* Volanomark slows by 80% under CFS
@ 2007-07-27 22:01 Tim Chen
2007-07-28 0:31 ` Chris Snook
` (3 more replies)
0 siblings, 4 replies; 18+ messages in thread
From: Tim Chen @ 2007-07-27 22:01 UTC (permalink / raw)
To: mingo; +Cc: linux-kernel
[-- Attachment #1: Type: text/plain, Size: 1141 bytes --]
Ingo,
Volanomark slows by 80% with CFS scheduler on 2.6.23-rc1.
Benchmark was run on a 2 socket Core2 machine.
The change in scheduler treatment of sched_yield
could play a part in changing Volanomark behavior.
In CFS, sched_yield is implemented
by dequeueing and requeueing a process . The time a process
has spent running probably reduced the the cpu time due it
by only a bit. The process could get re-queued pretty close
to head of the queue, and may get scheduled again pretty
quickly if there is still a lot of cpu time due.
It may make sense to queue the
yielding process a bit further behind in the queue.
I made a slight change by zeroing out wait_runtime
(i.e. have the process gives
up cpu time due for it to run) for experimentation.
Let's put aside gripes that Volanomark should have used a
better mechanism to coordinate threads instead sched_yield for
a second. Volanomark runs better
and is only 40% (instead of 80%) down from old scheduler
without CFS.
Of course we should not tune for Volanomark and this is
reference data.
What are your view on how CFS's sched_yield should behave?
Regards,
Tim
[-- Attachment #2: patch.sched_yield --]
[-- Type: text/plain, Size: 336 bytes --]
--- linux-2.6.23-rc1/kernel/sched_fair.c.orig 2007-07-27 09:39:11.000000000 -0700
+++ linux-2.6.23-rc1/kernel/sched_fair.c 2007-07-27 09:40:41.000000000 -0700
@@ -841,6 +841,7 @@
* position within the tree:
*/
dequeue_entity(cfs_rq, &p->se, 0, now);
+ p->se.wait_runtime = 0;
enqueue_entity(cfs_rq, &p->se, 0, now);
}
^ permalink raw reply [flat|nested] 18+ messages in thread* Re: Volanomark slows by 80% under CFS 2007-07-27 22:01 Volanomark slows by 80% under CFS Tim Chen @ 2007-07-28 0:31 ` Chris Snook 2007-07-28 0:59 ` Andrea Arcangeli 2007-07-28 13:28 ` Volanomark slows by 80% under CFS Dmitry Adamushko 2007-07-28 2:47 ` Rik van Riel ` (2 subsequent siblings) 3 siblings, 2 replies; 18+ messages in thread From: Chris Snook @ 2007-07-28 0:31 UTC (permalink / raw) To: tim.c.chen; +Cc: mingo, linux-kernel Tim Chen wrote: > Ingo, > > Volanomark slows by 80% with CFS scheduler on 2.6.23-rc1. > Benchmark was run on a 2 socket Core2 machine. > > The change in scheduler treatment of sched_yield > could play a part in changing Volanomark behavior. > In CFS, sched_yield is implemented > by dequeueing and requeueing a process . The time a process > has spent running probably reduced the the cpu time due it > by only a bit. The process could get re-queued pretty close > to head of the queue, and may get scheduled again pretty > quickly if there is still a lot of cpu time due. > > It may make sense to queue the > yielding process a bit further behind in the queue. > I made a slight change by zeroing out wait_runtime > (i.e. have the process gives > up cpu time due for it to run) for experimentation. > Let's put aside gripes that Volanomark should have used a > better mechanism to coordinate threads instead sched_yield for > a second. Volanomark runs better > and is only 40% (instead of 80%) down from old scheduler > without CFS. > > Of course we should not tune for Volanomark and this is > reference data. > What are your view on how CFS's sched_yield should behave? > > Regards, > Tim The primary purpose of sched_yield is for SCHED_FIFO realtime processes. Where nothing else will run, ever, unless the running thread blocks or yields the CPU. Under CFS, the yielding process will still be leftmost in the rbtree, otherwise it would have already been scheduled out. Zeroing out wait_runtime on sched_yield strikes me as completely appropriate. If the process wanted to sleep a finite duration, it should actually call a sleep function, but sched_yield is essentially saying "I don't have anything else to do right now", so it's hardly fair to claim you've been waiting for your chance when you just gave it up. As for the remaining 40% degradation, if Volanomark is using it for synchronization, the scheduler is probably cycling through threads until it gets to the one that actually wants to do work. The O(1) scheduler will do this very quickly, whereas CFS has a bit more overhead. Interactivity boosting may have also helped the old scheduler find the right thread faster. I think Volanomark is being pretty stupid, and deserves to run slowly, but there are legitimate reasons to want to call sched_yield in a non-SCHED_FIFO process. If I'm performing multiple different calculations on the same set of data in multiple threads, and accessing the shared data in a linear fashion, I'd like to be able to have one thread give the other some CPU time so they can stay at the same point in the stream and improve cache hit rates, but this is only an optimization if I can do it without wasting CPU or gradually nicing myself into oblivion. Having sched_yield zero out wait_runtime seems like an appropriate way to make this use case work to the extent possible. Any user attempting such an optimization should have the good sense to do real work between sched_yield calls, to avoid calling the scheduler in a tight loop. -- Chris ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: Volanomark slows by 80% under CFS 2007-07-28 0:31 ` Chris Snook @ 2007-07-28 0:59 ` Andrea Arcangeli 2007-07-28 3:43 ` pluggable scheduler flamewar thread (was Re: Volanomark slows by 80% under CFS) Chris Snook 2007-07-28 13:28 ` Volanomark slows by 80% under CFS Dmitry Adamushko 1 sibling, 1 reply; 18+ messages in thread From: Andrea Arcangeli @ 2007-07-28 0:59 UTC (permalink / raw) To: Chris Snook; +Cc: tim.c.chen, mingo, linux-kernel On Fri, Jul 27, 2007 at 08:31:19PM -0400, Chris Snook wrote: > I think Volanomark is being pretty stupid, and deserves to run slowly, but Indeed, any app doing what volanomark does is pretty inefficient. But this is not the point. I/O schedulers are pluggable to help for inefficient apps too. If apps would be extremely smart they would all use async-io for their reads, and there wouldn't be the need of anticipatory scheduler just for an example. The fact is there's no technical explanation for which we're forbidden to be able to choose between CFS and O(1) at least at boot time. ^ permalink raw reply [flat|nested] 18+ messages in thread
