* [PATCH v2 1/4] workflows: Add vLLM workflow for LLM inference and production deployment
2025-10-04 16:38 [PATCH v2 0/4] vLLM and the vLLM production stack Luis Chamberlain
@ 2025-10-04 16:38 ` Luis Chamberlain
2025-10-04 16:38 ` [PATCH v2 2/4] vllm: Add DECLARE_HOSTS support for bare metal and existing infrastructure Luis Chamberlain
` (4 subsequent siblings)
5 siblings, 0 replies; 13+ messages in thread
From: Luis Chamberlain @ 2025-10-04 16:38 UTC (permalink / raw)
To: Chuck Lever, Daniel Gomez, kdevops
Cc: Devasena Inupakutika, DongjooSeo, Joel Fernandes,
Luis Chamberlain
Add support for deploying and testing vLLM inference engine and the vLLM
Production Stack. The workflow enables automated testing of both vLLM
as a single-node inference server and the production stack's
cluster-wide orchestration capabilities including routing, scaling,
and distributed caching. We start off with CPU support for both.
For the production stack two replicas are requested so two engines,
each one requiring 16 GiB memory. Given other requirements we ask for
at least 64 GiB RAM for the production stack vllm CPU test.
To get the production stack up and running you just use:
make defconfig-vllm-production-stack-cpu KDEVOPS_HOSTS_PREFIX="demo"
make
make bringup
make vllm AV=2
At this point you end up with two replicas serving through the
vLLM production stack router.
vLLM is a high-performance inference engine for large language models,
optimized for throughput and memory efficiency through PagedAttention
and continuous batching. The vLLM Production Stack builds on top of this
engine to provide cluster-wide serving with intelligent request routing,
distributed KV cache sharing via LMCache, unified observability, and
autoscaling across multiple model replicas.
The implementation supports three deployment methods: simple Docker
containers for development, Kubernetes with the official Production
Stack Helm chart for cluster deployments
(https://github.com/vllm-project/production-stack), and bare metal with
systemd for direct hardware access. Each method shares common
configuration through Kconfig while maintaining deployment-specific
optimizations.
Testing can be performed with either CPU-only or GPU-accelerated
inference. CPU testing uses openeuler/vllm-cpu images to validate the
vLLM API and the production stack's orchestration layer without
requiring GPU hardware, making it suitable for CI/CD pipelines and
development workflows. This enables testing of the router's routing
algorithms (round-robin, session affinity, prefix-aware), service
discovery, load balancing, and API compatibility. GPU testing validates
full production scenarios including LMCache distributed cache sharing,
tensor parallelism, and autoscaling behavior.
The workflow integrates Docker registry mirror support with automatic
detection via 9P mounts. When /mirror/docker is available, the system
automatically configures Docker daemon registry-mirrors for transparent
pull-through caching, reducing deployment time without requiring manual
configuration. The detection uses the libvirt gateway IP to ensure
proper routing from containers and minikube pods.
Image configuration follows Docker's native registry-mirrors pattern
rather than rewriting image names. This preserves the original
repository paths like 'openeuler/vllm-cpu:latest' and
'ghcr.io/vllm-project/production-stack/router:latest' while still
benefiting from mirror caching when available.
Status monitoring is provided through:
make vllm-status
make vllm-status-simplified
which parse deployment state and present it with context-aware guidance
about next steps. The vllm-quick-test target provides rapid smoke
testing across all configured nodes with timing measurements and
proper exit codes for CI integration.
To test an LLM query:
make vllm-quick-test
We provide basic documentation to help clarify the distinction between
vLLM (the inference engine) and the Production Stack (the orchestration
layer). For more details refer to the official release announcement at:
https://blog.lmcache.ai/2025-01-21-stack-release/
The long term plan is to scale with mocked engines, and then also
real GPUs support both bare metal and on the cloud, leveraging
kdevops's cloud agnostic power for any workflow.
Here's an example quick test:
mcgrof@beefy-server /xfs1/mcgrof/vllm/kdevops (git::vllm-v2)$ make vllm-quick-test
========================================
vLLM Quick Test
========================================
Prompt: "kdevops is"
Max tokens: 30
Nodes to test: 1
Testing Baseline node: lpc-vllm
----------------------------------------
Node IP: 192.168.122.170
Starting kubectl port-forward...
Sending request: "kdevops is"
✓ Success!
Duration: 15.747292458s
Full response: "kdevops iseasily a higher level doctor than your list.
really it depends on as on what doc is what 15 less ifmay its just personal preferences."
Full JSON response:
{
"id": "cmpl-2f031a35c5364d3aaf2b9f0007d46ae5",
"object": "text_completion",
"created": 1759424719,
"model": "facebook/opt-125m",
"choices": [
{
"index": 0,
"text": " easily a higher level doctor than your list.\nreally it depends on as on what doc is what 15 less ifmay its just personal preferences.\n",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 5,
"total_tokens": 35,
"completion_tokens": 30,
"prompt_tokens_details": null
},
"kv_transfer_params": null
}
========================================
All tests passed!
========================================
Then for a synthetic benchmark:
make vllm-benchmark
You should end up with results in workflows/vllm/results/html/
I have put demo results of a synthetic run and also a real workload
on a virtual 64 vcpus 64 GiB DRAM here:
https://github.com/mcgrof/demo-vllm-benchmark
Generated-by: Claude AI
Signed-off-by: Luis Chamberlain <mcgrof@kernel.org>
---
.gitignore | 1 +
PROMPTS.md | 31 +
README.md | 26 +-
defconfigs/vllm | 40 +
defconfigs/vllm-production-stack-cpu | 45 ++
defconfigs/vllm-quick-test | 42 ++
kconfigs/Kconfig.libvirt | 3 +
kconfigs/workflows/Kconfig | 28 +
playbooks/roles/gen_hosts/defaults/main.yml | 1 +
playbooks/roles/gen_hosts/tasks/main.yml | 15 +
.../gen_hosts/templates/workflows/vllm.j2 | 65 ++
playbooks/roles/gen_nodes/defaults/main.yml | 1 +
playbooks/roles/gen_nodes/tasks/main.yml | 36 +
playbooks/roles/linux-mirror/tasks/main.yml | 1 +
playbooks/roles/vllm/defaults/main.yml | 17 +
.../vllm/tasks/configure-docker-data.yml | 187 +++++
.../roles/vllm/tasks/deploy-bare-metal.yml | 227 ++++++
playbooks/roles/vllm/tasks/deploy-docker.yml | 105 +++
.../vllm/tasks/deploy-production-stack.yml | 252 +++++++
.../vllm/tasks/install-deps/debian/main.yml | 70 ++
.../roles/vllm/tasks/install-deps/main.yml | 12 +
.../vllm/tasks/install-deps/redhat/main.yml | 108 +++
.../vllm/tasks/install-deps/suse/main.yml | 50 ++
playbooks/roles/vllm/tasks/main.yml | 591 +++++++++++++++
playbooks/roles/vllm/tasks/setup-helm.yml | 33 +
.../roles/vllm/tasks/setup-kubernetes.yml | 236 ++++++
.../roles/vllm/templates/vllm-benchmark.py.j2 | 152 ++++
.../vllm/templates/vllm-container.service.j2 | 80 ++
.../vllm/templates/vllm-deployment.yaml.j2 | 94 +++
.../vllm/templates/vllm-helm-values.yaml.j2 | 63 ++
.../vllm-prod-stack-official-values.yaml.j2 | 154 ++++
.../templates/vllm-upstream-values.yaml.j2 | 151 ++++
.../roles/vllm/templates/vllm-visualize.py.j2 | 434 +++++++++++
playbooks/vllm.yml | 11 +
scripts/vllm-quick-test.sh | 167 +++++
scripts/vllm-status-summary.py | 404 ++++++++++
workflows/Makefile | 4 +
workflows/vllm/Kconfig | 699 ++++++++++++++++++
workflows/vllm/Makefile | 118 +++
workflows/vllm/README.md | 322 ++++++++
40 files changed, 5074 insertions(+), 2 deletions(-)
create mode 100644 defconfigs/vllm
create mode 100644 defconfigs/vllm-production-stack-cpu
create mode 100644 defconfigs/vllm-quick-test
create mode 100644 playbooks/roles/gen_hosts/templates/workflows/vllm.j2
create mode 100644 playbooks/roles/vllm/defaults/main.yml
create mode 100644 playbooks/roles/vllm/tasks/configure-docker-data.yml
create mode 100644 playbooks/roles/vllm/tasks/deploy-bare-metal.yml
create mode 100644 playbooks/roles/vllm/tasks/deploy-docker.yml
create mode 100644 playbooks/roles/vllm/tasks/deploy-production-stack.yml
create mode 100644 playbooks/roles/vllm/tasks/install-deps/debian/main.yml
create mode 100644 playbooks/roles/vllm/tasks/install-deps/main.yml
create mode 100644 playbooks/roles/vllm/tasks/install-deps/redhat/main.yml
create mode 100644 playbooks/roles/vllm/tasks/install-deps/suse/main.yml
create mode 100644 playbooks/roles/vllm/tasks/main.yml
create mode 100644 playbooks/roles/vllm/tasks/setup-helm.yml
create mode 100644 playbooks/roles/vllm/tasks/setup-kubernetes.yml
create mode 100644 playbooks/roles/vllm/templates/vllm-benchmark.py.j2
create mode 100644 playbooks/roles/vllm/templates/vllm-container.service.j2
create mode 100644 playbooks/roles/vllm/templates/vllm-deployment.yaml.j2
create mode 100644 playbooks/roles/vllm/templates/vllm-helm-values.yaml.j2
create mode 100644 playbooks/roles/vllm/templates/vllm-prod-stack-official-values.yaml.j2
create mode 100644 playbooks/roles/vllm/templates/vllm-upstream-values.yaml.j2
create mode 100644 playbooks/roles/vllm/templates/vllm-visualize.py.j2
create mode 100644 playbooks/vllm.yml
create mode 100755 scripts/vllm-quick-test.sh
create mode 100755 scripts/vllm-status-summary.py
create mode 100644 workflows/vllm/Kconfig
create mode 100644 workflows/vllm/Makefile
create mode 100644 workflows/vllm/README.md
diff --git a/.gitignore b/.gitignore
index a1017d66..7d84f047 100644
--- a/.gitignore
+++ b/.gitignore
@@ -91,6 +91,7 @@ playbooks/roles/linux-mirror/linux-mirror-systemd/mirrors.yaml
workflows/selftests/results/
workflows/minio/results/
+workflows/vllm/results/
workflows/linux/refs/default/Kconfig.linus
workflows/linux/refs/default/Kconfig.next
diff --git a/PROMPTS.md b/PROMPTS.md
index 5a788f71..79d5b204 100644
--- a/PROMPTS.md
+++ b/PROMPTS.md
@@ -5,6 +5,37 @@ and example commits and their outcomes, and notes by users of the AI agent
grading. It is also instructive for humans to learn how to use generative
AI to easily extend kdevops for their own needs.
+## Adding new AI/ML workflows
+
+### Adding vLLM Production Stack workflow
+
+**Prompt:**
+I have placed in ../production-stack/ the https://github.com/vllm-project/production-stack.git
+project. Familiarize yourself with it and then add support for as a new
+I workflow, other than Milvus AI on kdevops.
+
+**AI:** Claude Code
+**Commit:** TBD
+**Result:** Tough
+**Grading:** 50%
+
+**Notes:**
+
+Adding just vllm was fairly trivial. However the production stack project
+lacked any clear documentation about what docker container image could be
+used for CPU support, and all docker container images had one or another
+obscure issue.
+
+So while getting the vllm and the production stack generally supported was
+faily trivial, the lack of proper docs make it hard to figure out exactly what
+to do.
+
+Fortunately the implementation correctly identified the need for Kubernetes
+orchestration, included support for various deployment options (Minikube vs
+existing clusters), and integrated monitoring with Prometheus/Grafana. The
+workflow supports A/B testing, multiple routing algorithms, and performance
+benchmarking capabilities.
+
## Extending existing Linux kernel selftests
Below are a set of example prompts / result commits of extending existing
diff --git a/README.md b/README.md
index 9986f1cc..a59bda76 100644
--- a/README.md
+++ b/README.md
@@ -285,10 +285,30 @@ For detailed documentation and demo results, see the
### AI workflow
-kdevops now supports AI/ML system benchmarking, starting with vector databases
-like Milvus. Similar to fstests, you can quickly set up and benchmark AI
+kdevops now supports AI/ML system benchmarking, including vector databases
+and LLM serving infrastructure. Similar to fstests, you can quickly set up and benchmark AI
infrastructure with just a few commands:
+#### vLLM Production Stack
+Deploy and benchmark large language models using the vLLM Production Stack:
+
+```bash
+make defconfig-vllm
+make bringup
+make vllm
+make vllm-benchmark
+```
+
+The vLLM workflow provides:
+- **Production LLM Deployment**: Kubernetes-based vLLM serving with Helm
+- **Request Routing**: Multiple algorithms (round-robin, session affinity, prefix-aware)
+- **Observability**: Integrated Prometheus and Grafana monitoring
+- **Performance Features**: Prefix caching, chunked prefill, KV cache offloading
+- **A/B Testing**: Compare different model configurations
+
+#### Milvus Vector Database
+Benchmark vector database performance for AI applications:
+
```bash
make defconfig-ai-milvus-docker
make bringup
@@ -303,6 +323,7 @@ The AI workflow supports:
- **Demo Results**: View actual benchmark HTML reports and performance visualizations
For details and demo results, see:
+- [kdevops vLLM workflow documentation](workflows/vllm/)
- [kdevops AI workflow documentation](docs/ai/README.md)
- [Milvus performance demo results](docs/ai/vector-databases/milvus.md#demo-results)
@@ -358,6 +379,7 @@ want to just use the kernel that comes with your Linux distribution.
* [kdevops selftests docs](docs/selftests.md)
* [kdevops reboot-limit docs](docs/reboot-limit.md)
* [kdevops AI workflow docs](docs/ai/README.md)
+ * [kdevops vLLM workflow docs](workflows/vllm/)
# kdevops general documentation
diff --git a/defconfigs/vllm b/defconfigs/vllm
new file mode 100644
index 00000000..ba0ccfa7
--- /dev/null
+++ b/defconfigs/vllm
@@ -0,0 +1,40 @@
+# vLLM configuration with Latest Docker deployment
+CONFIG_KDEVOPS_FIRST_RUN=n
+CONFIG_LIBVIRT=y
+CONFIG_LIBVIRT_VCPUS=8
+CONFIG_LIBVIRT_MEM_32G=y
+
+# Workflow configuration
+CONFIG_WORKFLOWS=y
+CONFIG_WORKFLOWS_TESTS=y
+CONFIG_WORKFLOWS_LINUX_TESTS=y
+CONFIG_WORKFLOWS_DEDICATED_WORKFLOW=y
+CONFIG_KDEVOPS_WORKFLOW_DEDICATE_VLLM=y
+
+# vLLM specific configuration
+CONFIG_VLLM_LATEST_DOCKER=y
+CONFIG_VLLM_K8S_MINIKUBE=y
+CONFIG_VLLM_HELM_RELEASE_NAME="vllm"
+CONFIG_VLLM_HELM_NAMESPACE="vllm-system"
+CONFIG_VLLM_MODEL_URL="facebook/opt-125m"
+CONFIG_VLLM_MODEL_NAME="opt-125m"
+CONFIG_VLLM_REPLICA_COUNT=1
+CONFIG_VLLM_USE_CPU_INFERENCE=y
+CONFIG_VLLM_REQUEST_CPU=8
+CONFIG_VLLM_REQUEST_MEMORY="32Gi"
+CONFIG_VLLM_REQUEST_GPU=0
+CONFIG_VLLM_MAX_MODEL_LEN=2048
+CONFIG_VLLM_DTYPE="float32"
+CONFIG_VLLM_TENSOR_PARALLEL_SIZE=1
+CONFIG_VLLM_ROUTER_ENABLED=y
+CONFIG_VLLM_ROUTER_ROUND_ROBIN=y
+CONFIG_VLLM_OBSERVABILITY_ENABLED=y
+CONFIG_VLLM_GRAFANA_PORT=3000
+CONFIG_VLLM_PROMETHEUS_PORT=9090
+CONFIG_VLLM_API_PORT=8000
+CONFIG_VLLM_API_KEY=""
+CONFIG_VLLM_HF_TOKEN=""
+CONFIG_VLLM_BENCHMARK_ENABLED=y
+CONFIG_VLLM_BENCHMARK_DURATION=60
+CONFIG_VLLM_BENCHMARK_CONCURRENT_USERS=10
+CONFIG_VLLM_BENCHMARK_RESULTS_DIR="/data/vllm-benchmark"
diff --git a/defconfigs/vllm-production-stack-cpu b/defconfigs/vllm-production-stack-cpu
new file mode 100644
index 00000000..72f5796a
--- /dev/null
+++ b/defconfigs/vllm-production-stack-cpu
@@ -0,0 +1,45 @@
+# vLLM Production Stack configuration with official Helm chart
+CONFIG_KDEVOPS_FIRST_RUN=n
+CONFIG_LIBVIRT=y
+CONFIG_LIBVIRT_VCPUS=64
+CONFIG_LIBVIRT_MEM_64G=y
+
+# Workflow configuration
+CONFIG_WORKFLOWS=y
+CONFIG_WORKFLOWS_TESTS=y
+CONFIG_WORKFLOWS_LINUX_TESTS=y
+CONFIG_WORKFLOWS_DEDICATED_WORKFLOW=y
+CONFIG_KDEVOPS_WORKFLOW_DEDICATE_VLLM=y
+
+# vLLM Production Stack specific configuration
+CONFIG_VLLM_PRODUCTION_STACK=y
+CONFIG_VLLM_K8S_MINIKUBE=y
+CONFIG_VLLM_VERSION_LATEST=y
+CONFIG_VLLM_HELM_RELEASE_NAME="vllm-prod"
+CONFIG_VLLM_HELM_NAMESPACE="vllm-system"
+CONFIG_VLLM_PROD_STACK_REPO="https://vllm-project.github.io/production-stack"
+CONFIG_VLLM_PROD_STACK_CHART_VERSION="latest"
+CONFIG_VLLM_PROD_STACK_ROUTER_IMAGE="ghcr.io/vllm-project/production-stack/router"
+CONFIG_VLLM_PROD_STACK_ROUTER_TAG="latest"
+CONFIG_VLLM_PROD_STACK_ENABLE_MONITORING=y
+CONFIG_VLLM_PROD_STACK_ENABLE_AUTOSCALING=n
+CONFIG_VLLM_MODEL_URL="facebook/opt-125m"
+CONFIG_VLLM_MODEL_NAME="opt-125m"
+CONFIG_VLLM_REPLICA_COUNT=2
+CONFIG_VLLM_USE_CPU_INFERENCE=y
+CONFIG_VLLM_REQUEST_CPU=8
+CONFIG_VLLM_REQUEST_MEMORY="20Gi"
+CONFIG_VLLM_REQUEST_GPU=0
+CONFIG_VLLM_MAX_MODEL_LEN=2048
+CONFIG_VLLM_DTYPE="float32"
+CONFIG_VLLM_TENSOR_PARALLEL_SIZE=1
+CONFIG_VLLM_ROUTER_ENABLED=y
+CONFIG_VLLM_ROUTER_ROUND_ROBIN=y
+CONFIG_VLLM_OBSERVABILITY_ENABLED=y
+CONFIG_VLLM_GRAFANA_PORT=3000
+CONFIG_VLLM_PROMETHEUS_PORT=9090
+CONFIG_VLLM_API_PORT=8000
+CONFIG_VLLM_BENCHMARK_ENABLED=y
+CONFIG_VLLM_BENCHMARK_DURATION=60
+CONFIG_VLLM_BENCHMARK_CONCURRENT_USERS=10
+CONFIG_VLLM_BENCHMARK_RESULTS_DIR="/data/vllm-benchmark"
diff --git a/defconfigs/vllm-quick-test b/defconfigs/vllm-quick-test
new file mode 100644
index 00000000..39bed05f
--- /dev/null
+++ b/defconfigs/vllm-quick-test
@@ -0,0 +1,42 @@
+# vLLM Production Stack quick test configuration (CI/demo)
+CONFIG_KDEVOPS_FIRST_RUN=n
+CONFIG_LIBVIRT=y
+CONFIG_LIBVIRT_VCPUS=4
+CONFIG_LIBVIRT_MEM_16G=y
+
+# Workflow configuration
+CONFIG_WORKFLOWS=y
+CONFIG_WORKFLOWS_TESTS=y
+CONFIG_WORKFLOWS_LINUX_TESTS=y
+CONFIG_WORKFLOWS_DEDICATED_WORKFLOW=y
+CONFIG_KDEVOPS_WORKFLOW_DEDICATE_VLLM=y
+
+# vLLM specific configuration - Quick test mode
+CONFIG_VLLM_PRODUCTION_STACK=y
+CONFIG_VLLM_K8S_MINIKUBE=y
+CONFIG_VLLM_HELM_RELEASE_NAME="vllm"
+CONFIG_VLLM_HELM_NAMESPACE="vllm-system"
+CONFIG_VLLM_MODEL_URL="facebook/opt-125m"
+CONFIG_VLLM_MODEL_NAME="opt-125m"
+CONFIG_VLLM_REPLICA_COUNT=1
+CONFIG_VLLM_REQUEST_CPU=2
+CONFIG_VLLM_REQUEST_MEMORY="8Gi"
+CONFIG_VLLM_REQUEST_GPU=0
+CONFIG_VLLM_GPU_TYPE=""
+CONFIG_VLLM_MAX_MODEL_LEN=512
+CONFIG_VLLM_DTYPE="auto"
+CONFIG_VLLM_GPU_MEMORY_UTILIZATION="0.9"
+CONFIG_VLLM_TENSOR_PARALLEL_SIZE=1
+CONFIG_VLLM_ROUTER_ENABLED=y
+CONFIG_VLLM_ROUTER_ROUND_ROBIN=y
+CONFIG_VLLM_OBSERVABILITY_ENABLED=y
+CONFIG_VLLM_GRAFANA_PORT=3000
+CONFIG_VLLM_PROMETHEUS_PORT=9090
+CONFIG_VLLM_API_PORT=8000
+CONFIG_VLLM_API_KEY=""
+CONFIG_VLLM_HF_TOKEN=""
+CONFIG_VLLM_QUICK_TEST=y
+CONFIG_VLLM_BENCHMARK_ENABLED=y
+CONFIG_VLLM_BENCHMARK_DURATION=30
+CONFIG_VLLM_BENCHMARK_CONCURRENT_USERS=5
+CONFIG_VLLM_BENCHMARK_RESULTS_DIR="/data/vllm-benchmark"
diff --git a/kconfigs/Kconfig.libvirt b/kconfigs/Kconfig.libvirt
index 95204ad1..4f296309 100644
--- a/kconfigs/Kconfig.libvirt
+++ b/kconfigs/Kconfig.libvirt
@@ -335,6 +335,7 @@ config LIBVIRT_LARGE_CPU
choice
prompt "Guest vCPUs"
+ default LIBVIRT_VCPUS_64 if KDEVOPS_WORKFLOW_DEDICATE_VLLM
default LIBVIRT_VCPUS_8
config LIBVIRT_VCPUS_2
@@ -408,6 +409,7 @@ config LIBVIRT_VCPUS_COUNT
choice
prompt "How much GiB memory to use per guest"
+ default LIBVIRT_MEM_64G if KDEVOPS_WORKFLOW_DEDICATE_VLLM
default LIBVIRT_MEM_4G
config LIBVIRT_MEM_2G
@@ -478,6 +480,7 @@ config LIBVIRT_MEM_MB
config LIBVIRT_IMAGE_SIZE
string "VM image size"
output yaml
+ default "100G" if KDEVOPS_WORKFLOW_DEDICATE_VLLM
default "20G"
depends on GUESTFS
help
diff --git a/kconfigs/workflows/Kconfig b/kconfigs/workflows/Kconfig
index 1be04c9c..5797521f 100644
--- a/kconfigs/workflows/Kconfig
+++ b/kconfigs/workflows/Kconfig
@@ -233,6 +233,14 @@ config KDEVOPS_WORKFLOW_DEDICATE_AI
This will dedicate your configuration to running only the
AI workflow for vector database performance testing.
+config KDEVOPS_WORKFLOW_DEDICATE_VLLM
+ bool "vllm"
+ select KDEVOPS_WORKFLOW_ENABLE_VLLM
+ help
+ This will dedicate your configuration to running only the
+ vLLM Production Stack workflow for deploying and benchmarking
+ large language models with Kubernetes.
+
config KDEVOPS_WORKFLOW_DEDICATE_MINIO
bool "minio"
select KDEVOPS_WORKFLOW_ENABLE_MINIO
@@ -265,6 +273,7 @@ config KDEVOPS_WORKFLOW_NAME
default "mmtests" if KDEVOPS_WORKFLOW_DEDICATE_MMTESTS
default "fio-tests" if KDEVOPS_WORKFLOW_DEDICATE_FIO_TESTS
default "ai" if KDEVOPS_WORKFLOW_DEDICATE_AI
+ default "vllm" if KDEVOPS_WORKFLOW_DEDICATE_VLLM
default "minio" if KDEVOPS_WORKFLOW_DEDICATE_MINIO
default "build-linux" if KDEVOPS_WORKFLOW_DEDICATE_BUILD_LINUX
@@ -395,6 +404,14 @@ config KDEVOPS_WORKFLOW_NOT_DEDICATED_ENABLE_AI
Select this option if you want to provision AI benchmarks on a
single target node for by-hand testing.
+config KDEVOPS_WORKFLOW_NOT_DEDICATED_ENABLE_VLLM
+ bool "vllm"
+ select KDEVOPS_WORKFLOW_ENABLE_VLLM
+ depends on LIBVIRT || TERRAFORM_PRIVATE_NET
+ help
+ Select this option if you want to provision vLLM Production Stack
+ on a single target node for by-hand testing and development.
