats_put - Release a reference count on struct drm_sched_entity_stats object
+ *
+ * @stats: struct drm_sched_entity_stats pointer
+ */
+static inline void
+drm_sched_entity_stats_put(struct drm_sched_entity_stats *stats)
+{
+ kref_put(&stats->kref, drm_sched_entity_stats_release);
+}
+
+/**
+ * drm_sched_entity_stats_job_add_gpu_time - Account job execution time to entity
+ *
+ * @job: Scheduler job to account.
+ *
+ * Accounts the execution time of @job to its respective entity stats object.
+ */
+static inline void
+drm_sched_entity_stats_job_add_gpu_time(struct drm_sched_job *job)
+{
+ struct drm_sched_entity_stats *stats = job->entity_stats;
+ struct drm_sched_fence *s_fence = job->s_fence;
+ ktime_t start, end;
+
+ start = dma_fence_timestamp(&s_fence->scheduled);
+ end = dma_fence_timestamp(&s_fence->finished);
+
+ spin_lock(&stats->lock);
+ stats->runtime = ktime_add(stats->runtime, ktime_sub(end, start));
+ spin_unlock(&stats->lock);
+}
+
#endif
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 41e076fdcb0d..f180d292bf66 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -658,6 +658,7 @@ void drm_sched_job_arm(struct drm_sched_job *job)
job->sched = sched;
job->s_priority = entity->priority;
+ job->entity_stats = drm_sched_entity_stats_get(entity->stats);
drm_sched_fence_init(job->s_fence, job->entity);
}
@@ -846,6 +847,7 @@ void drm_sched_job_cleanup(struct drm_sched_job *job)
* been called.
*/
dma_fence_put(&job->s_fence->finished);
+ drm_sched_entity_stats_put(job->entity_stats);
} else {
/* The job was aborted before it has been committed to be run;
* notably, drm_sched_job_arm() has not been called.
@@ -997,8 +999,10 @@ static void drm_sched_free_job_work(struct work_struct *w)
container_of(w, struct drm_gpu_scheduler, work_free_job);
struct drm_sched_job *job;
- while ((job = drm_sched_get_finished_job(sched)))
+ while ((job = drm_sched_get_finished_job(sched))) {
+ drm_sched_entity_stats_job_add_gpu_time(job);
sched->ops->free_job(job);
+ }
drm_sched_run_job_queue(sched);
}
diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
index 8992393ed200..93d0b7224a57 100644
--- a/include/drm/gpu_scheduler.h
+++ b/include/drm/gpu_scheduler.h
@@ -71,6 +71,8 @@ enum drm_sched_priority {
DRM_SCHED_PRIORITY_COUNT
};
+struct drm_sched_entity_stats;
+
/**
* struct drm_sched_entity - A wrapper around a job queue (typically
* attached to the DRM file_priv).
@@ -110,6 +112,11 @@ struct drm_sched_entity {
*/
struct drm_sched_rq *rq;
+ /**
+ * @stats: Stats object reference held by the entity and jobs.
+ */
+ struct drm_sched_entity_stats *stats;
+
/**
* @sched_list:
*
@@ -365,6 +372,11 @@ struct drm_sched_job {
struct drm_sched_fence *s_fence;
struct drm_sched_entity *entity;
+ /**
+ * @entity_stats: Stats object reference held by the job and entity.
+ */
+ struct drm_sched_entity_stats *entity_stats;
+
enum drm_sched_priority s_priority;
u32 credits;
/** @last_dependency: tracks @dependencies as they signal */
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 08/28] drm/sched: Account entity GPU time
2025-10-08 8:53 ` [PATCH 08/28] drm/sched: Account entity GPU time Tvrtko Ursulin
@ 2025-10-10 12:22 ` Philipp Stanner
2025-10-11 14:56 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 12:22 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> To implement fair scheduling we need a view into the GPU time consumed by
> entities. Problem we have is that jobs and entities objects have decoupled
> lifetimes, where at the point we have a view into accurate GPU time, we
> cannot link back to the entity any longer.
>
> Solve this by adding a light weight entity stats object which is reference
> counted by both entity and the job and hence can safely be used from
> either side.
>
> With that, the only other thing we need is to add a helper for adding the
> job's GPU time into the respective entity stats object, and call it once
> the accurate GPU time has been calculated.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> ---
> drivers/gpu/drm/scheduler/sched_entity.c | 39 ++++++++++++
> drivers/gpu/drm/scheduler/sched_internal.h | 71 ++++++++++++++++++++++
> drivers/gpu/drm/scheduler/sched_main.c | 6 +-
> include/drm/gpu_scheduler.h | 12 ++++
> 4 files changed, 127 insertions(+), 1 deletion(-)
>
> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> index 7a0a52ba87bf..04ce8b7d436b 100644
> --- a/drivers/gpu/drm/scheduler/sched_entity.c
> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> @@ -32,6 +32,39 @@
>
> #include "gpu_scheduler_trace.h"
>
> +
> +/**
> + * drm_sched_entity_stats_release - Entity stats kref release function
> + *
> + * @kref: Entity stats embedded kref pointer
We've got fractured docstring style throughout drm_sched. What I'd like
us to move to is no empty lines between first line and first parameter
for the function docstrings.
Applies to all the other functions, too.
> + */
> +void drm_sched_entity_stats_release(struct kref *kref)
> +{
> + struct drm_sched_entity_stats *stats =
> + container_of(kref, typeof(*stats), kref);
> +
> + kfree(stats);
> +}
> +
> +/**
> + * drm_sched_entity_stats_alloc - Allocate a new struct drm_sched_entity_stats object
> + *
> + * Returns: Pointer to newly allocated struct drm_sched_entity_stats object.
s/Returns/Return
That's at least how it's documented in the official docstring docu, and
we have fractured style here, too. Unifying that mid-term will be good.
> + */
> +static struct drm_sched_entity_stats *drm_sched_entity_stats_alloc(void)
> +{
> + struct drm_sched_entity_stats *stats;
> +
> + stats = kzalloc(sizeof(*stats), GFP_KERNEL);
> + if (!stats)
> + return NULL;
> +
> + kref_init(&stats->kref);
> + spin_lock_init(&stats->lock);
> +
> + return stats;
> +}
> +
> /**
> * drm_sched_entity_init - Init a context entity used by scheduler when
> * submit to HW ring.
> @@ -65,6 +98,11 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> return -EINVAL;
>
> memset(entity, 0, sizeof(struct drm_sched_entity));
> +
> + entity->stats = drm_sched_entity_stats_alloc();
> + if (!entity->stats)
> + return -ENOMEM;
> +
> INIT_LIST_HEAD(&entity->list);
> entity->rq = NULL;
> entity->guilty = guilty;
> @@ -338,6 +376,7 @@ void drm_sched_entity_fini(struct drm_sched_entity *entity)
>
> dma_fence_put(rcu_dereference_check(entity->last_scheduled, true));
> RCU_INIT_POINTER(entity->last_scheduled, NULL);
> + drm_sched_entity_stats_put(entity->stats);
> }
> EXPORT_SYMBOL(drm_sched_entity_fini);
>
> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> index 5a8984e057e5..1132a771aa37 100644
> --- a/drivers/gpu/drm/scheduler/sched_internal.h
> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> @@ -3,6 +3,27 @@
> #ifndef _DRM_GPU_SCHEDULER_INTERNAL_H_
> #define _DRM_GPU_SCHEDULER_INTERNAL_H_
>
> +#include <linux/ktime.h>
> +#include <linux/kref.h>
> +#include <linux/spinlock.h>
> +
> +/**
> + * struct drm_sched_entity_stats - execution stats for an entity.
> + *
> + * Because jobs and entities have decoupled lifetimes, ie. we cannot access the
> + * entity once the job is completed and we know how much time it took on the
> + * GPU, we need to track these stats in a separate object which is then
> + * reference counted by both entities and jobs.
> + *
> + * @kref: reference count for the object.
> + * @lock: lock guarding the @runtime updates.
> + * @runtime: time entity spent on the GPU.
Same here, let's follow the official style
https://docs.kernel.org/doc-guide/kernel-doc.html#members
> + */
> +struct drm_sched_entity_stats {
> + struct kref kref;
> + spinlock_t lock;
> + ktime_t runtime;
> +};
>
> /* Used to choose between FIFO and RR job-scheduling */
> extern int drm_sched_policy;
> @@ -93,4 +114,54 @@ drm_sched_entity_is_ready(struct drm_sched_entity *entity)
> return true;
> }
>
> +void drm_sched_entity_stats_release(struct kref *kref);
> +
> +/**
> + * drm_sched_entity_stats_get - Obtain a reference count on struct drm_sched_entity_stats object
If you want to cross-link it you need a '&struct'
> + *
> + * @stats: struct drm_sched_entity_stats pointer
> + *
> + * Returns: struct drm_sched_entity_stats pointer
> + */
> +static inline struct drm_sched_entity_stats *
> +drm_sched_entity_stats_get(struct drm_sched_entity_stats *stats)
> +{
> + kref_get(&stats->kref);
> +
> + return stats;
> +}
> +
> +/**
> + * drm_sched_entity_stats_put - Release a reference count on struct drm_sched_entity_stats object
Same
> + *
> + * @stats: struct drm_sched_entity_stats pointer
> + */
> +static inline void
> +drm_sched_entity_stats_put(struct drm_sched_entity_stats *stats)
> +{
> + kref_put(&stats->kref, drm_sched_entity_stats_release);
> +}
> +
> +/**
> + * drm_sched_entity_stats_job_add_gpu_time - Account job execution time to entity
> + *
> + * @job: Scheduler job to account.
> + *
> + * Accounts the execution time of @job to its respective entity stats object.
> + */
> +static inline void
> +drm_sched_entity_stats_job_add_gpu_time(struct drm_sched_job *job)
> +{
> + struct drm_sched_entity_stats *stats = job->entity_stats;
> + struct drm_sched_fence *s_fence = job->s_fence;
> + ktime_t start, end;
> +
> + start = dma_fence_timestamp(&s_fence->scheduled);
> + end = dma_fence_timestamp(&s_fence->finished);
> +
> + spin_lock(&stats->lock);
> + stats->runtime = ktime_add(stats->runtime, ktime_sub(end, start));
> + spin_unlock(&stats->lock);
> +}
> +
> #endif
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index 41e076fdcb0d..f180d292bf66 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -658,6 +658,7 @@ void drm_sched_job_arm(struct drm_sched_job *job)
>
> job->sched = sched;
> job->s_priority = entity->priority;
> + job->entity_stats = drm_sched_entity_stats_get(entity->stats);
>
> drm_sched_fence_init(job->s_fence, job->entity);
> }
> @@ -846,6 +847,7 @@ void drm_sched_job_cleanup(struct drm_sched_job *job)
> * been called.
> */
> dma_fence_put(&job->s_fence->finished);
> + drm_sched_entity_stats_put(job->entity_stats);
Maybe you want to comment on this patch here:
https://lore.kernel.org/dri-devel/20250926123630.200920-2-phasta@kernel.org/
I submitted it becausue of this change you make here.
> } else {
> /* The job was aborted before it has been committed to be run;
> * notably, drm_sched_job_arm() has not been called.
> @@ -997,8 +999,10 @@ static void drm_sched_free_job_work(struct work_struct *w)
> container_of(w, struct drm_gpu_scheduler, work_free_job);
> struct drm_sched_job *job;
>
> - while ((job = drm_sched_get_finished_job(sched)))
> + while ((job = drm_sched_get_finished_job(sched))) {
> + drm_sched_entity_stats_job_add_gpu_time(job);
> sched->ops->free_job(job);
> + }
>
> drm_sched_run_job_queue(sched);
> }
> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> index 8992393ed200..93d0b7224a57 100644
> --- a/include/drm/gpu_scheduler.h
> +++ b/include/drm/gpu_scheduler.h
> @@ -71,6 +71,8 @@ enum drm_sched_priority {
> DRM_SCHED_PRIORITY_COUNT
> };
>
> +struct drm_sched_entity_stats;
> +
> /**
> * struct drm_sched_entity - A wrapper around a job queue (typically
> * attached to the DRM file_priv).
> @@ -110,6 +112,11 @@ struct drm_sched_entity {
> */
> struct drm_sched_rq *rq;
>
> + /**
> + * @stats: Stats object reference held by the entity and jobs.
> + */
> + struct drm_sched_entity_stats *stats;
> +
> /**
> * @sched_list:
> *
> @@ -365,6 +372,11 @@ struct drm_sched_job {
> struct drm_sched_fence *s_fence;
> struct drm_sched_entity *entity;
>
> + /**
> + * @entity_stats: Stats object reference held by the job and entity.
> + */
> + struct drm_sched_entity_stats *entity_stats;
> +
> enum drm_sched_priority s_priority;
> u32 credits;
> /** @last_dependency: tracks @dependencies as they signal */
Code itself looks correct and very nice and clean to me.
P.
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 08/28] drm/sched: Account entity GPU time
2025-10-10 12:22 ` Philipp Stanner
@ 2025-10-11 14:56 ` Tvrtko Ursulin
0 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-11 14:56 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 10/10/2025 13:22, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> To implement fair scheduling we need a view into the GPU time consumed by
>> entities. Problem we have is that jobs and entities objects have decoupled
>> lifetimes, where at the point we have a view into accurate GPU time, we
>> cannot link back to the entity any longer.
>>
>> Solve this by adding a light weight entity stats object which is reference
>> counted by both entity and the job and hence can safely be used from
>> either side.
>>
>> With that, the only other thing we need is to add a helper for adding the
>> job's GPU time into the respective entity stats object, and call it once
>> the accurate GPU time has been calculated.
>>
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> ---
>> drivers/gpu/drm/scheduler/sched_entity.c | 39 ++++++++++++
>> drivers/gpu/drm/scheduler/sched_internal.h | 71 ++++++++++++++++++++++
>> drivers/gpu/drm/scheduler/sched_main.c | 6 +-
>> include/drm/gpu_scheduler.h | 12 ++++
>> 4 files changed, 127 insertions(+), 1 deletion(-)
>>
>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>> index 7a0a52ba87bf..04ce8b7d436b 100644
>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>> @@ -32,6 +32,39 @@
>>
>> #include "gpu_scheduler_trace.h"
>>
>> +
>> +/**
>> + * drm_sched_entity_stats_release - Entity stats kref release function
>> + *
>> + * @kref: Entity stats embedded kref pointer
>
> We've got fractured docstring style throughout drm_sched. What I'd like
> us to move to is no empty lines between first line and first parameter
> for the function docstrings.
>
> Applies to all the other functions, too.
Done here and throughout the series.
>> + */
>> +void drm_sched_entity_stats_release(struct kref *kref)
>> +{
>> + struct drm_sched_entity_stats *stats =
>> + container_of(kref, typeof(*stats), kref);
>> +
>> + kfree(stats);
>> +}
>> +
>> +/**
>> + * drm_sched_entity_stats_alloc - Allocate a new struct drm_sched_entity_stats object
>> + *
>> + * Returns: Pointer to newly allocated struct drm_sched_entity_stats object.
>
> s/Returns/Return
>
> That's at least how it's documented in the official docstring docu, and
> we have fractured style here, too. Unifying that mid-term will be good.
Ditto.
>> + */
>> +static struct drm_sched_entity_stats *drm_sched_entity_stats_alloc(void)
>> +{
>> + struct drm_sched_entity_stats *stats;
>> +
>> + stats = kzalloc(sizeof(*stats), GFP_KERNEL);
>> + if (!stats)
>> + return NULL;
>> +
>> + kref_init(&stats->kref);
>> + spin_lock_init(&stats->lock);
>> +
>> + return stats;
>> +}
>> +
>> /**
>> * drm_sched_entity_init - Init a context entity used by scheduler when
>> * submit to HW ring.
>> @@ -65,6 +98,11 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>> return -EINVAL;
>>
>> memset(entity, 0, sizeof(struct drm_sched_entity));
>> +
>> + entity->stats = drm_sched_entity_stats_alloc();
>> + if (!entity->stats)
>> + return -ENOMEM;
>> +
>> INIT_LIST_HEAD(&entity->list);
>> entity->rq = NULL;
>> entity->guilty = guilty;
>> @@ -338,6 +376,7 @@ void drm_sched_entity_fini(struct drm_sched_entity *entity)
>>
>> dma_fence_put(rcu_dereference_check(entity->last_scheduled, true));
>> RCU_INIT_POINTER(entity->last_scheduled, NULL);
>> + drm_sched_entity_stats_put(entity->stats);
>> }
>> EXPORT_SYMBOL(drm_sched_entity_fini);
>>
>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>> index 5a8984e057e5..1132a771aa37 100644
>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>> @@ -3,6 +3,27 @@
>> #ifndef _DRM_GPU_SCHEDULER_INTERNAL_H_
>> #define _DRM_GPU_SCHEDULER_INTERNAL_H_
>>
>> +#include <linux/ktime.h>
>> +#include <linux/kref.h>
>> +#include <linux/spinlock.h>
>> +
>> +/**
>> + * struct drm_sched_entity_stats - execution stats for an entity.
>> + *
>> + * Because jobs and entities have decoupled lifetimes, ie. we cannot access the
>> + * entity once the job is completed and we know how much time it took on the
>> + * GPU, we need to track these stats in a separate object which is then
>> + * reference counted by both entities and jobs.
>> + *
>> + * @kref: reference count for the object.
>> + * @lock: lock guarding the @runtime updates.
>> + * @runtime: time entity spent on the GPU.
>
> Same here, let's follow the official style
>
> https://docs.kernel.org/doc-guide/kernel-doc.html#members
Yep.
>
>
>> + */
>> +struct drm_sched_entity_stats {
>> + struct kref kref;
>> + spinlock_t lock;
>> + ktime_t runtime;
>> +};
>>
>> /* Used to choose between FIFO and RR job-scheduling */
>> extern int drm_sched_policy;
>> @@ -93,4 +114,54 @@ drm_sched_entity_is_ready(struct drm_sched_entity *entity)
>> return true;
>> }
>>
>> +void drm_sched_entity_stats_release(struct kref *kref);
>> +
>> +/**
>> + * drm_sched_entity_stats_get - Obtain a reference count on struct drm_sched_entity_stats object
>
> If you want to cross-link it you need a '&struct'
Done.
>
>> + *
>> + * @stats: struct drm_sched_entity_stats pointer
>> + *
>> + * Returns: struct drm_sched_entity_stats pointer
>> + */
>> +static inline struct drm_sched_entity_stats *
>> +drm_sched_entity_stats_get(struct drm_sched_entity_stats *stats)
>> +{
>> + kref_get(&stats->kref);
>> +
>> + return stats;
>> +}
>> +
>> +/**
>> + * drm_sched_entity_stats_put - Release a reference count on struct drm_sched_entity_stats object
>
> Same
>
>> + *
>> + * @stats: struct drm_sched_entity_stats pointer
>> + */
>> +static inline void
>> +drm_sched_entity_stats_put(struct drm_sched_entity_stats *stats)
>> +{
>> + kref_put(&stats->kref, drm_sched_entity_stats_release);
>> +}
>> +
>> +/**
>> + * drm_sched_entity_stats_job_add_gpu_time - Account job execution time to entity
>> + *
>> + * @job: Scheduler job to account.
>> + *
>> + * Accounts the execution time of @job to its respective entity stats object.
>> + */
>> +static inline void
>> +drm_sched_entity_stats_job_add_gpu_time(struct drm_sched_job *job)
>> +{
>> + struct drm_sched_entity_stats *stats = job->entity_stats;
>> + struct drm_sched_fence *s_fence = job->s_fence;
>> + ktime_t start, end;
>> +
>> + start = dma_fence_timestamp(&s_fence->scheduled);
>> + end = dma_fence_timestamp(&s_fence->finished);
>> +
>> + spin_lock(&stats->lock);
>> + stats->runtime = ktime_add(stats->runtime, ktime_sub(end, start));
>> + spin_unlock(&stats->lock);
>> +}
>> +
>> #endif
>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>> index 41e076fdcb0d..f180d292bf66 100644
>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>> @@ -658,6 +658,7 @@ void drm_sched_job_arm(struct drm_sched_job *job)
>>
>> job->sched = sched;
>> job->s_priority = entity->priority;
>> + job->entity_stats = drm_sched_entity_stats_get(entity->stats);
>>
>> drm_sched_fence_init(job->s_fence, job->entity);
>> }
>> @@ -846,6 +847,7 @@ void drm_sched_job_cleanup(struct drm_sched_job *job)
>> * been called.
>> */
>> dma_fence_put(&job->s_fence->finished);
>> + drm_sched_entity_stats_put(job->entity_stats);
>
> Maybe you want to comment on this patch here:
>
> https://lore.kernel.org/dri-devel/20250926123630.200920-2-phasta@kernel.org/
>
> I submitted it becausue of this change you make here.
I see there was some discussion. I'll try to form an opinion and reply
next week but feel free to ping me if I forget.
Regards,
Tvrtko
>
>
>> } else {
>> /* The job was aborted before it has been committed to be run;
>> * notably, drm_sched_job_arm() has not been called.
>> @@ -997,8 +999,10 @@ static void drm_sched_free_job_work(struct work_struct *w)
>> container_of(w, struct drm_gpu_scheduler, work_free_job);
>> struct drm_sched_job *job;
>>
>> - while ((job = drm_sched_get_finished_job(sched)))
>> + while ((job = drm_sched_get_finished_job(sched))) {
>> + drm_sched_entity_stats_job_add_gpu_time(job);
>> sched->ops->free_job(job);
>> + }
>>
>> drm_sched_run_job_queue(sched);
>> }
>> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
>> index 8992393ed200..93d0b7224a57 100644
>> --- a/include/drm/gpu_scheduler.h
>> +++ b/include/drm/gpu_scheduler.h
>> @@ -71,6 +71,8 @@ enum drm_sched_priority {
>> DRM_SCHED_PRIORITY_COUNT
>> };
>>
>> +struct drm_sched_entity_stats;
>> +
>> /**
>> * struct drm_sched_entity - A wrapper around a job queue (typically
>> * attached to the DRM file_priv).
>> @@ -110,6 +112,11 @@ struct drm_sched_entity {
>> */
>> struct drm_sched_rq *rq;
>>
>> + /**
>> + * @stats: Stats object reference held by the entity and jobs.
>> + */
>> + struct drm_sched_entity_stats *stats;
>> +
>> /**
>> * @sched_list:
>> *
>> @@ -365,6 +372,11 @@ struct drm_sched_job {
>> struct drm_sched_fence *s_fence;
>> struct drm_sched_entity *entity;
>>
>> + /**
>> + * @entity_stats: Stats object reference held by the job and entity.
>> + */
>> + struct drm_sched_entity_stats *entity_stats;
>> +
>> enum drm_sched_priority s_priority;
>> u32 credits;
>> /** @last_dependency: tracks @dependencies as they signal */
>
>
> Code itself looks correct and very nice and clean to me.
>
> P.
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 09/28] drm/sched: Remove idle entity from tree
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (7 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 08/28] drm/sched: Account entity GPU time Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 10/28] drm/sched: Add fair scheduling policy Tvrtko Ursulin
` (19 subsequent siblings)
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
There is no need to keep entities with no jobs in the tree so lets remove
it once the last job is consumed. This keeps the tree smaller which is
nicer and more efficient as entities are removed and re-added on every
popped job.
Apart from that, the upcoming fair scheduling algorithm will rely on the
tree only containing runnable entities.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/scheduler/sched_rq.c | 28 +++++++++++++++++-----------
1 file changed, 17 insertions(+), 11 deletions(-)
diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
index 75cbca53b3d3..09d316bc3dfa 100644
--- a/drivers/gpu/drm/scheduler/sched_rq.c
+++ b/drivers/gpu/drm/scheduler/sched_rq.c
@@ -19,6 +19,9 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
struct drm_sched_rq *rq)
{
+ lockdep_assert_held(&entity->lock);
+ lockdep_assert_held(&rq->lock);
+
if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
RB_CLEAR_NODE(&entity->rb_tree_node);
@@ -158,24 +161,27 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
{
struct drm_sched_job *next_job;
struct drm_sched_rq *rq;
- ktime_t ts;
/*
* Update the entity's location in the min heap according to
* the timestamp of the next job, if any.
*/
+ spin_lock(&entity->lock);
+ rq = entity->rq;
+ spin_lock(&rq->lock);
next_job = drm_sched_entity_queue_peek(entity);
- if (!next_job)
- return;
+ if (next_job) {
+ ktime_t ts;
- spin_lock(&entity->lock);
- rq = entity->rq;
- spin_lock(&rq->lock);
- if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
- ts = next_job->submit_ts;
- else
- ts = drm_sched_rq_get_rr_ts(rq, entity);
- drm_sched_rq_update_fifo_locked(entity, rq, ts);
+ if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
+ ts = next_job->submit_ts;
+ else
+ ts = drm_sched_rq_get_rr_ts(rq, entity);
+
+ drm_sched_rq_update_fifo_locked(entity, rq, ts);
+ } else {
+ drm_sched_rq_remove_fifo_locked(entity, rq);
+ }
spin_unlock(&rq->lock);
spin_unlock(&entity->lock);
}
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (8 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 09/28] drm/sched: Remove idle entity from tree Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-14 10:27 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 11/28] drm/sched: Favour interactive clients slightly Tvrtko Ursulin
` (18 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner,
Pierre-Eric Pelloux-Prayer
Fair scheduling policy is built upon the same concepts as the well known
CFS kernel scheduler - entity run queue is sorted by the virtual GPU time
consumed by entities in a way that the entity with least vruntime runs
first.
It is able to avoid total priority starvation, which is one of the
problems with FIFO, and it also does not need for per priority run queues.
As it scales the actual GPU runtime by an exponential factor as the
priority decreases, therefore the virtual runtime for low priority
entities grows faster than for normal priority, pushing them further down
the runqueue order for the same real GPU time spent.
Apart from this fundamental fairness, fair policy is especially strong in
oversubscription workloads where it is able to give more GPU time to short
and bursty workloads when they are running in parallel with GPU heavy
clients submitting deep job queues.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
---
drivers/gpu/drm/scheduler/sched_entity.c | 28 ++--
drivers/gpu/drm/scheduler/sched_internal.h | 9 +-
drivers/gpu/drm/scheduler/sched_main.c | 12 +-
drivers/gpu/drm/scheduler/sched_rq.c | 147 ++++++++++++++++++++-
include/drm/gpu_scheduler.h | 16 ++-
5 files changed, 191 insertions(+), 21 deletions(-)
diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
index 04ce8b7d436b..58f51875547a 100644
--- a/drivers/gpu/drm/scheduler/sched_entity.c
+++ b/drivers/gpu/drm/scheduler/sched_entity.c
@@ -108,6 +108,8 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
entity->guilty = guilty;
entity->num_sched_list = num_sched_list;
entity->priority = priority;
+ entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
+ DRM_SCHED_PRIORITY_KERNEL : priority;
/*
* It's perfectly valid to initialize an entity without having a valid
* scheduler attached. It's just not valid to use the scheduler before it
@@ -124,17 +126,23 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
*/
pr_warn("%s: called with uninitialized scheduler\n", __func__);
} else if (num_sched_list) {
- /* The "priority" of an entity cannot exceed the number of run-queues of a
- * scheduler. Protect against num_rqs being 0, by converting to signed. Choose
- * the lowest priority available.
+ enum drm_sched_priority p = entity->priority;
+
+ /*
+ * The "priority" of an entity cannot exceed the number of
+ * run-queues of a scheduler. Protect against num_rqs being 0,
+ * by converting to signed. Choose the lowest priority
+ * available.
*/
- if (entity->priority >= sched_list[0]->num_rqs) {
- dev_err(sched_list[0]->dev, "entity has out-of-bounds priority: %u. num_rqs: %u\n",
- entity->priority, sched_list[0]->num_rqs);
- entity->priority = max_t(s32, (s32) sched_list[0]->num_rqs - 1,
- (s32) DRM_SCHED_PRIORITY_KERNEL);
+ if (p >= sched_list[0]->num_user_rqs) {
+ dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
+ p, sched_list[0]->num_user_rqs);
+ p = max_t(s32,
+ (s32)sched_list[0]->num_user_rqs - 1,
+ (s32)DRM_SCHED_PRIORITY_KERNEL);
+ entity->priority = p;
}
- entity->rq = sched_list[0]->sched_rq[entity->priority];
+ entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
}
init_completion(&entity->entity_idle);
@@ -567,7 +575,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
spin_lock(&entity->lock);
sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
- rq = sched ? sched->sched_rq[entity->priority] : NULL;
+ rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
if (rq != entity->rq) {
drm_sched_rq_remove_entity(entity->rq, entity);
entity->rq = rq;
diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
index 1132a771aa37..c94e38acc6f2 100644
--- a/drivers/gpu/drm/scheduler/sched_internal.h
+++ b/drivers/gpu/drm/scheduler/sched_internal.h
@@ -18,18 +18,23 @@
* @kref: reference count for the object.
* @lock: lock guarding the @runtime updates.
* @runtime: time entity spent on the GPU.
+ * @prev_runtime: previous @runtime used to get the runtime delta
+ * @vruntime: virtual runtime as accumulated by the fair algorithm
*/
struct drm_sched_entity_stats {
struct kref kref;
spinlock_t lock;
ktime_t runtime;
+ ktime_t prev_runtime;
+ u64 vruntime;
};
/* Used to choose between FIFO and RR job-scheduling */
extern int drm_sched_policy;
-#define DRM_SCHED_POLICY_RR 0
-#define DRM_SCHED_POLICY_FIFO 1
+#define DRM_SCHED_POLICY_RR 0
+#define DRM_SCHED_POLICY_FIFO 1
+#define DRM_SCHED_POLICY_FAIR 2
bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
struct drm_sched_entity *entity);
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index f180d292bf66..8d8f9c8411f5 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -90,7 +90,7 @@ int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
* DOC: sched_policy (int)
* Used to override default entities scheduling policy in a run queue.
*/
-MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO (default).");
+MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
module_param_named(sched_policy, drm_sched_policy, int, 0444);
static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
@@ -1132,11 +1132,15 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
sched->own_submit_wq = true;
}
- sched->sched_rq = kmalloc_array(args->num_rqs, sizeof(*sched->sched_rq),
+ sched->num_user_rqs = args->num_rqs;
+ sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
+ args->num_rqs : 1;
+ sched->sched_rq = kmalloc_array(sched->num_rqs,
+ sizeof(*sched->sched_rq),
GFP_KERNEL | __GFP_ZERO);
if (!sched->sched_rq)
goto Out_check_own;
- sched->num_rqs = args->num_rqs;
+
for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
if (!sched->sched_rq[i])
@@ -1278,7 +1282,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
atomic_inc(&bad->karma);
- for (i = DRM_SCHED_PRIORITY_HIGH; i < sched->num_rqs; i++) {
+ for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
struct drm_sched_rq *rq = sched->sched_rq[i];
spin_lock(&rq->lock);
diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
index 09d316bc3dfa..b868c794cc9d 100644
--- a/drivers/gpu/drm/scheduler/sched_rq.c
+++ b/drivers/gpu/drm/scheduler/sched_rq.c
@@ -16,6 +16,24 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
}
+static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
+{
+ enum drm_sched_priority prio = -1;
+ struct rb_node *rb;
+
+ lockdep_assert_held(&rq->lock);
+
+ rb = rb_first_cached(&rq->rb_tree_root);
+ if (rb) {
+ struct drm_sched_entity *entity =
+ rb_entry(rb, typeof(*entity), rb_tree_node);
+
+ prio = entity->priority; /* Unlocked read */
+ }
+
+ rq->head_prio = prio;
+}
+
static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
struct drm_sched_rq *rq)
{
@@ -25,6 +43,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
RB_CLEAR_NODE(&entity->rb_tree_node);
+ drm_sched_rq_update_prio(rq);
}
}
@@ -46,6 +65,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
drm_sched_entity_compare_before);
+ drm_sched_rq_update_prio(rq);
}
/**
@@ -63,6 +83,114 @@ void drm_sched_rq_init(struct drm_sched_rq *rq,
INIT_LIST_HEAD(&rq->entities);
rq->rb_tree_root = RB_ROOT_CACHED;
rq->sched = sched;
+ rq->head_prio = -1;
+}
+
+static ktime_t
+drm_sched_rq_get_min_vruntime(struct drm_sched_rq *rq)
+{
+ struct drm_sched_entity *entity;
+ struct rb_node *rb;
+
+ lockdep_assert_held(&rq->lock);
+
+ for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
+ entity = rb_entry(rb, typeof(*entity), rb_tree_node);
+
+ return entity->stats->vruntime; /* Unlocked read */
+ }
+
+ return 0;
+}
+
+static void
+drm_sched_entity_save_vruntime(struct drm_sched_entity *entity,
+ ktime_t min_vruntime)
+{
+ struct drm_sched_entity_stats *stats = entity->stats;
+ ktime_t vruntime;
+
+ spin_lock(&stats->lock);
+ vruntime = stats->vruntime;
+ if (min_vruntime && vruntime > min_vruntime)
+ vruntime = ktime_sub(vruntime, min_vruntime);
+ else
+ vruntime = 0;
+ stats->vruntime = vruntime;
+ spin_unlock(&stats->lock);
+}
+
+static ktime_t
+drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
+ ktime_t min_vruntime,
+ enum drm_sched_priority rq_prio)
+{
+ struct drm_sched_entity_stats *stats = entity->stats;
+ enum drm_sched_priority prio = entity->priority;
+ ktime_t vruntime;
+
+ BUILD_BUG_ON(DRM_SCHED_PRIORITY_NORMAL < DRM_SCHED_PRIORITY_HIGH);
+
+ spin_lock(&stats->lock);
+ vruntime = stats->vruntime;
+
+ /*
+ * Special handling for entities which were picked from the top of the
+ * queue and are now re-joining the top with another one already there.
+ */
+ if (!vruntime && min_vruntime) {
+ if (prio > rq_prio) {
+ /*
+ * Lower priority should not overtake higher when re-
+ * joining at the top of the queue.
+ */
+ vruntime = us_to_ktime(prio - rq_prio);
+ } else if (prio < rq_prio) {
+ /*
+ * Higher priority can go first.
+ */
+ vruntime = -us_to_ktime(rq_prio - prio);
+ }
+ }
+
+ /*
+ * Restore saved relative position in the queue.
+ */
+ vruntime = ktime_add(min_vruntime, vruntime);
+
+ stats->vruntime = vruntime;
+ spin_unlock(&stats->lock);
+
+ return vruntime;
+}
+
+static ktime_t drm_sched_entity_update_vruntime(struct drm_sched_entity *entity)
+{
+ static const unsigned int shift[] = {
+ [DRM_SCHED_PRIORITY_KERNEL] = 1,
+ [DRM_SCHED_PRIORITY_HIGH] = 2,
+ [DRM_SCHED_PRIORITY_NORMAL] = 4,
+ [DRM_SCHED_PRIORITY_LOW] = 7,
+ };
+ struct drm_sched_entity_stats *stats = entity->stats;
+ ktime_t runtime, prev;
+
+ spin_lock(&stats->lock);
+ prev = stats->prev_runtime;
+ runtime = stats->runtime;
+ stats->prev_runtime = runtime;
+ runtime = ktime_add_ns(stats->vruntime,
+ ktime_to_ns(ktime_sub(runtime, prev)) <<
+ shift[entity->priority]);
+ stats->vruntime = runtime;
+ spin_unlock(&stats->lock);
+
+ return runtime;
+}
+
+static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
+{
+ return drm_sched_entity_update_vruntime(entity);
}
/**
@@ -99,8 +227,14 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
list_add_tail(&entity->list, &rq->entities);
}
- if (drm_sched_policy == DRM_SCHED_POLICY_RR)
+ if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
+ ts = drm_sched_rq_get_min_vruntime(rq);
+ ts = drm_sched_entity_restore_vruntime(entity, ts,
+ rq->head_prio);
+ } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
ts = entity->rr_ts;
+ }
+
drm_sched_rq_update_fifo_locked(entity, rq, ts);
spin_unlock(&rq->lock);
@@ -173,7 +307,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
if (next_job) {
ktime_t ts;
- if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
+ if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
+ ts = drm_sched_entity_get_job_ts(entity);
+ else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
ts = next_job->submit_ts;
else
ts = drm_sched_rq_get_rr_ts(rq, entity);
@@ -181,6 +317,13 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
drm_sched_rq_update_fifo_locked(entity, rq, ts);
} else {
drm_sched_rq_remove_fifo_locked(entity, rq);
+
+ if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
+ ktime_t min_vruntime;
+
+ min_vruntime = drm_sched_rq_get_min_vruntime(rq);
+ drm_sched_entity_save_vruntime(entity, min_vruntime);
+ }
}
spin_unlock(&rq->lock);
spin_unlock(&entity->lock);
diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
index 93d0b7224a57..bc25508a6ff6 100644
--- a/include/drm/gpu_scheduler.h
+++ b/include/drm/gpu_scheduler.h
@@ -150,6 +150,11 @@ struct drm_sched_entity {
*/
enum drm_sched_priority priority;
+ /**
+ * @rq_priority: Run-queue priority
+ */
+ enum drm_sched_priority rq_priority;
+
/**
* @rr_ts:
*
@@ -254,10 +259,11 @@ struct drm_sched_entity {
* struct drm_sched_rq - queue of entities to be scheduled.
*
* @sched: the scheduler to which this rq belongs to.
- * @lock: protects @entities, @rb_tree_root and @rr_ts.
+ * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
* @rr_ts: monotonically incrementing fake timestamp for RR mode
* @entities: list of the entities to be scheduled.
* @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
+ * @head_prio: priority of the top tree element
*
* Run queue is a set of entities scheduling command submissions for
* one specific ring. It implements the scheduling policy that selects
@@ -271,6 +277,7 @@ struct drm_sched_rq {
ktime_t rr_ts;
struct list_head entities;
struct rb_root_cached rb_tree_root;
+ enum drm_sched_priority head_prio;
};
/**
@@ -563,8 +570,10 @@ struct drm_sched_backend_ops {
* @credit_count: the current credit count of this scheduler
* @timeout: the time after which a job is removed from the scheduler.
* @name: name of the ring for which this scheduler is being used.
- * @num_rqs: Number of run-queues. This is at most DRM_SCHED_PRIORITY_COUNT,
- * as there's usually one run-queue per priority, but could be less.
+ * @num_user_rqs: Number of run-queues. This is at most
+ * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
+ * priority, but could be less.
+ * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
* @sched_rq: An allocated array of run-queues of size @num_rqs;
* @job_scheduled: once drm_sched_entity_flush() is called the scheduler
* waits on this wait queue until all the scheduled jobs are
@@ -597,6 +606,7 @@ struct drm_gpu_scheduler {
long timeout;
const char *name;
u32 num_rqs;
+ u32 num_user_rqs;
struct drm_sched_rq **sched_rq;
wait_queue_head_t job_scheduled;
atomic64_t job_id_count;
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-08 8:53 ` [PATCH 10/28] drm/sched: Add fair scheduling policy Tvrtko Ursulin
@ 2025-10-14 10:27 ` Philipp Stanner
2025-10-14 12:56 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-14 10:27 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner, Pierre-Eric Pelloux-Prayer
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> Fair scheduling policy is built upon the same concepts as the well known
nit: "The fair …"
Or maybe better: call it FAIR, being congruent with the FIFO below.
> CFS kernel scheduler - entity run queue is sorted by the virtual GPU time
nit: Call it "CPU scheduler". The GPU scheduler is a kernel scheduler,
too.
> consumed by entities in a way that the entity with least vruntime runs
> first.
>
> It is able to avoid total priority starvation, which is one of the
> problems with FIFO, and it also does not need for per priority run queues.
> As it scales the actual GPU runtime by an exponential factor as the
> priority decreases, therefore the virtual runtime for low priority
"therefore," is not necessary because of the sentence starting with
"As"
> entities grows faster than for normal priority, pushing them further down
> the runqueue order for the same real GPU time spent.
>
> Apart from this fundamental fairness, fair policy is especially strong in
> oversubscription workloads where it is able to give more GPU time to short
> and bursty workloads when they are running in parallel with GPU heavy
> clients submitting deep job queues.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
> ---
> drivers/gpu/drm/scheduler/sched_entity.c | 28 ++--
> drivers/gpu/drm/scheduler/sched_internal.h | 9 +-
> drivers/gpu/drm/scheduler/sched_main.c | 12 +-
> drivers/gpu/drm/scheduler/sched_rq.c | 147 ++++++++++++++++++++-
> include/drm/gpu_scheduler.h | 16 ++-
> 5 files changed, 191 insertions(+), 21 deletions(-)
>
> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> index 04ce8b7d436b..58f51875547a 100644
> --- a/drivers/gpu/drm/scheduler/sched_entity.c
> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> @@ -108,6 +108,8 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> entity->guilty = guilty;
> entity->num_sched_list = num_sched_list;
> entity->priority = priority;
> + entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
> + DRM_SCHED_PRIORITY_KERNEL : priority;
> /*
> * It's perfectly valid to initialize an entity without having a valid
> * scheduler attached. It's just not valid to use the scheduler before it
> @@ -124,17 +126,23 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> */
> pr_warn("%s: called with uninitialized scheduler\n", __func__);
> } else if (num_sched_list) {
> - /* The "priority" of an entity cannot exceed the number of run-queues of a
> - * scheduler. Protect against num_rqs being 0, by converting to signed. Choose
> - * the lowest priority available.
> + enum drm_sched_priority p = entity->priority;
> +
> + /*
> + * The "priority" of an entity cannot exceed the number of
> + * run-queues of a scheduler. Protect against num_rqs being 0,
> + * by converting to signed. Choose the lowest priority
> + * available.
> */
> - if (entity->priority >= sched_list[0]->num_rqs) {
> - dev_err(sched_list[0]->dev, "entity has out-of-bounds priority: %u. num_rqs: %u\n",
> - entity->priority, sched_list[0]->num_rqs);
> - entity->priority = max_t(s32, (s32) sched_list[0]->num_rqs - 1,
> - (s32) DRM_SCHED_PRIORITY_KERNEL);
> + if (p >= sched_list[0]->num_user_rqs) {
> + dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
> + p, sched_list[0]->num_user_rqs);
> + p = max_t(s32,
> + (s32)sched_list[0]->num_user_rqs - 1,
> + (s32)DRM_SCHED_PRIORITY_KERNEL);
> + entity->priority = p;
> }
> - entity->rq = sched_list[0]->sched_rq[entity->priority];
> + entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
That rename could be a separate patch, couldn't it? As I said before
it's always great to have general code improvements as separate patches
since it makes it far easier to review (i.e.: detect / see) core
functionality changes.
> }
>
> init_completion(&entity->entity_idle);
> @@ -567,7 +575,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
>
> spin_lock(&entity->lock);
> sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
> - rq = sched ? sched->sched_rq[entity->priority] : NULL;
> + rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
> if (rq != entity->rq) {
> drm_sched_rq_remove_entity(entity->rq, entity);
> entity->rq = rq;
> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> index 1132a771aa37..c94e38acc6f2 100644
> --- a/drivers/gpu/drm/scheduler/sched_internal.h
> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> @@ -18,18 +18,23 @@
> * @kref: reference count for the object.
> * @lock: lock guarding the @runtime updates.
> * @runtime: time entity spent on the GPU.
> + * @prev_runtime: previous @runtime used to get the runtime delta
> + * @vruntime: virtual runtime as accumulated by the fair algorithm
The other docstrings are all terminated with a full stop '.'
> */
> struct drm_sched_entity_stats {
> struct kref kref;
> spinlock_t lock;
> ktime_t runtime;
> + ktime_t prev_runtime;
> + u64 vruntime;
> };
>
> /* Used to choose between FIFO and RR job-scheduling */
> extern int drm_sched_policy;
>
> -#define DRM_SCHED_POLICY_RR 0
> -#define DRM_SCHED_POLICY_FIFO 1
> +#define DRM_SCHED_POLICY_RR 0
> +#define DRM_SCHED_POLICY_FIFO 1
> +#define DRM_SCHED_POLICY_FAIR 2
>
Formatting unnecessarily increases the git diff.
Let's die the death of having the old formatting. As far as it's
forseeable FAIR will be the last policy for the classic drm_sched
anyways, so no future changes here expected.
>
> bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> struct drm_sched_entity *entity);
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index f180d292bf66..8d8f9c8411f5 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -90,7 +90,7 @@ int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
> * DOC: sched_policy (int)
> * Used to override default entities scheduling policy in a run queue.
> */
> -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO (default).");
> +MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
> module_param_named(sched_policy, drm_sched_policy, int, 0444);
>
> static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
> @@ -1132,11 +1132,15 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> sched->own_submit_wq = true;
> }
>
> - sched->sched_rq = kmalloc_array(args->num_rqs, sizeof(*sched->sched_rq),
> + sched->num_user_rqs = args->num_rqs;
> + sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
> + args->num_rqs : 1;
> + sched->sched_rq = kmalloc_array(sched->num_rqs,
> + sizeof(*sched->sched_rq),
Don't reformat that for the git diff? Line doesn't seem crazily long.
> GFP_KERNEL | __GFP_ZERO);
> if (!sched->sched_rq)
> goto Out_check_own;
> - sched->num_rqs = args->num_rqs;
> +
> for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
> if (!sched->sched_rq[i])
> @@ -1278,7 +1282,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
> if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
> atomic_inc(&bad->karma);
>
> - for (i = DRM_SCHED_PRIORITY_HIGH; i < sched->num_rqs; i++) {
> + for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
Give me a pointer here quickly – what's that about?
> struct drm_sched_rq *rq = sched->sched_rq[i];
>
> spin_lock(&rq->lock);
> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
> index 09d316bc3dfa..b868c794cc9d 100644
> --- a/drivers/gpu/drm/scheduler/sched_rq.c
> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
> @@ -16,6 +16,24 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
> return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
> }
>
> +static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
> +{
> + enum drm_sched_priority prio = -1;
> + struct rb_node *rb;
nit:
"node" might be a bitter name than rb. When iterating over a list we
also typically call the iterator sth like "head" and not "list".
But no hard feelings on that change.
> +
> + lockdep_assert_held(&rq->lock);
> +
> + rb = rb_first_cached(&rq->rb_tree_root);
> + if (rb) {
> + struct drm_sched_entity *entity =
> + rb_entry(rb, typeof(*entity), rb_tree_node);
> +
> + prio = entity->priority; /* Unlocked read */
Why an unlocked read? Why is that OK? The comment could detail that.
> + }
> +
> + rq->head_prio = prio;
> +}
> +
> static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> struct drm_sched_rq *rq)
> {
> @@ -25,6 +43,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
> rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
> RB_CLEAR_NODE(&entity->rb_tree_node);
> + drm_sched_rq_update_prio(rq);
> }
> }
>
> @@ -46,6 +65,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>
> rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
> drm_sched_entity_compare_before);
> + drm_sched_rq_update_prio(rq);
> }
>
> /**
> @@ -63,6 +83,114 @@ void drm_sched_rq_init(struct drm_sched_rq *rq,
> INIT_LIST_HEAD(&rq->entities);
> rq->rb_tree_root = RB_ROOT_CACHED;
> rq->sched = sched;
> + rq->head_prio = -1;
head_prio is an enum.
Better to give the enum an entry like:
PRIO_INVALID = -1,
> +}
> +
> +static ktime_t
> +drm_sched_rq_get_min_vruntime(struct drm_sched_rq *rq)
> +{
> + struct drm_sched_entity *entity;
> + struct rb_node *rb;
> +
> + lockdep_assert_held(&rq->lock);
> +
> + for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
> + entity = rb_entry(rb, typeof(*entity), rb_tree_node);
> +
> + return entity->stats->vruntime; /* Unlocked read */
Seems the read is unlocked because we just don't care about it racing?
> + }
> +
> + return 0;
> +}
> +
> +static void
> +drm_sched_entity_save_vruntime(struct drm_sched_entity *entity,
> + ktime_t min_vruntime)
> +{
> + struct drm_sched_entity_stats *stats = entity->stats;
Unlocked read?
