* [net-next PATCH V6 0/2] qdisc: bulk dequeue support
@ 2014-10-01 20:35 Jesper Dangaard Brouer
2014-10-01 20:35 ` [net-next PATCH V6 1/2] qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE Jesper Dangaard Brouer
` (3 more replies)
0 siblings, 4 replies; 42+ messages in thread
From: Jesper Dangaard Brouer @ 2014-10-01 20:35 UTC (permalink / raw)
To: Jesper Dangaard Brouer, netdev, David S. Miller, Tom Herbert,
Eric Dumazet, Hannes Frederic Sowa, Florian Westphal,
Daniel Borkmann
Cc: Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht,
toke
This patchset uses DaveM's recent API changes to dev_hard_start_xmit(),
from the qdisc layer, to implement dequeue bulking.
Patch01: "qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE"
- Implement basic qdisc dequeue bulking
- This time, 100% relying on BQL limits, no magic safe-guard constants
Patch02: "qdisc: dequeue bulking also pickup GSO/TSO packets"
- Extend bulking to bulk several GSO/TSO packets
- Seperate patch, as it introduce a small regression, see test section.
We do have a patch03, which exports a userspace tunable as a BQL
tunable, that can byte-cap or disable the bulking/bursting. But we
could not agree on it internally, thus not sending it now. We
basically strive to avoid adding any new userspace tunable.
Testing patch01:
================
Demonstrating the performance improvement of qdisc dequeue bulking, is
tricky because the effect only "kicks-in" once the qdisc system have a
backlog. Thus, for a backlog to form, we need either 1) to exceed wirespeed
of the link or 2) exceed the capability of the device driver.
For practical use-cases, the measureable effect of this will be a
reduction in CPU usage
01-TCP_STREAM:
--------------
Testing effect for TCP involves disabling TSO and GSO, because TCP
already benefit from bulking, via TSO and especially for GSO segmented
packets. This patch view TSO/GSO as a seperate kind of bulking, and
avoid further bulking of these packet types.
The measured perf diff benefit (at 10Gbit/s) for a single netperf
TCP_STREAM were 9.24% less CPU used on calls to _raw_spin_lock()
(mostly from sch_direct_xmit).
If my E5-2695v2(ES) CPU is tuned according to:
http://netoptimizer.blogspot.dk/2014/04/basic-tuning-for-network-overload.html
Then it is possible that a single netperf TCP_STREAM, with GSO and TSO
disabled, can utilize all bandwidth on a 10Gbit/s link. This will
then cause a standing backlog queue at the qdisc layer.
Trying to pressure the system some more CPU util wise, I'm starting
24x TCP_STREAMs and monitoring the overall CPU utilization. This
confirms bulking saves CPU cycles when it "kicks-in".
Tool mpstat, while stressing the system with netperf 24x TCP_STREAM, shows:
* Disabled bulking: sys:2.58% soft:8.50% idle:88.78%
* Enabled bulking: sys:2.43% soft:7.66% idle:89.79%
02-UDP_STREAM
-------------
The measured perf diff benefit for UDP_STREAM were 6.41% less CPU used
on calls to _raw_spin_lock(). 24x UDP_STREAM with packet size -m 1472 (to
avoid sending UDP/IP fragments).
03-trafgen driver test
----------------------
The performance of the 10Gbit/s ixgbe driver is limited due to
updating the HW ring-queue tail-pointer on every packet. As
previously demonstrated with pktgen.
Using trafgen to send RAW frames from userspace (via AF_PACKET), and
forcing it through qdisc path (with option --qdisc-path and -t0),
sending with 12 CPUs.
I can demonstrate this driver layer limitation:
* 12.8 Mpps with no qdisc bulking
* 14.8 Mpps with qdisc bulking (full 10G-wirespeed)
Testing patch02:
================
Testing Bulking several GSO/TSO packets:
Measuring HoL (Head-of-Line) blocking for TSO and GSO, with
netperf-wrapper. Bulking several TSO show no performance regressions
(requeues were in the area 32 requeues/sec for 10G while transmitting
approx 813Kpps).
Bulking several GSOs does show small regression or very small
improvement (requeues were in the area 8000 requeues/sec, for 10G
while transmitting approx 813Kpps).
Using ixgbe 10Gbit/s with GSO bulking, we can measure some additional
latency. Base-case, which is "normal" GSO bulking, sees varying
high-prio queue delay between 0.38ms to 0.47ms. Bulking several GSOs
together, result in a stable high-prio queue delay of 0.50ms.