+
endif # !WORKFLOWS_DEDICATED_WORKFLOW
config KDEVOPS_WORKFLOW_ENABLE_FSTESTS
@@ -530,6 +547,17 @@ source "workflows/ai/Kconfig"
endmenu
endif # KDEVOPS_WORKFLOW_ENABLE_AI
+config KDEVOPS_WORKFLOW_ENABLE_VLLM
+ bool
+ output yaml
+ default y if KDEVOPS_WORKFLOW_NOT_DEDICATED_ENABLE_VLLM || KDEVOPS_WORKFLOW_DEDICATE_VLLM
+
+if KDEVOPS_WORKFLOW_ENABLE_VLLM
+menu "Configure and run vLLM Production Stack"
+source "workflows/vllm/Kconfig"
+endmenu
+endif # KDEVOPS_WORKFLOW_ENABLE_VLLM
+
config KDEVOPS_WORKFLOW_ENABLE_MINIO
bool
output yaml
diff --git a/playbooks/roles/gen_hosts/defaults/main.yml b/playbooks/roles/gen_hosts/defaults/main.yml
index b0b59542..63e7a02c 100644
--- a/playbooks/roles/gen_hosts/defaults/main.yml
+++ b/playbooks/roles/gen_hosts/defaults/main.yml
@@ -30,6 +30,7 @@ kdevops_workflow_enable_sysbench: false
kdevops_workflow_enable_fio_tests: false
kdevops_workflow_enable_mmtests: false
kdevops_workflow_enable_ai: false
+kdevops_workflow_enable_vllm: false
workflows_reboot_limit: false
kdevops_use_declared_hosts: false
diff --git a/playbooks/roles/gen_hosts/tasks/main.yml b/playbooks/roles/gen_hosts/tasks/main.yml
index c4599e4e..546a0038 100644
--- a/playbooks/roles/gen_hosts/tasks/main.yml
+++ b/playbooks/roles/gen_hosts/tasks/main.yml
@@ -270,6 +270,21 @@
- ansible_hosts_template.stat.exists
- not kdevops_use_declared_hosts|default(false)|bool
+- name: Generate the Ansible hosts file for a dedicated vLLM setup
+ tags: ['hosts']
+ ansible.builtin.template:
+ src: "{{ kdevops_hosts_template }}"
+ dest: "{{ ansible_cfg_inventory }}"
+ force: true
+ trim_blocks: True
+ lstrip_blocks: True
+ mode: '0644'
+ when:
+ - kdevops_workflows_dedicated_workflow
+ - kdevops_workflow_enable_vllm|default(false)|bool
+ - ansible_hosts_template.stat.exists
+ - not kdevops_use_declared_hosts|default(false)|bool
+
- name: Verify if final host file exists
ansible.builtin.stat:
path: "{{ ansible_cfg_inventory }}"
diff --git a/playbooks/roles/gen_hosts/templates/workflows/vllm.j2 b/playbooks/roles/gen_hosts/templates/workflows/vllm.j2
new file mode 100644
index 00000000..d0564e80
--- /dev/null
+++ b/playbooks/roles/gen_hosts/templates/workflows/vllm.j2
@@ -0,0 +1,65 @@
+{# Workflow template for vLLM Production Stack #}
+[all]
+localhost ansible_connection=local
+{{ kdevops_host_prefix }}-vllm
+{% if kdevops_baseline_and_dev %}
+{{ kdevops_host_prefix }}-vllm-dev
+{% endif %}
+
+[all:vars]
+ansible_python_interpreter = "{{ kdevops_python_interpreter }}"
+
+[baseline]
+{{ kdevops_host_prefix }}-vllm
+
+[baseline:vars]
+ansible_python_interpreter = "{{ kdevops_python_interpreter }}"
+
+{% if kdevops_baseline_and_dev %}
+[dev]
+{{ kdevops_host_prefix }}-vllm-dev
+
+[dev:vars]
+ansible_python_interpreter = "{{ kdevops_python_interpreter }}"
+
+{% endif %}
+[vllm]
+{{ kdevops_host_prefix }}-vllm
+{% if kdevops_baseline_and_dev %}
+{{ kdevops_host_prefix }}-vllm-dev
+{% endif %}
+
+[vllm:vars]
+ansible_python_interpreter = "{{ kdevops_python_interpreter }}"
+
+{% if kdevops_enable_iscsi %}
+[iscsi]
+{{ kdevops_host_prefix }}-iscsi
+
+[iscsi:vars]
+ansible_python_interpreter = "{{ kdevops_python_interpreter }}"
+{% endif %}
+
+{% if kdevops_nfsd_enable %}
+[nfsd]
+{{ kdevops_host_prefix }}-nfsd
+
+[nfsd:vars]
+ansible_python_interpreter = "{{ kdevops_python_interpreter }}"
+{% endif %}
+
+{% if kdevops_smbd_enable %}
+[smbd]
+{{ kdevops_host_prefix }}-smbd
+
+[smbd:vars]
+ansible_python_interpreter = "{{ kdevops_python_interpreter }}"
+{% endif %}
+
+{% if kdevops_krb5_enable %}
+[kdc]
+{{ kdevops_host_prefix }}-kdc
+
+[kdc:vars]
+ansible_python_interpreter = "{{ kdevops_python_interpreter }}"
+{% endif %}
diff --git a/playbooks/roles/gen_nodes/defaults/main.yml b/playbooks/roles/gen_nodes/defaults/main.yml
index aa8037cd..c6275721 100644
--- a/playbooks/roles/gen_nodes/defaults/main.yml
+++ b/playbooks/roles/gen_nodes/defaults/main.yml
@@ -13,6 +13,7 @@ kdevops_workflow_enable_selftests: false
kdevops_workflow_enable_mmtests: false
kdevops_workflow_enable_fio_tests: false
kdevops_workflow_enable_ai: false
+kdevops_workflow_enable_vllm: false
kdevops_nfsd_enable: false
kdevops_smbd_enable: false
kdevops_krb5_enable: false
diff --git a/playbooks/roles/gen_nodes/tasks/main.yml b/playbooks/roles/gen_nodes/tasks/main.yml
index 716c8ec0..7a98fff4 100644
--- a/playbooks/roles/gen_nodes/tasks/main.yml
+++ b/playbooks/roles/gen_nodes/tasks/main.yml
@@ -790,6 +790,42 @@
- ai_enabled_section_types is defined
- ai_enabled_section_types | length > 0
+# vLLM Production Stack workflow nodes
+
+- name: Generate the vLLM kdevops nodes file using {{ kdevops_nodes_template }} as jinja2 source template
+ tags: ['hosts']
+ vars:
+ node_template: "{{ kdevops_nodes_template | basename }}"
+ nodes: "{{ [kdevops_host_prefix + '-vllm'] }}"
+ all_generic_nodes: "{{ [kdevops_host_prefix + '-vllm'] }}"
+ ansible.builtin.template:
+ src: "{{ node_template }}"
+ dest: "{{ topdir_path }}/{{ kdevops_nodes }}"
+ force: true
+ mode: "0644"
+ when:
+ - kdevops_workflows_dedicated_workflow
+ - kdevops_workflow_enable_vllm
+ - ansible_nodes_template.stat.exists
+ - not kdevops_baseline_and_dev
+
+- name: Generate the vLLM kdevops nodes file with dev hosts using {{ kdevops_nodes_template }} as jinja2 source template
+ tags: ['hosts']
+ vars:
+ node_template: "{{ kdevops_nodes_template | basename }}"
+ nodes: "{{ [kdevops_host_prefix + '-vllm', kdevops_host_prefix + '-vllm-dev'] }}"
+ all_generic_nodes: "{{ [kdevops_host_prefix + '-vllm', kdevops_host_prefix + '-vllm-dev'] }}"
+ ansible.builtin.template:
+ src: "{{ node_template }}"
+ dest: "{{ topdir_path }}/{{ kdevops_nodes }}"
+ force: true
+ mode: "0644"
+ when:
+ - kdevops_workflows_dedicated_workflow
+ - kdevops_workflow_enable_vllm
+ - ansible_nodes_template.stat.exists
+ - kdevops_baseline_and_dev
+
# MinIO S3 Storage Testing workflow nodes
# Multi-filesystem MinIO configurations
diff --git a/playbooks/roles/linux-mirror/tasks/main.yml b/playbooks/roles/linux-mirror/tasks/main.yml
index 007a0411..b028729f 100644
--- a/playbooks/roles/linux-mirror/tasks/main.yml
+++ b/playbooks/roles/linux-mirror/tasks/main.yml
@@ -259,6 +259,7 @@
- not install_only_git_daemon|bool
tags: ["nfs", "mirror"]
+
- name: Check if /mirror is already exported
become: true
ansible.builtin.command:
diff --git a/playbooks/roles/vllm/defaults/main.yml b/playbooks/roles/vllm/defaults/main.yml
new file mode 100644
index 00000000..739c8136
--- /dev/null
+++ b/playbooks/roles/vllm/defaults/main.yml
@@ -0,0 +1,17 @@
+---
+# vLLM role default variables
+vllm_production_stack_repo: https://github.com/vllm-project/production-stack.git
+vllm_production_stack_version: main
+vllm_local_path: /data/vllm
+vllm_results_dir: "{{ vllm_benchmark_results_dir | default('/data/vllm-benchmark') }}"
+
+# Default image versions that are known to work
+# Note: vLLM v0.10.2+ is recommended for Production Stack with CPU inference
+# - v0.6.5+ required for --no-enable-prefix-caching flag support
+# - v0.6.5-v0.6.6 have CPU inference bugs (NotImplementedError in is_async_output_supported)
+# - v0.10.2 fixes all CPU inference issues and is production ready
+# For CPU inference, use openeuler/vllm-cpu instead of vllm/vllm-openai
+vllm_engine_image_repo: "{{ 'openeuler/vllm-cpu' if vllm_use_cpu_inference | default(false) else 'vllm/vllm-openai' }}"
+vllm_engine_image_tag: "{{ 'latest' if vllm_use_cpu_inference | default(false) else 'v0.10.2' }}"
+vllm_prod_stack_router_image: ghcr.io/vllm-project/production-stack/router
+vllm_prod_stack_router_tag: latest
diff --git a/playbooks/roles/vllm/tasks/configure-docker-data.yml b/playbooks/roles/vllm/tasks/configure-docker-data.yml
new file mode 100644
index 00000000..c00b0f48
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/configure-docker-data.yml
@@ -0,0 +1,187 @@
+---
+# Configure Docker to use /data for storage to avoid filling up root filesystem
+
+- name: Ensure /data/docker directory exists
+ ansible.builtin.file:
+ path: /data/docker
+ state: directory
+ mode: '0755'
+ owner: root
+ group: root
+ become: yes
+
+- name: Check if Docker daemon.json exists
+ ansible.builtin.stat:
+ path: /etc/docker/daemon.json
+ register: docker_daemon_config
+
+- name: Read existing Docker daemon configuration
+ ansible.builtin.slurp:
+ src: /etc/docker/daemon.json
+ register: docker_daemon_json
+ when: docker_daemon_config.stat.exists
+
+- name: Parse existing Docker daemon configuration
+ set_fact:
+ docker_config: "{{ docker_daemon_json.content | b64decode | from_json }}"
+ when: docker_daemon_config.stat.exists
+
+- name: Initialize Docker configuration if not exists
+ set_fact:
+ docker_config: {}
+ when: not docker_daemon_config.stat.exists
+
+- name: Check if Docker mirror is available
+ ansible.builtin.stat:
+ path: /mirror/docker
+ register: docker_mirror_check
+
+- name: Auto-detect Docker mirror registry endpoint via 9P mount
+ set_fact:
+ docker_registry_mirrors:
+ - "http://{{ ansible_default_ipv4.gateway }}:5000"
+ docker_insecure_registries:
+ - "{{ ansible_default_ipv4.gateway }}:5000"
+ docker_mirror_type: "9p_mount"
+ when:
+ - docker_mirror_check.stat.exists
+ - docker_mirror_check.stat.isdir
+
+- name: Auto-detect Docker mirror registry endpoint via IP
+ ansible.builtin.uri:
+ url: "http://{{ ansible_default_ipv4.gateway }}:5000/v2/_catalog"
+ method: GET
+ timeout: 5
+ register: mirror_registry_check
+ failed_when: false
+ when:
+ - not docker_mirror_check.stat.exists
+ - docker_registry_mirrors is not defined
+
+- name: Set Docker registry mirror configuration via IP
+ set_fact:
+ docker_registry_mirrors:
+ - "http://{{ ansible_default_ipv4.gateway }}:5000"
+ docker_insecure_registries:
+ - "{{ ansible_default_ipv4.gateway }}:5000"
+ docker_mirror_type: "ip_gateway"
+ when:
+ - not docker_mirror_check.stat.exists
+ - mirror_registry_check.status | default(0) == 200
+
+- name: Display Docker mirror auto-detection result
+ debug:
+ msg: >-
+ Docker mirror auto-detection:
+ {% if docker_registry_mirrors is defined %}
+ ✅ Found Docker mirror at {{ docker_registry_mirrors[0] }}
+ ({{ docker_mirror_type | default('unknown') }}) - will use for faster image pulls
+ {% elif docker_mirror_check.stat.exists %}
+ ⚠️ Docker mirror directory exists but registry not accessible
+ {% else %}
+ ℹ️ No Docker mirror detected - using Docker Hub directly
+ {% endif %}
+
+- name: Update Docker configuration with data-root and optional registry mirrors
+ set_fact:
+ docker_config: >-
+ {{ docker_config | combine({'data-root': '/data/docker'}) |
+ combine({
+ 'registry-mirrors': docker_registry_mirrors,
+ 'insecure-registries': docker_insecure_registries
+ }, recursive=True)
+ if docker_registry_mirrors is defined
+ else docker_config | combine({'data-root': '/data/docker'}) }}
+
+- name: Configure Docker daemon to use /data
+ ansible.builtin.copy:
+ content: "{{ docker_config | to_nice_json }}"
+ dest: /etc/docker/daemon.json
+ mode: '0644'
+ owner: root
+ group: root
+ backup: yes
+ become: yes
+ register: docker_daemon_updated
+
+- name: Stop Docker service
+ ansible.builtin.systemd:
+ name: docker
+ state: stopped
+ become: yes
+ when: docker_daemon_updated.changed
+
+# Handle existing Docker data if present
+- name: Check if old Docker data exists
+ ansible.builtin.stat:
+ path: /var/lib/docker
+ register: old_docker_data
+
+- name: Check if Docker data directory has content
+ ansible.builtin.find:
+ paths: /var/lib/docker
+ file_type: any
+ recurse: no
+ register: docker_content
+ when: old_docker_data.stat.exists and old_docker_data.stat.isdir
+
+- name: Move existing Docker data to /data (if any exists)
+ ansible.builtin.shell:
+ cmd: "cp -a /var/lib/docker/. /data/docker/ && rm -rf /var/lib/docker"
+ become: yes
+ when:
+ - docker_daemon_updated.changed
+ - old_docker_data.stat.exists
+ - old_docker_data.stat.isdir
+ - docker_content.matched | default(0) > 0
+
+- name: Remove empty Docker data directory
+ ansible.builtin.file:
+ path: /var/lib/docker
+ state: absent
+ become: yes
+ when:
+ - docker_daemon_updated.changed
+ - old_docker_data.stat.exists
+ - docker_content.matched | default(0) == 0
+
+- name: Start Docker service
+ ansible.builtin.systemd:
+ name: docker
+ state: started
+ daemon_reload: yes
+ become: yes
+ when: docker_daemon_updated.changed
+
+- name: Ensure Docker service is enabled and running
+ ansible.builtin.systemd:
+ name: docker
+ state: started
+ enabled: yes
+ become: yes
+
+# Configure minikube to use /data as well
+- name: Ensure /data/minikube directory exists with correct ownership
+ ansible.builtin.file:
+ path: /data/minikube
+ state: directory
+ mode: '0755'
+ owner: kdevops
+ group: kdevops
+ recurse: yes
+ become: yes
+
+# Ensure vLLM specific directories use /data
+- name: Create vLLM data directories
+ ansible.builtin.file:
+ path: "{{ item }}"
+ state: directory
+ mode: '0755'
+ owner: kdevops
+ group: kdevops
+ become: yes
+ loop:
+ - /data/vllm
+ - /data/vllm/models
+ - /data/vllm/cache
+ - /data/vllm-benchmark
diff --git a/playbooks/roles/vllm/tasks/deploy-bare-metal.yml b/playbooks/roles/vllm/tasks/deploy-bare-metal.yml
new file mode 100644
index 00000000..0aaea73d
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/deploy-bare-metal.yml
@@ -0,0 +1,227 @@
+---
+# Deploy vLLM on bare metal with systemd
+- name: vLLM bare metal deployment tasks
+ block:
+ - name: Create vLLM directories
+ file:
+ path: "{{ item }}"
+ state: directory
+ mode: '0755'
+ owner: "{{ ansible_user_id }}"
+ group: "{{ ansible_user_gid }}"
+ become: yes
+ loop:
+ - "{{ vllm_bare_metal_data_dir | default('/var/lib/vllm') }}"
+ - "{{ vllm_bare_metal_log_dir | default('/var/log/vllm') }}"
+ - /etc/vllm
+
+ - name: Check GPU availability
+ ansible.builtin.command:
+ cmd: nvidia-smi -L
+ register: gpu_check
+ failed_when: false
+ changed_when: false
+
+ - name: Set GPU facts
+ set_fact:
+ has_nvidia_gpu: "{{ gpu_check.rc == 0 }}"
+ gpu_count: "{{ vllm_bare_metal_declare_host_gpu_count | default(gpu_check.stdout_lines | length if gpu_check.rc == 0 else 0) }}"
+ gpu_type: "{{ vllm_bare_metal_declare_host_gpu_type | default('auto-detected') }}"
+
+ - name: Display GPU information
+ debug:
+ msg: |
+ GPU Configuration:
+ - GPUs Available: {{ 'Yes' if has_nvidia_gpu else 'No' }}
+ - GPU Count: {{ gpu_count }}
+ {% if has_nvidia_gpu %}
+ - GPU Type: {{ gpu_type }}
+ {% endif %}
+ - Inference Mode: {{ 'GPU' if has_nvidia_gpu else 'CPU' }}
+
+ # Container-based deployment
+ - name: Deploy vLLM with container runtime
+ when: vllm_bare_metal_use_container | default(true)
+ block:
+ - name: Determine container runtime
+ set_fact:
+ container_runtime: "{{ 'docker' if vllm_bare_metal_docker | default(true) else 'podman' }}"
+
+ - name: Ensure container runtime is installed
+ package:
+ name: "{{ container_runtime }}"
+ state: present
+ become: yes
+
+ - name: Install nvidia-container-toolkit for GPU support
+ when: has_nvidia_gpu
+ package:
+ name: nvidia-container-toolkit
+ state: present
+ become: yes
+
+ - name: Configure container runtime for GPU
+ when: has_nvidia_gpu and container_runtime == 'docker'
+ ansible.builtin.command:
+ cmd: nvidia-ctk runtime configure --runtime=docker
+ become: yes
+ register: nvidia_config
+ changed_when: nvidia_config.rc == 0
+
+ - name: Restart Docker to apply GPU configuration
+ when: has_nvidia_gpu and container_runtime == 'docker' and nvidia_config.changed
+ systemd:
+ name: docker
+ state: restarted
+ become: yes
+
+ - name: Set vLLM bare metal container image with Docker mirror if enabled
+ ansible.builtin.set_fact:
+ vllm_bare_metal_image_final: >-
+ {%- if use_docker_mirror | default(false) | bool -%}
+ {%- if not has_nvidia_gpu -%}
+ localhost:{{ docker_mirror_port | default(5000) }}/vllm:v0.6.3-cpu
+ {%- else -%}
+ localhost:{{ docker_mirror_port | default(5000) }}/vllm-openai:latest
+ {%- endif -%}
+ {%- else -%}
+ {%- if not has_nvidia_gpu -%}
+ substratusai/vllm:v0.6.3-cpu
+ {%- else -%}
+ vllm/vllm-openai:latest
+ {%- endif -%}
+ {%- endif -%}
+
+ - name: Pull vLLM container image
+ community.docker.docker_image:
+ name: "{{ vllm_bare_metal_image_final }}"
+ source: pull
+
+ - name: Create vLLM systemd service for container
+ template:
+ src: vllm-container.service.j2
+ dest: "/etc/systemd/system/{{ vllm_bare_metal_service_name | default('vllm') }}.service"
+ mode: '0644'
+ become: yes
+ notify: restart vllm
+
+ # Direct installation (pip/source)
+ - name: Deploy vLLM with direct installation
+ when: not (vllm_bare_metal_use_container | default(true))
+ block:
+ - name: Ensure Python 3.8+ is installed
+ package:
+ name:
+ - python3
+ - python3-pip
+ - python3-venv
+ state: present
+ become: yes
+
+ - name: Create vLLM virtual environment
+ command:
+ cmd: python3 -m venv /opt/vllm/venv
+ creates: /opt/vllm/venv
+ become: yes
+
+ - name: Install vLLM from pip
+ pip:
+ name: vllm
+ virtualenv: /opt/vllm/venv
+ state: present
+ when: vllm_bare_metal_install_method | default('pip') == 'pip'
+ become: yes
+
+ - name: Install vLLM from source
+ when: vllm_bare_metal_install_method | default('pip') == 'source'
+ block:
+ - name: Clone vLLM repository
+ git:
+ repo: https://github.com/vllm-project/vllm.git
+ dest: /opt/vllm/src
+ version: main
+ become: yes
+
+ - name: Install vLLM from source
+ pip:
+ name: /opt/vllm/src
+ virtualenv: /opt/vllm/venv
+ editable: true
+ become: yes
+
+ - name: Create vLLM systemd service for direct installation
+ template:
+ src: vllm-direct.service.j2
+ dest: "/etc/systemd/system/{{ vllm_bare_metal_service_name | default('vllm') }}.service"
+ mode: '0644'
+ become: yes
+ notify: restart vllm
+
+ - name: Create vLLM configuration file
+ template:
+ src: vllm.conf.j2
+ dest: /etc/vllm/vllm.conf
+ mode: '0644'
+ become: yes
+ notify: restart vllm
+
+ - name: Reload systemd daemon
+ systemd:
+ daemon_reload: yes
+ become: yes
+
+ - name: Start and enable vLLM service
+ systemd:
+ name: "{{ vllm_bare_metal_service_name | default('vllm') }}"
+ state: started
+ enabled: yes
+ become: yes
+
+ - name: Wait for vLLM to be ready
+ uri:
+ url: "http://localhost:{{ vllm_api_port | default(8000) }}/health"
+ status_code: 200
+ register: health_check
+ until: health_check.status == 200
+ retries: 30
+ delay: 5
+
+ - name: Get vLLM models
+ uri:
+ url: "http://localhost:{{ vllm_api_port | default(8000) }}/v1/models"
+ method: GET
+ register: models_response
+
+ - name: Display deployment information
+ debug:
+ msg: |
+ vLLM deployed successfully on bare metal!
+
+ Service: {{ vllm_bare_metal_service_name | default('vllm') }}
+ Status: Active
+ API Endpoint: http://{{ ansible_default_ipv4.address }}:{{ vllm_api_port | default(8000) }}
+
+ Available Models:
+ {% for model in models_response.json.data %}
+ - {{ model.id }}
+ {% endfor %}
+
+ GPU Configuration:
+ - Mode: {{ 'GPU-accelerated' if has_nvidia_gpu else 'CPU-only' }}
+ {% if has_nvidia_gpu %}
+ - GPUs: {{ gpu_count }}
+ - Type: {{ gpu_type }}
+ {% endif %}
+
+ Service Management:
+ - Start: sudo systemctl start {{ vllm_bare_metal_service_name | default('vllm') }}
+ - Stop: sudo systemctl stop {{ vllm_bare_metal_service_name | default('vllm') }}
+ - Status: sudo systemctl status {{ vllm_bare_metal_service_name | default('vllm') }}
+ - Logs: sudo journalctl -u {{ vllm_bare_metal_service_name | default('vllm') }} -f
+
+# Handler for restarting vLLM
+- name: restart vllm
+ systemd:
+ name: "{{ vllm_bare_metal_service_name | default('vllm') }}"
+ state: restarted
+ become: yes
diff --git a/playbooks/roles/vllm/tasks/deploy-docker.yml b/playbooks/roles/vllm/tasks/deploy-docker.yml
new file mode 100644
index 00000000..be80eb74
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/deploy-docker.yml
@@ -0,0 +1,105 @@
+---
+# Deploy vLLM using latest Docker images
+- name: vLLM Docker deployment tasks
+ block:
+ - name: Ensure Docker service is started and enabled
+ ansible.builtin.systemd:
+ name: docker
+ state: started
+ enabled: yes
+ become: yes
+
+ - name: Add current user to docker group
+ ansible.builtin.user:
+ name: "{{ ansible_user_id }}"
+ groups: docker
+ append: yes
+ become: yes
+
+ - name: Ensure docker socket has correct permissions
+ ansible.builtin.file:
+ path: /var/run/docker.sock
+ mode: '0666'
+ become: yes
+
+ - name: Reset connection to apply docker group membership
+ meta: reset_connection
+
+ - name: Setup Kubernetes environment
+ ansible.builtin.import_tasks: tasks/setup-kubernetes.yml
+ when: vllm_k8s_minikube | default(false) or vllm_k8s_existing | default(false)
+
+ - name: Create vLLM local directory
+ file:
+ path: "{{ vllm_local_path | default('/data/vllm') }}"
+ state: directory
+ mode: '0755'
+
+ - name: Create results directory
+ file:
+ path: "{{ vllm_results_dir | default('/data/vllm-benchmark') }}"
+ state: directory
+ mode: '0755'
+
+ - name: Set vLLM Docker image with mirror if enabled
+ ansible.builtin.set_fact:
+ vllm_docker_image_final: >-
+ {%- if use_docker_mirror | default(false) | bool -%}
+ {%- if vllm_use_cpu_inference | default(false) -%}
+ localhost:{{ docker_mirror_port | default(5000) }}/vllm:v0.6.3-cpu
+ {%- else -%}
+ localhost:{{ docker_mirror_port | default(5000) }}/vllm-openai:latest
+ {%- endif -%}
+ {%- else -%}
+ {%- if vllm_use_cpu_inference | default(false) -%}
+ substratusai/vllm:v0.6.3-cpu
+ {%- else -%}
+ vllm/vllm-openai:latest
+ {%- endif -%}
+ {%- endif -%}
+
+ - name: Generate vLLM deployment manifest
+ template:
+ src: vllm-deployment.yaml.j2
+ dest: "{{ vllm_local_path | default('/data/vllm') }}/vllm-deployment.yaml"
+ mode: '0644'
+
+ - name: Deploy vLLM using kubectl
+ become: no
+ ansible.builtin.command:
+ cmd: kubectl apply -f {{ vllm_local_path | default('/data/vllm') }}/vllm-deployment.yaml
+ register: kubectl_apply
+ changed_when: "'created' in kubectl_apply.stdout or 'configured' in kubectl_apply.stdout"
+
+ - name: Wait for vLLM pods to be ready
+ become: no
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Pod
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ label_selectors:
+ - app=vllm-server
+ register: pod_list
+ until: pod_list.resources | length > 0 and pod_list.resources | selectattr('status.phase', 'equalto', 'Running') | list | length == pod_list.resources | length
+ retries: 30
+ delay: 10
+
+ - name: Get vLLM service endpoint
+ become: no
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Service
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ name: vllm-service
+ register: vllm_service
+
+ - name: Display vLLM endpoint information
+ debug:
+ msg: |
+ vLLM deployed successfully!