> + ktime_t vruntime;
> +
> + spin_lock(&stats->lock);
> + vruntime = stats->vruntime;
> + if (min_vruntime && vruntime > min_vruntime)
> + vruntime = ktime_sub(vruntime, min_vruntime);
> + else
> + vruntime = 0;
> + stats->vruntime = vruntime;
> + spin_unlock(&stats->lock);
> +}
> +
> +static ktime_t
> +drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
> + ktime_t min_vruntime,
> + enum drm_sched_priority rq_prio)
> +{
> + struct drm_sched_entity_stats *stats = entity->stats;
> + enum drm_sched_priority prio = entity->priority;
> + ktime_t vruntime;
> +
> + BUILD_BUG_ON(DRM_SCHED_PRIORITY_NORMAL < DRM_SCHED_PRIORITY_HIGH);
> +
> + spin_lock(&stats->lock);
> + vruntime = stats->vruntime;
> +
> + /*
> + * Special handling for entities which were picked from the top of the
> + * queue and are now re-joining the top with another one already there.
> + */
> + if (!vruntime && min_vruntime) {
> + if (prio > rq_prio) {
> + /*
> + * Lower priority should not overtake higher when re-
> + * joining at the top of the queue.
> + */
> + vruntime = us_to_ktime(prio - rq_prio);
> + } else if (prio < rq_prio) {
> + /*
> + * Higher priority can go first.
> + */
> + vruntime = -us_to_ktime(rq_prio - prio);
> + }
> + }
> +
> + /*
> + * Restore saved relative position in the queue.
> + */
> + vruntime = ktime_add(min_vruntime, vruntime);
> +
> + stats->vruntime = vruntime;
> + spin_unlock(&stats->lock);
> +
> + return vruntime;
> +}
> +
> +static ktime_t drm_sched_entity_update_vruntime(struct drm_sched_entity *entity)
> +{
> + static const unsigned int shift[] = {
> + [DRM_SCHED_PRIORITY_KERNEL] = 1,
> + [DRM_SCHED_PRIORITY_HIGH] = 2,
> + [DRM_SCHED_PRIORITY_NORMAL] = 4,
> + [DRM_SCHED_PRIORITY_LOW] = 7,
Are those numbers copied from CPU CFS? Are they from an academic paper?
Or have you measured that these generate best results?
Some hint about their background here would be nice.
> + };
> + struct drm_sched_entity_stats *stats = entity->stats;
> + ktime_t runtime, prev;
> +
> + spin_lock(&stats->lock);
> + prev = stats->prev_runtime;
> + runtime = stats->runtime;
> + stats->prev_runtime = runtime;
> + runtime = ktime_add_ns(stats->vruntime,
> + ktime_to_ns(ktime_sub(runtime, prev)) <<
> + shift[entity->priority]);
> + stats->vruntime = runtime;
> + spin_unlock(&stats->lock);
> +
> + return runtime;
> +}
> +
> +static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
> +{
> + return drm_sched_entity_update_vruntime(entity);
> }
>
> /**
> @@ -99,8 +227,14 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> list_add_tail(&entity->list, &rq->entities);
> }
>
> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> + ts = drm_sched_rq_get_min_vruntime(rq);
> + ts = drm_sched_entity_restore_vruntime(entity, ts,
> + rq->head_prio);
> + } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
> ts = entity->rr_ts;
> + }
> +
> drm_sched_rq_update_fifo_locked(entity, rq, ts);
>
> spin_unlock(&rq->lock);
> @@ -173,7 +307,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> if (next_job) {
> ktime_t ts;
>
> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
> + ts = drm_sched_entity_get_job_ts(entity);
> + else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
Could the git diff here and above be kept smaller by reversing the
order of 'if' and 'else if'?
> ts = next_job->submit_ts;
> else
> ts = drm_sched_rq_get_rr_ts(rq, entity);
> @@ -181,6 +317,13 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> drm_sched_rq_update_fifo_locked(entity, rq, ts);
> } else {
> drm_sched_rq_remove_fifo_locked(entity, rq);
> +
> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> + ktime_t min_vruntime;
> +
> + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
> + drm_sched_entity_save_vruntime(entity, min_vruntime);
> + }
> }
> spin_unlock(&rq->lock);
> spin_unlock(&entity->lock);
> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> index 93d0b7224a57..bc25508a6ff6 100644
> --- a/include/drm/gpu_scheduler.h
> +++ b/include/drm/gpu_scheduler.h
> @@ -150,6 +150,11 @@ struct drm_sched_entity {
> */
> enum drm_sched_priority priority;
>
> + /**
> + * @rq_priority: Run-queue priority
> + */
> + enum drm_sched_priority rq_priority;
> +
AFAIR that's just a temporary addition and will be simplified later.
Still, would probably be neat to be more obvious about why we now have
two priorities.
> /**
> * @rr_ts:
> *
> @@ -254,10 +259,11 @@ struct drm_sched_entity {
> * struct drm_sched_rq - queue of entities to be scheduled.
> *
> * @sched: the scheduler to which this rq belongs to.
> - * @lock: protects @entities, @rb_tree_root and @rr_ts.
> + * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
> * @rr_ts: monotonically incrementing fake timestamp for RR mode
> * @entities: list of the entities to be scheduled.
> * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
> + * @head_prio: priority of the top tree element
> *
> * Run queue is a set of entities scheduling command submissions for
> * one specific ring. It implements the scheduling policy that selects
> @@ -271,6 +277,7 @@ struct drm_sched_rq {
> ktime_t rr_ts;
> struct list_head entities;
> struct rb_root_cached rb_tree_root;
> + enum drm_sched_priority head_prio;
> };
>
> /**
> @@ -563,8 +570,10 @@ struct drm_sched_backend_ops {
> * @credit_count: the current credit count of this scheduler
> * @timeout: the time after which a job is removed from the scheduler.
> * @name: name of the ring for which this scheduler is being used.
> - * @num_rqs: Number of run-queues. This is at most DRM_SCHED_PRIORITY_COUNT,
> - * as there's usually one run-queue per priority, but could be less.
> + * @num_user_rqs: Number of run-queues. This is at most
> + * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
> + * priority, but could be less.
> + * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
Alright, so that seems to be what I was looking for above?
P.
> * @sched_rq: An allocated array of run-queues of size @num_rqs;
> * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
> * waits on this wait queue until all the scheduled jobs are
> @@ -597,6 +606,7 @@ struct drm_gpu_scheduler {
> long timeout;
> const char *name;
> u32 num_rqs;
> + u32 num_user_rqs;
> struct drm_sched_rq **sched_rq;
> wait_queue_head_t job_scheduled;
> atomic64_t job_id_count;
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-14 10:27 ` Philipp Stanner
@ 2025-10-14 12:56 ` Tvrtko Ursulin
2025-10-14 14:02 ` Philipp Stanner
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-14 12:56 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Pierre-Eric Pelloux-Prayer
On 14/10/2025 11:27, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> Fair scheduling policy is built upon the same concepts as the well known
>
> nit: "The fair …"
>
> Or maybe better: call it FAIR, being congruent with the FIFO below.
>
>> CFS kernel scheduler - entity run queue is sorted by the virtual GPU time
>
> nit: Call it "CPU scheduler". The GPU scheduler is a kernel scheduler,
> too.
>
>> consumed by entities in a way that the entity with least vruntime runs
>> first.
>>
>> It is able to avoid total priority starvation, which is one of the
>> problems with FIFO, and it also does not need for per priority run queues.
>> As it scales the actual GPU runtime by an exponential factor as the
>> priority decreases, therefore the virtual runtime for low priority
>
> "therefore," is not necessary because of the sentence starting with
> "As"
Done x3 above.
>
>> entities grows faster than for normal priority, pushing them further down
>> the runqueue order for the same real GPU time spent.
>>
>> Apart from this fundamental fairness, fair policy is especially strong in
>> oversubscription workloads where it is able to give more GPU time to short
>> and bursty workloads when they are running in parallel with GPU heavy
>> clients submitting deep job queues.
>>
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
>> ---
>> drivers/gpu/drm/scheduler/sched_entity.c | 28 ++--
>> drivers/gpu/drm/scheduler/sched_internal.h | 9 +-
>> drivers/gpu/drm/scheduler/sched_main.c | 12 +-
>> drivers/gpu/drm/scheduler/sched_rq.c | 147 ++++++++++++++++++++-
>> include/drm/gpu_scheduler.h | 16 ++-
>> 5 files changed, 191 insertions(+), 21 deletions(-)
>>
>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>> index 04ce8b7d436b..58f51875547a 100644
>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>> @@ -108,6 +108,8 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>> entity->guilty = guilty;
>> entity->num_sched_list = num_sched_list;
>> entity->priority = priority;
>> + entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
>> + DRM_SCHED_PRIORITY_KERNEL : priority;
>> /*
>> * It's perfectly valid to initialize an entity without having a valid
>> * scheduler attached. It's just not valid to use the scheduler before it
>> @@ -124,17 +126,23 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>> */
>> pr_warn("%s: called with uninitialized scheduler\n", __func__);
>> } else if (num_sched_list) {
>> - /* The "priority" of an entity cannot exceed the number of run-queues of a
>> - * scheduler. Protect against num_rqs being 0, by converting to signed. Choose
>> - * the lowest priority available.
>> + enum drm_sched_priority p = entity->priority;
>> +
>> + /*
>> + * The "priority" of an entity cannot exceed the number of
>> + * run-queues of a scheduler. Protect against num_rqs being 0,
>> + * by converting to signed. Choose the lowest priority
>> + * available.
>> */
>> - if (entity->priority >= sched_list[0]->num_rqs) {
>> - dev_err(sched_list[0]->dev, "entity has out-of-bounds priority: %u. num_rqs: %u\n",
>> - entity->priority, sched_list[0]->num_rqs);
>> - entity->priority = max_t(s32, (s32) sched_list[0]->num_rqs - 1,
>> - (s32) DRM_SCHED_PRIORITY_KERNEL);
>> + if (p >= sched_list[0]->num_user_rqs) {
>> + dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
>> + p, sched_list[0]->num_user_rqs);
>> + p = max_t(s32,
>> + (s32)sched_list[0]->num_user_rqs - 1,
>> + (s32)DRM_SCHED_PRIORITY_KERNEL);
>> + entity->priority = p;
>> }
>> - entity->rq = sched_list[0]->sched_rq[entity->priority];
>> + entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
>
> That rename could be a separate patch, couldn't it? As I said before
> it's always great to have general code improvements as separate patches
> since it makes it far easier to review (i.e.: detect / see) core
> functionality changes.
No, this is the new struct member only added in this patch.
>
>> }
>>
>> init_completion(&entity->entity_idle);
>> @@ -567,7 +575,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
>>
>> spin_lock(&entity->lock);
>> sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
>> - rq = sched ? sched->sched_rq[entity->priority] : NULL;
>> + rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
>> if (rq != entity->rq) {
>> drm_sched_rq_remove_entity(entity->rq, entity);
>> entity->rq = rq;
>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>> index 1132a771aa37..c94e38acc6f2 100644
>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>> @@ -18,18 +18,23 @@
>> * @kref: reference count for the object.
>> * @lock: lock guarding the @runtime updates.
>> * @runtime: time entity spent on the GPU.
>> + * @prev_runtime: previous @runtime used to get the runtime delta
>> + * @vruntime: virtual runtime as accumulated by the fair algorithm
>
> The other docstrings are all terminated with a full stop '.'
Yep I fixed the whole series in this respect already as response to one
of your earlier comments.
>
>> */
>> struct drm_sched_entity_stats {
>> struct kref kref;
>> spinlock_t lock;
>> ktime_t runtime;
>> + ktime_t prev_runtime;
>> + u64 vruntime;
>> };
>>
>> /* Used to choose between FIFO and RR job-scheduling */
>> extern int drm_sched_policy;
>>
>> -#define DRM_SCHED_POLICY_RR 0
>> -#define DRM_SCHED_POLICY_FIFO 1
>> +#define DRM_SCHED_POLICY_RR 0
>> +#define DRM_SCHED_POLICY_FIFO 1
>> +#define DRM_SCHED_POLICY_FAIR 2
>>
>
> Formatting unnecessarily increases the git diff.
>
> Let's die the death of having the old formatting. As far as it's
> forseeable FAIR will be the last policy for the classic drm_sched
> anyways, so no future changes here expected.
Strange I thought I fixed this already in the previous respin. Re-fixed
and verfied.
>> bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
>> struct drm_sched_entity *entity);
>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>> index f180d292bf66..8d8f9c8411f5 100644
>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>> @@ -90,7 +90,7 @@ int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
>> * DOC: sched_policy (int)
>> * Used to override default entities scheduling policy in a run queue.
>> */
>> -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO (default).");
>> +MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
>> module_param_named(sched_policy, drm_sched_policy, int, 0444);
>>
>> static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
>> @@ -1132,11 +1132,15 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>> sched->own_submit_wq = true;
>> }
>>
>> - sched->sched_rq = kmalloc_array(args->num_rqs, sizeof(*sched->sched_rq),
>> + sched->num_user_rqs = args->num_rqs;
>> + sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
>> + args->num_rqs : 1;
>> + sched->sched_rq = kmalloc_array(sched->num_rqs,
>> + sizeof(*sched->sched_rq),
>
> Don't reformat that for the git diff? Line doesn't seem crazily long.
Ok.
>
>> GFP_KERNEL | __GFP_ZERO);
>> if (!sched->sched_rq)
>> goto Out_check_own;
>> - sched->num_rqs = args->num_rqs;
>> +
>> for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>> sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
>> if (!sched->sched_rq[i])
>> @@ -1278,7 +1282,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
>> if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
>> atomic_inc(&bad->karma);
>>
>> - for (i = DRM_SCHED_PRIORITY_HIGH; i < sched->num_rqs; i++) {
>> + for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>
> Give me a pointer here quickly – what's that about?
Since FAIR stuffs everthing into a single run queue it needs to start
looking into it when looking for the guilty context. FIFO and RR are not
affected since they will not find the context with the kernel priority
in the kernel run queue anyway.
>
>> struct drm_sched_rq *rq = sched->sched_rq[i];
>>
>> spin_lock(&rq->lock);
>> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
>> index 09d316bc3dfa..b868c794cc9d 100644
>> --- a/drivers/gpu/drm/scheduler/sched_rq.c
>> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
>> @@ -16,6 +16,24 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
>> return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
>> }
>>
>> +static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
>> +{
>> + enum drm_sched_priority prio = -1;
>> + struct rb_node *rb;
>
> nit:
> "node" might be a bitter name than rb. When iterating over a list we
> also typically call the iterator sth like "head" and not "list".
>
> But no hard feelings on that change.
I am following the convention from drm_sched_rq_select_entity_fifo() to
avoid someone complaining I was diverging from the pattern established
in the same file. ;)
>> +
>> + lockdep_assert_held(&rq->lock);
>> +
>> + rb = rb_first_cached(&rq->rb_tree_root);
>> + if (rb) {
>> + struct drm_sched_entity *entity =
>> + rb_entry(rb, typeof(*entity), rb_tree_node);
>> +
>> + prio = entity->priority; /* Unlocked read */
>
> Why an unlocked read? Why is that OK? The comment could detail that.
Fair point, expanded the explanation.
>> + }
>> +
>> + rq->head_prio = prio;
>> +}
>> +
>> static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>> struct drm_sched_rq *rq)
>> {
>> @@ -25,6 +43,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>> if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
>> rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
>> RB_CLEAR_NODE(&entity->rb_tree_node);
>> + drm_sched_rq_update_prio(rq);
>> }
>> }
>>
>> @@ -46,6 +65,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>
>> rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
>> drm_sched_entity_compare_before);
>> + drm_sched_rq_update_prio(rq);
>> }
>>
>> /**
>> @@ -63,6 +83,114 @@ void drm_sched_rq_init(struct drm_sched_rq *rq,
>> INIT_LIST_HEAD(&rq->entities);
>> rq->rb_tree_root = RB_ROOT_CACHED;
>> rq->sched = sched;
>> + rq->head_prio = -1;
>
> head_prio is an enum.
>
> Better to give the enum an entry like:
>
> PRIO_INVALID = -1,
Ok.
>
>> +}
>> +
>> +static ktime_t
>> +drm_sched_rq_get_min_vruntime(struct drm_sched_rq *rq)
>> +{
>> + struct drm_sched_entity *entity;
>> + struct rb_node *rb;
>> +
>> + lockdep_assert_held(&rq->lock);
>> +
>> + for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
>> + entity = rb_entry(rb, typeof(*entity), rb_tree_node);
>> +
>> + return entity->stats->vruntime; /* Unlocked read */
>
> Seems the read is unlocked because we just don't care about it racing?
If there is a platform which tears ktime_t writes I suppose this could
read garbage. I am not sure if there is. Perhaps safer to add the lock
around it nevertheless.
>> + }
>> +
>> + return 0;
>> +}
>> +
>> +static void
>> +drm_sched_entity_save_vruntime(struct drm_sched_entity *entity,
>> + ktime_t min_vruntime)
>> +{
>> + struct drm_sched_entity_stats *stats = entity->stats;
>
> Unlocked read?
This one isn't, entity->stats never changes from drm_sched_entity_init()
to the end.
>> + ktime_t vruntime;
>> +
>> + spin_lock(&stats->lock);
>> + vruntime = stats->vruntime;
>> + if (min_vruntime && vruntime > min_vruntime)
>> + vruntime = ktime_sub(vruntime, min_vruntime);
>> + else
>> + vruntime = 0;
>> + stats->vruntime = vruntime;
>> + spin_unlock(&stats->lock);
>> +}
>> +
>> +static ktime_t
>> +drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
>> + ktime_t min_vruntime,
>> + enum drm_sched_priority rq_prio)
>> +{
>> + struct drm_sched_entity_stats *stats = entity->stats;
>> + enum drm_sched_priority prio = entity->priority;
>> + ktime_t vruntime;
>> +
>> + BUILD_BUG_ON(DRM_SCHED_PRIORITY_NORMAL < DRM_SCHED_PRIORITY_HIGH);
>> +
>> + spin_lock(&stats->lock);
>> + vruntime = stats->vruntime;
>> +
>> + /*
>> + * Special handling for entities which were picked from the top of the
>> + * queue and are now re-joining the top with another one already there.
>> + */
>> + if (!vruntime && min_vruntime) {
>> + if (prio > rq_prio) {
>> + /*
>> + * Lower priority should not overtake higher when re-
>> + * joining at the top of the queue.
>> + */
>> + vruntime = us_to_ktime(prio - rq_prio);
>> + } else if (prio < rq_prio) {
>> + /*
>> + * Higher priority can go first.
>> + */
>> + vruntime = -us_to_ktime(rq_prio - prio);
>> + }
>> + }
>> +
>> + /*
>> + * Restore saved relative position in the queue.
>> + */
>> + vruntime = ktime_add(min_vruntime, vruntime);
>> +
>> + stats->vruntime = vruntime;
>> + spin_unlock(&stats->lock);
>> +
>> + return vruntime;
>> +}
>> +
>> +static ktime_t drm_sched_entity_update_vruntime(struct drm_sched_entity *entity)
>> +{
>> + static const unsigned int shift[] = {
>> + [DRM_SCHED_PRIORITY_KERNEL] = 1,
>> + [DRM_SCHED_PRIORITY_HIGH] = 2,
>> + [DRM_SCHED_PRIORITY_NORMAL] = 4,
>> + [DRM_SCHED_PRIORITY_LOW] = 7,
>
> Are those numbers copied from CPU CFS? Are they from an academic paper?
> Or have you measured that these generate best results?
>
> Some hint about their background here would be nice.
Finger in the air I'm afraid.
>> + };
>> + struct drm_sched_entity_stats *stats = entity->stats;
>> + ktime_t runtime, prev;
>> +
>> + spin_lock(&stats->lock);
>> + prev = stats->prev_runtime;
>> + runtime = stats->runtime;
>> + stats->prev_runtime = runtime;
>> + runtime = ktime_add_ns(stats->vruntime,
>> + ktime_to_ns(ktime_sub(runtime, prev)) <<
>> + shift[entity->priority]);
>> + stats->vruntime = runtime;
>> + spin_unlock(&stats->lock);
>> +
>> + return runtime;
>> +}
>> +
>> +static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
>> +{
>> + return drm_sched_entity_update_vruntime(entity);
>> }
>>
>> /**
>> @@ -99,8 +227,14 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
>> list_add_tail(&entity->list, &rq->entities);
>> }
>>
>> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
>> + ts = drm_sched_rq_get_min_vruntime(rq);
>> + ts = drm_sched_entity_restore_vruntime(entity, ts,
>> + rq->head_prio);
>> + } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
>> ts = entity->rr_ts;
>> + }
>> +
>> drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>
>> spin_unlock(&rq->lock);
>> @@ -173,7 +307,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>> if (next_job) {
>> ktime_t ts;
>>
>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
>> + ts = drm_sched_entity_get_job_ts(entity);
>> + else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>
> Could the git diff here and above be kept smaller by reversing the
> order of 'if' and 'else if'?
Maybe but I liked having the best policy first. Can change if you want.
>
>> ts = next_job->submit_ts;
>> else
>> ts = drm_sched_rq_get_rr_ts(rq, entity);
>> @@ -181,6 +317,13 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>> drm_sched_rq_update_fifo_locked(entity, rq, ts);
>> } else {
>> drm_sched_rq_remove_fifo_locked(entity, rq);
>> +
>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
>> + ktime_t min_vruntime;
>> +
>> + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
>> + drm_sched_entity_save_vruntime(entity, min_vruntime);
>> + }
>> }
>> spin_unlock(&rq->lock);
>> spin_unlock(&entity->lock);
>> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
>> index 93d0b7224a57..bc25508a6ff6 100644
>> --- a/include/drm/gpu_scheduler.h
>> +++ b/include/drm/gpu_scheduler.h
>> @@ -150,6 +150,11 @@ struct drm_sched_entity {
>> */
>> enum drm_sched_priority priority;
>>
>> + /**
>> + * @rq_priority: Run-queue priority
>> + */
>> + enum drm_sched_priority rq_priority;
>> +
>
> AFAIR that's just a temporary addition and will be simplified later.
> Still, would probably be neat to be more obvious about why we now have
> two priorities.
>
>> /**
>> * @rr_ts:
>> *
>> @@ -254,10 +259,11 @@ struct drm_sched_entity {
>> * struct drm_sched_rq - queue of entities to be scheduled.
>> *
>> * @sched: the scheduler to which this rq belongs to.
>> - * @lock: protects @entities, @rb_tree_root and @rr_ts.
>> + * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
>> * @rr_ts: monotonically incrementing fake timestamp for RR mode
>> * @entities: list of the entities to be scheduled.
>> * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
>> + * @head_prio: priority of the top tree element
>> *
>> * Run queue is a set of entities scheduling command submissions for
>> * one specific ring. It implements the scheduling policy that selects
>> @@ -271,6 +277,7 @@ struct drm_sched_rq {
>> ktime_t rr_ts;
>> struct list_head entities;
>> struct rb_root_cached rb_tree_root;
>> + enum drm_sched_priority head_prio;
>> };
>>
>> /**
>> @@ -563,8 +570,10 @@ struct drm_sched_backend_ops {
>> * @credit_count: the current credit count of this scheduler
>> * @timeout: the time after which a job is removed from the scheduler.
>> * @name: name of the ring for which this scheduler is being used.
>> - * @num_rqs: Number of run-queues. This is at most DRM_SCHED_PRIORITY_COUNT,
>> - * as there's usually one run-queue per priority, but could be less.
>> + * @num_user_rqs: Number of run-queues. This is at most
>> + * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
>> + * priority, but could be less.
>> + * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
>
> Alright, so that seems to be what I was looking for above?
Yep.
Regards,
Tvrtko
>> * @sched_rq: An allocated array of run-queues of size @num_rqs;
>> * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
>> * waits on this wait queue until all the scheduled jobs are
>> @@ -597,6 +606,7 @@ struct drm_gpu_scheduler {
>> long timeout;
>> const char *name;
>> u32 num_rqs;
>> + u32 num_user_rqs;
>> struct drm_sched_rq **sched_rq;
>> wait_queue_head_t job_scheduled;
>> atomic64_t job_id_count;
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-14 12:56 ` Tvrtko Ursulin
@ 2025-10-14 14:02 ` Philipp Stanner
2025-10-14 14:32 ` Simona Vetter
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-14 14:02 UTC (permalink / raw)
To: Tvrtko Ursulin, phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Pierre-Eric Pelloux-Prayer, Simona Vetter
On Tue, 2025-10-14 at 13:56 +0100, Tvrtko Ursulin wrote:
>
> On 14/10/2025 11:27, Philipp Stanner wrote:
> > On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> > > Fair scheduling policy is built upon the same concepts as the well known
> >
> > nit: "The fair …"
> >
> > Or maybe better: call it FAIR, being congruent with the FIFO below.
> >
> > > CFS kernel scheduler - entity run queue is sorted by the virtual GPU time
> >
> > nit: Call it "CPU scheduler". The GPU scheduler is a kernel scheduler,
> > too.
> >
> > > consumed by entities in a way that the entity with least vruntime runs
> > > first.
> > >
> > > It is able to avoid total priority starvation, which is one of the
> > > problems with FIFO, and it also does not need for per priority run queues.
> > > As it scales the actual GPU runtime by an exponential factor as the
> > > priority decreases, therefore the virtual runtime for low priority
> >
> > "therefore," is not necessary because of the sentence starting with
> > "As"
>
> Done x3 above.
>
> >
> > > entities grows faster than for normal priority, pushing them further down
> > > the runqueue order for the same real GPU time spent.
> > >
> > > Apart from this fundamental fairness, fair policy is especially strong in
> > > oversubscription workloads where it is able to give more GPU time to short
> > > and bursty workloads when they are running in parallel with GPU heavy
> > > clients submitting deep job queues.
> > >
> > > Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> > > Cc: Christian König <christian.koenig@amd.com>
> > > Cc: Danilo Krummrich <dakr@kernel.org>
> > > Cc: Matthew Brost <matthew.brost@intel.com>
> > > Cc: Philipp Stanner <phasta@kernel.org>
> > > Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
> > > ---
> > > drivers/gpu/drm/scheduler/sched_entity.c | 28 ++--
> > > drivers/gpu/drm/scheduler/sched_internal.h | 9 +-
> > > drivers/gpu/drm/scheduler/sched_main.c | 12 +-
> > > drivers/gpu/drm/scheduler/sched_rq.c | 147 ++++++++++++++++++++-
> > > include/drm/gpu_scheduler.h | 16 ++-
> > > 5 files changed, 191 insertions(+), 21 deletions(-)
> > >
> > > diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> > > index 04ce8b7d436b..58f51875547a 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_entity.c
> > > +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> > > @@ -108,6 +108,8 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> > > entity->guilty = guilty;
> > > entity->num_sched_list = num_sched_list;
> > > entity->priority = priority;
> > > + entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
> > > + DRM_SCHED_PRIORITY_KERNEL : priority;
> > > /*
> > > * It's perfectly valid to initialize an entity without having a valid
> > > * scheduler attached. It's just not valid to use the scheduler before it
> > > @@ -124,17 +126,23 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> > > */
> > > pr_warn("%s: called with uninitialized scheduler\n", __func__);
> > > } else if (num_sched_list) {
> > > - /* The "priority" of an entity cannot exceed the number of run-queues of a
> > > - * scheduler. Protect against num_rqs being 0, by converting to signed. Choose
> > > - * the lowest priority available.
> > > + enum drm_sched_priority p = entity->priority;
> > > +
> > > + /*
> > > + * The "priority" of an entity cannot exceed the number of
> > > + * run-queues of a scheduler. Protect against num_rqs being 0,
> > > + * by converting to signed. Choose the lowest priority
> > > + * available.
> > > */
> > > - if (entity->priority >= sched_list[0]->num_rqs) {
> > > - dev_err(sched_list[0]->dev, "entity has out-of-bounds priority: %u. num_rqs: %u\n",
> > > - entity->priority, sched_list[0]->num_rqs);
> > > - entity->priority = max_t(s32, (s32) sched_list[0]->num_rqs - 1,
> > > - (s32) DRM_SCHED_PRIORITY_KERNEL);
> > > + if (p >= sched_list[0]->num_user_rqs) {
> > > + dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
> > > + p, sched_list[0]->num_user_rqs);
> > > + p = max_t(s32,
> > > + (s32)sched_list[0]->num_user_rqs - 1,
> > > + (s32)DRM_SCHED_PRIORITY_KERNEL);
> > > + entity->priority = p;
> > > }
> > > - entity->rq = sched_list[0]->sched_rq[entity->priority];
> > > + entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
> >
> > That rename could be a separate patch, couldn't it? As I said before
> > it's always great to have general code improvements as separate patches
> > since it makes it far easier to review (i.e.: detect / see) core
> > functionality changes.
>
> No, this is the new struct member only added in this patch.
>
> >
> > > }
> > >
> > > init_completion(&entity->entity_idle);
> > > @@ -567,7 +575,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
> > >
> > > spin_lock(&entity->lock);
> > > sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
> > > - rq = sched ? sched->sched_rq[entity->priority] : NULL;
> > > + rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
> > > if (rq != entity->rq) {
> > > drm_sched_rq_remove_entity(entity->rq, entity);
> > > entity->rq = rq;
> > > diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> > > index 1132a771aa37..c94e38acc6f2 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_internal.h
> > > +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> > > @@ -18,18 +18,23 @@
> > > * @kref: reference count for the object.
> > > * @lock: lock guarding the @runtime updates.
> > > * @runtime: time entity spent on the GPU.
> > > + * @prev_runtime: previous @runtime used to get the runtime delta
> > > + * @vruntime: virtual runtime as accumulated by the fair algorithm
> >
> > The other docstrings are all terminated with a full stop '.'
>
> Yep I fixed the whole series in this respect already as response to one
> of your earlier comments.
>
> >
> > > */
> > > struct drm_sched_entity_stats {
> > > struct kref kref;
> > > spinlock_t lock;
> > > ktime_t runtime;
> > > + ktime_t prev_runtime;
> > > + u64 vruntime;
> > > };
> > >
> > > /* Used to choose between FIFO and RR job-scheduling */
> > > extern int drm_sched_policy;
> > >
> > > -#define DRM_SCHED_POLICY_RR 0
> > > -#define DRM_SCHED_POLICY_FIFO 1
> > > +#define DRM_SCHED_POLICY_RR 0
> > > +#define DRM_SCHED_POLICY_FIFO 1
> > > +#define DRM_SCHED_POLICY_FAIR 2
> > >
> >
> > Formatting unnecessarily increases the git diff.
> >
> > Let's die the death of having the old formatting. As far as it's
> > forseeable FAIR will be the last policy for the classic drm_sched
> > anyways, so no future changes here expected.
>
> Strange I thought I fixed this already in the previous respin. Re-fixed
> and verfied.
> > > bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> > > struct drm_sched_entity *entity);
> > > diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> > > index f180d292bf66..8d8f9c8411f5 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_main.c
> > > +++ b/drivers/gpu/drm/scheduler/sched_main.c
> > > @@ -90,7 +90,7 @@ int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
> > > * DOC: sched_policy (int)
> > > * Used to override default entities scheduling policy in a run queue.
> > > */
> > > -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO (default).");
> > > +MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
> > > module_param_named(sched_policy, drm_sched_policy, int, 0444);
> > >
> > > static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
> > > @@ -1132,11 +1132,15 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> > > sched->own_submit_wq = true;
> > > }
> > >
> > > - sched->sched_rq = kmalloc_array(args->num_rqs, sizeof(*sched->sched_rq),
> > > + sched->num_user_rqs = args->num_rqs;
> > > + sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
> > > + args->num_rqs : 1;
> > > + sched->sched_rq = kmalloc_array(sched->num_rqs,
> > > + sizeof(*sched->sched_rq),
> >
> > Don't reformat that for the git diff? Line doesn't seem crazily long.
>
> Ok.
>
> >
> > > GFP_KERNEL | __GFP_ZERO);
> > > if (!sched->sched_rq)
> > > goto Out_check_own;
> > > - sched->num_rqs = args->num_rqs;
> > > +
> > > for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> > > sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
> > > if (!sched->sched_rq[i])
> > > @@ -1278,7 +1282,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
> > > if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
> > > atomic_inc(&bad->karma);
> > >
> > > - for (i = DRM_SCHED_PRIORITY_HIGH; i < sched->num_rqs; i++) {
> > > + for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> >
> > Give me a pointer here quickly – what's that about?
>
> Since FAIR stuffs everthing into a single run queue it needs to start
> looking into it when looking for the guilty context. FIFO and RR are not
> affected since they will not find the context with the kernel priority
> in the kernel run queue anyway.
>
> >
> > > struct drm_sched_rq *rq = sched->sched_rq[i];
> > >
> > > spin_lock(&rq->lock);
> > > diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
> > > index 09d316bc3dfa..b868c794cc9d 100644
> > > --- a/drivers/gpu/drm/scheduler/sched_rq.c
> > > +++ b/drivers/gpu/drm/scheduler/sched_rq.c
> > > @@ -16,6 +16,24 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
> > > return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
> > > }
> > >
> > > +static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
> > > +{
> > > + enum drm_sched_priority prio = -1;
> > > + struct rb_node *rb;
> >
> > nit:
> > "node" might be a bitter name than rb. When iterating over a list we
> > also typically call the iterator sth like "head" and not "list".
> >
> > But no hard feelings on that change.
>
> I am following the convention from drm_sched_rq_select_entity_fifo() to
> avoid someone complaining I was diverging from the pattern established
> in the same file. ;)
Don't worry, I will always cover your back against such people!
> > > +
> > > + lockdep_assert_held(&rq->lock);
> > > +
> > > + rb = rb_first_cached(&rq->rb_tree_root);
> > > + if (rb) {
> > > + struct drm_sched_entity *entity =
> > > + rb_entry(rb, typeof(*entity), rb_tree_node);
> > > +
> > > + prio = entity->priority; /* Unlocked read */
> >
> > Why an unlocked read? Why is that OK? The comment could detail that.
>
> Fair point, expanded the explanation.
> > > + }
> > > +
> > > + rq->head_prio = prio;
> > > +}
> > > +
> > > static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > struct drm_sched_rq *rq)
> > > {
> > > @@ -25,6 +43,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
> > > rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
> > > RB_CLEAR_NODE(&entity->rb_tree_node);
> > > + drm_sched_rq_update_prio(rq);
> > > }
> > > }
> > >
> > > @@ -46,6 +65,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > >
> > > rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
> > > drm_sched_entity_compare_before);
> > > + drm_sched_rq_update_prio(rq);
> > > }
> > >
> > > /**
> > > @@ -63,6 +83,114 @@ void drm_sched_rq_init(struct drm_sched_rq *rq,
> > > INIT_LIST_HEAD(&rq->entities);
> > > rq->rb_tree_root = RB_ROOT_CACHED;
> > > rq->sched = sched;
> > > + rq->head_prio = -1;
> >
> > head_prio is an enum.
> >
> > Better to give the enum an entry like:
> >
> > PRIO_INVALID = -1,
>
> Ok.
>
> >
> > > +}
> > > +
> > > +static ktime_t
> > > +drm_sched_rq_get_min_vruntime(struct drm_sched_rq *rq)
> > > +{
> > > + struct drm_sched_entity *entity;
> > > + struct rb_node *rb;
> > > +
> > > + lockdep_assert_held(&rq->lock);
> > > +
> > > + for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
> > > + entity = rb_entry(rb, typeof(*entity), rb_tree_node);
> > > +
> > > + return entity->stats->vruntime; /* Unlocked read */
> >
> > Seems the read is unlocked because we just don't care about it racing?
>
> If there is a platform which tears ktime_t writes I suppose this could
> read garbage. I am not sure if there is. Perhaps safer to add the lock
> around it nevertheless.
I think Sima (+cc) was very explicit about us never to implement our
own locking or synchronization primitives.
Not locking stuff that can get accessed asynchronously is just a hard
No-Go.
That you access things here asynchronously is even more confusing
considering that in the kunit patch you explicitly add READ_ONCE() for
documentation purposes.
Premature performance optimization is the root of all evil, and think
about the unlocked runqueue readers. 5 years down the road no one has
the slightest clue anymore what is supposed to be locked by whom and
accessed when and how.
At XDC we had an entire room of highly experienced experts and we had
no clue anymore.
My need to establish in DRM that everything accessed by more than 1 CPU
at the same time always has to be locked.
Alternatives (memory barriers, RCU, atomics, read once) are permitted
if one can give really good justification (performance measurements)
and can provide a clear and clean concept.
I'd have to consult the C standard, but I think just reading from
something that is not an atomic might even be UB.
(That said, all platforms Linux runs on don't tear integers AFAIK.
Otherwise RCU couldn't work.)
> > > + }
> > > +
> > > + return 0;
> > > +}
> > > +
> > > +static void
> > > +drm_sched_entity_save_vruntime(struct drm_sched_entity *entity,
> > > + ktime_t min_vruntime)
> > > +{
> > > + struct drm_sched_entity_stats *stats = entity->stats;
> >
> > Unlocked read?
>
> This one isn't, entity->stats never changes from drm_sched_entity_init()
> to the end.
>
> > > + ktime_t vruntime;
> > > +
> > > + spin_lock(&stats->lock);
> > > + vruntime = stats->vruntime;
> > > + if (min_vruntime && vruntime > min_vruntime)
> > > + vruntime = ktime_sub(vruntime, min_vruntime);
> > > + else
> > > + vruntime = 0;
> > > + stats->vruntime = vruntime;
> > > + spin_unlock(&stats->lock);
> > > +}
> > > +
> > > +static ktime_t
> > > +drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
> > > + ktime_t min_vruntime,
> > > + enum drm_sched_priority rq_prio)
> > > +{
> > > + struct drm_sched_entity_stats *stats = entity->stats;
> > > + enum drm_sched_priority prio = entity->priority;
> > > + ktime_t vruntime;
> > > +
> > > + BUILD_BUG_ON(DRM_SCHED_PRIORITY_NORMAL < DRM_SCHED_PRIORITY_HIGH);
> > > +
> > > + spin_lock(&stats->lock);
> > > + vruntime = stats->vruntime;
> > > +
> > > + /*
> > > + * Special handling for entities which were picked from the top of the
> > > + * queue and are now re-joining the top with another one already there.
> > > + */
> > > + if (!vruntime && min_vruntime) {
> > > + if (prio > rq_prio) {
> > > + /*
> > > + * Lower priority should not overtake higher when re-
> > > + * joining at the top of the queue.
> > > + */
> > > + vruntime = us_to_ktime(prio - rq_prio);
> > > + } else if (prio < rq_prio) {
> > > + /*
> > > + * Higher priority can go first.
> > > + */
> > > + vruntime = -us_to_ktime(rq_prio - prio);
> > > + }
> > > + }
> > > +
> > > + /*
> > > + * Restore saved relative position in the queue.
> > > + */
> > > + vruntime = ktime_add(min_vruntime, vruntime);
> > > +
> > > + stats->vruntime = vruntime;
> > > + spin_unlock(&stats->lock);
> > > +
> > > + return vruntime;
> > > +}
> > > +
> > > +static ktime_t drm_sched_entity_update_vruntime(struct drm_sched_entity *entity)
> > > +{
> > > + static const unsigned int shift[] = {
> > > + [DRM_SCHED_PRIORITY_KERNEL] = 1,
> > > + [DRM_SCHED_PRIORITY_HIGH] = 2,
> > > + [DRM_SCHED_PRIORITY_NORMAL] = 4,
> > > + [DRM_SCHED_PRIORITY_LOW] = 7,
> >
> > Are those numbers copied from CPU CFS? Are they from an academic paper?
> > Or have you measured that these generate best results?
> >
> > Some hint about their background here would be nice.
>
> Finger in the air I'm afraid.
You mean you just tried some numbers?
That's OK, but you could state so here. In a nicer formulation.
> > > + };
> > > + struct drm_sched_entity_stats *stats = entity->stats;
> > > + ktime_t runtime, prev;
> > > +
> > > + spin_lock(&stats->lock);
> > > + prev = stats->prev_runtime;
> > > + runtime = stats->runtime;
> > > + stats->prev_runtime = runtime;
> > > + runtime = ktime_add_ns(stats->vruntime,
> > > + ktime_to_ns(ktime_sub(runtime, prev)) <<
> > > + shift[entity->priority]);
> > > + stats->vruntime = runtime;
> > > + spin_unlock(&stats->lock);
> > > +
> > > + return runtime;
> > > +}
> > > +
> > > +static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
> > > +{
> > > + return drm_sched_entity_update_vruntime(entity);
> > > }
> > >
> > > /**
> > > @@ -99,8 +227,14 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> > > list_add_tail(&entity->list, &rq->entities);
> > > }
> > >
> > > - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> > > + ts = drm_sched_rq_get_min_vruntime(rq);
> > > + ts = drm_sched_entity_restore_vruntime(entity, ts,
> > > + rq->head_prio);
> > > + } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
> > > ts = entity->rr_ts;
> > > + }
> > > +
> > > drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > >
> > > spin_unlock(&rq->lock);
> > > @@ -173,7 +307,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> > > if (next_job) {
> > > ktime_t ts;
> > >
> > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
> > > + ts = drm_sched_entity_get_job_ts(entity);
> > > + else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> >
> > Could the git diff here and above be kept smaller by reversing the
> > order of 'if' and 'else if'?
>
> Maybe but I liked having the best policy first. Can change if you want.
It's optional.
P.
>
> >
> > > ts = next_job->submit_ts;
> > > else
> > > ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > @@ -181,6 +317,13 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> > > drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > } else {
> > > drm_sched_rq_remove_fifo_locked(entity, rq);
> > > +
> > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> > > + ktime_t min_vruntime;
> > > +
> > > + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
> > > + drm_sched_entity_save_vruntime(entity, min_vruntime);
> > > + }
> > > }
> > > spin_unlock(&rq->lock);
> > > spin_unlock(&entity->lock);
> > > diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> > > index 93d0b7224a57..bc25508a6ff6 100644
> > > --- a/include/drm/gpu_scheduler.h
> > > +++ b/include/drm/gpu_scheduler.h
> > > @@ -150,6 +150,11 @@ struct drm_sched_entity {
> > > */
> > > enum drm_sched_priority priority;
> > >
> > > + /**
> > > + * @rq_priority: Run-queue priority
> > > + */
> > > + enum drm_sched_priority rq_priority;
> > > +
> >
> > AFAIR that's just a temporary addition and will be simplified later.
> > Still, would probably be neat to be more obvious about why we now have
> > two priorities.
> >
> > > /**
> > > * @rr_ts:
> > > *
> > > @@ -254,10 +259,11 @@ struct drm_sched_entity {
> > > * struct drm_sched_rq - queue of entities to be scheduled.
> > > *
> > > * @sched: the scheduler to which this rq belongs to.
> > > - * @lock: protects @entities, @rb_tree_root and @rr_ts.
> > > + * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
> > > * @rr_ts: monotonically incrementing fake timestamp for RR mode
> > > * @entities: list of the entities to be scheduled.
> > > * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
> > > + * @head_prio: priority of the top tree element
> > > *
> > > * Run queue is a set of entities scheduling command submissions for
> > > * one specific ring. It implements the scheduling policy that selects
> > > @@ -271,6 +277,7 @@ struct drm_sched_rq {
> > > ktime_t rr_ts;
> > > struct list_head entities;
> > > struct rb_root_cached rb_tree_root;
> > > + enum drm_sched_priority head_prio;
> > > };
> > >
> > > /**
> > > @@ -563,8 +570,10 @@ struct drm_sched_backend_ops {
> > > * @credit_count: the current credit count of this scheduler
> > > * @timeout: the time after which a job is removed from the scheduler.
> > > * @name: name of the ring for which this scheduler is being used.
> > > - * @num_rqs: Number of run-queues. This is at most DRM_SCHED_PRIORITY_COUNT,
> > > - * as there's usually one run-queue per priority, but could be less.
> > > + * @num_user_rqs: Number of run-queues. This is at most
> > > + * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
> > > + * priority, but could be less.
> > > + * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
> >
> > Alright, so that seems to be what I was looking for above?
>
> Yep.
>
> Regards,
>
> Tvrtko
>
> > > * @sched_rq: An allocated array of run-queues of size @num_rqs;
> > > * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
> > > * waits on this wait queue until all the scheduled jobs are
> > > @@ -597,6 +606,7 @@ struct drm_gpu_scheduler {
> > > long timeout;
> > > const char *name;
> > > u32 num_rqs;
> > > + u32 num_user_rqs;
> > > struct drm_sched_rq **sched_rq;
> > > wait_queue_head_t job_scheduled;
> > > atomic64_t job_id_count;
> >
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-14 14:02 ` Philipp Stanner
@ 2025-10-14 14:32 ` Simona Vetter
2025-10-14 14:58 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Simona Vetter @ 2025-10-14 14:32 UTC (permalink / raw)
To: phasta
Cc: Tvrtko Ursulin, amd-gfx, dri-devel, kernel-dev,
Christian König, Danilo Krummrich, Matthew Brost,
Pierre-Eric Pelloux-Prayer, Simona Vetter
On Tue, Oct 14, 2025 at 04:02:52PM +0200, Philipp Stanner wrote:
> On Tue, 2025-10-14 at 13:56 +0100, Tvrtko Ursulin wrote:
> >
> > On 14/10/2025 11:27, Philipp Stanner wrote:
> > > On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> > > > Fair scheduling policy is built upon the same concepts as the well known
> > >
> > > nit: "The fair …"
> > >
> > > Or maybe better: call it FAIR, being congruent with the FIFO below.
> > >
> > > > CFS kernel scheduler - entity run queue is sorted by the virtual GPU time
> > >
> > > nit: Call it "CPU scheduler". The GPU scheduler is a kernel scheduler,
> > > too.
> > >
> > > > consumed by entities in a way that the entity with least vruntime runs
> > > > first.
> > > >
> > > > It is able to avoid total priority starvation, which is one of the
> > > > problems with FIFO, and it also does not need for per priority run queues.
> > > > As it scales the actual GPU runtime by an exponential factor as the
> > > > priority decreases, therefore the virtual runtime for low priority
> > >
> > > "therefore," is not necessary because of the sentence starting with
> > > "As"
> >
> > Done x3 above.
> >
> > >
> > > > entities grows faster than for normal priority, pushing them further down
> > > > the runqueue order for the same real GPU time spent.
> > > >
> > > > Apart from this fundamental fairness, fair policy is especially strong in
> > > > oversubscription workloads where it is able to give more GPU time to short
> > > > and bursty workloads when they are running in parallel with GPU heavy
> > > > clients submitting deep job queues.
> > > >
> > > > Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> > > > Cc: Christian König <christian.koenig@amd.com>
> > > > Cc: Danilo Krummrich <dakr@kernel.org>
> > > > Cc: Matthew Brost <matthew.brost@intel.com>
> > > > Cc: Philipp Stanner <phasta@kernel.org>
> > > > Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
> > > > ---
> > > > drivers/gpu/drm/scheduler/sched_entity.c | 28 ++--
> > > > drivers/gpu/drm/scheduler/sched_internal.h | 9 +-
> > > > drivers/gpu/drm/scheduler/sched_main.c | 12 +-
> > > > drivers/gpu/drm/scheduler/sched_rq.c | 147 ++++++++++++++++++++-
> > > > include/drm/gpu_scheduler.h | 16 ++-
> > > > 5 files changed, 191 insertions(+), 21 deletions(-)
> > > >
> > > > diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> > > > index 04ce8b7d436b..58f51875547a 100644
> > > > --- a/drivers/gpu/drm/scheduler/sched_entity.c
> > > > +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> > > > @@ -108,6 +108,8 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> > > > entity->guilty = guilty;
> > > > entity->num_sched_list = num_sched_list;
> > > > entity->priority = priority;
> > > > + entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
> > > > + DRM_SCHED_PRIORITY_KERNEL : priority;
> > > > /*
> > > > * It's perfectly valid to initialize an entity without having a valid
> > > > * scheduler attached. It's just not valid to use the scheduler before it
> > > > @@ -124,17 +126,23 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> > > > */
> > > > pr_warn("%s: called with uninitialized scheduler\n", __func__);
> > > > } else if (num_sched_list) {
> > > > - /* The "priority" of an entity cannot exceed the number of run-queues of a
> > > > - * scheduler. Protect against num_rqs being 0, by converting to signed. Choose
> > > > - * the lowest priority available.
