* Re: speed difference between using hard-linked and modular drives? [not found] ` <Pine.LNX.4.33.0111081836080.15975-100000@localhost.localdomain.suse.lists.linux.kernel> @ 2001-11-08 23:00 ` Andi Kleen 2001-11-09 0:05 ` Anton Blanchard 2001-11-09 3:12 ` speed difference between using hard-linked and modular drives? Rusty Russell 0 siblings, 2 replies; 49+ messages in thread From: Andi Kleen @ 2001-11-08 23:00 UTC (permalink / raw) To: Ingo Molnar; +Cc: linux-kernel Ingo Molnar <mingo@elte.hu> writes: > > we should fix this by trying to allocate continuous physical memory if > possible, and fall back to vmalloc() only if this allocation fails. Check -aa. A patch to do that has been in there for some time now. -Andi P.S.: It makes a measurable difference with some Oracle benchmarks with the Qlogic driver. ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-08 23:00 ` speed difference between using hard-linked and modular drives? Andi Kleen @ 2001-11-09 0:05 ` Anton Blanchard 2001-11-09 5:45 ` Andi Kleen 2001-11-09 3:12 ` speed difference between using hard-linked and modular drives? Rusty Russell 1 sibling, 1 reply; 49+ messages in thread From: Anton Blanchard @ 2001-11-09 0:05 UTC (permalink / raw) To: Andi Kleen; +Cc: Ingo Molnar, linux-kernel > > we should fix this by trying to allocate continuous physical memory if > > possible, and fall back to vmalloc() only if this allocation fails. > > Check -aa. A patch to do that has been in there for some time now. We also need a way to satisfy very large allocations for the hashes (eg the pagecache hash). On a 32G machine we get awful performance on the pagecache hash because we can only get an order 9 allocation out of get_free_pages: http://samba.org/~anton/linux/pagecache/pagecache_before.png When switching to vmalloc the hash is large enough to be useful: http://samba.org/~anton/linux/pagecache/pagecache_after.png As pointed out by Davem and Ingo we should try and avoid vmalloc here due to tlb trashing. Anton ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 0:05 ` Anton Blanchard @ 2001-11-09 5:45 ` Andi Kleen 2001-11-09 6:04 ` David S. Miller 0 siblings, 1 reply; 49+ messages in thread From: Andi Kleen @ 2001-11-09 5:45 UTC (permalink / raw) To: Anton Blanchard; +Cc: Andi Kleen, Ingo Molnar, linux-kernel On Fri, Nov 09, 2001 at 11:05:32AM +1100, Anton Blanchard wrote: > We also need a way to satisfy very large allocations for the hashes (eg > the pagecache hash). On a 32G machine we get awful performance on the > pagecache hash because we can only get an order 9 allocation out of > get_free_pages: > > http://samba.org/~anton/linux/pagecache/pagecache_before.png > > When switching to vmalloc the hash is large enough to be useful: > > http://samba.org/~anton/linux/pagecache/pagecache_after.png > > As pointed out by Davem and Ingo we should try and avoid vmalloc here > due to tlb trashing. Sounds like you need a better hash function instead. -Andi ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 5:45 ` Andi Kleen @ 2001-11-09 6:04 ` David S. Miller 2001-11-09 6:39 ` Andi Kleen 0 siblings, 1 reply; 49+ messages in thread From: David S. Miller @ 2001-11-09 6:04 UTC (permalink / raw) To: ak; +Cc: anton, mingo, linux-kernel From: Andi Kleen <ak@suse.de> Date: Fri, 9 Nov 2001 06:45:40 +0100 Sounds like you need a better hash function instead. Andi, please think about the problem before jumping to conclusions. N_PAGES / N_CHAINS > 1 in his situation. A better hash function cannot help. Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 6:04 ` David S. Miller @ 2001-11-09 6:39 ` Andi Kleen 2001-11-09 6:54 ` Andrew Morton ` (3 more replies) 0 siblings, 4 replies; 49+ messages in thread From: Andi Kleen @ 2001-11-09 6:39 UTC (permalink / raw) To: David S. Miller; +Cc: ak, anton, mingo, linux-kernel On Thu, Nov 08, 2001 at 10:04:44PM -0800, David S. Miller wrote: > From: Andi Kleen <ak@suse.de> > Date: Fri, 9 Nov 2001 06:45:40 +0100 > > Sounds like you need a better hash function instead. > > Andi, please think about the problem before jumping to conclusions. > N_PAGES / N_CHAINS > 1 in his situation. A better hash function > cannot help. I'm assuming that walking on average 5-10 pages on a lookup is not too big a deal, especially when you use prefetch for the list walk. It is a tradeoff between a big hash table thrashing your cache and a smaller hash table that can be cached but has on average >1 entries/buckets. At some point the the smaller hash table wins, assuming the hash function is evenly distributed. It would only get bad if the average chain length would become much bigger. Before jumping to real conclusions it would be interesting to gather some statistics on Anton's machine, but I suspect he just has an very unevenly populated table. -Andi ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 6:39 ` Andi Kleen @ 2001-11-09 6:54 ` Andrew Morton 2001-11-09 7:17 ` David S. Miller 2001-11-09 7:14 ` David S. Miller ` (2 subsequent siblings) 3 siblings, 1 reply; 49+ messages in thread From: Andrew Morton @ 2001-11-09 6:54 UTC (permalink / raw) To: Andi Kleen; +Cc: David S. Miller, anton, mingo, linux-kernel Andi Kleen wrote: > > On Thu, Nov 08, 2001 at 10:04:44PM -0800, David S. Miller wrote: > > From: Andi Kleen <ak@suse.de> > > Date: Fri, 9 Nov 2001 06:45:40 +0100 > > > > Sounds like you need a better hash function instead. > > > > Andi, please think about the problem before jumping to conclusions. > > N_PAGES / N_CHAINS > 1 in his situation. A better hash function > > cannot help. > > I'm assuming that walking on average 5-10 pages on a lookup is not too big a > deal, especially when you use prefetch for the list walk. It is a tradeoff > between a big hash table thrashing your cache and a smaller hash table that > can be cached but has on average >1 entries/buckets. At some point the the > smaller hash table wins, assuming the hash function is evenly distributed. > > It would only get bad if the average chain length would become much bigger. > > Before jumping to real conclusions it would be interesting to gather > some statistics on Anton's machine, but I suspect he just has an very > unevenly populated table. I played with that earlier in the year. Shrinking the hash table by a factor of eight made no measurable difference to anything on a Pentium II. The hash distribution was all over the place though. Lots of buckets with 1-2 pages, lots with 12-13. - ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 6:54 ` Andrew Morton @ 2001-11-09 7:17 ` David S. Miller 2001-11-09 7:16 ` Andrew Morton 0 siblings, 1 reply; 49+ messages in thread From: David S. Miller @ 2001-11-09 7:17 UTC (permalink / raw) To: akpm; +Cc: ak, anton, mingo, linux-kernel From: Andrew Morton <akpm@zip.com.au> Date: Thu, 08 Nov 2001 22:54:30 -0800 I played with that earlier in the year. Shrinking the hash table by a factor of eight made no measurable difference to anything on a Pentium II. The hash distribution was all over the place though. Lots of buckets with 1-2 pages, lots with 12-13. What is the distribution when you don't shrink the hash table? Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 7:17 ` David S. Miller @ 2001-11-09 7:16 ` Andrew Morton 2001-11-09 7:24 ` David S. Miller 2001-11-09 8:21 ` Ingo Molnar 0 siblings, 2 replies; 49+ messages in thread From: Andrew Morton @ 2001-11-09 7:16 UTC (permalink / raw) To: David S. Miller; +Cc: ak, anton, mingo, linux-kernel "David S. Miller" wrote: > > From: Andrew Morton <akpm@zip.com.au> > Date: Thu, 08 Nov 2001 22:54:30 -0800 > > I played with that earlier in the year. Shrinking the hash table > by a factor of eight made no measurable difference to anything on > a Pentium II. The hash distribution was all over the place though. > Lots of buckets with 1-2 pages, lots with 12-13. > > What is the distribution when you don't shrink the hash > table? > Well on my setup, there are more hash buckets than there are pages in the system. So - basically empty. If memory serves me, never more than two pages in a bucket. ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 7:16 ` Andrew Morton @ 2001-11-09 7:24 ` David S. Miller 2001-11-09 8:21 ` Ingo Molnar 1 sibling, 0 replies; 49+ messages in thread From: David S. Miller @ 2001-11-09 7:24 UTC (permalink / raw) To: akpm; +Cc: ak, anton, mingo, linux-kernel From: Andrew Morton <akpm@zip.com.au> Date: Thu, 08 Nov 2001 23:16:08 -0800 Well on my setup, there are more hash buckets than there are pages in the system. So - basically empty. If memory serves me, never more than two pages in a bucket. Ok, this is what I expected. The function is tuned for having N_HASH_CHAINS being roughly equal to N_PAGES. If you want to experiment with smaller hash tables, there are some hacks in the FreeBSD sources that choose a different "salt" per inode. You xor the salt into the hash for each page on that inode. Something like this... Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 7:16 ` Andrew Morton 2001-11-09 7:24 ` David S. Miller @ 2001-11-09 8:21 ` Ingo Molnar 2001-11-09 7:35 ` Andrew Morton 1 sibling, 1 reply; 49+ messages in thread From: Ingo Molnar @ 2001-11-09 8:21 UTC (permalink / raw) To: Andrew Morton; +Cc: David S. Miller, ak, anton, linux-kernel On Thu, 8 Nov 2001, Andrew Morton wrote: > Well on my setup, there are more hash buckets than there are pages in > the system. So - basically empty. If memory serves me, never more > than two pages in a bucket. how much RAM and how many buckets are there on your system? Ingo ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 8:21 ` Ingo Molnar @ 2001-11-09 7:35 ` Andrew Morton 2001-11-09 7:44 ` David S. Miller 0 siblings, 1 reply; 49+ messages in thread From: Andrew Morton @ 2001-11-09 7:35 UTC (permalink / raw) To: mingo; +Cc: David S. Miller, ak, anton, linux-kernel Ingo Molnar wrote: > > On Thu, 8 Nov 2001, Andrew Morton wrote: > > > Well on my setup, there are more hash buckets than there are pages in > > the system. So - basically empty. If memory serves me, never more > > than two pages in a bucket. > > how much RAM and how many buckets are there on your system? > urgh. It was ages ago. I shouldn't have stuck my head up ;) I guess it was 256 megs: Kernel command line: ... mem=256m Page-cache hash table entries: 65536 (order: 6, 262144 bytes) And that's one entry per page, yes? I ended up concluding that a) The hash is sucky and b) Except for certain specialised workloads, a lookup is usually associated with a big memory copy, so none of it matters and c) given b), the page cache hashtable is on the wrong side of the size/space tradeoff :) - ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 7:35 ` Andrew Morton @ 2001-11-09 7:44 ` David S. Miller 0 siblings, 0 replies; 49+ messages in thread From: David S. Miller @ 2001-11-09 7:44 UTC (permalink / raw) To: akpm; +Cc: mingo, ak, anton, linux-kernel From: Andrew Morton <akpm@zip.com.au> Date: Thu, 08 Nov 2001 23:35:04 -0800 b) Except for certain specialised workloads, a lookup is usually associated with a big memory copy, so none of it matters and I disagree, cache pollution always matters. Especially, if the cpu does memcpy's using cache-bypass-on-miss. Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 6:39 ` Andi Kleen 2001-11-09 6:54 ` Andrew Morton @ 2001-11-09 7:14 ` David S. Miller 2001-11-09 7:16 ` David S. Miller 2001-11-10 4:56 ` Anton Blanchard 3 siblings, 0 replies; 49+ messages in thread From: David S. Miller @ 2001-11-09 7:14 UTC (permalink / raw) To: ak; +Cc: anton, mingo, linux-kernel From: Andi Kleen <ak@suse.de> Date: Fri, 9 Nov 2001 07:39:46 +0100 Before jumping to real conclusions it would be interesting to gather some statistics on Anton's machine, but I suspect he just has an very unevenly populated table. N_PAGES / N_HASHCHAINS was on the order of 9, and the hash chains were evenly distributed. He posted URLs to graphs of the hash table chain lengths. Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 6:39 ` Andi Kleen 2001-11-09 6:54 ` Andrew Morton 2001-11-09 7:14 ` David S. Miller @ 2001-11-09 7:16 ` David S. Miller 2001-11-09 12:59 ` Alan Cox 2001-11-10 5:20 ` Anton Blanchard 2001-11-10 4:56 ` Anton Blanchard 3 siblings, 2 replies; 49+ messages in thread From: David S. Miller @ 2001-11-09 7:16 UTC (permalink / raw) To: ak; +Cc: anton, mingo, linux-kernel From: Andi Kleen <ak@suse.de> Date: Fri, 9 Nov 2001 07:39:46 +0100 I'm assuming that walking on average 5-10 pages on a lookup is not too big a deal, especially when you use prefetch for the list walk. Oh no, not this again... It _IS_ a big deal. Fetching _ONE_ hash chain cache line is always going to be cheaper than fetching _FIVE_ to _TEN_ page struct cache lines while walking the list. Even if prefetch would kill all of this overhead (sorry, it won't), it is _DUMB_ and _STUPID_ to bring those _FIVE_ to _TEN_ cache lines into the processor just to lookup _ONE_ page. Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 7:16 ` David S. Miller @ 2001-11-09 12:59 ` Alan Cox 2001-11-09 12:54 ` David S. Miller 2001-11-10 5:20 ` Anton Blanchard 1 sibling, 1 reply; 49+ messages in thread From: Alan Cox @ 2001-11-09 12:59 UTC (permalink / raw) To: David S. Miller; +Cc: ak, anton, mingo, linux-kernel > Oh no, not this again... > > It _IS_ a big deal. Fetching _ONE_ hash chain cache line > is always going to be cheaper than fetching _FIVE_ to _TEN_ > page struct cache lines while walking the list. Big picture time. What costs more - the odd five cache line hit or swapping 200Kbytes/second on and off disk ? - thats obviously workload dependant. Perhaps at some point we need to accept there is a memory/speed tradeoff throughout the kernel and we need a CONFIG option for it - especially for the handheld world. I don't want to do lots of I/O on an ipaq, I don't need big tcp hashes, and I'd rather take a small performance hit. ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 12:59 ` Alan Cox @ 2001-11-09 12:54 ` David S. Miller 2001-11-09 13:15 ` Philip Dodd 2001-11-09 13:17 ` Andi Kleen 0 siblings, 2 replies; 49+ messages in thread From: David S. Miller @ 2001-11-09 12:54 UTC (permalink / raw) To: alan; +Cc: ak, anton, mingo, linux-kernel From: Alan Cox <alan@lxorguk.ukuu.org.uk> Date: Fri, 9 Nov 2001 12:59:09 +0000 (GMT) we need a CONFIG option for it I think a boot time commandline option is more appropriate for something like this. Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 12:54 ` David S. Miller @ 2001-11-09 13:15 ` Philip Dodd 2001-11-09 13:26 ` David S. Miller 2001-11-09 13:17 ` Andi Kleen 1 sibling, 1 reply; 49+ messages in thread From: Philip Dodd @ 2001-11-09 13:15 UTC (permalink / raw) To: alan, David S. Miller; +Cc: ak, anton, mingo, linux-kernel > > we need a CONFIG option for it > > I think a boot time commandline option is more appropriate > for something like this. In the light of what was said about embedded systems, I'm not really sure a boot time option really is the way to go... Just a thought. Philip DODD Sales Engineer SIVA Les Fjords - Immeuble Narvik 19 Avenue de Norvège Z.A. de Courtaboeuf 1 91953 LES ULIS CEDEX http://www.siva.fr ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 13:15 ` Philip Dodd @ 2001-11-09 13:26 ` David S. Miller 2001-11-09 20:45 ` Mike Fedyk 0 siblings, 1 reply; 49+ messages in thread From: David S. Miller @ 2001-11-09 13:26 UTC (permalink / raw) To: smpcomputing; +Cc: alan, ak, anton, mingo, linux-kernel From: "Philip Dodd" <smpcomputing@free.fr> Date: Fri, 9 Nov 2001 14:15:32 +0100 > I think a boot time commandline option is more appropriate > for something like this. In the light of what was said about embedded systems, I'm not really sure a boot time option really is the way to go... All the hash tables in question are allocated dynamically, we size them at boot time, the memory is not consumed until the kernel begins executing. So a boottime option would be just fine. Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 13:26 ` David S. Miller @ 2001-11-09 20:45 ` Mike Fedyk 0 siblings, 0 replies; 49+ messages in thread From: Mike Fedyk @ 2001-11-09 20:45 UTC (permalink / raw) To: David S. Miller; +Cc: smpcomputing, alan, ak, anton, mingo, linux-kernel On Fri, Nov 09, 2001 at 05:26:50AM -0800, David S. Miller wrote: > From: "Philip Dodd" <smpcomputing@free.fr> > Date: Fri, 9 Nov 2001 14:15:32 +0100 > > > I think a boot time commandline option is more appropriate > > for something like this. > > In the light of what was said about embedded systems, I'm not really sure a > boot time option really is the way to go... > > All the hash tables in question are allocated dynamically, > we size them at boot time, the memory is not consumed until > the kernel begins executing. So a boottime option would be > just fine. How much is this code going to affect the kernel image size? ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 12:54 ` David S. Miller 2001-11-09 13:15 ` Philip Dodd @ 2001-11-09 13:17 ` Andi Kleen 2001-11-09 13:25 ` David S. Miller 1 sibling, 1 reply; 49+ messages in thread From: Andi Kleen @ 2001-11-09 13:17 UTC (permalink / raw) To: David S. Miller; +Cc: alan, ak, anton, mingo, linux-kernel On Fri, Nov 09, 2001 at 04:54:55AM -0800, David S. Miller wrote: > From: Alan Cox <alan@lxorguk.ukuu.org.uk> > Date: Fri, 9 Nov 2001 12:59:09 +0000 (GMT) > > we need a CONFIG option for it > > I think a boot time commandline option is more appropriate > for something like this. Fine if you don't mind an indirect function call pointer somewhere in the TCP hash path. I'm thinking about adding one that removes the separate time wait table. It is not needed for desktops because they should have little or no time-wait sockets. also it should throttle the hash table sizing aggressively; e.g. 256-512 buckets should be more than enough for a client. BTW I noticed that 1/4 of the big hash table is not used on SMP. The time wait buckets share the locks of the lower half, so the spinlocks in the upper half are never used. What would you think about splitting the table and not putting spinlocks in the time-wait range? -Andi ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 13:17 ` Andi Kleen @ 2001-11-09 13:25 ` David S. Miller 2001-11-09 13:39 ` Andi Kleen 0 siblings, 1 reply; 49+ messages in thread From: David S. Miller @ 2001-11-09 13:25 UTC (permalink / raw) To: ak; +Cc: alan, anton, mingo, linux-kernel From: Andi Kleen <ak@suse.de> Date: Fri, 9 Nov 2001 14:17:55 +0100 Fine if you don't mind an indirect function call pointer somewhere in the TCP hash path. The hashes are sized at boot time, we can just reduce the size when the boot time option says "small machine" or whatever. Why in the world do we need indirection function call pointers in TCP to handle that? Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 13:25 ` David S. Miller @ 2001-11-09 13:39 ` Andi Kleen 2001-11-09 13:41 ` David S. Miller 0 siblings, 1 reply; 49+ messages in thread From: Andi Kleen @ 2001-11-09 13:39 UTC (permalink / raw) To: David S. Miller; +Cc: ak, alan, anton, mingo, linux-kernel On Fri, Nov 09, 2001 at 05:25:54AM -0800, David S. Miller wrote: > Why in the world do we need indirection function call pointers > in TCP to handle that? To handle the case of not having a separate TIME-WAIT table (sorry for being unclear). Or alternatively several conditionals. -Andi ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 13:39 ` Andi Kleen @ 2001-11-09 13:41 ` David S. Miller 0 siblings, 0 replies; 49+ messages in thread From: David S. Miller @ 2001-11-09 13:41 UTC (permalink / raw) To: ak; +Cc: alan, anton, mingo, linux-kernel From: Andi Kleen <ak@suse.de> Date: Fri, 9 Nov 2001 14:39:30 +0100 On Fri, Nov 09, 2001 at 05:25:54AM -0800, David S. Miller wrote: > Why in the world do we need indirection function call pointers > in TCP to handle that? To handle the case of not having a separate TIME-WAIT table (sorry for being unclear). Or alternatively several conditionals. The TIME-WAIT half of the hash table is most useful on clients actually. I mean, just double the amount you "downsize" the TCP established hash table if it bothers you that much. Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 7:16 ` David S. Miller 2001-11-09 12:59 ` Alan Cox @ 2001-11-10 5:20 ` Anton Blanchard 1 sibling, 0 replies; 49+ messages in thread From: Anton Blanchard @ 2001-11-10 5:20 UTC (permalink / raw) To: David S. Miller; +Cc: ak, mingo, linux-kernel Hi, > It _IS_ a big deal. Fetching _ONE_ hash chain cache line > is always going to be cheaper than fetching _FIVE_ to _TEN_ > page struct cache lines while walking the list. Exactly, the reason I found the pagecache hash was too small was because __find_page_nolock was one of the worst offenders when doing zero copy web serving of a large dataset. > Even if prefetch would kill all of this overhead (sorry, it won't), it > is _DUMB_ and _STUPID_ to bring those _FIVE_ to _TEN_ cache lines into > the processor just to lookup _ONE_ page. Yes you cant expect prefetch to help you when you use the data 10 instructions after you issue the prefetch. (ie walking the hash chain) Anton ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 6:39 ` Andi Kleen ` (2 preceding siblings ...) 2001-11-09 7:16 ` David S. Miller @ 2001-11-10 4:56 ` Anton Blanchard 2001-11-10 5:09 ` Andi Kleen ` (2 more replies) 3 siblings, 3 replies; 49+ messages in thread From: Anton Blanchard @ 2001-11-10 4:56 UTC (permalink / raw) To: Andi Kleen; +Cc: David S. Miller, mingo, linux-kernel Hi, > I'm assuming that walking on average 5-10 pages on a lookup is not too big a > deal, especially when you use prefetch for the list walk. It is a tradeoff > between a big hash table thrashing your cache and a smaller hash table that > can be cached but has on average >1 entries/buckets. At some point the the > smaller hash table wins, assuming the hash function is evenly distributed. > > It would only get bad if the average chain length would become much bigger. > > Before jumping to real conclusions it would be interesting to gather > some statistics on Anton's machine, but I suspect he just has an very > unevenly populated table. You can find the raw data here: http://samba.org/~anton/linux/pagecache/pagecache_data_gfp.gz http://samba.org/~anton/linux/pagecache/pagecache_data_vmalloc.gz You can see the average depth of the get_free_page hash is way too deep. I agree there are a lot of pagecache pages (17GB in the gfp test and 21GB in the vmalloc test), but we have to make use of the 32GB of RAM :) I did some experimentation with prefetch and I dont think it will gain you anything here. We need to issue the prefetch many cycles before using the data which we cannot do when walking the chain. Anton ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-10 4:56 ` Anton Blanchard @ 2001-11-10 5:09 ` Andi Kleen 2001-11-10 13:29 ` David S. Miller 2001-11-12 16:59 ` [patch] arbitrary size memory allocator, memarea-2.4.15-D6 Ingo Molnar 2 siblings, 0 replies; 49+ messages in thread From: Andi Kleen @ 2001-11-10 5:09 UTC (permalink / raw) To: Anton Blanchard; +Cc: linux-kernel > You can see the average depth of the get_free_page hash is way too deep. > I agree there are a lot of pagecache pages (17GB in the gfp test and 21GB > in the vmalloc test), but we have to make use of the 32GB of RAM :) Thanks for the information. I guess the fix for your case would be then to use the bootmem allocator for allocating the page table hash. It should have no problems with very large continuous tables, assuming you have the (physically continuous) memory. Another possibility would be to switch to some tree/skiplist, but that's probably too radical and may have other problems on smaller boxes. -Andi ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-10 4:56 ` Anton Blanchard 2001-11-10 5:09 ` Andi Kleen @ 2001-11-10 13:29 ` David S. Miller 2001-11-10 13:44 ` David S. Miller 2001-11-10 13:52 ` David S. Miller 2001-11-12 16:59 ` [patch] arbitrary size memory allocator, memarea-2.4.15-D6 Ingo Molnar 2 siblings, 2 replies; 49+ messages in thread From: David S. Miller @ 2001-11-10 13:29 UTC (permalink / raw) To: anton; +Cc: ak, mingo, linux-kernel From: Anton Blanchard <anton@samba.org> Date: Sat, 10 Nov 2001 15:56:03 +1100 You can see the average depth of the get_free_page hash is way too deep. I agree there are a lot of pagecache pages (17GB in the gfp test and 21GB in the vmalloc test), but we have to make use of the 32GB of RAM :) Anton, are you bored? :-) If so, could you test out the patch below on your ppc64 box? It does the "page hash table via bootmem" thing. It is against 2.4.15-pre2 The ppc64 specific bits you'll need to do, but they should be very straight forward. It also fixes a really stupid bug in the bootmem allocator. If the bootmem area starts in some unaligned address, the "align" argument to the bootmem allocator isn't honored. --- ./arch/alpha/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/alpha/mm/init.c Sat Nov 10 01:49:56 2001 @@ -23,6 +23,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/system.h> #include <asm/uaccess.h> @@ -360,6 +361,7 @@ mem_init(void) { max_mapnr = num_physpages = max_low_pfn; + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); high_memory = (void *) __va(max_low_pfn * PAGE_SIZE); --- ./arch/alpha/mm/numa.