+ {% if vllm_k8s_type | default('minikube') == 'minikube' %}
+ To access the API, run: kubectl port-forward -n {{ vllm_helm_namespace | default('vllm-system') }} svc/vllm-service {{ vllm_api_port | default(8000) }}:8000
+ Then access: http://localhost:{{ vllm_api_port | default(8000) }}/v1/models
+ {% else %}
+ API endpoint: {{ vllm_service.resources[0].status.loadBalancer.ingress[0].ip | default('pending') }}:{{ vllm_api_port | default(8000) }}
+ {% endif %}
diff --git a/playbooks/roles/vllm/tasks/deploy-production-stack.yml b/playbooks/roles/vllm/tasks/deploy-production-stack.yml
new file mode 100644
index 00000000..6cf95e0b
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/deploy-production-stack.yml
@@ -0,0 +1,252 @@
+---
+# Deploy vLLM Production Stack using official Helm charts
+- name: vLLM Production Stack deployment tasks
+ block:
+ - name: Setup Kubernetes environment
+ ansible.builtin.import_tasks: tasks/setup-kubernetes.yml
+
+ - name: Ensure Helm is installed
+ ansible.builtin.import_tasks: tasks/setup-helm.yml
+
+ - name: Use default vLLM engine image (Docker mirror acts as pull-through cache)
+ ansible.builtin.set_fact:
+ vllm_engine_image_final: "{{ vllm_engine_image_repo }}"
+
+ - name: Use default router image (Docker mirror acts as pull-through cache)
+ ansible.builtin.set_fact:
+ vllm_router_image_final: "{{ vllm_prod_stack_router_image | default('ghcr.io/vllm-project/production-stack/router') }}"
+
+ - name: Add vLLM Production Stack Helm repository
+ kubernetes.core.helm_repository:
+ name: vllm-prod-stack
+ repo_url: "{{ vllm_prod_stack_repo | default('https://vllm-project.github.io/production-stack') }}"
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+
+ - name: Update Helm repositories
+ ansible.builtin.command:
+ cmd: helm repo update
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+ changed_when: false
+
+ - name: Verify kubectl context and cluster connectivity
+ ansible.builtin.command:
+ cmd: kubectl cluster-info --request-timeout=30s
+ register: cluster_info
+ retries: 3
+ delay: 10
+ until: cluster_info.rc == 0
+ failed_when: cluster_info.rc != 0
+
+ - name: Set kubectl context for Helm operations
+ ansible.builtin.command:
+ cmd: kubectl config use-context minikube
+ when: vllm_k8s_minikube | default(false)
+ ignore_errors: yes
+
+ - name: Create vLLM local directory
+ ansible.builtin.file:
+ path: "{{ vllm_local_path | default('/data/vllm') }}"
+ state: directory
+ mode: '0755'
+ become: yes
+
+ - name: Create vLLM namespace
+ kubernetes.core.k8s:
+ name: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ api_version: v1
+ kind: Namespace
+ state: present
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+
+ - name: Generate Helm values file for Production Stack
+ template:
+ src: vllm-prod-stack-official-values.yaml.j2
+ dest: "{{ vllm_local_path | default('/data/vllm') }}/prod-stack-values.yaml"
+ mode: '0644'
+ when: not (vllm_prod_stack_custom_values | default(false))
+
+ - name: Copy custom Helm values file
+ copy:
+ src: "{{ vllm_prod_stack_values_path }}"
+ dest: "{{ vllm_local_path | default('/data/vllm') }}/prod-stack-values.yaml"
+ mode: '0644'
+ when: vllm_prod_stack_custom_values | default(false)
+
+ - name: Deploy vLLM Production Stack with Helm
+ kubernetes.core.helm:
+ name: "{{ vllm_helm_release_name | default('vllm-prod') }}-{{ inventory_hostname_short }}"
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ chart_ref: vllm-prod-stack/vllm-stack
+ values_files:
+ - "{{ vllm_local_path | default('/data/vllm') }}/prod-stack-values.yaml"
+ wait: true
+ timeout: 30m
+ chart_version: "{{ vllm_prod_stack_chart_version if vllm_prod_stack_chart_version != 'latest' else omit }}"
+ force: true # Force reinstall if needed
+ atomic: false # Don't rollback on failure to help debugging
+ create_namespace: true
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+ register: helm_deploy
+ retries: 2
+ delay: 30
+ until: helm_deploy is succeeded
+
+ - name: Wait for vLLM engine pods to be ready
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Pod
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ label_selectors:
+ - model={{ vllm_model_name }}
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+ register: engine_pods
+ until: >
+ engine_pods.resources | length > 0 and
+ engine_pods.resources | selectattr('status.phase', 'equalto', 'Running') | list | length == engine_pods.resources | length
+ retries: 30
+ delay: 10
+
+ - name: Wait for router pod to be ready
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Deployment
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ name: "{{ vllm_helm_release_name | default('vllm-prod') }}-{{ inventory_hostname_short }}-deployment-router"
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+ register: router_deployment
+ until: >
+ router_deployment.resources | length > 0 and
+ router_deployment.resources[0].status.readyReplicas | default(0) > 0 and
+ router_deployment.resources[0].status.readyReplicas == router_deployment.resources[0].status.replicas
+ retries: 20
+ delay: 5
+ when: vllm_router_enabled | default(true)
+
+ - name: Check if monitoring components exist
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Pod
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ label_selectors:
+ - app.kubernetes.io/name=prometheus
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+ register: prometheus_check
+ ignore_errors: yes
+ when: vllm_prod_stack_enable_monitoring | default(true)
+
+ - name: Setup monitoring stack
+ when:
+ - vllm_prod_stack_enable_monitoring | default(true)
+ - prometheus_check is defined
+ - prometheus_check.resources | length > 0
+ block:
+ - name: Wait for Prometheus to be ready
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Pod
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ label_selectors:
+ - app.kubernetes.io/name=prometheus
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+ register: prometheus_pod
+ until: prometheus_pod.resources | length > 0 and prometheus_pod.resources[0].status.phase == "Running"
+ retries: 20
+ delay: 5
+
+ - name: Wait for Grafana to be ready
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Pod
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ label_selectors:
+ - app.kubernetes.io/name=grafana
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+ register: grafana_pod
+ until: grafana_pod.resources | length > 0 and grafana_pod.resources[0].status.phase == "Running"
+ retries: 20
+ delay: 5
+
+ - name: Get service endpoints
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Service
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ environment:
+ KUBECONFIG: "{{ '/root/.kube/config' if vllm_k8s_minikube | default(false) else '~/.kube/config' }}"
+ MINIKUBE_HOME: "{{ '/data/minikube' if vllm_k8s_minikube | default(false) else omit }}"
+ become: "{{ true if vllm_k8s_minikube | default(false) else false }}"
+ register: services
+
+ - name: Display deployment information
+ debug:
+ msg: |
+ vLLM Production Stack deployed successfully!
+
+ Services available:
+ {% for service in services.resources %}
+ - {{ service.metadata.name }}: {{ service.spec.type }}
+ {% if service.spec.type == 'LoadBalancer' and service.status.loadBalancer.ingress is defined %}
+ External IP: {{ service.status.loadBalancer.ingress[0].ip | default('pending') }}
+ {% endif %}
+ {% endfor %}
+
+ {% if vllm_k8s_minikube | default(false) %}
+ To access services on Minikube:
+ - API: kubectl port-forward -n {{ vllm_helm_namespace }} svc/vllm-router {{ vllm_api_port }}:8000
+ {% if vllm_prod_stack_enable_monitoring | default(true) %}
+ - Grafana: kubectl port-forward -n {{ vllm_helm_namespace }} svc/grafana {{ vllm_grafana_port }}:3000
+ - Prometheus: kubectl port-forward -n {{ vllm_helm_namespace }} svc/prometheus {{ vllm_prometheus_port }}:9090
+ {% endif %}
+ {% endif %}
+
+ - name: Setup autoscaling
+ when: vllm_prod_stack_enable_autoscaling | default(false)
+ kubernetes.core.k8s:
+ state: present
+ definition:
+ apiVersion: autoscaling/v2
+ kind: HorizontalPodAutoscaler
+ metadata:
+ name: vllm-engine-hpa
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ spec:
+ scaleTargetRef:
+ apiVersion: apps/v1
+ kind: Deployment
+ name: vllm-engine
+ minReplicas: "{{ vllm_prod_stack_min_replicas | default(1) }}"
+ maxReplicas: "{{ vllm_prod_stack_max_replicas | default(5) }}"
+ metrics:
+ - type: Resource
+ resource:
+ name: "{{ 'nvidia.com/gpu' if not (vllm_use_cpu_inference | default(false)) else 'cpu' }}"
+ target:
+ type: Utilization
+ averageUtilization: "{{ vllm_prod_stack_target_gpu_utilization | default(80) }}"
diff --git a/playbooks/roles/vllm/tasks/install-deps/debian/main.yml b/playbooks/roles/vllm/tasks/install-deps/debian/main.yml
new file mode 100644
index 00000000..12a8a8e3
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/install-deps/debian/main.yml
@@ -0,0 +1,70 @@
+---
+- name: Update apt cache
+ become: true
+ become_method: sudo
+ ansible.builtin.apt:
+ update_cache: true
+ tags: vllm
+
+- name: Install vLLM system dependencies
+ become: true
+ become_method: sudo
+ ansible.builtin.apt:
+ name:
+ - git
+ - curl
+ - wget
+ - python3
+ - python3-venv
+ - docker.io
+ - ca-certificates
+ - gnupg
+ - lsb-release
+ - apt-transport-https
+ - iptables
+ - conntrack
+ state: present
+ update_cache: true
+ tags: ["vllm", "deps"]
+
+- name: Install Python development dependencies
+ become: true
+ become_method: sudo
+ ansible.builtin.apt:
+ name:
+ - python3-dev
+ - python3-setuptools
+ - python3-wheel
+ - build-essential
+ state: present
+ tags: ["vllm", "deps"]
+
+- name: Install Python benchmarking dependencies
+ become: true
+ become_method: sudo
+ ansible.builtin.apt:
+ name:
+ - python3-aiohttp
+ - python3-numpy
+ - python3-pandas
+ - python3-matplotlib
+ state: present
+ tags: ["vllm", "deps", "benchmark"]
+
+- name: Install Python Kubernetes client library
+ become: true
+ become_method: sudo
+ ansible.builtin.apt:
+ name:
+ - python3-kubernetes
+ state: present
+ tags: ["vllm", "deps"]
+
+- name: Add kdevops user to docker group
+ become: true
+ become_method: sudo
+ ansible.builtin.user:
+ name: kdevops
+ groups: docker
+ append: yes
+ tags: ["vllm", "deps", "docker-config"]
diff --git a/playbooks/roles/vllm/tasks/install-deps/main.yml b/playbooks/roles/vllm/tasks/install-deps/main.yml
new file mode 100644
index 00000000..6b637133
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/install-deps/main.yml
@@ -0,0 +1,12 @@
+---
+- ansible.builtin.include_role:
+ name: pkg
+
+# tasks to install dependencies for vLLM
+- name: vLLM distribution specific setup
+ ansible.builtin.import_tasks: tasks/install-deps/debian/main.yml
+ when: ansible_facts['os_family']|lower == 'debian'
+- ansible.builtin.import_tasks: tasks/install-deps/suse/main.yml
+ when: ansible_facts['os_family']|lower == 'suse'
+- ansible.builtin.import_tasks: tasks/install-deps/redhat/main.yml
+ when: ansible_facts['os_family']|lower == 'redhat'
diff --git a/playbooks/roles/vllm/tasks/install-deps/redhat/main.yml b/playbooks/roles/vllm/tasks/install-deps/redhat/main.yml
new file mode 100644
index 00000000..12efb9e1
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/install-deps/redhat/main.yml
@@ -0,0 +1,108 @@
+---
+- name: Install vLLM system dependencies
+ become: true
+ become_method: sudo
+ ansible.builtin.yum:
+ name:
+ - git
+ - curl
+ - wget
+ - python3
+ - docker
+ - ca-certificates
+ - gnupg
+ state: present
+ when: ansible_distribution_major_version|int <= 7
+ tags: ["vllm", "deps"]
+
+- name: Install vLLM system dependencies (dnf)
+ become: true
+ become_method: sudo
+ ansible.builtin.dnf:
+ name:
+ - git
+ - curl
+ - wget
+ - python3
+ - docker
+ - ca-certificates
+ - gnupg
+ state: present
+ when: ansible_distribution_major_version|int >= 8
+ tags: ["vllm", "deps"]
+
+- name: Install Python development dependencies
+ become: true
+ become_method: sudo
+ ansible.builtin.yum:
+ name:
+ - python3-devel
+ - python3-setuptools
+ - python3-wheel
+ - gcc
+ - gcc-c++
+ - make
+ state: present
+ when: ansible_distribution_major_version|int <= 7
+ tags: ["vllm", "deps"]
+
+- name: Install Python development dependencies (dnf)
+ become: true
+ become_method: sudo
+ ansible.builtin.dnf:
+ name:
+ - python3-devel
+ - python3-setuptools
+ - python3-wheel
+ - gcc
+ - gcc-c++
+ - make
+ state: present
+ when: ansible_distribution_major_version|int >= 8
+ tags: ["vllm", "deps"]
+
+- name: Install Python benchmarking dependencies (yum)
+ become: true
+ become_method: sudo
+ ansible.builtin.yum:
+ name:
+ - python3-aiohttp
+ - python3-numpy
+ - python3-pandas
+ - python3-matplotlib
+ state: present
+ when: ansible_distribution_major_version|int <= 7
+ tags: ["vllm", "deps", "benchmark"]
+
+- name: Install Python benchmarking dependencies (dnf)
+ become: true
+ become_method: sudo
+ ansible.builtin.dnf:
+ name:
+ - python3-aiohttp
+ - python3-numpy
+ - python3-pandas
+ - python3-matplotlib
+ state: present
+ when: ansible_distribution_major_version|int >= 8
+ tags: ["vllm", "deps", "benchmark"]
+
+- name: Install Python Kubernetes client library (yum)
+ become: true
+ become_method: sudo
+ ansible.builtin.yum:
+ name:
+ - python3-kubernetes
+ state: present
+ when: ansible_distribution_major_version|int <= 7
+ tags: ["vllm", "deps"]
+
+- name: Install Python Kubernetes client library (dnf)
+ become: true
+ become_method: sudo
+ ansible.builtin.dnf:
+ name:
+ - python3-kubernetes
+ state: present
+ when: ansible_distribution_major_version|int >= 8
+ tags: ["vllm", "deps"]
diff --git a/playbooks/roles/vllm/tasks/install-deps/suse/main.yml b/playbooks/roles/vllm/tasks/install-deps/suse/main.yml
new file mode 100644
index 00000000..fcb17d94
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/install-deps/suse/main.yml
@@ -0,0 +1,50 @@
+---
+- name: Install vLLM system dependencies
+ become: true
+ become_method: sudo
+ ansible.builtin.zypper:
+ name:
+ - git
+ - curl
+ - wget
+ - python3
+ - docker
+ - ca-certificates
+ - gnupg
+ state: present
+ tags: ["vllm", "deps"]
+
+- name: Install Python development dependencies
+ become: true
+ become_method: sudo
+ ansible.builtin.zypper:
+ name:
+ - python3-devel
+ - python3-setuptools
+ - python3-wheel
+ - gcc
+ - gcc-c++
+ - make
+ state: present
+ tags: ["vllm", "deps"]
+
+- name: Install Python benchmarking dependencies
+ become: true
+ become_method: sudo
+ ansible.builtin.zypper:
+ name:
+ - python3-aiohttp
+ - python3-numpy
+ - python3-pandas
+ - python3-matplotlib
+ state: present
+ tags: ["vllm", "deps", "benchmark"]
+
+- name: Install Python Kubernetes client library
+ become: true
+ become_method: sudo
+ ansible.builtin.zypper:
+ name:
+ - python3-kubernetes
+ state: present
+ tags: ["vllm", "deps"]
diff --git a/playbooks/roles/vllm/tasks/main.yml b/playbooks/roles/vllm/tasks/main.yml
new file mode 100644
index 00000000..d6b239f4
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/main.yml
@@ -0,0 +1,591 @@
+---
+# First ensure we have the data partition for vLLM storage
+- ansible.builtin.include_role:
+ name: create_data_partition
+ tags: ["data_partition", "vllm-storage"]
+
+# Set up Docker mirror 9P mount if available and configured
+- ansible.builtin.import_role:
+ name: docker_mirror_9p
+ tags: ["deps", "docker-config"]
+
+- name: Set vLLM workflow variables
+ set_fact:
+ vllm_workflow_enabled: true
+ tags: vars
+
+- name: Install vLLM dependencies
+ ansible.builtin.import_tasks: tasks/install-deps/main.yml
+ tags: ["vllm", "deps"]
+
+# Configure Docker and storage to use /data partition BEFORE starting any containers
+- name: Configure Docker to use /data for storage
+ ansible.builtin.import_tasks: tasks/configure-docker-data.yml
+ tags: ["deps", "docker-config", "storage", "vllm-deploy"]
+
+# Route to appropriate deployment method based on configuration
+- name: Deploy vLLM using latest Docker images
+ ansible.builtin.import_tasks: tasks/deploy-docker.yml
+ when: vllm_deployment_type | default('docker') == 'docker'
+ tags: ["vllm-deploy"]
+
+- name: Deploy vLLM Production Stack with Helm
+ ansible.builtin.import_tasks: tasks/deploy-production-stack.yml
+ when: vllm_deployment_type | default('docker') == 'production-stack'
+ tags: ["vllm-deploy"]
+
+- name: Deploy vLLM on bare metal
+ ansible.builtin.import_tasks: tasks/deploy-bare-metal.yml
+ when: vllm_deployment_type | default('docker') == 'bare-metal'
+ tags: ["vllm-deploy"]
+
+# Legacy deployment block - will be moved to deploy-docker.yml
+- name: vLLM deployment tasks (legacy)
+ tags: vllm-deploy
+ when: vllm_deployment_type | default('docker') != 'production-stack'
+ block:
+ - name: Ensure Docker service is started and enabled
+ ansible.builtin.systemd:
+ name: docker
+ state: started
+ enabled: yes
+ become: yes
+
+ - name: Add current user to docker group
+ ansible.builtin.user:
+ name: "{{ ansible_user_id }}"
+ groups: docker
+ append: yes
+ become: yes
+
+ - name: Ensure docker socket has correct permissions
+ ansible.builtin.file:
+ path: /var/run/docker.sock
+ mode: '0666'
+ become: yes
+
+ - name: Reset connection to apply docker group membership
+ meta: reset_connection
+
+ - name: Wait for Docker to be accessible
+ ansible.builtin.wait_for:
+ path: /var/run/docker.sock
+ state: present
+ timeout: 30
+
+ - name: Test Docker access
+ ansible.builtin.command:
+ cmd: docker version
+ register: docker_test
+ become: no
+ failed_when: false
+ changed_when: false
+ retries: 3
+ delay: 2
+ until: docker_test.rc == 0
+
+ - name: Check if kubectl exists
+ ansible.builtin.stat:
+ path: /usr/local/bin/kubectl
+ register: kubectl_stat
+
+ - name: Get latest kubectl version
+ when: not kubectl_stat.stat.exists
+ ansible.builtin.uri:
+ url: https://dl.k8s.io/release/stable.txt
+ return_content: yes
+ register: kubectl_version
+
+ - name: Download kubectl
+ when: not kubectl_stat.stat.exists
+ ansible.builtin.get_url:
+ url: "https://dl.k8s.io/release/{{ kubectl_version.content | trim }}/bin/linux/amd64/kubectl"
+ dest: /tmp/kubectl
+ mode: '0755'
+
+ - name: Install kubectl
+ when: not kubectl_stat.stat.exists
+ ansible.builtin.copy:
+ src: /tmp/kubectl
+ dest: /usr/local/bin/kubectl
+ mode: '0755'
+ remote_src: yes
+
+ - name: Check if helm exists
+ ansible.builtin.stat:
+ path: /usr/local/bin/helm
+ register: helm_stat
+
+ - name: Download Helm installer script
+ when: not helm_stat.stat.exists
+ ansible.builtin.get_url:
+ url: https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
+ dest: /tmp/get-helm-3.sh
+ mode: '0755'
+
+ - name: Install Helm
+ when: not helm_stat.stat.exists
+ ansible.builtin.command:
+ cmd: /tmp/get-helm-3.sh
+ environment:
+ HELM_INSTALL_DIR: /usr/local/bin
+
+ - name: Check if minikube exists
+ when: vllm_k8s_type | default('minikube') == 'minikube'
+ ansible.builtin.stat:
+ path: /usr/local/bin/minikube
+ register: minikube_stat
+
+ - name: Download Minikube
+ when:
+ - vllm_k8s_type | default('minikube') == 'minikube'
+ - not minikube_stat.stat.exists
+ ansible.builtin.get_url:
+ url: https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
+ dest: /tmp/minikube-linux-amd64
+ mode: '0755'
+
+ - name: Install Minikube
+ when:
+ - vllm_k8s_type | default('minikube') == 'minikube'
+ - not minikube_stat.stat.exists
+ ansible.builtin.copy:
+ src: /tmp/minikube-linux-amd64
+ dest: /usr/local/bin/minikube
+ mode: '0755'
+ remote_src: yes
+
+ - name: Get available system memory
+ ansible.builtin.command:
+ cmd: free -m
+ register: memory_info
+ changed_when: false
+
+ - name: Calculate minikube memory allocation
+ set_fact:
+ minikube_memory_mb: >-
+ {%- set total_mem = memory_info.stdout_lines[1].split()[1] | int -%}
+ {%- set requested_mem = (vllm_request_memory | default('16Gi') | regex_replace('Gi', '') | int) * 1024 -%}
+ {%- set available_mem = (total_mem * 0.8) | int -%}
+ {{ [requested_mem, available_mem, 3072] | min }}
+
+ - name: Calculate minikube CPU allocation
+ set_fact:
+ minikube_cpus: >-
+ {%- set requested_cpus = vllm_request_cpu | default(4) | int -%}
+ {%- set available_cpus = ansible_processor_vcpus | default(4) | int -%}
+ {{ [requested_cpus, available_cpus] | min }}
+
+ - name: Check if Minikube is already running
+ when: vllm_k8s_type | default('minikube') == 'minikube'
+ become: no
+ ansible.builtin.command:
+ cmd: minikube status --format={{ "{{.Host}}" }}
+ register: minikube_status
+ changed_when: false
+ failed_when: false
+
+ - name: Ensure Minikube directory permissions
+ when: vllm_k8s_type | default('minikube') == 'minikube'
+ ansible.builtin.file:
+ path: /data/minikube
+ state: directory
+ owner: "kdevops"
+ group: "kdevops"
+ mode: '0755'
+ recurse: yes
+ become: yes
+
+ - name: Display minikube start parameters
+ when:
+ - vllm_k8s_type | default('minikube') == 'minikube'
+ - minikube_status.stdout != 'Running'
+ debug:
+ msg: "Starting minikube with {{ minikube_cpus }} CPUs, {{ minikube_memory_mb }}MB RAM, 50GB disk. This may take 5-10 minutes on first run..."
+
+ - name: Start Minikube cluster
+ when:
+ - vllm_k8s_type | default('minikube') == 'minikube'
+ - minikube_status.stdout != 'Running'
+ become: no
+ ansible.builtin.command:
+ cmd: minikube start --driver=docker --cpus={{ minikube_cpus }} --memory={{ minikube_memory_mb }} --disk-size=50g --insecure-registry="{{ ansible_default_ipv4.gateway }}:5000"
+ environment:
+ MINIKUBE_HOME: /data/minikube
+ register: minikube_start
+ changed_when: "'Done!' in minikube_start.stdout"
+ async: 600 # Allow up to 10 minutes
+ poll: 30 # Check every 30 seconds
+
+ - name: Enable GPU support in Minikube (if available)
+ when:
+ - vllm_k8s_type | default('minikube') == 'minikube'
+ - not (vllm_use_cpu_inference | default(false))
+ - vllm_request_gpu | default(1) | int > 0
+ become: no
+ ansible.builtin.command:
+ cmd: minikube addons enable nvidia-gpu-device-plugin
+ ignore_errors: yes
+
+ - name: Disable GPU support in Minikube for CPU inference
+ when:
+ - vllm_k8s_type | default('minikube') == 'minikube'
+ - vllm_use_cpu_inference | default(false)
+ - minikube_status.stdout == 'Running'
+ become: no
+ ansible.builtin.command:
+ cmd: minikube addons disable nvidia-gpu-device-plugin
+ ignore_errors: yes
+
+ - name: Clone vLLM production stack repository
+ git:
+ repo: "{{ vllm_production_stack_repo }}"
+ dest: "{{ vllm_local_path }}/production-stack-repo"
+ version: "{{ vllm_production_stack_version }}"
+ update: yes
+ force: yes
+ when: false # Not needed for production-stack deployment type which uses Helm
+
+ - name: Create results directory
+ file:
+ path: "{{ vllm_results_dir }}"
+ state: directory
+ mode: '0755'
+
+ - name: Generate vLLM deployment manifest
+ template:
+ src: vllm-deployment.yaml.j2
+ dest: "{{ vllm_local_path }}/vllm-deployment.yaml"
+ mode: '0644'
+ when: vllm_deployment_type != "production-stack"
+
+ - name: Deploy vLLM using kubectl
+ become: no
+ ansible.builtin.command:
+ cmd: kubectl apply -f {{ vllm_local_path }}/vllm-deployment.yaml
+ register: kubectl_apply
+ changed_when: "'created' in kubectl_apply.stdout or 'configured' in kubectl_apply.stdout"
+ when: vllm_deployment_type != "production-stack"
+
+ - name: Wait for vLLM pods to be ready
+ become: no
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Pod
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ label_selectors:
+ - app=vllm-server
+ register: pod_list
+ until: pod_list.resources | length > 0 and pod_list.resources | selectattr('status.phase', 'equalto', 'Running') | list | length == pod_list.resources | length
+ retries: 30
+ delay: 10
+ when: vllm_deployment_type != "production-stack"
+
+ - name: Get vLLM service endpoint
+ become: no
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Service
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ name: vllm-service
+ register: vllm_service
+
+ - name: Display vLLM endpoint information
+ debug:
+ msg: |
+ vLLM deployed successfully!