> > > > + enum drm_sched_priority p = entity->priority;
> > > > +
> > > > + /*
> > > > + * The "priority" of an entity cannot exceed the number of
> > > > + * run-queues of a scheduler. Protect against num_rqs being 0,
> > > > + * by converting to signed. Choose the lowest priority
> > > > + * available.
> > > > */
> > > > - if (entity->priority >= sched_list[0]->num_rqs) {
> > > > - dev_err(sched_list[0]->dev, "entity has out-of-bounds priority: %u. num_rqs: %u\n",
> > > > - entity->priority, sched_list[0]->num_rqs);
> > > > - entity->priority = max_t(s32, (s32) sched_list[0]->num_rqs - 1,
> > > > - (s32) DRM_SCHED_PRIORITY_KERNEL);
> > > > + if (p >= sched_list[0]->num_user_rqs) {
> > > > + dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
> > > > + p, sched_list[0]->num_user_rqs);
> > > > + p = max_t(s32,
> > > > + (s32)sched_list[0]->num_user_rqs - 1,
> > > > + (s32)DRM_SCHED_PRIORITY_KERNEL);
> > > > + entity->priority = p;
> > > > }
> > > > - entity->rq = sched_list[0]->sched_rq[entity->priority];
> > > > + entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
> > >
> > > That rename could be a separate patch, couldn't it? As I said before
> > > it's always great to have general code improvements as separate patches
> > > since it makes it far easier to review (i.e.: detect / see) core
> > > functionality changes.
> >
> > No, this is the new struct member only added in this patch.
> >
> > >
> > > > }
> > > >
> > > > init_completion(&entity->entity_idle);
> > > > @@ -567,7 +575,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
> > > >
> > > > spin_lock(&entity->lock);
> > > > sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
> > > > - rq = sched ? sched->sched_rq[entity->priority] : NULL;
> > > > + rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
> > > > if (rq != entity->rq) {
> > > > drm_sched_rq_remove_entity(entity->rq, entity);
> > > > entity->rq = rq;
> > > > diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> > > > index 1132a771aa37..c94e38acc6f2 100644
> > > > --- a/drivers/gpu/drm/scheduler/sched_internal.h
> > > > +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> > > > @@ -18,18 +18,23 @@
> > > > * @kref: reference count for the object.
> > > > * @lock: lock guarding the @runtime updates.
> > > > * @runtime: time entity spent on the GPU.
> > > > + * @prev_runtime: previous @runtime used to get the runtime delta
> > > > + * @vruntime: virtual runtime as accumulated by the fair algorithm
> > >
> > > The other docstrings are all terminated with a full stop '.'
> >
> > Yep I fixed the whole series in this respect already as response to one
> > of your earlier comments.
> >
> > >
> > > > */
> > > > struct drm_sched_entity_stats {
> > > > struct kref kref;
> > > > spinlock_t lock;
> > > > ktime_t runtime;
> > > > + ktime_t prev_runtime;
> > > > + u64 vruntime;
> > > > };
> > > >
> > > > /* Used to choose between FIFO and RR job-scheduling */
> > > > extern int drm_sched_policy;
> > > >
> > > > -#define DRM_SCHED_POLICY_RR 0
> > > > -#define DRM_SCHED_POLICY_FIFO 1
> > > > +#define DRM_SCHED_POLICY_RR 0
> > > > +#define DRM_SCHED_POLICY_FIFO 1
> > > > +#define DRM_SCHED_POLICY_FAIR 2
> > > >
> > >
> > > Formatting unnecessarily increases the git diff.
> > >
> > > Let's die the death of having the old formatting. As far as it's
> > > forseeable FAIR will be the last policy for the classic drm_sched
> > > anyways, so no future changes here expected.
> >
> > Strange I thought I fixed this already in the previous respin. Re-fixed
> > and verfied.
> > > > bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> > > > struct drm_sched_entity *entity);
> > > > diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> > > > index f180d292bf66..8d8f9c8411f5 100644
> > > > --- a/drivers/gpu/drm/scheduler/sched_main.c
> > > > +++ b/drivers/gpu/drm/scheduler/sched_main.c
> > > > @@ -90,7 +90,7 @@ int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
> > > > * DOC: sched_policy (int)
> > > > * Used to override default entities scheduling policy in a run queue.
> > > > */
> > > > -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO (default).");
> > > > +MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
> > > > module_param_named(sched_policy, drm_sched_policy, int, 0444);
> > > >
> > > > static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
> > > > @@ -1132,11 +1132,15 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> > > > sched->own_submit_wq = true;
> > > > }
> > > >
> > > > - sched->sched_rq = kmalloc_array(args->num_rqs, sizeof(*sched->sched_rq),
> > > > + sched->num_user_rqs = args->num_rqs;
> > > > + sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
> > > > + args->num_rqs : 1;
> > > > + sched->sched_rq = kmalloc_array(sched->num_rqs,
> > > > + sizeof(*sched->sched_rq),
> > >
> > > Don't reformat that for the git diff? Line doesn't seem crazily long.
> >
> > Ok.
> >
> > >
> > > > GFP_KERNEL | __GFP_ZERO);
> > > > if (!sched->sched_rq)
> > > > goto Out_check_own;
> > > > - sched->num_rqs = args->num_rqs;
> > > > +
> > > > for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> > > > sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
> > > > if (!sched->sched_rq[i])
> > > > @@ -1278,7 +1282,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
> > > > if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
> > > > atomic_inc(&bad->karma);
> > > >
> > > > - for (i = DRM_SCHED_PRIORITY_HIGH; i < sched->num_rqs; i++) {
> > > > + for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> > >
> > > Give me a pointer here quickly – what's that about?
> >
> > Since FAIR stuffs everthing into a single run queue it needs to start
> > looking into it when looking for the guilty context. FIFO and RR are not
> > affected since they will not find the context with the kernel priority
> > in the kernel run queue anyway.
> >
> > >
> > > > struct drm_sched_rq *rq = sched->sched_rq[i];
> > > >
> > > > spin_lock(&rq->lock);
> > > > diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
> > > > index 09d316bc3dfa..b868c794cc9d 100644
> > > > --- a/drivers/gpu/drm/scheduler/sched_rq.c
> > > > +++ b/drivers/gpu/drm/scheduler/sched_rq.c
> > > > @@ -16,6 +16,24 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
> > > > return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
> > > > }
> > > >
> > > > +static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
> > > > +{
> > > > + enum drm_sched_priority prio = -1;
> > > > + struct rb_node *rb;
> > >
> > > nit:
> > > "node" might be a bitter name than rb. When iterating over a list we
> > > also typically call the iterator sth like "head" and not "list".
> > >
> > > But no hard feelings on that change.
> >
> > I am following the convention from drm_sched_rq_select_entity_fifo() to
> > avoid someone complaining I was diverging from the pattern established
> > in the same file. ;)
>
> Don't worry, I will always cover your back against such people!
>
> > > > +
> > > > + lockdep_assert_held(&rq->lock);
> > > > +
> > > > + rb = rb_first_cached(&rq->rb_tree_root);
> > > > + if (rb) {
> > > > + struct drm_sched_entity *entity =
> > > > + rb_entry(rb, typeof(*entity), rb_tree_node);
> > > > +
> > > > + prio = entity->priority; /* Unlocked read */
> > >
> > > Why an unlocked read? Why is that OK? The comment could detail that.
> >
> > Fair point, expanded the explanation.
> > > > + }
> > > > +
> > > > + rq->head_prio = prio;
> > > > +}
> > > > +
> > > > static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > > struct drm_sched_rq *rq)
> > > > {
> > > > @@ -25,6 +43,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > > if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
> > > > rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
> > > > RB_CLEAR_NODE(&entity->rb_tree_node);
> > > > + drm_sched_rq_update_prio(rq);
> > > > }
> > > > }
> > > >
> > > > @@ -46,6 +65,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > >
> > > > rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
> > > > drm_sched_entity_compare_before);
> > > > + drm_sched_rq_update_prio(rq);
> > > > }
> > > >
> > > > /**
> > > > @@ -63,6 +83,114 @@ void drm_sched_rq_init(struct drm_sched_rq *rq,
> > > > INIT_LIST_HEAD(&rq->entities);
> > > > rq->rb_tree_root = RB_ROOT_CACHED;
> > > > rq->sched = sched;
> > > > + rq->head_prio = -1;
> > >
> > > head_prio is an enum.
> > >
> > > Better to give the enum an entry like:
> > >
> > > PRIO_INVALID = -1,
> >
> > Ok.
> >
> > >
> > > > +}
> > > > +
> > > > +static ktime_t
> > > > +drm_sched_rq_get_min_vruntime(struct drm_sched_rq *rq)
> > > > +{
> > > > + struct drm_sched_entity *entity;
> > > > + struct rb_node *rb;
> > > > +
> > > > + lockdep_assert_held(&rq->lock);
> > > > +
> > > > + for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
> > > > + entity = rb_entry(rb, typeof(*entity), rb_tree_node);
> > > > +
> > > > + return entity->stats->vruntime; /* Unlocked read */
> > >
> > > Seems the read is unlocked because we just don't care about it racing?
> >
> > If there is a platform which tears ktime_t writes I suppose this could
> > read garbage. I am not sure if there is. Perhaps safer to add the lock
> > around it nevertheless.
>
> I think Sima (+cc) was very explicit about us never to implement our
> own locking or synchronization primitives.
Yeah, doing lockless just in case isn't great, especially if you're not
really sure about the lkmm. I've done a full-lenght talk ranting about
this all and 2 big blog posts, here's all the links:
https://blog.ffwll.ch/2023/07/eoss-prague-locking-engineering.html
The above discussion definitely doesn't inspire the cozy confidence that
this is justified by perf data and engineered by people who know the
ins&outs of how to do lockless stuff under the lkmm. And I know that the
current drm/sched code plays a bit fast&loose in this regard, but we
should try and at least not make things worse. Which means if we do decide
that lockless is required here, it needs to be engineered and documented
with the required utmost care to make sure it won't bite us too badly some
random time in the future.
Cheers, Sima
> Not locking stuff that can get accessed asynchronously is just a hard
> No-Go.
>
> That you access things here asynchronously is even more confusing
> considering that in the kunit patch you explicitly add READ_ONCE() for
> documentation purposes.
>
> Premature performance optimization is the root of all evil, and think
> about the unlocked runqueue readers. 5 years down the road no one has
> the slightest clue anymore what is supposed to be locked by whom and
> accessed when and how.
>
> At XDC we had an entire room of highly experienced experts and we had
> no clue anymore.
>
>
> My need to establish in DRM that everything accessed by more than 1 CPU
> at the same time always has to be locked.
>
> Alternatives (memory barriers, RCU, atomics, read once) are permitted
> if one can give really good justification (performance measurements)
> and can provide a clear and clean concept.
>
> I'd have to consult the C standard, but I think just reading from
> something that is not an atomic might even be UB.
>
>
> (That said, all platforms Linux runs on don't tear integers AFAIK.
> Otherwise RCU couldn't work.)
>
>
> > > > + }
> > > > +
> > > > + return 0;
> > > > +}
> > > > +
> > > > +static void
> > > > +drm_sched_entity_save_vruntime(struct drm_sched_entity *entity,
> > > > + ktime_t min_vruntime)
> > > > +{
> > > > + struct drm_sched_entity_stats *stats = entity->stats;
> > >
> > > Unlocked read?
> >
> > This one isn't, entity->stats never changes from drm_sched_entity_init()
> > to the end.
> >
> > > > + ktime_t vruntime;
> > > > +
> > > > + spin_lock(&stats->lock);
> > > > + vruntime = stats->vruntime;
> > > > + if (min_vruntime && vruntime > min_vruntime)
> > > > + vruntime = ktime_sub(vruntime, min_vruntime);
> > > > + else
> > > > + vruntime = 0;
> > > > + stats->vruntime = vruntime;
> > > > + spin_unlock(&stats->lock);
> > > > +}
> > > > +
> > > > +static ktime_t
> > > > +drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
> > > > + ktime_t min_vruntime,
> > > > + enum drm_sched_priority rq_prio)
> > > > +{
> > > > + struct drm_sched_entity_stats *stats = entity->stats;
> > > > + enum drm_sched_priority prio = entity->priority;
> > > > + ktime_t vruntime;
> > > > +
> > > > + BUILD_BUG_ON(DRM_SCHED_PRIORITY_NORMAL < DRM_SCHED_PRIORITY_HIGH);
> > > > +
> > > > + spin_lock(&stats->lock);
> > > > + vruntime = stats->vruntime;
> > > > +
> > > > + /*
> > > > + * Special handling for entities which were picked from the top of the
> > > > + * queue and are now re-joining the top with another one already there.
> > > > + */
> > > > + if (!vruntime && min_vruntime) {
> > > > + if (prio > rq_prio) {
> > > > + /*
> > > > + * Lower priority should not overtake higher when re-
> > > > + * joining at the top of the queue.
> > > > + */
> > > > + vruntime = us_to_ktime(prio - rq_prio);
> > > > + } else if (prio < rq_prio) {
> > > > + /*
> > > > + * Higher priority can go first.
> > > > + */
> > > > + vruntime = -us_to_ktime(rq_prio - prio);
> > > > + }
> > > > + }
> > > > +
> > > > + /*
> > > > + * Restore saved relative position in the queue.
> > > > + */
> > > > + vruntime = ktime_add(min_vruntime, vruntime);
> > > > +
> > > > + stats->vruntime = vruntime;
> > > > + spin_unlock(&stats->lock);
> > > > +
> > > > + return vruntime;
> > > > +}
> > > > +
> > > > +static ktime_t drm_sched_entity_update_vruntime(struct drm_sched_entity *entity)
> > > > +{
> > > > + static const unsigned int shift[] = {
> > > > + [DRM_SCHED_PRIORITY_KERNEL] = 1,
> > > > + [DRM_SCHED_PRIORITY_HIGH] = 2,
> > > > + [DRM_SCHED_PRIORITY_NORMAL] = 4,
> > > > + [DRM_SCHED_PRIORITY_LOW] = 7,
> > >
> > > Are those numbers copied from CPU CFS? Are they from an academic paper?
> > > Or have you measured that these generate best results?
> > >
> > > Some hint about their background here would be nice.
> >
> > Finger in the air I'm afraid.
>
> You mean you just tried some numbers?
>
> That's OK, but you could state so here. In a nicer formulation.
>
> > > > + };
> > > > + struct drm_sched_entity_stats *stats = entity->stats;
> > > > + ktime_t runtime, prev;
> > > > +
> > > > + spin_lock(&stats->lock);
> > > > + prev = stats->prev_runtime;
> > > > + runtime = stats->runtime;
> > > > + stats->prev_runtime = runtime;
> > > > + runtime = ktime_add_ns(stats->vruntime,
> > > > + ktime_to_ns(ktime_sub(runtime, prev)) <<
> > > > + shift[entity->priority]);
> > > > + stats->vruntime = runtime;
> > > > + spin_unlock(&stats->lock);
> > > > +
> > > > + return runtime;
> > > > +}
> > > > +
> > > > +static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
> > > > +{
> > > > + return drm_sched_entity_update_vruntime(entity);
> > > > }
> > > >
> > > > /**
> > > > @@ -99,8 +227,14 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> > > > list_add_tail(&entity->list, &rq->entities);
> > > > }
> > > >
> > > > - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> > > > + ts = drm_sched_rq_get_min_vruntime(rq);
> > > > + ts = drm_sched_entity_restore_vruntime(entity, ts,
> > > > + rq->head_prio);
> > > > + } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
> > > > ts = entity->rr_ts;
> > > > + }
> > > > +
> > > > drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > >
> > > > spin_unlock(&rq->lock);
> > > > @@ -173,7 +307,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> > > > if (next_job) {
> > > > ktime_t ts;
> > > >
> > > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
> > > > + ts = drm_sched_entity_get_job_ts(entity);
> > > > + else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > >
> > > Could the git diff here and above be kept smaller by reversing the
> > > order of 'if' and 'else if'?
> >
> > Maybe but I liked having the best policy first. Can change if you want.
>
> It's optional.
>
>
> P.
>
> >
> > >
> > > > ts = next_job->submit_ts;
> > > > else
> > > > ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > > @@ -181,6 +317,13 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> > > > drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > > } else {
> > > > drm_sched_rq_remove_fifo_locked(entity, rq);
> > > > +
> > > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> > > > + ktime_t min_vruntime;
> > > > +
> > > > + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
> > > > + drm_sched_entity_save_vruntime(entity, min_vruntime);
> > > > + }
> > > > }
> > > > spin_unlock(&rq->lock);
> > > > spin_unlock(&entity->lock);
> > > > diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> > > > index 93d0b7224a57..bc25508a6ff6 100644
> > > > --- a/include/drm/gpu_scheduler.h
> > > > +++ b/include/drm/gpu_scheduler.h
> > > > @@ -150,6 +150,11 @@ struct drm_sched_entity {
> > > > */
> > > > enum drm_sched_priority priority;
> > > >
> > > > + /**
> > > > + * @rq_priority: Run-queue priority
> > > > + */
> > > > + enum drm_sched_priority rq_priority;
> > > > +
> > >
> > > AFAIR that's just a temporary addition and will be simplified later.
> > > Still, would probably be neat to be more obvious about why we now have
> > > two priorities.
> > >
> > > > /**
> > > > * @rr_ts:
> > > > *
> > > > @@ -254,10 +259,11 @@ struct drm_sched_entity {
> > > > * struct drm_sched_rq - queue of entities to be scheduled.
> > > > *
> > > > * @sched: the scheduler to which this rq belongs to.
> > > > - * @lock: protects @entities, @rb_tree_root and @rr_ts.
> > > > + * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
> > > > * @rr_ts: monotonically incrementing fake timestamp for RR mode
> > > > * @entities: list of the entities to be scheduled.
> > > > * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
> > > > + * @head_prio: priority of the top tree element
> > > > *
> > > > * Run queue is a set of entities scheduling command submissions for
> > > > * one specific ring. It implements the scheduling policy that selects
> > > > @@ -271,6 +277,7 @@ struct drm_sched_rq {
> > > > ktime_t rr_ts;
> > > > struct list_head entities;
> > > > struct rb_root_cached rb_tree_root;
> > > > + enum drm_sched_priority head_prio;
> > > > };
> > > >
> > > > /**
> > > > @@ -563,8 +570,10 @@ struct drm_sched_backend_ops {
> > > > * @credit_count: the current credit count of this scheduler
> > > > * @timeout: the time after which a job is removed from the scheduler.
> > > > * @name: name of the ring for which this scheduler is being used.
> > > > - * @num_rqs: Number of run-queues. This is at most DRM_SCHED_PRIORITY_COUNT,
> > > > - * as there's usually one run-queue per priority, but could be less.
> > > > + * @num_user_rqs: Number of run-queues. This is at most
> > > > + * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
> > > > + * priority, but could be less.
> > > > + * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
> > >
> > > Alright, so that seems to be what I was looking for above?
> >
> > Yep.
> >
> > Regards,
> >
> > Tvrtko
> >
> > > > * @sched_rq: An allocated array of run-queues of size @num_rqs;
> > > > * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
> > > > * waits on this wait queue until all the scheduled jobs are
> > > > @@ -597,6 +606,7 @@ struct drm_gpu_scheduler {
> > > > long timeout;
> > > > const char *name;
> > > > u32 num_rqs;
> > > > + u32 num_user_rqs;
> > > > struct drm_sched_rq **sched_rq;
> > > > wait_queue_head_t job_scheduled;
> > > > atomic64_t job_id_count;
> > >
> >
>
--
Simona Vetter
Software Engineer
http://blog.ffwll.ch
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-14 14:32 ` Simona Vetter
@ 2025-10-14 14:58 ` Tvrtko Ursulin
2025-10-16 7:06 ` Philipp Stanner
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-14 14:58 UTC (permalink / raw)
To: Simona Vetter, phasta
Cc: amd-gfx, dri-devel, kernel-dev, Christian König,
Danilo Krummrich, Matthew Brost, Pierre-Eric Pelloux-Prayer,
Simona Vetter
On 14/10/2025 15:32, Simona Vetter wrote:
> On Tue, Oct 14, 2025 at 04:02:52PM +0200, Philipp Stanner wrote:
>> On Tue, 2025-10-14 at 13:56 +0100, Tvrtko Ursulin wrote:
>>>
>>> On 14/10/2025 11:27, Philipp Stanner wrote:
>>>> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>>>>> Fair scheduling policy is built upon the same concepts as the well known
>>>>
>>>> nit: "The fair …"
>>>>
>>>> Or maybe better: call it FAIR, being congruent with the FIFO below.
>>>>
>>>>> CFS kernel scheduler - entity run queue is sorted by the virtual GPU time
>>>>
>>>> nit: Call it "CPU scheduler". The GPU scheduler is a kernel scheduler,
>>>> too.
>>>>
>>>>> consumed by entities in a way that the entity with least vruntime runs
>>>>> first.
>>>>>
>>>>> It is able to avoid total priority starvation, which is one of the
>>>>> problems with FIFO, and it also does not need for per priority run queues.
>>>>> As it scales the actual GPU runtime by an exponential factor as the
>>>>> priority decreases, therefore the virtual runtime for low priority
>>>>
>>>> "therefore," is not necessary because of the sentence starting with
>>>> "As"
>>>
>>> Done x3 above.
>>>
>>>>
>>>>> entities grows faster than for normal priority, pushing them further down
>>>>> the runqueue order for the same real GPU time spent.
>>>>>
>>>>> Apart from this fundamental fairness, fair policy is especially strong in
>>>>> oversubscription workloads where it is able to give more GPU time to short
>>>>> and bursty workloads when they are running in parallel with GPU heavy
>>>>> clients submitting deep job queues.
>>>>>
>>>>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>>>>> Cc: Christian König <christian.koenig@amd.com>
>>>>> Cc: Danilo Krummrich <dakr@kernel.org>
>>>>> Cc: Matthew Brost <matthew.brost@intel.com>
>>>>> Cc: Philipp Stanner <phasta@kernel.org>
>>>>> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
>>>>> ---
>>>>> drivers/gpu/drm/scheduler/sched_entity.c | 28 ++--
>>>>> drivers/gpu/drm/scheduler/sched_internal.h | 9 +-
>>>>> drivers/gpu/drm/scheduler/sched_main.c | 12 +-
>>>>> drivers/gpu/drm/scheduler/sched_rq.c | 147 ++++++++++++++++++++-
>>>>> include/drm/gpu_scheduler.h | 16 ++-
>>>>> 5 files changed, 191 insertions(+), 21 deletions(-)
>>>>>
>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>>>>> index 04ce8b7d436b..58f51875547a 100644
>>>>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>>>>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>>>>> @@ -108,6 +108,8 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>>>>> entity->guilty = guilty;
>>>>> entity->num_sched_list = num_sched_list;
>>>>> entity->priority = priority;
>>>>> + entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
>>>>> + DRM_SCHED_PRIORITY_KERNEL : priority;
>>>>> /*
>>>>> * It's perfectly valid to initialize an entity without having a valid
>>>>> * scheduler attached. It's just not valid to use the scheduler before it
>>>>> @@ -124,17 +126,23 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>>>>> */
>>>>> pr_warn("%s: called with uninitialized scheduler\n", __func__);
>>>>> } else if (num_sched_list) {
>>>>> - /* The "priority" of an entity cannot exceed the number of run-queues of a
>>>>> - * scheduler. Protect against num_rqs being 0, by converting to signed. Choose
>>>>> - * the lowest priority available.
>>>>> + enum drm_sched_priority p = entity->priority;
>>>>> +
>>>>> + /*
>>>>> + * The "priority" of an entity cannot exceed the number of
>>>>> + * run-queues of a scheduler. Protect against num_rqs being 0,
>>>>> + * by converting to signed. Choose the lowest priority
>>>>> + * available.
>>>>> */
>>>>> - if (entity->priority >= sched_list[0]->num_rqs) {
>>>>> - dev_err(sched_list[0]->dev, "entity has out-of-bounds priority: %u. num_rqs: %u\n",
>>>>> - entity->priority, sched_list[0]->num_rqs);
>>>>> - entity->priority = max_t(s32, (s32) sched_list[0]->num_rqs - 1,
>>>>> - (s32) DRM_SCHED_PRIORITY_KERNEL);
>>>>> + if (p >= sched_list[0]->num_user_rqs) {
>>>>> + dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
>>>>> + p, sched_list[0]->num_user_rqs);
>>>>> + p = max_t(s32,
>>>>> + (s32)sched_list[0]->num_user_rqs - 1,
>>>>> + (s32)DRM_SCHED_PRIORITY_KERNEL);
>>>>> + entity->priority = p;
>>>>> }
>>>>> - entity->rq = sched_list[0]->sched_rq[entity->priority];
>>>>> + entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
>>>>
>>>> That rename could be a separate patch, couldn't it? As I said before
>>>> it's always great to have general code improvements as separate patches
>>>> since it makes it far easier to review (i.e.: detect / see) core
>>>> functionality changes.
>>>
>>> No, this is the new struct member only added in this patch.
>>>
>>>>
>>>>> }
>>>>>
>>>>> init_completion(&entity->entity_idle);
>>>>> @@ -567,7 +575,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
>>>>>
>>>>> spin_lock(&entity->lock);
>>>>> sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
>>>>> - rq = sched ? sched->sched_rq[entity->priority] : NULL;
>>>>> + rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
>>>>> if (rq != entity->rq) {
>>>>> drm_sched_rq_remove_entity(entity->rq, entity);
>>>>> entity->rq = rq;
>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>>>>> index 1132a771aa37..c94e38acc6f2 100644
>>>>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>>>>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>>>>> @@ -18,18 +18,23 @@
>>>>> * @kref: reference count for the object.
>>>>> * @lock: lock guarding the @runtime updates.
>>>>> * @runtime: time entity spent on the GPU.
>>>>> + * @prev_runtime: previous @runtime used to get the runtime delta
>>>>> + * @vruntime: virtual runtime as accumulated by the fair algorithm
>>>>
>>>> The other docstrings are all terminated with a full stop '.'
>>>
>>> Yep I fixed the whole series in this respect already as response to one
>>> of your earlier comments.
>>>
>>>>
>>>>> */
>>>>> struct drm_sched_entity_stats {
>>>>> struct kref kref;
>>>>> spinlock_t lock;
>>>>> ktime_t runtime;
>>>>> + ktime_t prev_runtime;
>>>>> + u64 vruntime;
>>>>> };
>>>>>
>>>>> /* Used to choose between FIFO and RR job-scheduling */
>>>>> extern int drm_sched_policy;
>>>>>
>>>>> -#define DRM_SCHED_POLICY_RR 0
>>>>> -#define DRM_SCHED_POLICY_FIFO 1
>>>>> +#define DRM_SCHED_POLICY_RR 0
>>>>> +#define DRM_SCHED_POLICY_FIFO 1
>>>>> +#define DRM_SCHED_POLICY_FAIR 2
>>>>>
>>>>
>>>> Formatting unnecessarily increases the git diff.
>>>>
>>>> Let's die the death of having the old formatting. As far as it's
>>>> forseeable FAIR will be the last policy for the classic drm_sched
>>>> anyways, so no future changes here expected.
>>>
>>> Strange I thought I fixed this already in the previous respin. Re-fixed
>>> and verfied.
>>>>> bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
>>>>> struct drm_sched_entity *entity);
>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>>>>> index f180d292bf66..8d8f9c8411f5 100644
>>>>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>>>>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>>>>> @@ -90,7 +90,7 @@ int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
>>>>> * DOC: sched_policy (int)
>>>>> * Used to override default entities scheduling policy in a run queue.
>>>>> */
>>>>> -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO (default).");
>>>>> +MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
>>>>> module_param_named(sched_policy, drm_sched_policy, int, 0444);
>>>>>
>>>>> static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
>>>>> @@ -1132,11 +1132,15 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>>>>> sched->own_submit_wq = true;
>>>>> }
>>>>>
>>>>> - sched->sched_rq = kmalloc_array(args->num_rqs, sizeof(*sched->sched_rq),
>>>>> + sched->num_user_rqs = args->num_rqs;
>>>>> + sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
>>>>> + args->num_rqs : 1;
>>>>> + sched->sched_rq = kmalloc_array(sched->num_rqs,
>>>>> + sizeof(*sched->sched_rq),
>>>>
>>>> Don't reformat that for the git diff? Line doesn't seem crazily long.
>>>
>>> Ok.
>>>
>>>>
>>>>> GFP_KERNEL | __GFP_ZERO);
>>>>> if (!sched->sched_rq)
>>>>> goto Out_check_own;
>>>>> - sched->num_rqs = args->num_rqs;
>>>>> +
>>>>> for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>>>>> sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
>>>>> if (!sched->sched_rq[i])
>>>>> @@ -1278,7 +1282,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
>>>>> if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
>>>>> atomic_inc(&bad->karma);
>>>>>
>>>>> - for (i = DRM_SCHED_PRIORITY_HIGH; i < sched->num_rqs; i++) {
>>>>> + for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>>>>
>>>> Give me a pointer here quickly – what's that about?
>>>
>>> Since FAIR stuffs everthing into a single run queue it needs to start
>>> looking into it when looking for the guilty context. FIFO and RR are not
>>> affected since they will not find the context with the kernel priority
>>> in the kernel run queue anyway.
>>>
>>>>
>>>>> struct drm_sched_rq *rq = sched->sched_rq[i];
>>>>>
>>>>> spin_lock(&rq->lock);
>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
>>>>> index 09d316bc3dfa..b868c794cc9d 100644
>>>>> --- a/drivers/gpu/drm/scheduler/sched_rq.c
>>>>> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
>>>>> @@ -16,6 +16,24 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
>>>>> return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
>>>>> }
>>>>>
>>>>> +static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
>>>>> +{
>>>>> + enum drm_sched_priority prio = -1;
>>>>> + struct rb_node *rb;
>>>>
>>>> nit:
>>>> "node" might be a bitter name than rb. When iterating over a list we
>>>> also typically call the iterator sth like "head" and not "list".
>>>>
>>>> But no hard feelings on that change.
>>>
>>> I am following the convention from drm_sched_rq_select_entity_fifo() to
>>> avoid someone complaining I was diverging from the pattern established
>>> in the same file. ;)
>>
>> Don't worry, I will always cover your back against such people!
>>
>>>>> +
>>>>> + lockdep_assert_held(&rq->lock);
>>>>> +
>>>>> + rb = rb_first_cached(&rq->rb_tree_root);
>>>>> + if (rb) {
>>>>> + struct drm_sched_entity *entity =
>>>>> + rb_entry(rb, typeof(*entity), rb_tree_node);
>>>>> +
>>>>> + prio = entity->priority; /* Unlocked read */
>>>>
>>>> Why an unlocked read? Why is that OK? The comment could detail that.
>>>
>>> Fair point, expanded the explanation.
>>>>> + }
>>>>> +
>>>>> + rq->head_prio = prio;
>>>>> +}
>>>>> +
>>>>> static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>>>>> struct drm_sched_rq *rq)
>>>>> {
>>>>> @@ -25,6 +43,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>>>>> if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
>>>>> rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
>>>>> RB_CLEAR_NODE(&entity->rb_tree_node);
>>>>> + drm_sched_rq_update_prio(rq);
>>>>> }
>>>>> }
>>>>>
>>>>> @@ -46,6 +65,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>>>
>>>>> rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
>>>>> drm_sched_entity_compare_before);
>>>>> + drm_sched_rq_update_prio(rq);
>>>>> }
>>>>>
>>>>> /**
>>>>> @@ -63,6 +83,114 @@ void drm_sched_rq_init(struct drm_sched_rq *rq,
>>>>> INIT_LIST_HEAD(&rq->entities);
>>>>> rq->rb_tree_root = RB_ROOT_CACHED;
>>>>> rq->sched = sched;
>>>>> + rq->head_prio = -1;
>>>>
>>>> head_prio is an enum.
>>>>
>>>> Better to give the enum an entry like:
>>>>
>>>> PRIO_INVALID = -1,
>>>
>>> Ok.
>>>
>>>>
>>>>> +}
>>>>> +
>>>>> +static ktime_t
>>>>> +drm_sched_rq_get_min_vruntime(struct drm_sched_rq *rq)
>>>>> +{
>>>>> + struct drm_sched_entity *entity;
>>>>> + struct rb_node *rb;
>>>>> +
>>>>> + lockdep_assert_held(&rq->lock);
>>>>> +
>>>>> + for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
>>>>> + entity = rb_entry(rb, typeof(*entity), rb_tree_node);
>>>>> +
>>>>> + return entity->stats->vruntime; /* Unlocked read */
>>>>
>>>> Seems the read is unlocked because we just don't care about it racing?
>>>
>>> If there is a platform which tears ktime_t writes I suppose this could
>>> read garbage. I am not sure if there is. Perhaps safer to add the lock
>>> around it nevertheless.
>>
>> I think Sima (+cc) was very explicit about us never to implement our
>> own locking or synchronization primitives.
>
> Yeah, doing lockless just in case isn't great, especially if you're not
> really sure about the lkmm. I've done a full-lenght talk ranting about
> this all and 2 big blog posts, here's all the links:
>
> https://blog.ffwll.ch/2023/07/eoss-prague-locking-engineering.html
>
> The above discussion definitely doesn't inspire the cozy confidence that
> this is justified by perf data and engineered by people who know the
> ins&outs of how to do lockless stuff under the lkmm. And I know that the
> current drm/sched code plays a bit fast&loose in this regard, but we
> should try and at least not make things worse. Which means if we do decide
> that lockless is required here, it needs to be engineered and documented
> with the required utmost care to make sure it won't bite us too badly some
> random time in the future.
There isn't any lockless algorithms here, nor any performance claims. It
is just a read of a ktime_t. I can add the _existing_ entity->stats lock
around it just as well for those warm and fuzzy feelings.
Regards,
Tvrtko
>> Not locking stuff that can get accessed asynchronously is just a hard
>> No-Go.
>>
>> That you access things here asynchronously is even more confusing
>> considering that in the kunit patch you explicitly add READ_ONCE() for
>> documentation purposes.
>>
>> Premature performance optimization is the root of all evil, and think
>> about the unlocked runqueue readers. 5 years down the road no one has
>> the slightest clue anymore what is supposed to be locked by whom and
>> accessed when and how.
>>
>> At XDC we had an entire room of highly experienced experts and we had
>> no clue anymore.
>>
>>
>> My need to establish in DRM that everything accessed by more than 1 CPU
>> at the same time always has to be locked.
>>
>> Alternatives (memory barriers, RCU, atomics, read once) are permitted
>> if one can give really good justification (performance measurements)
>> and can provide a clear and clean concept.
>>
>> I'd have to consult the C standard, but I think just reading from
>> something that is not an atomic might even be UB.
>>
>>
>> (That said, all platforms Linux runs on don't tear integers AFAIK.
>> Otherwise RCU couldn't work.)
>>
>>
>>>>> + }
>>>>> +
>>>>> + return 0;
>>>>> +}
>>>>> +
>>>>> +static void
>>>>> +drm_sched_entity_save_vruntime(struct drm_sched_entity *entity,
>>>>> + ktime_t min_vruntime)
>>>>> +{
>>>>> + struct drm_sched_entity_stats *stats = entity->stats;
>>>>
>>>> Unlocked read?
>>>
>>> This one isn't, entity->stats never changes from drm_sched_entity_init()
>>> to the end.
>>>
>>>>> + ktime_t vruntime;
>>>>> +
>>>>> + spin_lock(&stats->lock);
>>>>> + vruntime = stats->vruntime;
>>>>> + if (min_vruntime && vruntime > min_vruntime)
>>>>> + vruntime = ktime_sub(vruntime, min_vruntime);
>>>>> + else
>>>>> + vruntime = 0;
>>>>> + stats->vruntime = vruntime;
>>>>> + spin_unlock(&stats->lock);
>>>>> +}
>>>>> +
>>>>> +static ktime_t
>>>>> +drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
>>>>> + ktime_t min_vruntime,
>>>>> + enum drm_sched_priority rq_prio)
>>>>> +{
>>>>> + struct drm_sched_entity_stats *stats = entity->stats;
>>>>> + enum drm_sched_priority prio = entity->priority;
>>>>> + ktime_t vruntime;
>>>>> +
>>>>> + BUILD_BUG_ON(DRM_SCHED_PRIORITY_NORMAL < DRM_SCHED_PRIORITY_HIGH);
>>>>> +
>>>>> + spin_lock(&stats->lock);
>>>>> + vruntime = stats->vruntime;
>>>>> +
>>>>> + /*
>>>>> + * Special handling for entities which were picked from the top of the
>>>>> + * queue and are now re-joining the top with another one already there.
>>>>> + */
>>>>> + if (!vruntime && min_vruntime) {
>>>>> + if (prio > rq_prio) {
>>>>> + /*
>>>>> + * Lower priority should not overtake higher when re-
>>>>> + * joining at the top of the queue.
>>>>> + */
>>>>> + vruntime = us_to_ktime(prio - rq_prio);
>>>>> + } else if (prio < rq_prio) {
>>>>> + /*
>>>>> + * Higher priority can go first.
>>>>> + */
>>>>> + vruntime = -us_to_ktime(rq_prio - prio);
>>>>> + }
>>>>> + }
>>>>> +
>>>>> + /*
>>>>> + * Restore saved relative position in the queue.
>>>>> + */
>>>>> + vruntime = ktime_add(min_vruntime, vruntime);
>>>>> +
>>>>> + stats->vruntime = vruntime;
>>>>> + spin_unlock(&stats->lock);
>>>>> +
>>>>> + return vruntime;
>>>>> +}
>>>>> +
>>>>> +static ktime_t drm_sched_entity_update_vruntime(struct drm_sched_entity *entity)
>>>>> +{
>>>>> + static const unsigned int shift[] = {
>>>>> + [DRM_SCHED_PRIORITY_KERNEL] = 1,
>>>>> + [DRM_SCHED_PRIORITY_HIGH] = 2,
>>>>> + [DRM_SCHED_PRIORITY_NORMAL] = 4,
>>>>> + [DRM_SCHED_PRIORITY_LOW] = 7,
>>>>
>>>> Are those numbers copied from CPU CFS? Are they from an academic paper?
>>>> Or have you measured that these generate best results?
>>>>
>>>> Some hint about their background here would be nice.
>>>
>>> Finger in the air I'm afraid.
>>
>> You mean you just tried some numbers?
>>
>> That's OK, but you could state so here. In a nicer formulation.
>>
>>>>> + };
>>>>> + struct drm_sched_entity_stats *stats = entity->stats;
>>>>> + ktime_t runtime, prev;
>>>>> +
>>>>> + spin_lock(&stats->lock);
>>>>> + prev = stats->prev_runtime;
>>>>> + runtime = stats->runtime;
>>>>> + stats->prev_runtime = runtime;
>>>>> + runtime = ktime_add_ns(stats->vruntime,
>>>>> + ktime_to_ns(ktime_sub(runtime, prev)) <<
>>>>> + shift[entity->priority]);
>>>>> + stats->vruntime = runtime;
>>>>> + spin_unlock(&stats->lock);
>>>>> +
>>>>> + return runtime;
>>>>> +}
>>>>> +
>>>>> +static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
>>>>> +{
>>>>> + return drm_sched_entity_update_vruntime(entity);
>>>>> }
>>>>>
>>>>> /**
>>>>> @@ -99,8 +227,14 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
>>>>> list_add_tail(&entity->list, &rq->entities);
>>>>> }
>>>>>
>>>>> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>>>>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
>>>>> + ts = drm_sched_rq_get_min_vruntime(rq);
>>>>> + ts = drm_sched_entity_restore_vruntime(entity, ts,
>>>>> + rq->head_prio);
>>>>> + } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
>>>>> ts = entity->rr_ts;
>>>>> + }
>>>>> +
>>>>> drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>>>>
>>>>> spin_unlock(&rq->lock);
>>>>> @@ -173,7 +307,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>>>>> if (next_job) {
>>>>> ktime_t ts;
>>>>>
>>>>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>>>>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
>>>>> + ts = drm_sched_entity_get_job_ts(entity);
>>>>> + else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>>>>
>>>> Could the git diff here and above be kept smaller by reversing the
>>>> order of 'if' and 'else if'?
>>>
>>> Maybe but I liked having the best policy first. Can change if you want.
>>
>> It's optional.
>>
>>
>> P.
>>
>>>
>>>>
>>>>> ts = next_job->submit_ts;
>>>>> else
>>>>> ts = drm_sched_rq_get_rr_ts(rq, entity);
>>>>> @@ -181,6 +317,13 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>>>>> drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>>>> } else {
>>>>> drm_sched_rq_remove_fifo_locked(entity, rq);
>>>>> +
>>>>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
>>>>> + ktime_t min_vruntime;
>>>>> +
>>>>> + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
>>>>> + drm_sched_entity_save_vruntime(entity, min_vruntime);
>>>>> + }
>>>>> }
>>>>> spin_unlock(&rq->lock);
>>>>> spin_unlock(&entity->lock);
>>>>> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
>>>>> index 93d0b7224a57..bc25508a6ff6 100644
>>>>> --- a/include/drm/gpu_scheduler.h
>>>>> +++ b/include/drm/gpu_scheduler.h
>>>>> @@ -150,6 +150,11 @@ struct drm_sched_entity {
>>>>> */
>>>>> enum drm_sched_priority priority;
>>>>>
>>>>> + /**
>>>>> + * @rq_priority: Run-queue priority
>>>>> + */
>>>>> + enum drm_sched_priority rq_priority;
>>>>> +
>>>>
>>>> AFAIR that's just a temporary addition and will be simplified later.
>>>> Still, would probably be neat to be more obvious about why we now have
>>>> two priorities.
>>>>
>>>>> /**
>>>>> * @rr_ts:
>>>>> *
>>>>> @@ -254,10 +259,11 @@ struct drm_sched_entity {
>>>>> * struct drm_sched_rq - queue of entities to be scheduled.
>>>>> *
>>>>> * @sched: the scheduler to which this rq belongs to.
>>>>> - * @lock: protects @entities, @rb_tree_root and @rr_ts.
>>>>> + * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
>>>>> * @rr_ts: monotonically incrementing fake timestamp for RR mode
>>>>> * @entities: list of the entities to be scheduled.
>>>>> * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
>>>>> + * @head_prio: priority of the top tree element
>>>>> *
>>>>> * Run queue is a set of entities scheduling command submissions for
>>>>> * one specific ring. It implements the scheduling policy that selects
>>>>> @@ -271,6 +277,7 @@ struct drm_sched_rq {
>>>>> ktime_t rr_ts;
>>>>> struct list_head entities;
>>>>> struct rb_root_cached rb_tree_root;
>>>>> + enum drm_sched_priority head_prio;
>>>>> };
>>>>>
>>>>> /**
>>>>> @@ -563,8 +570,10 @@ struct drm_sched_backend_ops {
>>>>> * @credit_count: the current credit count of this scheduler
>>>>> * @timeout: the time after which a job is removed from the scheduler.
>>>>> * @name: name of the ring for which this scheduler is being used.
>>>>> - * @num_rqs: Number of run-queues. This is at most DRM_SCHED_PRIORITY_COUNT,
>>>>> - * as there's usually one run-queue per priority, but could be less.
>>>>> + * @num_user_rqs: Number of run-queues. This is at most
>>>>> + * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
>>>>> + * priority, but could be less.
>>>>> + * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
>>>>
>>>> Alright, so that seems to be what I was looking for above?
>>>
>>> Yep.
>>>
>>> Regards,
>>>
>>> Tvrtko
>>>
>>>>> * @sched_rq: An allocated array of run-queues of size @num_rqs;
>>>>> * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
>>>>> * waits on this wait queue until all the scheduled jobs are
>>>>> @@ -597,6 +606,7 @@ struct drm_gpu_scheduler {
>>>>> long timeout;
>>>>> const char *name;
>>>>> u32 num_rqs;
>>>>> + u32 num_user_rqs;
>>>>> struct drm_sched_rq **sched_rq;
>>>>> wait_queue_head_t job_scheduled;
>>>>> atomic64_t job_id_count;
>>>>
>>>
>>
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-14 14:58 ` Tvrtko Ursulin
@ 2025-10-16 7:06 ` Philipp Stanner
2025-10-16 8:42 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-16 7:06 UTC (permalink / raw)
To: Tvrtko Ursulin, Simona Vetter, phasta
Cc: amd-gfx, dri-devel, kernel-dev, Christian König,
Danilo Krummrich, Matthew Brost, Pierre-Eric Pelloux-Prayer,
Simona Vetter
On Tue, 2025-10-14 at 15:58 +0100, Tvrtko Ursulin wrote:
>
> On 14/10/2025 15:32, Simona Vetter wrote:
> > On Tue, Oct 14, 2025 at 04:02:52PM +0200, Philipp Stanner wrote:
> > > On Tue, 2025-10-14 at 13:56 +0100, Tvrtko Ursulin wrote:
> > > >
> > > > On 14/10/2025 11:27, Philipp Stanner wrote:
> > > > > On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> > > > > > Fair scheduling policy is built upon the same concepts as the well known
> > > > >
> > > > > nit: "The fair …"
> > > > >
> > > > > Or maybe better: call it FAIR, being congruent with the FIFO below.
> > > > >
> > > > > > CFS kernel scheduler - entity run queue is sorted by the virtual GPU time
> > > > >
> > > > > nit: Call it "CPU scheduler". The GPU scheduler is a kernel scheduler,
> > > > > too.
> > > > >
> > > > > > consumed by entities in a way that the entity with least vruntime runs
> > > > > > first.
> > > > > >
> > > > > > It is able to avoid total priority starvation, which is one of the
> > > > > > problems with FIFO, and it also does not need for per priority run queues.
> > > > > > As it scales the actual GPU runtime by an exponential factor as the
> > > > > > priority decreases, therefore the virtual runtime for low priority
> > > > >
> > > > > "therefore," is not necessary because of the sentence starting with
> > > > > "As"
> > > >
> > > > Done x3 above.
> > > >
> > > > >
> > > > > > entities grows faster than for normal priority, pushing them further down
> > > > > > the runqueue order for the same real GPU time spent.
> > > > > >
> > > > > > Apart from this fundamental fairness, fair policy is especially strong in
> > > > > > oversubscription workloads where it is able to give more GPU time to short
> > > > > > and bursty workloads when they are running in parallel with GPU heavy
> > > > > > clients submitting deep job queues.
> > > > > >
> > > > > > Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> > > > > > Cc: Christian König <christian.koenig@amd.com>
> > > > > > Cc: Danilo Krummrich <dakr@kernel.org>
> > > > > > Cc: Matthew Brost <matthew.brost@intel.com>
> > > > > > Cc: Philipp Stanner <phasta@kernel.org>
> > > > > > Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
> > > > > > ---
> > > > > > drivers/gpu/drm/scheduler/sched_entity.c | 28 ++--
> > > > > > drivers/gpu/drm/scheduler/sched_internal.h | 9 +-
> > > > > > drivers/gpu/drm/scheduler/sched_main.c | 12 +-
> > > > > > drivers/gpu/drm/scheduler/sched_rq.c | 147 ++++++++++++++++++++-
> > > > > > include/drm/gpu_scheduler.h | 16 ++-
> > > > > > 5 files changed, 191 insertions(+), 21 deletions(-)
> > > > > >
> > > > > > diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > > index 04ce8b7d436b..58f51875547a 100644
> > > > > > --- a/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > > +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> > > > > > @@ -108,6 +108,8 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> > > > > > entity->guilty = guilty;
> > > > > > entity->num_sched_list = num_sched_list;
> > > > > > entity->priority = priority;
> > > > > > + entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
> > > > > > + DRM_SCHED_PRIORITY_KERNEL : priority;
> > > > > > /*
> > > > > > * It's perfectly valid to initialize an entity without having a valid
> > > > > > * scheduler attached. It's just not valid to use the scheduler before it
> > > > > > @@ -124,17 +126,23 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> > > > > > */
> > > > > > pr_warn("%s: called with uninitialized scheduler\n", __func__);
> > > > > > } else if (num_sched_list) {
> > > > > > - /* The "priority" of an entity cannot exceed the number of run-queues of a
> > > > > > - * scheduler. Protect against num_rqs being 0, by converting to signed. Choose
> > > > > > - * the lowest priority available.
