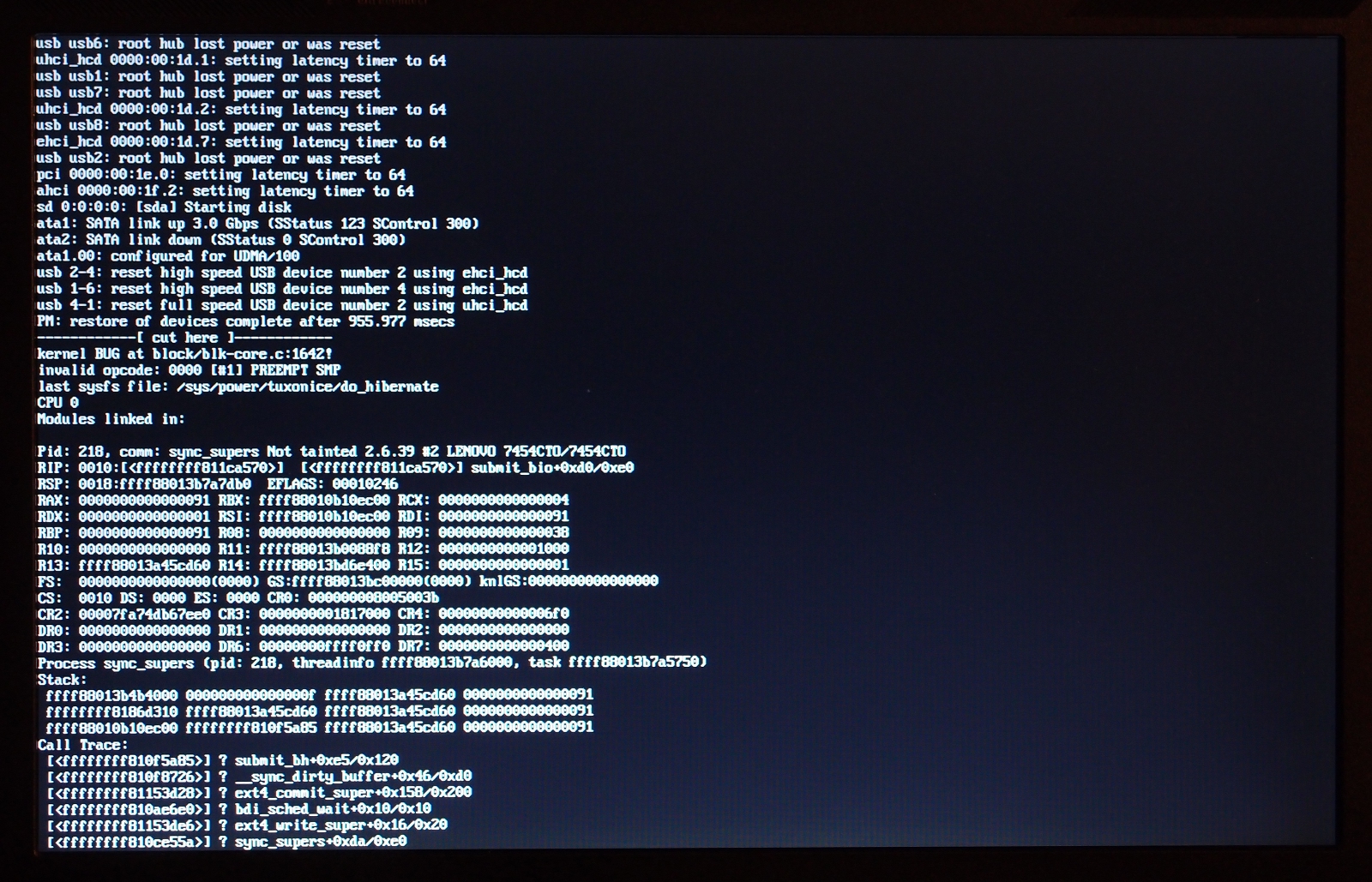
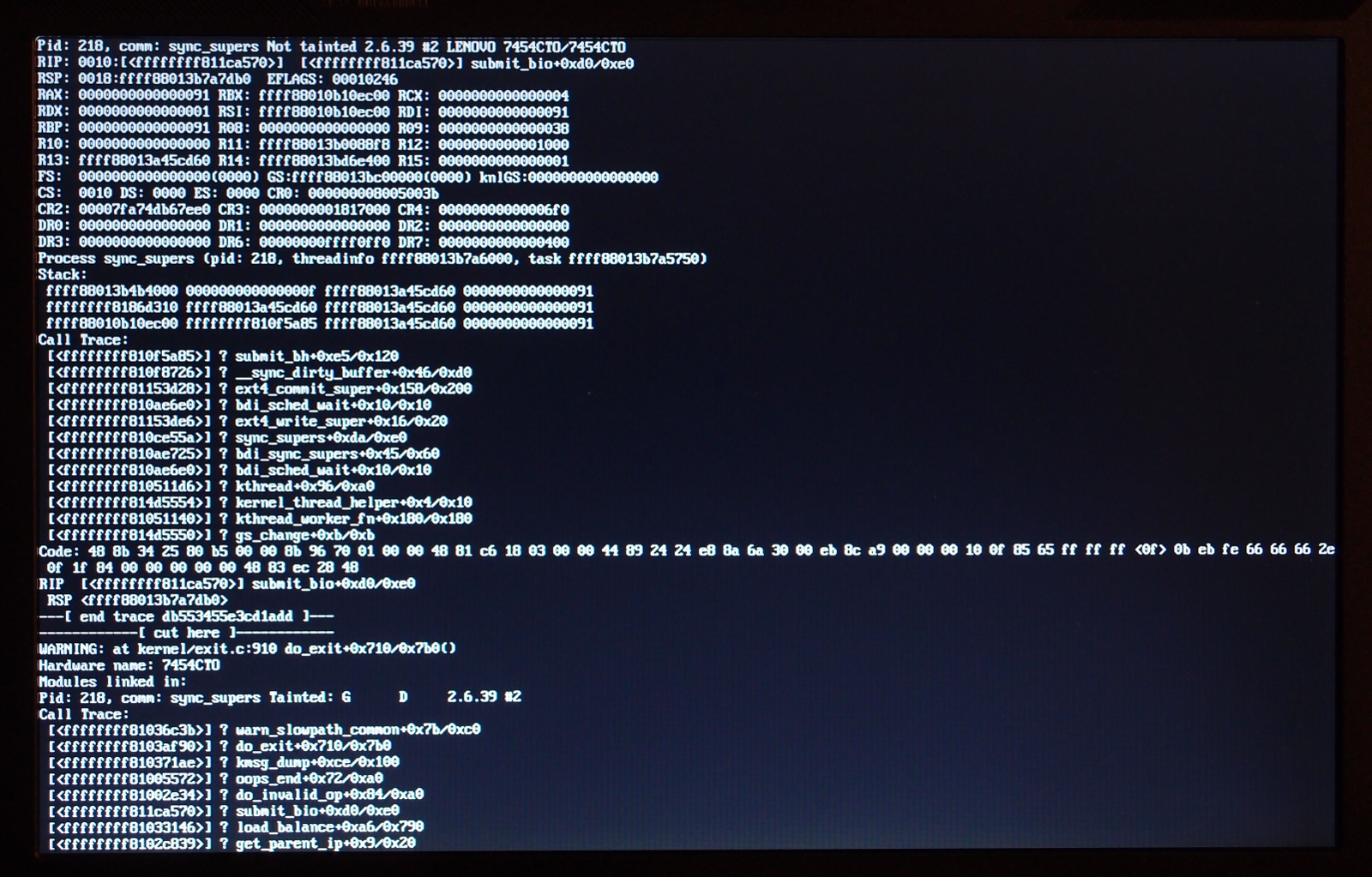
* Re: Repeatable md OOPS on suspend, 2.6.39.4 and 3.0.3 [not found] ` <loom.20110906T201030-97@post.gmane.org> @ 2011-09-09 12:55 ` Nix 2011-09-14 23:32 ` Nigel Cunningham 0 siblings, 1 reply; 6+ messages in thread From: Nix @ 2011-09-09 12:55 UTC (permalink / raw) To: TuxOnIce users' list; +Cc: linux-raid, Neil Brown On 6 Sep 2011, Vitaly Minko spake thusly: > Matt Graham <danceswithcrows <at> gmail.com> writes: > >> Vitaly, could you get a picture of the OOPS you get? > > For 2.6.39: > http://vminko.org/storage/toi_oops/photo0.jpg > http://vminko.org/storage/toi_oops/photo1.jpg That's a different oops from the one I started seeing in 2.6.39. (I use md1 for every filesystem, but not for swap.) I see an oops-panic-and-reboot with this backtrace right before what would normally be the post-hibernation powerdown, plainly an attempt to submit a bio for an md superblock write after the blockdev has been frozen: panic+0x0a/0x1a6 oops_end+0x86/0x93 die+0x5a/0x66 do_trap+0x121/0x130 do_invalid_op+0x96/0x9f ? submit_bio+0x33/0xf8 invalid_op+0x15/0x20 ? submit_bio+0x33/0xf8 md_super_write+0x85/0x94 md_update_sb+0x253/0x2f4 __md_stop_writes+0x73/0x77 md_set_readonly+0x7a/0xcc md_notify_reboot+0x64/0xce notifier_call_chain+0x37/0x63 __blocking_notifier_call_chain+0x4b/0x60 blocking_notifier_call_chain+0x14/0x16 kernel_shutdown_prepare+0x2b/0x3f kernel_power_off+0x13/0x4a __toi_power_down+0xef/0x133 ? memory_bm_next_pfn+0x10/0x12 do_toi_step+0x608/0x700 toi_try_hibernate+0x108/0x145 toi_main_wrapper+0xe/0x10 toi_attr_store+0x203/0x256 sysfs_write_file+0xf4/0x130 vfs_write+0xb5/0x151 sys_write+0x4a/0x71 system_call_fastpath+0x16/0x1b The cause is plainly this, in md_set_readonly(): if (!mddev->in_sync || mddev->flags) { /* mark array as shutdown cleanly */ mddev->in_sync = 1; md_update_sb(mddev, 1); } which you juwt can't do once the blockdev has been frozen. -- not that I'm terribly clear on what we *should* do: mark the array as shut down at the same moment as we suspend the first of the blockdevs that makes it up, perhaps? Neil will know, he knows everything. >> I guess it won't >> have md_super_write anywhere, but it'd be interesting to see where the >> common elements are. > > Actually the call trace is completely different. Not mine. We may have two different bugs. But as with yours, the oops above started in the 2.6.39.x era. -- NULL && (void) ^ permalink raw reply [flat|nested] 6+ messages in thread