+ {% if vllm_k8s_type | default('minikube') == 'minikube' %}
+ To access the API, run: kubectl port-forward -n {{ vllm_helm_namespace | default('vllm-system') }} svc/vllm-service {{ vllm_api_port | default(8000) }}:8000
+ Then access: http://localhost:{{ vllm_api_port | default(8000) }}/v1/models
+ {% else %}
+ API endpoint: {{ vllm_service.resources[0].status.loadBalancer.ingress[0].ip | default('pending') }}:{{ vllm_api_port | default(8000) }}
+ {% endif %}
+
+- name: vLLM benchmark tasks
+ tags: vllm-benchmark
+ when: vllm_benchmark_enabled | default(true)
+ block:
+ - name: Create benchmark script
+ template:
+ src: vllm-benchmark.py.j2
+ dest: "{{ vllm_local_path }}/benchmark.py"
+ mode: '0755'
+
+ - name: Create benchmark results directory
+ become: yes
+ ansible.builtin.file:
+ path: "{{ vllm_results_dir }}"
+ state: directory
+ mode: '0755'
+ owner: "{{ ansible_user | default('ubuntu') }}"
+ group: "{{ ansible_user | default('ubuntu') }}"
+
+ - name: Set up port forwarding for benchmarking
+ when: vllm_k8s_type | default('minikube') == 'minikube'
+ become: no
+ ansible.builtin.command:
+ cmd: kubectl port-forward -n {{ vllm_helm_namespace | default('vllm-system') }} svc/vllm-service {{ vllm_api_port | default(8000) }}:8000
+ async: 300
+ poll: 0
+ register: port_forward_task
+
+ - name: Wait for port forwarding to be ready
+ when: vllm_k8s_type | default('minikube') == 'minikube'
+ ansible.builtin.wait_for:
+ port: "{{ vllm_api_port | default(8000) }}"
+ host: localhost
+ delay: 2
+ timeout: 30
+
+ - name: Run benchmark
+ become: no
+ ansible.builtin.command:
+ cmd: python3 benchmark.py
+ chdir: "{{ vllm_local_path }}"
+ register: benchmark_output
+ ignore_errors: yes
+
+ - name: Stop port forwarding
+ when:
+ - vllm_k8s_type | default('minikube') == 'minikube'
+ - port_forward_task is defined
+ become: no
+ ansible.builtin.async_status:
+ jid: "{{ port_forward_task.ansible_job_id }}"
+ register: job_result
+ failed_when: false
+
+ - name: Kill port forwarding if still running
+ when:
+ - vllm_k8s_type | default('minikube') == 'minikube'
+ - port_forward_task is defined
+ - job_result.finished is defined
+ - not job_result.finished
+ become: no
+ ansible.builtin.command:
+ cmd: kill {{ port_forward_task.ansible_job_id }}
+ ignore_errors: yes
+
+ - name: Display benchmark results
+ debug:
+ msg: "{{ benchmark_output.stdout }}"
+ when: benchmark_output.stdout is defined
+
+ - name: Collect benchmark results from remote
+ when: benchmark_output.rc == 0
+ fetch:
+ src: "{{ vllm_results_dir }}/benchmark_results.json"
+ dest: "{{ topdir_path }}/workflows/vllm/results/{{ inventory_hostname }}_benchmark_results.json"
+ flat: yes
+ ignore_errors: yes
+
+ - name: Collect system information
+ ansible.builtin.setup:
+ gather_subset:
+ - hardware
+ - virtual
+ register: system_info
+
+ - name: Save system information
+ copy:
+ content: |
+ {
+ "hostname": "{{ inventory_hostname }}",
+ "distribution": "{{ ansible_distribution }}",
+ "distribution_version": "{{ ansible_distribution_version }}",
+ "kernel": "{{ ansible_kernel }}",
+ "processor_count": {{ ansible_processor_count }},
+ "processor_cores": {{ ansible_processor_cores }},
+ "memtotal_mb": {{ ansible_memtotal_mb }},
+ "virtualization_type": "{{ ansible_virtualization_type | default('bare-metal') }}",
+ "virtualization_role": "{{ ansible_virtualization_role | default('host') }}",
+ "date": "{{ ansible_date_time.iso8601 }}"
+ }
+ dest: "{{ vllm_results_dir }}/system_info.json"
+ mode: '0644'
+
+ - name: Collect system information to control host
+ fetch:
+ src: "{{ vllm_results_dir }}/system_info.json"
+ dest: "{{ topdir_path }}/workflows/vllm/results/{{ inventory_hostname }}_system_info.json"
+ flat: yes
+
+- name: vLLM monitoring tasks
+ tags: vllm-monitor
+ when: vllm_observability_enabled | default(true)
+ block:
+ - name: Get Grafana service information
+ become: no
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Service
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ name: vllm-grafana
+ register: grafana_service
+
+ - name: Get Prometheus service information
+ become: no
+ kubernetes.core.k8s_info:
+ api_version: v1
+ kind: Service
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ name: vllm-prometheus
+ register: prometheus_service
+
+ - name: Display monitoring URLs
+ debug:
+ msg: |
+ Monitoring Stack URLs:
+ {% if vllm_k8s_type | default('minikube') == 'minikube' %}
+ Grafana: kubectl port-forward -n {{ vllm_helm_namespace | default('vllm-system') }} svc/vllm-grafana {{ vllm_grafana_port | default(3000) }}:3000
+ Prometheus: kubectl port-forward -n {{ vllm_helm_namespace | default('vllm-system') }} svc/vllm-prometheus {{ vllm_prometheus_port | default(9090) }}:9090
+ {% else %}
+ Grafana: http://{{ grafana_service.resources[0].status.loadBalancer.ingress[0].ip | default('pending') }}:{{ vllm_grafana_port | default(3000) }}
+ Prometheus: http://{{ prometheus_service.resources[0].status.loadBalancer.ingress[0].ip | default('pending') }}:{{ vllm_prometheus_port | default(9090) }}
+ {% endif %}
+
+- name: vLLM cleanup tasks
+ tags: vllm-cleanup
+ block:
+ - name: Delete all resources in vLLM namespace
+ become: no
+ kubernetes.core.k8s:
+ api_version: v1
+ kind: Namespace
+ name: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ state: absent
+ wait: true
+ ignore_errors: yes
+
+ - name: Delete Helm release if exists
+ become: no
+ kubernetes.core.helm:
+ name: "{{ vllm_helm_release_name | default('vllm') }}"
+ namespace: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ state: absent
+ ignore_errors: yes
+
+- name: vLLM teardown tasks
+ tags: vllm-teardown
+ block:
+ - name: Delete vLLM deployment
+ become: no
+ ansible.builtin.command:
+ cmd: kubectl delete -f {{ vllm_local_path }}/vllm-deployment.yaml
+ ignore_errors: yes
+
+ - name: Delete namespace
+ become: no
+ kubernetes.core.k8s:
+ name: "{{ vllm_helm_namespace | default('vllm-system') }}"
+ api_version: v1
+ kind: Namespace
+ state: absent
+ wait: true
+
+ - name: Stop Minikube if configured
+ when: vllm_k8s_type | default('minikube') == 'minikube'
+ become: no
+ ansible.builtin.command:
+ cmd: minikube stop
+ ignore_errors: yes
+
+- name: vLLM results tasks
+ tags: vllm-results
+ block:
+ - name: Check if benchmark results exist
+ stat:
+ path: "{{ vllm_results_dir }}/benchmark_results.json"
+ register: results_file
+
+ - name: Collect benchmark results from remote to control host
+ when: results_file.stat.exists
+ fetch:
+ src: "{{ vllm_results_dir }}/benchmark_results.json"
+ dest: "{{ topdir_path }}/workflows/vllm/results/{{ inventory_hostname }}_benchmark_results.json"
+ flat: yes
+ ignore_errors: yes
+
+ - name: Check if system info exists
+ stat:
+ path: "{{ vllm_results_dir }}/system_info.json"
+ register: sysinfo_file
+
+ - name: Collect system information to control host
+ when: sysinfo_file.stat.exists
+ fetch:
+ src: "{{ vllm_results_dir }}/system_info.json"
+ dest: "{{ topdir_path }}/workflows/vllm/results/{{ inventory_hostname }}_system_info.json"
+ flat: yes
+ ignore_errors: yes
+
+ - name: Read benchmark results
+ when: results_file.stat.exists
+ slurp:
+ src: "{{ vllm_results_dir }}/benchmark_results.json"
+ register: benchmark_data
+
+ - name: Display benchmark results
+ when: results_file.stat.exists
+ debug:
+ msg: |
+ === vLLM Benchmark Results ===
+ {{ benchmark_data.content | b64decode | from_json | to_nice_yaml }}
+
+ - name: No results found
+ when: not results_file.stat.exists
+ debug:
+ msg: "No benchmark results found. Run 'make vllm-benchmark' first."
+
+- name: vLLM visualization tasks
+ tags: vllm-visualize
+ block:
+ - name: Create local results directory
+ file:
+ path: "{{ topdir_path }}/workflows/vllm/results/html"
+ state: directory
+ mode: '0755'
+ delegate_to: localhost
+ become: no
+ run_once: true
+
+ - name: Generate visualization script
+ template:
+ src: vllm-visualize.py.j2
+ dest: "{{ topdir_path }}/workflows/vllm/results/visualize.py"
+ mode: '0755'
+ delegate_to: localhost
+ become: no
+ run_once: true
+
+ - name: Check for collected results
+ find:
+ paths: "{{ topdir_path }}/workflows/vllm/results"
+ patterns: "*_benchmark_results.json"
+ register: result_files
+ delegate_to: localhost
+ become: no
+ run_once: true
+
+ - name: Generate HTML visualization
+ when: result_files.files | length > 0
+ ansible.builtin.command:
+ cmd: python3 visualize.py
+ chdir: "{{ topdir_path }}/workflows/vllm/results"
+ delegate_to: localhost
+ become: no
+ run_once: true
+ register: viz_output
+
+ - name: Display visualization results
+ when: result_files.files | length > 0
+ debug:
+ msg: |
+ Visualization complete!
+ Open the following file in your browser:
+ {{ topdir_path }}/workflows/vllm/results/html/index.html
+
+ - name: No results to visualize
+ when: result_files.files | length == 0
+ debug:
+ msg: "No benchmark results found. Run 'make vllm-benchmark' first to generate data."
diff --git a/playbooks/roles/vllm/tasks/setup-helm.yml b/playbooks/roles/vllm/tasks/setup-helm.yml
new file mode 100644
index 00000000..d059a113
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/setup-helm.yml
@@ -0,0 +1,33 @@
+---
+# Setup Helm for vLLM deployment
+- name: Setup Helm
+ block:
+ - name: Check if helm exists
+ ansible.builtin.stat:
+ path: /usr/local/bin/helm
+ register: helm_stat
+
+ - name: Download Helm installer script
+ when: not helm_stat.stat.exists
+ ansible.builtin.get_url:
+ url: https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
+ dest: /tmp/get-helm-3.sh
+ mode: '0755'
+
+ - name: Install Helm
+ when: not helm_stat.stat.exists
+ ansible.builtin.command:
+ cmd: /tmp/get-helm-3.sh
+ environment:
+ HELM_INSTALL_DIR: /usr/local/bin
+ become: yes
+
+ - name: Verify Helm installation
+ ansible.builtin.command:
+ cmd: helm version --short
+ register: helm_version
+ changed_when: false
+
+ - name: Display Helm version
+ debug:
+ msg: "Helm version: {{ helm_version.stdout }}"
diff --git a/playbooks/roles/vllm/tasks/setup-kubernetes.yml b/playbooks/roles/vllm/tasks/setup-kubernetes.yml
new file mode 100644
index 00000000..c3cde217
--- /dev/null
+++ b/playbooks/roles/vllm/tasks/setup-kubernetes.yml
@@ -0,0 +1,236 @@
+---
+# Setup Kubernetes environment for vLLM deployment
+- name: Setup Kubernetes
+ block:
+ - name: Check if kubectl exists
+ ansible.builtin.stat:
+ path: /usr/local/bin/kubectl
+ register: kubectl_stat
+
+ - name: Get latest kubectl version
+ when: not kubectl_stat.stat.exists
+ ansible.builtin.uri:
+ url: https://dl.k8s.io/release/stable.txt
+ return_content: yes
+ register: kubectl_version
+
+ - name: Download kubectl
+ when: not kubectl_stat.stat.exists
+ ansible.builtin.get_url:
+ url: "https://dl.k8s.io/release/{{ kubectl_version.content | trim }}/bin/linux/amd64/kubectl"
+ dest: /tmp/kubectl
+ mode: '0755'
+
+ - name: Install kubectl
+ when: not kubectl_stat.stat.exists
+ ansible.builtin.copy:
+ src: /tmp/kubectl
+ dest: /usr/local/bin/kubectl
+ mode: '0755'
+ remote_src: yes
+ become: yes
+
+ # Minikube setup
+ - name: Setup Minikube
+ when: vllm_k8s_minikube | default(false)
+ block:
+ - name: Check if minikube exists
+ ansible.builtin.stat:
+ path: /usr/local/bin/minikube
+ register: minikube_stat
+
+ - name: Download minikube
+ when: not minikube_stat.stat.exists
+ ansible.builtin.get_url:
+ url: https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
+ dest: /tmp/minikube
+ mode: '0755'
+
+ - name: Install minikube
+ when: not minikube_stat.stat.exists
+ ansible.builtin.copy:
+ src: /tmp/minikube
+ dest: /usr/local/bin/minikube
+ mode: '0755'
+ remote_src: yes
+ become: yes
+
+ # Install crictl for none driver support
+ - name: Check if crictl exists
+ ansible.builtin.stat:
+ path: /usr/local/bin/crictl
+ register: crictl_stat
+
+ - name: Get latest crictl version
+ when: not crictl_stat.stat.exists
+ ansible.builtin.uri:
+ url: https://api.github.com/repos/kubernetes-sigs/cri-tools/releases/latest
+ return_content: yes
+ register: crictl_release
+
+ - name: Download crictl
+ when: not crictl_stat.stat.exists
+ ansible.builtin.get_url:
+ url: "https://github.com/kubernetes-sigs/cri-tools/releases/download/{{ crictl_release.json.tag_name }}/crictl-{{ crictl_release.json.tag_name }}-linux-amd64.tar.gz"
+ dest: /tmp/crictl.tar.gz
+
+ - name: Extract and install crictl
+ when: not crictl_stat.stat.exists
+ ansible.builtin.unarchive:
+ src: /tmp/crictl.tar.gz
+ dest: /usr/local/bin/
+ mode: '0755'
+ remote_src: yes
+ become: yes
+
+ - name: Check if minikube is running
+ ansible.builtin.command:
+ cmd: minikube status
+ register: minikube_status
+ failed_when: false
+ changed_when: false
+ environment:
+ MINIKUBE_HOME: /data/minikube
+
+ - name: Check if minikube container exists but is stopped
+ when: minikube_status.rc != 0
+ ansible.builtin.command:
+ cmd: docker ps -a --format "table {% raw %}{{.Names}}\t{{.Status}}{% endraw %}" | grep minikube || true
+ register: minikube_container
+ failed_when: false
+ changed_when: false
+
+ - name: Clean up stopped minikube container if exists
+ when:
+ - minikube_status.rc != 0
+ - "'minikube' in minikube_container.stdout"
+ ansible.builtin.command:
+ cmd: minikube delete --all --purge
+ environment:
+ MINIKUBE_HOME: /data/minikube
+ ignore_errors: yes
+
+ - name: Fix minikube permissions
+ ansible.builtin.file:
+ path: /root/.minikube
+ state: directory
+ mode: '0755'
+ owner: "{{ ansible_user_id | default('root') }}"
+ recurse: yes
+ become: yes
+ ignore_errors: yes
+
+ - name: Ensure /tmp has correct permissions
+ ansible.builtin.file:
+ path: /tmp
+ state: directory
+ mode: '1777'
+ owner: root
+ group: root
+ become: yes
+
+ - name: Apply sysctl setting for minikube
+ ansible.builtin.sysctl:
+ name: fs.protected_regular
+ value: '0'
+ state: present
+ reload: yes
+ become: yes
+ ignore_errors: yes
+
+ - name: Check current user for minikube driver selection
+ ansible.builtin.command:
+ cmd: whoami
+ register: current_user
+ changed_when: false
+
+ - name: Ensure kdevops user is in docker group
+ ansible.builtin.user:
+ name: kdevops
+ groups: docker
+ append: yes
+ become: yes
+
+ - name: Ensure /data/minikube has correct permissions for minikube
+ ansible.builtin.file:
+ path: /data/minikube
+ state: directory
+ owner: kdevops
+ group: docker
+ mode: '0775'
+ recurse: yes
+ become: yes
+
+ - name: Start minikube with appropriate resources
+ when: minikube_status.rc != 0
+ ansible.builtin.command:
+ cmd: >-
+ minikube start
+ --driver=docker
+ --force
+ --cpus={{ [ansible_processor_vcpus | default(4), 32] | min }}
+ --memory={{ [(ansible_memtotal_mb * 0.75) | int, 49152] | min }}
+ --disk-size=50g
+ --delete-on-failure=true
+ environment:
+ MINIKUBE_HOME: /data/minikube
+ register: minikube_start
+
+ - name: Wait for minikube to be ready
+ ansible.builtin.command:
+ cmd: minikube status
+ register: minikube_ready
+ until: minikube_ready.rc == 0
+ retries: 10
+ delay: 10
+ environment:
+ MINIKUBE_HOME: /data/minikube
+
+ - name: Enable minikube addons
+ ansible.builtin.command:
+ cmd: "minikube addons enable {{ item }}"
+ loop:
+ - metrics-server
+ - ingress
+ - storage-provisioner
+ environment:
+ MINIKUBE_HOME: /data/minikube
+ changed_when: false
+ register: addon_result
+ until: addon_result.rc == 0
+ retries: 3
+ delay: 5
+
+ # Existing cluster verification
+ - name: Verify existing Kubernetes cluster
+ when: vllm_k8s_existing | default(false)
+ block:
+ - name: Check kubectl connectivity
+ ansible.builtin.command:
+ cmd: kubectl cluster-info
+ register: cluster_info
+ failed_when: cluster_info.rc != 0
+
+ - name: Display cluster information
+ debug:
+ msg: "{{ cluster_info.stdout }}"
+
+ - name: Check for GPU support in cluster
+ when: not (vllm_use_cpu_inference | default(true))
+ ansible.builtin.command:
+ cmd: kubectl get nodes -o json
+ register: nodes_json
+ changed_when: false
+
+ - name: Verify GPU resources available
+ when: not (vllm_use_cpu_inference | default(true))
+ set_fact:
+ cluster_has_gpu: "{{ nodes_json.stdout | from_json | json_query('items[*].status.capacity.\"nvidia.com/gpu\"') | select | list | length > 0 }}"
+
+ - name: Warn if no GPU resources found
+ when: not (vllm_use_cpu_inference | default(true)) and not cluster_has_gpu | default(false)
+ debug:
+ msg: |
+ WARNING: No GPU resources found in the cluster.
+ The deployment will proceed but GPU acceleration won't be available.
+ Consider using CPU inference mode or adding GPU nodes to your cluster.
diff --git a/playbooks/roles/vllm/templates/vllm-benchmark.py.j2 b/playbooks/roles/vllm/templates/vllm-benchmark.py.j2
new file mode 100644
index 00000000..b25aaae3
--- /dev/null
+++ b/playbooks/roles/vllm/templates/vllm-benchmark.py.j2
@@ -0,0 +1,152 @@
+#!/usr/bin/env python3
+import asyncio
+import aiohttp
+import time
+import json
+import sys
+from typing import List, Dict
+import numpy as np
+
+
+async def send_request(session, url, prompt, max_tokens=100):
+ payload = {
+ "model": "{{ vllm_model_url | default('facebook/opt-125m') }}",
+ "prompt": prompt,
+ "max_tokens": max_tokens,
+ "temperature": 0.7,
+ }
+
+ start_time = time.time()
+ try:
+ async with session.post(f"{url}/v1/completions", json=payload) as response:
+ latency = time.time() - start_time
+ if response.status == 200:
+ result = await response.json()
+ return {
+ "success": True,
+ "latency": latency,
+ "tokens": len(
+ result.get("choices", [{}])[0].get("text", "").split()
+ ),
+ "status": response.status,
+ }
+ else:
+ text = await response.text()
+ return {
+ "success": False,
+ "latency": latency,
+ "error": f"HTTP {response.status}: {text}",
+ "status": response.status,
+ }
+ except Exception as e:
+ return {
+ "success": False,
+ "latency": time.time() - start_time,
+ "error": str(e),
+ "status": None,
+ }
+
+
+async def run_benchmark(url: str, num_requests: int, concurrent_users: int):
+ prompts = [
+ "What is machine learning?",
+ "Explain quantum computing in simple terms.",
+ "How does the internet work?",
+ "What are the benefits of renewable energy?",
+ "Describe the process of photosynthesis.",
+ ]
+
+ results = []
+ async with aiohttp.ClientSession() as session:
+ tasks = []
+ for i in range(num_requests):
+ prompt = prompts[i % len(prompts)]
+ task = send_request(session, url, prompt)
+ tasks.append(task)
+
+ if len(tasks) >= concurrent_users:
+ batch_results = await asyncio.gather(*tasks)
+ results.extend(batch_results)
+ tasks = []
+
+ if tasks:
+ batch_results = await asyncio.gather(*tasks)
+ results.extend(batch_results)
+
+ return results
+
+
+async def main():
+ url = "http://localhost:{{ vllm_api_port | default(8000) }}"
+ duration = {{vllm_benchmark_duration | default(60)}}
+ concurrent_users = {{vllm_benchmark_concurrent_users | default(10)}}
+
+ print(
+ f"Running benchmark for {duration} seconds with {concurrent_users} concurrent users..."
+ )
+
+ start_time = time.time()
+ total_requests = 0
+ all_results = []
+
+ while time.time() - start_time < duration:
+ batch_size = concurrent_users * 10
+ results = await run_benchmark(url, batch_size, concurrent_users)
+ all_results.extend(results)
+ total_requests += batch_size
+
+ elapsed = time.time() - start_time
+ if elapsed > 0:
+ print(
+ f"Progress: {elapsed:.1f}s, Requests: {total_requests}, RPS: {total_requests/elapsed:.2f}"
+ )
+
+ # Calculate statistics
+ successful = [r for r in all_results if r.get("success", False)]
+ failed = [r for r in all_results if not r.get("success", False)]
+
+ print(
+ f"\nSummary: {len(successful)} successful, {len(failed)} failed out of {len(all_results)} total"
+ )
+
+ if failed:
+ print("Sample failures:")
+ for failure in failed[:3]: # Show first 3 failures
+ print(f" Error: {failure.get('error', 'Unknown')}")
+
+ if successful:
+ latencies = [r["latency"] for r in successful]
+ p50 = np.percentile(latencies, 50)
+ p95 = np.percentile(latencies, 95)
+ p99 = np.percentile(latencies, 99)
+
+ results_summary = {
+ "total_requests": len(all_results),
+ "successful_requests": len(successful),
+ "failed_requests": len(all_results) - len(successful),
+ "duration_seconds": time.time() - start_time,
+ "requests_per_second": len(all_results) / (time.time() - start_time),
+ "latency_p50_ms": p50 * 1000,
+ "latency_p95_ms": p95 * 1000,
+ "latency_p99_ms": p99 * 1000,
+ "mean_latency_ms": np.mean(latencies) * 1000,
+ }
+
+ print("\n=== Benchmark Results ===")
+ for key, value in results_summary.items():
+ print(
+ f"{key}: {value:.2f}" if isinstance(value, float) else f"{key}: {value}"
+ )
+
+ # Save results
+ with open("{{ vllm_results_dir }}/benchmark_results.json", "w") as f:
+ json.dump(results_summary, f, indent=2)
+
+ print(f"\nResults saved to {{ vllm_results_dir }}/benchmark_results.json")
+ else:
+ print("No successful requests completed!")