> > > > > > + enum drm_sched_priority p = entity->priority;
> > > > > > +
> > > > > > + /*
> > > > > > + * The "priority" of an entity cannot exceed the number of
> > > > > > + * run-queues of a scheduler. Protect against num_rqs being 0,
> > > > > > + * by converting to signed. Choose the lowest priority
> > > > > > + * available.
> > > > > > */
> > > > > > - if (entity->priority >= sched_list[0]->num_rqs) {
> > > > > > - dev_err(sched_list[0]->dev, "entity has out-of-bounds priority: %u. num_rqs: %u\n",
> > > > > > - entity->priority, sched_list[0]->num_rqs);
> > > > > > - entity->priority = max_t(s32, (s32) sched_list[0]->num_rqs - 1,
> > > > > > - (s32) DRM_SCHED_PRIORITY_KERNEL);
> > > > > > + if (p >= sched_list[0]->num_user_rqs) {
> > > > > > + dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
> > > > > > + p, sched_list[0]->num_user_rqs);
> > > > > > + p = max_t(s32,
> > > > > > + (s32)sched_list[0]->num_user_rqs - 1,
> > > > > > + (s32)DRM_SCHED_PRIORITY_KERNEL);
> > > > > > + entity->priority = p;
> > > > > > }
> > > > > > - entity->rq = sched_list[0]->sched_rq[entity->priority];
> > > > > > + entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
> > > > >
> > > > > That rename could be a separate patch, couldn't it? As I said before
> > > > > it's always great to have general code improvements as separate patches
> > > > > since it makes it far easier to review (i.e.: detect / see) core
> > > > > functionality changes.
> > > >
> > > > No, this is the new struct member only added in this patch.
> > > >
> > > > >
> > > > > > }
> > > > > >
> > > > > > init_completion(&entity->entity_idle);
> > > > > > @@ -567,7 +575,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
> > > > > >
> > > > > > spin_lock(&entity->lock);
> > > > > > sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
> > > > > > - rq = sched ? sched->sched_rq[entity->priority] : NULL;
> > > > > > + rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
> > > > > > if (rq != entity->rq) {
> > > > > > drm_sched_rq_remove_entity(entity->rq, entity);
> > > > > > entity->rq = rq;
> > > > > > diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > > index 1132a771aa37..c94e38acc6f2 100644
> > > > > > --- a/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > > +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> > > > > > @@ -18,18 +18,23 @@
> > > > > > * @kref: reference count for the object.
> > > > > > * @lock: lock guarding the @runtime updates.
> > > > > > * @runtime: time entity spent on the GPU.
> > > > > > + * @prev_runtime: previous @runtime used to get the runtime delta
> > > > > > + * @vruntime: virtual runtime as accumulated by the fair algorithm
> > > > >
> > > > > The other docstrings are all terminated with a full stop '.'
> > > >
> > > > Yep I fixed the whole series in this respect already as response to one
> > > > of your earlier comments.
> > > >
> > > > >
> > > > > > */
> > > > > > struct drm_sched_entity_stats {
> > > > > > struct kref kref;
> > > > > > spinlock_t lock;
> > > > > > ktime_t runtime;
> > > > > > + ktime_t prev_runtime;
> > > > > > + u64 vruntime;
> > > > > > };
> > > > > >
> > > > > > /* Used to choose between FIFO and RR job-scheduling */
> > > > > > extern int drm_sched_policy;
> > > > > >
> > > > > > -#define DRM_SCHED_POLICY_RR 0
> > > > > > -#define DRM_SCHED_POLICY_FIFO 1
> > > > > > +#define DRM_SCHED_POLICY_RR 0
> > > > > > +#define DRM_SCHED_POLICY_FIFO 1
> > > > > > +#define DRM_SCHED_POLICY_FAIR 2
> > > > > >
> > > > >
> > > > > Formatting unnecessarily increases the git diff.
> > > > >
> > > > > Let's die the death of having the old formatting. As far as it's
> > > > > forseeable FAIR will be the last policy for the classic drm_sched
> > > > > anyways, so no future changes here expected.
> > > >
> > > > Strange I thought I fixed this already in the previous respin. Re-fixed
> > > > and verfied.
> > > > > > bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> > > > > > struct drm_sched_entity *entity);
> > > > > > diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> > > > > > index f180d292bf66..8d8f9c8411f5 100644
> > > > > > --- a/drivers/gpu/drm/scheduler/sched_main.c
> > > > > > +++ b/drivers/gpu/drm/scheduler/sched_main.c
> > > > > > @@ -90,7 +90,7 @@ int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
> > > > > > * DOC: sched_policy (int)
> > > > > > * Used to override default entities scheduling policy in a run queue.
> > > > > > */
> > > > > > -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO (default).");
> > > > > > +MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
> > > > > > module_param_named(sched_policy, drm_sched_policy, int, 0444);
> > > > > >
> > > > > > static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
> > > > > > @@ -1132,11 +1132,15 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> > > > > > sched->own_submit_wq = true;
> > > > > > }
> > > > > >
> > > > > > - sched->sched_rq = kmalloc_array(args->num_rqs, sizeof(*sched->sched_rq),
> > > > > > + sched->num_user_rqs = args->num_rqs;
> > > > > > + sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
> > > > > > + args->num_rqs : 1;
> > > > > > + sched->sched_rq = kmalloc_array(sched->num_rqs,
> > > > > > + sizeof(*sched->sched_rq),
> > > > >
> > > > > Don't reformat that for the git diff? Line doesn't seem crazily long.
> > > >
> > > > Ok.
> > > >
> > > > >
> > > > > > GFP_KERNEL | __GFP_ZERO);
> > > > > > if (!sched->sched_rq)
> > > > > > goto Out_check_own;
> > > > > > - sched->num_rqs = args->num_rqs;
> > > > > > +
> > > > > > for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> > > > > > sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
> > > > > > if (!sched->sched_rq[i])
> > > > > > @@ -1278,7 +1282,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
> > > > > > if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
> > > > > > atomic_inc(&bad->karma);
> > > > > >
> > > > > > - for (i = DRM_SCHED_PRIORITY_HIGH; i < sched->num_rqs; i++) {
> > > > > > + for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> > > > >
> > > > > Give me a pointer here quickly – what's that about?
> > > >
> > > > Since FAIR stuffs everthing into a single run queue it needs to start
> > > > looking into it when looking for the guilty context. FIFO and RR are not
> > > > affected since they will not find the context with the kernel priority
> > > > in the kernel run queue anyway.
> > > >
> > > > >
> > > > > > struct drm_sched_rq *rq = sched->sched_rq[i];
> > > > > >
> > > > > > spin_lock(&rq->lock);
> > > > > > diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
> > > > > > index 09d316bc3dfa..b868c794cc9d 100644
> > > > > > --- a/drivers/gpu/drm/scheduler/sched_rq.c
> > > > > > +++ b/drivers/gpu/drm/scheduler/sched_rq.c
> > > > > > @@ -16,6 +16,24 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
> > > > > > return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
> > > > > > }
> > > > > >
> > > > > > +static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
> > > > > > +{
> > > > > > + enum drm_sched_priority prio = -1;
> > > > > > + struct rb_node *rb;
> > > > >
> > > > > nit:
> > > > > "node" might be a bitter name than rb. When iterating over a list we
> > > > > also typically call the iterator sth like "head" and not "list".
> > > > >
> > > > > But no hard feelings on that change.
> > > >
> > > > I am following the convention from drm_sched_rq_select_entity_fifo() to
> > > > avoid someone complaining I was diverging from the pattern established
> > > > in the same file. ;)
> > >
> > > Don't worry, I will always cover your back against such people!
> > >
> > > > > > +
> > > > > > + lockdep_assert_held(&rq->lock);
> > > > > > +
> > > > > > + rb = rb_first_cached(&rq->rb_tree_root);
> > > > > > + if (rb) {
> > > > > > + struct drm_sched_entity *entity =
> > > > > > + rb_entry(rb, typeof(*entity), rb_tree_node);
> > > > > > +
> > > > > > + prio = entity->priority; /* Unlocked read */
> > > > >
> > > > > Why an unlocked read? Why is that OK? The comment could detail that.
> > > >
> > > > Fair point, expanded the explanation.
> > > > > > + }
> > > > > > +
> > > > > > + rq->head_prio = prio;
> > > > > > +}
> > > > > > +
> > > > > > static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > > > > struct drm_sched_rq *rq)
> > > > > > {
> > > > > > @@ -25,6 +43,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> > > > > > if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
> > > > > > rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
> > > > > > RB_CLEAR_NODE(&entity->rb_tree_node);
> > > > > > + drm_sched_rq_update_prio(rq);
> > > > > > }
> > > > > > }
> > > > > >
> > > > > > @@ -46,6 +65,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> > > > > >
> > > > > > rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
> > > > > > drm_sched_entity_compare_before);
> > > > > > + drm_sched_rq_update_prio(rq);
> > > > > > }
> > > > > >
> > > > > > /**
> > > > > > @@ -63,6 +83,114 @@ void drm_sched_rq_init(struct drm_sched_rq *rq,
> > > > > > INIT_LIST_HEAD(&rq->entities);
> > > > > > rq->rb_tree_root = RB_ROOT_CACHED;
> > > > > > rq->sched = sched;
> > > > > > + rq->head_prio = -1;
> > > > >
> > > > > head_prio is an enum.
> > > > >
> > > > > Better to give the enum an entry like:
> > > > >
> > > > > PRIO_INVALID = -1,
> > > >
> > > > Ok.
> > > >
> > > > >
> > > > > > +}
> > > > > > +
> > > > > > +static ktime_t
> > > > > > +drm_sched_rq_get_min_vruntime(struct drm_sched_rq *rq)
> > > > > > +{
> > > > > > + struct drm_sched_entity *entity;
> > > > > > + struct rb_node *rb;
> > > > > > +
> > > > > > + lockdep_assert_held(&rq->lock);
> > > > > > +
> > > > > > + for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
> > > > > > + entity = rb_entry(rb, typeof(*entity), rb_tree_node);
> > > > > > +
> > > > > > + return entity->stats->vruntime; /* Unlocked read */
> > > > >
> > > > > Seems the read is unlocked because we just don't care about it racing?
> > > >
> > > > If there is a platform which tears ktime_t writes I suppose this could
> > > > read garbage. I am not sure if there is. Perhaps safer to add the lock
> > > > around it nevertheless.
> > >
> > > I think Sima (+cc) was very explicit about us never to implement our
> > > own locking or synchronization primitives.
> >
> > Yeah, doing lockless just in case isn't great, especially if you're not
> > really sure about the lkmm. I've done a full-lenght talk ranting about
> > this all and 2 big blog posts, here's all the links:
> >
> > https://blog.ffwll.ch/2023/07/eoss-prague-locking-engineering.html
> >
> > The above discussion definitely doesn't inspire the cozy confidence that
> > this is justified by perf data and engineered by people who know the
> > ins&outs of how to do lockless stuff under the lkmm. And I know that the
> > current drm/sched code plays a bit fast&loose in this regard, but we
> > should try and at least not make things worse. Which means if we do decide
> > that lockless is required here, it needs to be engineered and documented
> > with the required utmost care to make sure it won't bite us too badly some
> > random time in the future.
>
> There isn't any lockless algorithms here, nor any performance claims. It
> is just a read of a ktime_t. I can add the _existing_ entity->stats lock
> around it just as well for those warm and fuzzy feelings.
Tvrtko.
This is not about anyone's feelings. It's about not adding undefined
behavior. You cannot know whether these values you access locklessly
will really be loaded each time / loaded correctly. You just literally
admitted that yourself. Even if you knew, there could be a new
architecture in 3 years that loads tearingly. There could be a new
"great" compiler optimization.
That's exactly why they designed atomic_t, which merely capsules an
integer, which one could also "just read".
Something like the issue with the runqueues not being locked for
readers must *never* happen again in drm_sched (or elsewhere). We
discussed that in our workshop at XDC. I think there was mutual
agreement:
Always lock everything, and only use well defined and carefully
engineered alternatives to locking when there is good justification.
P.
>
> Regards,
>
> Tvrtko
>
> > > Not locking stuff that can get accessed asynchronously is just a hard
> > > No-Go.
> > >
> > > That you access things here asynchronously is even more confusing
> > > considering that in the kunit patch you explicitly add READ_ONCE() for
> > > documentation purposes.
> > >
> > > Premature performance optimization is the root of all evil, and think
> > > about the unlocked runqueue readers. 5 years down the road no one has
> > > the slightest clue anymore what is supposed to be locked by whom and
> > > accessed when and how.
> > >
> > > At XDC we had an entire room of highly experienced experts and we had
> > > no clue anymore.
> > >
> > >
> > > My need to establish in DRM that everything accessed by more than 1 CPU
> > > at the same time always has to be locked.
> > >
> > > Alternatives (memory barriers, RCU, atomics, read once) are permitted
> > > if one can give really good justification (performance measurements)
> > > and can provide a clear and clean concept.
> > >
> > > I'd have to consult the C standard, but I think just reading from
> > > something that is not an atomic might even be UB.
> > >
> > >
> > > (That said, all platforms Linux runs on don't tear integers AFAIK.
> > > Otherwise RCU couldn't work.)
> > >
> > >
> > > > > > + }
> > > > > > +
> > > > > > + return 0;
> > > > > > +}
> > > > > > +
> > > > > > +static void
> > > > > > +drm_sched_entity_save_vruntime(struct drm_sched_entity *entity,
> > > > > > + ktime_t min_vruntime)
> > > > > > +{
> > > > > > + struct drm_sched_entity_stats *stats = entity->stats;
> > > > >
> > > > > Unlocked read?
> > > >
> > > > This one isn't, entity->stats never changes from drm_sched_entity_init()
> > > > to the end.
> > > >
> > > > > > + ktime_t vruntime;
> > > > > > +
> > > > > > + spin_lock(&stats->lock);
> > > > > > + vruntime = stats->vruntime;
> > > > > > + if (min_vruntime && vruntime > min_vruntime)
> > > > > > + vruntime = ktime_sub(vruntime, min_vruntime);
> > > > > > + else
> > > > > > + vruntime = 0;
> > > > > > + stats->vruntime = vruntime;
> > > > > > + spin_unlock(&stats->lock);
> > > > > > +}
> > > > > > +
> > > > > > +static ktime_t
> > > > > > +drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
> > > > > > + ktime_t min_vruntime,
> > > > > > + enum drm_sched_priority rq_prio)
> > > > > > +{
> > > > > > + struct drm_sched_entity_stats *stats = entity->stats;
> > > > > > + enum drm_sched_priority prio = entity->priority;
> > > > > > + ktime_t vruntime;
> > > > > > +
> > > > > > + BUILD_BUG_ON(DRM_SCHED_PRIORITY_NORMAL < DRM_SCHED_PRIORITY_HIGH);
> > > > > > +
> > > > > > + spin_lock(&stats->lock);
> > > > > > + vruntime = stats->vruntime;
> > > > > > +
> > > > > > + /*
> > > > > > + * Special handling for entities which were picked from the top of the
> > > > > > + * queue and are now re-joining the top with another one already there.
> > > > > > + */
> > > > > > + if (!vruntime && min_vruntime) {
> > > > > > + if (prio > rq_prio) {
> > > > > > + /*
> > > > > > + * Lower priority should not overtake higher when re-
> > > > > > + * joining at the top of the queue.
> > > > > > + */
> > > > > > + vruntime = us_to_ktime(prio - rq_prio);
> > > > > > + } else if (prio < rq_prio) {
> > > > > > + /*
> > > > > > + * Higher priority can go first.
> > > > > > + */
> > > > > > + vruntime = -us_to_ktime(rq_prio - prio);
> > > > > > + }
> > > > > > + }
> > > > > > +
> > > > > > + /*
> > > > > > + * Restore saved relative position in the queue.
> > > > > > + */
> > > > > > + vruntime = ktime_add(min_vruntime, vruntime);
> > > > > > +
> > > > > > + stats->vruntime = vruntime;
> > > > > > + spin_unlock(&stats->lock);
> > > > > > +
> > > > > > + return vruntime;
> > > > > > +}
> > > > > > +
> > > > > > +static ktime_t drm_sched_entity_update_vruntime(struct drm_sched_entity *entity)
> > > > > > +{
> > > > > > + static const unsigned int shift[] = {
> > > > > > + [DRM_SCHED_PRIORITY_KERNEL] = 1,
> > > > > > + [DRM_SCHED_PRIORITY_HIGH] = 2,
> > > > > > + [DRM_SCHED_PRIORITY_NORMAL] = 4,
> > > > > > + [DRM_SCHED_PRIORITY_LOW] = 7,
> > > > >
> > > > > Are those numbers copied from CPU CFS? Are they from an academic paper?
> > > > > Or have you measured that these generate best results?
> > > > >
> > > > > Some hint about their background here would be nice.
> > > >
> > > > Finger in the air I'm afraid.
> > >
> > > You mean you just tried some numbers?
> > >
> > > That's OK, but you could state so here. In a nicer formulation.
> > >
> > > > > > + };
> > > > > > + struct drm_sched_entity_stats *stats = entity->stats;
> > > > > > + ktime_t runtime, prev;
> > > > > > +
> > > > > > + spin_lock(&stats->lock);
> > > > > > + prev = stats->prev_runtime;
> > > > > > + runtime = stats->runtime;
> > > > > > + stats->prev_runtime = runtime;
> > > > > > + runtime = ktime_add_ns(stats->vruntime,
> > > > > > + ktime_to_ns(ktime_sub(runtime, prev)) <<
> > > > > > + shift[entity->priority]);
> > > > > > + stats->vruntime = runtime;
> > > > > > + spin_unlock(&stats->lock);
> > > > > > +
> > > > > > + return runtime;
> > > > > > +}
> > > > > > +
> > > > > > +static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
> > > > > > +{
> > > > > > + return drm_sched_entity_update_vruntime(entity);
> > > > > > }
> > > > > >
> > > > > > /**
> > > > > > @@ -99,8 +227,14 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> > > > > > list_add_tail(&entity->list, &rq->entities);
> > > > > > }
> > > > > >
> > > > > > - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
> > > > > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> > > > > > + ts = drm_sched_rq_get_min_vruntime(rq);
> > > > > > + ts = drm_sched_entity_restore_vruntime(entity, ts,
> > > > > > + rq->head_prio);
> > > > > > + } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
> > > > > > ts = entity->rr_ts;
> > > > > > + }
> > > > > > +
> > > > > > drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > > > >
> > > > > > spin_unlock(&rq->lock);
> > > > > > @@ -173,7 +307,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> > > > > > if (next_job) {
> > > > > > ktime_t ts;
> > > > > >
> > > > > > - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > > > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
> > > > > > + ts = drm_sched_entity_get_job_ts(entity);
> > > > > > + else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> > > > >
> > > > > Could the git diff here and above be kept smaller by reversing the
> > > > > order of 'if' and 'else if'?
> > > >
> > > > Maybe but I liked having the best policy first. Can change if you want.
> > >
> > > It's optional.
> > >
> > >
> > > P.
> > >
> > > >
> > > > >
> > > > > > ts = next_job->submit_ts;
> > > > > > else
> > > > > > ts = drm_sched_rq_get_rr_ts(rq, entity);
> > > > > > @@ -181,6 +317,13 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> > > > > > drm_sched_rq_update_fifo_locked(entity, rq, ts);
> > > > > > } else {
> > > > > > drm_sched_rq_remove_fifo_locked(entity, rq);
> > > > > > +
> > > > > > + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> > > > > > + ktime_t min_vruntime;
> > > > > > +
> > > > > > + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
> > > > > > + drm_sched_entity_save_vruntime(entity, min_vruntime);
> > > > > > + }
> > > > > > }
> > > > > > spin_unlock(&rq->lock);
> > > > > > spin_unlock(&entity->lock);
> > > > > > diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> > > > > > index 93d0b7224a57..bc25508a6ff6 100644
> > > > > > --- a/include/drm/gpu_scheduler.h
> > > > > > +++ b/include/drm/gpu_scheduler.h
> > > > > > @@ -150,6 +150,11 @@ struct drm_sched_entity {
> > > > > > */
> > > > > > enum drm_sched_priority priority;
> > > > > >
> > > > > > + /**
> > > > > > + * @rq_priority: Run-queue priority
> > > > > > + */
> > > > > > + enum drm_sched_priority rq_priority;
> > > > > > +
> > > > >
> > > > > AFAIR that's just a temporary addition and will be simplified later.
> > > > > Still, would probably be neat to be more obvious about why we now have
> > > > > two priorities.
> > > > >
> > > > > > /**
> > > > > > * @rr_ts:
> > > > > > *
> > > > > > @@ -254,10 +259,11 @@ struct drm_sched_entity {
> > > > > > * struct drm_sched_rq - queue of entities to be scheduled.
> > > > > > *
> > > > > > * @sched: the scheduler to which this rq belongs to.
> > > > > > - * @lock: protects @entities, @rb_tree_root and @rr_ts.
> > > > > > + * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
> > > > > > * @rr_ts: monotonically incrementing fake timestamp for RR mode
> > > > > > * @entities: list of the entities to be scheduled.
> > > > > > * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
> > > > > > + * @head_prio: priority of the top tree element
> > > > > > *
> > > > > > * Run queue is a set of entities scheduling command submissions for
> > > > > > * one specific ring. It implements the scheduling policy that selects
> > > > > > @@ -271,6 +277,7 @@ struct drm_sched_rq {
> > > > > > ktime_t rr_ts;
> > > > > > struct list_head entities;
> > > > > > struct rb_root_cached rb_tree_root;
> > > > > > + enum drm_sched_priority head_prio;
> > > > > > };
> > > > > >
> > > > > > /**
> > > > > > @@ -563,8 +570,10 @@ struct drm_sched_backend_ops {
> > > > > > * @credit_count: the current credit count of this scheduler
> > > > > > * @timeout: the time after which a job is removed from the scheduler.
> > > > > > * @name: name of the ring for which this scheduler is being used.
> > > > > > - * @num_rqs: Number of run-queues. This is at most DRM_SCHED_PRIORITY_COUNT,
> > > > > > - * as there's usually one run-queue per priority, but could be less.
> > > > > > + * @num_user_rqs: Number of run-queues. This is at most
> > > > > > + * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
> > > > > > + * priority, but could be less.
> > > > > > + * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
> > > > >
> > > > > Alright, so that seems to be what I was looking for above?
> > > >
> > > > Yep.
> > > >
> > > > Regards,
> > > >
> > > > Tvrtko
> > > >
> > > > > > * @sched_rq: An allocated array of run-queues of size @num_rqs;
> > > > > > * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
> > > > > > * waits on this wait queue until all the scheduled jobs are
> > > > > > @@ -597,6 +606,7 @@ struct drm_gpu_scheduler {
> > > > > > long timeout;
> > > > > > const char *name;
> > > > > > u32 num_rqs;
> > > > > > + u32 num_user_rqs;
> > > > > > struct drm_sched_rq **sched_rq;
> > > > > > wait_queue_head_t job_scheduled;
> > > > > > atomic64_t job_id_count;
> > > > >
> > > >
> > >
> >
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-16 7:06 ` Philipp Stanner
@ 2025-10-16 8:42 ` Tvrtko Ursulin
2025-10-16 9:50 ` Danilo Krummrich
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-16 8:42 UTC (permalink / raw)
To: phasta, Simona Vetter
Cc: amd-gfx, dri-devel, kernel-dev, Christian König,
Danilo Krummrich, Matthew Brost, Pierre-Eric Pelloux-Prayer,
Simona Vetter
On 16/10/2025 08:06, Philipp Stanner wrote:
> On Tue, 2025-10-14 at 15:58 +0100, Tvrtko Ursulin wrote:
>>
>> On 14/10/2025 15:32, Simona Vetter wrote:
>>> On Tue, Oct 14, 2025 at 04:02:52PM +0200, Philipp Stanner wrote:
>>>> On Tue, 2025-10-14 at 13:56 +0100, Tvrtko Ursulin wrote:
>>>>>
>>>>> On 14/10/2025 11:27, Philipp Stanner wrote:
>>>>>> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>>>>>>> Fair scheduling policy is built upon the same concepts as the well known
>>>>>>
>>>>>> nit: "The fair …"
>>>>>>
>>>>>> Or maybe better: call it FAIR, being congruent with the FIFO below.
>>>>>>
>>>>>>> CFS kernel scheduler - entity run queue is sorted by the virtual GPU time
>>>>>>
>>>>>> nit: Call it "CPU scheduler". The GPU scheduler is a kernel scheduler,
>>>>>> too.
>>>>>>
>>>>>>> consumed by entities in a way that the entity with least vruntime runs
>>>>>>> first.
>>>>>>>
>>>>>>> It is able to avoid total priority starvation, which is one of the
>>>>>>> problems with FIFO, and it also does not need for per priority run queues.
>>>>>>> As it scales the actual GPU runtime by an exponential factor as the
>>>>>>> priority decreases, therefore the virtual runtime for low priority
>>>>>>
>>>>>> "therefore," is not necessary because of the sentence starting with
>>>>>> "As"
>>>>>
>>>>> Done x3 above.
>>>>>
>>>>>>
>>>>>>> entities grows faster than for normal priority, pushing them further down
>>>>>>> the runqueue order for the same real GPU time spent.
>>>>>>>
>>>>>>> Apart from this fundamental fairness, fair policy is especially strong in
>>>>>>> oversubscription workloads where it is able to give more GPU time to short
>>>>>>> and bursty workloads when they are running in parallel with GPU heavy
>>>>>>> clients submitting deep job queues.
>>>>>>>
>>>>>>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>>>>>>> Cc: Christian König <christian.koenig@amd.com>
>>>>>>> Cc: Danilo Krummrich <dakr@kernel.org>
>>>>>>> Cc: Matthew Brost <matthew.brost@intel.com>
>>>>>>> Cc: Philipp Stanner <phasta@kernel.org>
>>>>>>> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
>>>>>>> ---
>>>>>>> drivers/gpu/drm/scheduler/sched_entity.c | 28 ++--
>>>>>>> drivers/gpu/drm/scheduler/sched_internal.h | 9 +-
>>>>>>> drivers/gpu/drm/scheduler/sched_main.c | 12 +-
>>>>>>> drivers/gpu/drm/scheduler/sched_rq.c | 147 ++++++++++++++++++++-
>>>>>>> include/drm/gpu_scheduler.h | 16 ++-
>>>>>>> 5 files changed, 191 insertions(+), 21 deletions(-)
>>>>>>>
>>>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>>>>>>> index 04ce8b7d436b..58f51875547a 100644
>>>>>>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>>>>>>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>>>>>>> @@ -108,6 +108,8 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>>>>>>> entity->guilty = guilty;
>>>>>>> entity->num_sched_list = num_sched_list;
>>>>>>> entity->priority = priority;
>>>>>>> + entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
>>>>>>> + DRM_SCHED_PRIORITY_KERNEL : priority;
>>>>>>> /*
>>>>>>> * It's perfectly valid to initialize an entity without having a valid
>>>>>>> * scheduler attached. It's just not valid to use the scheduler before it
>>>>>>> @@ -124,17 +126,23 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>>>>>>> */
>>>>>>> pr_warn("%s: called with uninitialized scheduler\n", __func__);
>>>>>>> } else if (num_sched_list) {
>>>>>>> - /* The "priority" of an entity cannot exceed the number of run-queues of a
>>>>>>> - * scheduler. Protect against num_rqs being 0, by converting to signed. Choose
>>>>>>> - * the lowest priority available.
>>>>>>> + enum drm_sched_priority p = entity->priority;
>>>>>>> +
>>>>>>> + /*
>>>>>>> + * The "priority" of an entity cannot exceed the number of
>>>>>>> + * run-queues of a scheduler. Protect against num_rqs being 0,
>>>>>>> + * by converting to signed. Choose the lowest priority
>>>>>>> + * available.
>>>>>>> */
>>>>>>> - if (entity->priority >= sched_list[0]->num_rqs) {
>>>>>>> - dev_err(sched_list[0]->dev, "entity has out-of-bounds priority: %u. num_rqs: %u\n",
>>>>>>> - entity->priority, sched_list[0]->num_rqs);
>>>>>>> - entity->priority = max_t(s32, (s32) sched_list[0]->num_rqs - 1,
>>>>>>> - (s32) DRM_SCHED_PRIORITY_KERNEL);
>>>>>>> + if (p >= sched_list[0]->num_user_rqs) {
>>>>>>> + dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
>>>>>>> + p, sched_list[0]->num_user_rqs);
>>>>>>> + p = max_t(s32,
>>>>>>> + (s32)sched_list[0]->num_user_rqs - 1,
>>>>>>> + (s32)DRM_SCHED_PRIORITY_KERNEL);
>>>>>>> + entity->priority = p;
>>>>>>> }
>>>>>>> - entity->rq = sched_list[0]->sched_rq[entity->priority];
>>>>>>> + entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
>>>>>>
>>>>>> That rename could be a separate patch, couldn't it? As I said before
>>>>>> it's always great to have general code improvements as separate patches
>>>>>> since it makes it far easier to review (i.e.: detect / see) core
>>>>>> functionality changes.
>>>>>
>>>>> No, this is the new struct member only added in this patch.
>>>>>
>>>>>>
>>>>>>> }
>>>>>>>
>>>>>>> init_completion(&entity->entity_idle);
>>>>>>> @@ -567,7 +575,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
>>>>>>>
>>>>>>> spin_lock(&entity->lock);
>>>>>>> sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
>>>>>>> - rq = sched ? sched->sched_rq[entity->priority] : NULL;
>>>>>>> + rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
>>>>>>> if (rq != entity->rq) {
>>>>>>> drm_sched_rq_remove_entity(entity->rq, entity);
>>>>>>> entity->rq = rq;
>>>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>>>>>>> index 1132a771aa37..c94e38acc6f2 100644
>>>>>>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>>>>>>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>>>>>>> @@ -18,18 +18,23 @@
>>>>>>> * @kref: reference count for the object.
>>>>>>> * @lock: lock guarding the @runtime updates.
>>>>>>> * @runtime: time entity spent on the GPU.
>>>>>>> + * @prev_runtime: previous @runtime used to get the runtime delta
>>>>>>> + * @vruntime: virtual runtime as accumulated by the fair algorithm
>>>>>>
>>>>>> The other docstrings are all terminated with a full stop '.'
>>>>>
>>>>> Yep I fixed the whole series in this respect already as response to one
>>>>> of your earlier comments.
>>>>>
>>>>>>
>>>>>>> */
>>>>>>> struct drm_sched_entity_stats {
>>>>>>> struct kref kref;
>>>>>>> spinlock_t lock;
>>>>>>> ktime_t runtime;
>>>>>>> + ktime_t prev_runtime;
>>>>>>> + u64 vruntime;
>>>>>>> };
>>>>>>>
>>>>>>> /* Used to choose between FIFO and RR job-scheduling */
>>>>>>> extern int drm_sched_policy;
>>>>>>>
>>>>>>> -#define DRM_SCHED_POLICY_RR 0
>>>>>>> -#define DRM_SCHED_POLICY_FIFO 1
>>>>>>> +#define DRM_SCHED_POLICY_RR 0
>>>>>>> +#define DRM_SCHED_POLICY_FIFO 1
>>>>>>> +#define DRM_SCHED_POLICY_FAIR 2
>>>>>>>
>>>>>>
>>>>>> Formatting unnecessarily increases the git diff.
>>>>>>
>>>>>> Let's die the death of having the old formatting. As far as it's
>>>>>> forseeable FAIR will be the last policy for the classic drm_sched
>>>>>> anyways, so no future changes here expected.
>>>>>
>>>>> Strange I thought I fixed this already in the previous respin. Re-fixed
>>>>> and verfied.
>>>>>>> bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
>>>>>>> struct drm_sched_entity *entity);
>>>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>>>>>>> index f180d292bf66..8d8f9c8411f5 100644
>>>>>>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>>>>>>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>>>>>>> @@ -90,7 +90,7 @@ int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
>>>>>>> * DOC: sched_policy (int)
>>>>>>> * Used to override default entities scheduling policy in a run queue.
>>>>>>> */
>>>>>>> -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO (default).");
>>>>>>> +MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
>>>>>>> module_param_named(sched_policy, drm_sched_policy, int, 0444);
>>>>>>>
>>>>>>> static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
>>>>>>> @@ -1132,11 +1132,15 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>>>>>>> sched->own_submit_wq = true;
>>>>>>> }
>>>>>>>
>>>>>>> - sched->sched_rq = kmalloc_array(args->num_rqs, sizeof(*sched->sched_rq),
>>>>>>> + sched->num_user_rqs = args->num_rqs;
>>>>>>> + sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
>>>>>>> + args->num_rqs : 1;
>>>>>>> + sched->sched_rq = kmalloc_array(sched->num_rqs,
>>>>>>> + sizeof(*sched->sched_rq),
>>>>>>
>>>>>> Don't reformat that for the git diff? Line doesn't seem crazily long.
>>>>>
>>>>> Ok.
>>>>>
>>>>>>
>>>>>>> GFP_KERNEL | __GFP_ZERO);
>>>>>>> if (!sched->sched_rq)
>>>>>>> goto Out_check_own;
>>>>>>> - sched->num_rqs = args->num_rqs;
>>>>>>> +
>>>>>>> for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>>>>>>> sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
>>>>>>> if (!sched->sched_rq[i])
>>>>>>> @@ -1278,7 +1282,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
>>>>>>> if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
>>>>>>> atomic_inc(&bad->karma);
>>>>>>>
>>>>>>> - for (i = DRM_SCHED_PRIORITY_HIGH; i < sched->num_rqs; i++) {
>>>>>>> + for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>>>>>>
>>>>>> Give me a pointer here quickly – what's that about?
>>>>>
>>>>> Since FAIR stuffs everthing into a single run queue it needs to start
>>>>> looking into it when looking for the guilty context. FIFO and RR are not
>>>>> affected since they will not find the context with the kernel priority
>>>>> in the kernel run queue anyway.
>>>>>
>>>>>>
>>>>>>> struct drm_sched_rq *rq = sched->sched_rq[i];
>>>>>>>
>>>>>>> spin_lock(&rq->lock);
>>>>>>> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
>>>>>>> index 09d316bc3dfa..b868c794cc9d 100644
>>>>>>> --- a/drivers/gpu/drm/scheduler/sched_rq.c
>>>>>>> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
>>>>>>> @@ -16,6 +16,24 @@ drm_sched_entity_compare_before(struct rb_node *a, const struct rb_node *b)
>>>>>>> return ktime_before(ea->oldest_job_waiting, eb->oldest_job_waiting);
>>>>>>> }
>>>>>>>
>>>>>>> +static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
>>>>>>> +{
>>>>>>> + enum drm_sched_priority prio = -1;
>>>>>>> + struct rb_node *rb;
>>>>>>
>>>>>> nit:
>>>>>> "node" might be a bitter name than rb. When iterating over a list we
>>>>>> also typically call the iterator sth like "head" and not "list".
>>>>>>
>>>>>> But no hard feelings on that change.
>>>>>
>>>>> I am following the convention from drm_sched_rq_select_entity_fifo() to
>>>>> avoid someone complaining I was diverging from the pattern established
>>>>> in the same file. ;)
>>>>
>>>> Don't worry, I will always cover your back against such people!
>>>>
>>>>>>> +
>>>>>>> + lockdep_assert_held(&rq->lock);
>>>>>>> +
>>>>>>> + rb = rb_first_cached(&rq->rb_tree_root);
>>>>>>> + if (rb) {
>>>>>>> + struct drm_sched_entity *entity =
>>>>>>> + rb_entry(rb, typeof(*entity), rb_tree_node);
>>>>>>> +
>>>>>>> + prio = entity->priority; /* Unlocked read */
>>>>>>
>>>>>> Why an unlocked read? Why is that OK? The comment could detail that.
>>>>>
>>>>> Fair point, expanded the explanation.
>>>>>>> + }
>>>>>>> +
>>>>>>> + rq->head_prio = prio;
>>>>>>> +}
>>>>>>> +
>>>>>>> static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>>>>>>> struct drm_sched_rq *rq)
>>>>>>> {
>>>>>>> @@ -25,6 +43,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>>>>>>> if (!RB_EMPTY_NODE(&entity->rb_tree_node)) {
>>>>>>> rb_erase_cached(&entity->rb_tree_node, &rq->rb_tree_root);
>>>>>>> RB_CLEAR_NODE(&entity->rb_tree_node);
>>>>>>> + drm_sched_rq_update_prio(rq);
>>>>>>> }
>>>>>>> }
>>>>>>>
>>>>>>> @@ -46,6 +65,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>>>>>>>
>>>>>>> rb_add_cached(&entity->rb_tree_node, &rq->rb_tree_root,
>>>>>>> drm_sched_entity_compare_before);
>>>>>>> + drm_sched_rq_update_prio(rq);
>>>>>>> }
>>>>>>>
>>>>>>> /**
>>>>>>> @@ -63,6 +83,114 @@ void drm_sched_rq_init(struct drm_sched_rq *rq,
>>>>>>> INIT_LIST_HEAD(&rq->entities);
>>>>>>> rq->rb_tree_root = RB_ROOT_CACHED;
>>>>>>> rq->sched = sched;
>>>>>>> + rq->head_prio = -1;
>>>>>>
>>>>>> head_prio is an enum.
>>>>>>
>>>>>> Better to give the enum an entry like:
>>>>>>
>>>>>> PRIO_INVALID = -1,
>>>>>
>>>>> Ok.
>>>>>
>>>>>>
>>>>>>> +}
>>>>>>> +
>>>>>>> +static ktime_t
>>>>>>> +drm_sched_rq_get_min_vruntime(struct drm_sched_rq *rq)
>>>>>>> +{
>>>>>>> + struct drm_sched_entity *entity;
>>>>>>> + struct rb_node *rb;
>>>>>>> +
>>>>>>> + lockdep_assert_held(&rq->lock);
>>>>>>> +
>>>>>>> + for (rb = rb_first_cached(&rq->rb_tree_root); rb; rb = rb_next(rb)) {
>>>>>>> + entity = rb_entry(rb, typeof(*entity), rb_tree_node);
>>>>>>> +
>>>>>>> + return entity->stats->vruntime; /* Unlocked read */
>>>>>>
>>>>>> Seems the read is unlocked because we just don't care about it racing?
>>>>>
>>>>> If there is a platform which tears ktime_t writes I suppose this could
>>>>> read garbage. I am not sure if there is. Perhaps safer to add the lock
>>>>> around it nevertheless.
>>>>
>>>> I think Sima (+cc) was very explicit about us never to implement our
>>>> own locking or synchronization primitives.
>>>
>>> Yeah, doing lockless just in case isn't great, especially if you're not
>>> really sure about the lkmm. I've done a full-lenght talk ranting about
>>> this all and 2 big blog posts, here's all the links:
>>>
>>> https://blog.ffwll.ch/2023/07/eoss-prague-locking-engineering.html
>>>
>>> The above discussion definitely doesn't inspire the cozy confidence that
>>> this is justified by perf data and engineered by people who know the
>>> ins&outs of how to do lockless stuff under the lkmm. And I know that the
>>> current drm/sched code plays a bit fast&loose in this regard, but we
>>> should try and at least not make things worse. Which means if we do decide
>>> that lockless is required here, it needs to be engineered and documented
>>> with the required utmost care to make sure it won't bite us too badly some
>>> random time in the future.
>>
>> There isn't any lockless algorithms here, nor any performance claims. It
>> is just a read of a ktime_t. I can add the _existing_ entity->stats lock
>> around it just as well for those warm and fuzzy feelings.
>
> Tvrtko.
> This is not about anyone's feelings. It's about not adding undefined
> behavior. You cannot know whether these values you access locklessly
> will really be loaded each time / loaded correctly. You just literally
> admitted that yourself. Even if you knew, there could be a new
Yes, I even said two replies ago I will add the lock. In fact, it is
write tearing which would be a problem on 32-bit architectures, not just
read tearing.
But again, it is not a lockless algorithm and nowhere I am implementing
a new locking primitive. So as much as my attempt to keep it light
hearted with the warm and fuzzy feeling comment was a miss, I also think
the whole long writeups afterwards about dangers of implementing own
lockelss algorithms and performance were the same.
So lets move on, there is no argument here.
Tvrtko
> architecture in 3 years that loads tearingly. There could be a new
> "great" compiler optimization.
>
> That's exactly why they designed atomic_t, which merely capsules an
> integer, which one could also "just read".
>
>
> Something like the issue with the runqueues not being locked for
> readers must *never* happen again in drm_sched (or elsewhere). We
> discussed that in our workshop at XDC. I think there was mutual
> agreement:
>
> Always lock everything, and only use well defined and carefully
> engineered alternatives to locking when there is good justification.
>
> P.
>
>>
>> Regards,
>>
>> Tvrtko
>>
>>>> Not locking stuff that can get accessed asynchronously is just a hard
>>>> No-Go.
>>>>
>>>> That you access things here asynchronously is even more confusing
>>>> considering that in the kunit patch you explicitly add READ_ONCE() for
>>>> documentation purposes.
>>>>
>>>> Premature performance optimization is the root of all evil, and think
>>>> about the unlocked runqueue readers. 5 years down the road no one has
>>>> the slightest clue anymore what is supposed to be locked by whom and
>>>> accessed when and how.
>>>>
>>>> At XDC we had an entire room of highly experienced experts and we had
>>>> no clue anymore.
>>>>
>>>>
>>>> My need to establish in DRM that everything accessed by more than 1 CPU
>>>> at the same time always has to be locked.
>>>>
>>>> Alternatives (memory barriers, RCU, atomics, read once) are permitted
>>>> if one can give really good justification (performance measurements)
>>>> and can provide a clear and clean concept.
>>>>
>>>> I'd have to consult the C standard, but I think just reading from
>>>> something that is not an atomic might even be UB.
>>>>
>>>>
>>>> (That said, all platforms Linux runs on don't tear integers AFAIK.
>>>> Otherwise RCU couldn't work.)
>>>>
>>>>
>>>>>>> + }
>>>>>>> +
>>>>>>> + return 0;
>>>>>>> +}
>>>>>>> +
>>>>>>> +static void
>>>>>>> +drm_sched_entity_save_vruntime(struct drm_sched_entity *entity,
>>>>>>> + ktime_t min_vruntime)
>>>>>>> +{
>>>>>>> + struct drm_sched_entity_stats *stats = entity->stats;
>>>>>>
>>>>>> Unlocked read?
>>>>>
>>>>> This one isn't, entity->stats never changes from drm_sched_entity_init()
>>>>> to the end.
>>>>>
>>>>>>> + ktime_t vruntime;
>>>>>>> +
>>>>>>> + spin_lock(&stats->lock);
>>>>>>> + vruntime = stats->vruntime;
>>>>>>> + if (min_vruntime && vruntime > min_vruntime)
>>>>>>> + vruntime = ktime_sub(vruntime, min_vruntime);
>>>>>>> + else
>>>>>>> + vruntime = 0;
>>>>>>> + stats->vruntime = vruntime;
>>>>>>> + spin_unlock(&stats->lock);
>>>>>>> +}
>>>>>>> +
>>>>>>> +static ktime_t
>>>>>>> +drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
>>>>>>> + ktime_t min_vruntime,
>>>>>>> + enum drm_sched_priority rq_prio)
>>>>>>> +{
>>>>>>> + struct drm_sched_entity_stats *stats = entity->stats;
>>>>>>> + enum drm_sched_priority prio = entity->priority;
>>>>>>> + ktime_t vruntime;
>>>>>>> +
>>>>>>> + BUILD_BUG_ON(DRM_SCHED_PRIORITY_NORMAL < DRM_SCHED_PRIORITY_HIGH);
>>>>>>> +
>>>>>>> + spin_lock(&stats->lock);
>>>>>>> + vruntime = stats->vruntime;
>>>>>>> +
>>>>>>> + /*
>>>>>>> + * Special handling for entities which were picked from the top of the
>>>>>>> + * queue and are now re-joining the top with another one already there.
>>>>>>> + */
>>>>>>> + if (!vruntime && min_vruntime) {
>>>>>>> + if (prio > rq_prio) {
>>>>>>> + /*
>>>>>>> + * Lower priority should not overtake higher when re-
>>>>>>> + * joining at the top of the queue.
>>>>>>> + */
>>>>>>> + vruntime = us_to_ktime(prio - rq_prio);
>>>>>>> + } else if (prio < rq_prio) {
>>>>>>> + /*
>>>>>>> + * Higher priority can go first.
>>>>>>> + */
>>>>>>> + vruntime = -us_to_ktime(rq_prio - prio);
>>>>>>> + }
>>>>>>> + }
>>>>>>> +
>>>>>>> + /*
>>>>>>> + * Restore saved relative position in the queue.
>>>>>>> + */
>>>>>>> + vruntime = ktime_add(min_vruntime, vruntime);
>>>>>>> +
>>>>>>> + stats->vruntime = vruntime;
>>>>>>> + spin_unlock(&stats->lock);
>>>>>>> +
>>>>>>> + return vruntime;
>>>>>>> +}
>>>>>>> +
>>>>>>> +static ktime_t drm_sched_entity_update_vruntime(struct drm_sched_entity *entity)
>>>>>>> +{
>>>>>>> + static const unsigned int shift[] = {
>>>>>>> + [DRM_SCHED_PRIORITY_KERNEL] = 1,
>>>>>>> + [DRM_SCHED_PRIORITY_HIGH] = 2,
>>>>>>> + [DRM_SCHED_PRIORITY_NORMAL] = 4,
>>>>>>> + [DRM_SCHED_PRIORITY_LOW] = 7,
>>>>>>
>>>>>> Are those numbers copied from CPU CFS? Are they from an academic paper?
>>>>>> Or have you measured that these generate best results?
>>>>>>
>>>>>> Some hint about their background here would be nice.
>>>>>
>>>>> Finger in the air I'm afraid.
>>>>
>>>> You mean you just tried some numbers?
>>>>
>>>> That's OK, but you could state so here. In a nicer formulation.
>>>>
>>>>>>> + };
>>>>>>> + struct drm_sched_entity_stats *stats = entity->stats;
>>>>>>> + ktime_t runtime, prev;
>>>>>>> +
>>>>>>> + spin_lock(&stats->lock);
>>>>>>> + prev = stats->prev_runtime;
>>>>>>> + runtime = stats->runtime;
>>>>>>> + stats->prev_runtime = runtime;
>>>>>>> + runtime = ktime_add_ns(stats->vruntime,
>>>>>>> + ktime_to_ns(ktime_sub(runtime, prev)) <<
>>>>>>> + shift[entity->priority]);
>>>>>>> + stats->vruntime = runtime;
>>>>>>> + spin_unlock(&stats->lock);
>>>>>>> +
>>>>>>> + return runtime;
>>>>>>> +}
>>>>>>> +
>>>>>>> +static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
>>>>>>> +{
>>>>>>> + return drm_sched_entity_update_vruntime(entity);
>>>>>>> }
>>>>>>>
>>>>>>> /**
>>>>>>> @@ -99,8 +227,14 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
>>>>>>> list_add_tail(&entity->list, &rq->entities);
>>>>>>> }
>>>>>>>
>>>>>>> - if (drm_sched_policy == DRM_SCHED_POLICY_RR)
>>>>>>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
>>>>>>> + ts = drm_sched_rq_get_min_vruntime(rq);
>>>>>>> + ts = drm_sched_entity_restore_vruntime(entity, ts,
>>>>>>> + rq->head_prio);
>>>>>>> + } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
>>>>>>> ts = entity->rr_ts;
>>>>>>> + }
>>>>>>> +
>>>>>>> drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>>>>>>
>>>>>>> spin_unlock(&rq->lock);
>>>>>>> @@ -173,7 +307,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>>>>>>> if (next_job) {
>>>>>>> ktime_t ts;
>>>>>>>
>>>>>>> - if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>>>>>>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
>>>>>>> + ts = drm_sched_entity_get_job_ts(entity);
>>>>>>> + else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>>>>>>
>>>>>> Could the git diff here and above be kept smaller by reversing the
>>>>>> order of 'if' and 'else if'?