Corrosponding to:
(10000*10^6)*((0.50-0.47)/10^3)/8 = 37500 bytes
(10000*10^6)*((0.50-0.38)/10^3)/8 = 150000 bytes
37500/1500 = 25 pkts
150000/1500 = 100 pkts
Using igb at 100Mbit/s with GSO bulking, shows an improvement.
Base-case sees varying high-prio queue delay between 2.23ms to 2.35ms
diff of 0.12ms corrosponding to 1500 bytes at 100Mbit/s. Bulking
several GSOs together, result in a stable high-prio queue delay of
2.23ms.
---
Jesper Dangaard Brouer (2):
qdisc: dequeue bulking also pickup GSO/TSO packets
qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE
include/net/sch_generic.h | 16 ++++++++++++++++
net/sched/sch_generic.c | 40 ++++++++++++++++++++++++++++++++++++++--
2 files changed, 54 insertions(+), 2 deletions(-)
--
^ permalink raw reply [flat|nested] 42+ messages in thread* [net-next PATCH V6 1/2] qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE 2014-10-01 20:35 [net-next PATCH V6 0/2] qdisc: bulk dequeue support Jesper Dangaard Brouer @ 2014-10-01 20:35 ` Jesper Dangaard Brouer 2014-10-01 20:36 ` [net-next PATCH V6 2/2] qdisc: dequeue bulking also pickup GSO/TSO packets Jesper Dangaard Brouer ` (2 subsequent siblings) 3 siblings, 0 replies; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-01 20:35 UTC (permalink / raw) To: Jesper Dangaard Brouer, netdev, David S. Miller, Tom Herbert, Eric Dumazet, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann Cc: Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, toke Based on DaveM's recent API work on dev_hard_start_xmit(), that allows sending/processing an entire skb list. This patch implements qdisc bulk dequeue, by allowing multiple packets to be dequeued in dequeue_skb(). The optimization principle for this is two fold, (1) to amortize locking cost and (2) avoid expensive tailptr update for notifying HW. (1) Several packets are dequeued while holding the qdisc root_lock, amortizing locking cost over several packet. The dequeued SKB list is processed under the TXQ lock in dev_hard_start_xmit(), thus also amortizing the cost of the TXQ lock. (2) Further more, dev_hard_start_xmit() will utilize the skb->xmit_more API to delay HW tailptr update, which also reduces the cost per packet. One restriction of the new API is that every SKB must belong to the same TXQ. This patch takes the easy way out, by restricting bulk dequeue to qdisc's with the TCQ_F_ONETXQUEUE flag, that specifies the qdisc only have attached a single TXQ. Some detail about the flow; dev_hard_start_xmit() will process the skb list, and transmit packets individually towards the driver (see xmit_one()). In case the driver stops midway in the list, the remaining skb list is returned by dev_hard_start_xmit(). In sch_direct_xmit() this returned list is requeued by dev_requeue_skb(). To avoid overshooting the HW limits, which results in requeuing, the patch limits the amount of bytes dequeued, based on the drivers BQL limits. In-effect bulking will only happen for BQL enabled drivers. Small amounts for extra HoL blocking (2x MTU/0.24ms) were measured at 100Mbit/s, with bulking 8 packets, but the oscillating nature of the measurement indicate something, like sched latency might be causing this effect. More comparisons show, that this oscillation goes away occationally. Thus, we disregard this artifact completely and remove any "magic" bulking limit. For now, as a conservative approach, stop bulking when seeing TSO and segmented GSO packets. They already benefit from bulking on their own. A followup patch add this, to allow easier bisect-ability for finding regressions. Jointed work with Hannes, Daniel and Florian. Signed-off-by: Jesper Dangaard Brouer <brouer@redhat.com> Signed-off-by: Hannes Frederic Sowa <hannes@stressinduktion.org> Signed-off-by: Daniel Borkmann <dborkman@redhat.com> Signed-off-by: Florian Westphal <fw@strlen.de> --- V6: - Remove packet "budget" limit, rely 100% on BQL V5: - Changed "budget" limit to 7 packets (from 8) - Choosing to use skb->len, because BQL uses that - Added testing results to patch desc V4: - Patch rewritten in the Red Hat Neuchatel office jointed work with Hannes, Daniel and Florian. - Conservative approach of only using on BQL enabled drivers - No user tunable parameter, but limit bulking to 8 packets. - For