+ sys.exit(1)
+
+
+if __name__ == "__main__":
+ asyncio.run(main())
diff --git a/playbooks/roles/vllm/templates/vllm-container.service.j2 b/playbooks/roles/vllm/templates/vllm-container.service.j2
new file mode 100644
index 00000000..54ddb747
--- /dev/null
+++ b/playbooks/roles/vllm/templates/vllm-container.service.j2
@@ -0,0 +1,80 @@
+[Unit]
+Description=vLLM Container Service
+Documentation=https://docs.vllm.ai
+After=network.target {{ container_runtime | default('docker') }}.service
+Requires={{ container_runtime | default('docker') }}.service
+
+[Service]
+Type=simple
+Restart=always
+RestartSec=10
+User={{ ansible_user_id }}
+Group={{ ansible_user_gid }}
+
+# Environment variables
+Environment="MODEL={{ vllm_model_url | default('facebook/opt-125m') }}"
+Environment="PORT={{ vllm_api_port | default(8000) }}"
+Environment="MAX_MODEL_LEN={{ vllm_max_model_len | default(2048) }}"
+{% if vllm_hf_token is defined and vllm_hf_token %}
+Environment="HF_TOKEN={{ vllm_hf_token }}"
+{% endif %}
+{% if vllm_api_key is defined and vllm_api_key %}
+Environment="VLLM_API_KEY={{ vllm_api_key }}"
+{% endif %}
+
+# Container command
+{% if container_runtime | default('docker') == 'docker' %}
+ExecStartPre=/usr/bin/{{ container_runtime }} pull {{ 'substratusai/vllm:v0.6.3-cpu' if not has_nvidia_gpu else 'vllm/vllm-openai:latest' }}
+ExecStart=/usr/bin/{{ container_runtime }} run --rm \
+ --name {{ vllm_bare_metal_service_name | default('vllm') }} \
+ -p {{ vllm_api_port | default(8000) }}:8000 \
+ -v {{ vllm_bare_metal_data_dir | default('/var/lib/vllm') }}:/data \
+ -v {{ vllm_bare_metal_log_dir | default('/var/log/vllm') }}:/logs \
+ {% if has_nvidia_gpu %}--gpus all {% endif %}\
+ {% if vllm_hf_token is defined and vllm_hf_token %}-e HF_TOKEN=${HF_TOKEN} {% endif %}\
+ {% if vllm_api_key is defined and vllm_api_key %}-e VLLM_API_KEY=${VLLM_API_KEY} {% endif %}\
+ {{ 'substratusai/vllm:v0.6.3-cpu' if not has_nvidia_gpu else 'vllm/vllm-openai:latest' }} \
+ --model ${MODEL} \
+ --host 0.0.0.0 \
+ --port 8000 \
+ --max-model-len ${MAX_MODEL_LEN} \
+ {% if not has_nvidia_gpu %}--device cpu --dtype float32 {% endif %}\
+ {% if has_nvidia_gpu %}--tensor-parallel-size {{ vllm_tensor_parallel_size | default(1) }} {% endif %}\
+ {% if has_nvidia_gpu %}--gpu-memory-utilization {{ vllm_gpu_memory_utilization | default('0.9') }} {% endif %}\
+ {% if vllm_enable_prefix_caching | default(false) %}--enable-prefix-caching {% endif %}\
+ {% if vllm_enable_chunked_prefill | default(false) %}--enable-chunked-prefill {% endif %}\
+ --download-dir {{ vllm_bare_metal_data_dir | default('/var/lib/vllm') }}/models
+
+ExecStop=/usr/bin/{{ container_runtime }} stop {{ vllm_bare_metal_service_name | default('vllm') }}
+{% else %}
+# Podman support
+ExecStartPre=/usr/bin/podman pull {{ 'substratusai/vllm:v0.6.3-cpu' if not has_nvidia_gpu else 'vllm/vllm-openai:latest' }}
+ExecStart=/usr/bin/podman run --rm \
+ --name {{ vllm_bare_metal_service_name | default('vllm') }} \
+ -p {{ vllm_api_port | default(8000) }}:8000 \
+ -v {{ vllm_bare_metal_data_dir | default('/var/lib/vllm') }}:/data:Z \
+ -v {{ vllm_bare_metal_log_dir | default('/var/log/vllm') }}:/logs:Z \
+ {% if has_nvidia_gpu %}--device nvidia.com/gpu=all {% endif %}\
+ {% if vllm_hf_token is defined and vllm_hf_token %}-e HF_TOKEN=${HF_TOKEN} {% endif %}\
+ {% if vllm_api_key is defined and vllm_api_key %}-e VLLM_API_KEY=${VLLM_API_KEY} {% endif %}\
+ {{ 'substratusai/vllm:v0.6.3-cpu' if not has_nvidia_gpu else 'vllm/vllm-openai:latest' }} \
+ --model ${MODEL} \
+ --host 0.0.0.0 \
+ --port 8000 \
+ --max-model-len ${MAX_MODEL_LEN} \
+ {% if not has_nvidia_gpu %}--device cpu --dtype float32 {% endif %}\
+ {% if has_nvidia_gpu %}--tensor-parallel-size {{ vllm_tensor_parallel_size | default(1) }} {% endif %}\
+ {% if has_nvidia_gpu %}--gpu-memory-utilization {{ vllm_gpu_memory_utilization | default('0.9') }} {% endif %}\
+ {% if vllm_enable_prefix_caching | default(false) %}--enable-prefix-caching {% endif %}\
+ {% if vllm_enable_chunked_prefill | default(false) %}--enable-chunked-prefill {% endif %}\
+ --download-dir {{ vllm_bare_metal_data_dir | default('/var/lib/vllm') }}/models
+
+ExecStop=/usr/bin/podman stop {{ vllm_bare_metal_service_name | default('vllm') }}
+{% endif %}
+
+# Resource limits
+LimitNOFILE=65536
+LimitNPROC=4096
+
+[Install]
+WantedBy=multi-user.target
diff --git a/playbooks/roles/vllm/templates/vllm-deployment.yaml.j2 b/playbooks/roles/vllm/templates/vllm-deployment.yaml.j2
new file mode 100644
index 00000000..88e1d5ce
--- /dev/null
+++ b/playbooks/roles/vllm/templates/vllm-deployment.yaml.j2
@@ -0,0 +1,94 @@
+---
+apiVersion: v1
+kind: Namespace
+metadata:
+ name: {{ vllm_helm_namespace | default('vllm-system') }}
+---
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: vllm-server
+ namespace: {{ vllm_helm_namespace | default('vllm-system') }}
+spec:
+ replicas: {{ vllm_replica_count | default(1) }}
+ selector:
+ matchLabels:
+ app: vllm-server
+ template:
+ metadata:
+ labels:
+ app: vllm-server
+ spec:
+ containers:
+ - name: vllm
+ image: {{ vllm_docker_image_final | default('vllm/vllm-openai:latest') }}
+{% if vllm_use_cpu_inference | default(false) %}
+ env:
+ - name: VLLM_CPU_ONLY
+ value: "1"
+{% endif %}
+ args:
+ - "--model"
+ - "{{ vllm_model_url | default('facebook/opt-125m') }}"
+ - "--host"
+ - "0.0.0.0"
+ - "--port"
+ - "8000"
+ - "--max-model-len"
+ - "512"
+{% if vllm_use_cpu_inference | default(false) %}
+ - "--device"
+ - "cpu"
+ - "--dtype"
+ - "float32"
+ - "--swap-space"
+ - "0"
+ - "--block-size"
+ - "16"
+{% else %}
+ - "--dtype"
+ - "{{ vllm_dtype | default('auto') }}"
+ - "--tensor-parallel-size"
+ - "{{ vllm_tensor_parallel_size | default(1) | string }}"
+{% endif %}
+{% if vllm_hf_token is defined and vllm_hf_token %}
+ - "--hf-token"
+ - "{{ vllm_hf_token }}"
+{% endif %}
+ ports:
+ - containerPort: 8000
+ name: http
+ resources:
+ requests:
+{% if vllm_use_cpu_inference | default(false) %}
+ cpu: 2
+ memory: 4Gi
+{% else %}
+ cpu: {{ vllm_request_cpu | default(4) }}
+ memory: {{ vllm_request_memory | default('16Gi') }}
+ nvidia.com/gpu: {{ vllm_request_gpu | default(1) }}
+{% endif %}
+ limits:
+{% if vllm_use_cpu_inference | default(false) %}
+ cpu: 2
+ memory: 4Gi
+{% else %}
+ cpu: {{ vllm_request_cpu | default(4) }}
+ memory: {{ vllm_request_memory | default('16Gi') }}
+ nvidia.com/gpu: {{ vllm_request_gpu | default(1) }}
+{% endif %}
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: vllm-service
+ namespace: {{ vllm_helm_namespace | default('vllm-system') }}
+spec:
+ selector:
+ app: vllm-server
+ ports:
+ - port: {{ vllm_api_port | default(8000) }}
+ targetPort: 8000
+ protocol: TCP
+ name: http
+ type: ClusterIP
diff --git a/playbooks/roles/vllm/templates/vllm-helm-values.yaml.j2 b/playbooks/roles/vllm/templates/vllm-helm-values.yaml.j2
new file mode 100644
index 00000000..378511d6
--- /dev/null
+++ b/playbooks/roles/vllm/templates/vllm-helm-values.yaml.j2
@@ -0,0 +1,63 @@
+servingEngineSpec:
+ enableEngine: true
+ modelSpec:
+ - name: "{{ vllm_model_name | default('opt-125m') }}"
+{% if vllm_use_cpu_inference | default(false) %}
+ # Using third-party CPU image until official CPU image is available
+ repository: substratusai/vllm
+ tag: v0.6.3-cpu
+{% else %}
+ repository: vllm/vllm-openai
+ tag: latest
+{% endif %}
+ modelURL: "{{ vllm_model_url | default('facebook/opt-125m') }}"
+ replicaCount: {{ vllm_replica_count | default(1) }}
+ requestCPU: {{ vllm_request_cpu | default(4) }}
+ requestMemory: "{{ vllm_request_memory | default('16Gi') }}"
+ requestGPU: {{ vllm_request_gpu | default(0 if vllm_use_cpu_inference else 1) }}
+{% if vllm_gpu_type is defined and vllm_gpu_type and not (vllm_use_cpu_inference | default(false)) %}
+ requestGPUType: "{{ vllm_gpu_type }}"
+{% endif %}
+{% if vllm_use_cpu_inference | default(false) %}
+ runtimeClassName: "" # Explicitly disable GPU runtime for CPU inference
+{% endif %}
+ vllmConfig:
+ maxModelLen: {{ vllm_max_model_len | default(2048) }}
+{% if vllm_use_cpu_inference | default(false) %}
+ device: "cpu"
+ dtype: "float32"
+ tensorParallelSize: 1
+{% else %}
+ dtype: "{{ vllm_dtype | default('auto') }}"
+ tensorParallelSize: {{ vllm_tensor_parallel_size | default(1) }}
+ gpuMemoryUtilization: {{ vllm_gpu_memory_utilization | default('0.9') }}
+{% endif %}
+ enablePrefixCaching: {{ vllm_enable_prefix_caching | default(false) | lower }}
+ enableChunkedPrefill: {{ vllm_enable_chunked_prefill | default(false) | lower }}
+{% if vllm_lmcache_enabled | default(false) %}
+ lmcacheConfig:
+ enabled: true
+ cpuOffloadingBufferSize: "{{ vllm_lmcache_cpu_buffer_size | default('30') }}"
+{% endif %}
+{% if vllm_hf_token is defined and vllm_hf_token %}
+ hf_token: "{{ vllm_hf_token }}"
+{% endif %}
+{% if vllm_api_key is defined and vllm_api_key %}
+ vllmApiKey: "{{ vllm_api_key }}"
+{% endif %}
+
+{% if vllm_router_enabled | default(true) %}
+router:
+ enabled: true
+ routingAlgorithm: "{{ vllm_router_algorithm | default('round_robin') }}"
+{% endif %}
+
+{% if vllm_observability_enabled | default(true) %}
+observability:
+ prometheus:
+ enabled: true
+ port: {{ vllm_prometheus_port | default(9090) }}
+ grafana:
+ enabled: true
+ port: {{ vllm_grafana_port | default(3000) }}
+{% endif %}
diff --git a/playbooks/roles/vllm/templates/vllm-prod-stack-official-values.yaml.j2 b/playbooks/roles/vllm/templates/vllm-prod-stack-official-values.yaml.j2
new file mode 100644
index 00000000..0df9fa2a
--- /dev/null
+++ b/playbooks/roles/vllm/templates/vllm-prod-stack-official-values.yaml.j2
@@ -0,0 +1,154 @@
+# vLLM Production Stack Official Helm Chart values
+# Generated by kdevops for github.com/vllm-project/production-stack
+
+# Serving engine configuration
+servingEngineSpec:
+ enableEngine: true
+ labels:
+ environment: "vllm"
+ release: "vllm"
+
+ # Runtime configuration - leave empty to use default
+ runtimeClassName: ""
+
+ # Model specifications - array format required by official chart
+ modelSpec:
+ - name: "{{ vllm_model_name | default('opt-125m') }}"
+ # Use CPU-specific image for CPU inference, GPU image otherwise
+ # For CPU: openeuler/vllm-cpu:latest (pre-built CPU image)
+ # For GPU: vllm/vllm-openai:v0.10.2 (official GPU image)
+ # Uses Docker mirror when available for faster deployments
+ repository: "{{ vllm_engine_image_final | default(vllm_engine_image_repo | default('openeuler/vllm-cpu' if vllm_use_cpu_inference else 'vllm/vllm-openai')) }}"
+ tag: "{{ vllm_engine_image_tag | default('latest' if vllm_use_cpu_inference else 'v0.10.2') }}"
+ modelURL: "{{ vllm_model_url | default('facebook/opt-125m') }}"
+ replicaCount: {{ vllm_replica_count | default(2) }}
+
+ # Resource requests - conservative for CPU inference to fit in available resources
+ requestCPU: {{ vllm_request_cpu | default(16 if vllm_use_cpu_inference else 4) }}
+ requestMemory: "{{ vllm_request_memory | default('16Gi' if vllm_use_cpu_inference else '16Gi') }}"
+{% if not vllm_use_cpu_inference | default(false) %}
+ requestGPU: {{ vllm_request_gpu | default(1) }}
+{% if vllm_gpu_type | default('') %}
+ requestGPUType: "{{ vllm_gpu_type }}"
+{% endif %}
+{% else %}
+ requestGPU: 0
+{% endif %}
+
+ # Resource limits (optional, but recommended)
+ limitCPU: {{ (vllm_request_cpu | default(16 if vllm_use_cpu_inference else 4)) * 1.5 | int }}
+ limitMemory: "{{ vllm_limit_memory | default('24Gi' if vllm_use_cpu_inference else '20Gi') }}"
+
+ # Storage configuration - disabled for minikube/testing environments
+{% if vllm_enable_model_cache | default(true) and not (vllm_k8s_minikube | default(false)) %}
+ pvcStorage: "{{ vllm_model_cache_size | default('50Gi') }}"
+ pvcAccessMode: ["ReadWriteOnce"]
+ storageClass: "{{ vllm_storage_class | default('') }}"
+{% endif %}
+
+ # vLLM specific configuration - optimized for CPU or GPU
+ vllmConfig:
+ maxModelLen: {{ vllm_max_model_len | default(2048) }}
+{% if vllm_use_cpu_inference | default(false) %}
+ # CPU-specific settings
+ dtype: "float32" # CPU requires float32
+ device: "cpu"
+ tensorParallelSize: 1 # CPU doesn't support tensor parallelism
+{% else %}
+ # GPU-specific settings
+ dtype: "{{ vllm_dtype | default('auto') }}"
+ tensorParallelSize: {{ vllm_tensor_parallel_size | default(1) }}
+ gpuMemoryUtilization: {{ vllm_gpu_memory_utilization | default('0.9') }}
+{% endif %}
+ # Add extra arguments
+ extraArgs:
+ - "--disable-log-requests"
+{% if vllm_use_cpu_inference | default(false) %}
+ - "--device"
+ - "cpu"
+ - "--dtype"
+ - "float32"
+{% endif %}
+
+{% if vllm_enable_lmcache | default(false) %}
+ # LMCache configuration for KV cache offloading
+ lmcacheConfig:
+ enabled: true
+ cpuOffloadingBufferSize: "{{ vllm_lmcache_buffer_size | default('30') }}"
+{% endif %}
+
+# Router configuration
+routerSpec:
+ enabled: {{ vllm_router_enabled | default(true) | lower }}
+{% if vllm_router_enabled | default(true) %}
+ labels:
+ environment: "vllm"
+ release: "vllm"
+
+ # Use the official production stack router
+ # Uses Docker mirror when available for faster deployments
+ repository: "{{ vllm_router_image_final | default(vllm_prod_stack_router_image | default('ghcr.io/vllm-project/production-stack/router')) }}"
+ tag: "{{ vllm_prod_stack_router_tag | default('latest') }}"
+ replicaCount: {{ vllm_router_replica_count | default(1) }}
+
+ # Router resources
+ requestCPU: {{ vllm_router_request_cpu | default(2) }}
+ requestMemory: "{{ vllm_router_request_memory | default('4Gi') }}"
+ limitCPU: {{ vllm_router_limit_cpu | default(4) }}
+ limitMemory: "{{ vllm_router_limit_memory | default('8Gi') }}"
+
+ # Routing configuration
+ algorithm: "{{ vllm_router_algorithm | default('round_robin') }}"
+{% if vllm_router_session_affinity | default(false) %}
+ sessionAffinity: true
+ sessionAffinityTimeout: {{ vllm_router_session_timeout | default(3600) }}
+{% endif %}
+{% endif %}
+
+# Service configuration
+service:
+ type: {{ vllm_service_type | default('ClusterIP') }}
+ port: {{ vllm_api_port | default(8000) }}
+{% if vllm_service_type | default('ClusterIP') == 'LoadBalancer' %}
+ annotations:
+ service.beta.kubernetes.io/aws-load-balancer-type: "nlb"
+{% endif %}
+
+# Monitoring configuration (if supported by the chart)
+{% if vllm_prod_stack_enable_monitoring | default(true) %}
+monitoring:
+ enabled: true
+ prometheus:
+ enabled: true
+ retention: "{{ vllm_prometheus_retention | default('7d') }}"
+ resources:
+ requests:
+ cpu: 1
+ memory: 2Gi
+ limits:
+ cpu: 2
+ memory: 4Gi
+
+ grafana:
+ enabled: true
+ adminPassword: "{{ vllm_grafana_admin_password | default('admin') }}"
+ resources:
+ requests:
+ cpu: 500m
+ memory: 512Mi
+ limits:
+ cpu: 1
+ memory: 1Gi
+{% endif %}
+
+# Autoscaling configuration
+{% if vllm_prod_stack_enable_autoscaling | default(false) %}
+autoscaling:
+ enabled: true
+ minReplicas: {{ vllm_prod_stack_min_replicas | default(1) }}
+ maxReplicas: {{ vllm_prod_stack_max_replicas | default(5) }}
+ targetCPUUtilizationPercentage: {{ vllm_prod_stack_target_cpu | default(80) }}
+{% if not vllm_use_cpu_inference | default(false) %}
+ targetGPUUtilizationPercentage: {{ vllm_prod_stack_target_gpu_utilization | default(80) }}
+{% endif %}
+{% endif %}
diff --git a/playbooks/roles/vllm/templates/vllm-upstream-values.yaml.j2 b/playbooks/roles/vllm/templates/vllm-upstream-values.yaml.j2
new file mode 100644
index 00000000..9d08a58d
--- /dev/null
+++ b/playbooks/roles/vllm/templates/vllm-upstream-values.yaml.j2
@@ -0,0 +1,151 @@
+# vLLM Production Stack Helm values
+# Generated by kdevops
+
+# Router configuration
+router:
+ enabled: {{ vllm_router_enabled | default(true) | lower }}
+ image:
+ repository: "{{ vllm_prod_stack_router_image | default('ghcr.io/vllm-project/production-stack/router') }}"
+ tag: "{{ vllm_prod_stack_router_tag | default('latest') }}"
+ replicaCount: 1
+ algorithm: "{{ vllm_router_algorithm | default('round_robin') }}"
+ resources:
+ requests:
+ cpu: 2
+ memory: 4Gi
+ limits:
+ cpu: 4
+ memory: 8Gi
+
+# vLLM Engine configuration
+engine:
+ replicaCount: {{ vllm_replica_count | default(1) }}
+ image:
+{% if vllm_use_cpu_inference | default(false) %}
+ repository: substratusai/vllm
+ tag: v0.6.3-cpu
+{% else %}
+ repository: vllm/vllm-openai
+ tag: latest
+{% endif %}
+
+ model:
+ name: "{{ vllm_model_name | default('opt-125m') }}"
+ url: "{{ vllm_model_url | default('facebook/opt-125m') }}"
+{% if vllm_hf_token is defined and vllm_hf_token %}
+ hf_token: "{{ vllm_hf_token }}"
+{% endif %}
+
+ resources:
+ requests:
+ cpu: {{ vllm_request_cpu | default(8 if vllm_use_cpu_inference else 4) }}
+ memory: "{{ vllm_request_memory | default('32Gi' if vllm_use_cpu_inference else '16Gi') }}"
+{% if not vllm_use_cpu_inference | default(false) %}
+ nvidia.com/gpu: {{ vllm_request_gpu | default(1) }}
+{% endif %}
+ limits:
+ cpu: {{ vllm_request_cpu * 2 | default(16 if vllm_use_cpu_inference else 8) }}
+ memory: "{{ vllm_request_memory | default('32Gi' if vllm_use_cpu_inference else '16Gi') }}"
+{% if not vllm_use_cpu_inference | default(false) %}
+ nvidia.com/gpu: {{ vllm_request_gpu | default(1) }}
+{% endif %}
+
+ vllmConfig:
+ maxModelLen: {{ vllm_max_model_len | default(2048) }}
+{% if vllm_use_cpu_inference | default(false) %}
+ device: "cpu"
+ dtype: "float32"
+ tensorParallelSize: 1
+{% else %}
+ dtype: "{{ vllm_dtype | default('auto') }}"
+ tensorParallelSize: {{ vllm_tensor_parallel_size | default(1) }}
+ gpuMemoryUtilization: {{ vllm_gpu_memory_utilization | default('0.9') }}
+{% endif %}
+ enablePrefixCaching: {{ vllm_enable_prefix_caching | default(false) | lower }}
+ enableChunkedPrefill: {{ vllm_enable_chunked_prefill | default(false) | lower }}
+
+# LMCache configuration
+{% if vllm_lmcache_enabled | default(false) %}
+lmcache:
+ enabled: true
+ cpuOffloadingBufferSize: "{{ vllm_lmcache_cpu_buffer_size | default('30') }}"
+{% else %}
+lmcache:
+ enabled: false
+{% endif %}
+
+# Monitoring configuration
+{% if vllm_prod_stack_enable_monitoring | default(true) %}
+monitoring:
+ enabled: true
+ prometheus:
+ enabled: true
+ retention: 7d
+ resources:
+ requests:
+ cpu: 1
+ memory: 2Gi
+ limits:
+ cpu: 2
+ memory: 4Gi
+
+ grafana:
+ enabled: true
+ adminPassword: "{{ vllm_grafana_admin_password | default('admin') }}"
+ resources:
+ requests:
+ cpu: 500m
+ memory: 512Mi
+ limits:
+ cpu: 1
+ memory: 1Gi
+
+ # Pre-configured dashboards
+ dashboards:
+ - vllm-overview
+ - vllm-performance
+ - vllm-requests
+ - vllm-gpu-metrics
+{% else %}
+monitoring:
+ enabled: false
+{% endif %}
+
+# Autoscaling configuration
+{% if vllm_prod_stack_enable_autoscaling | default(false) %}
+autoscaling:
+ enabled: true
+ minReplicas: {{ vllm_prod_stack_min_replicas | default(1) }}
+ maxReplicas: {{ vllm_prod_stack_max_replicas | default(5) }}
+ targetGPUUtilization: {{ vllm_prod_stack_target_gpu_utilization | default(80) }}
+{% else %}
+autoscaling:
+ enabled: false
+{% endif %}
+
+# Service configuration
+service:
+ type: {{ 'LoadBalancer' if vllm_k8s_existing | default(false) else 'ClusterIP' }}
+ port: {{ vllm_api_port | default(8000) }}
+{% if vllm_api_key is defined and vllm_api_key %}
+ apiKey: "{{ vllm_api_key }}"
+{% endif %}
+
+# Persistence
+persistence:
+ enabled: true
+ storageClass: {{ vllm_storage_class | default('') }}
+ modelCache:
+ size: 100Gi
+ path: /models
+
+# Node affinity for GPU nodes
+{% if not vllm_use_cpu_inference | default(false) %}
+nodeSelector:
+ nvidia.com/gpu: "true"
+
+tolerations:
+ - key: nvidia.com/gpu
+ operator: Exists
+ effect: NoSchedule
+{% endif %}
diff --git a/playbooks/roles/vllm/templates/vllm-visualize.py.j2 b/playbooks/roles/vllm/templates/vllm-visualize.py.j2
new file mode 100644
index 00000000..b5c02e60
--- /dev/null
+++ b/playbooks/roles/vllm/templates/vllm-visualize.py.j2
@@ -0,0 +1,434 @@
+#!/usr/bin/env python3
+{% raw %}
+"""
+vLLM Benchmark Results Visualization
+Generates HTML report with performance graphs
+"""
+
+import json
+import os
+import glob
+from datetime import datetime
+import matplotlib
+matplotlib.use('Agg') # Use non-interactive backend
+import matplotlib.pyplot as plt
+import numpy as np
+
+def load_results():
+ """Load all benchmark and system info JSON files"""
+ results = {}
+
+ # Load benchmark results
+ for filename in glob.glob("*_benchmark_results.json"):
+ hostname = filename.replace("_benchmark_results.json", "")
+ try:
+ with open(filename, 'r') as f:
+ results[hostname] = {'benchmark': json.load(f)}
+ except:
+ print(f"Warning: Could not load {filename}")
+ continue
+
+ # Load system info
+ for filename in glob.glob("*_system_info.json"):
+ hostname = filename.replace("_system_info.json", "")
+ try:
+ with open(filename, 'r') as f:
+ if hostname in results:
+ results[hostname]['system'] = json.load(f)
+ else:
+ results[hostname] = {'system': json.load(f)}
+ except:
+ print(f"Warning: Could not load {filename}")
+
+ return results
+
+def create_latency_chart(results):
+ """Create latency comparison chart"""
+ fig, ax = plt.subplots(figsize=(10, 6))
+
+ hosts = []
+ p50_values = []
+ p95_values = []
+ p99_values = []
+
+ for hostname, data in results.items():
+ if 'benchmark' in data:
+ hosts.append(hostname)
+ benchmark = data['benchmark']
+ p50_values.append(benchmark.get('latency_p50_ms', 0))
+ p95_values.append(benchmark.get('latency_p95_ms', 0))
+ p99_values.append(benchmark.get('latency_p99_ms', 0))
+
+ if hosts:
+ x = np.arange(len(hosts))
+ width = 0.25
+
+ ax.bar(x - width, p50_values, width, label='P50', color='green', alpha=0.8)
+ ax.bar(x, p95_values, width, label='P95', color='orange', alpha=0.8)
+ ax.bar(x + width, p99_values, width, label='P99', color='red', alpha=0.8)
+
+ ax.set_xlabel('Host')
+ ax.set_ylabel('Latency (ms)')
+ ax.set_title('vLLM Response Latency by Percentile')
+ ax.set_xticks(x)
+ ax.set_xticklabels(hosts, rotation=45, ha='right')
+ ax.legend()
+ ax.grid(True, alpha=0.3)
+
+ plt.tight_layout()
+ plt.savefig('html/latency_chart.png', dpi=100, bbox_inches='tight')
+ plt.close()
+ return True
+ return False
+
+def create_throughput_chart(results):
+ """Create throughput comparison chart"""
+ fig, ax = plt.subplots(figsize=(10, 6))
+
+ hosts = []
+ rps_values = []
+
+ for hostname, data in results.items():
+ if 'benchmark' in data:
+ hosts.append(hostname)
+ benchmark = data['benchmark']
+ rps_values.append(benchmark.get('requests_per_second', 0))
+
+ if hosts:
+ colors = plt.cm.viridis(np.linspace(0.3, 0.9, len(hosts)))
+ bars = ax.bar(hosts, rps_values, color=colors, alpha=0.8)
+
+ # Add value labels on bars
+ for bar, value in zip(bars, rps_values):
+ height = bar.get_height()
+ ax.text(bar.get_x() + bar.get_width()/2., height,
+ f'{value:.0f}',
+ ha='center', va='bottom')
+
+ ax.set_xlabel('Host')
+ ax.set_ylabel('Requests per Second')