>>>>>
>>>>> Maybe but I liked having the best policy first. Can change if you want.
>>>>
>>>> It's optional.
>>>>
>>>>
>>>> P.
>>>>
>>>>>
>>>>>>
>>>>>>> ts = next_job->submit_ts;
>>>>>>> else
>>>>>>> ts = drm_sched_rq_get_rr_ts(rq, entity);
>>>>>>> @@ -181,6 +317,13 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>>>>>>> drm_sched_rq_update_fifo_locked(entity, rq, ts);
>>>>>>> } else {
>>>>>>> drm_sched_rq_remove_fifo_locked(entity, rq);
>>>>>>> +
>>>>>>> + if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
>>>>>>> + ktime_t min_vruntime;
>>>>>>> +
>>>>>>> + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
>>>>>>> + drm_sched_entity_save_vruntime(entity, min_vruntime);
>>>>>>> + }
>>>>>>> }
>>>>>>> spin_unlock(&rq->lock);
>>>>>>> spin_unlock(&entity->lock);
>>>>>>> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
>>>>>>> index 93d0b7224a57..bc25508a6ff6 100644
>>>>>>> --- a/include/drm/gpu_scheduler.h
>>>>>>> +++ b/include/drm/gpu_scheduler.h
>>>>>>> @@ -150,6 +150,11 @@ struct drm_sched_entity {
>>>>>>> */
>>>>>>> enum drm_sched_priority priority;
>>>>>>>
>>>>>>> + /**
>>>>>>> + * @rq_priority: Run-queue priority
>>>>>>> + */
>>>>>>> + enum drm_sched_priority rq_priority;
>>>>>>> +
>>>>>>
>>>>>> AFAIR that's just a temporary addition and will be simplified later.
>>>>>> Still, would probably be neat to be more obvious about why we now have
>>>>>> two priorities.
>>>>>>
>>>>>>> /**
>>>>>>> * @rr_ts:
>>>>>>> *
>>>>>>> @@ -254,10 +259,11 @@ struct drm_sched_entity {
>>>>>>> * struct drm_sched_rq - queue of entities to be scheduled.
>>>>>>> *
>>>>>>> * @sched: the scheduler to which this rq belongs to.
>>>>>>> - * @lock: protects @entities, @rb_tree_root and @rr_ts.
>>>>>>> + * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
>>>>>>> * @rr_ts: monotonically incrementing fake timestamp for RR mode
>>>>>>> * @entities: list of the entities to be scheduled.
>>>>>>> * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
>>>>>>> + * @head_prio: priority of the top tree element
>>>>>>> *
>>>>>>> * Run queue is a set of entities scheduling command submissions for
>>>>>>> * one specific ring. It implements the scheduling policy that selects
>>>>>>> @@ -271,6 +277,7 @@ struct drm_sched_rq {
>>>>>>> ktime_t rr_ts;
>>>>>>> struct list_head entities;
>>>>>>> struct rb_root_cached rb_tree_root;
>>>>>>> + enum drm_sched_priority head_prio;
>>>>>>> };
>>>>>>>
>>>>>>> /**
>>>>>>> @@ -563,8 +570,10 @@ struct drm_sched_backend_ops {
>>>>>>> * @credit_count: the current credit count of this scheduler
>>>>>>> * @timeout: the time after which a job is removed from the scheduler.
>>>>>>> * @name: name of the ring for which this scheduler is being used.
>>>>>>> - * @num_rqs: Number of run-queues. This is at most DRM_SCHED_PRIORITY_COUNT,
>>>>>>> - * as there's usually one run-queue per priority, but could be less.
>>>>>>> + * @num_user_rqs: Number of run-queues. This is at most
>>>>>>> + * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
>>>>>>> + * priority, but could be less.
>>>>>>> + * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
>>>>>>
>>>>>> Alright, so that seems to be what I was looking for above?
>>>>>
>>>>> Yep.
>>>>>
>>>>> Regards,
>>>>>
>>>>> Tvrtko
>>>>>
>>>>>>> * @sched_rq: An allocated array of run-queues of size @num_rqs;
>>>>>>> * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
>>>>>>> * waits on this wait queue until all the scheduled jobs are
>>>>>>> @@ -597,6 +606,7 @@ struct drm_gpu_scheduler {
>>>>>>> long timeout;
>>>>>>> const char *name;
>>>>>>> u32 num_rqs;
>>>>>>> + u32 num_user_rqs;
>>>>>>> struct drm_sched_rq **sched_rq;
>>>>>>> wait_queue_head_t job_scheduled;
>>>>>>> atomic64_t job_id_count;
>>>>>>
>>>>>
>>>>
>>>
>>
>
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-16 8:42 ` Tvrtko Ursulin
@ 2025-10-16 9:50 ` Danilo Krummrich
2025-10-16 10:54 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Danilo Krummrich @ 2025-10-16 9:50 UTC (permalink / raw)
To: Tvrtko Ursulin
Cc: phasta, Simona Vetter, amd-gfx, dri-devel, kernel-dev,
Christian König, Matthew Brost, Pierre-Eric Pelloux-Prayer,
Simona Vetter
On Thu Oct 16, 2025 at 10:42 AM CEST, Tvrtko Ursulin wrote:
> Yes, I even said two replies ago I will add the lock. In fact, it is
> write tearing which would be a problem on 32-bit architectures, not just
> read tearing.
>
> But again, it is not a lockless algorithm and nowhere I am implementing
> a new locking primitive. So as much as my attempt to keep it light
> hearted with the warm and fuzzy feeling comment was a miss, I also think
> the whole long writeups afterwards about dangers of implementing own
> lockelss algorithms and performance were the same.
I think what's confusing people is the following:
entity->stats->vruntime; /* Unlocked read */
You indicate with your comment that you are accessing something the is protected
by a lock intentionally without the lock being held.
I think there's not much room for people to interpret this as something else
than a lockless algorithm approach.
> So lets move on, there is no argument here.
Indeed, there is no argument. But, if you say something like:
"I can add the _existing_ entity->stats lock around it just as well for those
warm and fuzzy feelings."
it may be read by people as if you don't agree that for correctness either a
lock or an atomic is required. So, people might keep arguing regardless. :)
^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-16 9:50 ` Danilo Krummrich
@ 2025-10-16 10:54 ` Tvrtko Ursulin
2025-10-16 11:14 ` Danilo Krummrich
0 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-16 10:54 UTC (permalink / raw)
To: Danilo Krummrich
Cc: phasta, Simona Vetter, amd-gfx, dri-devel, kernel-dev,
Christian König, Matthew Brost, Pierre-Eric Pelloux-Prayer,
Simona Vetter
On 16/10/2025 10:50, Danilo Krummrich wrote:
> On Thu Oct 16, 2025 at 10:42 AM CEST, Tvrtko Ursulin wrote:
>> Yes, I even said two replies ago I will add the lock. In fact, it is
>> write tearing which would be a problem on 32-bit architectures, not just
>> read tearing.
>>
>> But again, it is not a lockless algorithm and nowhere I am implementing
>> a new locking primitive. So as much as my attempt to keep it light
>> hearted with the warm and fuzzy feeling comment was a miss, I also think
>> the whole long writeups afterwards about dangers of implementing own
>> lockelss algorithms and performance were the same.
>
> I think what's confusing people is the following:
>
> entity->stats->vruntime; /* Unlocked read */
>
> You indicate with your comment that you are accessing something the is protected
> by a lock intentionally without the lock being held.
>
> I think there's not much room for people to interpret this as something else
> than a lockless algorithm approach.
>
>> So lets move on, there is no argument here.
>
> Indeed, there is no argument. But, if you say something like:
>
> "I can add the _existing_ entity->stats lock around it just as well for those
> warm and fuzzy feelings."
You quote a comment from earlier in the thread which I already
acknowledged was misplaced.
> it may be read by people as if you don't agree that for correctness either a
> lock or an atomic is required. So, people might keep arguing regardless. In the message you reply to I wrote that unlocked read in fact isn't
safe on 32-bit architectures.
So yeah, good catch, will fix. No need for long writeups about things
which I did not say like performance claims, or inventing new locking
primitives.
Regards,
Tvrtko
^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [PATCH 10/28] drm/sched: Add fair scheduling policy
2025-10-16 10:54 ` Tvrtko Ursulin
@ 2025-10-16 11:14 ` Danilo Krummrich
0 siblings, 0 replies; 76+ messages in thread
From: Danilo Krummrich @ 2025-10-16 11:14 UTC (permalink / raw)
To: Tvrtko Ursulin
Cc: phasta, Simona Vetter, amd-gfx, dri-devel, kernel-dev,
Christian König, Matthew Brost, Pierre-Eric Pelloux-Prayer,
Simona Vetter
On Thu Oct 16, 2025 at 12:54 PM CEST, Tvrtko Ursulin wrote:
> On 16/10/2025 10:50, Danilo Krummrich wrote:
>> On Thu Oct 16, 2025 at 10:42 AM CEST, Tvrtko Ursulin wrote:
>>> Yes, I even said two replies ago I will add the lock. In fact, it is
>>> write tearing which would be a problem on 32-bit architectures, not just
>>> read tearing.
>>>
>>> But again, it is not a lockless algorithm and nowhere I am implementing
>>> a new locking primitive. So as much as my attempt to keep it light
>>> hearted with the warm and fuzzy feeling comment was a miss, I also think
>>> the whole long writeups afterwards about dangers of implementing own
>>> lockelss algorithms and performance were the same.
>>
>> I think what's confusing people is the following:
>>
>> entity->stats->vruntime; /* Unlocked read */
>>
>> You indicate with your comment that you are accessing something the is protected
>> by a lock intentionally without the lock being held.
>>
>> I think there's not much room for people to interpret this as something else
>> than a lockless algorithm approach.
>>
>>> So lets move on, there is no argument here.
>>
>> Indeed, there is no argument. But, if you say something like:
>>
>> "I can add the _existing_ entity->stats lock around it just as well for those
>> warm and fuzzy feelings."
>
> You quote a comment from earlier in the thread which I already
> acknowledged was misplaced.
>
>> it may be read by people as if you don't agree that for correctness either a
>> lock or an atomic is required. So, people might keep arguing regardless.
>
> In the message you reply to I wrote that unlocked read in fact isn't
> safe on 32-bit architectures.
>
> So yeah, good catch, will fix. No need for long writeups about things
> which I did not say like performance claims, or inventing new locking
> primitives.
Please read my reply carefully, I tried explaining to you why people may have
read it in this way and why it may caused them to write the replies you think
are unnecessary.
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 11/28] drm/sched: Favour interactive clients slightly
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (9 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 10/28] drm/sched: Add fair scheduling policy Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-14 10:53 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 12/28] drm/sched: Switch default policy to fair Tvrtko Ursulin
` (17 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner,
Pierre-Eric Pelloux-Prayer
GPUs do not always implement preemption and DRM scheduler definitely
does not support it at the front end scheduling level. This means
execution quanta can be quite long and is controlled by userspace,
consequence of which is picking the "wrong" entity to run can have a
larger negative effect than it would have with a virtual runtime based CPU
scheduler.
Another important consideration is that rendering clients often have
shallow submission queues, meaning they will be entering and exiting the
scheduler's runnable queue often.
Relevant scenario here is what happens when an entity re-joins the
runnable queue with other entities already present. One cornerstone of the
virtual runtime algorithm is to let it re-join at the head and rely on the
virtual runtime accounting and timeslicing to sort it out.
However, as explained above, this may not work perfectly in the GPU world.
Entity could always get to overtake the existing entities, or not,
depending on the submission order and rbtree equal key insertion
behaviour.
Allow interactive jobs to overtake entities already queued up for the
limited case when interactive entity is re-joining the queue after
being idle.
This gives more opportunity for the compositors to have their rendering
executed before the GPU hogs even if they have been configured with the
same scheduling priority.
To classify a client as interactive we look at its average job duration
versus the average for the whole scheduler. We can track this easily by
plugging into the existing job runtime tracking and applying the
exponential moving average window on the past submissions. Then, all other
things being equal, we let the more interactive jobs go first.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
---
drivers/gpu/drm/scheduler/sched_entity.c | 1 +
drivers/gpu/drm/scheduler/sched_internal.h | 15 ++++++++++++---
drivers/gpu/drm/scheduler/sched_main.c | 8 +++++++-
drivers/gpu/drm/scheduler/sched_rq.c | 14 ++++++++++++++
include/drm/gpu_scheduler.h | 5 +++++
5 files changed, 39 insertions(+), 4 deletions(-)
diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
index 58f51875547a..1715e1caec40 100644
--- a/drivers/gpu/drm/scheduler/sched_entity.c
+++ b/drivers/gpu/drm/scheduler/sched_entity.c
@@ -61,6 +61,7 @@ static struct drm_sched_entity_stats *drm_sched_entity_stats_alloc(void)
kref_init(&stats->kref);
spin_lock_init(&stats->lock);
+ ewma_drm_sched_avgtime_init(&stats->avg_job_us);
return stats;
}
diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
index c94e38acc6f2..a120efc5d763 100644
--- a/drivers/gpu/drm/scheduler/sched_internal.h
+++ b/drivers/gpu/drm/scheduler/sched_internal.h
@@ -20,6 +20,7 @@
* @runtime: time entity spent on the GPU.
* @prev_runtime: previous @runtime used to get the runtime delta
* @vruntime: virtual runtime as accumulated by the fair algorithm
+ * @avg_job_us: average job duration
*/
struct drm_sched_entity_stats {
struct kref kref;
@@ -27,6 +28,8 @@ struct drm_sched_entity_stats {
ktime_t runtime;
ktime_t prev_runtime;
u64 vruntime;
+
+ struct ewma_drm_sched_avgtime avg_job_us;
};
/* Used to choose between FIFO and RR job-scheduling */
@@ -153,20 +156,26 @@ drm_sched_entity_stats_put(struct drm_sched_entity_stats *stats)
* @job: Scheduler job to account.
*
* Accounts the execution time of @job to its respective entity stats object.
+ *
+ * Returns job's real duration in micro seconds.
*/
-static inline void
+static inline ktime_t
drm_sched_entity_stats_job_add_gpu_time(struct drm_sched_job *job)
{
struct drm_sched_entity_stats *stats = job->entity_stats;
struct drm_sched_fence *s_fence = job->s_fence;
- ktime_t start, end;
+ ktime_t start, end, duration;
start = dma_fence_timestamp(&s_fence->scheduled);
end = dma_fence_timestamp(&s_fence->finished);
+ duration = ktime_sub(end, start);
spin_lock(&stats->lock);
- stats->runtime = ktime_add(stats->runtime, ktime_sub(end, start));
+ stats->runtime = ktime_add(stats->runtime, duration);
+ ewma_drm_sched_avgtime_add(&stats->avg_job_us, ktime_to_us(duration));
spin_unlock(&stats->lock);
+
+ return duration;
}
#endif
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 8d8f9c8411f5..204d99c6699f 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -1000,7 +1000,12 @@ static void drm_sched_free_job_work(struct work_struct *w)
struct drm_sched_job *job;
while ((job = drm_sched_get_finished_job(sched))) {
- drm_sched_entity_stats_job_add_gpu_time(job);
+ ktime_t duration = drm_sched_entity_stats_job_add_gpu_time(job);
+
+ /* Serialized by the worker. */
+ ewma_drm_sched_avgtime_add(&sched->avg_job_us,
+ ktime_to_us(duration));
+
sched->ops->free_job(job);
}
@@ -1158,6 +1163,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
atomic_set(&sched->_score, 0);
atomic64_set(&sched->job_id_count, 0);
sched->pause_submit = false;
+ ewma_drm_sched_avgtime_init(&sched->avg_job_us);
sched->ready = true;
return 0;
diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
index b868c794cc9d..02742869e75b 100644
--- a/drivers/gpu/drm/scheduler/sched_rq.c
+++ b/drivers/gpu/drm/scheduler/sched_rq.c
@@ -150,6 +150,20 @@ drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
* Higher priority can go first.
*/
vruntime = -us_to_ktime(rq_prio - prio);
+ } else {
+ struct drm_gpu_scheduler *sched = entity->rq->sched;
+
+ /*
+ * Favour entity with shorter jobs (interactivity).
+ *
+ * (Unlocked read is fine since it is just heuristics.)
+ *
+ */
+ if (ewma_drm_sched_avgtime_read(&stats->avg_job_us) <=
+ ewma_drm_sched_avgtime_read(&sched->avg_job_us))
+ vruntime = -1;
+ else
+ vruntime = 1;
}
}
diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
index bc25508a6ff6..a7e407e04ce0 100644
--- a/include/drm/gpu_scheduler.h
+++ b/include/drm/gpu_scheduler.h
@@ -25,11 +25,14 @@
#define _DRM_GPU_SCHEDULER_H_
#include <drm/spsc_queue.h>
+#include <linux/average.h>
#include <linux/dma-fence.h>
#include <linux/completion.h>
#include <linux/xarray.h>
#include <linux/workqueue.h>
+DECLARE_EWMA(drm_sched_avgtime, 6, 4);
+
#define MAX_WAIT_SCHED_ENTITY_Q_EMPTY msecs_to_jiffies(1000)
/**
@@ -581,6 +584,7 @@ struct drm_sched_backend_ops {
* @job_id_count: used to assign unique id to the each job.
* @submit_wq: workqueue used to queue @work_run_job and @work_free_job
* @timeout_wq: workqueue used to queue @work_tdr
+ * @avg_job_us: Average job duration
* @work_run_job: work which calls run_job op of each scheduler.
* @work_free_job: work which calls free_job op of each scheduler.
* @work_tdr: schedules a delayed call to @drm_sched_job_timedout after the
@@ -612,6 +616,7 @@ struct drm_gpu_scheduler {
atomic64_t job_id_count;
struct workqueue_struct *submit_wq;
struct workqueue_struct *timeout_wq;
+ struct ewma_drm_sched_avgtime avg_job_us;
struct work_struct work_run_job;
struct work_struct work_free_job;
struct delayed_work work_tdr;
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 11/28] drm/sched: Favour interactive clients slightly
2025-10-08 8:53 ` [PATCH 11/28] drm/sched: Favour interactive clients slightly Tvrtko Ursulin
@ 2025-10-14 10:53 ` Philipp Stanner
2025-10-14 12:20 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-14 10:53 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner, Pierre-Eric Pelloux-Prayer
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> GPUs do not always implement preemption and DRM scheduler definitely
> does not support it at the front end scheduling level. This means
> execution quanta can be quite long and is controlled by userspace,
> consequence of which is picking the "wrong" entity to run can have a
> larger negative effect than it would have with a virtual runtime based CPU
> scheduler.
>
> Another important consideration is that rendering clients often have
> shallow submission queues, meaning they will be entering and exiting the
> scheduler's runnable queue often.
>
> Relevant scenario here is what happens when an entity re-joins the
> runnable queue with other entities already present. One cornerstone of the
> virtual runtime algorithm is to let it re-join at the head and rely on the
> virtual runtime accounting and timeslicing to sort it out.
>
> However, as explained above, this may not work perfectly in the GPU world.
> Entity could always get to overtake the existing entities, or not,
> depending on the submission order and rbtree equal key insertion
> behaviour.
>
> Allow interactive jobs to overtake entities already queued up for the
> limited case when interactive entity is re-joining the queue after
> being idle.
>
> This gives more opportunity for the compositors to have their rendering
> executed before the GPU hogs even if they have been configured with the
> same scheduling priority.
>
> To classify a client as interactive we look at its average job duration
> versus the average for the whole scheduler. We can track this easily by
> plugging into the existing job runtime tracking and applying the
> exponential moving average window on the past submissions. Then, all other
> things being equal, we let the more interactive jobs go first.
OK so this patch is new. Why was it added? The cover letter says:
"Improved handling of interactive clients by replacing the random noise
on tie approach with the average job duration statistics."
So this is based on additional research you have done in the mean time?
Does it change behavior significantly when compared to the RFC?
The firmware scheduler bros are not affected in any case. Still, I
think that the RFC we discussed in the past and at XDC is now quite
more different from the actual proposal in this v1.
I suppose it's in general good for graphics applications.. what about
compute, doesn't that have longer jobs? Probably still good for people
who do compute on their productive system..
@AMD:
can you review / ack this?
P.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
> ---
> drivers/gpu/drm/scheduler/sched_entity.c | 1 +
> drivers/gpu/drm/scheduler/sched_internal.h | 15 ++++++++++++---
> drivers/gpu/drm/scheduler/sched_main.c | 8 +++++++-
> drivers/gpu/drm/scheduler/sched_rq.c | 14 ++++++++++++++
> include/drm/gpu_scheduler.h | 5 +++++
> 5 files changed, 39 insertions(+), 4 deletions(-)
>
> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> index 58f51875547a..1715e1caec40 100644
> --- a/drivers/gpu/drm/scheduler/sched_entity.c
> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> @@ -61,6 +61,7 @@ static struct drm_sched_entity_stats *drm_sched_entity_stats_alloc(void)
>
> kref_init(&stats->kref);
> spin_lock_init(&stats->lock);
> + ewma_drm_sched_avgtime_init(&stats->avg_job_us);
>
> return stats;
> }
> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> index c94e38acc6f2..a120efc5d763 100644
> --- a/drivers/gpu/drm/scheduler/sched_internal.h
> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> @@ -20,6 +20,7 @@
> * @runtime: time entity spent on the GPU.
> * @prev_runtime: previous @runtime used to get the runtime delta
> * @vruntime: virtual runtime as accumulated by the fair algorithm
> + * @avg_job_us: average job duration
> */
> struct drm_sched_entity_stats {
> struct kref kref;
> @@ -27,6 +28,8 @@ struct drm_sched_entity_stats {
> ktime_t runtime;
> ktime_t prev_runtime;
> u64 vruntime;
> +
> + struct ewma_drm_sched_avgtime avg_job_us;
> };
>
> /* Used to choose between FIFO and RR job-scheduling */
> @@ -153,20 +156,26 @@ drm_sched_entity_stats_put(struct drm_sched_entity_stats *stats)
> * @job: Scheduler job to account.
> *
> * Accounts the execution time of @job to its respective entity stats object.
> + *
> + * Returns job's real duration in micro seconds.
> */
> -static inline void
> +static inline ktime_t
> drm_sched_entity_stats_job_add_gpu_time(struct drm_sched_job *job)
> {
> struct drm_sched_entity_stats *stats = job->entity_stats;
> struct drm_sched_fence *s_fence = job->s_fence;
> - ktime_t start, end;
> + ktime_t start, end, duration;
>
> start = dma_fence_timestamp(&s_fence->scheduled);
> end = dma_fence_timestamp(&s_fence->finished);
> + duration = ktime_sub(end, start);
>
> spin_lock(&stats->lock);
> - stats->runtime = ktime_add(stats->runtime, ktime_sub(end, start));
> + stats->runtime = ktime_add(stats->runtime, duration);
> + ewma_drm_sched_avgtime_add(&stats->avg_job_us, ktime_to_us(duration));
> spin_unlock(&stats->lock);
> +
> + return duration;
> }
>
> #endif
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index 8d8f9c8411f5..204d99c6699f 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -1000,7 +1000,12 @@ static void drm_sched_free_job_work(struct work_struct *w)
> struct drm_sched_job *job;
>
> while ((job = drm_sched_get_finished_job(sched))) {
> - drm_sched_entity_stats_job_add_gpu_time(job);
> + ktime_t duration = drm_sched_entity_stats_job_add_gpu_time(job);
> +
> + /* Serialized by the worker. */
> + ewma_drm_sched_avgtime_add(&sched->avg_job_us,
> + ktime_to_us(duration));
> +
> sched->ops->free_job(job);
> }
>
> @@ -1158,6 +1163,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> atomic_set(&sched->_score, 0);
> atomic64_set(&sched->job_id_count, 0);
> sched->pause_submit = false;
> + ewma_drm_sched_avgtime_init(&sched->avg_job_us);
>
> sched->ready = true;
> return 0;
> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
> index b868c794cc9d..02742869e75b 100644
> --- a/drivers/gpu/drm/scheduler/sched_rq.c
> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
> @@ -150,6 +150,20 @@ drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
> * Higher priority can go first.
> */
> vruntime = -us_to_ktime(rq_prio - prio);
> + } else {
> + struct drm_gpu_scheduler *sched = entity->rq->sched;
> +
> + /*
> + * Favour entity with shorter jobs (interactivity).
> + *
> + * (Unlocked read is fine since it is just heuristics.)
> + *
> + */
> + if (ewma_drm_sched_avgtime_read(&stats->avg_job_us) <=
> + ewma_drm_sched_avgtime_read(&sched->avg_job_us))
> + vruntime = -1;
> + else
> + vruntime = 1;
> }
> }
>
> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> index bc25508a6ff6..a7e407e04ce0 100644
> --- a/include/drm/gpu_scheduler.h
> +++ b/include/drm/gpu_scheduler.h
> @@ -25,11 +25,14 @@
> #define _DRM_GPU_SCHEDULER_H_
>
> #include <drm/spsc_queue.h>
> +#include <linux/average.h>
> #include <linux/dma-fence.h>
> #include <linux/completion.h>
> #include <linux/xarray.h>
> #include <linux/workqueue.h>
>
> +DECLARE_EWMA(drm_sched_avgtime, 6, 4);
> +
> #define MAX_WAIT_SCHED_ENTITY_Q_EMPTY msecs_to_jiffies(1000)
>
> /**
> @@ -581,6 +584,7 @@ struct drm_sched_backend_ops {
> * @job_id_count: used to assign unique id to the each job.
> * @submit_wq: workqueue used to queue @work_run_job and @work_free_job
> * @timeout_wq: workqueue used to queue @work_tdr
> + * @avg_job_us: Average job duration
> * @work_run_job: work which calls run_job op of each scheduler.
> * @work_free_job: work which calls free_job op of each scheduler.
> * @work_tdr: schedules a delayed call to @drm_sched_job_timedout after the
> @@ -612,6 +616,7 @@ struct drm_gpu_scheduler {
> atomic64_t job_id_count;
> struct workqueue_struct *submit_wq;
> struct workqueue_struct *timeout_wq;
> + struct ewma_drm_sched_avgtime avg_job_us;
> struct work_struct work_run_job;
> struct work_struct work_free_job;
> struct delayed_work work_tdr;
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 11/28] drm/sched: Favour interactive clients slightly
2025-10-14 10:53 ` Philipp Stanner
@ 2025-10-14 12:20 ` Tvrtko Ursulin
0 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-14 12:20 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Pierre-Eric Pelloux-Prayer
On 14/10/2025 11:53, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> GPUs do not always implement preemption and DRM scheduler definitely
>> does not support it at the front end scheduling level. This means
>> execution quanta can be quite long and is controlled by userspace,
>> consequence of which is picking the "wrong" entity to run can have a
>> larger negative effect than it would have with a virtual runtime based CPU
>> scheduler.
>>
>> Another important consideration is that rendering clients often have
>> shallow submission queues, meaning they will be entering and exiting the
>> scheduler's runnable queue often.
>>
>> Relevant scenario here is what happens when an entity re-joins the
>> runnable queue with other entities already present. One cornerstone of the
>> virtual runtime algorithm is to let it re-join at the head and rely on the
>> virtual runtime accounting and timeslicing to sort it out.
>>
>> However, as explained above, this may not work perfectly in the GPU world.
>> Entity could always get to overtake the existing entities, or not,
>> depending on the submission order and rbtree equal key insertion
>> behaviour.
>>
>> Allow interactive jobs to overtake entities already queued up for the
>> limited case when interactive entity is re-joining the queue after
>> being idle.
>>
>> This gives more opportunity for the compositors to have their rendering
>> executed before the GPU hogs even if they have been configured with the
>> same scheduling priority.
>>
>> To classify a client as interactive we look at its average job duration
>> versus the average for the whole scheduler. We can track this easily by
>> plugging into the existing job runtime tracking and applying the
>> exponential moving average window on the past submissions. Then, all other
>> things being equal, we let the more interactive jobs go first.
>
> OK so this patch is new. Why was it added? The cover letter says:
>
> "Improved handling of interactive clients by replacing the random noise
> on tie approach with the average job duration statistics."
>
> So this is based on additional research you have done in the mean time?
> Does it change behavior significantly when compared to the RFC?
It is a replacement patch for what used to be called "drm/sched: Break
submission patterns with some randomness".
It is only significant for a subset of workload patterns. The ones where
a lightweight client runs in parallel to something heavy. Pseudo random
noise approach made FAIR kind of middle of the road between RR and FIFO
while this version makes it almost as good as RR.
With random noise as tie breaker criteria:
https://people.igalia.com/tursulin/drm-sched-fair/4-heavy-vs-interactive.png
https://people.igalia.com/tursulin/drm-sched-fair/4-very-heavy-vs-interactive.png
https://people.igalia.com/tursulin/drm-sched-fair/4-low-hog-vs-interactive.png
With entity_job_avg < sched_job_avg tie breaker criteria:
https://people.igalia.com/tursulin/drm-sched-fair/251008/4-heavy-vs-interactive.png
https://people.igalia.com/tursulin/drm-sched-fair/251008/4-very-heavy-vs-interactive.png
https://people.igalia.com/tursulin/drm-sched-fair/251008/4-low-hog-vs-interactive.png
> The firmware scheduler bros are not affected in any case. Still, I
> think that the RFC we discussed in the past and at XDC is now quite
> more different from the actual proposal in this v1.
Series as code is not that much different, just the end result with some
use cases gets better.
If we ignore the EWMA job runtime housekeeping, it only replaced this:
+ } else {
+ static const int shuffle[2] = { -1, 1 };
+ static bool r = 0;
+
+ /*
+ * For equal priority apply some randomness to break
+ * latching caused by submission patterns.
+ */
+ vruntime = shuffle[r];
+ r ^= 1;
With this:
+ } else {
+ struct drm_gpu_scheduler *sched = entity->rq->sched;
+
+ /*
+ * Favour entity with shorter jobs (interactivity).
+ *
+ * (Unlocked read is fine since it is just heuristics.)
+ *
+ */
+ if (ewma_drm_sched_avgtime_read(&stats->avg_job_us) <=
+ ewma_drm_sched_avgtime_read(&sched->avg_job_us))
+ vruntime = -1;
+ else
+ vruntime = 1;
> I suppose it's in general good for graphics applications.. what about
> compute, doesn't that have longer jobs? Probably still good for people
> who do compute on their productive system..
Yes, should be good for everyone who runs interactive clients in
parallel to demanding workloads.
> @AMD:
> can you review / ack this?
Someone other than me is bound to test it one od these days. ;)
Regards,
Tvrtko
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
>> ---
>> drivers/gpu/drm/scheduler/sched_entity.c | 1 +
>> drivers/gpu/drm/scheduler/sched_internal.h | 15 ++++++++++++---
>> drivers/gpu/drm/scheduler/sched_main.c | 8 +++++++-
>> drivers/gpu/drm/scheduler/sched_rq.c | 14 ++++++++++++++
>> include/drm/gpu_scheduler.h | 5 +++++
>> 5 files changed, 39 insertions(+), 4 deletions(-)
>>
>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>> index 58f51875547a..1715e1caec40 100644
>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>> @@ -61,6 +61,7 @@ static struct drm_sched_entity_stats *drm_sched_entity_stats_alloc(void)
>>
>> kref_init(&stats->kref);
>> spin_lock_init(&stats->lock);
>> + ewma_drm_sched_avgtime_init(&stats->avg_job_us);
>>
>> return stats;
>> }
>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>> index c94e38acc6f2..a120efc5d763 100644
>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>> @@ -20,6 +20,7 @@
>> * @runtime: time entity spent on the GPU.
>> * @prev_runtime: previous @runtime used to get the runtime delta
>> * @vruntime: virtual runtime as accumulated by the fair algorithm
>> + * @avg_job_us: average job duration
>> */
>> struct drm_sched_entity_stats {
>> struct kref kref;
>> @@ -27,6 +28,8 @@ struct drm_sched_entity_stats {
>> ktime_t runtime;
>> ktime_t prev_runtime;
>> u64 vruntime;
>> +
>> + struct ewma_drm_sched_avgtime avg_job_us;
>> };
>>
>> /* Used to choose between FIFO and RR job-scheduling */
>> @@ -153,20 +156,26 @@ drm_sched_entity_stats_put(struct drm_sched_entity_stats *stats)
>> * @job: Scheduler job to account.
>> *
>> * Accounts the execution time of @job to its respective entity stats object.
>> + *
>> + * Returns job's real duration in micro seconds.
>> */
>> -static inline void
>> +static inline ktime_t
>> drm_sched_entity_stats_job_add_gpu_time(struct drm_sched_job *job)
>> {
>> struct drm_sched_entity_stats *stats = job->entity_stats;
>> struct drm_sched_fence *s_fence = job->s_fence;
>> - ktime_t start, end;
>> + ktime_t start, end, duration;
>>
>> start = dma_fence_timestamp(&s_fence->scheduled);
>> end = dma_fence_timestamp(&s_fence->finished);
>> + duration = ktime_sub(end, start);
>>
>> spin_lock(&stats->lock);
>> - stats->runtime = ktime_add(stats->runtime, ktime_sub(end, start));
>> + stats->runtime = ktime_add(stats->runtime, duration);
>> + ewma_drm_sched_avgtime_add(&stats->avg_job_us, ktime_to_us(duration));
>> spin_unlock(&stats->lock);
>> +
>> + return duration;
>> }
>>
>> #endif
>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>> index 8d8f9c8411f5..204d99c6699f 100644
>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>> @@ -1000,7 +1000,12 @@ static void drm_sched_free_job_work(struct work_struct *w)
>> struct drm_sched_job *job;
>>
>> while ((job = drm_sched_get_finished_job(sched))) {
>> - drm_sched_entity_stats_job_add_gpu_time(job);
>> + ktime_t duration = drm_sched_entity_stats_job_add_gpu_time(job);
>> +
>> + /* Serialized by the worker. */
>> + ewma_drm_sched_avgtime_add(&sched->avg_job_us,
>> + ktime_to_us(duration));
>> +
>> sched->ops->free_job(job);
>> }
>>
>> @@ -1158,6 +1163,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>> atomic_set(&sched->_score, 0);
>> atomic64_set(&sched->job_id_count, 0);
>> sched->pause_submit = false;
>> + ewma_drm_sched_avgtime_init(&sched->avg_job_us);
>>
>> sched->ready = true;
>> return 0;
>> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
>> index b868c794cc9d..02742869e75b 100644
>> --- a/drivers/gpu/drm/scheduler/sched_rq.c
>> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
>> @@ -150,6 +150,20 @@ drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
>> * Higher priority can go first.
>> */
>> vruntime = -us_to_ktime(rq_prio - prio);
>> + } else {
>> + struct drm_gpu_scheduler *sched = entity->rq->sched;
>> +
>> + /*
>> + * Favour entity with shorter jobs (interactivity).
>> + *
>> + * (Unlocked read is fine since it is just heuristics.)
>> + *
>> + */
>> + if (ewma_drm_sched_avgtime_read(&stats->avg_job_us) <=
>> + ewma_drm_sched_avgtime_read(&sched->avg_job_us))
>> + vruntime = -1;
>> + else
>> + vruntime = 1;
>> }
>> }
>>
>> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
>> index bc25508a6ff6..a7e407e04ce0 100644
>> --- a/include/drm/gpu_scheduler.h
>> +++ b/include/drm/gpu_scheduler.h
>> @@ -25,11 +25,14 @@
>> #define _DRM_GPU_SCHEDULER_H_
>>
>> #include <drm/spsc_queue.h>
>> +#include <linux/average.h>
>> #include <linux/dma-fence.h>
>> #include <linux/completion.h>
>> #include <linux/xarray.h>
>> #include <linux/workqueue.h>
>>
>> +DECLARE_EWMA(drm_sched_avgtime, 6, 4);
>> +
>> #define MAX_WAIT_SCHED_ENTITY_Q_EMPTY msecs_to_jiffies(1000)
>>
>> /**
>> @@ -581,6 +584,7 @@ struct drm_sched_backend_ops {
>> * @job_id_count: used to assign unique id to the each job.
>> * @submit_wq: workqueue used to queue @work_run_job and @work_free_job
>> * @timeout_wq: workqueue used to queue @work_tdr
>> + * @avg_job_us: Average job duration
>> * @work_run_job: work which calls run_job op of each scheduler.
>> * @work_free_job: work which calls free_job op of each scheduler.
>> * @work_tdr: schedules a delayed call to @drm_sched_job_timedout after the
>> @@ -612,6 +616,7 @@ struct drm_gpu_scheduler {
>> atomic64_t job_id_count;
>> struct workqueue_struct *submit_wq;
>> struct workqueue_struct *timeout_wq;
>> + struct ewma_drm_sched_avgtime avg_job_us;
>> struct work_struct work_run_job;
>> struct work_struct work_free_job;
>> struct delayed_work work_tdr;
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 12/28] drm/sched: Switch default policy to fair
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (10 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 11/28] drm/sched: Favour interactive clients slightly Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 12:56 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 13/28] drm/sched: Remove FIFO and RR and simplify to a single run queue Tvrtko Ursulin
` (16 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner,
Pierre-Eric Pelloux-Prayer
Fair policy works better than FIFO for all known use cases and either
matches or gets close to RR. Lets make it a default to improve the user
experience especially with interactive workloads competing with heavy
clients.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
---
drivers/gpu/drm/scheduler/sched_main.c | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 204d99c6699f..858fc28e91e4 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -84,7 +84,7 @@
#define CREATE_TRACE_POINTS
#include "gpu_scheduler_trace.h"
-int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
+int drm_sched_policy = DRM_SCHED_POLICY_FAIR;
/**
* DOC: sched_policy (int)
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 12/28] drm/sched: Switch default policy to fair
2025-10-08 8:53 ` [PATCH 12/28] drm/sched: Switch default policy to fair Tvrtko Ursulin
@ 2025-10-10 12:56 ` Philipp Stanner
0 siblings, 0 replies; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 12:56 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner, Pierre-Eric Pelloux-Prayer, Alex Deucher
s/fair/FAIR
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> Fair policy works better than FIFO for all known use cases and either
s/Fair/FAIR
> matches or gets close to RR. Lets make it a default to improve the user
> experience especially with interactive workloads competing with heavy
> clients.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
I hope that we'll see an a-b or two here from some of the driver folks
to see that they're aware of this coming.
@Christian, @Alex (+Cc)
Your driver is the main benefactor from this series, so your blessing
for FAIR would be neat.
P.
> ---
> drivers/gpu/drm/scheduler/sched_main.c | 2 +-
> 1 file changed, 1 insertion(+), 1 deletion(-)
>
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index 204d99c6699f..858fc28e91e4 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -84,7 +84,7 @@
> #define CREATE_TRACE_POINTS
> #include "gpu_scheduler_trace.h"
>
> -int drm_sched_policy = DRM_SCHED_POLICY_FIFO;
> +int drm_sched_policy = DRM_SCHED_POLICY_FAIR;
>
> /**
> * DOC: sched_policy (int)
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 13/28] drm/sched: Remove FIFO and RR and simplify to a single run queue
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (11 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 12/28] drm/sched: Switch default policy to fair Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-14 11:16 ` Philipp Stanner
2025-10-08 8:53 ` [PATCH 14/28] drm/sched: Embed run queue singleton into the scheduler Tvrtko Ursulin
` (15 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
Since the new fair policy is at least as good as FIFO and we can afford to
remove round-robin, we can simplify the scheduler code by making the
scheduler to run queue relationship always 1:1 and remove some code.
Also, now that the FIFO policy is gone the tree of entities is not a FIFO
tree any more so rename it to just the tree.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/amd/amdgpu/amdgpu_job.c | 23 ++-
drivers/gpu/drm/scheduler/sched_entity.c | 29 +---
drivers/gpu/drm/scheduler/sched_internal.h | 12 +-
drivers/gpu/drm/scheduler/sched_main.c | 161 ++++++---------------
drivers/gpu/drm/scheduler/sched_rq.c | 67 +++------
include/drm/gpu_scheduler.h | 36 +----
6 files changed, 82 insertions(+), 246 deletions(-)
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
index d020a890a0ea..bc07fd57310c 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
@@ -434,25 +434,22 @@ drm_sched_entity_queue_pop(struct drm_sched_entity *entity)
void amdgpu_job_stop_all_jobs_on_sched(struct drm_gpu_scheduler *sched)
{
+ struct drm_sched_rq *rq = sched->rq;
+ struct drm_sched_entity *s_entity;
struct drm_sched_job *s_job;
- struct drm_sched_entity *s_entity = NULL;
- int i;
/* Signal all jobs not yet scheduled */
- for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
- struct drm_sched_rq *rq = sched->sched_rq[i];
- spin_lock(&rq->lock);
- list_for_each_entry(s_entity, &rq->entities, list) {
- while ((s_job = drm_sched_entity_queue_pop(s_entity))) {
- struct drm_sched_fence *s_fence = s_job->s_fence;
+ spin_lock(&rq->lock);
+ list_for_each_entry(s_entity, &rq->entities, list) {
+ while ((s_job = drm_sched_entity_queue_pop(s_entity))) {
+ struct drm_sched_fence *s_fence = s_job->s_fence;
- dma_fence_signal(&s_fence->scheduled);
- dma_fence_set_error(&s_fence->finished, -EHWPOISON);
- dma_fence_signal(&s_fence->finished);
- }
+ dma_fence_signal(&s_fence->scheduled);
+ dma_fence_set_error(&s_fence->finished, -EHWPOISON);
+ dma_fence_signal(&s_fence->finished);
}
- spin_unlock(&rq->lock);
}
+ spin_unlock(&rq->lock);
/* Signal all jobs already scheduled to HW */
list_for_each_entry(s_job, &sched->pending_list, list) {
diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
index 1715e1caec40..2b03ca7c835a 100644
--- a/drivers/gpu/drm/scheduler/sched_entity.c
+++ b/drivers/gpu/drm/scheduler/sched_entity.c
@@ -109,8 +109,6 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
entity->guilty = guilty;
entity->num_sched_list = num_sched_list;
entity->priority = priority;
- entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
- DRM_SCHED_PRIORITY_KERNEL : priority;
/*
* It's perfectly valid to initialize an entity without having a valid
* scheduler attached. It's just not valid to use the scheduler before it
@@ -120,30 +118,14 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
RCU_INIT_POINTER(entity->last_scheduled, NULL);
RB_CLEAR_NODE(&entity->rb_tree_node);
- if (num_sched_list && !sched_list[0]->sched_rq) {
+ if (num_sched_list && !sched_list[0]->rq) {
/* Since every entry covered by num_sched_list
* should be non-NULL and therefore we warn drivers
* not to do this and to fix their DRM calling order.
*/
pr_warn("%s: called with uninitialized scheduler\n", __func__);
} else if (num_sched_list) {
- enum drm_sched_priority p = entity->priority;
-
- /*
- * The "priority" of an entity cannot exceed the number of
- * run-queues of a scheduler. Protect against num_rqs being 0,
- * by converting to signed. Choose the lowest priority
- * available.
- */
- if (p >= sched_list[0]->num_user_rqs) {
- dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
- p, sched_list[0]->num_user_rqs);
- p = max_t(s32,
- (s32)sched_list[0]->num_user_rqs - 1,
- (s32)DRM_SCHED_PRIORITY_KERNEL);
- entity->priority = p;
- }
- entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
+ entity->rq = sched_list[0]->rq;
}
init_completion(&entity->entity_idle);
@@ -576,7 +558,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
spin_lock(&entity->lock);
sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
- rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
+ rq = sched ? sched->rq : NULL;
if (rq != entity->rq) {
drm_sched_rq_remove_entity(entity->rq, entity);
entity->rq = rq;
@@ -600,7 +582,6 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
{
struct drm_sched_entity *entity = sched_job->entity;
bool first;
- ktime_t submit_ts;
trace_drm_sched_job_queue(sched_job, entity);
@@ -617,16 +598,14 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
/*
* After the sched_job is pushed into the entity queue, it may be
* completed and freed up at any time. We can no longer access it.
- * Make sure to set the submit_ts first, to avoid a race.
*/
- sched_job->submit_ts = submit_ts = ktime_get();
first = spsc_queue_push(&entity->job_queue, &sched_job->queue_node);
/* first job wakes up scheduler */
if (first) {
struct drm_gpu_scheduler *sched;
- sched = drm_sched_rq_add_entity(entity, submit_ts);
+ sched = drm_sched_rq_add_entity(entity);
if (sched)
drm_sched_wakeup(sched);
}
diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
index a120efc5d763..0a5b7bf2cb93 100644
--- a/drivers/gpu/drm/scheduler/sched_internal.h
+++ b/drivers/gpu/drm/scheduler/sched_internal.h
@@ -32,13 +32,6 @@ struct drm_sched_entity_stats {
struct ewma_drm_sched_avgtime avg_job_us;
};
-/* Used to choose between FIFO and RR job-scheduling */
-extern int drm_sched_policy;
-
-#define DRM_SCHED_POLICY_RR 0
-#define DRM_SCHED_POLICY_FIFO 1
-#define DRM_SCHED_POLICY_FAIR 2
-
bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
struct drm_sched_entity *entity);
void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
@@ -46,10 +39,9 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
void drm_sched_rq_init(struct drm_sched_rq *rq,
struct drm_gpu_scheduler *sched);
struct drm_sched_entity *
-drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
- struct drm_sched_rq *rq);
+drm_sched_select_entity(struct drm_gpu_scheduler *sched);
struct drm_gpu_scheduler *
-drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
+drm_sched_rq_add_entity(struct drm_sched_entity *entity);
void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
struct drm_sched_entity *entity);
void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 858fc28e91e4..518ce87f844a 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -84,15 +84,6 @@
#define CREATE_TRACE_POINTS
#include "gpu_scheduler_trace.h"
-int drm_sched_policy = DRM_SCHED_POLICY_FAIR;
-
-/**
- * DOC: sched_policy (int)
- * Used to override default entities scheduling policy in a run queue.
- */
-MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
-module_param_named(sched_policy, drm_sched_policy, int, 0444);
-
static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
{
u32 credits;
@@ -876,34 +867,6 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched)
drm_sched_run_job_queue(sched);
}
-/**
- * drm_sched_select_entity - Select next entity to process
- *
- * @sched: scheduler instance
- *
- * Return an entity to process or NULL if none are found.
- *
- * Note, that we break out of the for-loop when "entity" is non-null, which can
- * also be an error-pointer--this assures we don't process lower priority
- * run-queues. See comments in the respectively called functions.
- */
-static struct drm_sched_entity *
-drm_sched_select_entity(struct drm_gpu_scheduler *sched)
-{
- struct drm_sched_entity *entity = NULL;
- int i;
-
- /* Start with the highest priority.