* pluggable scheduler flamewar thread (was Re: Volanomark slows by 80% under CFS) 2007-07-28 0:59 ` Andrea Arcangeli @ 2007-07-28 3:43 ` Chris Snook 2007-07-28 5:01 ` pluggable scheduler " Andrea Arcangeli 0 siblings, 1 reply; 18+ messages in thread From: Chris Snook @ 2007-07-28 3:43 UTC (permalink / raw) To: Andrea Arcangeli; +Cc: tim.c.chen, mingo, linux-kernel Andrea Arcangeli wrote: > On Fri, Jul 27, 2007 at 08:31:19PM -0400, Chris Snook wrote: >> I think Volanomark is being pretty stupid, and deserves to run slowly, but > > Indeed, any app doing what volanomark does is pretty inefficient. > > But this is not the point. I/O schedulers are pluggable to help for > inefficient apps too. If apps would be extremely smart they would all > use async-io for their reads, and there wouldn't be the need of > anticipatory scheduler just for an example. I'm pretty sure the point of posting a patch that triples CFS performance on a certain benchmark and arguably improves the semantics of sched_yield was to improve CFS. You have a point, but it is a point for a different thread. I have taken the liberty of starting this thread for you. > The fact is there's no technical explanation for which we're forbidden > to be able to choose between CFS and O(1) at least at boot time. Sure there is. We can run a fully-functional POSIX OS without using any block devices at all. We cannot run a fully-functional POSIX OS without a scheduler. Any feature without which the OS cannot execute userspace code is sufficiently primitive that somewhere there is a device on which it will be impossible to debug if that feature fails to initialize. It is quite reasonable to insist on only having one implementation of such features in any given kernel build. Whether or not these alternatives belong in the source tree as config-time options is a political question, but preserving boot-time debugging capability is a perfectly reasonable technical motivation. -- Chris ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: pluggable scheduler thread (was Re: Volanomark slows by 80% under CFS) 2007-07-28 3:43 ` pluggable scheduler flamewar thread (was Re: Volanomark slows by 80% under CFS) Chris Snook @ 2007-07-28 5:01 ` Andrea Arcangeli 2007-07-28 6:51 ` Chris Snook 0 siblings, 1 reply; 18+ messages in thread From: Andrea Arcangeli @ 2007-07-28 5:01 UTC (permalink / raw) To: Chris Snook; +Cc: tim.c.chen, mingo, linux-kernel On Fri, Jul 27, 2007 at 11:43:23PM -0400, Chris Snook wrote: > I'm pretty sure the point of posting a patch that triples CFS performance > on a certain benchmark and arguably improves the semantics of sched_yield > was to improve CFS. You have a point, but it is a point for a different > thread. I have taken the liberty of starting this thread for you. I've no real interest in starting or participating in flamewars (especially the ones not backed by hard numbers). So I adjusted the subject a bit in the hope the discussion will not degenerate as you predicted, hope you don't mind. I'm pretty sure the point of posting that email was to show the remaining performance regression with the sched_yield fix applied too. Given you considered my post both offtopic and inflammatory, I guess you think it's possible and reasonably easy to fix that remaining regression without a pluggable scheduler, right? So please enlighten us on your intend to achieve it. Also consider the other numbers likely used nptl so they shouldn't be affected by sched_yield changes. > Sure there is. We can run a fully-functional POSIX OS without using any > block devices at all. We cannot run a fully-functional POSIX OS without a > scheduler. Any feature without which the OS cannot execute userspace code > is sufficiently primitive that somewhere there is a device on which it will > be impossible to debug if that feature fails to initialize. It is quite > reasonable to insist on only having one implementation of such features in > any given kernel build. Sounds like a red-herring to me... There aren't just pluggable I/O schedulers in the kernel, there are pluggable packet schedulers too (see `tc qdisc`). And both are switchable at runtime (not just at boot time). Can you run your fully-functional POSIX OS without a packet scheduler and without an I/O scheduler? I wonder where are you going to read/write data without HD and network? Also those pluggable things don't increase the risk of crash much, if compared to the complexity of the schedulers. > Whether or not these alternatives belong in the source tree as config-time > options is a political question, but preserving boot-time debugging > capability is a perfectly reasonable technical motivation. The scheduler is invoked very late in the boot process (printk and serial console, kdb are working for ages when scheduler kicks in), so it's fully debuggable (no debugger depends on the scheduler, they run inside the nmi handler...), I don't really see your point. And even if there would be a subtle bug in the scheduler you'll never trigger it at boot with so few tasks and so few context switches. ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: pluggable scheduler thread (was Re: Volanomark slows by 80% under CFS) 2007-07-28 5:01 ` pluggable scheduler " Andrea Arcangeli @ 2007-07-28 6:51 ` Chris Snook 2007-07-30 18:49 ` Tim Chen 0 siblings, 1 reply; 18+ messages in thread From: Chris Snook @ 2007-07-28 6:51 UTC (permalink / raw) To: Andrea Arcangeli; +Cc: tim.c.chen, mingo, linux-kernel Andrea Arcangeli wrote: > On Fri, Jul 27, 2007 at 11:43:23PM -0400, Chris Snook wrote: >> I'm pretty sure the point of posting a patch that triples CFS performance >> on a certain benchmark and arguably improves the semantics of sched_yield >> was to improve CFS. You have a point, but it is a point for a different >> thread. I have taken the liberty of starting this thread for you. > > I've no real interest in starting or participating in flamewars > (especially the ones not backed by hard numbers). So I adjusted the > subject a bit in the hope the discussion will not degenerate as you > predicted, hope you don't mind. Not at all. I clearly misread your tone. > I'm pretty sure the point of posting that email was to show the > remaining performance regression with the sched_yield fix applied > too. Given you considered my