+ ax.set_title('vLLM Throughput Performance')
+ ax.set_xticklabels(hosts, rotation=45, ha='right')
+ ax.grid(True, alpha=0.3, axis='y')
+
+ plt.tight_layout()
+ plt.savefig('html/throughput_chart.png', dpi=100, bbox_inches='tight')
+ plt.close()
+ return True
+ return False
+
+def create_success_rate_chart(results):
+ """Create success rate pie chart"""
+ total_successful = 0
+ total_failed = 0
+
+ for hostname, data in results.items():
+ if 'benchmark' in data:
+ benchmark = data['benchmark']
+ total_successful += benchmark.get('successful_requests', 0)
+ total_failed += benchmark.get('failed_requests', 0)
+
+ if total_successful > 0 or total_failed > 0:
+ fig, ax = plt.subplots(figsize=(8, 8))
+
+ sizes = [total_successful, total_failed]
+ labels = ['Successful', 'Failed']
+ colors = ['#28a745', '#dc3545']
+ explode = (0.05, 0.05)
+
+ ax.pie(sizes, explode=explode, labels=labels, colors=colors,
+ autopct='%1.1f%%', shadow=True, startangle=90)
+ ax.axis('equal')
+ ax.set_title('Overall Request Success Rate')
+
+ plt.tight_layout()
+ plt.savefig('html/success_rate_chart.png', dpi=100, bbox_inches='tight')
+ plt.close()
+ return True
+ return False
+
+def generate_html_report(results):
+ """Generate HTML report with embedded charts"""
+
+ # Calculate summary statistics
+ total_requests = 0
+ total_successful = 0
+ total_failed = 0
+ avg_rps = []
+ avg_p50 = []
+ avg_p95 = []
+ avg_p99 = []
+
+ for hostname, data in results.items():
+ if 'benchmark' in data:
+ benchmark = data['benchmark']
+ total_requests += benchmark.get('total_requests', 0)
+ total_successful += benchmark.get('successful_requests', 0)
+ total_failed += benchmark.get('failed_requests', 0)
+ avg_rps.append(benchmark.get('requests_per_second', 0))
+ avg_p50.append(benchmark.get('latency_p50_ms', 0))
+ avg_p95.append(benchmark.get('latency_p95_ms', 0))
+ avg_p99.append(benchmark.get('latency_p99_ms', 0))
+
+ html_content = f"""<!DOCTYPE html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <meta name="viewport" content="width=device-width, initial-scale=1.0">
+ <title>vLLM Benchmark Results - {{ ansible_date_time.date }}</title>
+ <style>
+ body {{
+ font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, 'Helvetica Neue', Arial, sans-serif;
+ line-height: 1.6;
+ color: #333;
+ max-width: 1400px;
+ margin: 0 auto;
+ padding: 20px;
+ background: #f5f5f5;
+ }}
+ h1 {{
+ color: #2c3e50;
+ border-bottom: 3px solid #3498db;
+ padding-bottom: 10px;
+ }}
+ h2 {{
+ color: #34495e;
+ margin-top: 30px;
+ border-bottom: 2px solid #ecf0f1;
+ padding-bottom: 5px;
+ }}
+ .summary-grid {{
+ display: grid;
+ grid-template-columns: repeat(auto-fit, minmax(200px, 1fr));
+ gap: 20px;
+ margin: 20px 0;
+ }}
+ .metric-card {{
+ background: white;
+ padding: 20px;
+ border-radius: 8px;
+ box-shadow: 0 2px 4px rgba(0,0,0,0.1);
+ }}
+ .metric-value {{
+ font-size: 2em;
+ font-weight: bold;
+ color: #3498db;
+ }}
+ .metric-label {{
+ color: #7f8c8d;
+ text-transform: uppercase;
+ font-size: 0.9em;
+ margin-top: 5px;
+ }}
+ table {{
+ width: 100%;
+ border-collapse: collapse;
+ background: white;
+ margin: 20px 0;
+ box-shadow: 0 2px 4px rgba(0,0,0,0.1);
+ }}
+ th, td {{
+ padding: 12px;
+ text-align: left;
+ border-bottom: 1px solid #ecf0f1;
+ }}
+ th {{
+ background: #34495e;
+ color: white;
+ font-weight: 600;
+ }}
+ tr:hover {{
+ background: #f8f9fa;
+ }}
+ .chart-container {{
+ background: white;
+ padding: 20px;
+ border-radius: 8px;
+ margin: 20px 0;
+ box-shadow: 0 2px 4px rgba(0,0,0,0.1);
+ }}
+ .chart-container img {{
+ max-width: 100%;
+ height: auto;
+ }}
+ .success {{ color: #27ae60; font-weight: bold; }}
+ .warning {{ color: #f39c12; font-weight: bold; }}
+ .error {{ color: #e74c3c; font-weight: bold; }}
+ .footer {{
+ margin-top: 50px;
+ padding-top: 20px;
+ border-top: 1px solid #ecf0f1;
+ color: #7f8c8d;
+ text-align: center;
+ }}
+ </style>
+</head>
+<body>
+ <h1>🚀 vLLM Benchmark Results Report</h1>
+ <p><strong>Generated:</strong> {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}</p>
+
+ <h2>📊 Summary Statistics</h2>
+ <div class="summary-grid">
+ <div class="metric-card">
+ <div class="metric-value">{total_requests:,d}</div>
+ <div class="metric-label">Total Requests</div>
+ </div>
+ <div class="metric-card">
+ <div class="metric-value">{np.mean(avg_rps) if avg_rps else 0:.0f}</div>
+ <div class="metric-label">Avg Requests/Sec</div>
+ </div>
+ <div class="metric-card">
+ <div class="metric-value">{np.mean(avg_p50) if avg_p50 else 0:.1f}ms</div>
+ <div class="metric-label">Avg P50 Latency</div>
+ </div>
+ <div class="metric-card">
+ <div class="metric-value">{np.mean(avg_p95) if avg_p95 else 0:.1f}ms</div>
+ <div class="metric-label">Avg P95 Latency</div>
+ </div>
+ <div class="metric-card">
+ <div class="metric-value">{np.mean(avg_p99) if avg_p99 else 0:.1f}ms</div>
+ <div class="metric-label">Avg P99 Latency</div>
+ </div>
+ <div class="metric-card">
+ <div class="metric-value" class="{'success' if total_failed == 0 else 'warning' if total_failed < total_successful else 'error'}">
+ {(total_successful / (total_successful + total_failed) * 100) if (total_successful + total_failed) > 0 else 0:.1f}%
+ </div>
+ <div class="metric-label">Success Rate</div>
+ </div>
+ </div>
+
+ <h2>🖥️ Test Environment Details</h2>
+ <table>
+ <thead>
+ <tr>
+ <th>Host</th>
+ <th>Distribution</th>
+ <th>Kernel</th>
+ <th>CPUs</th>
+ <th>Memory (MB)</th>
+ <th>Virtualization</th>
+ <th>Test Date</th>
+ </tr>
+ </thead>
+ <tbody>"""
+
+ for hostname, data in results.items():
+ if 'system' in data:
+ sys = data['system']
+ html_content += f"""
+ <tr>
+ <td><strong>{hostname}</strong></td>
+ <td>{sys.get('distribution', 'N/A')} {sys.get('distribution_version', '')}</td>
+ <td>{sys.get('kernel', 'N/A')}</td>
+ <td>{sys.get('processor_cores', 'N/A')}</td>
+ <td>{'{:,}'.format(sys.get('memtotal_mb', 0)) if isinstance(sys.get('memtotal_mb', 0), int) else 'N/A'}</td>
+ <td>{sys.get('virtualization_type', 'N/A')}</td>
+ <td>{sys.get('date', 'N/A')}</td>
+ </tr>"""
+
+ html_content += """
+ </tbody>
+ </table>
+
+ <h2>📈 Performance Results</h2>
+ <table>
+ <thead>
+ <tr>
+ <th>Host</th>
+ <th>Total Requests</th>
+ <th>Successful</th>
+ <th>Failed</th>
+ <th>Requests/Sec</th>
+ <th>P50 (ms)</th>
+ <th>P95 (ms)</th>
+ <th>P99 (ms)</th>
+ <th>Mean (ms)</th>
+ </tr>
+ </thead>
+ <tbody>"""
+
+ for hostname, data in results.items():
+ if 'benchmark' in data:
+ bench = data['benchmark']
+ success_class = 'success' if bench.get('failed_requests', 0) == 0 else 'warning' if bench.get('failed_requests', 0) < bench.get('successful_requests', 1) else 'error'
+ html_content += f"""
+ <tr>
+ <td><strong>{hostname}</strong></td>
+ <td>{bench.get('total_requests', 0):,d}</td>
+ <td class="success">{bench.get('successful_requests', 0):,d}</td>
+ <td class="{success_class}">{bench.get('failed_requests', 0):,d}</td>
+ <td>{bench.get('requests_per_second', 0):.1f}</td>
+ <td>{bench.get('latency_p50_ms', 0):.1f}</td>
+ <td>{bench.get('latency_p95_ms', 0):.1f}</td>
+ <td>{bench.get('latency_p99_ms', 0):.1f}</td>
+ <td>{bench.get('mean_latency_ms', 0):.1f}</td>
+ </tr>"""
+
+ html_content += """
+ </tbody>
+ </table>
+
+ <h2>📊 Performance Visualizations</h2>"""
+
+ # Add charts if they exist
+ if os.path.exists('html/throughput_chart.png'):
+ html_content += """
+ <div class="chart-container">
+ <h3>Throughput Comparison</h3>
+ <img src="throughput_chart.png" alt="Throughput Chart">
+ </div>"""
+
+ if os.path.exists('html/latency_chart.png'):
+ html_content += """
+ <div class="chart-container">
+ <h3>Latency Distribution</h3>
+ <img src="latency_chart.png" alt="Latency Chart">
+ </div>"""
+
+ if os.path.exists('html/success_rate_chart.png'):
+ html_content += """
+ <div class="chart-container">
+ <h3>Success Rate Overview</h3>
+ <img src="success_rate_chart.png" alt="Success Rate Chart">
+ </div>"""
+
+ html_content += f"""
+ <div class="footer">
+ <p>Generated by vLLM kdevops workflow | Configuration: {% endraw %}{{ vllm_model_url | default('facebook/opt-125m') }}{% raw %}</p>
+ <p>CPU Inference Mode: {% endraw %}{{ vllm_use_cpu_inference | default(false) }}{% raw %} | Max Model Length: {% endraw %}{{ vllm_max_model_len | default(2048) }}{% raw %}</p>
+ </div>
+</body>
+</html>"""
+
+ with open('html/index.html', 'w') as f:
+ f.write(html_content)
+
+ print(f"HTML report generated: html/index.html")
+
+def main():
+ """Main execution function"""
+ print("Loading benchmark results...")
+ results = load_results()
+
+ if not results:
+ print("Error: No results found to visualize")
+ return 1
+
+ print(f"Found results for {len(results)} hosts")
+
+ # Create charts
+ print("Generating performance charts...")
+ create_throughput_chart(results)
+ create_latency_chart(results)
+ create_success_rate_chart(results)
+
+ # Generate HTML report
+ print("Generating HTML report...")
+ generate_html_report(results)
+
+ print("Visualization complete!")
+ return 0
+
+if __name__ == "__main__":
+ exit(main())
+{% endraw %}
diff --git a/playbooks/vllm.yml b/playbooks/vllm.yml
new file mode 100644
index 00000000..2aad56a8
--- /dev/null
+++ b/playbooks/vllm.yml
@@ -0,0 +1,11 @@
+---
+- name: Deploy and manage vLLM Production Stack
+ hosts: baseline:dev
+ become: yes
+ become_method: sudo
+ vars:
+ ansible_ssh_pipelining: true
+ roles:
+ - role: create_data_partition
+ tags: ["data_partition"]
+ - role: vllm
diff --git a/scripts/vllm-quick-test.sh b/scripts/vllm-quick-test.sh
new file mode 100755
index 00000000..c68de2c8
--- /dev/null
+++ b/scripts/vllm-quick-test.sh
@@ -0,0 +1,167 @@
+#!/bin/bash
+# Quick test script for vLLM deployment
+# Tests both baseline and dev nodes, measures response time, and validates output
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+TOPDIR="${SCRIPT_DIR}/.."
+
+# Colors for output
+RED='\033[0;31m'
+GREEN='\033[0;32m'
+YELLOW='\033[1;33m'
+NC='\033[0m' # No Color
+
+# Test configuration
+PROMPT="kdevops is"
+MAX_TOKENS=30
+TIMEOUT=30
+
+# Load configuration
+if [[ ! -f "${TOPDIR}/.config" ]]; then
+ echo -e "${RED}Error: No .config found. Run 'make menuconfig' first.${NC}"
+ exit 1
+fi
+
+# Check if baseline and dev are enabled
+BASELINE_AND_DEV=$(grep "^CONFIG_KDEVOPS_BASELINE_AND_DEV=y" "${TOPDIR}/.config" || true)
+
+# Get node names from extra_vars.yaml
+if [[ ! -f "${TOPDIR}/extra_vars.yaml" ]]; then
+ echo -e "${RED}Error: extra_vars.yaml not found. Run 'make' first.${NC}"
+ exit 1
+fi
+
+KDEVOPS_HOST_PREFIX=$(grep "^kdevops_host_prefix:" "${TOPDIR}/extra_vars.yaml" | awk '{print $2}' | tr -d '"')
+if [[ -z "$KDEVOPS_HOST_PREFIX" ]]; then
+ echo -e "${RED}Error: Could not determine host prefix from extra_vars.yaml${NC}"
+ exit 1
+fi
+
+# Determine nodes to test
+NODES=("${KDEVOPS_HOST_PREFIX}-vllm")
+if [[ -n "$BASELINE_AND_DEV" ]]; then
+ NODES+=("${KDEVOPS_HOST_PREFIX}-vllm-dev")
+fi
+
+# Function to test a single node
+test_node() {
+ local node=$1
+ local node_type=$2
+ local exit_code=0
+
+ echo ""
+ echo "Testing ${node_type} node: ${node}"
+ echo "----------------------------------------"
+
+ # Get node IP
+ local node_ip=$(ansible "${node}" -i "${TOPDIR}/hosts" -m shell -a "hostname -I | awk '{print \$1}'" 2>/dev/null | grep -A1 "${node} |" | tail -1 | xargs)
+
+ if [[ -z "$node_ip" ]]; then
+ echo -e "${RED}✗ Failed to get IP for ${node}${NC}"
+ return 1
+ fi
+
+ echo "Node IP: ${node_ip}"
+
+ # Check if port-forward is running
+ local pf_running=$(ssh "${node}" "ps aux | grep 'kubectl port-forward' | grep 8000 | grep -v grep" 2>/dev/null || true)
+
+ if [[ -z "$pf_running" ]]; then
+ echo "Starting kubectl port-forward..."
+ ssh "${node}" "sudo nohup kubectl --kubeconfig=/root/.kube/config port-forward -n vllm-system svc/vllm-prod-${node}-router-service 8000:80 --address=0.0.0.0 > /tmp/pf.log 2>&1 &" 2>/dev/null || true
+ sleep 2
+ else
+ echo "kubectl port-forward already running"
+ fi
+
+ # Test the endpoint with timing
+ echo "Sending request: \"${PROMPT}\""
+ local start_time=$(date +%s.%N)
+
+ # Run curl on the node itself via SSH to avoid network routing issues
+ # Use printf to properly escape the JSON payload
+ local response=$(ssh "${node}" "curl -s -m ${TIMEOUT} http://localhost:8000/v1/completions -H 'Content-Type: application/json' -d '{\"model\": \"facebook/opt-125m\", \"prompt\": \"${PROMPT}\", \"max_tokens\": ${MAX_TOKENS}}'" 2>&1)
+
+ local curl_exit=$?
+ local end_time=$(date +%s.%N)
+ local duration=$(echo "$end_time - $start_time" | bc)
+
+ if [[ $curl_exit -ne 0 ]]; then
+ echo -e "${RED}✗ Request failed (curl exit code: ${curl_exit})${NC}"
+ echo "Response: ${response}"
+ return 1
+ fi
+
+ # Check if response is valid JSON
+ if ! echo "${response}" | python3 -m json.tool > /dev/null 2>&1; then
+ echo -e "${RED}✗ Invalid JSON response${NC}"
+ echo "Response: ${response}"
+ return 1
+ fi
+
+ # Extract completion text
+ local completion=$(echo "${response}" | python3 -c "import sys, json; data=json.load(sys.stdin); print(data.get('choices', [{}])[0].get('text', 'N/A').strip())" 2>/dev/null || echo "ERROR")
+
+ if [[ "$completion" == "ERROR" ]] || [[ "$completion" == "N/A" ]]; then
+ echo -e "${RED}✗ Failed to extract completion from response${NC}"
+ echo "Response: ${response}"
+ return 1
+ fi
+
+ # Check for error in response
+ local error_msg=$(echo "${response}" | python3 -c "import sys, json; data=json.load(sys.stdin); print(data.get('message', ''))" 2>/dev/null || echo "")
+
+ if [[ -n "$error_msg" ]] && [[ "$error_msg" != "" ]]; then
+ echo -e "${RED}✗ API returned error: ${error_msg}${NC}"
+ return 1
+ fi
+
+ # Success!
+ echo -e "${GREEN}✓ Success!${NC}"
+ echo "Duration: ${duration}s"
+ echo "Full response: \"${PROMPT}${completion}\""
+ echo ""
+
+ # Pretty print full JSON response
+ echo "Full JSON response:"
+ echo "${response}" | python3 -m json.tool | head -30
+
+ return 0
+}
+
+# Main execution
+echo "========================================"
+echo "vLLM Quick Test"
+echo "========================================"
+echo "Prompt: \"${PROMPT}\""
+echo "Max tokens: ${MAX_TOKENS}"
+echo "Nodes to test: ${#NODES[@]}"
+
+overall_exit=0
+
+for i in "${!NODES[@]}"; do
+ node="${NODES[$i]}"
+ if [[ $i -eq 0 ]]; then
+ node_type="Baseline"
+ else
+ node_type="Development"
+ fi
+
+ if ! test_node "$node" "$node_type"; then
+ overall_exit=1
+ echo -e "${RED}✗ Test failed for ${node}${NC}"
+ fi
+done
+
+echo ""
+echo "========================================"
+if [[ $overall_exit -eq 0 ]]; then
+ echo -e "${GREEN}All tests passed!${NC}"
+else
+ echo -e "${RED}Some tests failed!${NC}"
+fi
+echo "========================================"
+
+exit $overall_exit
diff --git a/scripts/vllm-status-summary.py b/scripts/vllm-status-summary.py
new file mode 100755
index 00000000..777bc2b2
--- /dev/null
+++ b/scripts/vllm-status-summary.py
@@ -0,0 +1,404 @@
+#!/usr/bin/env python3
+"""
+Simplified vLLM deployment status summary.
+Parses verbose ansible output and presents a clean status overview.
+"""
+
+import sys
+import re
+from datetime import datetime
+
+
+def parse_status_output(lines):
+ """Parse the verbose status output and extract key information."""
+ status = {
+ "timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
+ "ansible_running": False,
+ "nodes": {},
+ "overall_state": "unknown",
+ "docker_images": {},
+ "helm_values": {},
+ "services": {},
+ }
+
+ current_section = None
+ current_node = None
+
+ for line in lines:
+ # Track sections
+ if "--- Ansible Process ---" in line:
+ current_section = "ansible"
+ elif "--- Helm Deployment" in line:
+ current_section = "helm"
+ elif "--- Kubernetes Cluster Status ---" in line:
+ current_section = "k8s_cluster"
+ elif "--- Kubernetes Pods ---" in line:
+ current_section = "k8s_pods"
+ elif "--- Docker Containers ---" in line:
+ current_section = "docker"
+ elif "--- Docker Mirror 9P Mount ---" in line:
+ current_section = "9p_mount"
+ elif "--- Docker Images" in line:
+ current_section = "docker_images"
+ elif "--- Helm Values" in line:
+ current_section = "helm_values"
+ elif "--- Kubernetes Services ---" in line:
+ current_section = "k8s_services"
+
+ # Parse node names
+ if "| CHANGED |" in line or "| FAILED |" in line:
+ match = re.match(r"^(\S+)\s+\|", line)
+ if match:
+ current_node = match.group(1)
+ if current_node not in status["nodes"] and current_node != "localhost":
+ status["nodes"][current_node] = {
+ "helm_deploying": False,
+ "k8s_ready": False,
+ "minikube_running": False,
+ "docker_mirror_9p": False,
+ "pods_running": 0,
+ "pods_pending": 0,
+ }
+
+ # Ansible process detection
+ if (
+ current_section == "ansible"
+ and "ansible-playbook" in line
+ and "vllm" in line
+ ):
+ status["ansible_running"] = True
+
+ # Helm deployment detection
+ if current_section == "helm" and current_node and current_node != "localhost":
+ if "/usr/local/bin/helm upgrade" in line and "vllm" in line:
+ status["nodes"][current_node]["helm_deploying"] = True
+
+ # Kubernetes cluster status
+ if (
+ current_section == "k8s_cluster"
+ and current_node
+ and current_node != "localhost"
+ ):
+ if "Kubernetes control plane is running" in line:
+ status["nodes"][current_node]["k8s_ready"] = True
+ elif "connection refused" in line or "unreachable" in line:
+ status["nodes"][current_node]["k8s_ready"] = False
+
+ # Docker containers - detect minikube
+ if current_section == "docker" and current_node and current_node != "localhost":
+ if "minikube" in line and "Up" in line:
+ status["nodes"][current_node]["minikube_running"] = True
+
+ # 9P mount detection
+ if (
+ current_section == "9p_mount"
+ and current_node
+ and current_node != "localhost"
+ ):
+ if "kdevops_9p_docker_mirror" in line and "/mirror/docker" in line:
+ status["nodes"][current_node]["docker_mirror_9p"] = True
+
+ # Pod counting
+ if (
+ current_section == "k8s_pods"
+ and current_node
+ and current_node != "localhost"
+ ):
+ if re.search(r"\s+Running\s+", line):
+ status["nodes"][current_node]["pods_running"] += 1
+ elif re.search(r"\s+Pending\s+", line):
+ status["nodes"][current_node]["pods_pending"] += 1
+
+ # Docker images detection
+ if (
+ current_section == "docker_images"
+ and current_node
+ and current_node != "localhost"
+ ):
+ # Look for vllm or openeuler images
+ if (
+ ("vllm" in line.lower() or "openeuler" in line.lower())
+ and "REPOSITORY" not in line
+ and "|" not in line
+ ):
+ # Parse docker images output: REPOSITORY TAG IMAGE_ID CREATED SIZE
+ parts = line.split()
+ if len(parts) >= 2 and parts[0] not in [
+ "REPOSITORY",
+ "No",
+ "Unable",
+ "---",
+ ]:
+ # Validate it looks like a real image (has slashes or well-known names)
+ if "/" in parts[0] or parts[0] in ["vllm", "openeuler"]:
+ image_name = f"{parts[0]}:{parts[1]}"
+ if current_node not in status["docker_images"]:
+ status["docker_images"][current_node] = []
+ if image_name not in status["docker_images"][current_node]:
+ status["docker_images"][current_node].append(image_name)
+
+ # Helm values detection
+ if (
+ current_section == "helm_values"
+ and current_node
+ and current_node != "localhost"
+ ):
+ if "repository:" in line:
+ match = re.search(r'repository:\s*["\']?([^"\']+)["\']?', line)
+ if match:
+ if current_node not in status["helm_values"]:
+ status["helm_values"][current_node] = {
+ "images": [],
+ "model": None,
+ }
+ # Store repository for next tag
+ status["helm_values"][current_node]["_pending_repo"] = match.group(
+ 1
+ )
+ elif "tag:" in line:
+ match = re.search(r'tag:\s*["\']?([^"\']+)["\']?', line)
+ if match:
+ if current_node not in status["helm_values"]:
+ status["helm_values"][current_node] = {
+ "images": [],
+ "model": None,
+ }
+ # Combine with pending repository
+ repo = status["helm_values"][current_node].get(
+ "_pending_repo", "unknown"
+ )
+ tag = match.group(1)
+ full_image = f"{repo}:{tag}"
+ if full_image not in status["helm_values"][current_node]["images"]:
+ status["helm_values"][current_node]["images"].append(full_image)
+ status["helm_values"][current_node]["_pending_repo"] = None
+ elif "modelURL:" in line:
+ match = re.search(r'modelURL:\s*["\']?([^"\']+)["\']?', line)
+ if match:
+ if current_node not in status["helm_values"]:
+ status["helm_values"][current_node] = {
+ "images": [],
+ "model": None,
+ }
+ status["helm_values"][current_node]["model"] = match.group(1)
+
+ # Kubernetes services detection
+ if (
+ current_section == "k8s_services"
+ and current_node
+ and current_node != "localhost"
+ ):
+ # Look for vllm services with ClusterIP
+ if "vllm" in line.lower() and "ClusterIP" in line:
+ parts = line.split()
+ if len(parts) >= 4:
+ svc_name = parts[0]
+ cluster_ip = parts[2]
+ ports = parts[4] if len(parts) > 4 else "unknown"
+ if current_node not in status["services"]:
+ status["services"][current_node] = []
+ status["services"][current_node].append(
+ {"name": svc_name, "ip": cluster_ip, "ports": ports}
+ )
+
+ # Determine overall state
+ if status["ansible_running"]:
+ if any(n["helm_deploying"] for n in status["nodes"].values()):
+ status["overall_state"] = "deploying"
+ else:
+ status["overall_state"] = "configuring"
+ elif any(
+ n["k8s_ready"] and n["pods_running"] > 0 for n in status["nodes"].values()
+ ):
+ status["overall_state"] = "running"
+ elif any(n["minikube_running"] for n in status["nodes"].values()):
+ status["overall_state"] = "starting"
+ else:
+ status["overall_state"] = "stopped"
+
+ return status
+
+
+def print_simplified_status(status):
+ """Print a clean, simplified status summary."""
+
+ # Header
+ print("=" * 60)
+ print(f"vLLM Deployment Status - {status['timestamp']}")
+ print("=" * 60)
+ print()
+
+ # Overall status with emoji
+ state_emoji = {
+ "running": "✅",
+ "deploying": "🚀",
+ "configuring": "⚙️",
+ "starting": "⏳",
+ "stopped": "⏸️",
+ "unknown": "❓",
+ }
+
+ state_desc = {
+ "running": "Running and Ready",
+ "deploying": "Deploying with Helm",
+ "configuring": "Configuring Infrastructure",
+ "starting": "Starting Services",
+ "stopped": "Stopped",
+ "unknown": "Unknown State",
+ }
+
+ emoji = state_emoji.get(status["overall_state"], "❓")
+ desc = state_desc.get(status["overall_state"], "Unknown")
+
+ print(f"Overall Status: {emoji} {desc}")
+ print()
+
+ # Ansible status
+ if status["ansible_running"]:
+ print("📦 Ansible: Running deployment playbook")
+ else:
+ print("📦 Ansible: Idle")
+ print()
+
+ # Per-node status
+ if status["nodes"]:
+ print("Nodes:")
+ print("-" * 60)
+ for node_name, node_info in sorted(status["nodes"].items()):
+ print(f"\n {node_name}:")
+
+ # Helm status
+ if node_info["helm_deploying"]:
+ print(" 🚀 Helm: Deploying vLLM production stack...")
+ else:
+ print(" 📊 Helm: Idle")
+
+ # Kubernetes status
+ if node_info["k8s_ready"]:
+ print(" ✅ Kubernetes: Cluster ready")
+ elif node_info["minikube_running"]:
+ print(" ⏳ Kubernetes: Cluster starting...")