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/alpha/mm/numa.c Sat Nov 10 01:52:27 2001 @@ -15,6 +15,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/hwrpb.h> #include <asm/pgalloc.h> @@ -359,8 +360,13 @@ extern char _text, _etext, _data, _edata; extern char __init_begin, __init_end; extern unsigned long totalram_pages; - unsigned long nid, i; + unsigned long nid, i, num_free_bootmem_pages; mem_map_t * lmem_map; + + num_free_bootmem_pages = 0; + for (nid = 0; nid < numnodes; nid++) + num_free_bootmem_pages += count_free_bootmem_node(NODE_DATA(nid)); + page_cache_init(num_free_bootmem_pages); high_memory = (void *) __va(max_mapnr <<PAGE_SHIFT); --- ./arch/arm/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/arm/mm/init.c Sat Nov 10 01:52:34 2001 @@ -23,6 +23,7 @@ #include <linux/init.h> #include <linux/bootmem.h> #include <linux/blk.h> +#include <linux/pagemap.h> #include <asm/segment.h> #include <asm/mach-types.h> @@ -594,6 +595,7 @@ void __init mem_init(void) { unsigned int codepages, datapages, initpages; + unsigned long num_free_bootmem_pages; int i, node; codepages = &_etext - &_text; @@ -608,6 +610,11 @@ */ if (meminfo.nr_banks != 1) create_memmap_holes(&meminfo); + + num_free_bootmem_pages = 0; + for (node = 0; node < numnodes; node++) + num_free_bootmem_pages += count_free_bootmem_node(NODE_DATA(node)); + page_cache_init(num_free_bootmem_pages); /* this will put all unused low memory onto the freelists */ for (node = 0; node < numnodes; node++) { --- ./arch/i386/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/i386/mm/init.c Sat Nov 10 01:53:43 2001 @@ -455,6 +455,8 @@ #endif high_memory = (void *) __va(max_low_pfn * PAGE_SIZE); + page_cache_init(count_free_bootmem()); + /* clear the zero-page */ memset(empty_zero_page, 0, PAGE_SIZE); --- ./arch/m68k/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/m68k/mm/init.c Sat Nov 10 01:54:47 2001 @@ -20,6 +20,7 @@ #ifdef CONFIG_BLK_DEV_RAM #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/setup.h> #include <asm/uaccess.h> @@ -135,6 +136,8 @@ if (MACH_IS_ATARI) atari_stram_mem_init_hook(); #endif + + page_cache_init(count_free_bootmem()); /* this will put all memory onto the freelists */ totalram_pages = free_all_bootmem(); --- ./arch/mips/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/mips/mm/init.c Sat Nov 10 01:55:09 2001 @@ -28,6 +28,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/bootinfo.h> #include <asm/cachectl.h> @@ -203,6 +204,8 @@ max_mapnr = num_physpages = max_low_pfn; high_memory = (void *) __va(max_mapnr << PAGE_SHIFT); + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); totalram_pages -= setup_zero_pages(); /* Setup zeroed pages. */ --- ./arch/ppc/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/ppc/mm/init.c Sat Nov 10 01:57:34 2001 @@ -34,6 +34,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> /* for initrd_* */ #endif +#include <linux/pagemap.h> #include <asm/pgalloc.h> #include <asm/prom.h> @@ -462,6 +463,8 @@ high_memory = (void *) __va(max_low_pfn * PAGE_SIZE); num_physpages = max_mapnr; /* RAM is assumed contiguous */ + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); --- ./arch/sparc/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/sparc/mm/init.c Sat Nov 10 01:59:48 2001 @@ -25,6 +25,7 @@ #include <linux/init.h> #include <linux/highmem.h> #include <linux/bootmem.h> +#include <linux/pagemap.h> #include <asm/system.h> #include <asm/segment.h> @@ -434,6 +435,8 @@ max_mapnr = last_valid_pfn - (phys_base >> PAGE_SHIFT); high_memory = __va(max_low_pfn << PAGE_SHIFT); + + page_cache_init(count_free_bootmem()); #ifdef DEBUG_BOOTMEM prom_printf("mem_init: Calling free_all_bootmem().\n"); --- ./arch/sparc64/mm/init.c.~1~ Fri Nov 9 18:42:08 2001 +++ ./arch/sparc64/mm/init.c Sat Nov 10 02:00:23 2001 @@ -16,6 +16,7 @@ #include <linux/blk.h> #include <linux/swap.h> #include <linux/swapctl.h> +#include <linux/pagemap.h> #include <asm/head.h> #include <asm/system.h> @@ -1584,6 +1585,8 @@ max_mapnr = last_valid_pfn - (phys_base >> PAGE_SHIFT); high_memory = __va(last_valid_pfn << PAGE_SHIFT); + + page_cache_init(count_free_bootmem()); num_physpages = free_all_bootmem() - 1; --- ./arch/sh/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/sh/mm/init.c Sat Nov 10 01:59:56 2001 @@ -26,6 +26,7 @@ #endif #include <linux/highmem.h> #include <linux/bootmem.h> +#include <linux/pagemap.h> #include <asm/processor.h> #include <asm/system.h> @@ -139,6 +140,7 @@ void __init mem_init(void) { extern unsigned long empty_zero_page[1024]; + unsigned long num_free_bootmem_pages; int codesize, reservedpages, datasize, initsize; int tmp; @@ -148,6 +150,12 @@ /* clear the zero-page */ memset(empty_zero_page, 0, PAGE_SIZE); __flush_wback_region(empty_zero_page, PAGE_SIZE); + + num_free_bootmem_pages = count_free_bootmem_node(NODE_DATA(0)); +#ifdef CONFIG_DISCONTIGMEM + num_free_bootmem_pages += count_free_bootmem_node(NODE_DATA(1)); +#endif + page_cache_init(num_free_bootmem_pages); /* this will put all low memory onto the freelists */ totalram_pages += free_all_bootmem_node(NODE_DATA(0)); --- ./arch/s390/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/s390/mm/init.c Sat Nov 10 01:57:56 2001 @@ -186,6 +186,8 @@ /* clear the zero-page */ memset(empty_zero_page, 0, PAGE_SIZE); + page_cache_init(count_free_bootmem()); + /* this will put all low memory onto the freelists */ totalram_pages += free_all_bootmem(); --- ./arch/ia64/mm/init.c.~1~ Fri Nov 9 19:08:02 2001 +++ ./arch/ia64/mm/init.c Sat Nov 10 01:54:20 2001 @@ -13,6 +13,7 @@ #include <linux/reboot.h> #include <linux/slab.h> #include <linux/swap.h> +#include <linux/pagemap.h> #include <asm/bitops.h> #include <asm/dma.h> @@ -406,6 +407,8 @@ max_mapnr = max_low_pfn; high_memory = __va(max_low_pfn * PAGE_SIZE); + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); --- ./arch/mips64/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/mips64/mm/init.c Sat Nov 10 01:55:30 2001 @@ -25,6 +25,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/bootinfo.h> #include <asm/cachectl.h> @@ -396,6 +397,8 @@ max_mapnr = num_physpages = max_low_pfn; high_memory = (void *) __va(max_mapnr << PAGE_SHIFT); + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); totalram_pages -= setup_zero_pages(); /* Setup zeroed pages. */ --- ./arch/mips64/sgi-ip27/ip27-memory.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/mips64/sgi-ip27/ip27-memory.c Sat Nov 10 02:02:33 2001 @@ -15,6 +15,7 @@ #include <linux/mm.h> #include <linux/bootmem.h> #include <linux/swap.h> +#include <linux/pagemap.h> #include <asm/page.h> #include <asm/bootinfo.h> @@ -277,6 +278,11 @@ num_physpages = numpages; /* memory already sized by szmem */ max_mapnr = pagenr; /* already found during paging_init */ high_memory = (void *) __va(max_mapnr << PAGE_SHIFT); + + tmp = 0; + for (nid = 0; nid < numnodes; nid++) + tmp += count_free_bootmem_node(NODE_DATA(nid)); + page_cache_init(tmp); for (nid = 0; nid < numnodes; nid++) { --- ./arch/parisc/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/parisc/mm/init.c Sat Nov 10 01:57:11 2001 @@ -17,6 +17,7 @@ #include <linux/pci.h> /* for hppa_dma_ops and pcxl_dma_ops */ #include <linux/swap.h> #include <linux/unistd.h> +#include <linux/pagemap.h> #include <asm/pgalloc.h> @@ -48,6 +49,8 @@ { max_mapnr = num_physpages = max_low_pfn; high_memory = __va(max_low_pfn * PAGE_SIZE); + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); printk("Memory: %luk available\n", totalram_pages << (PAGE_SHIFT-10)); --- ./arch/cris/mm/init.c.~1~ Sun Oct 21 02:47:53 2001 +++ ./arch/cris/mm/init.c Sat Nov 10 01:53:10 2001 @@ -95,6 +95,7 @@ #include <linux/swap.h> #include <linux/smp.h> #include <linux/bootmem.h> +#include <linux/pagemap.h> #include <asm/system.h> #include <asm/segment.h> @@ -366,6 +367,8 @@ max_mapnr = num_physpages = max_low_pfn - min_low_pfn; + page_cache_init(count_free_bootmem()); + /* this will put all memory onto the freelists */ totalram_pages = free_all_bootmem(); --- ./arch/s390x/mm/init.c.~1~ Fri Nov 9 19:08:02 2001 +++ ./arch/s390x/mm/init.c Sat Nov 10 01:58:14 2001 @@ -198,6 +198,8 @@ /* clear the zero-page */ memset(empty_zero_page, 0, PAGE_SIZE); + page_cache_init(count_free_bootmem()); + /* this will put all low memory onto the freelists */ totalram_pages += free_all_bootmem(); --- ./include/linux/bootmem.h.~1~ Fri Nov 9 19:35:08 2001 +++ ./include/linux/bootmem.h Sat Nov 10 02:33:45 2001 @@ -43,11 +43,13 @@ #define alloc_bootmem_low_pages(x) \ __alloc_bootmem((x), PAGE_SIZE, 0) extern unsigned long __init free_all_bootmem (void); +extern unsigned long __init count_free_bootmem (void); extern unsigned long __init init_bootmem_node (pg_data_t *pgdat, unsigned long freepfn, unsigned long startpfn, unsigned long endpfn); extern void __init reserve_bootmem_node (pg_data_t *pgdat, unsigned long physaddr, unsigned long size); extern void __init free_bootmem_node (pg_data_t *pgdat, unsigned long addr, unsigned long size); extern unsigned long __init free_all_bootmem_node (pg_data_t *pgdat); +extern unsigned long __init count_free_bootmem_node (pg_data_t *pgdat); extern void * __init __alloc_bootmem_node (pg_data_t *pgdat, unsigned long size, unsigned long align, unsigned long goal); #define alloc_bootmem_node(pgdat, x) \ __alloc_bootmem_node((pgdat), (x), SMP_CACHE_BYTES, __pa(MAX_DMA_ADDRESS)) --- ./init/main.c.~1~ Fri Nov 9 19:08:11 2001 +++ ./init/main.c Sat Nov 10 04:58:16 2001 @@ -597,7 +597,6 @@ proc_caches_init(); vfs_caches_init(mempages); buffer_init(mempages); - page_cache_init(mempages); #if defined(CONFIG_ARCH_S390) ccwcache_init(); #endif --- ./mm/filemap.c.~1~ Fri Nov 9 19:08:11 2001 +++ ./mm/filemap.c Sat Nov 10 05:15:16 2001 @@ -24,6 +24,7 @@ #include <linux/mm.h> #include <linux/iobuf.h> #include <linux/compiler.h> +#include <linux/bootmem.h> #include <asm/pgalloc.h> #include <asm/uaccess.h> @@ -2929,28 +2930,48 @@ goto unlock; } +/* This is called from the arch specific mem_init routine. + * It is done right before free_all_bootmem (or NUMA equivalent). + * + * The mempages arg is the number of pages free_all_bootmem is + * going to liberate, or a close approximation. + * + * We have to use bootmem because on huge systems (ie. 16GB ram) + * get_free_pages cannot give us a large enough allocation. + */ void __init page_cache_init(unsigned long mempages) { - unsigned long htable_size, order; + unsigned long htable_size, real_size; htable_size = mempages; htable_size *= sizeof(struct page *); - for(order = 0; (PAGE_SIZE << order) < htable_size; order++) + + for (real_size = 1UL; real_size < htable_size; real_size <<= 1UL) ; do { - unsigned long tmp = (PAGE_SIZE << order) / sizeof(struct page *); + unsigned long tmp = (real_size / sizeof(struct page *)); + unsigned long align; page_hash_bits = 0; while((tmp >>= 1UL) != 0UL) page_hash_bits++; + + align = real_size; + if (align > (4UL * 1024UL * 1024UL)) + align = (4UL * 1024UL * 1024UL); + + page_hash_table = __alloc_bootmem(real_size, align, + __pa(MAX_DMA_ADDRESS)); + + /* Perhaps the alignment was too strict. */ + if (page_hash_table == NULL) + page_hash_table = alloc_bootmem(real_size); + } while (page_hash_table == NULL && + (real_size >>= 1UL) >= PAGE_SIZE); - page_hash_table = (struct page **) - __get_free_pages(GFP_ATOMIC, order); - } while(page_hash_table == NULL && --order > 0); - - printk("Page-cache hash table entries: %d (order: %ld, %ld bytes)\n", - (1 << page_hash_bits), order, (PAGE_SIZE << order)); + printk("Page-cache hash table entries: %d (%ld bytes)\n", + (1 << page_hash_bits), real_size); if (!page_hash_table) panic("Failed to allocate page hash table\n"); memset((void *)page_hash_table, 0, PAGE_HASH_SIZE * sizeof(struct page *)); ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-10 13:29 ` David S. Miller @ 2001-11-10 13:44 ` David S. Miller 2001-11-10 13:52 ` David S. Miller 1 sibling, 0 replies; 49+ messages in thread From: David S. Miller @ 2001-11-10 13:44 UTC (permalink / raw) To: anton; +Cc: ak, mingo, linux-kernel From: "David S. Miller" <davem@redhat.com> Date: Sat, 10 Nov 2001 05:29:17 -0800 (PST) Anton, are you bored? :-) If so, could you test out the patch below on your ppc64 box? It does the "page hash table via bootmem" thing. It is against 2.4.15-pre2 Erm, ignore this patch, it was incomplete, I'll diff it up properly. Sorry... Franks a lot, David S. Miller davem@redhat.com ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-10 13:29 ` David S. Miller 2001-11-10 13:44 ` David S. Miller @ 2001-11-10 13:52 ` David S. Miller 2001-11-10 14:29 ` Numbers: ext2/ext3/reiser Performance (ext3 is slow) Oktay Akbal 1 sibling, 1 reply; 49+ messages in thread From: David S. Miller @ 2001-11-10 13:52 UTC (permalink / raw) To: anton; +Cc: ak, mingo, linux-kernel Ok, this should be a working patch, try this one :-) diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/alpha/mm/init.c linux/arch/alpha/mm/init.c --- vanilla/linux/arch/alpha/mm/init.c Thu Sep 20 20:02:03 2001 +++ linux/arch/alpha/mm/init.c Sat Nov 10 01:49:56 2001 @@ -23,6 +23,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/system.h> #include <asm/uaccess.h> @@ -360,6 +361,7 @@ mem_init(void) { max_mapnr = num_physpages = max_low_pfn; + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); high_memory = (void *) __va(max_low_pfn * PAGE_SIZE); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/alpha/mm/numa.c linux/arch/alpha/mm/numa.c --- vanilla/linux/arch/alpha/mm/numa.c Sun Aug 12 10:38:48 2001 +++ linux/arch/alpha/mm/numa.c Sat Nov 10 01:52:27 2001 @@ -15,6 +15,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/hwrpb.h> #include <asm/pgalloc.h> @@ -359,8 +360,13 @@ extern char _text, _etext, _data, _edata; extern char __init_begin, __init_end; extern unsigned long totalram_pages; - unsigned long nid, i; + unsigned long nid, i, num_free_bootmem_pages; mem_map_t * lmem_map; + + num_free_bootmem_pages = 0; + for (nid = 0; nid < numnodes; nid++) + num_free_bootmem_pages += count_free_bootmem_node(NODE_DATA(nid)); + page_cache_init(num_free_bootmem_pages); high_memory = (void *) __va(max_mapnr <<PAGE_SHIFT); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/arm/mm/init.c linux/arch/arm/mm/init.c --- vanilla/linux/arch/arm/mm/init.c Thu Oct 11 09:04:57 2001 +++ linux/arch/arm/mm/init.c Sat Nov 10 01:52:34 2001 @@ -23,6 +23,7 @@ #include <linux/init.h> #include <linux/bootmem.h> #include <linux/blk.h> +#include <linux/pagemap.h> #include <asm/segment.h> #include <asm/mach-types.h> @@ -594,6 +595,7 @@ void __init mem_init(void) { unsigned int codepages, datapages, initpages; + unsigned long num_free_bootmem_pages; int i, node; codepages = &_etext - &_text; @@ -608,6 +610,11 @@ */ if (meminfo.nr_banks != 1) create_memmap_holes(&meminfo); + + num_free_bootmem_pages = 0; + for (node = 0; node < numnodes; node++) + num_free_bootmem_pages += count_free_bootmem_node(NODE_DATA(node)); + page_cache_init(num_free_bootmem_pages); /* this will put all unused low memory onto the freelists */ for (node = 0; node < numnodes; node++) { diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/cris/mm/init.c linux/arch/cris/mm/init.c --- vanilla/linux/arch/cris/mm/init.c Thu Jul 26 15:10:06 2001 +++ linux/arch/cris/mm/init.c Sat Nov 10 01:53:10 2001 @@ -95,6 +95,7 @@ #include <linux/swap.h> #include <linux/smp.h> #include <linux/bootmem.h> +#include <linux/pagemap.h> #include <asm/system.h> #include <asm/segment.h> @@ -366,6 +367,8 @@ max_mapnr = num_physpages = max_low_pfn - min_low_pfn; + page_cache_init(count_free_bootmem()); + /* this will put all memory onto the freelists */ totalram_pages = free_all_bootmem(); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/i386/mm/init.c linux/arch/i386/mm/init.c --- vanilla/linux/arch/i386/mm/init.c Thu Sep 20 19:59:20 2001 +++ linux/arch/i386/mm/init.c Sat Nov 10 01:53:43 2001 @@ -455,6 +455,8 @@ #endif high_memory = (void *) __va(max_low_pfn * PAGE_SIZE); + page_cache_init(count_free_bootmem()); + /* clear the zero-page */ memset(empty_zero_page, 0, PAGE_SIZE); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/ia64/mm/init.c linux/arch/ia64/mm/init.c --- vanilla/linux/arch/ia64/mm/init.c Fri Nov 9 18:39:51 2001 +++ linux/arch/ia64/mm/init.c Sat Nov 10 01:54:20 2001 @@ -13,6 +13,7 @@ #include <linux/reboot.h> #include <linux/slab.h> #include <linux/swap.h> +#include <linux/pagemap.h> #include <asm/bitops.h> #include <asm/dma.h> @@ -406,6 +407,8 @@ max_mapnr = max_low_pfn; high_memory = __va(max_low_pfn * PAGE_SIZE); + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/m68k/mm/init.c linux/arch/m68k/mm/init.c --- vanilla/linux/arch/m68k/mm/init.c Thu Sep 20 20:02:03 2001 +++ linux/arch/m68k/mm/init.c Sat Nov 10 01:54:47 2001 @@ -20,6 +20,7 @@ #ifdef CONFIG_BLK_DEV_RAM #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/setup.h> #include <asm/uaccess.h> @@ -135,6 +136,8 @@ if (MACH_IS_ATARI) atari_stram_mem_init_hook(); #endif + + page_cache_init(count_free_bootmem()); /* this will put all memory onto the freelists */ totalram_pages = free_all_bootmem(); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/mips/mm/init.c linux/arch/mips/mm/init.c --- vanilla/linux/arch/mips/mm/init.c Wed Jul 4 11:50:39 2001 +++ linux/arch/mips/mm/init.c Sat Nov 10 01:55:09 2001 @@ -28,6 +28,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/bootinfo.h> #include <asm/cachectl.h> @@ -203,6 +204,8 @@ max_mapnr = num_physpages = max_low_pfn; high_memory = (void *) __va(max_mapnr << PAGE_SHIFT); + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); totalram_pages -= setup_zero_pages(); /* Setup zeroed pages. */ diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/mips64/mm/init.c linux/arch/mips64/mm/init.c --- vanilla/linux/arch/mips64/mm/init.c Wed Jul 4 11:50:39 2001 +++ linux/arch/mips64/mm/init.c Sat Nov 10 01:55:30 2001 @@ -25,6 +25,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> #endif +#include <linux/pagemap.h> #include <asm/bootinfo.h> #include <asm/cachectl.h> @@ -396,6 +397,8 @@ max_mapnr = num_physpages = max_low_pfn; high_memory = (void *) __va(max_mapnr << PAGE_SHIFT); + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); totalram_pages -= setup_zero_pages(); /* Setup zeroed pages. */ diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/mips64/sgi-ip27/ip27-memory.c linux/arch/mips64/sgi-ip27/ip27-memory.c --- vanilla/linux/arch/mips64/sgi-ip27/ip27-memory.c Sun Sep 9 10:43:02 2001 +++ linux/arch/mips64/sgi-ip27/ip27-memory.c Sat Nov 10 02:02:33 2001 @@ -15,6 +15,7 @@ #include <linux/mm.h> #include <linux/bootmem.h> #include <linux/swap.h> +#include <linux/pagemap.h> #include <asm/page.h> #include <asm/bootinfo.h> @@ -277,6 +278,11 @@ num_physpages = numpages; /* memory already sized by szmem */ max_mapnr = pagenr; /* already found during paging_init */ high_memory = (void *) __va(max_mapnr << PAGE_SHIFT); + + tmp = 0; + for (nid = 0; nid < numnodes; nid++) + tmp += count_free_bootmem_node(NODE_DATA(nid)); + page_cache_init(tmp); for (nid = 0; nid < numnodes; nid++) { diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/parisc/mm/init.c linux/arch/parisc/mm/init.c --- vanilla/linux/arch/parisc/mm/init.c Tue Dec 5 12:29:39 2000 +++ linux/arch/parisc/mm/init.c Sat Nov 10 01:57:11 2001 @@ -17,6 +17,7 @@ #include <linux/pci.h> /* for hppa_dma_ops and pcxl_dma_ops */ #include <linux/swap.h> #include <linux/unistd.h> +#include <linux/pagemap.h> #include <asm/pgalloc.h> @@ -48,6 +49,8 @@ { max_mapnr = num_physpages = max_low_pfn; high_memory = __va(max_low_pfn * PAGE_SIZE); + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); printk("Memory: %luk available\n", totalram_pages << (PAGE_SHIFT-10)); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/ppc/mm/init.c linux/arch/ppc/mm/init.c --- vanilla/linux/arch/ppc/mm/init.c Tue Oct 2 09:12:44 2001 +++ linux/arch/ppc/mm/init.c Sat Nov 10 01:57:34 2001 @@ -34,6 +34,7 @@ #ifdef CONFIG_BLK_DEV_INITRD #include <linux/blk.h> /* for initrd_* */ #endif +#include <linux/pagemap.h> #include <asm/pgalloc.h> #include <asm/prom.h> @@ -462,6 +463,8 @@ high_memory = (void *) __va(max_low_pfn * PAGE_SIZE); num_physpages = max_mapnr; /* RAM is assumed contiguous */ + + page_cache_init(count_free_bootmem()); totalram_pages += free_all_bootmem(); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/s390/mm/init.c linux/arch/s390/mm/init.c --- vanilla/linux/arch/s390/mm/init.c Thu Oct 11 09:04:57 2001 +++ linux/arch/s390/mm/init.c Sat Nov 10 01:57:56 2001 @@ -186,6 +186,8 @@ /* clear the zero-page */ memset(empty_zero_page, 0, PAGE_SIZE); + page_cache_init(count_free_bootmem()); + /* this will put all low memory onto the freelists */ totalram_pages += free_all_bootmem(); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/s390x/mm/init.c linux/arch/s390x/mm/init.c --- vanilla/linux/arch/s390x/mm/init.c Fri Nov 9 18:39:51 2001 +++ linux/arch/s390x/mm/init.c Sat Nov 10 01:58:14 2001 @@ -198,6 +198,8 @@ /* clear the zero-page */ memset(empty_zero_page, 0, PAGE_SIZE); + page_cache_init(count_free_bootmem()); + /* this will put all low memory onto the freelists */ totalram_pages += free_all_bootmem(); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/sh/mm/init.c linux/arch/sh/mm/init.c --- vanilla/linux/arch/sh/mm/init.c Mon Oct 15 13:36:48 2001 +++ linux/arch/sh/mm/init.c Sat Nov 10 01:59:56 2001 @@ -26,6 +26,7 @@ #endif #include <linux/highmem.h> #include <linux/bootmem.h> +#include <linux/pagemap.h> #include <asm/processor.h> #include <asm/system.h> @@ -139,6 +140,7 @@ void __init mem_init(void) { extern unsigned long empty_zero_page[1024]; + unsigned long num_free_bootmem_pages; int codesize, reservedpages, datasize, initsize; int tmp; @@ -148,6 +150,12 @@ /* clear the zero-page */ memset(empty_zero_page, 0, PAGE_SIZE); __flush_wback_region(empty_zero_page, PAGE_SIZE); + + num_free_bootmem_pages = count_free_bootmem_node(NODE_DATA(0)); +#ifdef CONFIG_DISCONTIGMEM + num_free_bootmem_pages += count_free_bootmem_node(NODE_DATA(1)); +#endif + page_cache_init(num_free_bootmem_pages); /* this will put all low memory onto the freelists */ totalram_pages += free_all_bootmem_node(NODE_DATA(0)); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/sparc/mm/init.c linux/arch/sparc/mm/init.c --- vanilla/linux/arch/sparc/mm/init.c Mon Oct 1 09:19:56 2001 +++ linux/arch/sparc/mm/init.c Sat Nov 10 05:30:31 2001 @@ -1,4 +1,4 @@ -/* $Id: init.c,v 1.100 2001/09/21 22:51:47 davem Exp $ +/* $Id: init.c,v 1.101 2001/11/10 13:30:31 davem Exp $ * linux/arch/sparc/mm/init.c * * Copyright (C) 1995 David S. Miller (davem@caip.rutgers.edu) @@ -25,6 +25,7 @@ #include <linux/init.h> #include <linux/highmem.h> #include <linux/bootmem.h> +#include <linux/pagemap.h> #include <asm/system.h> #include <asm/segment.h> @@ -434,6 +435,8 @@ max_mapnr = last_valid_pfn - (phys_base >> PAGE_SHIFT); high_memory = __va(max_low_pfn << PAGE_SHIFT); + + page_cache_init(count_free_bootmem()); #ifdef DEBUG_BOOTMEM prom_printf("mem_init: Calling free_all_bootmem().\n"); diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/arch/sparc64/mm/init.c linux/arch/sparc64/mm/init.c --- vanilla/linux/arch/sparc64/mm/init.c Tue Oct 30 15:08:11 2001 +++ linux/arch/sparc64/mm/init.c Sat Nov 10 05:30:31 2001 @@ -1,4 +1,4 @@ -/* $Id: init.c,v 1.199 2001/10/25 18:48:03 davem Exp $ +/* $Id: init.c,v 1.201 2001/11/10 13:30:31 davem Exp $ * arch/sparc64/mm/init.c * * Copyright (C) 1996-1999 David S. Miller (davem@caip.rutgers.edu) @@ -16,6 +16,7 @@ #include <linux/blk.h> #include <linux/swap.h> #include <linux/swapctl.h> +#include <linux/pagemap.h> #include <asm/head.h> #include <asm/system.h> @@ -1400,7 +1401,7 @@ if (second_alias_page) spitfire_flush_dtlb_nucleus_page(second_alias_page); - flush_tlb_all(); + __flush_tlb_all(); { unsigned long zones_size[MAX_NR_ZONES]; @@ -1584,6 +1585,8 @@ max_mapnr = last_valid_pfn - (phys_base >> PAGE_SHIFT); high_memory = __va(last_valid_pfn << PAGE_SHIFT); + + page_cache_init(count_free_bootmem()); num_physpages = free_all_bootmem() - 1; diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/include/linux/bootmem.h linux/include/linux/bootmem.h --- vanilla/linux/include/linux/bootmem.h Mon Nov 5 12:43:18 2001 +++ linux/include/linux/bootmem.h Sat Nov 10 02:33:45 2001 @@ -43,11 +43,13 @@ #define alloc_bootmem_low_pages(x) \ __alloc_bootmem((x), PAGE_SIZE, 0) extern unsigned long __init free_all_bootmem (void); +extern unsigned long __init count_free_bootmem (void); extern unsigned long __init init_bootmem_node (pg_data_t *pgdat, unsigned long freepfn, unsigned long startpfn, unsigned long endpfn); extern void __init reserve_bootmem_node (pg_data_t *pgdat, unsigned long physaddr, unsigned long size); extern void __init free_bootmem_node (pg_data_t *pgdat, unsigned long addr, unsigned long size); extern unsigned long __init free_all_bootmem_node (pg_data_t *pgdat); +extern unsigned long __init count_free_bootmem_node (pg_data_t *pgdat); extern void * __init __alloc_bootmem_node (pg_data_t *pgdat, unsigned long size, unsigned long align, unsigned long goal); #define alloc_bootmem_node(pgdat, x) \ __alloc_bootmem_node((pgdat), (x), SMP_CACHE_BYTES, __pa(MAX_DMA_ADDRESS)) diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/init/main.c linux/init/main.c --- vanilla/linux/init/main.c Fri Nov 9 18:40:00 2001 +++ linux/init/main.c Sat Nov 10 04:58:16 2001 @@ -597,7 +597,6 @@ proc_caches_init(); vfs_caches_init(mempages); buffer_init(mempages); - page_cache_init(mempages); #if defined(CONFIG_ARCH_S390) ccwcache_init(); #endif diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/mm/bootmem.c linux/mm/bootmem.c --- vanilla/linux/mm/bootmem.c Tue Sep 18 14:10:43 2001 +++ linux/mm/bootmem.c Sat Nov 10 05:18:53 2001 @@ -154,6 +154,9 @@ if (align & (align-1)) BUG(); + offset = (bdata->node_boot_start & (align - 1)); + offset >>= PAGE_SHIFT; + /* * We try to allocate bootmem pages above 'goal' * first, then we try to allocate lower pages. @@ -165,6 +168,7 @@ preferred = 0; preferred = ((preferred + align - 1) & ~(align - 1)) >> PAGE_SHIFT; + preferred += offset; areasize = (size+PAGE_SIZE-1)/PAGE_SIZE; incr = align >> PAGE_SHIFT ? : 1; @@ -184,7 +188,7 @@ fail_block:; } if (preferred) { - preferred = 0; + preferred = offset; goto restart_scan; } return NULL; @@ -272,6 +276,28 @@ return total; } +static unsigned long __init count_free_bootmem_core(pg_data_t *pgdat) +{ + bootmem_data_t *bdata = pgdat->bdata; + unsigned long i, idx, total; + + if (!bdata->node_bootmem_map) BUG(); + + total = 0; + idx = bdata->node_low_pfn - (bdata->node_boot_start >> PAGE_SHIFT); + for (i = 0; i < idx; i++) { + if (!test_bit(i, bdata->node_bootmem_map)) + total++; + } + + /* + * Count the allocator bitmap itself. + */ + total += ((bdata->node_low_pfn-(bdata->node_boot_start >> PAGE_SHIFT))/8 + PAGE_SIZE-1)/PAGE_SIZE; + + return total; +} + unsigned long __init init_bootmem_node (pg_data_t *pgdat, unsigned long freepfn, unsigned long startpfn, unsigned long endpfn) { return(init_bootmem_core(pgdat, freepfn, startpfn, endpfn)); @@ -292,6 +318,11 @@ return(free_all_bootmem_core(pgdat)); } +unsigned long __init count_free_bootmem_node (pg_data_t *pgdat) +{ + return(count_free_bootmem_core(pgdat)); +} + unsigned long __init init_bootmem (unsigned long start, unsigned long pages) { max_low_pfn = pages; @@ -312,6 +343,11 @@ unsigned long __init free_all_bootmem (void) { return(free_all_bootmem_core(&contig_page_data)); +} + +unsigned long __init count_free_bootmem (void) +{ + return(count_free_bootmem_core(&contig_page_data)); } void * __init __alloc_bootmem (unsigned long size, unsigned long align, unsigned long goal) diff -u --recursive --new-file --exclude=CVS --exclude=.cvsignore vanilla/linux/mm/filemap.c linux/mm/filemap.c --- vanilla/linux/mm/filemap.c Fri Nov 9 18:40:00 2001 +++ linux/mm/filemap.c Sat Nov 10 05:15:16 2001 @@ -24,6 +24,7 @@ #include <linux/mm.h> #include <linux/iobuf.h> #include <linux/compiler.h> +#include <linux/bootmem.h> #include <asm/pgalloc.h> #include <asm/uaccess.h> @@ -2929,28 +2930,48 @@ goto unlock; } +/* This is called from the arch specific mem_init routine. + * It is done right before free_all_bootmem (or NUMA equivalent). + * + * The mempages arg is the number of pages free_all_bootmem is + * going to liberate, or a close approximation. + * + * We have to use bootmem because on huge systems (ie. 16GB ram) + * get_free_pages cannot give us a large enough allocation. + */ void __init page_cache_init(unsigned long mempages) { - unsigned long htable_size, order; + unsigned long htable_size, real_size; htable_size = mempages; htable_size *= sizeof(struct page *); - for(order = 0; (PAGE_SIZE << order) < htable_size; order++) + + for (real_size = 1UL; real_size < htable_size; real_size <<= 1UL) ; do { - unsigned long tmp = (PAGE_SIZE << order) / sizeof(struct page *); + unsigned long tmp = (real_size / sizeof(struct page *)); + unsigned long align; page_hash_bits = 0; while((tmp >>= 1UL) != 0UL) page_hash_bits++; + + align = real_size; + if (align > (4UL * 1024UL * 1024UL)) + align = (4UL * 1024UL * 1024UL); + + page_hash_table = __alloc_bootmem(real_size, align, + __pa(MAX_DMA_ADDRESS)); + + /* Perhaps the alignment was too strict. */ + if (page_hash_table == NULL) + page_hash_table = alloc_bootmem(real_size); + } while (page_hash_table == NULL && + (real_size >>= 1UL) >= PAGE_SIZE); - page_hash_table = (struct page **) - __get_free_pages(GFP_ATOMIC, order); - } while(page_hash_table == NULL && --order > 0); - - printk("Page-cache hash table entries: %d (order: %ld, %ld bytes)\n", - (1 << page_hash_bits), order, (PAGE_SIZE << order)); + printk("Page-cache hash table entries: %d (%ld bytes)\n", + (1 << page_hash_bits), real_size); if (!page_hash_table) panic("Failed to allocate page hash table\n"); memset((void *)page_hash_table, 0, PAGE_HASH_SIZE * sizeof(struct page *)); ^ permalink raw reply [flat|nested] 49+ messages in thread
* Numbers: ext2/ext3/reiser Performance (ext3 is slow) 2001-11-10 13:52 ` David S. Miller @ 2001-11-10 14:29 ` Oktay Akbal 2001-11-10 14:47 ` arjan 0 siblings, 1 reply; 49+ messages in thread From: Oktay Akbal @ 2001-11-10 14:29 UTC (permalink / raw) To: linux-kernel Hello ! On my test to optimize mysql-Performance I noticed, that the sql-bench is significantly slower when the tables are stored on a partition with reiserfs than ext2. I assume this is normal due to the overhead of journal in write-intensiv tasks. I reran the test with ext3 and was shocked how slow the bench was then. Here are the numbers for my old K6/400 with scsi-disks. Time to complete sql-bench ext2 176min reiser 203min (+15%) ext3 310min (+76%) (first test with 2.4.14-ext3 319min) I ran all tests multiple times. Since I used the same Kernels this is not an vm-issue. I tested on 2.4.14, 2.4.14+ext3 and 2.5.15-pre2. Since the sql-bench is not an pure fs-test the fs should only play a minor role. +76% time on this test means to mean that either ext3 is horible slow or has a severe bug. For those who know sql-bench I say, that test-insert seems to be the worst case. It shows Total time: 5880 wallclock secs for ext2 and 13277 for ext3. swap was disabled during test. Anyone has an idea, why this ext3 "fails" at this specific test while on normal fs-benchmarks it is much better ? Oktay ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: Numbers: ext2/ext3/reiser Performance (ext3 is slow) 2001-11-10 14:29 ` Numbers: ext2/ext3/reiser Performance (ext3 is slow) Oktay Akbal @ 2001-11-10 14:47 ` arjan 2001-11-10 17:41 ` Oktay Akbal 0 siblings, 1 reply; 49+ messages in thread From: arjan @ 2001-11-10 14:47 UTC (permalink / raw) To: Oktay Akbal; +Cc: linux-kernel In article <Pine.LNX.4.40.0111101516050.14500-100000@omega.hbh.net> you wrote: > Hello ! > Anyone has an idea, why this ext3 "fails" at this specific test while on > normal fs-benchmarks it is much better ? ext3 by default imposes stricter ordering than the other journalling filesystems in order to improve _data_ consistency (as opposed to just the guarantee of consistent metadata as most other filesystems do). if you mount the filesystem with mount -t ext3 -o data=writeback /dev/foo /mnt/bar will make it use the same level of guarantee as reiserfs does. mount -t ext3 -o data=journal /dev/foo /mnt/bar will do FULL data journalling and will also guarantee data integrety after a crash... Greetings, Arjan van de Ven ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: Numbers: ext2/ext3/reiser Performance (ext3 is slow) 2001-11-10 14:47 ` arjan @ 2001-11-10 17:41 ` Oktay Akbal 2001-11-10 17:56 ` Arjan van de Ven 2001-11-15 17:24 ` Stephen C. Tweedie 0 siblings, 2 replies; 49+ messages in thread From: Oktay Akbal @ 2001-11-10 17:41 UTC (permalink / raw) To: arjan; +Cc: linux-kernel On Sat, 10 Nov 2001 arjan@fenrus.demon.nl wrote: > ext3 by default imposes stricter ordering than the other journalling > filesystems in order to improve _data_ consistency (as opposed to just > the guarantee of consistent metadata as most other filesystems do). > if you mount the filesystem with > > mount -t ext3 -o data=writeback /dev/foo /mnt/bar > > will make it use the same level of guarantee as reiserfs does. > > mount -t ext3 -o data=journal /dev/foo /mnt/bar test with writeback and journal a already running. But this will take some time. as far as i can tell now writeback is really much faster. The question is, when to use what mode. I would use data=journal on my CVS-Archive, and maybe writeback on a news-server. But what to use for an database like mysql ? Someone mailed me and asked why use a journal for an database ? Well, I think for speed of reboot after failover or crash. I don't know if mysql journals data itself. Oktay Akbal ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: Numbers: ext2/ext3/reiser Performance (ext3 is slow) 2001-11-10 17:41 ` Oktay Akbal @ 2001-11-10 17:56 ` Arjan van de Ven 2001-11-15 17:24 ` Stephen C. Tweedie 1 sibling, 0 replies; 49+ messages in thread From: Arjan van de Ven @ 2001-11-10 17:56 UTC (permalink / raw) To: Oktay Akbal; +Cc: linux-kernel On Sat, Nov 10, 2001 at 06:41:15PM +0100, Oktay Akbal wrote: > The question is, when to use what mode. I would use data=journal on my > CVS-Archive, and maybe writeback on a news-server. sounds right; add to this that sync NFS mounts also are far better of with data=journal. > But what to use for an database like mysql ? Well you used reiserfs before. data=writeback is equivalent to the protection reiserfs offers. Big databases such as Oracle do their own journalling and will make sure transactions are actually on disk before they finalize the transaction to the requestor. mysql... I'm not sure about, and it also depends on if it's a mostly-read-only database, a mostly-write database or a "mixed" one. In the first cases, mounting "sync" with full journalling will ensure full datasafety; the second case might just be faster with full journalling (full journalling has IO clustering benefits for lots of small, random, writes) but for the mixed case it's a matter of reliablity versus performance..... Greetings, Arjan van de Ven ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: Numbers: ext2/ext3/reiser Performance (ext3 is slow) 2001-11-10 17:41 ` Oktay Akbal 2001-11-10 17:56 ` Arjan van de Ven @ 2001-11-15 17:24 ` Stephen C. Tweedie 1 sibling, 0 replies; 49+ messages in thread From: Stephen C. Tweedie @ 2001-11-15 17:24 UTC (permalink / raw) To: Oktay Akbal; +Cc: arjan, linux-kernel, Stephen Tweedie Hi, On Sat, Nov 10, 2001 at 06:41:15PM +0100, Oktay Akbal wrote: > The question is, when to use what mode. I would use data=journal on my > CVS-Archive, and maybe writeback on a news-server. > But what to use for an database like mysql ? For a database, your application will be specifying the write ordering explicitly with fsync and/or O_SYNC. For the filesystem to try to sync its IO in addition to that is largely redundant. writeback is entirely appriopriate for databases. Remember, the key condition that ordered mode guards against is finding stale blocks in the middle of recently-allocated files. With databases, that's not a huge concern. Except during table creation, most database writes are into existing allocated blocks; and the data in the database is normally accessed directly only by a specified database process, not by normal client processes, so any leaks that do occur if the database extends its file won't be visible to normal users. Cheers, Stephen ^ permalink raw reply [flat|nested] 49+ messages in thread
* [patch] arbitrary size memory allocator, memarea-2.4.15-D6 2001-11-10 4:56 ` Anton Blanchard 2001-11-10 5:09 ` Andi Kleen 2001-11-10 13:29 ` David S. Miller @ 2001-11-12 16:59 ` Ingo Molnar 2001-11-12 18:19 ` Jeff Garzik 2001-11-17 18:00 ` Eric W. Biederman 2 siblings, 2 replies; 49+ messages in thread From: Ingo Molnar @ 2001-11-12 16:59 UTC (permalink / raw) To: linux-kernel Cc: Linus Torvalds, David S. Miller, Anton Blanchard, Alan Cox, linux-kernel [-- Attachment #1: Type: TEXT/PLAIN, Size: 4757 bytes --] in the past couple of years the buddy allocator has started to show limitations that are hurting performance and flexibility. eg. one of the main reasons why we keep MAX_ORDER at an almost obscenely high level is the fact that we occasionally have to allocate big, physically continuous memory areas. We do not realistically expect to be able to allocate such high-order pages after bootup, still every page allocation carries the cost of it. And even with MAX_ORDER at 10, large RAM boxes have hit this limit and are hurting visibly - as witnessed by Anton. Falling back to vmalloc() is not a high-quality option, due to the TLB-miss overhead. If we had an allocator that could handle large, rare but performance-insensitive allocations, then we could decrease MAX_ORDER back to 5 or 6, which would result in less cache-footprint and faster operation of the page allocator. the attached memarea-2.4.15-D6 patch does just this: it implements a new 'memarea' allocator which uses the buddy allocator data structures without impacting buddy allocator performance. It has two main entry points: struct page * alloc_memarea(unsigned int gfp_mask, unsigned int pages); void free_memarea(struct page *area, unsigned int pages); the main properties of the memarea allocator are: - to be an 'unlimited size' allocator: it will find and allocate 100 GB of physically continuous memory if that much RAM is available. - no alignment or size limitations either, size does not have to be a power of 2 like for the buddy allocator, and alignment will be whatever constellation the allocator finds. This property ensures that if there is a sufficiently sized physically continous piece of RAM available, the allocator will find it. The buddy allocator only finds order-2 aligned and order-2 sized pages. - no impact on the performance of the page allocator. (The only (very small) effect is the use of list_del_init() instead of list_del() when allocating pages. This is insignificant as the initialization will be done in two assembly instructions, touching an already present and dirty cacheline.) Obviously, alloc_memarea() can be pretty slow if RAM is getting full, nor does it guarantee allocation, so for non-boot allocations other backup mechanizms have to be used, such as vmalloc(). It is not a replacement for the buddy allocator - it's not intended for