post both offtopic and inflammatory, I > guess you think it's possible and reasonably easy to fix that > remaining regression without a pluggable scheduler, right? So please > enlighten us on your intend to achieve it. There are four possibilities that are immediately obvious to me: a) The remaining difference is due mostly to the algorithmic complexity of the rbtree algorithm in CFS. If this is the case, we should be able to vary the test parameters (CPU count, thread count, etc.) graph the results, and see a roughly logarithmic divergence between the schedulers as some parameter(s) vary. If this is the problem, we may be able to fix it with data structure tweaks or optimized base cases, like how quicksort can be optimized by using insertion sort below a certain threshold. b) The remaining difference is due mostly to how the scheduler handles volanomark. vmstat can give us a comparison of context switches between O(1), CFS, and CFS+patch. If the decrease in throughput correlates with an increase in context switches, we may be able to induce more O(1)-like behavior by charging tasks for context switch overhead. c) The remaining difference is due mostly to how the scheduler handles something other than volanomark. If context switch count is not the problem, context switch pattern still could be. I doubt we'd see a 40% difference due to cache misses, but it's possible. Fortunately, oprofile can sample based on cache misses, so we can debug this too. d) The remaining difference is due mostly to some implementation detail in CFS. It's possible there's some constant-factor overhead in CFS that is magnified heavily by the context switching volanomark deliberately induces. If this is the case, oprofile sampling on clock cycles should catch it. Tim -- Since you're already set up to do this benchmarking, would you mind varying the parameters a bit and collecting vmstat data? If you want to run oprofile too, that wouldn't hurt. > Also consider the other numbers likely used nptl so they shouldn't be > affected by sched_yield changes. > >> Sure there is. We can run a fully-functional POSIX OS without using any >> block devices at all. We cannot run a fully-functional POSIX OS without a >> scheduler. Any feature without which the OS cannot execute userspace code >> is sufficiently primitive that somewhere there is a device on which it will >> be impossible to debug if that feature fails to initialize. It is quite >> reasonable to insist on only having one implementation of such features in >> any given kernel build. > > Sounds like a red-herring to me... There aren't just pluggable I/O > schedulers in the kernel, there are pluggable packet schedulers too > (see `tc qdisc`). And both are switchable at runtime (not just at boot > time). > > Can you run your fully-functional POSIX OS without a packet scheduler > and without an I/O scheduler? I wonder where are you going to > read/write data without HD and network? If I'm missing both, I'm pretty screwed, but if either one is functional, I can send something out. > Also those pluggable things don't increase the risk of crash much, if > compared to the complexity of the schedulers. > >> Whether or not these alternatives belong in the source tree as config-time >> options is a political question, but preserving boot-time debugging >> capability is a perfectly reasonable technical motivation. > > The scheduler is invoked very late in the boot process (printk and > serial console, kdb are working for ages when scheduler kicks in), so > it's fully debuggable (no debugger depends on the scheduler, they run > inside the nmi handler...), I don't really see your point. I'm more concerned about embedded systems. These are the same people who want userspace character drivers to control their custom hardware. Having the robot point to where it hurts is a lot more convenient than hooking up a JTAG debugger. > And even if there would be a subtle bug in the scheduler you'll never > trigger it at boot with so few tasks and so few context switches. Sure, but it's the non-subtle bugs that worry me. These are usually related to low-level hardware setup, so they could miss the mainstream developers and clobber unsuspecting embedded developers. I acknowledge that debugging such problems shouldn't be terribly hard on mainstream systems, but some people are going to want to choose a single scheduler at build time and avoid the hassle. If we can improve CFS to be regression-free, and I think we can if we give ourselves a few percent tolerance and keep tracking down the corner cases, the pluggable scheduler infrastructure will just be another disused feature. -- Chris ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: pluggable scheduler thread (was Re: Volanomark slows by 80% under CFS) 2007-07-28 6:51 ` Chris Snook @ 2007-07-30 18:49 ` Tim Chen 2007-07-30 21:07 ` Chris Snook 0 siblings, 1 reply; 18+ messages in thread From: Tim Chen @ 2007-07-30 18:49 UTC (permalink / raw) To: Chris Snook; +Cc: Andrea Arcangeli, mingo, linux-kernel On Sat, 2007-07-28 at 02:51 -0400, Chris Snook wrote: > > Tim -- > > Since you're already set up to do this benchmarking, would you mind > varying the parameters a bit and collecting vmstat data? If you want to > run oprofile too, that wouldn't hurt. > Here's the vmstat data. The number of runnable processes are fewer and there're more contex switches with CFS. The vmstat for 2.6.22 looks like procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 391 0 0 1722564 14416 95472 0 0 169 25 76 6520 3 3 89 5 0 400 0 0 1722372 14416 95496 0 0 0 0 264 641685 47 53 0 0 0 368 0 0 1721504 14424 95496 0 0 0 7 261 648493 46 51 3 0 0 438 0 0 1721504 14432 95496 0 0 0 2 264 690834 46 54 0 0 0 400 0 0 1721380 14432 95496 0 0 0 0 260 657157 46 53 1 0 0 393 0 0 1719892 14440 95496 0 0 0 6 265 671599 45 53 2 0 0 423 0 0 1719892 14440 95496 0 0 0 15 264 701626 44 56 0 0 0 375 0 0 1720240 14472 95504 0 0 0 72 265 671795 43 53 3 0 0 393 0 0 1720140 14480 95504 0 0 0 7 265 733561 45 55 0 0 0 355 0 0 1716052 14480 95504 0 0 0 0 260 670676 43 54 3 0 0 419 0 0 1718900 14480 95504 0 0 0 4 265 680690 43 55 2 0 0 396 0 0 1719148 14488 95504 0 0 0 3 261 712307 43 56 0 0 0 395 0 0 1719148 14488 95504 0 0 0 2 264 692781 44 54 1 0 0 387 0 0 1719148 14492 95504 0 0 0 41 268 709579 43 57 0 0 0 420 0 0 1719148 14500 95504 0 0 0 3 265 690862 44 54 2 0 0 429 0 0 1719396 14500 95504 