- */
- for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
- entity = drm_sched_rq_select_entity(sched, sched->sched_rq[i]);
- if (entity)
- break;
- }
-
- return IS_ERR(entity) ? NULL : entity;
-}
-
/**
* drm_sched_get_finished_job - fetch the next finished job to be destroyed
*
@@ -1029,7 +992,7 @@ static void drm_sched_run_job_work(struct work_struct *w)
/* Find entity with a ready job */
entity = drm_sched_select_entity(sched);
- if (!entity)
+ if (IS_ERR_OR_NULL(entity))
return; /* No more work */
sched_job = drm_sched_entity_pop_job(entity);
@@ -1100,8 +1063,6 @@ static struct workqueue_struct *drm_sched_alloc_wq(const char *name)
*/
int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_args *args)
{
- int i;
-
sched->ops = args->ops;
sched->credit_limit = args->credit_limit;
sched->name = args->name;
@@ -1111,13 +1072,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
sched->score = args->score ? args->score : &sched->_score;
sched->dev = args->dev;
- if (args->num_rqs > DRM_SCHED_PRIORITY_COUNT) {
- /* This is a gross violation--tell drivers what the problem is.
- */
- dev_err(sched->dev, "%s: num_rqs cannot be greater than DRM_SCHED_PRIORITY_COUNT\n",
- __func__);
- return -EINVAL;
- } else if (sched->sched_rq) {
+ if (sched->rq) {
/* Not an error, but warn anyway so drivers can
* fine-tune their DRM calling order, and return all
* is good.
@@ -1137,21 +1092,11 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
sched->own_submit_wq = true;
}
- sched->num_user_rqs = args->num_rqs;
- sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
- args->num_rqs : 1;
- sched->sched_rq = kmalloc_array(sched->num_rqs,
- sizeof(*sched->sched_rq),
- GFP_KERNEL | __GFP_ZERO);
- if (!sched->sched_rq)
+ sched->rq = kmalloc(sizeof(*sched->rq), GFP_KERNEL | __GFP_ZERO);
+ if (!sched->rq)
goto Out_check_own;
- for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
- sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
- if (!sched->sched_rq[i])
- goto Out_unroll;
- drm_sched_rq_init(sched->sched_rq[i], sched);
- }
+ drm_sched_rq_init(sched->rq, sched);
init_waitqueue_head(&sched->job_scheduled);
INIT_LIST_HEAD(&sched->pending_list);
@@ -1167,12 +1112,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
sched->ready = true;
return 0;
-Out_unroll:
- for (--i ; i >= DRM_SCHED_PRIORITY_KERNEL; i--)
- kfree(sched->sched_rq[i]);
- kfree(sched->sched_rq);
- sched->sched_rq = NULL;
Out_check_own:
if (sched->own_submit_wq)
destroy_workqueue(sched->submit_wq);
@@ -1208,41 +1148,35 @@ static void drm_sched_cancel_remaining_jobs(struct drm_gpu_scheduler *sched)
*/
void drm_sched_fini(struct drm_gpu_scheduler *sched)
{
+
+ struct drm_sched_rq *rq = sched->rq;
struct drm_sched_entity *s_entity;
- int i;
drm_sched_wqueue_stop(sched);
- for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
- struct drm_sched_rq *rq = sched->sched_rq[i];
-
- spin_lock(&rq->lock);
- list_for_each_entry(s_entity, &rq->entities, list)
- /*
- * Prevents reinsertion and marks job_queue as idle,
- * it will be removed from the rq in drm_sched_entity_fini()
- * eventually
- *
- * FIXME:
- * This lacks the proper spin_lock(&s_entity->lock) and
- * is, therefore, a race condition. Most notably, it
- * can race with drm_sched_entity_push_job(). The lock
- * cannot be taken here, however, because this would
- * lead to lock inversion -> deadlock.
- *
- * The best solution probably is to enforce the life
- * time rule of all entities having to be torn down
- * before their scheduler. Then, however, locking could
- * be dropped alltogether from this function.
- *
- * For now, this remains a potential race in all
- * drivers that keep entities alive for longer than
- * the scheduler.
- */
- s_entity->stopped = true;
- spin_unlock(&rq->lock);
- kfree(sched->sched_rq[i]);
- }
+ spin_lock(&rq->lock);
+ list_for_each_entry(s_entity, &rq->entities, list)
+ /*
+ * Prevents re-insertion and marks job_queue as idle,
+ * it will be removed from the rq in drm_sched_entity_fini()
+ * eventually.
+ *
+ * FIXME:
+ * This lacks the proper spin_lock(&s_entity->lock) and is,
+ * therefore, a race condition. Most notably, it can race with
+ * drm_sched_entity_push_job(). The lock cannot be taken here,
+ * however, because this would lead to lock inversion.
+ *
+ * The best solution probably is to enforce the life time rule
+ * of all entities having to be torn down before their
+ * scheduler. Then locking could be dropped altogether from this
+ * function.
+ *
+ * For now, this remains a potential race in all drivers that
+ * keep entities alive for longer than the scheduler.
+ */
+ s_entity->stopped = true;
+ spin_unlock(&rq->lock);
/* Wakeup everyone stuck in drm_sched_entity_flush for this scheduler */
wake_up_all(&sched->job_scheduled);
@@ -1257,8 +1191,8 @@ void drm_sched_fini(struct drm_gpu_scheduler *sched)
if (sched->own_submit_wq)
destroy_workqueue(sched->submit_wq);
sched->ready = false;
- kfree(sched->sched_rq);
- sched->sched_rq = NULL;
+ kfree(sched->rq);
+ sched->rq = NULL;
if (!list_empty(&sched->pending_list))
dev_warn(sched->dev, "Tearing down scheduler while jobs are pending!\n");
@@ -1276,35 +1210,28 @@ EXPORT_SYMBOL(drm_sched_fini);
*/
void drm_sched_increase_karma(struct drm_sched_job *bad)
{
- int i;
- struct drm_sched_entity *tmp;
- struct drm_sched_entity *entity;
struct drm_gpu_scheduler *sched = bad->sched;
+ struct drm_sched_entity *entity, *tmp;
+ struct drm_sched_rq *rq = sched->rq;
/* don't change @bad's karma if it's from KERNEL RQ,
* because sometimes GPU hang would cause kernel jobs (like VM updating jobs)
* corrupt but keep in mind that kernel jobs always considered good.
*/
- if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
- atomic_inc(&bad->karma);
+ if (bad->s_priority == DRM_SCHED_PRIORITY_KERNEL)
+ return;
- for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
- struct drm_sched_rq *rq = sched->sched_rq[i];
+ atomic_inc(&bad->karma);
- spin_lock(&rq->lock);
- list_for_each_entry_safe(entity, tmp, &rq->entities, list) {
- if (bad->s_fence->scheduled.context ==
- entity->fence_context) {
- if (entity->guilty)
- atomic_set(entity->guilty, 1);
- break;
- }
- }
- spin_unlock(&rq->lock);
- if (&entity->list != &rq->entities)
- break;
+ spin_lock(&rq->lock);
+ list_for_each_entry_safe(entity, tmp, &rq->entities, list) {
+ if (bad->s_fence->scheduled.context == entity->fence_context) {
+ if (entity->guilty)
+ atomic_set(entity->guilty, 1);
+ break;
}
}
+ spin_unlock(&rq->lock);
}
EXPORT_SYMBOL(drm_sched_increase_karma);
diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
index 02742869e75b..f9c899a9629c 100644
--- a/drivers/gpu/drm/scheduler/sched_rq.c
+++ b/drivers/gpu/drm/scheduler/sched_rq.c
@@ -34,7 +34,7 @@ static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
rq->head_prio = prio;
}
-static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
+static void drm_sched_rq_remove_tree_locked(struct drm_sched_entity *entity,
struct drm_sched_rq *rq)
{
lockdep_assert_held(&entity->lock);
@@ -47,7 +47,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
}
}
-static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
+static void drm_sched_rq_update_tree_locked(struct drm_sched_entity *entity,
struct drm_sched_rq *rq,
ktime_t ts)
{
@@ -59,7 +59,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
lockdep_assert_held(&entity->lock);
lockdep_assert_held(&rq->lock);
- drm_sched_rq_remove_fifo_locked(entity, rq);
+ drm_sched_rq_remove_tree_locked(entity, rq);
entity->oldest_job_waiting = ts;
@@ -211,17 +211,17 @@ static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
* drm_sched_rq_add_entity - add an entity
*
* @entity: scheduler entity
- * @ts: submission timestamp
*
* Adds a scheduler entity to the run queue.
*
* Returns a DRM scheduler pre-selected to handle this entity.
*/
struct drm_gpu_scheduler *
-drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
+drm_sched_rq_add_entity(struct drm_sched_entity *entity)
{
struct drm_gpu_scheduler *sched;
struct drm_sched_rq *rq;
+ ktime_t ts;
/* Add the entity to the run queue */
spin_lock(&entity->lock);
@@ -241,15 +241,9 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
list_add_tail(&entity->list, &rq->entities);
}
- if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
- ts = drm_sched_rq_get_min_vruntime(rq);
- ts = drm_sched_entity_restore_vruntime(entity, ts,
- rq->head_prio);
- } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
- ts = entity->rr_ts;
- }
-
- drm_sched_rq_update_fifo_locked(entity, rq, ts);
+ ts = drm_sched_rq_get_min_vruntime(rq);
+ ts = drm_sched_entity_restore_vruntime(entity, ts, rq->head_prio);
+ drm_sched_rq_update_tree_locked(entity, rq, ts);
spin_unlock(&rq->lock);
spin_unlock(&entity->lock);
@@ -278,26 +272,11 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
atomic_dec(rq->sched->score);
list_del_init(&entity->list);
- drm_sched_rq_remove_fifo_locked(entity, rq);
+ drm_sched_rq_remove_tree_locked(entity, rq);
spin_unlock(&rq->lock);
}
-static ktime_t
-drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
-{
- ktime_t ts;
-
- lockdep_assert_held(&entity->lock);
- lockdep_assert_held(&rq->lock);
-
- ts = ktime_add_ns(rq->rr_ts, 1);
- entity->rr_ts = ts;
- rq->rr_ts = ts;
-
- return ts;
-}
-
/**
* drm_sched_rq_pop_entity - pops an entity
*
@@ -321,33 +300,23 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
if (next_job) {
ktime_t ts;
- if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
- ts = drm_sched_entity_get_job_ts(entity);
- else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
- ts = next_job->submit_ts;
- else
- ts = drm_sched_rq_get_rr_ts(rq, entity);
-
- drm_sched_rq_update_fifo_locked(entity, rq, ts);
+ ts = drm_sched_entity_get_job_ts(entity);
+ drm_sched_rq_update_tree_locked(entity, rq, ts);
} else {
- drm_sched_rq_remove_fifo_locked(entity, rq);
+ ktime_t min_vruntime;
- if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
- ktime_t min_vruntime;
-
- min_vruntime = drm_sched_rq_get_min_vruntime(rq);
- drm_sched_entity_save_vruntime(entity, min_vruntime);
- }
+ drm_sched_rq_remove_tree_locked(entity, rq);
+ min_vruntime = drm_sched_rq_get_min_vruntime(rq);
+ drm_sched_entity_save_vruntime(entity, min_vruntime);
}
spin_unlock(&rq->lock);
spin_unlock(&entity->lock);
}
/**
- * drm_sched_rq_select_entity - Select an entity which provides a job to run
+ * drm_sched_select_entity - Select an entity which provides a job to run
*
* @sched: the gpu scheduler
- * @rq: scheduler run queue to check.
*
* Find oldest waiting ready entity.
*
@@ -356,9 +325,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
* its job; return NULL, if no ready entity was found.
*/
struct drm_sched_entity *
-drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
- struct drm_sched_rq *rq)
+drm_sched_select_entity(struct drm_gpu_scheduler *sched)
{
+ struct drm_sched_rq *rq = sched->rq;
struct rb_node *rb;
spin_lock(&rq->lock);
diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
index a7e407e04ce0..d4dc4b8b770a 100644
--- a/include/drm/gpu_scheduler.h
+++ b/include/drm/gpu_scheduler.h
@@ -99,8 +99,7 @@ struct drm_sched_entity {
* @lock:
*
* Lock protecting the run-queue (@rq) to which this entity belongs,
- * @priority, the list of schedulers (@sched_list, @num_sched_list) and
- * the @rr_ts field.
+ * @priority and the list of schedulers (@sched_list, @num_sched_list).
*/
spinlock_t lock;
@@ -153,18 +152,6 @@ struct drm_sched_entity {
*/
enum drm_sched_priority priority;
- /**
- * @rq_priority: Run-queue priority
- */
- enum drm_sched_priority rq_priority;
-
- /**
- * @rr_ts:
- *
- * Fake timestamp of the last popped job from the entity.
- */
- ktime_t rr_ts;
-
/**
* @job_queue: the list of jobs of this entity.
*/
@@ -262,8 +249,7 @@ struct drm_sched_entity {
* struct drm_sched_rq - queue of entities to be scheduled.
*
* @sched: the scheduler to which this rq belongs to.
- * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
- * @rr_ts: monotonically incrementing fake timestamp for RR mode
+ * @lock: protects @entities, @rb_tree_root and @head_prio.
* @entities: list of the entities to be scheduled.
* @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
* @head_prio: priority of the top tree element
@@ -277,7 +263,6 @@ struct drm_sched_rq {
spinlock_t lock;
/* Following members are protected by the @lock: */
- ktime_t rr_ts;
struct list_head entities;
struct rb_root_cached rb_tree_root;
enum drm_sched_priority head_prio;
@@ -363,13 +348,6 @@ struct drm_sched_fence *to_drm_sched_fence(struct dma_fence *f);
* to schedule the job.
*/
struct drm_sched_job {
- /**
- * @submit_ts:
- *
- * When the job was pushed into the entity queue.
- */
- ktime_t submit_ts;
-
/**
* @sched:
*
@@ -573,11 +551,7 @@ struct drm_sched_backend_ops {
* @credit_count: the current credit count of this scheduler
* @timeout: the time after which a job is removed from the scheduler.
* @name: name of the ring for which this scheduler is being used.
- * @num_user_rqs: Number of run-queues. This is at most
- * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
- * priority, but could be less.
- * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
- * @sched_rq: An allocated array of run-queues of size @num_rqs;
+ * @rq: Scheduler run queue
* @job_scheduled: once drm_sched_entity_flush() is called the scheduler
* waits on this wait queue until all the scheduled jobs are
* finished.
@@ -609,9 +583,7 @@ struct drm_gpu_scheduler {
atomic_t credit_count;
long timeout;
const char *name;
- u32 num_rqs;
- u32 num_user_rqs;
- struct drm_sched_rq **sched_rq;
+ struct drm_sched_rq *rq;
wait_queue_head_t job_scheduled;
atomic64_t job_id_count;
struct workqueue_struct *submit_wq;
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 13/28] drm/sched: Remove FIFO and RR and simplify to a single run queue
2025-10-08 8:53 ` [PATCH 13/28] drm/sched: Remove FIFO and RR and simplify to a single run queue Tvrtko Ursulin
@ 2025-10-14 11:16 ` Philipp Stanner
2025-10-14 13:16 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-14 11:16 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> Since the new fair policy is at least as good as FIFO and we can afford to
s/fair/FAIR
> remove round-robin,
>
Better state that RR has not been used as the default since forever as
the justification.
> we can simplify the scheduler code by making the
> scheduler to run queue relationship always 1:1 and remove some code.
>
> Also, now that the FIFO policy is gone the tree of entities is not a FIFO
> tree any more so rename it to just the tree.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> ---
> drivers/gpu/drm/amd/amdgpu/amdgpu_job.c | 23 ++-
> drivers/gpu/drm/scheduler/sched_entity.c | 29 +---
> drivers/gpu/drm/scheduler/sched_internal.h | 12 +-
> drivers/gpu/drm/scheduler/sched_main.c | 161 ++++++---------------
> drivers/gpu/drm/scheduler/sched_rq.c | 67 +++------
> include/drm/gpu_scheduler.h | 36 +----
> 6 files changed, 82 insertions(+), 246 deletions(-)
Now that's nice!
Just a few more comments below; I have a bit of a tight schedule this
week.
>
> diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
> index d020a890a0ea..bc07fd57310c 100644
> --- a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
> +++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
> @@ -434,25 +434,22 @@ drm_sched_entity_queue_pop(struct drm_sched_entity *entity)
>
> void amdgpu_job_stop_all_jobs_on_sched(struct drm_gpu_scheduler *sched)
> {
> + struct drm_sched_rq *rq = sched->rq;
> + struct drm_sched_entity *s_entity;
> struct drm_sched_job *s_job;
> - struct drm_sched_entity *s_entity = NULL;
> - int i;
>
> /* Signal all jobs not yet scheduled */
> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> - struct drm_sched_rq *rq = sched->sched_rq[i];
> - spin_lock(&rq->lock);
> - list_for_each_entry(s_entity, &rq->entities, list) {
> - while ((s_job = drm_sched_entity_queue_pop(s_entity))) {
> - struct drm_sched_fence *s_fence = s_job->s_fence;
> + spin_lock(&rq->lock);
> + list_for_each_entry(s_entity, &rq->entities, list) {
> + while ((s_job = drm_sched_entity_queue_pop(s_entity))) {
> + struct drm_sched_fence *s_fence = s_job->s_fence;
>
> - dma_fence_signal(&s_fence->scheduled);
> - dma_fence_set_error(&s_fence->finished, -EHWPOISON);
> - dma_fence_signal(&s_fence->finished);
> - }
> + dma_fence_signal(&s_fence->scheduled);
> + dma_fence_set_error(&s_fence->finished, -EHWPOISON);
Do we btw. know why the error was even poisoned here?
> + dma_fence_signal(&s_fence->finished);
> }
> - spin_unlock(&rq->lock);
> }
> + spin_unlock(&rq->lock);
>
> /* Signal all jobs already scheduled to HW */
> list_for_each_entry(s_job, &sched->pending_list, list) {
> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
> index 1715e1caec40..2b03ca7c835a 100644
> --- a/drivers/gpu/drm/scheduler/sched_entity.c
> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
> @@ -109,8 +109,6 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> entity->guilty = guilty;
> entity->num_sched_list = num_sched_list;
> entity->priority = priority;
> - entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
> - DRM_SCHED_PRIORITY_KERNEL : priority;
> /*
> * It's perfectly valid to initialize an entity without having a valid
> * scheduler attached. It's just not valid to use the scheduler before it
> @@ -120,30 +118,14 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
> RCU_INIT_POINTER(entity->last_scheduled, NULL);
> RB_CLEAR_NODE(&entity->rb_tree_node);
>
> - if (num_sched_list && !sched_list[0]->sched_rq) {
> + if (num_sched_list && !sched_list[0]->rq) {
> /* Since every entry covered by num_sched_list
> * should be non-NULL and therefore we warn drivers
> * not to do this and to fix their DRM calling order.
> */
> pr_warn("%s: called with uninitialized scheduler\n", __func__);
> } else if (num_sched_list) {
> - enum drm_sched_priority p = entity->priority;
> -
> - /*
> - * The "priority" of an entity cannot exceed the number of
> - * run-queues of a scheduler. Protect against num_rqs being 0,
> - * by converting to signed. Choose the lowest priority
> - * available.
> - */
> - if (p >= sched_list[0]->num_user_rqs) {
> - dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
> - p, sched_list[0]->num_user_rqs);
> - p = max_t(s32,
> - (s32)sched_list[0]->num_user_rqs - 1,
> - (s32)DRM_SCHED_PRIORITY_KERNEL);
> - entity->priority = p;
> - }
> - entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
> + entity->rq = sched_list[0]->rq;
> }
>
> init_completion(&entity->entity_idle);
> @@ -576,7 +558,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
>
> spin_lock(&entity->lock);
> sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
> - rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
> + rq = sched ? sched->rq : NULL;
> if (rq != entity->rq) {
> drm_sched_rq_remove_entity(entity->rq, entity);
> entity->rq = rq;
> @@ -600,7 +582,6 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
> {
> struct drm_sched_entity *entity = sched_job->entity;
> bool first;
> - ktime_t submit_ts;
>
> trace_drm_sched_job_queue(sched_job, entity);
>
> @@ -617,16 +598,14 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
> /*
> * After the sched_job is pushed into the entity queue, it may be
> * completed and freed up at any time. We can no longer access it.
> - * Make sure to set the submit_ts first, to avoid a race.
> */
> - sched_job->submit_ts = submit_ts = ktime_get();
> first = spsc_queue_push(&entity->job_queue, &sched_job->queue_node);
>
> /* first job wakes up scheduler */
> if (first) {
> struct drm_gpu_scheduler *sched;
>
> - sched = drm_sched_rq_add_entity(entity, submit_ts);
> + sched = drm_sched_rq_add_entity(entity);
> if (sched)
> drm_sched_wakeup(sched);
> }
> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
> index a120efc5d763..0a5b7bf2cb93 100644
> --- a/drivers/gpu/drm/scheduler/sched_internal.h
> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
> @@ -32,13 +32,6 @@ struct drm_sched_entity_stats {
> struct ewma_drm_sched_avgtime avg_job_us;
> };
>
> -/* Used to choose between FIFO and RR job-scheduling */
> -extern int drm_sched_policy;
> -
> -#define DRM_SCHED_POLICY_RR 0
> -#define DRM_SCHED_POLICY_FIFO 1
> -#define DRM_SCHED_POLICY_FAIR 2
> -
> bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
> struct drm_sched_entity *entity);
> void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
> @@ -46,10 +39,9 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
> void drm_sched_rq_init(struct drm_sched_rq *rq,
> struct drm_gpu_scheduler *sched);
> struct drm_sched_entity *
> -drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
> - struct drm_sched_rq *rq);
> +drm_sched_select_entity(struct drm_gpu_scheduler *sched);
> struct drm_gpu_scheduler *
> -drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
> +drm_sched_rq_add_entity(struct drm_sched_entity *entity);
> void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> struct drm_sched_entity *entity);
> void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
> index 858fc28e91e4..518ce87f844a 100644
> --- a/drivers/gpu/drm/scheduler/sched_main.c
> +++ b/drivers/gpu/drm/scheduler/sched_main.c
> @@ -84,15 +84,6 @@
> #define CREATE_TRACE_POINTS
> #include "gpu_scheduler_trace.h"
>
> -int drm_sched_policy = DRM_SCHED_POLICY_FAIR;
> -
> -/**
> - * DOC: sched_policy (int)
> - * Used to override default entities scheduling policy in a run queue.
> - */
> -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
> -module_param_named(sched_policy, drm_sched_policy, int, 0444);
> -
> static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
> {
> u32 credits;
> @@ -876,34 +867,6 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched)
> drm_sched_run_job_queue(sched);
> }
>
> -/**
> - * drm_sched_select_entity - Select next entity to process
> - *
> - * @sched: scheduler instance
> - *
> - * Return an entity to process or NULL if none are found.
> - *
> - * Note, that we break out of the for-loop when "entity" is non-null, which can
> - * also be an error-pointer--this assures we don't process lower priority
> - * run-queues. See comments in the respectively called functions.
> - */
> -static struct drm_sched_entity *
> -drm_sched_select_entity(struct drm_gpu_scheduler *sched)
> -{
> - struct drm_sched_entity *entity = NULL;
> - int i;
> -
> - /* Start with the highest priority.
> - */
> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> - entity = drm_sched_rq_select_entity(sched, sched->sched_rq[i]);
> - if (entity)
> - break;
> - }
> -
> - return IS_ERR(entity) ? NULL : entity;
> -}
> -
> /**
> * drm_sched_get_finished_job - fetch the next finished job to be destroyed
> *
> @@ -1029,7 +992,7 @@ static void drm_sched_run_job_work(struct work_struct *w)
>
> /* Find entity with a ready job */
> entity = drm_sched_select_entity(sched);
> - if (!entity)
> + if (IS_ERR_OR_NULL(entity))
What's that about?
> return; /* No more work */
>
> sched_job = drm_sched_entity_pop_job(entity);
> @@ -1100,8 +1063,6 @@ static struct workqueue_struct *drm_sched_alloc_wq(const char *name)
> */
> int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_args *args)
> {
> - int i;
> -
> sched->ops = args->ops;
> sched->credit_limit = args->credit_limit;
> sched->name = args->name;
> @@ -1111,13 +1072,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> sched->score = args->score ? args->score : &sched->_score;
> sched->dev = args->dev;
>
> - if (args->num_rqs > DRM_SCHED_PRIORITY_COUNT) {
> - /* This is a gross violation--tell drivers what the problem is.
> - */
> - dev_err(sched->dev, "%s: num_rqs cannot be greater than DRM_SCHED_PRIORITY_COUNT\n",
> - __func__);
> - return -EINVAL;
> - } else if (sched->sched_rq) {
> + if (sched->rq) {
> /* Not an error, but warn anyway so drivers can
> * fine-tune their DRM calling order, and return all
> * is good.
> @@ -1137,21 +1092,11 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
> sched->own_submit_wq = true;
> }
>
> - sched->num_user_rqs = args->num_rqs;
> - sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
> - args->num_rqs : 1;
> - sched->sched_rq = kmalloc_array(sched->num_rqs,
> - sizeof(*sched->sched_rq),
> - GFP_KERNEL | __GFP_ZERO);
> - if (!sched->sched_rq)
> + sched->rq = kmalloc(sizeof(*sched->rq), GFP_KERNEL | __GFP_ZERO);
> + if (!sched->rq)
> goto Out_check_own;
>
> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> - sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
> - if (!sched->sched_rq[i])
> - goto Out_unroll;
> - drm_sched_rq_init(sched->sched_rq[i], sched);
> - }
> + drm_sched_rq_init(sched->rq, sched);
>
> init_waitqueue_head(&sched->job_scheduled);
> INIT_LIST_HEAD(&sched->pending_list);
> @@ -1167,12 +1112,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>
> sched->ready = true;
> return 0;
> -Out_unroll:
> - for (--i ; i >= DRM_SCHED_PRIORITY_KERNEL; i--)
> - kfree(sched->sched_rq[i]);
>
> - kfree(sched->sched_rq);
> - sched->sched_rq = NULL;
> Out_check_own:
> if (sched->own_submit_wq)
> destroy_workqueue(sched->submit_wq);
> @@ -1208,41 +1148,35 @@ static void drm_sched_cancel_remaining_jobs(struct drm_gpu_scheduler *sched)
> */
> void drm_sched_fini(struct drm_gpu_scheduler *sched)
> {
> +
Surplus empty line.
P.
> + struct drm_sched_rq *rq = sched->rq;
> struct drm_sched_entity *s_entity;
> - int i;
>
> drm_sched_wqueue_stop(sched);
>
> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> - struct drm_sched_rq *rq = sched->sched_rq[i];
> -
> - spin_lock(&rq->lock);
> - list_for_each_entry(s_entity, &rq->entities, list)
> - /*
> - * Prevents reinsertion and marks job_queue as idle,
> - * it will be removed from the rq in drm_sched_entity_fini()
> - * eventually
> - *
> - * FIXME:
> - * This lacks the proper spin_lock(&s_entity->lock) and
> - * is, therefore, a race condition. Most notably, it
> - * can race with drm_sched_entity_push_job(). The lock
> - * cannot be taken here, however, because this would
> - * lead to lock inversion -> deadlock.
> - *
> - * The best solution probably is to enforce the life
> - * time rule of all entities having to be torn down
> - * before their scheduler. Then, however, locking could
> - * be dropped alltogether from this function.
> - *
> - * For now, this remains a potential race in all
> - * drivers that keep entities alive for longer than
> - * the scheduler.
> - */
> - s_entity->stopped = true;
> - spin_unlock(&rq->lock);
> - kfree(sched->sched_rq[i]);
> - }
> + spin_lock(&rq->lock);
> + list_for_each_entry(s_entity, &rq->entities, list)
> + /*
> + * Prevents re-insertion and marks job_queue as idle,
> + * it will be removed from the rq in drm_sched_entity_fini()
> + * eventually.
> + *
> + * FIXME:
> + * This lacks the proper spin_lock(&s_entity->lock) and is,
> + * therefore, a race condition. Most notably, it can race with
> + * drm_sched_entity_push_job(). The lock cannot be taken here,
> + * however, because this would lead to lock inversion.
> + *
> + * The best solution probably is to enforce the life time rule
> + * of all entities having to be torn down before their
> + * scheduler. Then locking could be dropped altogether from this
> + * function.
> + *
> + * For now, this remains a potential race in all drivers that
> + * keep entities alive for longer than the scheduler.
> + */
> + s_entity->stopped = true;
> + spin_unlock(&rq->lock);
>
> /* Wakeup everyone stuck in drm_sched_entity_flush for this scheduler */
> wake_up_all(&sched->job_scheduled);
> @@ -1257,8 +1191,8 @@ void drm_sched_fini(struct drm_gpu_scheduler *sched)
> if (sched->own_submit_wq)
> destroy_workqueue(sched->submit_wq);
> sched->ready = false;
> - kfree(sched->sched_rq);
> - sched->sched_rq = NULL;
> + kfree(sched->rq);
> + sched->rq = NULL;
>
> if (!list_empty(&sched->pending_list))
> dev_warn(sched->dev, "Tearing down scheduler while jobs are pending!\n");
> @@ -1276,35 +1210,28 @@ EXPORT_SYMBOL(drm_sched_fini);
> */
> void drm_sched_increase_karma(struct drm_sched_job *bad)
> {
> - int i;
> - struct drm_sched_entity *tmp;
> - struct drm_sched_entity *entity;
> struct drm_gpu_scheduler *sched = bad->sched;
> + struct drm_sched_entity *entity, *tmp;
> + struct drm_sched_rq *rq = sched->rq;
>
> /* don't change @bad's karma if it's from KERNEL RQ,
> * because sometimes GPU hang would cause kernel jobs (like VM updating jobs)
> * corrupt but keep in mind that kernel jobs always considered good.
> */
> - if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
> - atomic_inc(&bad->karma);
> + if (bad->s_priority == DRM_SCHED_PRIORITY_KERNEL)
> + return;
>
> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
> - struct drm_sched_rq *rq = sched->sched_rq[i];
> + atomic_inc(&bad->karma);
>
> - spin_lock(&rq->lock);
> - list_for_each_entry_safe(entity, tmp, &rq->entities, list) {
> - if (bad->s_fence->scheduled.context ==
> - entity->fence_context) {
> - if (entity->guilty)
> - atomic_set(entity->guilty, 1);
> - break;
> - }
> - }
> - spin_unlock(&rq->lock);
> - if (&entity->list != &rq->entities)
> - break;
> + spin_lock(&rq->lock);
> + list_for_each_entry_safe(entity, tmp, &rq->entities, list) {
> + if (bad->s_fence->scheduled.context == entity->fence_context) {
> + if (entity->guilty)
> + atomic_set(entity->guilty, 1);
> + break;
> }
> }
> + spin_unlock(&rq->lock);
> }
> EXPORT_SYMBOL(drm_sched_increase_karma);
>
> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
> index 02742869e75b..f9c899a9629c 100644
> --- a/drivers/gpu/drm/scheduler/sched_rq.c
> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
> @@ -34,7 +34,7 @@ static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
> rq->head_prio = prio;
> }
>
> -static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> +static void drm_sched_rq_remove_tree_locked(struct drm_sched_entity *entity,
> struct drm_sched_rq *rq)
> {
> lockdep_assert_held(&entity->lock);
> @@ -47,7 +47,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
> }
> }
>
> -static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> +static void drm_sched_rq_update_tree_locked(struct drm_sched_entity *entity,
> struct drm_sched_rq *rq,
> ktime_t ts)
> {
> @@ -59,7 +59,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
> lockdep_assert_held(&entity->lock);
> lockdep_assert_held(&rq->lock);
>
> - drm_sched_rq_remove_fifo_locked(entity, rq);
> + drm_sched_rq_remove_tree_locked(entity, rq);
>
> entity->oldest_job_waiting = ts;
>
> @@ -211,17 +211,17 @@ static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
> * drm_sched_rq_add_entity - add an entity
> *
> * @entity: scheduler entity
> - * @ts: submission timestamp
> *
> * Adds a scheduler entity to the run queue.
> *
> * Returns a DRM scheduler pre-selected to handle this entity.
> */
> struct drm_gpu_scheduler *
> -drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> +drm_sched_rq_add_entity(struct drm_sched_entity *entity)
> {
> struct drm_gpu_scheduler *sched;
> struct drm_sched_rq *rq;
> + ktime_t ts;
>
> /* Add the entity to the run queue */
> spin_lock(&entity->lock);
> @@ -241,15 +241,9 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
> list_add_tail(&entity->list, &rq->entities);
> }
>
> - if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> - ts = drm_sched_rq_get_min_vruntime(rq);
> - ts = drm_sched_entity_restore_vruntime(entity, ts,
> - rq->head_prio);
> - } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
> - ts = entity->rr_ts;
> - }
> -
> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
> + ts = drm_sched_rq_get_min_vruntime(rq);
> + ts = drm_sched_entity_restore_vruntime(entity, ts, rq->head_prio);
> + drm_sched_rq_update_tree_locked(entity, rq, ts);
>
> spin_unlock(&rq->lock);
> spin_unlock(&entity->lock);
> @@ -278,26 +272,11 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
> atomic_dec(rq->sched->score);
> list_del_init(&entity->list);
>
> - drm_sched_rq_remove_fifo_locked(entity, rq);
> + drm_sched_rq_remove_tree_locked(entity, rq);
>
> spin_unlock(&rq->lock);
> }
>
> -static ktime_t
> -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
> -{
> - ktime_t ts;
> -
> - lockdep_assert_held(&entity->lock);
> - lockdep_assert_held(&rq->lock);
> -
> - ts = ktime_add_ns(rq->rr_ts, 1);
> - entity->rr_ts = ts;
> - rq->rr_ts = ts;
> -
> - return ts;
> -}
> -
> /**
> * drm_sched_rq_pop_entity - pops an entity
> *
> @@ -321,33 +300,23 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> if (next_job) {
> ktime_t ts;
>
> - if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
> - ts = drm_sched_entity_get_job_ts(entity);
> - else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
> - ts = next_job->submit_ts;
> - else
> - ts = drm_sched_rq_get_rr_ts(rq, entity);
> -
> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
> + ts = drm_sched_entity_get_job_ts(entity);
> + drm_sched_rq_update_tree_locked(entity, rq, ts);
> } else {
> - drm_sched_rq_remove_fifo_locked(entity, rq);
> + ktime_t min_vruntime;
>
> - if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
> - ktime_t min_vruntime;
> -
> - min_vruntime = drm_sched_rq_get_min_vruntime(rq);
> - drm_sched_entity_save_vruntime(entity, min_vruntime);
> - }
> + drm_sched_rq_remove_tree_locked(entity, rq);
> + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
> + drm_sched_entity_save_vruntime(entity, min_vruntime);
> }
> spin_unlock(&rq->lock);
> spin_unlock(&entity->lock);
> }
>
> /**
> - * drm_sched_rq_select_entity - Select an entity which provides a job to run
> + * drm_sched_select_entity - Select an entity which provides a job to run
> *
> * @sched: the gpu scheduler
> - * @rq: scheduler run queue to check.
> *
> * Find oldest waiting ready entity.
> *
> @@ -356,9 +325,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
> * its job; return NULL, if no ready entity was found.
> */
> struct drm_sched_entity *
> -drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
> - struct drm_sched_rq *rq)
> +drm_sched_select_entity(struct drm_gpu_scheduler *sched)
> {
> + struct drm_sched_rq *rq = sched->rq;
> struct rb_node *rb;
>
> spin_lock(&rq->lock);
> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> index a7e407e04ce0..d4dc4b8b770a 100644
> --- a/include/drm/gpu_scheduler.h
> +++ b/include/drm/gpu_scheduler.h
> @@ -99,8 +99,7 @@ struct drm_sched_entity {
> * @lock:
> *
> * Lock protecting the run-queue (@rq) to which this entity belongs,
> - * @priority, the list of schedulers (@sched_list, @num_sched_list) and
> - * the @rr_ts field.
> + * @priority and the list of schedulers (@sched_list, @num_sched_list).
> */
> spinlock_t lock;
>
> @@ -153,18 +152,6 @@ struct drm_sched_entity {
> */
> enum drm_sched_priority priority;
>
> - /**
> - * @rq_priority: Run-queue priority
> - */
> - enum drm_sched_priority rq_priority;
> -
> - /**
> - * @rr_ts:
> - *
> - * Fake timestamp of the last popped job from the entity.
> - */
> - ktime_t rr_ts;
> -
> /**
> * @job_queue: the list of jobs of this entity.
> */
> @@ -262,8 +249,7 @@ struct drm_sched_entity {
> * struct drm_sched_rq - queue of entities to be scheduled.
> *
> * @sched: the scheduler to which this rq belongs to.
> - * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
> - * @rr_ts: monotonically incrementing fake timestamp for RR mode
> + * @lock: protects @entities, @rb_tree_root and @head_prio.
> * @entities: list of the entities to be scheduled.
> * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
> * @head_prio: priority of the top tree element
> @@ -277,7 +263,6 @@ struct drm_sched_rq {
>
> spinlock_t lock;
> /* Following members are protected by the @lock: */
> - ktime_t rr_ts;
> struct list_head entities;
> struct rb_root_cached rb_tree_root;
> enum drm_sched_priority head_prio;
> @@ -363,13 +348,6 @@ struct drm_sched_fence *to_drm_sched_fence(struct dma_fence *f);
> * to schedule the job.
> */
> struct drm_sched_job {
> - /**
> - * @submit_ts:
> - *
> - * When the job was pushed into the entity queue.
> - */
> - ktime_t submit_ts;
> -
> /**
> * @sched:
> *
> @@ -573,11 +551,7 @@ struct drm_sched_backend_ops {
> * @credit_count: the current credit count of this scheduler
> * @timeout: the time after which a job is removed from the scheduler.
> * @name: name of the ring for which this scheduler is being used.
> - * @num_user_rqs: Number of run-queues. This is at most
> - * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
> - * priority, but could be less.
> - * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
> - * @sched_rq: An allocated array of run-queues of size @num_rqs;
> + * @rq: Scheduler run queue
> * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
> * waits on this wait queue until all the scheduled jobs are
> * finished.
> @@ -609,9 +583,7 @@ struct drm_gpu_scheduler {
> atomic_t credit_count;
> long timeout;
> const char *name;
> - u32 num_rqs;
> - u32 num_user_rqs;
> - struct drm_sched_rq **sched_rq;
> + struct drm_sched_rq *rq;
> wait_queue_head_t job_scheduled;
> atomic64_t job_id_count;
> struct workqueue_struct *submit_wq;
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 13/28] drm/sched: Remove FIFO and RR and simplify to a single run queue
2025-10-14 11:16 ` Philipp Stanner
@ 2025-10-14 13:16 ` Tvrtko Ursulin
0 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-14 13:16 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 14/10/2025 12:16, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> Since the new fair policy is at least as good as FIFO and we can afford to
>
> s/fair/FAIR
>
>> remove round-robin,
>>
>
> Better state that RR has not been used as the default since forever as
> the justification.
Yeah, I reworded the whole first paragraph.
>
>> we can simplify the scheduler code by making the
>> scheduler to run queue relationship always 1:1 and remove some code.
>>
>> Also, now that the FIFO policy is gone the tree of entities is not a FIFO
>> tree any more so rename it to just the tree.
>>
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> ---
>> drivers/gpu/drm/amd/amdgpu/amdgpu_job.c | 23 ++-
>> drivers/gpu/drm/scheduler/sched_entity.c | 29 +---
>> drivers/gpu/drm/scheduler/sched_internal.h | 12 +-
>> drivers/gpu/drm/scheduler/sched_main.c | 161 ++++++---------------
>> drivers/gpu/drm/scheduler/sched_rq.c | 67 +++------
>> include/drm/gpu_scheduler.h | 36 +----
>> 6 files changed, 82 insertions(+), 246 deletions(-)
>
> Now that's nice!
>
>
> Just a few more comments below; I have a bit of a tight schedule this
> week.
>
>>
>> diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
>> index d020a890a0ea..bc07fd57310c 100644
>> --- a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
>> +++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
>> @@ -434,25 +434,22 @@ drm_sched_entity_queue_pop(struct drm_sched_entity *entity)
>>
>> void amdgpu_job_stop_all_jobs_on_sched(struct drm_gpu_scheduler *sched)
>> {
>> + struct drm_sched_rq *rq = sched->rq;
>> + struct drm_sched_entity *s_entity;
>> struct drm_sched_job *s_job;
>> - struct drm_sched_entity *s_entity = NULL;
>> - int i;
>>
>> /* Signal all jobs not yet scheduled */
>> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>> - struct drm_sched_rq *rq = sched->sched_rq[i];
>> - spin_lock(&rq->lock);
>> - list_for_each_entry(s_entity, &rq->entities, list) {
>> - while ((s_job = drm_sched_entity_queue_pop(s_entity))) {
>> - struct drm_sched_fence *s_fence = s_job->s_fence;
>> + spin_lock(&rq->lock);
>> + list_for_each_entry(s_entity, &rq->entities, list) {
>> + while ((s_job = drm_sched_entity_queue_pop(s_entity))) {
>> + struct drm_sched_fence *s_fence = s_job->s_fence;
>>
>> - dma_fence_signal(&s_fence->scheduled);
>> - dma_fence_set_error(&s_fence->finished, -EHWPOISON);
>> - dma_fence_signal(&s_fence->finished);
>> - }
>> + dma_fence_signal(&s_fence->scheduled);
>> + dma_fence_set_error(&s_fence->finished, -EHWPOISON);
>
> Do we btw. know why the error was even poisoned here?
7c6e68c777f1 ("drm/amdgpu: Avoid HW GPU reset for RAS.")
Seems to be a way of RAS letting userspace know hardware error has been
detected.
>
>> + dma_fence_signal(&s_fence->finished);
>> }
>> - spin_unlock(&rq->lock);
>> }
>> + spin_unlock(&rq->lock);
>>
>> /* Signal all jobs already scheduled to HW */
>> list_for_each_entry(s_job, &sched->pending_list, list) {
>> diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
>> index 1715e1caec40..2b03ca7c835a 100644
>> --- a/drivers/gpu/drm/scheduler/sched_entity.c
>> +++ b/drivers/gpu/drm/scheduler/sched_entity.c
>> @@ -109,8 +109,6 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>> entity->guilty = guilty;
>> entity->num_sched_list = num_sched_list;
>> entity->priority = priority;
>> - entity->rq_priority = drm_sched_policy == DRM_SCHED_POLICY_FAIR ?
>> - DRM_SCHED_PRIORITY_KERNEL : priority;
>> /*
>> * It's perfectly valid to initialize an entity without having a valid
>> * scheduler attached. It's just not valid to use the scheduler before it
>> @@ -120,30 +118,14 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
>> RCU_INIT_POINTER(entity->last_scheduled, NULL);
>> RB_CLEAR_NODE(&entity->rb_tree_node);
>>
>> - if (num_sched_list && !sched_list[0]->sched_rq) {
>> + if (num_sched_list && !sched_list[0]->rq) {
>> /* Since every entry covered by num_sched_list
>> * should be non-NULL and therefore we warn drivers
>> * not to do this and to fix their DRM calling order.
>> */
>> pr_warn("%s: called with uninitialized scheduler\n", __func__);
>> } else if (num_sched_list) {
>> - enum drm_sched_priority p = entity->priority;
>> -
>> - /*
>> - * The "priority" of an entity cannot exceed the number of
>> - * run-queues of a scheduler. Protect against num_rqs being 0,
>> - * by converting to signed. Choose the lowest priority
>> - * available.
>> - */
>> - if (p >= sched_list[0]->num_user_rqs) {
>> - dev_err(sched_list[0]->dev, "entity with out-of-bounds priority:%u num_user_rqs:%u\n",
>> - p, sched_list[0]->num_user_rqs);
>> - p = max_t(s32,
>> - (s32)sched_list[0]->num_user_rqs - 1,
>> - (s32)DRM_SCHED_PRIORITY_KERNEL);
>> - entity->priority = p;
>> - }
>> - entity->rq = sched_list[0]->sched_rq[entity->rq_priority];
>> + entity->rq = sched_list[0]->rq;
>> }
>>
>> init_completion(&entity->entity_idle);
>> @@ -576,7 +558,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
>>
>> spin_lock(&entity->lock);
>> sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
>> - rq = sched ? sched->sched_rq[entity->rq_priority] : NULL;
>> + rq = sched ? sched->rq : NULL;
>> if (rq != entity->rq) {
>> drm_sched_rq_remove_entity(entity->rq, entity);
>> entity->rq = rq;
>> @@ -600,7 +582,6 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
>> {
>> struct drm_sched_entity *entity = sched_job->entity;
>> bool first;
>> - ktime_t submit_ts;
>>
>> trace_drm_sched_job_queue(sched_job, entity);
>>
>> @@ -617,16 +598,14 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
>> /*
>> * After the sched_job is pushed into the entity queue, it may be
>> * completed and freed up at any time. We can no longer access it.
>> - * Make sure to set the submit_ts first, to avoid a race.
>> */
>> - sched_job->submit_ts = submit_ts = ktime_get();
>> first = spsc_queue_push(&entity->job_queue, &sched_job->queue_node);
>>
>> /* first job wakes up scheduler */
>> if (first) {
>> struct drm_gpu_scheduler *sched;
>>
>> - sched = drm_sched_rq_add_entity(entity, submit_ts);
>> + sched = drm_sched_rq_add_entity(entity);
>> if (sched)
>> drm_sched_wakeup(sched);
>> }
>> diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
>> index a120efc5d763..0a5b7bf2cb93 100644
>> --- a/drivers/gpu/drm/scheduler/sched_internal.h
>> +++ b/drivers/gpu/drm/scheduler/sched_internal.h
>> @@ -32,13 +32,6 @@ struct drm_sched_entity_stats {
>> struct ewma_drm_sched_avgtime avg_job_us;
>> };
>>
>> -/* Used to choose between FIFO and RR job-scheduling */
>> -extern int drm_sched_policy;
>> -
>> -#define DRM_SCHED_POLICY_RR 0
>> -#define DRM_SCHED_POLICY_FIFO 1
>> -#define DRM_SCHED_POLICY_FAIR 2
>> -
>> bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
>> struct drm_sched_entity *entity);
>> void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
>> @@ -46,10 +39,9 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
>> void drm_sched_rq_init(struct drm_sched_rq *rq,
>> struct drm_gpu_scheduler *sched);
>> struct drm_sched_entity *
>> -drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
>> - struct drm_sched_rq *rq);
>> +drm_sched_select_entity(struct drm_gpu_scheduler *sched);
>> struct drm_gpu_scheduler *
>> -drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts);
>> +drm_sched_rq_add_entity(struct drm_sched_entity *entity);
>> void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
>> struct drm_sched_entity *entity);
>> void drm_sched_rq_pop_entity(struct drm_sched_entity *entity);
>> diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
>> index 858fc28e91e4..518ce87f844a 100644
>> --- a/drivers/gpu/drm/scheduler/sched_main.c
>> +++ b/drivers/gpu/drm/scheduler/sched_main.c
>> @@ -84,15 +84,6 @@
>> #define CREATE_TRACE_POINTS
>> #include "gpu_scheduler_trace.h"
>>
>> -int drm_sched_policy = DRM_SCHED_POLICY_FAIR;
>> -
>> -/**
>> - * DOC: sched_policy (int)
>> - * Used to override default entities scheduling policy in a run queue.
>> - */
>> -MODULE_PARM_DESC(sched_policy, "Specify the scheduling policy for entities on a run-queue, " __stringify(DRM_SCHED_POLICY_RR) " = Round Robin, " __stringify(DRM_SCHED_POLICY_FIFO) " = FIFO, " __stringify(DRM_SCHED_POLICY_FAIR) " = Fair (default).");
>> -module_param_named(sched_policy, drm_sched_policy, int, 0444);
>> -
>> static u32 drm_sched_available_credits(struct drm_gpu_scheduler *sched)
>> {
>> u32 credits;
>> @@ -876,34 +867,6 @@ void drm_sched_wakeup(struct drm_gpu_scheduler *sched)
>> drm_sched_run_job_queue(sched);
>> }
>>
>> -/**
>> - * drm_sched_select_entity - Select next entity to process
>> - *
>> - * @sched: scheduler instance
>> - *
>> - * Return an entity to process or NULL if none are found.