frequent use. right now the memarea allocator is used in one place: to allocate the pagecache hash table at boot time. [ Anton, it would be nice if you could check it out on your large-RAM box, does it improve the hash chain situation? ] other candidates of alloc_memarea() usage are: - module code segment allocation, fall back to vmalloc() if failure. - swap map allocation, it uses vmalloc() now. - buffer, inode, dentry, TCP hash allocations. (in case we decrease MAX_ORDER, which the patch does not do yet.) - those funky PCI devices that need some big chunk of physical memory. - other uses? alloc_memarea() tries to optimize away as much as possible from linear scanning of zone mem-maps, but the worst-case scenario is that it has to iterate over all pages - which can be ~256K iterations if eg. we search on a 1 GB box. possible future improvements: - alloc_memarea() could zap clean pagecache pages as well. - if/once reverse pte mappings are added, alloc_memarea() could also initiate the swapout of anonymous & dirty pages. These modifications would make it pretty likely to succeed if the allocation size is realistic. - possibly add 'alignment' and 'offset' to the __alloc_memarea() arguments, to possibly create a given alignment for the memarea, to handle really broken hardware and possibly result in better page coloring as well. - if we extended the buddy allocator to have a page-granularity bitmap as well, then alloc_memarea() could search for physically continuous page areas *much* faster. But this creates a real runtime (and cache footprint) overhead in the buddy allocator. the patch also cleans up the buddy allocator code: - cleaned up the zone structure namespace - removed the memlist_ defines. (I originally added them to play with FIFO vs. LIFO allocation, but now we have settled for the later.) - simplified code - ( fixed index to be unsigned long in rmqueue(). This enables 64-bit systems to have more than 32 TB of RAM in a single zone. [not quite realistic, yet, but hey.] ) NOTE: the memarea allocator pieces are in separate chunks and are completely non-intrusive if the filemap.c change is omitted. i've tested the patch pretty thoroughly on big and small RAM boxes. The patch is against 2.4.15-pre3. Reports, comments, suggestions welcome, Ingo [-- Attachment #2: Type: TEXT/PLAIN, Size: 16147 bytes --] --- linux/kernel/ksyms.c.orig Mon Nov 12 15:24:28 2001 +++ linux/kernel/ksyms.c Mon Nov 12 15:31:59 2001 @@ -91,6 +91,9 @@ /* internal kernel memory management */ EXPORT_SYMBOL(_alloc_pages); EXPORT_SYMBOL(__alloc_pages); +EXPORT_SYMBOL(__alloc_memarea); +EXPORT_SYMBOL(alloc_memarea); +EXPORT_SYMBOL(free_memarea); EXPORT_SYMBOL(alloc_pages_node); EXPORT_SYMBOL(__get_free_pages); EXPORT_SYMBOL(get_zeroed_page); --- linux/mm/page_alloc.c.orig Mon Nov 12 15:05:21 2001 +++ linux/mm/page_alloc.c Mon Nov 12 15:57:09 2001 @@ -43,18 +43,10 @@ * for the normal case, giving better asm-code. */ -#define memlist_init(x) INIT_LIST_HEAD(x) -#define memlist_add_head list_add -#define memlist_add_tail list_add_tail -#define memlist_del list_del -#define memlist_entry list_entry -#define memlist_next(x) ((x)->next) -#define memlist_prev(x) ((x)->prev) - /* * Temporary debugging check. */ -#define BAD_RANGE(zone,x) (((zone) != (x)->zone) || (((x)-mem_map) < (zone)->zone_start_mapnr) || (((x)-mem_map) >= (zone)->zone_start_mapnr+(zone)->size)) +#define BAD_RANGE(zone,x) (((zone) != (x)->zone) || (((x)-mem_map) < (zone)->start_mapnr) || (((x)-mem_map) >= (zone)->start_mapnr+(zone)->size)) /* * Buddy system. Hairy. You really aren't expected to understand this @@ -92,8 +84,8 @@ zone = page->zone; - mask = (~0UL) << order; - base = zone->zone_mem_map; + mask = ~0UL << order; + base = zone->mem_map; page_idx = page - base; if (page_idx & ~mask) BUG(); @@ -105,7 +97,7 @@ zone->free_pages -= mask; - while (mask + (1 << (MAX_ORDER-1))) { + while (mask != ((~0UL) << (MAX_ORDER-1))) { struct page *buddy1, *buddy2; if (area >= zone->free_area + MAX_ORDER) @@ -125,14 +117,13 @@ if (BAD_RANGE(zone,buddy2)) BUG(); - memlist_del(&buddy1->list); + list_del_init(&buddy1->list); mask <<= 1; area++; index >>= 1; page_idx &= mask; } - memlist_add_head(&(base + page_idx)->list, &area->free_list); - + list_add(&(base + page_idx)->list, &area->free_list); spin_unlock_irqrestore(&zone->lock, flags); return; @@ -142,6 +133,11 @@ if (in_interrupt()) goto back_local_freelist; + /* + * Set the page count to 1 here, so that we can + * distinguish local pages from free buddy pages. + */ + set_page_count(page, 1); list_add(&page->list, ¤t->local_pages); page->index = order; current->nr_local_pages++; @@ -150,7 +146,7 @@ #define MARK_USED(index, order, area) \ __change_bit((index) >> (1+(order)), (area)->map) -static inline struct page * expand (zone_t *zone, struct page *page, +static inline struct page * expand(zone_t *zone, struct page *page, unsigned long index, int low, int high, free_area_t * area) { unsigned long size = 1 << high; @@ -161,7 +157,7 @@ area--; high--; size >>= 1; - memlist_add_head(&(page)->list, &(area)->free_list); + list_add(&page->list, &area->free_list); MARK_USED(index, high, area); index += size; page += size; @@ -183,16 +179,16 @@ spin_lock_irqsave(&zone->lock, flags); do { head = &area->free_list; - curr = memlist_next(head); + curr = head->next; if (curr != head) { - unsigned int index; + unsigned long index; - page = memlist_entry(curr, struct page, list); + page = list_entry(curr, struct page, list); if (BAD_RANGE(zone,page)) BUG(); - memlist_del(curr); - index = page - zone->zone_mem_map; + list_del_init(curr); + index = page - zone->mem_map; if (curr_order != MAX_ORDER-1) MARK_USED(index, curr_order, area); zone->free_pages -= 1UL << order; @@ -256,9 +252,8 @@ do { tmp = list_entry(entry, struct page, list); if (tmp->index == order && memclass(tmp->zone, classzone)) { - list_del(entry); + list_del_init(entry); current->nr_local_pages--; - set_page_count(tmp, 1); page = tmp; if (page->buffers) @@ -286,7 +281,7 @@ nr_pages = current->nr_local_pages; /* free in reverse order so that the global order will be lifo */ while ((entry = local_pages->prev) != local_pages) { - list_del(entry); + list_del_init(entry); tmp = list_entry(entry, struct page, list); __free_pages_ok(tmp, tmp->index); if (!nr_pages--) @@ -399,6 +394,232 @@ goto rebalance; } +#ifndef CONFIG_DISCONTIGMEM + +/* + * Return the order if a page is part of a free page, or + * return -1 otherwise. + * + * (This function relies on the fact that the only zero-count pages that + * have a non-empty page->list are pages of the buddy allocator.) + */ +static inline int free_page_order(zone_t *zone, struct page *p) +{ + free_area_t *area; + struct page *page, *base; + unsigned long index0, index, mask; + int order; + + base = zone->mem_map; + index0 = p - base; + + /* + * First find the highest order free page which this page is part of. + */ + for (order = MAX_ORDER-1; order >= 0; order--) { + area = zone->free_area + order - 1; + /* + * eg. for order 4, mask is 0xfffffff0 + */ + mask = ~((1 << order) - 1); + index = index0 & mask; + page = base + index; + + if (!page_count(page) && !list_empty(&page->list)) + break; + } + return order; +} + +/* + * Expand a specific page. The normal expand() function returns the + * last low-order page from the high-order page. + */ +static inline void expand_specific(struct page *page0, zone_t *zone, struct page *bigpage, const int start, free_area_t * area) +{ + unsigned long index0, page_idx; + struct page *base, *page = NULL; + int order = start; + + base = zone->mem_map; + index0 = page0 - base; + if (!start) + BUG(); + while (order) { + struct page *buddy1, *buddy2; + area--; + order--; + + page_idx = index0 & ~((1 << order)-1); + buddy1 = base + (page_idx ^ (1 << order)); + buddy2 = base + page_idx; + + if (BAD_RANGE(zone,buddy1)) + BUG(); + if (BAD_RANGE(zone,buddy2)) + BUG(); + + list_add(&buddy1->list, &area->free_list); + MARK_USED(page_idx, order, area); + page = buddy2; + } + if (page != page0) + BUG(); +} + +/* + * Allocate a specific page at a given physical address and update + * the buddy allocator data structures accordingly. + */ +static void alloc_page_ptr(zone_t *zone, struct page *p) +{ + free_area_t *area; + struct page *page, *base; + unsigned long index0, index, mask; + int order; + + base = zone->mem_map; + index0 = p - base; + + /* + * First find the highest order free page which this page is part of. + */ + for (order = MAX_ORDER-1; order >= 1; order--) { + area = zone->free_area + order - 1; + /* + * eg. for order 4, mask is 0xfffffff0 + */ + mask = ~((1 << order) - 1); + index = index0 & mask; + page = base + index; + + if (!page_count(page) && !list_empty(&page->list)) + break; + } + if (order < 0) + BUG(); + /* + * Break up any possible higher order page the free + * page might be part of. + */ + if (order > 0) { + area = zone->free_area + order; + index = index0 & ~((1 << order) -1); + page = base + index; + + if (list_empty(&page->list)) + BUG(); + list_del_init(&page->list); + if (!list_empty(&page->list)) + BUG(); + if (order != MAX_ORDER-1) + MARK_USED(index, order, area); + expand_specific(p, zone, page, order, area); + } else { + MARK_USED(index0, 0, zone->free_area); + list_del_init(&p->list); + } + zone->free_pages--; + if (!list_empty(&p->list)) + BUG(); + set_page_count(p, 1); +} + +struct page * __alloc_memarea(unsigned int gfp_mask, unsigned int pages, zonelist_t *zonelist) +{ + struct page *p, *p_found = NULL; + unsigned int found = 0, order; + unsigned long flags; + zone_t **z, *zone; + + z = zonelist->zones; + zone = *z; +repeat: + spin_lock_irqsave(&zone->lock, flags); + if (zone->free_pages < pages) + goto next_zone; + /* + * We search the zone's mem_map for a range of empty pages: + */ + for (p = zone->mem_map; p < zone->mem_map + zone->size; p += 1 << order) { + order = free_page_order(zone, p); + if (order == -1) { + found = 0; + p_found = NULL; + order = 0; + continue; + } + if (!found) + p_found = p; + found += 1 << order; + + if (found < pages) + continue; + /* + * Got the area, now remove every page from the + * buddy structures: + */ + for (p = p_found; p != p_found + pages; p++) { + alloc_page_ptr(zone, p); + if (free_page_order(zone, p) != -1) + BUG(); + } + spin_unlock_irqrestore(&zone->lock, flags); + + return p_found; + } +next_zone: + spin_unlock_irqrestore(&zone->lock, flags); + + zone = *(++z); + if (zone) + goto repeat; + return NULL; +} + +/** + * alloc_memarea - allocate physically continuous pages. + * + * The memory area will be PAGE_SIZE aligned. This allocator is able to + * allocate arbitrary number of physically continuous pages (which does + * not have to be a power of 2), as long as such a free area is available. + * + * The returned address is a struct page pointer, the allocator is able + * to allocate highmem, lowmem and DMA pages as well. + * + * NOTE: while the allocator is always atomic, it has to search the whole + * memory map, so it can be quite slow and is thus not suited for use in + * interrupt handlers. It should only be used for initialization-time + * allocation of larger memory areas. Also, since the allocator does not + * attempt to free any memory to be able to fulfill the allocation request, + * the caller either has to make sure the call happens at boot-time, or that + * he can fall back to other means of allocation such as vmalloc(). + * + * @gfp_mask: allocation type + * @pages: the number of pages to be allocated + */ +struct page * alloc_memarea(unsigned int gfp_mask, unsigned int pages) +{ + return __alloc_memarea(gfp_mask, pages, + contig_page_data.node_zonelists+(gfp_mask & GFP_ZONEMASK)); +} + +/** + * free_memarea - free a set of physically continuous pages. + * + * @area: the first page in the area + * @pages: size of the area, in pages + */ +void free_memarea(struct page *area, unsigned int pages) +{ + int i; + + for (i = 0; i < pages; i++) + __free_page(area + i); +} + +#endif + /* * Common helper functions. */ @@ -554,7 +775,7 @@ curr = head; nr = 0; for (;;) { - curr = memlist_next(curr); + curr = curr->next; if (curr == head) break; nr++; @@ -689,7 +910,7 @@ set_page_count(p, 0); SetPageReserved(p); init_waitqueue_head(&p->wait); - memlist_init(&p->list); + INIT_LIST_HEAD(&p->list); } offset = lmem_map - mem_map; @@ -706,7 +927,7 @@ zone->size = size; zone->name = zone_names[j]; zone->lock = SPIN_LOCK_UNLOCKED; - zone->zone_pgdat = pgdat; + zone->pgdat = pgdat; zone->free_pages = 0; zone->need_balance = 0; if (!size) @@ -723,9 +944,9 @@ zone->pages_low = mask*2; zone->pages_high = mask*3; - zone->zone_mem_map = mem_map + offset; - zone->zone_start_mapnr = offset; - zone->zone_start_paddr = zone_start_paddr; + zone->mem_map = mem_map + offset; + zone->start_mapnr = offset; + zone->start_paddr = zone_start_paddr; if ((zone_start_paddr >> PAGE_SHIFT) & (zone_required_alignment-1)) printk("BUG: wrong zone alignment, it will