+ else:
+ print(" ⏸️ Kubernetes: Not ready")
+
+ # Pods
+ if node_info["pods_running"] > 0:
+ print(f" 🎯 Pods: {node_info['pods_running']} running", end="")
+ if node_info["pods_pending"] > 0:
+ print(f", {node_info['pods_pending']} pending")
+ else:
+ print()
+ elif node_info["pods_pending"] > 0:
+ print(f" ⏳ Pods: {node_info['pods_pending']} pending")
+
+ # Docker mirror
+ if node_info["docker_mirror_9p"]:
+ print(" 🔗 Docker Mirror: Connected via 9P")
+ else:
+ print(" 🌐 Docker Mirror: Not available")
+
+ # Docker images section (only show if there are actual images)
+ has_images = any(images for images in status["docker_images"].values() if images)
+ if has_images:
+ print()
+ print("Docker Images (vLLM-related):")
+ print("-" * 60)
+ for node_name, images in sorted(status["docker_images"].items()):
+ if images: # Only show nodes with images
+ print(f"\n {node_name}:")
+ for img in images[:5]: # Show first 5 images
+ print(f" 📦 {img}")
+ if len(images) > 5:
+ print(f" ... and {len(images) - 5} more")
+
+ # Helm configuration section
+ if status["helm_values"]:
+ print()
+ print("Helm Configuration (Images to Deploy):")
+ print("-" * 60)
+ for node_name, values in sorted(status["helm_values"].items()):
+ print(f"\n {node_name}:")
+ if "images" in values and values["images"]:
+ for img in values["images"]:
+ # Identify image type
+ if "vllm-cpu" in img or "vllm-openai" in img:
+ print(f" 🚀 Engine: {img}")
+ elif "router" in img:
+ print(f" 🔀 Router: {img}")
+ else:
+ print(f" 📦 Image: {img}")
+ if "model" in values and values["model"]:
+ print(f" 🤖 Model: {values['model']}")
+
+ # Services and test commands section
+ if status["services"]:
+ print()
+ print("Services & Testing:")
+ print("-" * 60)
+ for node_name, services in sorted(status["services"].items()):
+ print(f"\n {node_name}:")
+ router_svc = None
+ engine_svc = None
+ for svc in services:
+ if "router" in svc["name"]:
+ router_svc = svc
+ print(f" 🔀 Router: {svc['name']}")
+ print(f" IP: {svc['ip']}, Ports: {svc['ports']}")
+ elif "engine" in svc["name"]:
+ engine_svc = svc
+ print(f" 🚀 Engine: {svc['name']}")
+ print(f" IP: {svc['ip']}, Ports: {svc['ports']}")
+
+ # Provide test commands
+ if router_svc:
+ node_short = node_name.replace("lpc-", "").replace("-dev", "")
+ print(f"\n 📝 Test via kubectl port-forward:")
+ print(f" # Start port forward (run in background):")
+ print(
+ f" ssh {node_name} 'sudo KUBECONFIG=/root/.kube/config kubectl port-forward -n vllm-system \\"
+ )
+ print(f" svc/{router_svc['name']} 8000:80 --address=0.0.0.0 &'")
+ print(f"\n # Test API (list models):")
+ print(f" curl http://{node_name}:8000/v1/models")
+ print(f"\n # Text completion example:")
+ print(f" curl http://{node_name}:8000/v1/completions \\")
+ print(f" -H 'Content-Type: application/json' \\")
+ print(f" -d '{{")
+ print(f' "model": "facebook/opt-125m",')
+ print(f' "prompt": "The meaning of life is",')
+ print(f' "max_tokens": 50')
+ print(f" }}'")
+ print(f"\n Note: Use /v1/completions (not /v1/chat/completions)")
+ print(f" as this model doesn't have a chat template configured.")
+
+ print()
+ print("=" * 60)
+
+ # Helpful next steps based on state
+ if status["overall_state"] == "deploying":
+ print("\n💡 Deployment in progress. Helm may take 10-30 minutes.")
+ print(" Run 'make vllm-status-simplified' again to check progress.")
+ elif status["overall_state"] == "running":
+ print("\n💡 Deployment complete! Next steps:")
+ print(" - Use the test commands above to query the model")
+ print(" - make vllm-monitor (View monitoring dashboards)")
+ print(" - make vllm-benchmark (Run performance tests)")
+ elif status["overall_state"] == "starting":
+ print("\n💡 Kubernetes is starting. This may take a few minutes.")
+ elif status["overall_state"] == "stopped":
+ print("\n💡 vLLM is not running. To deploy:")
+ print(" - make vllm (Deploy vLLM stack)")
+
+ print()
+
+
+def main():
+ """Main entry point."""
+ lines = sys.stdin.readlines()
+ status = parse_status_output(lines)
+ print_simplified_status(status)
+ return 0
+
+
+if __name__ == "__main__":
+ sys.exit(main())
diff --git a/workflows/Makefile b/workflows/Makefile
index 05c75a2d..1c234b00 100644
--- a/workflows/Makefile
+++ b/workflows/Makefile
@@ -70,6 +70,10 @@ ifeq (y,$(CONFIG_KDEVOPS_WORKFLOW_ENABLE_AI))
include workflows/ai/Makefile
endif # CONFIG_KDEVOPS_WORKFLOW_ENABLE_AI == y
+ifeq (y,$(CONFIG_KDEVOPS_WORKFLOW_ENABLE_VLLM))
+include workflows/vllm/Makefile
+endif # CONFIG_KDEVOPS_WORKFLOW_ENABLE_VLLM == y
+
ifeq (y,$(CONFIG_KDEVOPS_WORKFLOW_ENABLE_MINIO))
include workflows/minio/Makefile
endif # CONFIG_KDEVOPS_WORKFLOW_ENABLE_MINIO == y
diff --git a/workflows/vllm/Kconfig b/workflows/vllm/Kconfig
new file mode 100644
index 00000000..e29726a9
--- /dev/null
+++ b/workflows/vllm/Kconfig
@@ -0,0 +1,699 @@
+if KDEVOPS_WORKFLOW_ENABLE_VLLM
+
+comment "vLLM Production Stack requires at least 64 GiB RAM per guest for stable operation"
+ depends on VLLM_PRODUCTION_STACK && LIBVIRT && !LIBVIRT_MEM_64G && !LIBVIRT_MEM_128G
+
+choice
+ prompt "vLLM deployment method"
+ default VLLM_LATEST_DOCKER
+
+config VLLM_LATEST_DOCKER
+ bool "Latest vLLM Docker image"
+ output yaml
+ help
+ Deploy vLLM using the latest official Docker images directly.
+ This provides a simple Kubernetes deployment with:
+ - Latest vLLM serving engine (vllm/vllm-openai:latest)
+ - Basic Kubernetes manifests
+ - CPU or GPU inference support
+ - Simple benchmarking capabilities
+
+ This is suitable for quick testing and development with the
+ most recent vLLM features.
+
+config VLLM_PRODUCTION_STACK
+ bool "vLLM Production Stack (official Helm chart)"
+ output yaml
+ help
+ Deploy the official vLLM Production Stack using Helm charts from
+ github.com/vllm-project/production-stack. This includes:
+ - vLLM serving engines with production configurations
+ - Request router (ghcr.io/vllm-project/production-stack/router)
+ - Observability stack with Prometheus and Grafana
+ - LMCache support for KV cache offloading
+ - Production-grade monitoring and scaling
+
+ IMPORTANT: Requires vLLM v0.6.6 or later (kdevops defaults to v0.6.6)
+ - The Helm chart hardcodes --no-enable-prefix-caching flag
+ - v0.6.5+ supports this flag but has CPU inference bugs
+ - v0.6.6 fixes CPU issues while maintaining compatibility
+ - For GPU-only deployments: v0.7.3+ offers V1 engine with 1.7x speedup
+
+ This is the recommended approach for production deployments.
+
+config VLLM_BARE_METAL
+ bool "Bare metal deployment with systemd"
+ depends on USE_LIBVIRT || TERRAFORM || KDEVOPS_USE_DECLARED_HOSTS
+ output yaml
+ help
+ Deploy vLLM directly on bare metal servers or VMs using systemd.
+ This provides:
+ - Direct vLLM installation via pip or containers
+ - Systemd service management
+ - Support for real GPU hardware
+ - No Kubernetes overhead
+
+ Use KDEVOPS_USE_DECLARED_HOSTS to specify existing servers with GPUs.
+ Ideal for dedicated GPU servers or HPC environments.
+
+endchoice
+
+# Common configuration for all deployment methods
+config VLLM_DEPLOYMENT_TYPE
+ string
+ output yaml
+ default "docker" if VLLM_LATEST_DOCKER
+ default "production-stack" if VLLM_PRODUCTION_STACK
+ default "bare-metal" if VLLM_BARE_METAL
+
+# Kubernetes-specific configuration
+if VLLM_LATEST_DOCKER || VLLM_PRODUCTION_STACK
+
+# Kubernetes deployment method
+choice
+ prompt "Kubernetes deployment method"
+ default VLLM_K8S_MINIKUBE
+
+config VLLM_K8S_MINIKUBE
+ bool "Minikube (local development)"
+ output yaml
+ help
+ Use Minikube for local Kubernetes development and testing.
+ This is suitable for single-node deployments and development.
+
+config VLLM_K8S_EXISTING
+ bool "Existing Kubernetes cluster"
+ output yaml
+ help
+ Use an existing Kubernetes cluster (AWS EKS, GCP GKE, Azure AKS, etc.).
+ The cluster should already be configured with kubectl access.
+
+endchoice
+
+# Helm configuration
+config VLLM_HELM_RELEASE_NAME
+ string "Helm release name"
+ output yaml
+ default "vllm"
+ help
+ The name for the Helm release when deploying vLLM stack.
+
+config VLLM_HELM_NAMESPACE
+ string "Kubernetes namespace"
+ output yaml
+ default "vllm-system"
+ help
+ The Kubernetes namespace where vLLM stack will be deployed.
+
+# Model configuration
+config VLLM_MODEL_URL
+ string "Model URL or HuggingFace model ID"
+ output yaml
+ default "facebook/opt-125m"
+ help
+ The model to serve. Can be a HuggingFace model ID
+ (e.g., "facebook/opt-125m", "meta-llama/Llama-2-7b-hf")
+ or a path to local model weights.
+
+config VLLM_MODEL_NAME
+ string "Model name alias"
+ output yaml
+ default "opt-125m"
+ help
+ A friendly name/alias for the model that will be used
+ in API requests.
+
+# vLLM Engine version configuration
+# CLI override via environment variable VLLM=nightly or VLLM=v0.7.3
+config VLLM_CLI_VERSION_OVERRIDE
+ bool
+ default $(shell, test -n "$VLLM" && echo y || echo n)
+
+config VLLM_CLI_VERSION_STRING
+ string
+ default "$(shell, echo $VLLM)"
+ depends on VLLM_CLI_VERSION_OVERRIDE
+
+config VLLM_CLI_IS_NIGHTLY
+ bool
+ default $(shell, test "$VLLM" = "nightly" && echo y || echo n)
+ depends on VLLM_CLI_VERSION_OVERRIDE
+
+choice
+ prompt "vLLM engine version"
+ default VLLM_VERSION_CLI_NIGHTLY if VLLM_CLI_IS_NIGHTLY
+ default VLLM_VERSION_CLI_CUSTOM if VLLM_CLI_VERSION_OVERRIDE
+ default VLLM_VERSION_LATEST if VLLM_PRODUCTION_STACK && VLLM_USE_CPU_INFERENCE
+ default VLLM_VERSION_STABLE
+
+config VLLM_VERSION_V0_10_0
+ bool "v0.10.0 (recommended for Production Stack)"
+ depends on !VLLM_CLI_VERSION_OVERRIDE
+ help
+ Use vLLM v0.10.0 - a recent version that:
+ - Supports --no-enable-prefix-caching flag (required by Production Stack)
+ - Should have CPU inference support improvements
+ - Represents a major version with significant updates
+ - Good balance of stability and features
+
+config VLLM_VERSION_STABLE
+ bool "Stable v0.10.2 (latest stable)"
+ depends on !VLLM_CLI_VERSION_OVERRIDE
+ help
+ Use vLLM v0.10.2 - the latest stable version
+ Note: v0.6.5-v0.6.6 have CPU inference bugs (NotImplementedError)
+
+config VLLM_VERSION_LATEST
+ bool "Latest release"
+ depends on !VLLM_CLI_VERSION_OVERRIDE
+ help
+ Use the latest stable vLLM release (currently points to v0.10.2).
+ Note: May have compatibility issues with Production Stack if the
+ chart hasn't been updated to match newer vLLM changes.
+
+config VLLM_VERSION_NIGHTLY
+ bool "Nightly build (bleeding edge)"
+ depends on !VLLM_CLI_VERSION_OVERRIDE
+ help
+ Use the latest nightly build for testing newest features.
+ WARNING: Nightly builds are unstable and may break frequently.
+ Not recommended for production use.
+
+config VLLM_VERSION_CLI_NIGHTLY
+ bool "Nightly build (set via CLI)"
+ depends on VLLM_CLI_IS_NIGHTLY
+ help
+ Using nightly build as specified via VLLM=nightly environment variable.
+
+config VLLM_VERSION_CLI_CUSTOM
+ bool "Custom version (set via CLI)"
+ depends on VLLM_CLI_VERSION_OVERRIDE && !VLLM_CLI_IS_NIGHTLY
+ help
+ Using custom version specified via VLLM environment variable.
+
+config VLLM_VERSION_CUSTOM
+ bool "Custom version"
+ depends on !VLLM_CLI_VERSION_OVERRIDE
+ help
+ Specify a custom vLLM version tag (e.g., "v0.7.3", "v0.6.5").
+ Use this to test specific versions or workaround compatibility issues.
+
+endchoice
+
+config VLLM_ENGINE_IMAGE_TAG
+ string "vLLM Docker image tag"
+ output yaml
+ default "latest" if VLLM_USE_CPU_INFERENCE
+ default "v0.10.0" if VLLM_VERSION_V0_10_0 && !VLLM_USE_CPU_INFERENCE
+ default "v0.10.2" if VLLM_VERSION_STABLE && !VLLM_USE_CPU_INFERENCE
+ default "v0.10.2" if VLLM_VERSION_CUSTOM && !VLLM_USE_CPU_INFERENCE
+ default "latest" if VLLM_VERSION_LATEST && !VLLM_USE_CPU_INFERENCE
+ default "nightly" if (VLLM_VERSION_NIGHTLY || VLLM_VERSION_CLI_NIGHTLY) && !VLLM_USE_CPU_INFERENCE
+ default "$(shell, echo $VLLM)" if VLLM_VERSION_CLI_CUSTOM && !VLLM_USE_CPU_INFERENCE
+ help
+ The Docker image tag for vLLM engine.
+ For custom version, specify the exact tag (e.g., "v0.10.2").
+
+ IMPORTANT for CPU inference:
+ - v0.6.3.post1: Works with CPU but lacks --no-enable-prefix-caching flag
+ - v0.6.5-v0.6.6: BROKEN - NotImplementedError in is_async_output_supported
+ - v0.10.0: Testing for Production Stack CPU support
+ - v0.10.2: Latest stable version
+ Can be overridden via VLLM environment variable (e.g., VLLM=nightly make).
+
+# Resource configuration
+config VLLM_REPLICA_COUNT
+ int "Number of vLLM engine replicas"
+ output yaml
+ default 1
+ range 1 10
+ help
+ The number of vLLM engine replicas to deploy.
+ Each replica requires GPU resources.
+
+config VLLM_REQUEST_CPU
+ int "CPU cores per replica"
+ output yaml
+ default 8 if VLLM_USE_CPU_INFERENCE
+ default 4
+ range 1 128
+ help
+ Number of CPU cores requested per vLLM engine replica.
+
+ For CPU inference, more cores enable better parallelization.
+ With 64 vCPUs total and 2 replicas, 24 cores per replica
+ leaves overhead for system processes.
+
+config VLLM_REQUEST_MEMORY
+ string "Memory per replica"
+ output yaml
+ default "20Gi" if VLLM_USE_CPU_INFERENCE
+ default "16Gi"
+ help
+ Amount of memory requested per vLLM engine replica.
+ Format: <number>Gi (e.g., "16Gi", "20Gi", "32Gi")
+
+ Note: Total memory usage = replicas * memory_per_replica + system overhead
+ With 64GB VM and 2 replicas, 20Gi per replica leaves ~20GB for
+ Kubernetes, Minikube, and monitoring components.
+
+# GPU/CPU deployment configuration
+config TERRAFORM_INSTANCE_SUPPORTS_GPU_COMPUTE
+ bool "Cloud instance has GPU compute support"
+ output yaml
+ default n
+ depends on TERRAFORM
+ help
+ Enable this if your cloud instances have GPU compute support.
+ This is typically available on specialized GPU instances like
+ AWS p3/g4, GCP A100/T4, or Azure NCv3 instances.
+
+ When enabled, vLLM will be configured to use GPU acceleration.
+ When disabled, vLLM will use CPU-only inference.
+
+config VLLM_USE_CPU_INFERENCE
+ bool "Use CPU inference mode"
+ output yaml
+ default y if !TERRAFORM_INSTANCE_SUPPORTS_GPU_COMPUTE && LIBVIRT
+ default n if TERRAFORM_INSTANCE_SUPPORTS_GPU_COMPUTE
+ help
+ Force vLLM to use CPU inference instead of GPU.
+ This is automatically enabled for libvirt/guestfs deployments
+ since virtual GPUs are not available for compute workloads.
+
+ CPU inference is slower but works everywhere and is suitable
+ for testing, CI, and development workflows.
+
+config VLLM_REQUEST_GPU
+ int "GPUs per replica"
+ output yaml
+ default 0 if VLLM_USE_CPU_INFERENCE
+ default 1
+ range 0 8
+ help
+ Number of GPUs requested per vLLM engine replica.
+ Automatically set to 0 for CPU-only deployments.
+
+config VLLM_GPU_TYPE
+ string "GPU type (optional)"
+ output yaml
+ default ""
+ depends on !VLLM_USE_CPU_INFERENCE
+ help
+ Optional GPU type specification (e.g., "nvidia.com/gpu",
+ "nvidia.com/mig-4g.71gb"). Leave empty for default GPU type.
+ Only applicable when using GPU inference.
+
+# vLLM engine configuration
+config VLLM_MAX_MODEL_LEN
+ int "Maximum model sequence length"
+ output yaml
+ default 2048
+ range 128 32768
+ help
+ Maximum sequence length the model can handle.
+ Should not exceed model's maximum context length.
+
+config VLLM_DTYPE
+ string "Model data type"
+ output yaml
+ default "auto"
+ help
+ Data type for model weights and activations.
+ Options: "auto", "half", "float16", "bfloat16", "float32"
+
+config VLLM_GPU_MEMORY_UTILIZATION
+ string "GPU memory utilization"
+ output yaml
+ default "0.9"
+ help
+ Fraction of GPU memory to use for model (0.0 to 1.0).
+ Default 0.9 leaves 10% for overhead.
+
+config VLLM_ENABLE_PREFIX_CACHING
+ bool "Enable prefix caching"
+ output yaml
+ default n
+ help
+ Enable automatic prefix caching to improve performance
+ for queries with common prefixes.
+
+config VLLM_ENABLE_CHUNKED_PREFILL
+ bool "Enable chunked prefill"
+ output yaml
+ default n
+ help
+ Enable chunked prefill to reduce memory usage during
+ the prefill phase.
+
+config VLLM_TENSOR_PARALLEL_SIZE
+ int "Tensor parallel size"
+ output yaml
+ default 1
+ range 1 8
+ help
+ Number of GPUs to use for tensor parallelism per replica.
+ Must be <= number of GPUs per replica.
+
+# LMCache configuration for KV cache offloading
+config VLLM_LMCACHE_ENABLED
+ bool "Enable LMCache for KV cache offloading"
+ output yaml
+ default n
+ help
+ Enable LMCache to offload KV cache to CPU memory,
+ allowing for larger batch sizes and better GPU utilization.
+
+if VLLM_LMCACHE_ENABLED
+
+config VLLM_LMCACHE_CPU_BUFFER_SIZE
+ string "CPU offloading buffer size (GB)"
+ output yaml
+ default "30"
+ help
+ Size of CPU buffer for KV cache offloading in GB.
+
+endif # VLLM_LMCACHE_ENABLED
+
+# Router configuration
+config VLLM_ROUTER_ENABLED
+ bool "Enable request router"
+ output yaml
+ default y
+ help
+ Enable the request router for load balancing and
+ session affinity across vLLM engine replicas.
+
+if VLLM_ROUTER_ENABLED
+
+choice
+ prompt "Routing algorithm"
+ default VLLM_ROUTER_ROUND_ROBIN
+
+config VLLM_ROUTER_ROUND_ROBIN
+ bool "Round-robin routing"
+ output yaml
+ help
+ Distribute requests evenly across all available backends.
+
+config VLLM_ROUTER_SESSION_AFFINITY
+ bool "Session-based routing"
+ output yaml
+ help
+ Route requests from the same session to the same backend
+ to maximize KV cache reuse.
+
+config VLLM_ROUTER_PREFIX_AWARE
+ bool "Prefix-aware routing"
+ output yaml
+ help
+ Route requests with similar prefixes to the same backend
+ for better cache utilization.
+
+endchoice
+
+endif # VLLM_ROUTER_ENABLED
+
+# Observability configuration
+config VLLM_OBSERVABILITY_ENABLED
+ bool "Enable observability stack"
+ output yaml
+ default y
+ help
+ Deploy Prometheus and Grafana for monitoring vLLM metrics.
+
+if VLLM_OBSERVABILITY_ENABLED
+
+config VLLM_GRAFANA_PORT
+ int "Grafana dashboard port"
+ output yaml
+ default 3000
+ help
+ Port for accessing the Grafana dashboard.
+
+config VLLM_PROMETHEUS_PORT
+ int "Prometheus port"
+ output yaml
+ default 9090
+ help
+ Port for accessing Prometheus metrics.
+
+endif # VLLM_OBSERVABILITY_ENABLED
+
+# API configuration
+config VLLM_API_PORT
+ int "vLLM API port"
+ output yaml
+ default 8000
+ help
+ Port for accessing the vLLM OpenAI-compatible API.
+
+config VLLM_API_KEY
+ string "API key for vLLM (optional)"
+ output yaml
+ default ""
+ help
+ Optional API key for securing vLLM API access.
+ Leave empty for no authentication.
+
+# HuggingFace token (for gated models)
+config VLLM_HF_TOKEN
+ string "HuggingFace token (optional)"
+ output yaml
+ default ""
+ help
+ HuggingFace token for accessing gated models.
+ Required for models like Llama-2.
+
+# Quick test mode for CI
+config VLLM_QUICK_TEST
+ bool "Enable quick test mode"
+ output yaml
+ default n
+ help
+ Quick test mode for CI/demo with minimal resources.
+ Uses smaller models and reduced resource requirements.
+
+# Results and benchmarking
+config VLLM_BENCHMARK_ENABLED
+ bool "Enable benchmarking"
+ output yaml
+ default y
+ help
+ Run performance benchmarks after deployment.
+
+if VLLM_BENCHMARK_ENABLED
+
+config VLLM_BENCHMARK_DURATION
+ int "Benchmark duration (seconds)"
+ output yaml
+ default 60
+ range 10 3600
+ help
+ Duration to run performance benchmarks.
+
+config VLLM_BENCHMARK_CONCURRENT_USERS
+ int "Concurrent users for benchmark"
+ output yaml
+ default 10
+ range 1 1000
+ help
+ Number of concurrent users to simulate during benchmarking.
+
+config VLLM_BENCHMARK_RESULTS_DIR
+ string "Benchmark results directory"
+ output yaml
+ default "/data/vllm-benchmark"
+ help
+ Directory where benchmark results will be stored.
+
+endif # VLLM_BENCHMARK_ENABLED
+
+endif # VLLM_LATEST_DOCKER || VLLM_PRODUCTION_STACK
+
+# vLLM Production Stack specific configuration
+if VLLM_PRODUCTION_STACK
+
+config VLLM_PROD_STACK_REPO
+ string "vLLM Production Stack Helm repository URL"
+ output yaml
+ default "https://vllm-project.github.io/production-stack"
+ help
+ URL of the Helm repository containing the vLLM Production Stack charts.
+
+config VLLM_PROD_STACK_CHART_VERSION
+ string "Helm chart version"
+ output yaml
+ default "latest"
+ help
+ Version of the vLLM Production Stack Helm chart to deploy.
+ Use "latest" for the most recent version or specify a specific
+ version like "0.1.0".
+
+config VLLM_PROD_STACK_ROUTER_IMAGE
+ string "Router image"
+ output yaml
+ default "ghcr.io/vllm-project/production-stack/router"
+ help
+ Container image for the vLLM Production Stack router component.
+
+config VLLM_PROD_STACK_ROUTER_TAG
+ string "Router image tag"
+ output yaml
+ default "latest"
+ help
+ Tag for the router container image.
+
+config VLLM_PROD_STACK_ENABLE_MONITORING
+ bool "Enable full monitoring stack"
+ output yaml
+ default y
+ help
+ Enable the complete monitoring stack including:
+ - Prometheus for metrics collection
+ - Grafana for visualization
+ - vLLM-specific dashboards
+ - Alert rules for production monitoring
+
+config VLLM_PROD_STACK_ENABLE_AUTOSCALING
+ bool "Enable autoscaling"
+ output yaml
+ default n
+ help
+ Enable Horizontal Pod Autoscaling (HPA) for vLLM engines
+ based on CPU/GPU utilization and request rate.
+
+if VLLM_PROD_STACK_ENABLE_AUTOSCALING
+
+config VLLM_PROD_STACK_MIN_REPLICAS
+ int "Minimum engine replicas"
+ output yaml
+ default 1
+ range 1 10
+ help
+ Minimum number of vLLM engine replicas for autoscaling.
+
+config VLLM_PROD_STACK_MAX_REPLICAS
+ int "Maximum engine replicas"
+ output yaml
+ default 5
+ range 2 50
+ help
+ Maximum number of vLLM engine replicas for autoscaling.
+
+config VLLM_PROD_STACK_TARGET_GPU_UTILIZATION
+ int "Target GPU utilization percentage"
+ output yaml
+ default 80
+ range 50 95
+ help
+ Target GPU utilization percentage for autoscaling decisions.
+
+endif # VLLM_PROD_STACK_ENABLE_AUTOSCALING
+
+config VLLM_PROD_STACK_CUSTOM_VALUES
+ bool "Use custom Helm values file"
+ output yaml
+ default n
+ help
+ Use a custom values.yaml file for Helm deployment instead of
+ generating one from kdevops configuration.
+
+if VLLM_PROD_STACK_CUSTOM_VALUES
+
+config VLLM_PROD_STACK_VALUES_PATH
+ string "Path to custom values.yaml"
+ output yaml
+ default "workflows/vllm/custom-values.yaml"
+ help
+ Path to custom Helm values file relative to kdevops root.
+
+endif # VLLM_PROD_STACK_CUSTOM_VALUES
+
+endif # VLLM_PRODUCTION_STACK
+
+# Bare metal deployment configuration
+if VLLM_BARE_METAL
+
+config VLLM_BARE_METAL_USE_CONTAINER
+ bool "Use container runtime on bare metal"
+ output yaml
+ default y
+ help
+ Use Docker/Podman to run vLLM on bare metal instead of
+ installing via pip. Containers provide better isolation
+ and dependency management.