>> - *
>> - * Note, that we break out of the for-loop when "entity" is non-null, which can
>> - * also be an error-pointer--this assures we don't process lower priority
>> - * run-queues. See comments in the respectively called functions.
>> - */
>> -static struct drm_sched_entity *
>> -drm_sched_select_entity(struct drm_gpu_scheduler *sched)
>> -{
>> - struct drm_sched_entity *entity = NULL;
>> - int i;
>> -
>> - /* Start with the highest priority.
>> - */
>> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>> - entity = drm_sched_rq_select_entity(sched, sched->sched_rq[i]);
>> - if (entity)
>> - break;
>> - }
>> -
>> - return IS_ERR(entity) ? NULL : entity;
>> -}
>> -
>> /**
>> * drm_sched_get_finished_job - fetch the next finished job to be destroyed
>> *
>> @@ -1029,7 +992,7 @@ static void drm_sched_run_job_work(struct work_struct *w)
>>
>> /* Find entity with a ready job */
>> entity = drm_sched_select_entity(sched);
>> - if (!entity)
>> + if (IS_ERR_OR_NULL(entity))
>
> What's that about?
drm_sched_select_entity has been replaced with renamed
drm_sched_rq_select_entity and the former has this return value contract.
>
>> return; /* No more work */
>>
>> sched_job = drm_sched_entity_pop_job(entity);
>> @@ -1100,8 +1063,6 @@ static struct workqueue_struct *drm_sched_alloc_wq(const char *name)
>> */
>> int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_args *args)
>> {
>> - int i;
>> -
>> sched->ops = args->ops;
>> sched->credit_limit = args->credit_limit;
>> sched->name = args->name;
>> @@ -1111,13 +1072,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>> sched->score = args->score ? args->score : &sched->_score;
>> sched->dev = args->dev;
>>
>> - if (args->num_rqs > DRM_SCHED_PRIORITY_COUNT) {
>> - /* This is a gross violation--tell drivers what the problem is.
>> - */
>> - dev_err(sched->dev, "%s: num_rqs cannot be greater than DRM_SCHED_PRIORITY_COUNT\n",
>> - __func__);
>> - return -EINVAL;
>> - } else if (sched->sched_rq) {
>> + if (sched->rq) {
>> /* Not an error, but warn anyway so drivers can
>> * fine-tune their DRM calling order, and return all
>> * is good.
>> @@ -1137,21 +1092,11 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>> sched->own_submit_wq = true;
>> }
>>
>> - sched->num_user_rqs = args->num_rqs;
>> - sched->num_rqs = drm_sched_policy != DRM_SCHED_POLICY_FAIR ?
>> - args->num_rqs : 1;
>> - sched->sched_rq = kmalloc_array(sched->num_rqs,
>> - sizeof(*sched->sched_rq),
>> - GFP_KERNEL | __GFP_ZERO);
>> - if (!sched->sched_rq)
>> + sched->rq = kmalloc(sizeof(*sched->rq), GFP_KERNEL | __GFP_ZERO);
>> + if (!sched->rq)
>> goto Out_check_own;
>>
>> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>> - sched->sched_rq[i] = kzalloc(sizeof(*sched->sched_rq[i]), GFP_KERNEL);
>> - if (!sched->sched_rq[i])
>> - goto Out_unroll;
>> - drm_sched_rq_init(sched->sched_rq[i], sched);
>> - }
>> + drm_sched_rq_init(sched->rq, sched);
>>
>> init_waitqueue_head(&sched->job_scheduled);
>> INIT_LIST_HEAD(&sched->pending_list);
>> @@ -1167,12 +1112,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
>>
>> sched->ready = true;
>> return 0;
>> -Out_unroll:
>> - for (--i ; i >= DRM_SCHED_PRIORITY_KERNEL; i--)
>> - kfree(sched->sched_rq[i]);
>>
>> - kfree(sched->sched_rq);
>> - sched->sched_rq = NULL;
>> Out_check_own:
>> if (sched->own_submit_wq)
>> destroy_workqueue(sched->submit_wq);
>> @@ -1208,41 +1148,35 @@ static void drm_sched_cancel_remaining_jobs(struct drm_gpu_scheduler *sched)
>> */
>> void drm_sched_fini(struct drm_gpu_scheduler *sched)
>> {
>> +
>
> Surplus empty line.
Too many rebases and re-orders I guess. Fixed.
Regards,
Tvrtko
>
>
> P.
>
>> + struct drm_sched_rq *rq = sched->rq;
>> struct drm_sched_entity *s_entity;
>> - int i;
>>
>> drm_sched_wqueue_stop(sched);
>>
>> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>> - struct drm_sched_rq *rq = sched->sched_rq[i];
>> -
>> - spin_lock(&rq->lock);
>> - list_for_each_entry(s_entity, &rq->entities, list)
>> - /*
>> - * Prevents reinsertion and marks job_queue as idle,
>> - * it will be removed from the rq in drm_sched_entity_fini()
>> - * eventually
>> - *
>> - * FIXME:
>> - * This lacks the proper spin_lock(&s_entity->lock) and
>> - * is, therefore, a race condition. Most notably, it
>> - * can race with drm_sched_entity_push_job(). The lock
>> - * cannot be taken here, however, because this would
>> - * lead to lock inversion -> deadlock.
>> - *
>> - * The best solution probably is to enforce the life
>> - * time rule of all entities having to be torn down
>> - * before their scheduler. Then, however, locking could
>> - * be dropped alltogether from this function.
>> - *
>> - * For now, this remains a potential race in all
>> - * drivers that keep entities alive for longer than
>> - * the scheduler.
>> - */
>> - s_entity->stopped = true;
>> - spin_unlock(&rq->lock);
>> - kfree(sched->sched_rq[i]);
>> - }
>> + spin_lock(&rq->lock);
>> + list_for_each_entry(s_entity, &rq->entities, list)
>> + /*
>> + * Prevents re-insertion and marks job_queue as idle,
>> + * it will be removed from the rq in drm_sched_entity_fini()
>> + * eventually.
>> + *
>> + * FIXME:
>> + * This lacks the proper spin_lock(&s_entity->lock) and is,
>> + * therefore, a race condition. Most notably, it can race with
>> + * drm_sched_entity_push_job(). The lock cannot be taken here,
>> + * however, because this would lead to lock inversion.
>> + *
>> + * The best solution probably is to enforce the life time rule
>> + * of all entities having to be torn down before their
>> + * scheduler. Then locking could be dropped altogether from this
>> + * function.
>> + *
>> + * For now, this remains a potential race in all drivers that
>> + * keep entities alive for longer than the scheduler.
>> + */
>> + s_entity->stopped = true;
>> + spin_unlock(&rq->lock);
>>
>> /* Wakeup everyone stuck in drm_sched_entity_flush for this scheduler */
>> wake_up_all(&sched->job_scheduled);
>> @@ -1257,8 +1191,8 @@ void drm_sched_fini(struct drm_gpu_scheduler *sched)
>> if (sched->own_submit_wq)
>> destroy_workqueue(sched->submit_wq);
>> sched->ready = false;
>> - kfree(sched->sched_rq);
>> - sched->sched_rq = NULL;
>> + kfree(sched->rq);
>> + sched->rq = NULL;
>>
>> if (!list_empty(&sched->pending_list))
>> dev_warn(sched->dev, "Tearing down scheduler while jobs are pending!\n");
>> @@ -1276,35 +1210,28 @@ EXPORT_SYMBOL(drm_sched_fini);
>> */
>> void drm_sched_increase_karma(struct drm_sched_job *bad)
>> {
>> - int i;
>> - struct drm_sched_entity *tmp;
>> - struct drm_sched_entity *entity;
>> struct drm_gpu_scheduler *sched = bad->sched;
>> + struct drm_sched_entity *entity, *tmp;
>> + struct drm_sched_rq *rq = sched->rq;
>>
>> /* don't change @bad's karma if it's from KERNEL RQ,
>> * because sometimes GPU hang would cause kernel jobs (like VM updating jobs)
>> * corrupt but keep in mind that kernel jobs always considered good.
>> */
>> - if (bad->s_priority != DRM_SCHED_PRIORITY_KERNEL) {
>> - atomic_inc(&bad->karma);
>> + if (bad->s_priority == DRM_SCHED_PRIORITY_KERNEL)
>> + return;
>>
>> - for (i = DRM_SCHED_PRIORITY_KERNEL; i < sched->num_rqs; i++) {
>> - struct drm_sched_rq *rq = sched->sched_rq[i];
>> + atomic_inc(&bad->karma);
>>
>> - spin_lock(&rq->lock);
>> - list_for_each_entry_safe(entity, tmp, &rq->entities, list) {
>> - if (bad->s_fence->scheduled.context ==
>> - entity->fence_context) {
>> - if (entity->guilty)
>> - atomic_set(entity->guilty, 1);
>> - break;
>> - }
>> - }
>> - spin_unlock(&rq->lock);
>> - if (&entity->list != &rq->entities)
>> - break;
>> + spin_lock(&rq->lock);
>> + list_for_each_entry_safe(entity, tmp, &rq->entities, list) {
>> + if (bad->s_fence->scheduled.context == entity->fence_context) {
>> + if (entity->guilty)
>> + atomic_set(entity->guilty, 1);
>> + break;
>> }
>> }
>> + spin_unlock(&rq->lock);
>> }
>> EXPORT_SYMBOL(drm_sched_increase_karma);
>>
>> diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
>> index 02742869e75b..f9c899a9629c 100644
>> --- a/drivers/gpu/drm/scheduler/sched_rq.c
>> +++ b/drivers/gpu/drm/scheduler/sched_rq.c
>> @@ -34,7 +34,7 @@ static void drm_sched_rq_update_prio(struct drm_sched_rq *rq)
>> rq->head_prio = prio;
>> }
>>
>> -static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>> +static void drm_sched_rq_remove_tree_locked(struct drm_sched_entity *entity,
>> struct drm_sched_rq *rq)
>> {
>> lockdep_assert_held(&entity->lock);
>> @@ -47,7 +47,7 @@ static void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity,
>> }
>> }
>>
>> -static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>> +static void drm_sched_rq_update_tree_locked(struct drm_sched_entity *entity,
>> struct drm_sched_rq *rq,
>> ktime_t ts)
>> {
>> @@ -59,7 +59,7 @@ static void drm_sched_rq_update_fifo_locked(struct drm_sched_entity *entity,
>> lockdep_assert_held(&entity->lock);
>> lockdep_assert_held(&rq->lock);
>>
>> - drm_sched_rq_remove_fifo_locked(entity, rq);
>> + drm_sched_rq_remove_tree_locked(entity, rq);
>>
>> entity->oldest_job_waiting = ts;
>>
>> @@ -211,17 +211,17 @@ static ktime_t drm_sched_entity_get_job_ts(struct drm_sched_entity *entity)
>> * drm_sched_rq_add_entity - add an entity
>> *
>> * @entity: scheduler entity
>> - * @ts: submission timestamp
>> *
>> * Adds a scheduler entity to the run queue.
>> *
>> * Returns a DRM scheduler pre-selected to handle this entity.
>> */
>> struct drm_gpu_scheduler *
>> -drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
>> +drm_sched_rq_add_entity(struct drm_sched_entity *entity)
>> {
>> struct drm_gpu_scheduler *sched;
>> struct drm_sched_rq *rq;
>> + ktime_t ts;
>>
>> /* Add the entity to the run queue */
>> spin_lock(&entity->lock);
>> @@ -241,15 +241,9 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity, ktime_t ts)
>> list_add_tail(&entity->list, &rq->entities);
>> }
>>
>> - if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
>> - ts = drm_sched_rq_get_min_vruntime(rq);
>> - ts = drm_sched_entity_restore_vruntime(entity, ts,
>> - rq->head_prio);
>> - } else if (drm_sched_policy == DRM_SCHED_POLICY_RR) {
>> - ts = entity->rr_ts;
>> - }
>> -
>> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
>> + ts = drm_sched_rq_get_min_vruntime(rq);
>> + ts = drm_sched_entity_restore_vruntime(entity, ts, rq->head_prio);
>> + drm_sched_rq_update_tree_locked(entity, rq, ts);
>>
>> spin_unlock(&rq->lock);
>> spin_unlock(&entity->lock);
>> @@ -278,26 +272,11 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
>> atomic_dec(rq->sched->score);
>> list_del_init(&entity->list);
>>
>> - drm_sched_rq_remove_fifo_locked(entity, rq);
>> + drm_sched_rq_remove_tree_locked(entity, rq);
>>
>> spin_unlock(&rq->lock);
>> }
>>
>> -static ktime_t
>> -drm_sched_rq_get_rr_ts(struct drm_sched_rq *rq, struct drm_sched_entity *entity)
>> -{
>> - ktime_t ts;
>> -
>> - lockdep_assert_held(&entity->lock);
>> - lockdep_assert_held(&rq->lock);
>> -
>> - ts = ktime_add_ns(rq->rr_ts, 1);
>> - entity->rr_ts = ts;
>> - rq->rr_ts = ts;
>> -
>> - return ts;
>> -}
>> -
>> /**
>> * drm_sched_rq_pop_entity - pops an entity
>> *
>> @@ -321,33 +300,23 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>> if (next_job) {
>> ktime_t ts;
>>
>> - if (drm_sched_policy == DRM_SCHED_POLICY_FAIR)
>> - ts = drm_sched_entity_get_job_ts(entity);
>> - else if (drm_sched_policy == DRM_SCHED_POLICY_FIFO)
>> - ts = next_job->submit_ts;
>> - else
>> - ts = drm_sched_rq_get_rr_ts(rq, entity);
>> -
>> - drm_sched_rq_update_fifo_locked(entity, rq, ts);
>> + ts = drm_sched_entity_get_job_ts(entity);
>> + drm_sched_rq_update_tree_locked(entity, rq, ts);
>> } else {
>> - drm_sched_rq_remove_fifo_locked(entity, rq);
>> + ktime_t min_vruntime;
>>
>> - if (drm_sched_policy == DRM_SCHED_POLICY_FAIR) {
>> - ktime_t min_vruntime;
>> -
>> - min_vruntime = drm_sched_rq_get_min_vruntime(rq);
>> - drm_sched_entity_save_vruntime(entity, min_vruntime);
>> - }
>> + drm_sched_rq_remove_tree_locked(entity, rq);
>> + min_vruntime = drm_sched_rq_get_min_vruntime(rq);
>> + drm_sched_entity_save_vruntime(entity, min_vruntime);
>> }
>> spin_unlock(&rq->lock);
>> spin_unlock(&entity->lock);
>> }
>>
>> /**
>> - * drm_sched_rq_select_entity - Select an entity which provides a job to run
>> + * drm_sched_select_entity - Select an entity which provides a job to run
>> *
>> * @sched: the gpu scheduler
>> - * @rq: scheduler run queue to check.
>> *
>> * Find oldest waiting ready entity.
>> *
>> @@ -356,9 +325,9 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
>> * its job; return NULL, if no ready entity was found.
>> */
>> struct drm_sched_entity *
>> -drm_sched_rq_select_entity(struct drm_gpu_scheduler *sched,
>> - struct drm_sched_rq *rq)
>> +drm_sched_select_entity(struct drm_gpu_scheduler *sched)
>> {
>> + struct drm_sched_rq *rq = sched->rq;
>> struct rb_node *rb;
>>
>> spin_lock(&rq->lock);
>> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
>> index a7e407e04ce0..d4dc4b8b770a 100644
>> --- a/include/drm/gpu_scheduler.h
>> +++ b/include/drm/gpu_scheduler.h
>> @@ -99,8 +99,7 @@ struct drm_sched_entity {
>> * @lock:
>> *
>> * Lock protecting the run-queue (@rq) to which this entity belongs,
>> - * @priority, the list of schedulers (@sched_list, @num_sched_list) and
>> - * the @rr_ts field.
>> + * @priority and the list of schedulers (@sched_list, @num_sched_list).
>> */
>> spinlock_t lock;
>>
>> @@ -153,18 +152,6 @@ struct drm_sched_entity {
>> */
>> enum drm_sched_priority priority;
>>
>> - /**
>> - * @rq_priority: Run-queue priority
>> - */
>> - enum drm_sched_priority rq_priority;
>> -
>> - /**
>> - * @rr_ts:
>> - *
>> - * Fake timestamp of the last popped job from the entity.
>> - */
>> - ktime_t rr_ts;
>> -
>> /**
>> * @job_queue: the list of jobs of this entity.
>> */
>> @@ -262,8 +249,7 @@ struct drm_sched_entity {
>> * struct drm_sched_rq - queue of entities to be scheduled.
>> *
>> * @sched: the scheduler to which this rq belongs to.
>> - * @lock: protects @entities, @rb_tree_root, @rr_ts and @head_prio.
>> - * @rr_ts: monotonically incrementing fake timestamp for RR mode
>> + * @lock: protects @entities, @rb_tree_root and @head_prio.
>> * @entities: list of the entities to be scheduled.
>> * @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
>> * @head_prio: priority of the top tree element
>> @@ -277,7 +263,6 @@ struct drm_sched_rq {
>>
>> spinlock_t lock;
>> /* Following members are protected by the @lock: */
>> - ktime_t rr_ts;
>> struct list_head entities;
>> struct rb_root_cached rb_tree_root;
>> enum drm_sched_priority head_prio;
>> @@ -363,13 +348,6 @@ struct drm_sched_fence *to_drm_sched_fence(struct dma_fence *f);
>> * to schedule the job.
>> */
>> struct drm_sched_job {
>> - /**
>> - * @submit_ts:
>> - *
>> - * When the job was pushed into the entity queue.
>> - */
>> - ktime_t submit_ts;
>> -
>> /**
>> * @sched:
>> *
>> @@ -573,11 +551,7 @@ struct drm_sched_backend_ops {
>> * @credit_count: the current credit count of this scheduler
>> * @timeout: the time after which a job is removed from the scheduler.
>> * @name: name of the ring for which this scheduler is being used.
>> - * @num_user_rqs: Number of run-queues. This is at most
>> - * DRM_SCHED_PRIORITY_COUNT, as there's usually one run-queue per
>> - * priority, but could be less.
>> - * @num_rqs: Equal to @num_user_rqs for FIFO and RR and 1 for the FAIR policy.
>> - * @sched_rq: An allocated array of run-queues of size @num_rqs;
>> + * @rq: Scheduler run queue
>> * @job_scheduled: once drm_sched_entity_flush() is called the scheduler
>> * waits on this wait queue until all the scheduled jobs are
>> * finished.
>> @@ -609,9 +583,7 @@ struct drm_gpu_scheduler {
>> atomic_t credit_count;
>> long timeout;
>> const char *name;
>> - u32 num_rqs;
>> - u32 num_user_rqs;
>> - struct drm_sched_rq **sched_rq;
>> + struct drm_sched_rq *rq;
>> wait_queue_head_t job_scheduled;
>> atomic64_t job_id_count;
>> struct workqueue_struct *submit_wq;
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 14/28] drm/sched: Embed run queue singleton into the scheduler
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (12 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 13/28] drm/sched: Remove FIFO and RR and simplify to a single run queue Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 15/28] accel/amdxdna: Remove drm_sched_init_args->num_rqs usage Tvrtko Ursulin
` (14 subsequent siblings)
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
Now that the run queue to scheduler relationship is always 1:1 we can
embed it (the run queue) directly in the scheduler struct and save on
some allocation error handling code and such.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
drivers/gpu/drm/amd/amdgpu/amdgpu_cs.c | 6 ++--
drivers/gpu/drm/amd/amdgpu/amdgpu_job.c | 6 ++--
drivers/gpu/drm/amd/amdgpu/amdgpu_job.h | 5 +++-
drivers/gpu/drm/amd/amdgpu/amdgpu_trace.h | 8 ++++--
drivers/gpu/drm/amd/amdgpu/amdgpu_vm_sdma.c | 8 +++---
drivers/gpu/drm/amd/amdgpu/amdgpu_xcp.c | 8 +++---
drivers/gpu/drm/scheduler/sched_entity.c | 32 +++++++++------------
drivers/gpu/drm/scheduler/sched_fence.c | 2 +-
drivers/gpu/drm/scheduler/sched_internal.h | 3 +-
drivers/gpu/drm/scheduler/sched_main.c | 29 +++----------------
drivers/gpu/drm/scheduler/sched_rq.c | 16 +++++------
include/drm/gpu_scheduler.h | 5 +---
12 files changed, 55 insertions(+), 73 deletions(-)
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_cs.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_cs.c
index 9cd7741d2254..63f8e4787dfa 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_cs.c
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_cs.c
@@ -1099,7 +1099,8 @@ static int amdgpu_cs_vm_handling(struct amdgpu_cs_parser *p)
if (p->gang_size > 1 && !adev->vm_manager.concurrent_flush) {
for (i = 0; i < p->gang_size; ++i) {
struct drm_sched_entity *entity = p->entities[i];
- struct drm_gpu_scheduler *sched = entity->rq->sched;
+ struct drm_gpu_scheduler *sched =
+ container_of(entity->rq, typeof(*sched), rq);
struct amdgpu_ring *ring = to_amdgpu_ring(sched);
if (amdgpu_vmid_uses_reserved(vm, ring->vm_hub))
@@ -1230,7 +1231,8 @@ static int amdgpu_cs_sync_rings(struct amdgpu_cs_parser *p)
return r;
}
- sched = p->gang_leader->base.entity->rq->sched;
+ sched = container_of(p->gang_leader->base.entity->rq, typeof(*sched),
+ rq);
while ((fence = amdgpu_sync_get_fence(&p->sync))) {
struct drm_sched_fence *s_fence = to_drm_sched_fence(fence);
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
index bc07fd57310c..cdfaf3eb736d 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.c
@@ -341,7 +341,9 @@ static struct dma_fence *
amdgpu_job_prepare_job(struct drm_sched_job *sched_job,
struct drm_sched_entity *s_entity)
{
- struct amdgpu_ring *ring = to_amdgpu_ring(s_entity->rq->sched);
+ struct drm_gpu_scheduler *sched =
+ container_of(s_entity->rq, typeof(*sched), rq);
+ struct amdgpu_ring *ring = to_amdgpu_ring(sched);
struct amdgpu_job *job = to_amdgpu_job(sched_job);
struct dma_fence *fence;
int r;
@@ -434,7 +436,7 @@ drm_sched_entity_queue_pop(struct drm_sched_entity *entity)
void amdgpu_job_stop_all_jobs_on_sched(struct drm_gpu_scheduler *sched)
{
- struct drm_sched_rq *rq = sched->rq;
+ struct drm_sched_rq *rq = &sched->rq;
struct drm_sched_entity *s_entity;
struct drm_sched_job *s_job;
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.h b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.h
index 4a6487eb6cb5..9530b5da3adc 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_job.h
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_job.h
@@ -102,7 +102,10 @@ struct amdgpu_job {
static inline struct amdgpu_ring *amdgpu_job_ring(struct amdgpu_job *job)
{
- return to_amdgpu_ring(job->base.entity->rq->sched);
+ struct drm_gpu_scheduler *sched =
+ container_of(job->base.entity->rq, typeof(*sched), rq);
+
+ return to_amdgpu_ring(sched);
}
int amdgpu_job_alloc(struct amdgpu_device *adev, struct amdgpu_vm *vm,
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_trace.h b/drivers/gpu/drm/amd/amdgpu/amdgpu_trace.h
index d13e64a69e25..85724ec6aaf8 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_trace.h
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_trace.h
@@ -145,6 +145,7 @@ TRACE_EVENT(amdgpu_cs,
struct amdgpu_ib *ib),
TP_ARGS(p, job, ib),
TP_STRUCT__entry(
+ __field(struct drm_gpu_scheduler *, sched)
__field(struct amdgpu_bo_list *, bo_list)
__field(u32, ring)
__field(u32, dw)
@@ -152,11 +153,14 @@ TRACE_EVENT(amdgpu_cs,
),
TP_fast_assign(
+ __entry->sched = container_of(job->base.entity->rq,
+ typeof(*__entry->sched),
+ rq);
__entry->bo_list = p->bo_list;
- __entry->ring = to_amdgpu_ring(job->base.entity->rq->sched)->idx;
+ __entry->ring = to_amdgpu_ring(__entry->sched)->idx;
__entry->dw = ib->length_dw;
__entry->fences = amdgpu_fence_count_emitted(
- to_amdgpu_ring(job->base.entity->rq->sched));
+ to_amdgpu_ring(__entry->sched));
),
TP_printk("bo_list=%p, ring=%u, dw=%u, fences=%u",
__entry->bo_list, __entry->ring, __entry->dw,
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_vm_sdma.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_vm_sdma.c
index 36805dcfa159..4ccd2e769799 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_vm_sdma.c
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_vm_sdma.c
@@ -106,13 +106,13 @@ static int amdgpu_vm_sdma_prepare(struct amdgpu_vm_update_params *p,
static int amdgpu_vm_sdma_commit(struct amdgpu_vm_update_params *p,
struct dma_fence **fence)
{
+ struct drm_gpu_scheduler *sched =
+ container_of(p->vm->delayed.rq, typeof(*sched), rq);
+ struct amdgpu_ring *ring =
+ container_of(sched, struct amdgpu_ring, sched);
struct amdgpu_ib *ib = p->job->ibs;
- struct amdgpu_ring *ring;
struct dma_fence *f;
- ring = container_of(p->vm->delayed.rq->sched, struct amdgpu_ring,
- sched);
-
WARN_ON(ib->length_dw == 0);
amdgpu_ring_pad_ib(ring, ib);
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_xcp.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_xcp.c
index 1083db8cea2e..be17635ac039 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_xcp.c
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_xcp.c
@@ -465,15 +465,15 @@ int amdgpu_xcp_open_device(struct amdgpu_device *adev,
void amdgpu_xcp_release_sched(struct amdgpu_device *adev,
struct amdgpu_ctx_entity *entity)
{
- struct drm_gpu_scheduler *sched;
- struct amdgpu_ring *ring;
+ struct drm_gpu_scheduler *sched =
+ container_of(entity->entity.rq, typeof(*sched), rq);
if (!adev->xcp_mgr)
return;
- sched = entity->entity.rq->sched;
if (drm_sched_wqueue_ready(sched)) {
- ring = to_amdgpu_ring(entity->entity.rq->sched);
+ struct amdgpu_ring *ring = to_amdgpu_ring(sched);
+
atomic_dec(&adev->xcp_mgr->xcp[ring->xcp_id].ref_cnt);
}
}
diff --git a/drivers/gpu/drm/scheduler/sched_entity.c b/drivers/gpu/drm/scheduler/sched_entity.c
index 2b03ca7c835a..187538448669 100644
--- a/drivers/gpu/drm/scheduler/sched_entity.c
+++ b/drivers/gpu/drm/scheduler/sched_entity.c
@@ -115,19 +115,12 @@ int drm_sched_entity_init(struct drm_sched_entity *entity,
* is initialized itself.
*/
entity->sched_list = num_sched_list > 1 ? sched_list : NULL;
+ if (num_sched_list) {
+ entity->sched_list = num_sched_list > 1 ? sched_list : NULL;
+ entity->rq = &sched_list[0]->rq;
+ }
RCU_INIT_POINTER(entity->last_scheduled, NULL);
RB_CLEAR_NODE(&entity->rb_tree_node);
-
- if (num_sched_list && !sched_list[0]->rq) {
- /* Since every entry covered by num_sched_list
- * should be non-NULL and therefore we warn drivers
- * not to do this and to fix their DRM calling order.
- */
- pr_warn("%s: called with uninitialized scheduler\n", __func__);
- } else if (num_sched_list) {
- entity->rq = sched_list[0]->rq;
- }
-
init_completion(&entity->entity_idle);
/* We start in an idle state. */
@@ -313,7 +306,7 @@ long drm_sched_entity_flush(struct drm_sched_entity *entity, long timeout)
if (!entity->rq)
return 0;
- sched = entity->rq->sched;
+ sched = container_of(entity->rq, typeof(*sched), rq);
/*
* The client will not queue more jobs during this fini - consume
* existing queued ones, or discard them on SIGKILL.
@@ -394,10 +387,12 @@ static void drm_sched_entity_wakeup(struct dma_fence *f,
{
struct drm_sched_entity *entity =
container_of(cb, struct drm_sched_entity, cb);
+ struct drm_gpu_scheduler *sched =
+ container_of(entity->rq, typeof(*sched), rq);
entity->dependency = NULL;
dma_fence_put(f);
- drm_sched_wakeup(entity->rq->sched);
+ drm_sched_wakeup(sched);
}
/**
@@ -424,7 +419,8 @@ EXPORT_SYMBOL(drm_sched_entity_set_priority);
static bool drm_sched_entity_add_dependency_cb(struct drm_sched_entity *entity,
struct drm_sched_job *sched_job)
{
- struct drm_gpu_scheduler *sched = entity->rq->sched;
+ struct drm_gpu_scheduler *sched =
+ container_of(entity->rq, typeof(*sched), rq);
struct dma_fence *fence = entity->dependency;
struct drm_sched_fence *s_fence;
@@ -558,7 +554,7 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
spin_lock(&entity->lock);
sched = drm_sched_pick_best(entity->sched_list, entity->num_sched_list);
- rq = sched ? sched->rq : NULL;
+ rq = sched ? &sched->rq : NULL;
if (rq != entity->rq) {
drm_sched_rq_remove_entity(entity->rq, entity);
entity->rq = rq;
@@ -581,6 +577,8 @@ void drm_sched_entity_select_rq(struct drm_sched_entity *entity)
void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
{
struct drm_sched_entity *entity = sched_job->entity;
+ struct drm_gpu_scheduler *sched =
+ container_of(entity->rq, typeof(*sched), rq);
bool first;
trace_drm_sched_job_queue(sched_job, entity);
@@ -592,7 +590,7 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
xa_for_each(&sched_job->dependencies, index, entry)
trace_drm_sched_job_add_dep(sched_job, entry);
}
- atomic_inc(entity->rq->sched->score);
+ atomic_inc(sched->score);
WRITE_ONCE(entity->last_user, current->group_leader);
/*
@@ -603,8 +601,6 @@ void drm_sched_entity_push_job(struct drm_sched_job *sched_job)
/* first job wakes up scheduler */
if (first) {
- struct drm_gpu_scheduler *sched;
-
sched = drm_sched_rq_add_entity(entity);
if (sched)
drm_sched_wakeup(sched);
diff --git a/drivers/gpu/drm/scheduler/sched_fence.c b/drivers/gpu/drm/scheduler/sched_fence.c
index 9391d6f0dc01..da4f53a9ca35 100644
--- a/drivers/gpu/drm/scheduler/sched_fence.c
+++ b/drivers/gpu/drm/scheduler/sched_fence.c
@@ -227,7 +227,7 @@ void drm_sched_fence_init(struct drm_sched_fence *fence,
{
unsigned seq;
- fence->sched = entity->rq->sched;
+ fence->sched = container_of(entity->rq, typeof(*fence->sched), rq);
seq = atomic_inc_return(&entity->fence_seq);
dma_fence_init(&fence->scheduled, &drm_sched_fence_ops_scheduled,
&fence->lock, entity->fence_context, seq);
diff --git a/drivers/gpu/drm/scheduler/sched_internal.h b/drivers/gpu/drm/scheduler/sched_internal.h
index 0a5b7bf2cb93..6e92cb15b3f5 100644
--- a/drivers/gpu/drm/scheduler/sched_internal.h
+++ b/drivers/gpu/drm/scheduler/sched_internal.h
@@ -36,8 +36,7 @@ bool drm_sched_can_queue(struct drm_gpu_scheduler *sched,
struct drm_sched_entity *entity);
void drm_sched_wakeup(struct drm_gpu_scheduler *sched);
-void drm_sched_rq_init(struct drm_sched_rq *rq,
- struct drm_gpu_scheduler *sched);
+void drm_sched_rq_init(struct drm_sched_rq *rq);
struct drm_sched_entity *
drm_sched_select_entity(struct drm_gpu_scheduler *sched);
struct drm_gpu_scheduler *
diff --git a/drivers/gpu/drm/scheduler/sched_main.c b/drivers/gpu/drm/scheduler/sched_main.c
index 518ce87f844a..7de16e06a2df 100644
--- a/drivers/gpu/drm/scheduler/sched_main.c
+++ b/drivers/gpu/drm/scheduler/sched_main.c
@@ -645,7 +645,7 @@ void drm_sched_job_arm(struct drm_sched_job *job)
BUG_ON(!entity);
drm_sched_entity_select_rq(entity);
- sched = entity->rq->sched;
+ sched = container_of(entity->rq, typeof(*sched), rq);
job->sched = sched;
job->s_priority = entity->priority;
@@ -1072,15 +1072,6 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
sched->score = args->score ? args->score : &sched->_score;
sched->dev = args->dev;
- if (sched->rq) {
- /* Not an error, but warn anyway so drivers can
- * fine-tune their DRM calling order, and return all
- * is good.
- */
- dev_warn(sched->dev, "%s: scheduler already initialized!\n", __func__);
- return 0;
- }
-
if (args->submit_wq) {
sched->submit_wq = args->submit_wq;
sched->own_submit_wq = false;
@@ -1092,11 +1083,7 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
sched->own_submit_wq = true;
}
- sched->rq = kmalloc(sizeof(*sched->rq), GFP_KERNEL | __GFP_ZERO);
- if (!sched->rq)
- goto Out_check_own;
-
- drm_sched_rq_init(sched->rq, sched);
+ drm_sched_rq_init(&sched->rq);
init_waitqueue_head(&sched->job_scheduled);
INIT_LIST_HEAD(&sched->pending_list);
@@ -1112,12 +1099,6 @@ int drm_sched_init(struct drm_gpu_scheduler *sched, const struct drm_sched_init_
sched->ready = true;
return 0;
-
-Out_check_own:
- if (sched->own_submit_wq)
- destroy_workqueue(sched->submit_wq);
- dev_err(sched->dev, "%s: Failed to setup GPU scheduler--out of memory\n", __func__);
- return -ENOMEM;
}
EXPORT_SYMBOL(drm_sched_init);
@@ -1149,7 +1130,7 @@ static void drm_sched_cancel_remaining_jobs(struct drm_gpu_scheduler *sched)
void drm_sched_fini(struct drm_gpu_scheduler *sched)
{
- struct drm_sched_rq *rq = sched->rq;
+ struct drm_sched_rq *rq = &sched->rq;
struct drm_sched_entity *s_entity;
drm_sched_wqueue_stop(sched);
@@ -1191,8 +1172,6 @@ void drm_sched_fini(struct drm_gpu_scheduler *sched)
if (sched->own_submit_wq)
destroy_workqueue(sched->submit_wq);
sched->ready = false;
- kfree(sched->rq);
- sched->rq = NULL;
if (!list_empty(&sched->pending_list))
dev_warn(sched->dev, "Tearing down scheduler while jobs are pending!\n");
@@ -1212,7 +1191,7 @@ void drm_sched_increase_karma(struct drm_sched_job *bad)
{
struct drm_gpu_scheduler *sched = bad->sched;
struct drm_sched_entity *entity, *tmp;
- struct drm_sched_rq *rq = sched->rq;
+ struct drm_sched_rq *rq = &sched->rq;
/* don't change @bad's karma if it's from KERNEL RQ,
* because sometimes GPU hang would cause kernel jobs (like VM updating jobs)
diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/scheduler/sched_rq.c
index f9c899a9629c..8b593e19b66c 100644
--- a/drivers/gpu/drm/scheduler/sched_rq.c
+++ b/drivers/gpu/drm/scheduler/sched_rq.c
@@ -72,17 +72,14 @@ static void drm_sched_rq_update_tree_locked(struct drm_sched_entity *entity,
* drm_sched_rq_init - initialize a given run queue struct
*
* @rq: scheduler run queue
- * @sched: scheduler instance to associate with this run queue
*
* Initializes a scheduler runqueue.
*/
-void drm_sched_rq_init(struct drm_sched_rq *rq,
- struct drm_gpu_scheduler *sched)
+void drm_sched_rq_init(struct drm_sched_rq *rq)
{
spin_lock_init(&rq->lock);
INIT_LIST_HEAD(&rq->entities);
rq->rb_tree_root = RB_ROOT_CACHED;
- rq->sched = sched;
rq->head_prio = -1;
}
@@ -151,7 +148,8 @@ drm_sched_entity_restore_vruntime(struct drm_sched_entity *entity,
*/
vruntime = -us_to_ktime(rq_prio - prio);
} else {
- struct drm_gpu_scheduler *sched = entity->rq->sched;
+ struct drm_gpu_scheduler *sched =
+ container_of(entity->rq, typeof(*sched), rq);
/*
* Favour entity with shorter jobs (interactivity).
@@ -233,8 +231,8 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity)
}
rq = entity->rq;
+ sched = container_of(rq, typeof(*sched), rq);
spin_lock(&rq->lock);
- sched = rq->sched;
if (list_empty(&entity->list)) {
atomic_inc(sched->score);
@@ -262,6 +260,8 @@ drm_sched_rq_add_entity(struct drm_sched_entity *entity)
void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
struct drm_sched_entity *entity)
{
+ struct drm_gpu_scheduler *sched = container_of(rq, typeof(*sched), rq);
+
lockdep_assert_held(&entity->lock);
if (list_empty(&entity->list))
@@ -269,7 +269,7 @@ void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,
spin_lock(&rq->lock);
- atomic_dec(rq->sched->score);
+ atomic_dec(sched->score);
list_del_init(&entity->list);
drm_sched_rq_remove_tree_locked(entity, rq);
@@ -327,7 +327,7 @@ void drm_sched_rq_pop_entity(struct drm_sched_entity *entity)
struct drm_sched_entity *
drm_sched_select_entity(struct drm_gpu_scheduler *sched)
{
- struct drm_sched_rq *rq = sched->rq;
+ struct drm_sched_rq *rq = &sched->rq;
struct rb_node *rb;
spin_lock(&rq->lock);
diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
index d4dc4b8b770a..21129c98ce56 100644
--- a/include/drm/gpu_scheduler.h
+++ b/include/drm/gpu_scheduler.h
@@ -248,7 +248,6 @@ struct drm_sched_entity {
/**
* struct drm_sched_rq - queue of entities to be scheduled.
*
- * @sched: the scheduler to which this rq belongs to.
* @lock: protects @entities, @rb_tree_root and @head_prio.
* @entities: list of the entities to be scheduled.
* @rb_tree_root: root of time based priority queue of entities for FIFO scheduling
@@ -259,8 +258,6 @@ struct drm_sched_entity {
* the next entity to emit commands from.