0 0 0 0 260 704872 46 54 0 0 0 460 0 0 1719396 14500 95504 0 0 0 0 264 716272 46 54 0 0 0 419 0 0 1719396 14508 95504 0 0 0 3 261 685864 43 55 2 0 0 455 0 0 1719396 14508 95504 0 0 0 0 264 703718 44 56 0 0 0 395 0 0 1719372 14540 95512 0 0 0 64 265 692785 45 54 1 0 0 424 0 0 1719396 14548 95512 0 0 0 10 265 732866 45 55 0 0 0 While 2.6.23-rc1 look like procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 23 0 0 1705992 17020 95720 0 0 0 0 261 1010016 53 42 5 0 0 7 0 0 1706116 17020 95720 0 0 0 13 267 1060997 52 41 7 0 0 5 0 0 1706116 17020 95720 0 0 0 28 266 1313361 56 41 3 0 0 19 0 0 1706116 17028 95720 0 0 0 8 265 1273669 55 41 4 0 0 18 0 0 1706116 17032 95720 0 0 0 2 262 1403588 55 41 4 0 0 23 0 0 1706116 17032 95720 0 0 0 0 264 1272561 56 40 4 0 0 14 0 0 1706116 17032 95720 0 0 0 0 262 1046795 55 40 5 0 0 16 0 0 1706116 17032 95720 0 0 0 0 260 1361102 58 39 4 0 0 4 0 0 1706224 17120 95724 0 0 0 126 273 1488711 56 41 3 0 0 24 0 0 1706224 17128 95724 0 0 0 6 261 1408432 55 41 4 0 0 3 0 0 1706240 17128 95724 0 0 0 48 273 1299203 54 42 4 0 0 16 0 0 1706240 17132 95724 0 0 0 3 261 1356609 54 42 4 0 0 5 0 0 1706364 17132 95724 0 0 0 0 264 1293198 58 39 3 0 0 9 0 0 1706364 17132 95724 0 0 0 0 261 1555153 56 41 3 0 0 13 0 0 1706364 17132 95724 0 0 0 0 264 1160296 56 40 4 0 0 8 0 0 1706364 17132 95724 0 0 0 0 261 1388909 58 38 4 0 0 18 0 0 1706364 17132 95724 0 0 0 0 264 1236774 56 39 5 0 0 11 0 0 1706364 17136 95724 0 0 0 2 261 1360325 57 40 3 0 0 5 0 0 1706364 17136 95724 0 0 0 1 265 1201912 57 40 3 0 0 8 0 0 1706364 17136 95724 0 0 0 0 261 1104308 57 39 4 0 0 7 0 0 1705976 17232 95724 0 0 0 127 274 1205212 58 39 4 0 0 Tim ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: pluggable scheduler thread (was Re: Volanomark slows by 80% under CFS) 2007-07-30 18:49 ` Tim Chen @ 2007-07-30 21:07 ` Chris Snook 2007-07-30 21:24 ` Andrea Arcangeli 0 siblings, 1 reply; 18+ messages in thread From: Chris Snook @ 2007-07-30 21:07 UTC (permalink / raw) To: tim.c.chen; +Cc: Andrea Arcangeli, mingo, linux-kernel Tim Chen wrote: > On Sat, 2007-07-28 at 02:51 -0400, Chris Snook wrote: > >> Tim -- >> >> Since you're already set up to do this benchmarking, would you mind >> varying the parameters a bit and collecting vmstat data? If you want to >> run oprofile too, that wouldn't hurt. >> > > Here's the vmstat data. The number of runnable processes are > fewer and there're more contex switches with CFS. > > The vmstat for 2.6.22 looks like > > procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ > r b swpd free buff cache si so bi bo in cs us sy id wa st > 391 0 0 1722564 14416 95472 0 0 169 25 76 6520 3 3 89 5 0 > 400 0 0 1722372 14416 95496 0 0 0 0 264 641685 47 53 0 0 0 > 368 0 0 1721504 14424 95496 0 0 0 7 261 648493 46 51 3 0 0 > 438 0 0 1721504 14432 95496 0 0 0 2 264 690834 46 54 0 0 0 > 400 0 0 1721380 14432 95496 0 0 0 0 260 657157 46 53 1 0 0 > 393 0 0 1719892 14440 95496 0 0 0 6 265 671599 45 53 2 0 0 > 423 0 0 1719892 14440 95496 0 0 0 15 264 701626 44 56 0 0 0 > 375 0 0 1720240 14472 95504 0 0 0 72 265 671795 43 53 3 0 0 > 393 0 0 1720140 14480 95504 0 0 0 7 265 733561 45 55 0 0 0 > 355 0 0 1716052 14480 95504 0 0 0 0 260 670676 43 54 3 0 0 > 419 0 0 1718900 14480 95504 0 0 0 4 265 680690 43 55 2 0 0 > 396 0 0 1719148 14488 95504 0 0 0 3 261 712307 43 56 0 0 0 > 395 0 0 1719148 14488 95504 0 0 0 2 264 692781 44 54 1 0 0 > 387 0 0 1719148 14492 95504 0 0 0 41 268 709579 43 57 0 0 0 > 420 0 0 1719148 14500 95504 0 0 0 3 265 690862 44 54 2 0 0 > 429 0 0 1719396 14500 95504 0 0 0 0 260 704872 46 54 0 0 0 > 460 0 0 1719396 14500 95504 0 0 0 0 264 716272 46 54 0 0 0 > 419 0 0 1719396 14508 95504 0 0 0 3 261 685864 43 55 2 0 0 > 455 0 0 1719396 14508 95504 0 0 0 0 264 703718 44 56 0 0 0 > 395 0 0 1719372 14540 95512 0 0 0 64 265 692785 45 54 1 0 0 > 424 0 0 1719396 14548 95512 0 0 0 10 265 732866 45 55 0 0 0 > > While 2.6.23-rc1 look like > procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ > r b swpd free buff cache si so bi bo in cs us sy id wa st > 23 0 0 1705992 17020 95720 0 0 0 0 261 1010016 53 42 5 0 0 > 7 0 0 1706116 17020 95720 0 0 0 13 267 1060997 52 41 7 0 0 > 5 0 0 1706116 17020 95720 0 0 0 28 266 1313361 56 41 3 0 0 > 19 0 0 1706116 17028 95720 0 0 0 8 265 1273669 55 41 4 0 0 > 18 0 0 1706116 17032 95720 0 0 0 2 262 1403588 55 41 4 0 0 > 23 0 0 1706116 17032 95720 0 0 0 0 264 1272561 56 40 4 0 0 > 14 0 0 1706116 17032 95720 0 0 0 0 262 1046795 55 40 5 0 0 > 16 0 0 1706116 17032 95720 0 0 0 0 260 1361102 58 39 4 0 0 > 4 0 0 1706224 17120 95724 0 0 0 126 273 1488711 56 41 3 0 0 > 24 0 0 1706224 17128 95724 0 0 0 6 261 1408432 55 41 4 0 0 > 3 0 0 1706240 17128 95724 0 0 0 48 273 1299203 54 42 4 0 0 > 16 0 0 1706240 17132 95724 0 0 0 3 261 1356609 54 42 4 0 0 > 5 0 0 1706364 17132 95724 0 0 0 0 264 1293198 58 39 3 0 0 > 9 0 0 1706364 17132 95724 0 0 0 0 261 1555153 56 41 3 0 0 > 13 0 0 1706364 17132 95724 0 0 0 0 264 1160296 56 40 4 0 0 > 8 0 0 1706364 17132 95724 0 0 0 0 261 1388909 58 38 4 0 0 > 18 0 0 1706364 17132 95724 0 0 0 0 264 1236774 56 39 5 0 0 > 11 0 0 1706364 17136 95724 0 0 0 2 261 1360325 57 40 3 0 0 > 5 0 0 1706364 17136 95724 0 0 0 1 265 1201912 57 40 3 0 0 > 8 0 0 1706364 17136 95724 0 0 0 0 261 1104308 57 39 4 0 0 > 7 0 0 1705976 17232 95724 0 0 0 127 274 1205212 58 39 4 0 0 > > Tim > From a scheduler performance perspective, it looks like CFS is doing much better on this workload. It's spending a lot less time in %sys despite the higher context switches, and there are far fewer tasks waiting for CPU time. The real problem seems to be that volanomark is optimized for a particular scheduler behavior. That's not to say that we can't improve volanomark performance under CFS, but simply that CFS isn't so fundamentally flawed that this is impossible. When I initially agreed with zeroing out wait time in sched_yield, I didn't realize that it could be negative and that this would actually promote processes in some cases. I still think it's reasonable to zero out positive wait times. Can you test to see if that optimization does better than unconditionally zeroing them out? -- Chris ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: pluggable scheduler thread (was Re: Volanomark slows by 80% under CFS) 2007-07-30 21:07 ` Chris Snook @ 2007-07-30 21:24 ` Andrea Arcangeli 0 siblings, 0 replies; 18+ messages in thread From: Andrea Arcangeli @ 2007-07-30 21:24 