crash\n"); @@ -742,7 +963,7 @@ for (i = 0; ; i++) { unsigned long bitmap_size; - memlist_init(&zone->free_area[i].free_list); + INIT_LIST_HEAD(&zone->free_area[i].free_list); if (i == MAX_ORDER-1) { zone->free_area[i].map = NULL; break; --- linux/mm/filemap.c.orig Mon Nov 12 15:05:21 2001 +++ linux/mm/filemap.c Mon Nov 12 15:25:21 2001 @@ -2931,23 +2931,29 @@ void __init page_cache_init(unsigned long mempages) { - unsigned long htable_size, order; + unsigned long htable_size, order, tmp; + struct page *area; htable_size = mempages; htable_size *= sizeof(struct page *); for(order = 0; (PAGE_SIZE << order) < htable_size; order++) ; - do { - unsigned long tmp = (PAGE_SIZE << order) / sizeof(struct page *); + tmp = (PAGE_SIZE << order) / sizeof(struct page *); - page_hash_bits = 0; - while((tmp >>= 1UL) != 0UL) - page_hash_bits++; + page_hash_bits = 0; + while((tmp >>= 1UL) != 0UL) + page_hash_bits++; - page_hash_table = (struct page **) - __get_free_pages(GFP_ATOMIC, order); - } while(page_hash_table == NULL && --order > 0); + /* + * We allocate the optimal-size structure. + * There is something seriously bad wrt. the sizing of the + * hash table if this allocation does not succeed, and we + * want to know about those cases! + */ + area = alloc_memarea(GFP_KERNEL, 1 << order); + if (area) + page_hash_table = page_address(area); printk("Page-cache hash table entries: %d (order: %ld, %ld bytes)\n", (1 << page_hash_bits), order, (PAGE_SIZE << order)); --- linux/mm/vmscan.c.orig Mon Nov 12 15:05:21 2001 +++ linux/mm/vmscan.c Mon Nov 12 15:25:21 2001 @@ -608,7 +608,7 @@ { zone_t * first_classzone; - first_classzone = classzone->zone_pgdat->node_zones; + first_classzone = classzone->pgdat->node_zones; while (classzone >= first_classzone) { if (classzone->free_pages > classzone->pages_high) return 0; --- linux/include/linux/mm.h.orig Mon Nov 12 15:05:21 2001 +++ linux/include/linux/mm.h Mon Nov 12 15:25:02 2001 @@ -369,6 +369,11 @@ extern unsigned long FASTCALL(__get_free_pages(unsigned int gfp_mask, unsigned int order)); extern unsigned long FASTCALL(get_zeroed_page(unsigned int gfp_mask)); +extern struct page * FASTCALL(__alloc_memarea(unsigned int gfp_mask, unsigned int pages, zonelist_t *zonelist)); +extern struct page * FASTCALL(alloc_memarea(unsigned int gfp_mask, unsigned int pages)); +extern void FASTCALL(free_memarea(struct page *area, unsigned int pages)); + + #define __get_free_page(gfp_mask) \ __get_free_pages((gfp_mask),0) --- linux/include/linux/mmzone.h.orig Mon Nov 12 15:05:12 2001 +++ linux/include/linux/mmzone.h Mon Nov 12 15:13:23 2001 @@ -50,10 +50,10 @@ /* * Discontig memory support fields. */ - struct pglist_data *zone_pgdat; - struct page *zone_mem_map; - unsigned long zone_start_paddr; - unsigned long zone_start_mapnr; + struct pglist_data *pgdat; + struct page *mem_map; + unsigned long start_paddr; + unsigned long start_mapnr; /* * rarely used fields: @@ -113,7 +113,7 @@ extern int numnodes; extern pg_data_t *pgdat_list; -#define memclass(pgzone, classzone) (((pgzone)->zone_pgdat == (classzone)->zone_pgdat) \ +#define memclass(pgzone, classzone) (((pgzone)->pgdat == (classzone)->pgdat) \ && ((pgzone) <= (classzone))) /* --- linux/include/asm-alpha/pgtable.h.orig Mon Nov 12 15:05:19 2001 +++ linux/include/asm-alpha/pgtable.h Mon Nov 12 15:12:24 2001 @@ -194,7 +194,7 @@ #define PAGE_TO_PA(page) ((page - mem_map) << PAGE_SHIFT) #else #define PAGE_TO_PA(page) \ - ((((page)-(page)->zone->zone_mem_map) << PAGE_SHIFT) \ + ((((page)-(page)->zone->mem_map) << PAGE_SHIFT) \ + (page)->zone->zone_start_paddr) #endif @@ -213,7 +213,7 @@ pte_t pte; \ unsigned long pfn; \ \ - pfn = ((unsigned long)((page)-(page)->zone->zone_mem_map)) << 32; \ + pfn = ((unsigned long)((page)-(page)->zone->mem_map)) << 32; \ pfn += (page)->zone->zone_start_paddr << (32-PAGE_SHIFT); \ pte_val(pte) = pfn | pgprot_val(pgprot); \ \ --- linux/include/asm-mips64/pgtable.h.orig Mon Nov 12 15:05:12 2001 +++ linux/include/asm-mips64/pgtable.h Mon Nov 12 15:12:24 2001 @@ -485,7 +485,7 @@ #define PAGE_TO_PA(page) ((page - mem_map) << PAGE_SHIFT) #else #define PAGE_TO_PA(page) \ - ((((page)-(page)->zone->zone_mem_map) << PAGE_SHIFT) \ + ((((page)-(page)->zone->mem_map) << PAGE_SHIFT) \ + ((page)->zone->zone_start_paddr)) #endif #define mk_pte(page, pgprot) \ ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: [patch] arbitrary size memory allocator, memarea-2.4.15-D6 2001-11-12 16:59 ` [patch] arbitrary size memory allocator, memarea-2.4.15-D6 Ingo Molnar @ 2001-11-12 18:19 ` Jeff Garzik 2001-11-12 23:26 ` Ingo Molnar 2001-11-13 15:59 ` Riley Williams 2001-11-17 18:00 ` Eric W. Biederman 1 sibling, 2 replies; 49+ messages in thread From: Jeff Garzik @ 2001-11-12 18:19 UTC (permalink / raw) To: mingo Cc: linux-kernel, Linus Torvalds, David S. Miller, Anton Blanchard, Alan Cox Ingo Molnar wrote: > the attached memarea-2.4.15-D6 patch does just this: it implements a new > 'memarea' allocator which uses the buddy allocator data structures without > impacting buddy allocator performance. It has two main entry points: > > struct page * alloc_memarea(unsigned int gfp_mask, unsigned int pages); > void free_memarea(struct page *area, unsigned int pages); > > the main properties of the memarea allocator are: > > - to be an 'unlimited size' allocator: it will find and allocate 100 GB > of physically continuous memory if that much RAM is available. [...] > Obviously, alloc_memarea() can be pretty slow if RAM is getting full, nor > does it guarantee allocation, so for non-boot allocations other backup > mechanizms have to be used, such as vmalloc(). It is not a replacement for > the buddy allocator - it's not intended for frequent use. What's wrong with bigphysarea patch or bootmem? In the realm of frame grabbers this is a known and solved problem... With bootmem you know that (for example) 100GB of physically contiguous memory is likely to be available; and after boot, memory get fragmented and the likelihood of alloc_memarea success decreases drastically... just like bootmem. Back when I was working on the Matrox Meteor II driver, which requires as large of a contiguous RAM area as you can give it, bootmem was suggested as the solution. IMHO your patch is not needed. If someone needs a -huge- slab of memory, then they should allocate it at boot time when they are sure they will get it. Otherwise it's an exercise in futility, because they will be forced to use a fallback method like vmalloc anyway. Jeff -- Jeff Garzik | Only so many songs can be sung Building 1024 | with two lips, two lungs, and one tongue. MandrakeSoft | - nomeansno ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: [patch] arbitrary size memory allocator, memarea-2.4.15-D6 2001-11-12 18:19 ` Jeff Garzik @ 2001-11-12 23:26 ` Ingo Molnar 2001-11-13 15:59 ` Riley Williams 1 sibling, 0 replies; 49+ messages in thread From: Ingo Molnar @ 2001-11-12 23:26 UTC (permalink / raw) To: Jeff Garzik Cc: linux-kernel, Linus Torvalds, David S. Miller, Anton Blanchard, Alan Cox On Mon, 12 Nov 2001, Jeff Garzik wrote: > What's wrong with bigphysarea patch or bootmem? In the realm of frame > grabbers this is a known and solved problem... bootmem is a limited boot-time only thing, eg. it does not work from modules. Nor is it generic enough to be eg. highmem-capable. It's not really a fully capable allocator, i wrote bootmem.c rather as a simple bootstap allocator, to be used to initialize the real allocator cleanly, and to be used in some criticial subsystems that initialize before the main allocator. bigphysarea is a separate allocator, while alloc_memarea() shares the page pool with the buddy allocator. > With bootmem you know that (for example) 100GB of physically > contiguous memory is likely to be available; and after boot, memory > get fragmented and the likelihood of alloc_memarea success decreases > drastically... just like bootmem. the likelyhood of alloc_memarea() succeeding should be pretty good even on loaded systems, once the two improvements i mentioned (zap clean pagecache pages, reverse-flush & zap dirty pages) are added to it. Until then it's indeed most effective at boot-time and deteriorates afterwards, so it basically has bootmem's capabilities without most of the limitations of bootmem. Ingo ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: [patch] arbitrary size memory allocator, memarea-2.4.15-D6 2001-11-12 18:19 ` Jeff Garzik 2001-11-12 23:26 ` Ingo Molnar @ 2001-11-13 15:59 ` Riley Williams 2001-11-14 20:49 ` Tom Gall 2001-11-15 1:11 ` Anton Blanchard 1 sibling, 2 replies; 49+ messages in thread From: Riley Williams @ 2001-11-13 15:59 UTC (permalink / raw) To: Jeff Garzik; +Cc: Linux Kernel Hi Jeff. > With bootmem you know that (for example) 100GB of physically > contiguous memory is likely to be available... Please point me to where you found a machine with 100 Gigabytes of RAM as I could realy make use of that here... Best wishes from Riley. ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: [patch] arbitrary size memory allocator, memarea-2.4.15-D6 2001-11-13 15:59 ` Riley Williams @ 2001-11-14 20:49 ` Tom Gall 2001-11-15 1:11 ` Anton Blanchard 1 sibling, 0 replies; 49+ messages in thread From: Tom Gall @ 2001-11-14 20:49 UTC (permalink / raw) To: Riley Williams; +Cc: Jeff Garzik, Linux Kernel Riley Williams wrote: > > Hi Jeff. > > > With bootmem you know that (for example) 100GB of physically > > contiguous memory is likely to be available... > > Please point me to where you found a machine with 100 Gigabytes of RAM > as I could realy make use of that here... Well as an example, the new IBM pSeries p690, and yes it does run Linux. Will it be 100 Gig of physically contiguous memory? Not necessarily but it certainly could be. Now if it would only fit under my desk.... > Best wishes from Riley. Regards, Tom -- Tom Gall - [embedded] [PPC64 | PPC32] Code Monkey Peace, Love & "Where's the ka-boom? There was Linux Technology Center supposed to be an earth http://www.ibm.com/linux/ltc/ shattering ka-boom!" (w) tom_gall@vnet.ibm.com -- Marvin Martian (w) 507-253-4558 (h) tgall@rochcivictheatre.org ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: [patch] arbitrary size memory allocator, memarea-2.4.15-D6 2001-11-13 15:59 ` Riley Williams 2001-11-14 20:49 ` Tom Gall @ 2001-11-15 1:11 ` Anton Blanchard 1 sibling, 0 replies; 49+ messages in thread From: Anton Blanchard @ 2001-11-15 1:11 UTC (permalink / raw) To: Riley Williams; +Cc: Jeff Garzik, Linux Kernel > Please point me to where you found a machine with 100 Gigabytes of RAM > as I could realy make use of that here... Really 128GB isnt that much RAM any more, and the negative effects from deep hash chains will probably start hitting at ~8GB. Most non-intel architectures (sparc64, alpha, ppc64) have booted Linux with > 100GB RAM - we have run 256GB ppc64 machines. Anton ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: [patch] arbitrary size memory allocator, memarea-2.4.15-D6 2001-11-12 16:59 ` [patch] arbitrary size memory allocator, memarea-2.4.15-D6 Ingo Molnar 2001-11-12 18:19 ` Jeff Garzik @ 2001-11-17 18:00 ` Eric W. Biederman 1 sibling, 0 replies; 49+ messages in thread From: Eric W. Biederman @ 2001-11-17 18:00 UTC (permalink / raw) To: mingo; +Cc: linux-kernel, linux-mm Ingo Molnar <mingo@elte.hu> writes: > in the past couple of years the buddy allocator has started to show > limitations that are hurting performance and flexibility. > > eg. one of the main reasons why we keep MAX_ORDER at an almost obscenely > high level is the fact that we occasionally have to allocate big, > physically continuous memory areas. We do not realistically expect to be > able to allocate such high-order pages after bootup, still every page > allocation carries the cost of it. And even with MAX_ORDER at 10, large > RAM boxes have hit this limit and are hurting visibly - as witnessed by > Anton. Falling back to vmalloc() is not a high-quality option, due to the > TLB-miss overhead. And additionally vmalloc is nearly as subject to fragmentation as contiguous memory is. And on some machines the amount of memory dedicated to vmalloc is comparatively small. 