+
+choice
+ prompt "Container runtime"
+ depends on VLLM_BARE_METAL_USE_CONTAINER
+ default VLLM_BARE_METAL_DOCKER
+
+config VLLM_BARE_METAL_DOCKER
+ bool "Docker"
+ output yaml
+ help
+ Use Docker as the container runtime.
+
+config VLLM_BARE_METAL_PODMAN
+ bool "Podman"
+ output yaml
+ help
+ Use Podman as the container runtime (rootless containers).
+
+endchoice
+
+config VLLM_BARE_METAL_INSTALL_METHOD
+ string "Installation method"
+ depends on !VLLM_BARE_METAL_USE_CONTAINER
+ output yaml
+ default "pip"
+ help
+ Method to install vLLM on bare metal.
+ Options: "pip" for PyPI installation, "source" for building from source.
+
+config VLLM_BARE_METAL_SERVICE_NAME
+ string "Systemd service name"
+ output yaml
+ default "vllm"
+ help
+ Name of the systemd service for managing vLLM.
+
+config VLLM_BARE_METAL_DATA_DIR
+ string "Data directory for models"
+ output yaml
+ default "/var/lib/vllm"
+ help
+ Directory where model weights and data will be stored.
+
+config VLLM_BARE_METAL_LOG_DIR
+ string "Log directory"
+ output yaml
+ default "/var/log/vllm"
+ help
+ Directory for vLLM logs.
+
+# Declared hosts support for bare metal
+if KDEVOPS_USE_DECLARED_HOSTS
+
+config VLLM_BARE_METAL_DECLARE_HOST_GPU_TYPE
+ string "GPU type on declared hosts"
+ output yaml
+ default "nvidia-a100"
+ help
+ Type of GPU available on the declared hosts.
+ Examples: nvidia-a100, nvidia-v100, nvidia-a10, nvidia-h100
+
+config VLLM_BARE_METAL_DECLARE_HOST_GPU_COUNT
+ int "Number of GPUs per host"
+ output yaml
+ default 1
+ range 1 8
+ help
+ Number of GPUs available on each declared host.
+
+endif # KDEVOPS_USE_DECLARED_HOSTS
+
+endif # VLLM_BARE_METAL
+
+endif # KDEVOPS_WORKFLOW_ENABLE_VLLM
diff --git a/workflows/vllm/Makefile b/workflows/vllm/Makefile
new file mode 100644
index 00000000..91966b28
--- /dev/null
+++ b/workflows/vllm/Makefile
@@ -0,0 +1,118 @@
+# vLLM Production Stack workflow
+
+HELP_TARGETS += vllm-help-menu
+
+vllm:
+ $(Q)ansible-playbook $(ANSIBLE_VERBOSE) \
+ --limit 'baseline:dev' \
+ playbooks/vllm.yml \
+ --tags data_partition,vars,deps,docker-config,vllm-deploy \
+ --extra-vars=@./extra_vars.yaml
+
+vllm-deploy:
+ $(Q)ansible-playbook $(ANSIBLE_VERBOSE) \
+ --limit 'baseline:dev' \
+ playbooks/vllm.yml \
+ --tags data_partition,vars,deps,docker-config,vllm-deploy \
+ --extra-vars=@./extra_vars.yaml
+
+vllm-benchmark:
+ $(Q)ansible-playbook $(ANSIBLE_VERBOSE) \
+ --limit 'baseline:dev' \
+ playbooks/vllm.yml \
+ --tags vars,vllm-benchmark \
+ --extra-vars=@./extra_vars.yaml
+
+vllm-monitor:
+ $(Q)ansible-playbook $(ANSIBLE_VERBOSE) \
+ --limit 'baseline:dev' \
+ playbooks/vllm.yml \
+ --tags vars,vllm-monitor \
+ --extra-vars=@./extra_vars.yaml
+
+vllm-teardown:
+ $(Q)ansible-playbook $(ANSIBLE_VERBOSE) \
+ --limit 'baseline:dev' \
+ playbooks/vllm.yml \
+ --tags vars,vllm-teardown \
+ --extra-vars=@./extra_vars.yaml
+
+vllm-cleanup:
+ $(Q)ansible-playbook $(ANSIBLE_VERBOSE) \
+ --limit 'baseline:dev' \
+ playbooks/vllm.yml \
+ --tags vars,vllm-cleanup \
+ --extra-vars=@./extra_vars.yaml
+
+vllm-results:
+ $(Q)ansible-playbook $(ANSIBLE_VERBOSE) \
+ --limit 'baseline:dev' \
+ playbooks/vllm.yml \
+ --tags vars,vllm-results,vllm-visualize \
+ --extra-vars=@./extra_vars.yaml
+
+vllm-visualize-results:
+ $(Q)ansible-playbook $(ANSIBLE_VERBOSE) \
+ --limit 'baseline:dev' \
+ playbooks/vllm.yml \
+ --tags vars,vllm-visualize \
+ --extra-vars=@./extra_vars.yaml
+
+vllm-status:
+ @echo "=========================================="
+ @echo "vLLM Deployment Status (Detailed)"
+ @echo "=========================================="
+ @echo ""
+ @echo "--- Ansible Process ---"
+ @ps aux | grep -E "ansible.*vllm" | grep -v grep || echo "No Ansible process running"
+ @echo ""
+ @echo "--- Helm Deployment (on nodes) ---"
+ @ansible all -i hosts -m shell -a "ps aux | grep -E 'helm.*vllm' | grep -v grep || echo 'No helm process running'" 2>/dev/null || echo "Unable to check helm status"
+ @echo ""
+ @echo "--- Kubernetes Cluster Status ---"
+ @ansible all -i hosts -m shell -a "kubectl cluster-info 2>&1 | head -5 || minikube status 2>&1 || echo 'Kubernetes not ready'" 2>/dev/null || echo "Unable to check k8s status"
+ @echo ""
+ @echo "--- Kubernetes Pods ---"
+ @ansible all -i hosts -m shell -a "KUBECONFIG=/root/.kube/config kubectl get pods -A 2>&1 | head -20 || echo 'Cannot get pods'" -b 2>/dev/null || echo "Unable to check pods"
+ @echo ""
+ @echo "--- Helm Releases ---"
+ @ansible all -i hosts -m shell -a "KUBECONFIG=/root/.kube/config helm list -A 2>&1 || echo 'No helm releases'" -b 2>/dev/null || echo "Unable to check helm releases"
+ @echo ""
+ @echo "--- Kubernetes Services ---"
+ @ansible all -i hosts -m shell -a "KUBECONFIG=/root/.kube/config kubectl get svc -n vllm-system 2>&1 | head -10 || echo 'No services found'" -b 2>/dev/null || echo "Unable to check services"
+ @echo ""
+ @echo "--- Docker Containers ---"
+ @ansible all -i hosts -m shell -a "docker ps 2>&1 | head -15 || echo 'Cannot get containers'" 2>/dev/null || echo "Unable to check docker containers"
+ @echo ""
+ @echo "--- Docker Mirror 9P Mount ---"
+ @ansible all -i hosts -m shell -a "mount | grep 9p || echo 'No 9P mounts found'" 2>/dev/null || echo "Unable to check 9P mounts"
+ @echo ""
+ @echo "--- Docker Images (vLLM related) ---"
+ @ansible all -i hosts -m shell -a "docker images | grep -E 'REPOSITORY|vllm|openeuler' | head -20 || echo 'No vLLM images found'" 2>/dev/null || echo "Unable to check docker images"
+ @echo ""
+ @echo "--- Helm Values (Image Configuration) ---"
+ @ansible all -i hosts -m shell -a "grep -E 'repository:|tag:|modelURL:' /data/vllm/prod-stack-values.yaml 2>/dev/null | head -10 || echo 'Values file not found'" 2>/dev/null || echo "Unable to check helm values"
+ @echo ""
+
+vllm-status-simplified:
+ @$(MAKE) -s vllm-status 2>&1 | python3 scripts/vllm-status-summary.py
+
+vllm-quick-test:
+ $(Q)bash scripts/vllm-quick-test.sh
+
+vllm-help-menu:
+ @echo "vLLM Production Stack options:"
+ @echo "vllm - Deploy vLLM stack to Kubernetes"
+ @echo "vllm-deploy - Deploy vLLM stack to Kubernetes (same as vllm)"
+ @echo "vllm-benchmark - Run performance benchmarks and collect results"
+ @echo "vllm-monitor - Display monitoring dashboard URLs"
+ @echo "vllm-status - Check detailed deployment status (verbose)"
+ @echo "vllm-status-simplified - Check deployment status (clean summary)"
+ @echo "vllm-quick-test - Quick API test (baseline + dev if enabled)"
+ @echo "vllm-teardown - Gracefully remove vLLM deployment"
+ @echo "vllm-cleanup - Force delete all vLLM resources (use when stuck)"
+ @echo "vllm-results - Collect and visualize benchmark results"
+ @echo "vllm-visualize-results - Generate HTML visualization of benchmark results"
+ @echo ""
+
+.PHONY: vllm vllm-deploy vllm-benchmark vllm-monitor vllm-status vllm-status-simplified vllm-quick-test vllm-teardown vllm-cleanup vllm-results vllm-visualize-results vllm-help-menu
diff --git a/workflows/vllm/README.md b/workflows/vllm/README.md
new file mode 100644
index 00000000..8335e0c7
--- /dev/null
+++ b/workflows/vllm/README.md
@@ -0,0 +1,322 @@
+# vLLM Production Stack Workflow for kdevops
+
+This workflow integrates the vLLM Production Stack into kdevops, providing automated deployment, testing, and benchmarking of large language models using Kubernetes, Helm, and the vLLM serving engine.
+
+## Understanding vLLM vs vLLM Production Stack
+
+### What is vLLM?
+
+**vLLM** is a high-performance inference engine for large language models, optimized for throughput and memory efficiency on a single node. It provides:
+- Fast inference with PagedAttention for efficient KV cache management
+- Continuous batching for high throughput
+- Optimized CUDA kernels for GPU acceleration
+- OpenAI-compatible API server
+
+
+*Image source: [LMCache Blog - Production Stack Release](https://blog.lmcache.ai/2025-01-21-stack-release/)*
+
+**vLLM excels at single-node inference** but requires additional infrastructure for production deployment at scale.
+
+### What is the vLLM Production Stack?
+
+The **vLLM Production Stack** is the layer **above** vLLM that transforms it from a single-node engine into a cluster-wide serving system. It provides:
+
+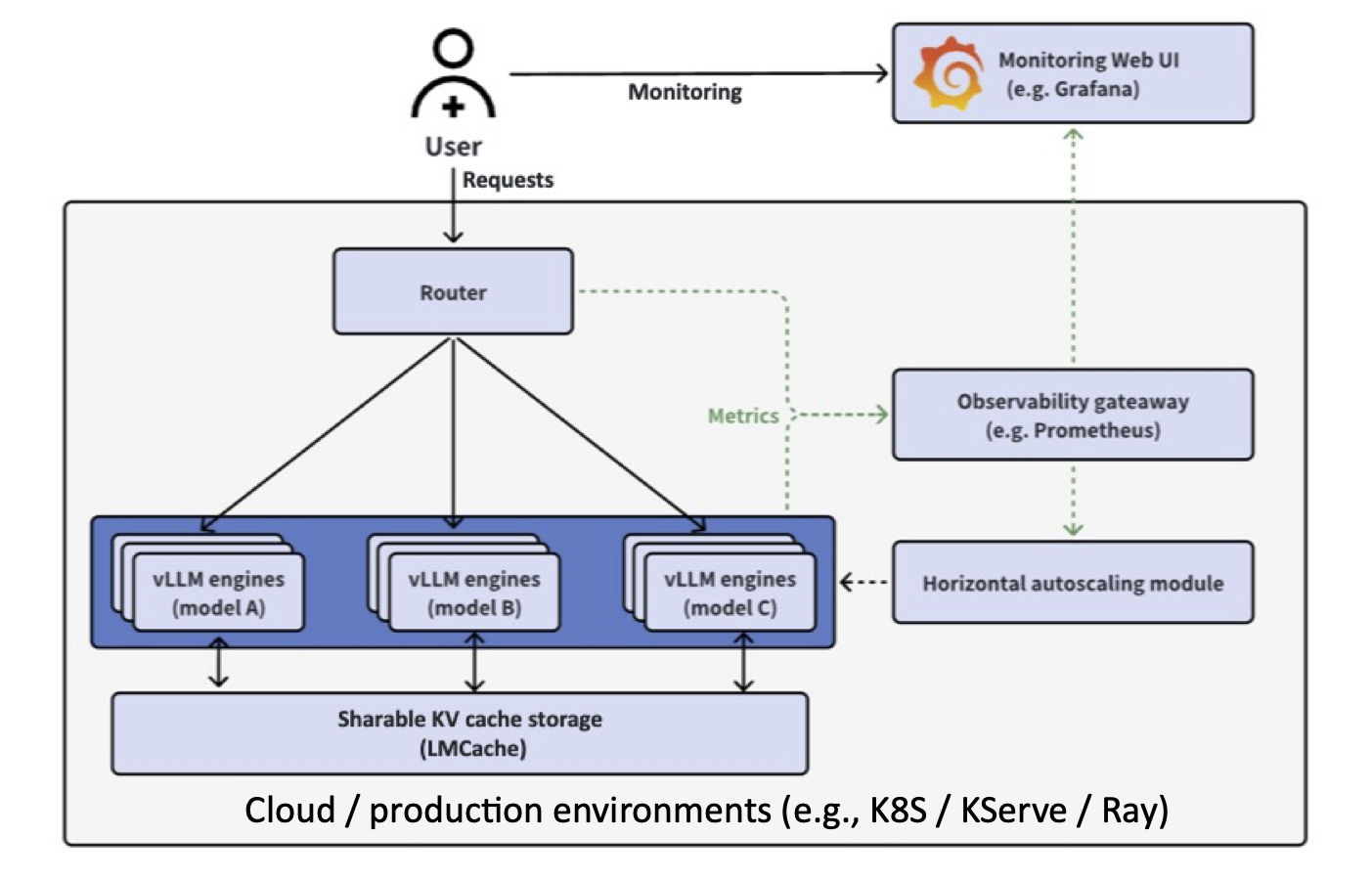
+*Image source: [LMCache Blog - Production Stack Overview](https://blog.lmcache.ai/2025-01-21-stack-release/)*
+
+**Key Components:**
+1. **Request Router**: Intelligent request distribution with prefix-aware routing
+2. **LMCache Integration**: Distributed KV cache sharing across instances (3-10x faster TTFT)
+3. **Observability**: Unified Prometheus/Grafana monitoring
+4. **Autoscaling**: Cluster-wide horizontal pod autoscaling
+5. **Fault Tolerance**: Automated failover and recovery
+
+**Performance Improvements:**
+- 3-10x lower response delay through KV cache reuse
+- 2-5x higher throughput with intelligent routing
+- 10x better overall performance in multi-turn conversations and RAG scenarios
+
+### kdevops' Goals for vLLM Testing
+
+The kdevops vLLM workflow aims to enable easier use, bringup, and automation of testing for **both vLLM and the vLLM Production Stack**, with support for:
+
+#### 1. Minimal Non-GPU VM Testing
+- **Core API Testing**: Validate OpenAI-compatible endpoints with CPU-only inference
+- **Routing Algorithm Testing**: Test round-robin, session affinity, and prefix-aware routing
+- **Scaling Logic Testing**: Verify multi-replica deployment and service discovery
+- **Integration Testing**: Validate router ↔ engine communication without GPU requirements
+
+**Use Cases:**
+- CI/CD pipelines that don't have GPU access
+- Development and testing on laptops and workstations
+- Kernel developers testing infrastructure changes
+- Quick validation of configuration changes
+
+#### 2. Full GPU Deployment & Testing
+- **Production Validation**: Test actual GPU inference performance
+- **LMCache Testing**: Validate distributed KV cache sharing with real workloads
+- **Autoscaling**: Test HPA behavior under GPU load
+- **Performance Benchmarking**: Measure TTFT, throughput, and cache hit rates
+
+**Use Cases:**
+- Performance regression testing
+- GPU driver and kernel development
+- Production deployment validation
+- Benchmark comparison (A/B testing)
+
+#### 3. Automated Deployment & Configuration for CPU testing
+- **One-Command Deployment**: `make defconfig-vllm-production-stack-cpu && make && make bringup && make vllm`
+- **A/B Testing**: Compare baseline vs development configurations automatically
+- **Mirror Support**: Docker registry mirror via 9P for faster deployments
+- **Status Monitoring**: `make vllm-status-simplified` for easy deployment tracking
+
+#### 4. Developer Experience
+- **No GPU Required for Core Testing**: Use `openeuler/vllm-cpu` for CPU inference
+- **Fast Iteration**: Docker mirror caching reduces image pull times
+- **Clear Feedback**: Emoji-rich status output with actionable next steps
+- **Quick Validation**: `make vllm-quick-test` for rapid API smoke testing
+
+### What kdevops Tests
+
+**Production Stack Components (with or without GPU):**
+- ✅ Request router deployment and configuration
+- ✅ Service discovery and endpoint management
+- ✅ Routing algorithms (round-robin, session affinity, prefix-aware)
+- ✅ Multi-replica scaling and load balancing
+- ✅ OpenAI API compatibility
+- ✅ Helm chart deployment and configuration
+- ✅ Kubernetes orchestration (Minikube or existing clusters)
+
+**vLLM Engine (CPU or GPU):**
+- ✅ Model loading and inference
+- ✅ OpenAI-compatible API endpoints
+- ✅ Resource allocation (CPU/Memory/GPU)
+- ✅ Configuration validation (dtype, max-model-len, etc.)
+
+**Optional Features (typically GPU-only):**
+- 🔧 LMCache distributed KV cache sharing
+- 🔧 GPU memory utilization optimization
+- 🔧 Tensor parallelism
+- 🔧 Autoscaling based on GPU metrics
+
+## Overview
+
+The vLLM Production Stack workflow enables:
+- 🚀 Scalable vLLM deployment from single instance to distributed setup
+- 💻 Monitoring through Prometheus and Grafana dashboards
+- 🧪 Testing without GPUs using CPU-optimized vLLM images
+- 🔄 A/B testing support for comparing different configurations
+- 🎯 Request routing with multiple algorithms (round-robin, session affinity, prefix-aware)
+- 💾 Optional KV cache offloading with LMCache (GPU recommended)
+- ⚡ Fast deployment with Docker registry mirror support
+
+## Architecture
+
+The production stack consists of:
+- **vLLM Serving Engines**: Run different LLMs with GPU or CPU inference
+- **Request Router**: Distributes requests across backends with intelligent routing
+- **Observability Stack**: Prometheus + Grafana for metrics monitoring
+- **Kubernetes Orchestration**: Using Minikube or existing clusters
+- **LMCache** (optional): Distributed KV cache sharing for 3-10x performance improvements
+
+### Component Details
+
+#### vLLM Engine Pods
+Each engine pod exposes:
+- **Port 8000**: OpenAI-compatible API (HTTP)
+- **Port 55555**: ZMQ port for distributed inference coordination
+- **Port 9999**: UCX port for RDMA/high-speed KV cache transfer
+
+#### Request Router
+The router pod provides:
+- **Port 80**: HTTP API endpoint (proxied to engines)
+- **Port 9000**: LMCache coordination port for distributed cache management
+
+#### LMCache Architecture
+When enabled (`vllm_lmcache_enabled: true`):
+- **LMCache Engine**: Runs inside each vLLM pod, manages local KV cache
+- **Distributed Cache**: Engines communicate via ZMQ (port 55555) and UCX (port 9999) for peer-to-peer KV cache sharing
+- **Router Coordination**: Router uses port 9000 to coordinate which engine has cached KVs for a given prefix
+- **Cache Offloading**: Can offload KV cache from GPU to CPU memory or disk when GPU memory is full
+
+**Workflow**:
+```
+1. Client request → Router:80
+2. Router checks LMCache:9000 for cache hit location
+3. Router directs request to engine with matching prefix cache
+4. Engines share KV cache via ZMQ/UCX if needed
+5. Response returned through router
+```
+
+**Note**: LMCache is currently disabled in the default configuration (`vllm_lmcache_enabled: False`) but can be enabled via menuconfig for testing distributed KV cache scenarios.
+
+## Quick Start
+
+### 1. Configure the Workflow
+
+```bash
+# For standard deployment
+make defconfig-vllm
+
+# For quick testing with reduced resources
+make defconfig-vllm-quick-test
+```
+
+### 2. Provision Infrastructure
+
+```bash
+make bringup
+```
+
+### 3. Deploy vLLM Stack
+
+```bash
+# Deploy and run complete workflow
+make vllm
+
+# Or run individual components:
+make vllm-deploy # Deploy stack to Kubernetes
+make vllm-benchmark # Run performance benchmarks
+make vllm-monitor # Display monitoring URLs
+make vllm-results # View benchmark results
+make vllm-teardown # Remove deployment
+```
+
+## Configuration Options
+
+Key configuration parameters (set via `make menuconfig`):
+
+### Deployment Options
+- `VLLM_K8S_MINIKUBE`: Use Minikube for local development
+- `VLLM_K8S_EXISTING`: Use existing Kubernetes cluster
+- `VLLM_HELM_RELEASE_NAME`: Helm release name (default: "vllm")
+- `VLLM_HELM_NAMESPACE`: Kubernetes namespace (default: "vllm-system")
+
+### Model Configuration
+- `VLLM_MODEL_URL`: HuggingFace model ID or local path
+- `VLLM_MODEL_NAME`: Model alias for API requests
+- `VLLM_REPLICA_COUNT`: Number of engine replicas
+
+### Resource Configuration
+- `VLLM_REQUEST_CPU`: CPU cores per replica
+- `VLLM_REQUEST_MEMORY`: Memory per replica (e.g., "16Gi")
+- `VLLM_REQUEST_GPU`: GPUs per replica
+- `VLLM_GPU_TYPE`: Optional GPU type specification
+
+### vLLM Engine Settings
+- `VLLM_MAX_MODEL_LEN`: Maximum sequence length
+- `VLLM_DTYPE`: Model data type (auto, half, float16, bfloat16)
+- `VLLM_GPU_MEMORY_UTILIZATION`: GPU memory fraction (0.0-1.0)
+- `VLLM_TENSOR_PARALLEL_SIZE`: Tensor parallelism degree
+
+### Performance Features
+- `VLLM_ENABLE_PREFIX_CACHING`: Enable prefix caching
+- `VLLM_ENABLE_CHUNKED_PREFILL`: Enable chunked prefill
+- `VLLM_LMCACHE_ENABLED`: Enable KV cache offloading
+
+### Routing Configuration
+- `VLLM_ROUTER_ENABLED`: Enable request router
+- `VLLM_ROUTER_ROUND_ROBIN`: Round-robin routing
+- `VLLM_ROUTER_SESSION_AFFINITY`: Session-based routing
+- `VLLM_ROUTER_PREFIX_AWARE`: Prefix-aware routing
+
+### Observability
+- `VLLM_OBSERVABILITY_ENABLED`: Enable Prometheus/Grafana
+- `VLLM_GRAFANA_PORT`: Grafana dashboard port
+- `VLLM_PROMETHEUS_PORT`: Prometheus port
+
+### Benchmarking
+- `VLLM_BENCHMARK_ENABLED`: Enable benchmarking
+- `VLLM_BENCHMARK_DURATION`: Test duration in seconds
+- `VLLM_BENCHMARK_CONCURRENT_USERS`: Concurrent users to simulate
+
+## A/B Testing
+
+The workflow supports A/B testing for comparing different configurations:
+
+1. Enable baseline and dev nodes in configuration
+2. Deploy different configurations to each node group
+3. Run benchmarks and compare results
+
+## Supported Models
+
+The workflow supports any HuggingFace model compatible with vLLM, including:
+- facebook/opt-125m (default, lightweight for testing)
+- meta-llama/Llama-2-7b-hf (requires HF token)
+- mistralai/Mistral-7B-v0.1
+- And many more...
+
+## Monitoring
+
+When observability is enabled, access monitoring dashboards:
+
+```bash
+# Get dashboard URLs
+make vllm-monitor
+
+# For Minikube, use port forwarding:
+kubectl port-forward -n vllm-system svc/vllm-grafana 3000:3000
+kubectl port-forward -n vllm-system svc/vllm-prometheus 9090:9090
+```
+
+Dashboard metrics include:
+- Available vLLM instances
+- Request latency distribution
+- Time-to-first-token (TTFT)
+- Active/pending requests
+- GPU KV cache usage and hit rates
+
+## Troubleshooting
+
+### Common Issues
+
+1. **Insufficient Resources**: Ensure nodes have adequate CPU/memory/GPU
+2. **Model Download**: Large models require time and bandwidth to download
+3. **GPU Access**: Verify GPU drivers and Kubernetes GPU plugin installation
+4. **Port Conflicts**: Check ports 8000, 3000, 9090 are available
+
+### Debug Commands
+
+```bash
+# Check pod status
+kubectl get pods -n vllm-system
+
+# View pod logs
+kubectl logs -n vllm-system <pod-name>
+
+# Describe deployment
+kubectl describe deployment -n vllm-system vllm
+
+# Check Helm release
+helm list -n vllm-system
+```
+
+## Integration with kdevops Workflows
+
+The vLLM workflow integrates with kdevops features:
+- Uses standard kdevops node provisioning
+- Supports terraform/libvirt backends
+- Compatible with kernel development workflows
+- Integrates with CI/CD pipelines
+
+## Contributing
+
+To modify or extend the vLLM workflow:
+
+1. Edit workflow configuration: `workflows/vllm/Kconfig`
+2. Modify Makefile targets: `workflows/vllm/Makefile`
+3. Update Ansible playbooks: `playbooks/vllm.yml`
+4. Add node generation rules: `playbooks/roles/gen_nodes/tasks/main.yml`
+
+## References
+
+### vLLM and Production Stack
+- [vLLM Production Stack Repository](https://github.com/vllm-project/production-stack)
+- [Production Stack Release Announcement](https://blog.lmcache.ai/2025-01-21-stack-release/) - Explains the rationale and architecture
+- [vLLM Documentation](https://docs.vllm.ai)
+- [Production Stack Documentation](https://docs.vllm.ai/projects/production-stack)
+- [LMCache Documentation](https://docs.lmcache.ai)
+
+### kdevops
+- [kdevops Documentation](https://github.com/linux-kdevops/kdevops)
+- [kdevops vLLM Workflow](https://github.com/linux-kdevops/kdevops/tree/main/workflows/vllm)
--
2.51.0
^ permalink raw reply related [flat|nested] 13+ messages in thread{kind=link}
{kind=link}