UTC (permalink / raw) To: Chris Snook; +Cc: tim.c.chen, mingo, linux-kernel On Mon, Jul 30, 2007 at 05:07:46PM -0400, Chris Snook wrote: > [..] It's spending a lot less time in %sys despite the > higher context switches, [..] The workload takes 40% more so you've to add up that additional 40% too into your math. "A lot less time" sounds an overstatement to me. Also you've to take into account cache effects in executing the scheduler so much etc... > [..] and there are far fewer tasks waiting for CPU > time. The real problem seems to be that volanomark is optimized for a It looks weird that there are a lot less tasks in R state. Could you press SYSRQ+T to see where those hundred tasks are sleeping in the CFS run? > That's not to say that we can't improve volanomark performance under CFS, > but simply that CFS isn't so fundamentally flawed that this is impossible. Given the increase of context switches, it means not all the ctx switches are "userland mandated", so the first thing to try here is to increase the granularity with the new tunable sysctl. Increasing the granularity has to reduce the context switch rate, and in turn it will reduce the slowdown to less than 40%. There's nothing necessarily flawed in CFS even if it's slower than O(1) in this load no matter how you tune it. The higher context switch rate to retain complete fariness is a feature, but fariness vs global performance is generally a tradeoff. ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: Volanomark slows by 80% under CFS 2007-07-28 0:31 ` Chris Snook 2007-07-28 0:59 ` Andrea Arcangeli @ 2007-07-28 13:28 ` Dmitry Adamushko 1 sibling, 0 replies; 18+ messages in thread From: Dmitry Adamushko @ 2007-07-28 13:28 UTC (permalink / raw) To: Chris Snook; +Cc: tim.c.chen, Ingo Molnar, Linux Kernel On 28/07/07, Chris Snook <csnook@redhat.com> wrote: > [ ... ] > Under CFS, the yielding process will still be leftmost in the rbtree, > otherwise it would have already been scheduled out. Not actually true. The position of the 'current' task within the rb-tree is updated with a timer tick's frequency. Being called somewhere in between 2 ticks, sched_yield() may trigger a reschedule which would otherwise take place upon the next tick. Moreover, 'scheduling granularity' may also take effect. e.g. effectively, the yielding task's 'fair_key' was already != 'left_most' upon the previous timer tick but an actual reschedule has been delayed due to the 'scheduling granularity' taking effect... and sched_yield() may trigger it. > Zeroing out wait_runtime on sched_yield strikes me as completely appropriate. > If the process wanted to sleep a finite duration, it should actually call a > sleep function, but sched_yield is essentially saying "I don't have anything > else to do right now", so it's hardly fair to claim you've been waiting for your > chance when you just gave it up. 'wait_runtime' describes dynamic behavior of a task on the rq. It doesn't matter what the task is about to do as 'wait_runtime' is something it fully deserves. Note, 'wait_runtime' can be both positive and negative, meaning credit/punishment appropriately. When it's negative, 'zeroing it out' effectively means the task gets helped -- in the sense that it doen't get 'punished' for some amount of time it actually spent running. Which is wrong. One more thing: we don't take time accounted to 'wait_runtime' just from the thin air. e.g. sleepers get an additional bonus to their 'wait_runtime' upon a wakeup _but_ the amount of "wait_runtime" == "a given bonus" will be additionally substracted from tasks which happen to run later on (grep for "sleeper_bonus" in sched_fair.c). That said, the sum (of additionally given/taken wait_runtime) is zero. All in all, I doubt the "zeroing out wait_runtime on sched_yield" thing is really appropriate. > > -- Chris > -- Best regards, Dmitry Adamushko ^ permalink raw reply [flat|nested] 18+ messages in thread
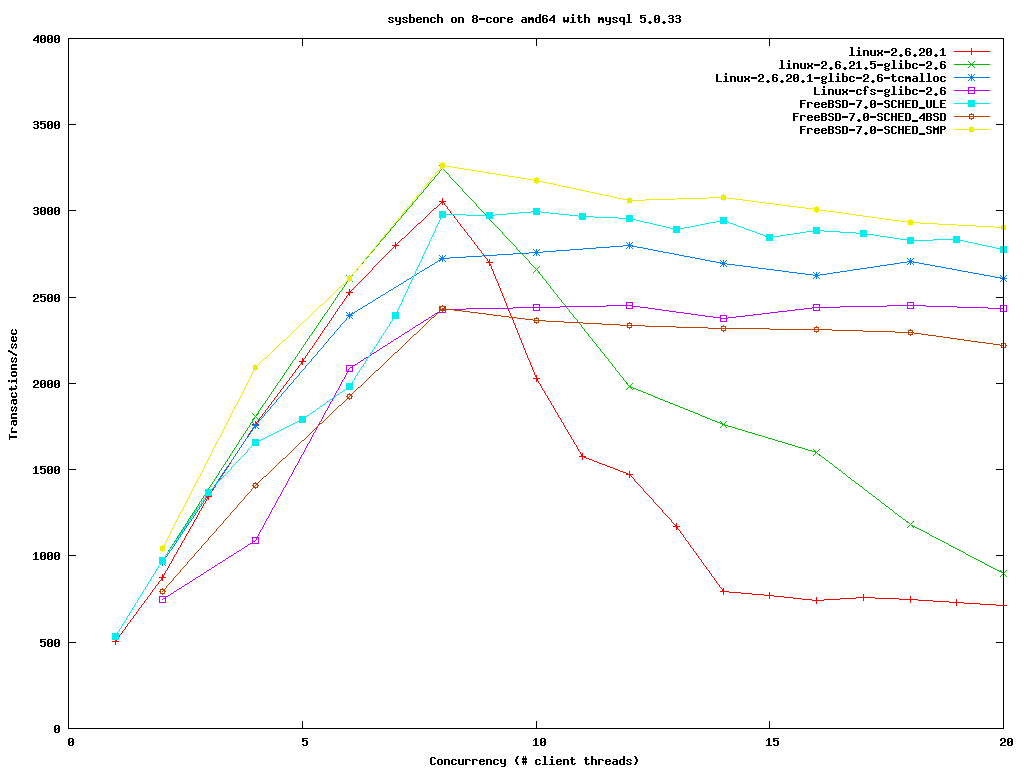
* Re: Volanomark slows by 80% under CFS 2007-07-27 22:01 Volanomark slows by 80% under CFS Tim Chen 2007-07-28 0:31 ` Chris Snook @ 2007-07-28 2:47 ` Rik van Riel 2007-07-28 20:26 ` Dave Jones 2007-07-28 12:36 ` Dmitry Adamushko 2007-07-29 17:37 ` [patch] sched: yield debugging Ingo Molnar 3 siblings, 1 reply; 18+ messages in thread From: Rik van Riel @ 2007-07-28 2:47 UTC (permalink / raw) To: tim.c.chen; +Cc: mingo, linux-kernel Tim Chen wrote: > Ingo, > > Volanomark slows by 80% with CFS scheduler on 2.6.23-rc1. > Benchmark was run on a 2 socket Core2 machine. > > The change in scheduler treatment of sched_yield > could play a part in changing Volanomark behavior. > In CFS, sched_yield is implemented > by dequeueing and requeueing a process . The time a process > has spent running probably reduced the the cpu time due it > by only a bit. The process could get re-queued pretty close > to head of the queue, and may get scheduled again pretty > quickly if there is still a lot of cpu time due. I wonder if this explains the 30% drop in top performance seen with the MySQL sysbench benchmark when the scheduler changed to CFS... See http://people.freebsd.org/~jeff/sysbench.png -- Politics is the struggle between those who want to make their country the best in the world, and those who believe it already is. Each group calls the other unpatriotic. ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: Volanomark slows by 80% under CFS 2007-07-28 2:47 ` Rik van Riel @ 2007-07-28 20:26 ` Dave Jones 0 siblings, 0 replies; 18+ messages in thread From: Dave Jones @ 2007-07-28 20:26 UTC (permalink / raw) To: Rik van Riel; +Cc: tim.c.chen, mingo, linux-kernel On Fri, Jul 27, 2007 at 10:47:21PM -0400, Rik van Riel wrote: > Tim Chen wrote: > > Ingo, > > > > Volanomark slows by 80% with CFS scheduler on 2.6.23-rc1. > > Benchmark was run on a 2 socket Core2 machine. > > > > The change in scheduler treatment of sched_yield > > could play a part in changing Volanomark behavior. > > In CFS, sched_yield is implemented > > by dequeueing and requeueing a process . The time a process > > has spent running probably reduced the the cpu time due it > > by only a bit. The process could get re-queued pretty close > > to head of the queue, and may get scheduled again pretty > > quickly if there is still a lot of cpu time due. > > I wonder if this explains the 30% drop in top performance > seen with the MySQL sysbench