128M or so. > If we had an allocator that could handle large, rare but > performance-insensitive allocations, then we could decrease MAX_ORDER back > to 5 or 6, which would result in less cache-footprint and faster operation > of the page allocator. It definitely sounds reasonable. A special allocator for a hard and different case. > Obviously, alloc_memarea() can be pretty slow if RAM is getting full, nor > does it guarantee allocation, so for non-boot allocations other backup > mechanizms have to be used, such as vmalloc(). It is not a replacement for > the buddy allocator - it's not intended for frequent use. If we can fix it so that this allocator works well enough that you don't need a backup allocator but instead when this fails you can pretty much figure that you couldn't allocate what you are after then it has a much better chance of being useful. > alloc_memarea() tries to optimize away as much as possible from linear > scanning of zone mem-maps, but the worst-case scenario is that it has to > iterate over all pages - which can be ~256K iterations if eg. we search on > a 1 GB box. Hmm. Can't you assume that buddies are coalesced? > possible future improvements: > > - alloc_memarea() could zap clean pagecache pages as well. > > - if/once reverse pte mappings are added, alloc_memarea() could also > initiate the swapout of anonymous & dirty pages. These modifications > would make it pretty likely to succeed if the allocation size is > realistic. Except for anonymous pages we have perfectly serviceable reverse mappings. They are slow but this is a performance insensitive allocator so it shouldn't be a big deal to use page->address_space->i_mmap. But I suspect you could get farther by generating a zone on the fly for the area you want to free up, and using the normal mechanisms, or a slight variation on them to free up all the pages in that area. > - possibly add 'alignment' and 'offset' to the __alloc_memarea() > arguments, to possibly create a given alignment for the memarea, to > handle really broken hardware and possibly result in better page > coloring as well. > > - if we extended the buddy allocator to have a page-granularity bitmap as > well, then alloc_memarea() could search for physically continuous page > areas *much* faster. But this creates a real runtime (and cache > footprint) overhead in the buddy allocator. I don't see the need to make this allocator especially fast so I doubt that would really help. > i've tested the patch pretty thoroughly on big and small RAM boxes. The > patch is against 2.4.15-pre3. > > Reports, comments, suggestions welcome, See above. Eric ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-08 23:00 ` speed difference between using hard-linked and modular drives? Andi Kleen 2001-11-09 0:05 ` Anton Blanchard @ 2001-11-09 3:12 ` Rusty Russell 2001-11-09 5:59 ` Andi Kleen 2001-11-09 11:16 ` Helge Hafting 1 sibling, 2 replies; 49+ messages in thread From: Rusty Russell @ 2001-11-09 3:12 UTC (permalink / raw) To: Andi Kleen; +Cc: mingo, linux-kernel On 09 Nov 2001 00:00:19 +0100 Andi Kleen <ak@suse.de> wrote: > Ingo Molnar <mingo@elte.hu> writes: > > > > we should fix this by trying to allocate continuous physical memory if > > possible, and fall back to vmalloc() only if this allocation fails. > > Check -aa. A patch to do that has been in there for some time now. > > -Andi > > P.S.: It makes a measurable difference with some Oracle benchmarks with > the Qlogic driver. Modules have lots of little disadvantages that add up. The speed penalty on various platforms is one, the load/unload race complexity is another. There's a widespread "modules are free!" mentality: they're not, and we can add complexity trying to make them "free", but it might be wiser to realize that dynamic adding and deleting from a running kernel is a problem on par with a pagagble kernel, and may not be the greatest thing since sliced bread. Rusty. ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 3:12 ` speed difference between using hard-linked and modular drives? Rusty Russell @ 2001-11-09 5:59 ` Andi Kleen 2001-11-09 11:16 ` Helge Hafting 1 sibling, 0 replies; 49+ messages in thread From: Andi Kleen @ 2001-11-09 5:59 UTC (permalink / raw) To: Rusty Russell; +Cc: Andi Kleen, mingo, linux-kernel On Fri, Nov 09, 2001 at 02:12:15PM +1100, Rusty Russell wrote: > Modules have lots of little disadvantages that add up. The speed penalty > on various platforms is one, the load/unload race complexity is another. At least for the speed penalty due to TLB thrashing: I would not really blame modules in this case, it is just an application crying for large pages support. -Andi ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 3:12 ` speed difference between using hard-linked and modular drives? Rusty Russell 2001-11-09 5:59 ` Andi Kleen @ 2001-11-09 11:16 ` Helge Hafting 2001-11-12 9:59 ` Rusty Russell 1 sibling, 1 reply; 49+ messages in thread From: Helge Hafting @ 2001-11-09 11:16 UTC (permalink / raw) To: Rusty Russell, linux-kernel Rusty Russell wrote: > Modules have lots of little disadvantages that add up. The speed penalty > on various platforms is one, the load/unload race complexity is another. > Races can be fixed. (Isn't that one of the things considered for 2.5?) Speed penalties on various platforms is there to stay, so you simply have to weigh that against having more swappable RAM. I use the following rules of thumb: 1. Modules only for seldom-used devices. A module for the mouse is no use if you do all your work in X. There's simply no gain from a module that never unloads. A seldom used fs may be modular though. I rarely use cd's, so isofs is a module on my machine. 2. No modules for high-speed stuff like harddisks and network, that's where you might feel the slowdown. Low-speed stuff like floppy and cdrom drivers are modular though. Helge Hafting ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-09 11:16 ` Helge Hafting @ 2001-11-12 9:59 ` Rusty Russell 2001-11-12 23:23 ` David S. Miller 0 siblings, 1 reply; 49+ messages in thread From: Rusty Russell @ 2001-11-12 9:59 UTC (permalink / raw) To: Helge Hafting; +Cc: linux-kernel On Fri, 09 Nov 2001 12:16:49 +0100 Helge Hafting <helgehaf@idb.hist.no> wrote: > Rusty Russell wrote: > > > Modules have lots of little disadvantages that add up. The speed penalty > > on various platforms is one, the load/unload race complexity is another. > > > Races can be fixed. (Isn't that one of the things considered for 2.5?) We get more problems if we go preemptible (some seem to thing that preemption is "free"). And some races can be fixed by paying more of a speed penalty (atomic_inc & atomic_dec_and_test for every packet, anyone?). Hope that clarifies, Rusty. ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-12 9:59 ` Rusty Russell @ 2001-11-12 23:23 ` David S. Miller 2001-11-12 23:14 ` Rusty Russell 0 siblings, 1 reply; 49+ messages in thread From: David S. Miller @ 2001-11-12 23:23 UTC (permalink / raw) To: rusty; +Cc: helgehaf, linux-kernel From: Rusty Russell <rusty@rustcorp.com.au> Date: Mon, 12 Nov 2001 20:59:05 +1100 (atomic_inc & atomic_dec_and_test for every packet, anyone?). We already do pay that price, in skb_release_data() :-) ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-12 23:23 ` David S. Miller @ 2001-11-12 23:14 ` Rusty Russell 2001-11-13 1:30 ` Mike Fedyk 0 siblings, 1 reply; 49+ messages in thread From: Rusty Russell @ 2001-11-12 23:14 UTC (permalink / raw) To: David S. Miller; +Cc: helgehaf, linux-kernel In message <20011112.152304.39155908.davem@redhat.com> you write: > From: Rusty Russell <rusty@rustcorp.com.au> > Date: Mon, 12 Nov 2001 20:59:05 +1100 > > (atomic_inc & atomic_dec_and_test for every packet, anyone?). > > We already do pay that price, in skb_release_data() :-) Sorry, I wasn't clear! skb_release_data() does an atomic ops on the skb data region, which is almost certainly on the same CPU. This is an atomic op on a global counter for the module, which almost certainly isn't. For something which (statistically speaking) never happens (module unload). Ouch, Rusty. -- Premature optmztion is rt of all evl. --DK ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-12 23:14 ` Rusty Russell @ 2001-11-13 1:30 ` Mike Fedyk 2001-11-13 1:15 ` David Lang 0 siblings, 1 reply; 49+ messages in thread From: Mike Fedyk @ 2001-11-13 1:30 UTC (permalink / raw) To: Rusty Russell; +Cc: David S. Miller, helgehaf, linux-kernel On Tue, Nov 13, 2001 at 10:14:22AM +1100, Rusty Russell wrote: > In message <20011112.152304.39155908.davem@redhat.com> you write: > > From: Rusty Russell <rusty@rustcorp.com.au> > > Date: Mon, 12 Nov 2001 20:59:05 +1100 > > > > (atomic_inc & atomic_dec_and_test for every packet, anyone?). > > > > We already do pay that price, in skb_release_data() :-) > > Sorry, I wasn't clear! skb_release_data() does an atomic ops on the > skb data region, which is almost certainly on the same CPU. This is > an atomic op on a global counter for the module, which almost > certainly isn't. > > For something which (statistically speaking) never happens (module > unload). > Is this in the fast path or slow path? If it only happens on (un)load, then there isn't any cost until it's needed... Mike ^ permalink raw reply [flat|nested] 49+ messages in thread
* Re: speed difference between using hard-linked and modular drives? 2001-11-13 1:30 ` Mike Fedyk @ 2001-11-13 1:15 ` David Lang 0 siblings, 0 replies; 49+ messages in thread From: David Lang @ 2001-11-13 1:15 UTC (permalink / raw) To: Mike Fedyk; +Cc: Rusty Russell, David S. Miller, helgehaf, linux-kernel Mike the point is that the module count inc/dec would need to be done for every packet so that when you go to unload you can check the usage value, so the check is done in the slow path, but the inc/dec is done in the fast path. David Lang On Mon, 12 Nov 2001, Mike Fedyk wrote: > Date: Mon, 12 Nov 2001 17:30:14 -0800 > From: Mike Fedyk <mfedyk@matchmail.com> > To: Rusty Russell <rusty@rustcorp.com.au> > Cc: David S. Miller <davem@redhat.com>, helgehaf@idb.hist.no, > linux-kernel@vger.kernel.org > Subject: Re: speed difference between using hard-linked and modular > drives? > > On Tue, Nov 13, 2001 at 10:14:22AM +1100, Rusty Russell wrote: > > In message <20011112.152304.39155908.davem@redhat.com> you write: > > > From: Rusty Russell <rusty@rustcorp.com.au> > > > Date: Mon, 12 Nov 2001 20:59:05 +1100 > > > > > > (atomic_inc & atomic_dec_and_test for every packet, anyone?). > > > > > > We already do pay that price, in skb_release_data() :-) > > > > Sorry, I wasn't clear! skb_release_data() does an atomic ops on the > > skb data region, which is almost certainly on the same CPU. This is > > an atomic op on a global counter for the module, which almost > > certainly isn't. > > > > For something which (statistically speaking) never happens (module > > unload). > > > > Is this in the fast path or slow path? > > If it only happens on (un)load, then there isn't any cost until it's needed... > > Mike > - > To unsubscribe from this list: send the line "unsubscribe linux-kernel" in > the body of a message to majordomo@vger.kernel.org > More majordomo info at http://vger.kernel.org/majordomo-info.html > Please read the FAQ at http://www.tux.org/lkml/ > ^ permalink raw reply [flat|nested] 49+ messages in thread
end of thread, other threads:[~2001-11-17 18:20 UTC | newest]
Thread overview: 49+ messages (download: mbox.gz follow: Atom feed
-- links below jump to the message on this page --
[not found] <Pine.LNX.4.33.0111081802380.15975-100000@localhost.localdomain.suse.lists.linux.kernel>
[not found] ` <Pine.LNX.4.33.0111081836080.15975-100000@localhost.localdomain.suse.lists.linux.kernel>
2001-11-08 23:00 ` speed difference between using hard-linked and modular drives? Andi Kleen
2001-11-09 0:05 ` Anton Blanchard
2001-11-09 5:45 ` Andi Kleen
2001-11-09 6:04 ` David S. Miller
2001-11-09 6:39 ` Andi Kleen
2001-11-09 6:54 ` Andrew Morton
2001-11-09 7:17 ` David S. Miller
2001-11-09 7:16 ` Andrew Morton
2001-11-09 7:24 ` David S. Miller
2001-11-09 8:21 ` Ingo Molnar
2001-11-09 7:35 ` Andrew Morton
2001-11-09 7:44 ` David S. Miller
2001-11-09 7:14 ` David S. Miller
2001-11-09 7:16 ` David S. Miller
2001-11-09 12:59 ` Alan Cox
2001-11-09 12:54 ` David S. Miller
2001-11-09 13:15 ` Philip Dodd
2001-11-09 13:26 ` David S. Miller
2001-11-09 20:45 ` Mike Fedyk
2001-11-09 13:17 ` Andi Kleen
2001-11-09 13:25 ` David S. Miller
2001-11-09 13:39 ` Andi Kleen
2001-11-09 13:41 ` David S. Miller
2001-11-10 5:20 ` Anton Blanchard
2001-11-10 4:56 ` Anton Blanchard
2001-11-10 5:09 ` Andi Kleen
2001-11-10 13:29 ` David S. Miller
2001-11-10 13:44 ` David S. Miller
2001-11-10 13:52 ` David S. Miller
2001-11-10 14:29 ` Numbers: ext2/ext3/reiser Performance (ext3 is slow) Oktay Akbal
2001-11-10 14:47 ` arjan
2001-11-10 17:41 ` Oktay Akbal
2001-11-10 17:56 ` Arjan van de Ven
2001-11-15 17:24 ` Stephen C. Tweedie
2001-11-12 16:59 ` [patch] arbitrary size memory allocator, memarea-2.4.15-D6 Ingo Molnar
2001-11-12 18:19 ` Jeff Garzik
2001-11-12 23:26 ` Ingo Molnar
2001-11-13 15:59 ` Riley Williams
2001-11-14 20:49 ` Tom Gall
2001-11-15 1:11 ` Anton Blanchard
2001-11-17 18:00 ` Eric W. Biederman
2001-11-09 3:12 ` speed difference between using hard-linked and modular drives? Rusty Russell
2001-11-09 5:59 ` Andi Kleen
2001-11-09 11:16 ` Helge Hafting
2001-11-12 9:59 ` Rusty Russell
2001-11-12 23:23 ` David S. Miller
2001-11-12 23:14 ` Rusty Russell
2001-11-13 1:30 ` Mike Fedyk
2001-11-13 1:15 ` David Lang
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox
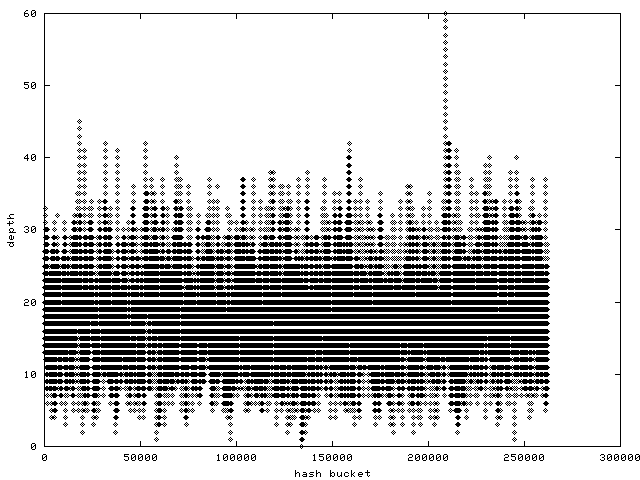{kind=link}
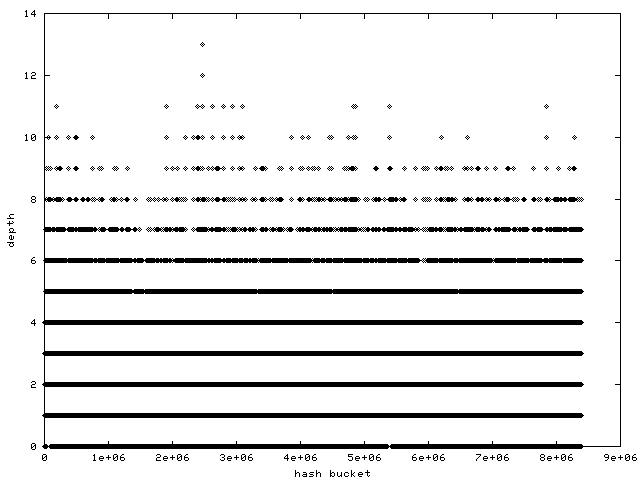{kind=link}