*/
struct drm_sched_rq {
- struct drm_gpu_scheduler *sched;
-
spinlock_t lock;
/* Following members are protected by the @lock: */
struct list_head entities;
@@ -583,7 +580,7 @@ struct drm_gpu_scheduler {
atomic_t credit_count;
long timeout;
const char *name;
- struct drm_sched_rq *rq;
+ struct drm_sched_rq rq;
wait_queue_head_t job_scheduled;
atomic64_t job_id_count;
struct workqueue_struct *submit_wq;
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 15/28] accel/amdxdna: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (13 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 14/28] drm/sched: Embed run queue singleton into the scheduler Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 16/28] accel/rocket: " Tvrtko Ursulin
` (13 subsequent siblings)
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Min Ma, Lizhi Hou, Oded Gabbay
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Min Ma <mamin506@gmail.com>
Cc: Lizhi Hou <lizhi.hou@amd.com>
Cc: Oded Gabbay <ogabbay@kernel.org>
---
drivers/accel/amdxdna/aie2_ctx.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/accel/amdxdna/aie2_ctx.c b/drivers/accel/amdxdna/aie2_ctx.c
index 691fdb3b008f..79dfea1bca02 100644
--- a/drivers/accel/amdxdna/aie2_ctx.c
+++ b/drivers/accel/amdxdna/aie2_ctx.c
@@ -528,7 +528,6 @@ int aie2_hwctx_init(struct amdxdna_hwctx *hwctx)
struct amdxdna_dev *xdna = client->xdna;
const struct drm_sched_init_args args = {
.ops = &sched_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = HWCTX_MAX_CMDS,
.timeout = msecs_to_jiffies(HWCTX_MAX_TIMEOUT),
.name = "amdxdna_js",
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 16/28] accel/rocket: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (14 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 15/28] accel/amdxdna: Remove drm_sched_init_args->num_rqs usage Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 17/28] drm/amdgpu: " Tvrtko Ursulin
` (12 subsequent siblings)
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel; +Cc: kernel-dev, Tvrtko Ursulin, Tomeu Vizoso, Oded Gabbay
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Tomeu Vizoso <tomeu@tomeuvizoso.net>
Cc: Oded Gabbay <ogabbay@kernel.org>
---
drivers/accel/rocket/rocket_job.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/accel/rocket/rocket_job.c b/drivers/accel/rocket/rocket_job.c
index acd606160dc9..6ff81cff81af 100644
--- a/drivers/accel/rocket/rocket_job.c
+++ b/drivers/accel/rocket/rocket_job.c
@@ -437,7 +437,6 @@ int rocket_job_init(struct rocket_core *core)
{
struct drm_sched_init_args args = {
.ops = &rocket_sched_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = 1,
.timeout = msecs_to_jiffies(JOB_TIMEOUT_MS),
.name = dev_name(core->dev),
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 17/28] drm/amdgpu: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (15 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 16/28] accel/rocket: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 18/28] drm/etnaviv: " Tvrtko Ursulin
` (11 subsequent siblings)
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Alex Deucher, Christian König
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Alex Deucher <alexander.deucher@amd.com>
Cc: "Christian König" <christian.koenig@amd.com>
Cc: amd-gfx@lists.freedesktop.org
---
drivers/gpu/drm/amd/amdgpu/amdgpu_device.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_device.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_device.c
index a77000c2e0bb..548f61515519 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_device.c
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_device.c
@@ -3032,7 +3032,6 @@ static int amdgpu_device_init_schedulers(struct amdgpu_device *adev)
{
struct drm_sched_init_args args = {
.ops = &amdgpu_sched_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.timeout_wq = adev->reset_domain->wq,
.dev = adev->dev,
};
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 18/28] drm/etnaviv: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (16 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 17/28] drm/amdgpu: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 10:31 ` Christian Gmeiner
2025-10-08 8:53 ` [PATCH 19/28] drm/imagination: " Tvrtko Ursulin
` (10 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Lucas Stach, Russell King,
Christian Gmeiner, etnaviv
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Lucas Stach <l.stach@pengutronix.de>
Cc: Russell King <linux+etnaviv@armlinux.org.uk>
Cc: Christian Gmeiner <christian.gmeiner@gmail.com>
Cc: etnaviv@lists.freedesktop.org
---
drivers/gpu/drm/etnaviv/etnaviv_sched.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/gpu/drm/etnaviv/etnaviv_sched.c b/drivers/gpu/drm/etnaviv/etnaviv_sched.c
index df4232d7e135..63f672536516 100644
--- a/drivers/gpu/drm/etnaviv/etnaviv_sched.c
+++ b/drivers/gpu/drm/etnaviv/etnaviv_sched.c
@@ -142,7 +142,6 @@ int etnaviv_sched_init(struct etnaviv_gpu *gpu)
{
const struct drm_sched_init_args args = {
.ops = &etnaviv_sched_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = etnaviv_hw_jobs_limit,
.hang_limit = etnaviv_job_hang_limit,
.timeout = msecs_to_jiffies(500),
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 19/28] drm/imagination: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (17 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 18/28] drm/etnaviv: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 14:29 ` Matt Coster
2025-10-08 8:53 ` [PATCH 20/28] drm/lima: " Tvrtko Ursulin
` (9 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel; +Cc: kernel-dev, Tvrtko Ursulin, Frank Binns, Matt Coster
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Frank Binns <frank.binns@imgtec.com>
Cc: Matt Coster <matt.coster@imgtec.com>
Cc: dri-devel@lists.freedesktop.org
---
drivers/gpu/drm/imagination/pvr_queue.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/gpu/drm/imagination/pvr_queue.c b/drivers/gpu/drm/imagination/pvr_queue.c
index fc415dd0d7a7..3509bea293bd 100644
--- a/drivers/gpu/drm/imagination/pvr_queue.c
+++ b/drivers/gpu/drm/imagination/pvr_queue.c
@@ -1228,7 +1228,6 @@ struct pvr_queue *pvr_queue_create(struct pvr_context *ctx,
const struct drm_sched_init_args sched_args = {
.ops = &pvr_queue_sched_ops,
.submit_wq = pvr_dev->sched_wq,
- .num_rqs = 1,
.credit_limit = 64 * 1024,
.hang_limit = 1,
.timeout = msecs_to_jiffies(500),
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 19/28] drm/imagination: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 ` [PATCH 19/28] drm/imagination: " Tvrtko Ursulin
@ 2025-10-10 14:29 ` Matt Coster
0 siblings, 0 replies; 76+ messages in thread
From: Matt Coster @ 2025-10-10 14:29 UTC (permalink / raw)
To: Tvrtko Ursulin
Cc: Frank Binns, Alessio Belle, Alexandru Dadu,
amd-gfx@lists.freedesktop.org, dri-devel@lists.freedesktop.org,
kernel-dev@igalia.com
[-- Attachment #1.1: Type: text/plain, Size: 1054 bytes --]
On 08/10/2025 09:53, Tvrtko Ursulin wrote:
> Remove member no longer used by the scheduler core.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Frank Binns <frank.binns@imgtec.com>
> Cc: Matt Coster <matt.coster@imgtec.com>
> Cc: dri-devel@lists.freedesktop.org
Reviewed-by: Matt Coster <matt.coster@imgtec.com>
> ---
> drivers/gpu/drm/imagination/pvr_queue.c | 1 -
> 1 file changed, 1 deletion(-)
>
> diff --git a/drivers/gpu/drm/imagination/pvr_queue.c b/drivers/gpu/drm/imagination/pvr_queue.c
> index fc415dd0d7a7..3509bea293bd 100644
> --- a/drivers/gpu/drm/imagination/pvr_queue.c
> +++ b/drivers/gpu/drm/imagination/pvr_queue.c
> @@ -1228,7 +1228,6 @@ struct pvr_queue *pvr_queue_create(struct pvr_context *ctx,
> const struct drm_sched_init_args sched_args = {
> .ops = &pvr_queue_sched_ops,
> .submit_wq = pvr_dev->sched_wq,
> - .num_rqs = 1,
> .credit_limit = 64 * 1024,
> .hang_limit = 1,
> .timeout = msecs_to_jiffies(500),
--
Matt Coster
E: matt.coster@imgtec.com
[-- Attachment #2: OpenPGP digital signature --]
[-- Type: application/pgp-signature, Size: 236 bytes --]
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 20/28] drm/lima: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (18 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 19/28] drm/imagination: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 21/28] drm/msm: " Tvrtko Ursulin
` (8 subsequent siblings)
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel; +Cc: kernel-dev, Tvrtko Ursulin, Qiang Yu, lima
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Qiang Yu <yuq825@gmail.com>
Cc: lima@lists.freedesktop.org
---
drivers/gpu/drm/lima/lima_sched.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/gpu/drm/lima/lima_sched.c b/drivers/gpu/drm/lima/lima_sched.c
index 739e8c6c6d90..88a861cb5c39 100644
--- a/drivers/gpu/drm/lima/lima_sched.c
+++ b/drivers/gpu/drm/lima/lima_sched.c
@@ -519,7 +519,6 @@ int lima_sched_pipe_init(struct lima_sched_pipe *pipe, const char *name)
lima_sched_timeout_ms : 10000;
const struct drm_sched_init_args args = {
.ops = &lima_sched_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = 1,
.hang_limit = lima_job_hang_limit,
.timeout = msecs_to_jiffies(timeout),
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 21/28] drm/msm: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (19 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 20/28] drm/lima: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 22/28] drm/nouveau: " Tvrtko Ursulin
` (7 subsequent siblings)
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Rob Clark, linux-arm-msm, freedreno
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Rob Clark <robin.clark@oss.qualcomm.com>
Cc: linux-arm-msm@vger.kernel.org
Cc: freedreno@lists.freedesktop.org
---
drivers/gpu/drm/msm/msm_gem_vma.c | 1 -
drivers/gpu/drm/msm/msm_ringbuffer.c | 1 -
2 files changed, 2 deletions(-)
diff --git a/drivers/gpu/drm/msm/msm_gem_vma.c b/drivers/gpu/drm/msm/msm_gem_vma.c
index 8316af1723c2..478e31073c31 100644
--- a/drivers/gpu/drm/msm/msm_gem_vma.c
+++ b/drivers/gpu/drm/msm/msm_gem_vma.c
@@ -813,7 +813,6 @@ msm_gem_vm_create(struct drm_device *drm, struct msm_mmu *mmu, const char *name,
if (!managed) {
struct drm_sched_init_args args = {
.ops = &msm_vm_bind_ops,
- .num_rqs = 1,
.credit_limit = 1,
.timeout = MAX_SCHEDULE_TIMEOUT,
.name = "msm-vm-bind",
diff --git a/drivers/gpu/drm/msm/msm_ringbuffer.c b/drivers/gpu/drm/msm/msm_ringbuffer.c
index b2f612e5dc79..f7f0312a7dc0 100644
--- a/drivers/gpu/drm/msm/msm_ringbuffer.c
+++ b/drivers/gpu/drm/msm/msm_ringbuffer.c
@@ -67,7 +67,6 @@ struct msm_ringbuffer *msm_ringbuffer_new(struct msm_gpu *gpu, int id,
{
struct drm_sched_init_args args = {
.ops = &msm_sched_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = num_hw_submissions,
.timeout = MAX_SCHEDULE_TIMEOUT,
.dev = gpu->dev->dev,
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 22/28] drm/nouveau: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (20 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 21/28] drm/msm: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 23/28] drm/panfrost: " Tvrtko Ursulin
` (6 subsequent siblings)
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Lyude Paul, Danilo Krummrich, nouveau
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Lyude Paul <lyude@redhat.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: nouveau@lists.freedesktop.org
---
drivers/gpu/drm/nouveau/nouveau_sched.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/gpu/drm/nouveau/nouveau_sched.c b/drivers/gpu/drm/nouveau/nouveau_sched.c
index e60f7892f5ce..d00e0f8dcfda 100644
--- a/drivers/gpu/drm/nouveau/nouveau_sched.c
+++ b/drivers/gpu/drm/nouveau/nouveau_sched.c
@@ -407,7 +407,6 @@ nouveau_sched_init(struct nouveau_sched *sched, struct nouveau_drm *drm,
struct drm_sched_entity *entity = &sched->entity;
struct drm_sched_init_args args = {
.ops = &nouveau_sched_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = credit_limit,
.timeout = msecs_to_jiffies(NOUVEAU_SCHED_JOB_TIMEOUT_MS),
.name = "nouveau_sched",
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 23/28] drm/panfrost: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (21 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 22/28] drm/nouveau: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 14:55 ` Steven Price
2025-10-08 8:53 ` [PATCH 24/28] drm/panthor: " Tvrtko Ursulin
` (5 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Boris Brezillon, Rob Herring
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Boris Brezillon <boris.brezillon@collabora.com>
Cc: Rob Herring <robh@kernel.org>
Cc: dri-devel@lists.freedesktop.org
---
drivers/gpu/drm/panfrost/panfrost_job.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/gpu/drm/panfrost/panfrost_job.c b/drivers/gpu/drm/panfrost/panfrost_job.c
index c47d14eabbae..351cda53d08d 100644
--- a/drivers/gpu/drm/panfrost/panfrost_job.c
+++ b/drivers/gpu/drm/panfrost/panfrost_job.c
@@ -843,7 +843,6 @@ int panfrost_job_init(struct panfrost_device *pfdev)
{
struct drm_sched_init_args args = {
.ops = &panfrost_sched_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = 2,
.timeout = msecs_to_jiffies(JOB_TIMEOUT_MS),
.name = "pan_js",
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 23/28] drm/panfrost: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 ` [PATCH 23/28] drm/panfrost: " Tvrtko Ursulin
@ 2025-10-08 14:55 ` Steven Price
0 siblings, 0 replies; 76+ messages in thread
From: Steven Price @ 2025-10-08 14:55 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Boris Brezillon, Rob Herring
On 08/10/2025 09:53, Tvrtko Ursulin wrote:
> Remove member no longer used by the scheduler core.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Boris Brezillon <boris.brezillon@collabora.com>
> Cc: Rob Herring <robh@kernel.org>
> Cc: dri-devel@lists.freedesktop.org
Reviewed-by: Steven Price <steven.price@arm.com>
> ---
> drivers/gpu/drm/panfrost/panfrost_job.c | 1 -
> 1 file changed, 1 deletion(-)
>
> diff --git a/drivers/gpu/drm/panfrost/panfrost_job.c b/drivers/gpu/drm/panfrost/panfrost_job.c
> index c47d14eabbae..351cda53d08d 100644
> --- a/drivers/gpu/drm/panfrost/panfrost_job.c
> +++ b/drivers/gpu/drm/panfrost/panfrost_job.c
> @@ -843,7 +843,6 @@ int panfrost_job_init(struct panfrost_device *pfdev)
> {
> struct drm_sched_init_args args = {
> .ops = &panfrost_sched_ops,
> - .num_rqs = DRM_SCHED_PRIORITY_COUNT,
> .credit_limit = 2,
> .timeout = msecs_to_jiffies(JOB_TIMEOUT_MS),
> .name = "pan_js",
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 24/28] drm/panthor: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (22 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 23/28] drm/panfrost: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 14:55 ` Steven Price
2025-10-10 10:02 ` Liviu Dudau
2025-10-08 8:53 ` [PATCH 25/28] drm/sched: " Tvrtko Ursulin
` (4 subsequent siblings)
28 siblings, 2 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Boris Brezillon, Steven Price,
Liviu Dudau
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Boris Brezillon <boris.brezillon@collabora.com>
Cc: Steven Price <steven.price@arm.com>
Cc: Liviu Dudau <liviu.dudau@arm.com>
Cc: dri-devel@lists.freedesktop.org
---
drivers/gpu/drm/panthor/panthor_mmu.c | 1 -
drivers/gpu/drm/panthor/panthor_sched.c | 1 -
2 files changed, 2 deletions(-)
diff --git a/drivers/gpu/drm/panthor/panthor_mmu.c b/drivers/gpu/drm/panthor/panthor_mmu.c
index 6dec4354e378..048a61d9fad6 100644
--- a/drivers/gpu/drm/panthor/panthor_mmu.c
+++ b/drivers/gpu/drm/panthor/panthor_mmu.c
@@ -2327,7 +2327,6 @@ panthor_vm_create(struct panthor_device *ptdev, bool for_mcu,
const struct drm_sched_init_args sched_args = {
.ops = &panthor_vm_bind_ops,
.submit_wq = ptdev->mmu->vm.wq,
- .num_rqs = 1,
.credit_limit = 1,
/* Bind operations are synchronous for now, no timeout needed. */
.timeout = MAX_SCHEDULE_TIMEOUT,
diff --git a/drivers/gpu/drm/panthor/panthor_sched.c b/drivers/gpu/drm/panthor/panthor_sched.c
index f5e01cb16cfc..5b95868169ac 100644
--- a/drivers/gpu/drm/panthor/panthor_sched.c
+++ b/drivers/gpu/drm/panthor/panthor_sched.c
@@ -3318,7 +3318,6 @@ group_create_queue(struct panthor_group *group,
struct drm_sched_init_args sched_args = {
.ops = &panthor_queue_sched_ops,
.submit_wq = group->ptdev->scheduler->wq,
- .num_rqs = 1,
/*
* The credit limit argument tells us the total number of
* instructions across all CS slots in the ringbuffer, with
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 24/28] drm/panthor: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 ` [PATCH 24/28] drm/panthor: " Tvrtko Ursulin
@ 2025-10-08 14:55 ` Steven Price
2025-10-10 10:02 ` Liviu Dudau
1 sibling, 0 replies; 76+ messages in thread
From: Steven Price @ 2025-10-08 14:55 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Boris Brezillon, Liviu Dudau
On 08/10/2025 09:53, Tvrtko Ursulin wrote:
> Remove member no longer used by the scheduler core.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Boris Brezillon <boris.brezillon@collabora.com>
> Cc: Steven Price <steven.price@arm.com>
> Cc: Liviu Dudau <liviu.dudau@arm.com>
> Cc: dri-devel@lists.freedesktop.org
Reviewed-by: Steven Price <steven.price@arm.com>
> ---
> drivers/gpu/drm/panthor/panthor_mmu.c | 1 -
> drivers/gpu/drm/panthor/panthor_sched.c | 1 -
> 2 files changed, 2 deletions(-)
>
> diff --git a/drivers/gpu/drm/panthor/panthor_mmu.c b/drivers/gpu/drm/panthor/panthor_mmu.c
> index 6dec4354e378..048a61d9fad6 100644
> --- a/drivers/gpu/drm/panthor/panthor_mmu.c
> +++ b/drivers/gpu/drm/panthor/panthor_mmu.c
> @@ -2327,7 +2327,6 @@ panthor_vm_create(struct panthor_device *ptdev, bool for_mcu,
> const struct drm_sched_init_args sched_args = {
> .ops = &panthor_vm_bind_ops,
> .submit_wq = ptdev->mmu->vm.wq,
> - .num_rqs = 1,
> .credit_limit = 1,
> /* Bind operations are synchronous for now, no timeout needed. */
> .timeout = MAX_SCHEDULE_TIMEOUT,
> diff --git a/drivers/gpu/drm/panthor/panthor_sched.c b/drivers/gpu/drm/panthor/panthor_sched.c
> index f5e01cb16cfc..5b95868169ac 100644
> --- a/drivers/gpu/drm/panthor/panthor_sched.c
> +++ b/drivers/gpu/drm/panthor/panthor_sched.c
> @@ -3318,7 +3318,6 @@ group_create_queue(struct panthor_group *group,
> struct drm_sched_init_args sched_args = {
> .ops = &panthor_queue_sched_ops,
> .submit_wq = group->ptdev->scheduler->wq,
> - .num_rqs = 1,
> /*
> * The credit limit argument tells us the total number of
> * instructions across all CS slots in the ringbuffer, with
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 24/28] drm/panthor: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 ` [PATCH 24/28] drm/panthor: " Tvrtko Ursulin
2025-10-08 14:55 ` Steven Price
@ 2025-10-10 10:02 ` Liviu Dudau
1 sibling, 0 replies; 76+ messages in thread
From: Liviu Dudau @ 2025-10-10 10:02 UTC (permalink / raw)
To: Tvrtko Ursulin
Cc: amd-gfx, dri-devel, kernel-dev, Boris Brezillon, Steven Price
On Wed, Oct 08, 2025 at 09:53:55AM +0100, Tvrtko Ursulin wrote:
> Remove member no longer used by the scheduler core.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Boris Brezillon <boris.brezillon@collabora.com>
> Cc: Steven Price <steven.price@arm.com>
> Cc: Liviu Dudau <liviu.dudau@arm.com>
> Cc: dri-devel@lists.freedesktop.org
Reviewed-by: Liviu Dudau <liviu.dudau@arm.com>
Best regards,
Liviu
> ---
> drivers/gpu/drm/panthor/panthor_mmu.c | 1 -
> drivers/gpu/drm/panthor/panthor_sched.c | 1 -
> 2 files changed, 2 deletions(-)
>
> diff --git a/drivers/gpu/drm/panthor/panthor_mmu.c b/drivers/gpu/drm/panthor/panthor_mmu.c
> index 6dec4354e378..048a61d9fad6 100644
> --- a/drivers/gpu/drm/panthor/panthor_mmu.c
> +++ b/drivers/gpu/drm/panthor/panthor_mmu.c
> @@ -2327,7 +2327,6 @@ panthor_vm_create(struct panthor_device *ptdev, bool for_mcu,
> const struct drm_sched_init_args sched_args = {
> .ops = &panthor_vm_bind_ops,
> .submit_wq = ptdev->mmu->vm.wq,
> - .num_rqs = 1,
> .credit_limit = 1,
> /* Bind operations are synchronous for now, no timeout needed. */
> .timeout = MAX_SCHEDULE_TIMEOUT,
> diff --git a/drivers/gpu/drm/panthor/panthor_sched.c b/drivers/gpu/drm/panthor/panthor_sched.c
> index f5e01cb16cfc..5b95868169ac 100644
> --- a/drivers/gpu/drm/panthor/panthor_sched.c
> +++ b/drivers/gpu/drm/panthor/panthor_sched.c
> @@ -3318,7 +3318,6 @@ group_create_queue(struct panthor_group *group,
> struct drm_sched_init_args sched_args = {
> .ops = &panthor_queue_sched_ops,
> .submit_wq = group->ptdev->scheduler->wq,
> - .num_rqs = 1,
> /*
> * The credit limit argument tells us the total number of
> * instructions across all CS slots in the ringbuffer, with
> --
> 2.48.0
>
--
====================
| I would like to |
| fix the world, |
| but they're not |
| giving me the |
\ source code! /
---------------
¯\_(ツ)_/¯
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 25/28] drm/sched: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (23 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 24/28] drm/panthor: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 22:44 ` Matthew Brost
2025-10-08 8:53 ` [PATCH 26/28] drm/v3d: " Tvrtko Ursulin
` (3 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Matthew Brost, Danilo Krummrich,
Philipp Stanner, Christian König
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Philipp Stanner <phasta@kernel.org>
Cc: "Christian König" <ckoenig.leichtzumerken@gmail.com>
Cc: dri-devel@lists.freedesktop.org
---
drivers/gpu/drm/scheduler/tests/mock_scheduler.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/gpu/drm/scheduler/tests/mock_scheduler.c b/drivers/gpu/drm/scheduler/tests/mock_scheduler.c
index 8e9ae7d980eb..14403a762335 100644
--- a/drivers/gpu/drm/scheduler/tests/mock_scheduler.c
+++ b/drivers/gpu/drm/scheduler/tests/mock_scheduler.c
@@ -290,7 +290,6 @@ struct drm_mock_scheduler *drm_mock_sched_new(struct kunit *test, long timeout)
{
struct drm_sched_init_args args = {
.ops = &drm_mock_scheduler_ops,
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = U32_MAX,
.hang_limit = 1,
.timeout = timeout,
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 25/28] drm/sched: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 ` [PATCH 25/28] drm/sched: " Tvrtko Ursulin
@ 2025-10-08 22:44 ` Matthew Brost
0 siblings, 0 replies; 76+ messages in thread
From: Matthew Brost @ 2025-10-08 22:44 UTC (permalink / raw)
To: Tvrtko Ursulin
Cc: amd-gfx, dri-devel, kernel-dev, Danilo Krummrich, Philipp Stanner,
Christian König
On Wed, Oct 08, 2025 at 09:53:56AM +0100, Tvrtko Ursulin wrote:
> Remove member no longer used by the scheduler core.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Reviewed-by: Matthew Brost <matthew.brost@intel.com>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Philipp Stanner <phasta@kernel.org>
> Cc: "Christian König" <ckoenig.leichtzumerken@gmail.com>
> Cc: dri-devel@lists.freedesktop.org
> ---
> drivers/gpu/drm/scheduler/tests/mock_scheduler.c | 1 -
> 1 file changed, 1 deletion(-)
>
> diff --git a/drivers/gpu/drm/scheduler/tests/mock_scheduler.c b/drivers/gpu/drm/scheduler/tests/mock_scheduler.c
> index 8e9ae7d980eb..14403a762335 100644
> --- a/drivers/gpu/drm/scheduler/tests/mock_scheduler.c
> +++ b/drivers/gpu/drm/scheduler/tests/mock_scheduler.c
> @@ -290,7 +290,6 @@ struct drm_mock_scheduler *drm_mock_sched_new(struct kunit *test, long timeout)
> {
> struct drm_sched_init_args args = {
> .ops = &drm_mock_scheduler_ops,
> - .num_rqs = DRM_SCHED_PRIORITY_COUNT,
> .credit_limit = U32_MAX,
> .hang_limit = 1,
> .timeout = timeout,
> --
> 2.48.0
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 26/28] drm/v3d: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (24 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 25/28] drm/sched: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 14:15 ` Melissa Wen
2025-10-08 8:53 ` [PATCH 27/28] drm/xe: " Tvrtko Ursulin
` (2 subsequent siblings)
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Melissa Wen, Maíra Canal
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Melissa Wen <mwen@igalia.com>
Cc: "Maíra Canal" <mcanal@igalia.com>
Cc: dri-devel@lists.freedesktop.org
---
drivers/gpu/drm/v3d/v3d_sched.c | 1 -
1 file changed, 1 deletion(-)
diff --git a/drivers/gpu/drm/v3d/v3d_sched.c b/drivers/gpu/drm/v3d/v3d_sched.c
index 0ec06bfbbebb..8978b21d6aa3 100644
--- a/drivers/gpu/drm/v3d/v3d_sched.c
+++ b/drivers/gpu/drm/v3d/v3d_sched.c
@@ -868,7 +868,6 @@ v3d_queue_sched_init(struct v3d_dev *v3d, const struct drm_sched_backend_ops *op
enum v3d_queue queue, const char *name)
{
struct drm_sched_init_args args = {
- .num_rqs = DRM_SCHED_PRIORITY_COUNT,
.credit_limit = 1,
.timeout = msecs_to_jiffies(500),
.dev = v3d->drm.dev,
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 26/28] drm/v3d: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 ` [PATCH 26/28] drm/v3d: " Tvrtko Ursulin
@ 2025-10-10 14:15 ` Melissa Wen
0 siblings, 0 replies; 76+ messages in thread
From: Melissa Wen @ 2025-10-10 14:15 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel; +Cc: kernel-dev, Maíra Canal
On 08/10/2025 05:53, Tvrtko Ursulin wrote:
> Remove member no longer used by the scheduler core.
Acked-by: Melissa Wen <mwen@igalia.com>
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Melissa Wen <mwen@igalia.com>
> Cc: "Maíra Canal" <mcanal@igalia.com>
> Cc: dri-devel@lists.freedesktop.org
> ---
> drivers/gpu/drm/v3d/v3d_sched.c | 1 -
> 1 file changed, 1 deletion(-)
>
> diff --git a/drivers/gpu/drm/v3d/v3d_sched.c b/drivers/gpu/drm/v3d/v3d_sched.c
> index 0ec06bfbbebb..8978b21d6aa3 100644
> --- a/drivers/gpu/drm/v3d/v3d_sched.c
> +++ b/drivers/gpu/drm/v3d/v3d_sched.c
> @@ -868,7 +868,6 @@ v3d_queue_sched_init(struct v3d_dev *v3d, const struct drm_sched_backend_ops *op
> enum v3d_queue queue, const char *name)
> {
> struct drm_sched_init_args args = {
> - .num_rqs = DRM_SCHED_PRIORITY_COUNT,
> .credit_limit = 1,
> .timeout = msecs_to_jiffies(500),
> .dev = v3d->drm.dev,
^ permalink raw reply [flat|nested] 76+ messages in thread
* [PATCH 27/28] drm/xe: Remove drm_sched_init_args->num_rqs usage
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (25 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 26/28] drm/v3d: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-08 8:53 ` [PATCH 28/28] drm/sched: Remove drm_sched_init_args->num_rqs Tvrtko Ursulin
2025-10-10 8:59 ` [PATCH 00/28] Fair DRM scheduler Philipp Stanner
28 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Lucas De Marchi,
Thomas Hellström, Rodrigo Vivi, intel-xe
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Lucas De Marchi <lucas.demarchi@intel.com>
Cc: "Thomas Hellström" <thomas.hellstrom@linux.intel.com>
Cc: Rodrigo Vivi <rodrigo.vivi@intel.com>
Cc: intel-xe@lists.freedesktop.org
---
drivers/gpu/drm/xe/xe_dep_scheduler.c | 1 -
drivers/gpu/drm/xe/xe_execlist.c | 1 -
drivers/gpu/drm/xe/xe_gpu_scheduler.c | 1 -
3 files changed, 3 deletions(-)
diff --git a/drivers/gpu/drm/xe/xe_dep_scheduler.c b/drivers/gpu/drm/xe/xe_dep_scheduler.c
index 9bd3bfd2e526..2c7f43e61069 100644
--- a/drivers/gpu/drm/xe/xe_dep_scheduler.c
+++ b/drivers/gpu/drm/xe/xe_dep_scheduler.c
@@ -78,7 +78,6 @@ xe_dep_scheduler_create(struct xe_device *xe,
const struct drm_sched_init_args args = {
.ops = &sched_ops,
.submit_wq = submit_wq,
- .num_rqs = 1,
.credit_limit = job_limit,
.timeout = MAX_SCHEDULE_TIMEOUT,
.name = name,
diff --git a/drivers/gpu/drm/xe/xe_execlist.c b/drivers/gpu/drm/xe/xe_execlist.c
index f83d421ac9d3..481ff90d0f05 100644
--- a/drivers/gpu/drm/xe/xe_execlist.c
+++ b/drivers/gpu/drm/xe/xe_execlist.c
@@ -338,7 +338,6 @@ static int execlist_exec_queue_init(struct xe_exec_queue *q)
struct drm_gpu_scheduler *sched;
const struct drm_sched_init_args args = {
.ops = &drm_sched_ops,
- .num_rqs = 1,
.credit_limit = q->lrc[0]->ring.size / MAX_JOB_SIZE_BYTES,
.hang_limit = XE_SCHED_HANG_LIMIT,
.timeout = XE_SCHED_JOB_TIMEOUT,
diff --git a/drivers/gpu/drm/xe/xe_gpu_scheduler.c b/drivers/gpu/drm/xe/xe_gpu_scheduler.c
index 455ccaf17314..8d3ffb444195 100644
--- a/drivers/gpu/drm/xe/xe_gpu_scheduler.c
+++ b/drivers/gpu/drm/xe/xe_gpu_scheduler.c
@@ -66,7 +66,6 @@ int xe_sched_init(struct xe_gpu_scheduler *sched,
const struct drm_sched_init_args args = {
.ops = ops,
.submit_wq = submit_wq,
- .num_rqs = 1,
.credit_limit = hw_submission,
.hang_limit = hang_limit,
.timeout = timeout,
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* [PATCH 28/28] drm/sched: Remove drm_sched_init_args->num_rqs
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (26 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 27/28] drm/xe: " Tvrtko Ursulin
@ 2025-10-08 8:53 ` Tvrtko Ursulin
2025-10-10 13:00 ` Philipp Stanner
2025-10-10 8:59 ` [PATCH 00/28] Fair DRM scheduler Philipp Stanner
28 siblings, 1 reply; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-08 8:53 UTC (permalink / raw)
To: amd-gfx, dri-devel
Cc: kernel-dev, Tvrtko Ursulin, Christian König,
Danilo Krummrich, Matthew Brost, Philipp Stanner
Remove member no longer used by the scheduler core.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
Cc: Christian König <christian.koenig@amd.com>
Cc: Danilo Krummrich <dakr@kernel.org>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Philipp Stanner <phasta@kernel.org>
---
include/drm/gpu_scheduler.h | 3 ---
1 file changed, 3 deletions(-)
diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
index 21129c98ce56..910c43fedcb9 100644
--- a/include/drm/gpu_scheduler.h
+++ b/include/drm/gpu_scheduler.h
@@ -607,8 +607,6 @@ struct drm_gpu_scheduler {
* @ops: backend operations provided by the driver
* @submit_wq: workqueue to use for submission. If NULL, an ordered wq is
* allocated and used.
- * @num_rqs: Number of run-queues. This may be at most DRM_SCHED_PRIORITY_COUNT,
- * as there's usually one run-queue per priority, but may be less.
* @credit_limit: the number of credits this scheduler can hold from all jobs
* @hang_limit: number of times to allow a job to hang before dropping it.
* This mechanism is DEPRECATED. Set it to 0.
@@ -622,7 +620,6 @@ struct drm_sched_init_args {
const struct drm_sched_backend_ops *ops;
struct workqueue_struct *submit_wq;
struct workqueue_struct *timeout_wq;
- u32 num_rqs;
u32 credit_limit;
unsigned int hang_limit;
long timeout;
--
2.48.0
^ permalink raw reply related [flat|nested] 76+ messages in thread* Re: [PATCH 28/28] drm/sched: Remove drm_sched_init_args->num_rqs
2025-10-08 8:53 ` [PATCH 28/28] drm/sched: Remove drm_sched_init_args->num_rqs Tvrtko Ursulin
@ 2025-10-10 13:00 ` Philipp Stanner
2025-10-11 14:58 ` Tvrtko Ursulin
0 siblings, 1 reply; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 13:00 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost,
Philipp Stanner
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> Remove member no longer used by the scheduler core.
"scheduler core and all drivers."
Apart from that, very nice that we can simplify the init-interface.
P.
>
> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> ---
> include/drm/gpu_scheduler.h | 3 ---
> 1 file changed, 3 deletions(-)
>
> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
> index 21129c98ce56..910c43fedcb9 100644
> --- a/include/drm/gpu_scheduler.h
> +++ b/include/drm/gpu_scheduler.h
> @@ -607,8 +607,6 @@ struct drm_gpu_scheduler {
> * @ops: backend operations provided by the driver
> * @submit_wq: workqueue to use for submission. If NULL, an ordered wq is
> * allocated and used.
> - * @num_rqs: Number of run-queues. This may be at most DRM_SCHED_PRIORITY_COUNT,
> - * as there's usually one run-queue per priority, but may be less.
> * @credit_limit: the number of credits this scheduler can hold from all jobs
> * @hang_limit: number of times to allow a job to hang before dropping it.
> * This mechanism is DEPRECATED. Set it to 0.
> @@ -622,7 +620,6 @@ struct drm_sched_init_args {
> const struct drm_sched_backend_ops *ops;
> struct workqueue_struct *submit_wq;
> struct workqueue_struct *timeout_wq;
> - u32 num_rqs;
> u32 credit_limit;
> unsigned int hang_limit;
> long timeout;
^ permalink raw reply [flat|nested] 76+ messages in thread* Re: [PATCH 28/28] drm/sched: Remove drm_sched_init_args->num_rqs
2025-10-10 13:00 ` Philipp Stanner
@ 2025-10-11 14:58 ` Tvrtko Ursulin
0 siblings, 0 replies; 76+ messages in thread
From: Tvrtko Ursulin @ 2025-10-11 14:58 UTC (permalink / raw)
To: phasta, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Matthew Brost
On 10/10/2025 14:00, Philipp Stanner wrote:
> On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
>> Remove member no longer used by the scheduler core.
>
> "scheduler core and all drivers."
Done.
Regards,
Tvrtko
> Apart from that, very nice that we can simplify the init-interface.
>
> P.
>
>>
>> Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@igalia.com>
>> Cc: Christian König <christian.koenig@amd.com>
>> Cc: Danilo Krummrich <dakr@kernel.org>
>> Cc: Matthew Brost <matthew.brost@intel.com>
>> Cc: Philipp Stanner <phasta@kernel.org>
>> ---
>> include/drm/gpu_scheduler.h | 3 ---
>> 1 file changed, 3 deletions(-)
>>
>> diff --git a/include/drm/gpu_scheduler.h b/include/drm/gpu_scheduler.h
>> index 21129c98ce56..910c43fedcb9 100644
>> --- a/include/drm/gpu_scheduler.h
>> +++ b/include/drm/gpu_scheduler.h
>> @@ -607,8 +607,6 @@ struct drm_gpu_scheduler {
>> * @ops: backend operations provided by the driver
>> * @submit_wq: workqueue to use for submission. If NULL, an ordered wq is
>> * allocated and used.
>> - * @num_rqs: Number of run-queues. This may be at most DRM_SCHED_PRIORITY_COUNT,
>> - * as there's usually one run-queue per priority, but may be less.
>> * @credit_limit: the number of credits this scheduler can hold from all jobs
>> * @hang_limit: number of times to allow a job to hang before dropping it.
>> * This mechanism is DEPRECATED. Set it to 0.
>> @@ -622,7 +620,6 @@ struct drm_sched_init_args {
>> const struct drm_sched_backend_ops *ops;
>> struct workqueue_struct *submit_wq;
>> struct workqueue_struct *timeout_wq;
>> - u32 num_rqs;
>> u32 credit_limit;
>> unsigned int hang_limit;
>> long timeout;
>
^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [PATCH 00/28] Fair DRM scheduler
2025-10-08 8:53 [PATCH 00/28] Fair DRM scheduler Tvrtko Ursulin
` (27 preceding siblings ...)
2025-10-08 8:53 ` [PATCH 28/28] drm/sched: Remove drm_sched_init_args->num_rqs Tvrtko Ursulin
@ 2025-10-10 8:59 ` Philipp Stanner
28 siblings, 0 replies; 76+ messages in thread
From: Philipp Stanner @ 2025-10-10 8:59 UTC (permalink / raw)
To: Tvrtko Ursulin, amd-gfx, dri-devel
Cc: kernel-dev, Christian König, Danilo Krummrich, Leo Liu,
Matthew Brost, Philipp Stanner, Pierre-Eric Pelloux-Prayer,
Michel Dänzer
On Wed, 2025-10-08 at 09:53 +0100, Tvrtko Ursulin wrote:
> [disclaimer]
> Please note that as this series includes patches which touch a good number of
> drivers, I did not copy everyone on everything. Assumption is people are
> subscribed to dri-devel and for context can look at the whole series there.
> [/disclaimer]
>
> As a summary, the new scheduling algorithm is insipired by the original Linux
> CFS and so far no scheduling regressions have been found relative to FIFO.
> There are improvements in fairness and scheduling of interactive clients when
> running in parallel with a heavy GPU load (for example Pierre-Eric has one
> viewperf medical test which shows a nice improvement with amdgpu).
>
> On the high level main advantages of the series are:
>
> 1. Scheduling quality - schedules better than FIFO, solves priority starvation.
> 2. Code simplification - no more multiple run queues and multiple algorithms.
> 3. Virtual GPU time based scheduling enables relatively simple addition
> of a scheduling cgroup controller in the future.
>
> There is a little bit more detailed write up on the motivation and results in
> the form of a blog post which may be easier to read:
> https://blogs.igalia.com/tursulin/fair-er-drm-gpu-scheduler/
>
> First patches add some unit tests which allow for easy evaluation of scheduling
> behaviour against different client submission patterns. From there onwards it is
> hopefully a natural progression of cleanups, enablers, adding the fair policy,
> and finally removing FIFO and RR and simplifying the code base due no more need
> for multiple run queues.
>
> Series is structured in a way where we could apply the first 12 patches (up to
> and including "drm/sched: Switch default policy to fair") in one kernel release
> and then follow up with the rest of the cleanups after a release or two if
> things will be looking fine. Until the remainder of the series would be merged
> it would be easy to flip the default algorithm back.
>
> Onto the performance evaluation. As a headline result I have tested three
> simultaneous clients on the Steam Deck:
>
> One instance of a deferredmultisampling Vulkan demo running with low priority,
> one normal priority instance of the same demo, and the Unigine Heaven benchmark.
>
> With the FIFO scheduler we can see that the low priority client is completely
> starved and the GPU time distribution between the other two clients is uneven:
>
> https://people.igalia.com/tursulin/drm-sched-fair/fifo-starvation.png
>
> Switching to the fair scheduler, GPU time distribution is almost equal and the
> low priority client does get a small share of the GPU:
>
> https://people.igalia.com/tursulin/drm-sched-fair/fair-no-starvation.png
>
> Moving onto the synthetic submission patterns, they are about two simultaneous
> clients which broadly cover the following categories:
>
> * Deep queue clients
> * Hogs versus interactive
> * Priority handling
>
> Lets look at the results:
>
> 1. Two normal priority deep queue clients.
>
> These ones submit one second worth of 8ms jobs. As fast as they can, no
> dependencies etc. There is no difference in runtime between FIFO and fair but
> the latter allows both clients to progress with work more evenly:
>
> https://people.igalia.com/tursulin/drm-sched-fair/normal-normal.png
>
> (X axis is time, Y is submitted queue-depth, hence lowering of qd corresponds
> with work progress for both clients, tested with both schedulers separately.)
>
> Round-robin is the same as fair here.
>
> 2. Same two clients but one is now low priority.
>
> https://people.igalia.com/tursulin/drm-sched-fair/normal-low.png
>
> Normal priority client is a solid line, low priority dotted. We can see how FIFO
> completely starves the low priority client until the normal priority is fully
> done. Only then the low priority client gets any GPU time.
>
> In constrast, fair scheduler allows some GPU time to the low priority client.
>
> Here round-robin flavours are the same as FIFO (same starvation issue).
>
> 3. Same clients but now high versus normal priority.
>
> Similar behaviour as in the previous one with normal a bit less de-prioritised
> relative to high, than low was against normal.
>
> https://people.igalia.com/tursulin/drm-sched-fair/high-normal.png
>
> And again round-robin flavours are the same as FIFO.
>
> 4. Heavy load vs interactive client.
>
> Heavy client emits a 75% GPU load in the format of 3x 2.5ms jobs followed by a
> 2.5ms wait. Interactive client emits a 10% GPU load in the format of 1x 1ms job
> followed by a 9ms wait.
>
> This simulates an interactive graphical client used on top of a relatively heavy
> background load but no GPU oversubscription.
>
> Graphs show the interactive client only and from now on, instead of looking at
> the client's queue depth, we look at its "fps".
>
> https://people.igalia.com/tursulin/drm-sched-fair/251008/4-heavy-vs-interactive.png
>
> Here round-robin and round-robin rewritten on top of FIFO are best, with the
> fair algorithm being very close. FIFO is clearly the worst.
>
> 5. An even heavier load vs interactive client.
>
> This one is oversubscribing the GPU by submitting 4x 50ms jobs and waiting for
> only one microsecond before repeating the cycle. Interactive client is the same
> 10% as above.
>
> https://people.igalia.com/tursulin/drm-sched-fair/251008/4-very-heavy-vs-interactive.png
>
> Here FIFO is even worse and fair is again almost as good as the two round-robin
> flavours.
>
> 6. Low priority GPU hog versus heavy-interactive.
>
> Low priority client: 3x 2.5ms jobs client followed by a 0.5ms wait.
> Interactive client: 1x 0.5ms job followed by a 10ms wait.
>
> https://people.igalia.com/tursulin/drm-sched-fair/251008/4-low-hog-vs-interactive.png
>
> All schedulers appear to handle this almost equally well but FIFO could still be
> the last while fair has a slight lead.
>
> As before, I am looking for feedback, ideas for what other kinds of submission
> scenarios to test, testing on different GPUs and of course reviews.
>
> v2:
> * Fixed many rebase errors.
> * Added some new patches.
> * Dropped single shot dependecy handling.
>
> v3:
> * Added scheduling quality unit tests.
> * Refined a tiny bit by adding some fairness.
> * Dropped a few patches for now.
>
> v4:
> * Replaced deadline with fair!
> * Refined scheduling quality unit tests.
> * Pulled one cleanup patch earlier.
> * Fixed "drm/sched: Avoid double re-lock on the job free path".
>
> v5:
> * Rebase on top of latest upstream DRM scheduler changes.
> * Kerneldoc fixup.
> * Improve commit message justification for one patch. (Philipp)
> * Add comment in drm_sched_alloc_wq. (Christian)
>
> v6:
> * Rebase for "drm/sched: De-clutter drm_sched_init" getting merged.
> * Avoid NULL rq dereference from a bad rebase. (Maira)
> * Added some kerneldoc throughout. (Maira)
> * Removed some lockdep annotations not belonging to one patch. (Maira)
> * Use dma_fence_is_signaled in "drm/sched: Avoid double re-lock on the job free path". (Maira, Philipp)
>
> v7:
> * Rebase for some prep patches getting merged.
> * Dropped submit all ready jobs patch.
> * Fixed 64-bit division in unit tests.
> * Fixed some more rebase and patch re-ordering mistakes.
> * Preserve entity RR order when re-entering the queue.
> * Fine tuned the queue re-enter logic for better behaviour with interactive
> clients.
> * Removed some static inlines.
> * Added more kerneldoc.
> * Done some benchmarks in the round-robin scheduling modes.
>
> v8:
> * Rebased for upstream changes.
> * Added assert for reverse numerical order of DRM_SCHED_PRIORITY enums.
> * Fixed head of rq priority updates.
>
> v9:
> * RFC -> PATCH for the series as agreed during the XDC.
So this is not v9 of an RFC, but v1 of the actual series :)
I think you wanna mark the old changelog section as belonging to the
RFC, since this one will likely move to v2 etc., which might cause
confusion.
P.
> * Updated interactive benchmark graphs.
> * Improved handling of interactive clients by replacing the random noise on tie
> approach with the average job duration statistics.
> * Document in code why we track entity GPU stats in a reference counted structures.
> * Document the new structure fields added by the fair policy.
> * Undo some tab vs spaces damage.
> * More accurate wording in the fair policy commit message.
> * Default to fair policy in a separate patch.
> * Renamed drm_sched_rq_select_entity to drm_sched_select_entity and make it only take sched.
> * Fixed kerneldoc after removing scheduling policies and renaming the rq.
> * Reversed arguments of drm_sched_rq_init and cleanup callers. (New patch)
> * Removed unused num_rqs from struct drm_sched_args. (New patches)
> * Unit tests:
> * Added wait duration comments.
> * Data structure comments.
> * Better name for a local variable.
> * Added comment to the short job duration assert.
> * Added comment for cond_resched().
> * Tweaked some comments
> * Added client_done() helper and documented the READ_ONCE.
> * Clarified cycles per second calculation.
>
> Cc: Christian König <christian.koenig@amd.com>
> Cc: Danilo Krummrich <dakr@kernel.org>
> CC: Leo Liu <Leo.Liu@amd.com>
> Cc: Matthew Brost <matthew.brost@intel.com>
> Cc: Philipp Stanner <phasta@kernel.org>
> Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-prayer@amd.com>
> Cc: Michel Dänzer <michel.daenzer@mailbox.org>
>
> Tvrtko Ursulin (28):
> drm/sched: Reverse drm_sched_rq_init arguments
> drm/sched: Add some scheduling quality unit tests
> drm/sched: Add some more scheduling quality unit tests
> drm/sched: Implement RR via FIFO
> drm/sched: Consolidate entity run queue management
> drm/sched: Move run queue related code into a separate file
> drm/sched: Free all finished jobs at once
> drm/sched: Account entity GPU time
> drm/sched: Remove idle entity from tree
> drm/sched: Add fair scheduling policy
> drm/sched: Favour interactive clients slightly
> drm/sched: Switch default policy to fair
> drm/sched: Remove FIFO and RR and simplify to a single run queue
> drm/sched: Embed run queue singleton into the scheduler
> accel/amdxdna: Remove drm_sched_init_args->num_rqs usage
> accel/rocket: Remove drm_sched_init_args->num_rqs usage
> drm/amdgpu: Remove drm_sched_init_args->num_rqs usage
> drm/etnaviv: Remove drm_sched_init_args->num_rqs usage
> drm/imagination: Remove drm_sched_init_args->num_rqs usage
> drm/lima: Remove drm_sched_init_args->num_rqs usage
> drm/msm: Remove drm_sched_init_args->num_rqs usage
> drm/nouveau: Remove drm_sched_init_args->num_rqs usage
> drm/panfrost: Remove drm_sched_init_args->num_rqs usage
> drm/panthor: Remove drm_sched_init_args->num_rqs usage
> drm/sched: Remove drm_sched_init_args->num_rqs usage
> drm/v3d: Remove drm_sched_init_args->num_rqs usage
> drm/xe: Remove drm_sched_init_args->num_rqs usage
> drm/sched: Remove drm_sched_init_args->num_rqs
>
> drivers/accel/amdxdna/aie2_ctx.c | 1 -
> drivers/accel/rocket/rocket_job.c | 1 -
> drivers/gpu/drm/amd/amdgpu/amdgpu_cs.c | 6 +-
> drivers/gpu/drm/amd/amdgpu/amdgpu_device.c | 1 -
> drivers/gpu/drm/amd/amdgpu/amdgpu_job.c | 27 +-
> drivers/gpu/drm/amd/amdgpu/amdgpu_job.h | 5 +-
> drivers/gpu/drm/amd/amdgpu/amdgpu_trace.h | 8 +-
> drivers/gpu/drm/amd/amdgpu/amdgpu_vm_sdma.c | 8 +-
> drivers/gpu/drm/amd/amdgpu/amdgpu_xcp.c | 8 +-
> drivers/gpu/drm/etnaviv/etnaviv_sched.c | 1 -
> drivers/gpu/drm/imagination/pvr_queue.c | 1 -
> drivers/gpu/drm/lima/lima_sched.c | 1 -
> drivers/gpu/drm/msm/msm_gem_vma.c | 1 -
> drivers/gpu/drm/msm/msm_ringbuffer.c | 1 -
> drivers/gpu/drm/nouveau/nouveau_sched.c | 1 -
> drivers/gpu/drm/panfrost/panfrost_job.c | 1 -
> drivers/gpu/drm/panthor/panthor_mmu.c | 1 -
> drivers/gpu/drm/panthor/panthor_sched.c | 1 -
> drivers/gpu/drm/scheduler/Makefile | 2 +-
> drivers/gpu/drm/scheduler/sched_entity.c | 132 ++-
> drivers/gpu/drm/scheduler/sched_fence.c | 2 +-
> drivers/gpu/drm/scheduler/sched_internal.h | 99 +-
> drivers/gpu/drm/scheduler/sched_main.c | 402 ++------
> drivers/gpu/drm/scheduler/sched_rq.c | 354 +++++++
> drivers/gpu/drm/scheduler/tests/Makefile | 3 +-
> .../gpu/drm/scheduler/tests/mock_scheduler.c | 1 -
> .../gpu/drm/scheduler/tests/tests_scheduler.c | 878 ++++++++++++++++++
> drivers/gpu/drm/v3d/v3d_sched.c | 1 -
> drivers/gpu/drm/xe/xe_dep_scheduler.c | 1 -
> drivers/gpu/drm/xe/xe_execlist.c | 1 -
> drivers/gpu/drm/xe/xe_gpu_scheduler.c | 1 -
> include/drm/gpu_scheduler.h | 43 +-
> 32 files changed, 1494 insertions(+), 500 deletions(-)
> create mode 100644 drivers/gpu/drm/scheduler/sched_rq.c
> create mode 100644 drivers/gpu/drm/scheduler/tests/tests_scheduler.c
>
^ permalink raw reply [flat|nested] 76+ messages in thread
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
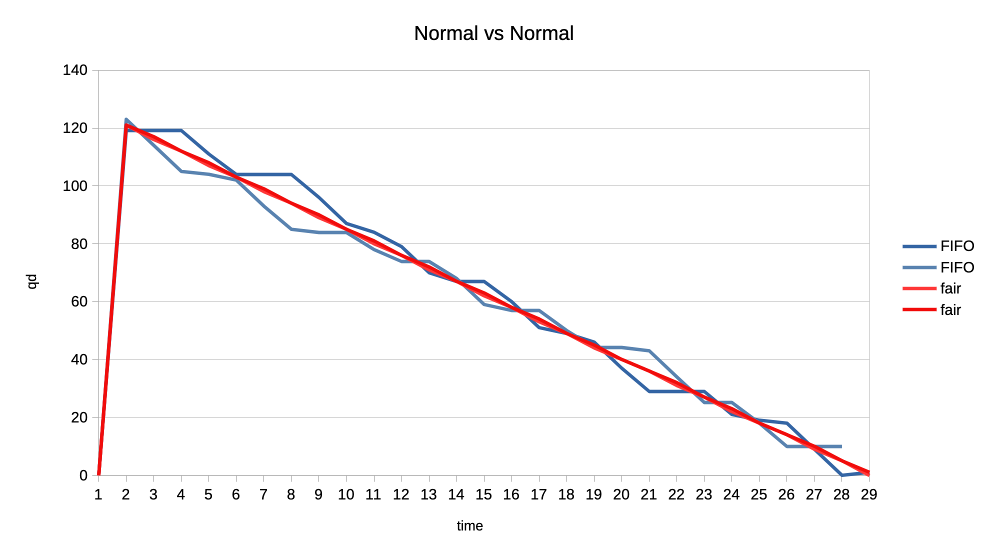{kind=link}
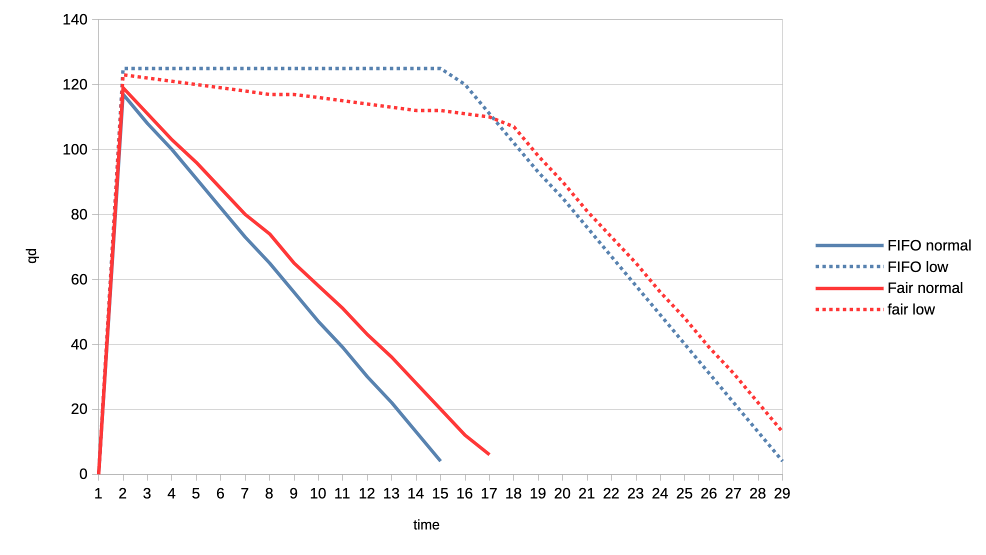{kind=link}
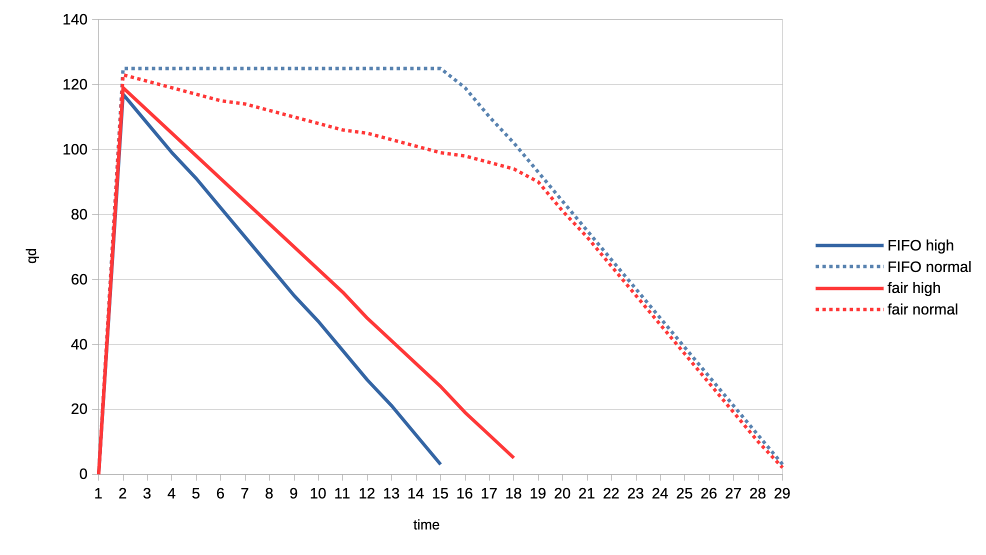{kind=link}