benchmark when the scheduler > changed to CFS... > > See http://people.freebsd.org/~jeff/sysbench.png From the authors blog when he did that graph: http://jeffr-tech.livejournal.com/10103.html "So I updated the image for the second time today to include Ingo's cfs scheduler. This kernel is from the rpm on his website. I double checked that it was not using tcmalloc at the time and switching back to a 2.6.21 kernel returned to the expected perf. Basically, it has the same performance as the FreeBSD 4BSD scheduler now. Which is to say the peak is terrible but it has virtually no dropoff and performs better under load than the default 2.6.21 scheduler. " Dave -- http://www.codemonkey.org.uk ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: Volanomark slows by 80% under CFS 2007-07-27 22:01 Volanomark slows by 80% under CFS Tim Chen 2007-07-28 0:31 ` Chris Snook 2007-07-28 2:47 ` Rik van Riel @ 2007-07-28 12:36 ` Dmitry Adamushko 2007-07-28 18:55 ` David Schwartz 2007-07-29 17:37 ` [patch] sched: yield debugging Ingo Molnar 3 siblings, 1 reply; 18+ messages in thread From: Dmitry Adamushko @ 2007-07-28 12:36 UTC (permalink / raw) To: tim.c.chen; +Cc: Ingo Molnar, Linux Kernel On 28/07/07, Tim Chen <tim.c.chen@linux.intel.com> wrote: > [ ... ] > It may make sense to queue the > yielding process a bit further behind in the queue. > I made a slight change by zeroing out wait_runtime > (i.e. have the process gives > up cpu time due for it to run) for experimentation. But that's wrong. The 'wait_runtime' might have been negative at this point (i.e. a task is in the negative 'run-time' balance wrt the 'etalon' nice-0 task). Your change ends up helping such a task to actually stay closer to the 'left most' element of the tree (or to be it) and not "further behind in the queue" as your intention is. I don't know Volanomark's details so refrain from speculating on why this change "improves" benchmark results indeed (maybe some afected tasks have positive 'wait_runtime's on average for this setup). If you want to make sure (just for a test) a yeilding task is not the left-most (at least) for some short interval of time (likely to be <= 1 tick), take a look at yield_task_fair() in e.g. cfs-v15. > Volanomark runs better > and is only 40% (instead of 80%) down from old scheduler > without CFS. 40 or 80 % is still a huge regression. > > Regards, > Tim > -- Best regards, Dmitry Adamushko ^ permalink raw reply [flat|nested] 18+ messages in thread
* RE: Volanomark slows by 80% under CFS 2007-07-28 12:36 ` Dmitry Adamushko @ 2007-07-28 18:55 ` David Schwartz 0 siblings, 0 replies; 18+ messages in thread From: David Schwartz @ 2007-07-28 18:55 UTC (permalink / raw) To: Linux-Kernel@Vger. Kernel. Org > > Volanomark runs better > > and is only 40% (instead of 80%) down from old scheduler > > without CFS. > 40 or 80 % is still a huge regression. > Dmitry Adamushko Can anyone explain precisely what Volanomark is doing? If it's something dumb like "looping on sched_yield until the 'right' thread runs and finishes what we're waiting for" then I think any regression can be ignored. This applies if and only if CFS' sched_yield behavior is sane and Volano's is insane. A sane sched_yield implementation must do two things: 1) Reward processes that actually do yield most of their CPU time to another process. 2) Make an effort to run every ready-to-run process at the same or higher static priority level before re-scheduling this process. (That won't always be possible due to SMP issues, but a reasonable effort is needed.) If CFS is doing these two things, and Volanomark is looping on sched_yield until the 'right thread' runs, then CFS is doing the right and Volanomark isn't. Volanomark deserves to lose. If CFS binds processes to processors more tightly and thus sched_yield can't yield to a process that was planned to run on another CPU in the future, that would be a legitimate complaint about CFS. DS ^ permalink raw reply [flat|nested] 18+ messages in thread
* [patch] sched: yield debugging 2007-07-27 22:01 Volanomark slows by 80% under CFS Tim Chen ` (2 preceding siblings ...) 2007-07-28 12:36 ` Dmitry Adamushko @ 2007-07-29 17:37 ` Ingo Molnar 2007-07-30 18:10 ` Tim Chen 3 siblings, 1 reply; 18+ messages in thread From: Ingo Molnar @ 2007-07-29 17:37 UTC (permalink / raw) To: Tim Chen; +Cc: linux-kernel Tim, * Tim Chen <tim.c.chen@linux.intel.com> wrote: > Ingo, > > Volanomark slows by 80% with CFS scheduler on 2.6.23-rc1. Benchmark > was run on a 2 socket Core2 machine. thanks for testing and reporting this! > The change in scheduler treatment of sched_yield could play a part in > changing Volanomark behavior. Could you try the patch below? It does not change the default behavior of yield but introduces 2 other yield strategies which you can activate runtime (if CONFIG_SCHED_DEBUG=y) via: # default one: echo 0 > /proc/sys/kernel/sched_yield_bug_workaround # always queues the current task next to the next task: echo 1 > /proc/sys/kernel/sched_yield_bug_workaround # NOP: echo 2 > /proc/sys/kernel/sched_yield_bug_workaround does variant '1' improve Java's VolanoMark performance perhaps? i'm also wondering, which JDK is this, and where does Java make use of sys_sched_yield()? It's a voefully badly defined (and thus unreliable) system call, IMO Java should stop using it ASAP and use a saner locking model. thanks, Ingo -------------------------------> Subject: sched: yield debugging From: Ingo Molnar <mingo@elte.hu> introduce various sched_yield implementations: # default one: echo 0 > /proc/sys/kernel/sched_yield_bug_workaround # always queues the current task next to the next task: echo 1 > /proc/sys/kernel/sched_yield_bug_workaround # NOP: echo 2 > /proc/sys/kernel/sched_yield_bug_workaround tunability depends on CONFIG_SCHED_DEBUG=y. Not-yet-signed-off-by: Ingo Molnar <mingo@elte.hu> --- include/linux/sched.h | 1 kernel/sched_fair.c | 71 +++++++++++++++++++++++++++++++++++++++++++++----- kernel/sysctl.c | 8 +++++ 3 files changed, 74 insertions(+), 6 deletions(-) Index: linux/include/linux/sched.h =================================================================== --- linux.orig/include/linux/sched.h +++ linux/include/linux/sched.h @@ -1401,6 +1401,7 @@ extern unsigned int sysctl_sched_wakeup_ extern unsigned int sysctl_sched_batch_wakeup_granularity; extern unsigned int sysctl_sched_stat_granularity; extern unsigned