* Re: Repeatable md OOPS on suspend, 2.6.39.4 and 3.0.3 2011-09-09 12:55 ` Repeatable md OOPS on suspend, 2.6.39.4 and 3.0.3 Nix @ 2011-09-14 23:32 ` Nigel Cunningham 2011-09-15 3:31 ` [TuxOnIce-users] " NeilBrown 2011-09-15 5:34 ` Nix 0 siblings, 2 replies; 6+ messages in thread From: Nigel Cunningham @ 2011-09-14 23:32 UTC (permalink / raw) To: TuxOnIce users' list; +Cc: linux-raid, Neil Brown [-- Attachment #1: Type: text/plain, Size: 488 bytes --] Hi. Please try/review the attached patch. The problem is that TuxOnIce adds a BUG_ON() to catch non-TuxOnIce I/O during hibernation, as a method of seeking to stop on-disk data getting corrupted by the writing of data that has potentially been overwritten by the atomic copy. Stopping the md devices from being marked readonly is the right thing to do - if we don't resume, we want recovery to be run. If we do resume, they should still be in the pre-hibernate state. Regards, Nigel [-- Attachment #2: md-reboot-mark-readonly.patch --] [-- Type: text/x-diff, Size: 478 bytes --] diff --git a/drivers/md/md.c b/drivers/md/md.c index af0e52c..25af0a8 100644 --- a/drivers/md/md.c +++ b/drivers/md/md.c @@ -8056,7 +8056,7 @@ static int md_notify_reboot(struct notifier_block *this, struct list_head *tmp; mddev_t *mddev; - if ((code == SYS_DOWN) || (code == SYS_HALT) || (code == SYS_POWER_OFF)) { + if (((code == SYS_DOWN) || (code == SYS_HALT) || (code == SYS_POWER_OFF)) && !freezer_state) { printk(KERN_INFO "md: stopping all md devices.\n"); [-- Attachment #3: Type: text/plain, Size: 159 bytes --] _______________________________________________ TuxOnIce-users mailing list TuxOnIce-users@lists.tuxonice.net http://lists.tuxonice.net/listinfo/tuxonice-users ^ permalink raw reply related [flat|nested] 6+ messages in thread
* Re: [TuxOnIce-users] Repeatable md OOPS on suspend, 2.6.39.4 and 3.0.3 2011-09-14 23:32 ` Nigel Cunningham @ 2011-09-15 3:31 ` NeilBrown 2011-09-15 4:18 ` Nigel Cunningham 2011-09-15 5:34 ` Nix 1 sibling, 1 reply; 6+ messages in thread From: NeilBrown @ 2011-09-15 3:31 UTC (permalink / raw) To: Nigel Cunningham; +Cc: TuxOnIce users' list, Nix, linux-raid [-- Attachment #1: Type: text/plain, Size: 1327 bytes --] On Thu, 15 Sep 2011 09:32:10 +1000 Nigel Cunningham <nigel@tuxonice.net> wrote: > Hi. > > Please try/review the attached patch. > > The problem is that TuxOnIce adds a BUG_ON() to catch non-TuxOnIce I/O > during hibernation, as a method of seeking to stop on-disk data getting > corrupted by the writing of data that has potentially been overwritten > by the atomic copy. > > Stopping the md devices from being marked readonly is the right thing to > do - if we don't resume, we want recovery to be run. If we do resume, > they should still be in the pre-hibernate state. > > Regards, > > Nigel This doesn't feel like the right approach to me. I think the 'md' device *should* be marked 'clean' when it is clean to avoid unnecessary resyncs. It would almost certainly make sense to have a way to tell md 'hibernate wrote to your device so things might have changed - you should check'. Then md could look at the metadata and refresh any in-memory information such as device failures and event counts. After all if a device fails while writing out the hibernation image, we want the hibernation to succeed (I assume) and we want md to know that the device is failed when it wakes back up, and currently it won't. So we really need that notification anyway. ?? Thanks, NeilBrown [-- Attachment #2: signature.asc --] [-- Type: application/pgp-signature, Size: 190 bytes --] ^ permalink raw reply [flat|nested] 6+ messages in thread
* Re: Repeatable md OOPS on suspend, 2.6.39.4 and 3.0.3 2011-09-15 3:31 ` [TuxOnIce-users] " NeilBrown @ 2011-09-15 4:18 ` Nigel Cunningham 2011-09-15 5:38 ` Nix 0 siblings, 1 reply; 6+ messages in thread From: Nigel Cunningham @ 2011-09-15 4:18 UTC (permalink / raw) To: NeilBrown; +Cc: linux-raid, TuxOnIce users' list Hi. On 15/09/11 13:31, NeilBrown wrote: > On Thu, 15 Sep 2011 09:32:10 +1000 Nigel Cunningham <nigel@tuxonice.net> > wrote: > >> Hi. >> >> Please try/review the attached patch. >> >> The problem is that TuxOnIce adds a BUG_ON() to catch non-TuxOnIce I/O >> during hibernation, as a method of seeking to stop on-disk data getting >> corrupted by the writing of data that has potentially been overwritten >> by the atomic copy. >> >> Stopping the md devices from being marked readonly is the right thing to >> do - if we don't resume, we want recovery to be run. If we do resume, >> they should still be in the pre-hibernate state. >> >> Regards, >> >> Nigel > > This doesn't feel like the right approach to me. > > I think the 'md' device *should* be marked 'clean' when it is clean to > avoid unnecessary resyncs. I must be missing something. In raid terminology, what does 'clean' mean? Googling gives me lots of references to flyspray :) I thought it meant the filesystems contained therein were cleanly unmounted (which it isn't in this case). Just 'cleanly shutdown'? > It would almost certainly make sense to have a way to tell md 'hibernate > wrote to your device so things might have changed - you should check'. > Then md could look at the metadata and refresh any in-memory information > such as device failures and event counts. > After all if a device fails while writing out the hibernation image, we want > the hibernation to succeed (I assume) and we want md to know that the device > is failed when it wakes back up, and currently it won't. So we really need > that notification anyway. Now that I understand and agree with. Regards, Nigel -- Evolution (n): A hypothetical process whereby improbable events occur with alarming frequency, order arises from chaos, and no one is given credit. ^ permalink raw reply [flat|nested] 6+ messages in thread
* Re: Repeatable md OOPS on suspend, 2.6.39.4 and 3.0.3 2011-09-15 4:18 ` Nigel Cunningham @ 2011-09-15 5:38 ` Nix 0 siblings, 0 replies; 6+ messages in thread From: Nix @ 2011-09-15 5:38 UTC (permalink / raw) To: Nigel Cunningham; +Cc: NeilBrown, linux-raid, TuxOnIce users' list On 15 Sep 2011, Nigel Cunningham outgrape: > Hi. > > On 15/09/11 13:31, NeilBrown wrote: >> I think the 'md' device *should* be marked 'clean' when it is clean to >> avoid unnecessary resyncs. > > I must be missing something. In raid terminology, what does 'clean' > mean? Googling gives me lots of references to flyspray :) I thought it > meant the filesystems contained therein were cleanly unmounted (which it > isn't in this case). Just 'cleanly