int sysctl_sched_runtime_limit; +extern unsigned int sysctl_sched_yield_bug_workaround; extern unsigned int sysctl_sched_child_runs_first; extern unsigned int sysctl_sched_features; Index: linux/kernel/sched_fair.c =================================================================== --- linux.orig/kernel/sched_fair.c +++ linux/kernel/sched_fair.c @@ -62,6 +62,16 @@ unsigned int sysctl_sched_stat_granulari unsigned int sysctl_sched_runtime_limit __read_mostly; /* + * sys_sched_yield workaround switch. + * + * This option switches the yield implementation of the + * old scheduler back on. + */ +unsigned int sysctl_sched_yield_bug_workaround __read_mostly = 0; + +EXPORT_SYMBOL_GPL(sysctl_sched_yield_bug_workaround); + +/* * Debugging: various feature bits */ enum { @@ -834,14 +844,63 @@ dequeue_task_fair(struct rq *rq, struct static void yield_task_fair(struct rq *rq, struct task_struct *p) { struct cfs_rq *cfs_rq = task_cfs_rq(p); + struct rb_node *curr, *next, *first; + struct task_struct *p_next; u64 now = __rq_clock(rq); + s64 yield_key; - /* - * Dequeue and enqueue the task to update its - * position within the tree: - */ - dequeue_entity(cfs_rq, &p->se, 0, now); - enqueue_entity(cfs_rq, &p->se, 0, now); + + switch (sysctl_sched_yield_bug_workaround) { + default: + /* + * Dequeue and enqueue the task to update its + * position within the tree: + */ + dequeue_entity(cfs_rq, &p->se, 0, now); + enqueue_entity(cfs_rq, &p->se, 0, now); + break; + case 1: + curr = &p->se.run_node; + first = first_fair(cfs_rq); + /* + * Move this task to the second place in the tree: + */ + if (unlikely(curr != first)) { + next = first; + } else { + next = rb_next(curr); + /* + * We were the last one already - nothing to do, return + * and reschedule: + */ + if (unlikely(!next)) + return; + } + + p_next = rb_entry(next, struct task_struct, se.run_node); + /* + * Minimally necessary key value to be the second in the tree: + */ + yield_key = p_next->se.fair_key + (int)sysctl_sched_granularity; + + dequeue_entity(cfs_rq, &p->se, 0, now); + + /* + * Only update the key if we need to move more backwards + * than the minimally necessary position to be the second: + */ + if (p->se.fair_key < yield_key) + p->se.fair_key = yield_key; + + __enqueue_entity(cfs_rq, &p->se); + break; + case 2: + /* + * Just reschedule, do nothing else: + */ + resched_task(p); + break; + } } /* Index: linux/kernel/sysctl.c =================================================================== --- linux.orig/kernel/sysctl.c +++ linux/kernel/sysctl.c @@ -278,6 +278,14 @@ static ctl_table kern_table[] = { }, { .ctl_name = CTL_UNNUMBERED, + .procname = "sched_yield_bug_workaround", + .data = &sysctl_sched_yield_bug_workaround, + .maxlen = sizeof(unsigned int), + .mode = 0644, + .proc_handler = &proc_dointvec, + }, + { + .ctl_name = CTL_UNNUMBERED, .procname = "sched_child_runs_first", .data = &sysctl_sched_child_runs_first, .maxlen = sizeof(unsigned int), ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: [patch] sched: yield debugging 2007-07-29 17:37 ` [patch] sched: yield debugging Ingo Molnar @ 2007-07-30 18:10 ` Tim Chen 2007-07-31 20:33 ` Ingo Molnar 0 siblings, 1 reply; 18+ messages in thread From: Tim Chen @ 2007-07-30 18:10 UTC (permalink / raw) To: Ingo Molnar; +Cc: linux-kernel On Sun, 2007-07-29 at 19:37 +0200, Ingo Molnar wrote: > Tim, > > * Tim Chen <tim.c.chen@linux.intel.com> wrote: > > > Could you try the patch below? It does not change the default behavior > of yield but introduces 2 other yield strategies which you can activate > runtime (if CONFIG_SCHED_DEBUG=y) via: > > # default one: > echo 0 > /proc/sys/kernel/sched_yield_bug_workaround > > # always queues the current task next to the next task: > echo 1 > /proc/sys/kernel/sched_yield_bug_workaround > > # NOP: > echo 2 > /proc/sys/kernel/sched_yield_bug_workaround > > does variant '1' improve Java's VolanoMark performance perhaps? > Here's a summary of Volanomark performance numbers: Variant 0 is 80% down from 2.6.22 Variant 1 is 20% down from 2.6.22 (this is indeed helped) Variant 2 is 89% down from 2.6.22 > i'm also wondering, which JDK is this, and where does Java make use of > sys_sched_yield()? It's a voefully badly defined (and thus unreliable) > system call, IMO Java should stop using it ASAP and use a saner locking > model. I am using a JRockit JDK. Thanks. Tim ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: [patch] sched: yield debugging 2007-07-30 18:10 ` Tim Chen @ 2007-07-31 20:33 ` Ingo Molnar 2007-08-01 20:53 ` Tim Chen 0 siblings, 1 reply; 18+ messages in thread From: Ingo Molnar @ 2007-07-31 20:33 UTC (permalink / raw) To: Tim Chen; +Cc: linux-kernel * Tim Chen <tim.c.chen@linux.intel.com> wrote: > Here's a summary of Volanomark performance numbers: > Variant 0 is 80% down from 2.6.22 > Variant 1 is 20% down from 2.6.22 (this is indeed helped) > Variant 2 is 89% down from 2.6.22 ok, good! Could you try the updated debug patch below? I've done two changes: made '1' the default, and added the /proc/sys/kernel/sched_yield_granularity_ns tunable. (available if CONFIG_SCHED_DEBUG=y) Could you try to change the yield-granularity tunable and see which value gives the best performance? A value of '100000' should in theory give the current (80% degraded) volanomark performance, the default value should give the above '20% down' result. The question is, is '20% down' the best we can get out of it? Does larger/smaller yield-granularity help perhaps? You can change it to any value between 100 usecs and 1 second. Ingo ------------------------------> Subject: sched: yield debugging From: Ingo Molnar <mingo@elte.hu> introduce various sched_yield implementations: # default one: echo 0 > /proc/sys/kernel/sched_yield_bug_workaround # always queues the current task next to the next task: echo 1 > /proc/sys/kernel/sched_yield_bug_workaround # NOP: echo 2 > /proc/sys/kernel/sched_yield_bug_workaround tunability depends on CONFIG_SCHED_DEBUG=y. Not-yet-signed-off-by: Ingo Molnar <mingo@elte.hu> --- include/linux/sched.h | 2 + kernel/sched_fair.c | 72 +++++++++++++++++++++++++++++++++++++++++++++----- kernel/sysctl.c | 19 +++++++++++++ 3 files changed, 87 insertions(+), 6 deletions(-) Index: linux/include/linux/sched.h =================================================================== --- linux.orig/include/linux/sched.h +++ linux/include/linux/sched.h @@ -1397,10 +1397,12 @@ static inline void idle_task_exit(void) extern void sched_idle_next(void); extern unsigned int sysctl_sched_granularity; +extern unsigned int sysctl_sched_yield_granularity; extern unsigned int sysctl_sched_wakeup_granularity; extern unsigned int sysctl_sched_batch_wakeup_granularity; extern unsigned int sysctl_sched_stat_granularity; extern unsigned int sysctl_sched_runtime_limit; +extern unsigned int sysctl_sched_yield_bug_workaround; extern unsigned int sysctl_sched_child_runs_first; extern unsigned int sysctl_sched_features; Index: linux/kernel/sched_fair.c =================================================================== --- linux.orig/kernel/sched_fair.c +++ linux/kernel/sched_fair.c @@ -32,6 +32,7 @@ * systems, 4x on 8-way systems, 5x on 16-way systems, etc.) */ unsigned int sysctl_sched_granularity __read_mostly = 2000000000ULL/HZ; +unsigned int sysctl_sched_yield_granularity __read_mostly = 2000000000ULL/HZ; /* * SCHED_BATCH wake-up granularity. @@ -62,6 +63,16 @@ unsigned int sysctl_sched_stat_granulari unsigned int sysctl_sched_runtime_limit __read_mostly; /* + * sys_sched_yield workaround switch. + * + * This option switches the yield implementation of the + * old scheduler back on. + */ +unsigned int sysctl_sched_yield_bug_workaround __read_mostly = 1; + +EXPORT_SYMBOL_GPL(sysctl_sched_yield_bug_workaround); + +/* * Debugging: various feature bits */ enum { @@ -834,14 +845,63 @@ dequeue_task_fair(struct rq *rq, struct static void yield_task_fair(struct rq *rq, struct task_struct *p) { struct cfs_rq *cfs_rq = task_cfs_rq(p); + struct rb_node *curr, *next, *first; + struct task_struct *p_next; u64 now = __rq_clock(rq); + s64 yield_key; - /* - * Dequeue and enqueue the task to update its - * position within the tree: - */ - dequeue_entity(cfs_rq, &p->se, 0, now); - enqueue_entity(cfs_rq, &p->se, 0, now); + + switch (sysctl_sched_yield_bug_workaround) { + default: + /* + * Dequeue and enqueue the task to update its + * position within the tree: + */ + dequeue_entity(cfs_rq, &p->se, 0, now); + enqueue_entity(cfs_rq, &p->se, 0, now); + break; + case 1: + curr = &p->se.run_node; + first = first_fair(cfs_rq); + /* + * Move this task to the second place in the tree: + */ + if (unlikely(curr != first)) { + next = first; + } else { + next = rb_next(curr); + /* + * We were the last one already - nothing to do, return + * and reschedule: + */ + if (unlikely(!next)) + return; + } + + p_next = rb_entry(next, struct task_struct, se.run_node); + /* + * Minimally necessary key value to be the second in the tree: + */ + yield_key = p_next->se.fair_key + (int)sysctl_sched_yield_granularity; + + dequeue_entity(cfs_rq, &p->se, 0, now); + + /* + * Only update the key if we need to move more backwards + * than the minimally necessary position to be the second: + */ + if (p->se.fair_key < yield_key) + p->se.fair_key = yield_key; + + __enqueue_entity(cfs_rq, &p->se); + break; + case 2: + /* + * Just reschedule, do nothing else: + */ + resched_task(p); + break; + } } /* Index: linux/kernel/sysctl.c =================================================================== --- linux.orig/kernel/sysctl.c +++ linux/kernel/sysctl.c @@ -234,6 +234,17 @@ static ctl_table kern_table[] = { }, { .ctl_name = CTL_UNNUMBERED, + .procname = "sched_yield_granularity_ns", + .data = &sysctl_sched_yield_granularity, + .maxlen = sizeof(unsigned int), + .mode = 0644, + .proc_handler = &proc_dointvec_minmax, + .strategy = &sysctl_intvec, + .extra1 = &min_sched_granularity_ns, + .extra2 = &max_sched_granularity_ns, + }, + { + .ctl_name = CTL_UNNUMBERED, .procname = "sched_wakeup_granularity_ns", .data = &sysctl_sched_wakeup_granularity, .maxlen = sizeof(unsigned int), @@ -278,6 +289,14 @@ static ctl_table kern_table[] = { }, { .ctl_name = CTL_UNNUMBERED, + .procname = "sched_yield_bug_workaround", + .data = &sysctl_sched_yield_bug_workaround, + .maxlen = sizeof(unsigned int), + .mode = 0644, + .proc_handler = &proc_dointvec, + }, + { + .ctl_name = CTL_UNNUMBERED, .procname = "sched_child_runs_first", .data = &sysctl_sched_child_runs_first, .maxlen = sizeof(unsigned int), ^ permalink raw reply [flat|nested] 18+ messages in thread
* Re: [patch] sched: yield debugging 2007-07-31 20:33 ` Ingo Molnar @ 2007-08-01 20:53 ` Tim Chen 0 siblings, 0 replies; 18+ messages in thread From: Tim Chen @ 2007-08-01 20:53 UTC (permalink / raw) To: Ingo Molnar; +Cc: linux-kernel On Tue, 2007-07-31 at 22:33 +0200, Ingo Molnar wrote: > ok, good! Could you try the updated debug patch below? I've done two > changes: made '1' the default, and added the > /proc/sys/kernel/sched_yield_granularity_ns tunable. (available if > CONFIG_SCHED_DEBUG=y) > > Could you try to change the yield-granularity tunable and see which > value gives the best performance? A value of '100000' should in theory > give the current (80% degraded) volanomark performance, the default > value should give the above '20% down' result. The question is, is '20% > down' the best we can get out of it? Does larger/smaller > yield-granularity help perhaps? You can change it to any value between > 100 usecs and 1 second. > Turning up the granuality helped. Here's the data I got for Volanomark performance relative to 2.6.22 Granuality 1000000000 (max) 9% down 800000000 8% down 80000000 13% down 8000000 20% down 100000 56% down Tim ^ permalink raw reply [flat|nested] 18+ messages in thread
end of thread, other threads:[~2007-08-01 22:47 UTC | newest] Thread overview: 18+ messages (download: mbox.gz follow: Atom feed -- links below jump to the message on this page -- 2007-07-27 22:01 Volanomark slows by 80% under CFS Tim Chen 2007-07-28 0:31 ` Chris Snook 2007-07-28 0:59 ` Andrea Arcangeli 2007-07-28 3:43 ` pluggable scheduler flamewar thread (was Re: Volanomark slows by 80% under CFS) Chris Snook 2007-07-28 5:01 ` pluggable scheduler " Andrea Arcangeli 2007-07-28 6:51 ` Chris Snook 2007-07-30 18:49 ` Tim Chen 2007-07-30 21:07 ` Chris Snook 2007-07-30 21:24 ` Andrea Arcangeli 2007-07-28 13:28 ` Volanomark slows by 80% under CFS Dmitry Adamushko 2007-07-28 2:47 ` Rik van Riel 2007-07-28 20:26 ` Dave Jones 2007-07-28 12:36 ` Dmitry Adamushko 2007-07-28 18:55 ` David Schwartz 2007-07-29 17:37 ` [patch] sched: yield debugging Ingo Molnar 2007-07-30 18:10 ` Tim Chen 2007-07-31 20:33 ` Ingo Molnar 2007-08-01 20:53 ` Tim Chen
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox
{kind=link}