shutdown'? It's got nothing to do with filesystems. Just 'all writes that were issued to this array have reached all constituent devices in the array'. (Which one hopes they have if we're about to power down!) Thus, if an array is dirty, one or more writes is presumed to have not got to one or more devices, so a resync is required. (The update of the superblock's state from dirty to clean is done lazily because the state changes very frequently and it means another write, so arrays can be briefly marked dirty if they are in fact clean, but should never be marked clean if they are in fact dirty.) -- NULL && (void) ^ permalink raw reply [flat|nested] 6+ messages in thread
* Re: Repeatable md OOPS on suspend, 2.6.39.4 and 3.0.3 2011-09-14 23:32 ` Nigel Cunningham 2011-09-15 3:31 ` [TuxOnIce-users] " NeilBrown @ 2011-09-15 5:34 ` Nix 1 sibling, 0 replies; 6+ messages in thread From: Nix @ 2011-09-15 5:34 UTC (permalink / raw) To: Nigel Cunningham; +Cc: linux-raid, Neil Brown, TuxOnIce users' list On 15 Sep 2011, Nigel Cunningham stated: > Please try/review the attached patch. That works perfectly. No oops, no panic, md a happy bunny on resume. (Haven't tried non-resuming a hibernated kernel on the grounds that I'd rather not kick off an umpty hour long automatic array rebuild right now.) -- NULL && (void) ^ permalink raw reply [flat|nested] 6+ messages in thread
end of thread, other threads:[~2011-09-15 5:38 UTC | newest]
Thread overview: 6+ messages (download: mbox.gz follow: Atom feed
-- links below jump to the message on this page --
[not found] <CALxPEfw-XdcosHemovkxj9aOwaYxUaQ6dj=yMaKCmoy2vkkUkg@mail.gmail.com>
[not found] ` <loom.20110901T032036-733@post.gmane.org>
[not found] ` <CALxPEfwJ99bvmSXkqSKutAYbcD9OLcyMcKQQO6G+Yxi9RQ1DFA@mail.gmail.com>
[not found] ` <CALxPEfyQrwWh1AWY-fwwCeMzDEeK390Eof9PwrsN6C11Wnt9=A@mail.gmail.com>
[not found] ` <loom.20110906T201030-97@post.gmane.org>
2011-09-09 12:55 ` Repeatable md OOPS on suspend, 2.6.39.4 and 3.0.3 Nix
2011-09-14 23:32 ` Nigel Cunningham
2011-09-15 3:31 ` [TuxOnIce-users] " NeilBrown
2011-09-15 4:18 ` Nigel Cunningham
2011-09-15 5:38 ` Nix
2011-09-15 5:34 ` Nix
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox; as well as URLs for NNTP newsgroup(s).
{kind=link}
{kind=link}