now, avoid bulking GSO packets packets. V3: - Correct use of BQL - Some minor adjustments based on feedback. - Default setting only bulk dequeue 1 extra packet (2 packets). V2: - Restruct functions, split out functionality - Use BQL bytelimit to avoid overshooting driver limits --- include/net/sch_generic.h | 16 ++++++++++++++++ net/sched/sch_generic.c | 46 +++++++++++++++++++++++++++++++++++++++++++-- 2 files changed, 60 insertions(+), 2 deletions(-) diff --git a/include/net/sch_generic.h b/include/net/sch_generic.h index f126698..d17ed6f 100644 --- a/include/net/sch_generic.h +++ b/include/net/sch_generic.h @@ -7,6 +7,7 @@ #include <linux/pkt_sched.h> #include <linux/pkt_cls.h> #include <linux/percpu.h> +#include <linux/dynamic_queue_limits.h> #include <net/gen_stats.h> #include <net/rtnetlink.h> @@ -119,6 +120,21 @@ static inline void qdisc_run_end(struct Qdisc *qdisc) qdisc->__state &= ~__QDISC___STATE_RUNNING; } +static inline bool qdisc_may_bulk(const struct Qdisc *qdisc) +{ + return qdisc->flags & TCQ_F_ONETXQUEUE; +} + +static inline int qdisc_avail_bulklimit(const struct netdev_queue *txq) +{ +#ifdef CONFIG_BQL + /* Non-BQL migrated drivers will return 0, too. */ + return dql_avail(&txq->dql); +#else + return 0; +#endif +} + static inline bool qdisc_is_throttled(const struct Qdisc *qdisc) { return test_bit(__QDISC_STATE_THROTTLED, &qdisc->state) ? true : false; diff --git a/net/sched/sch_generic.c b/net/sched/sch_generic.c index 7c8e5d7..c2e87e6 100644 --- a/net/sched/sch_generic.c +++ b/net/sched/sch_generic.c @@ -56,6 +56,41 @@ static inline int dev_requeue_skb(struct sk_buff *skb, struct Qdisc *q) return 0; } +static struct sk_buff *try_bulk_dequeue_skb(struct Qdisc *q, + struct sk_buff *head_skb, + int bytelimit) +{ + struct sk_buff *skb, *tail_skb = head_skb; + + while (bytelimit > 0) { + /* For now, don't bulk dequeue GSO (or GSO segmented) pkts */ + if (tail_skb->next || skb_is_gso(tail_skb)) + break; + + skb = q->dequeue(q); + if (!skb) + break; + + bytelimit -= skb->len; /* covers GSO len */ + skb = validate_xmit_skb(skb, qdisc_dev(q)); + if (!skb) + break; + + /* "skb" can be a skb list after validate call above + * (GSO segmented), but it is okay to append it to + * current tail_skb->next, because next round will exit + * in-case "tail_skb->next" is a skb list. + */ + tail_skb->next = skb; + tail_skb = skb; + } + + return head_skb; +} + +/* Note that dequeue_skb can possibly return a SKB list (via skb->next). + * A requeued skb (via q->gso_skb) can also be a SKB list. + */ static inline struct sk_buff *dequeue_skb(struct Qdisc *q) { struct sk_buff *skb = q->gso_skb; @@ -70,10 +105,17 @@ static inline struct sk_buff *dequeue_skb(struct Qdisc *q) } else skb = NULL; } else { - if (!(q->flags & TCQ_F_ONETXQUEUE) || !netif_xmit_frozen_or_stopped(txq)) { + if (!(q->flags & TCQ_F_ONETXQUEUE) || + !netif_xmit_frozen_or_stopped(txq)) { + int bytelimit = qdisc_avail_bulklimit(txq); + skb = q->dequeue(q); - if (skb) + if (skb) { + bytelimit -= skb->len; skb = validate_xmit_skb(skb, qdisc_dev(q)); + } + if (skb && qdisc_may_bulk(q)) + skb = try_bulk_dequeue_skb(q, skb, bytelimit); } } ^ permalink raw reply related [flat|nested] 42+ messages in thread
* [net-next PATCH V6 2/2] qdisc: dequeue bulking also pickup GSO/TSO packets 2014-10-01 20:35 [net-next PATCH V6 0/2] qdisc: bulk dequeue support Jesper Dangaard Brouer 2014-10-01 20:35 ` [net-next PATCH V6 1/2] qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE Jesper Dangaard Brouer @ 2014-10-01 20:36 ` Jesper Dangaard Brouer 2014-10-02 14:35 ` Eric Dumazet 2014-10-02 14:42 ` [net-next PATCH V6 0/2] qdisc: bulk dequeue support Tom Herbert 2014-10-03 19:38 ` David Miller 3 siblings, 1 reply; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-01 20:36 UTC (permalink / raw) To: Jesper Dangaard Brouer, netdev, David S. Miller, Tom Herbert, Eric Dumazet, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann Cc: Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, toke The TSO and GSO segmented packets already benefit from bulking on their own. The TSO packets have always taken advantage of the only updating the tailptr once for a large packet. The GSO segmented packets have recently taken advantage of bulking xmit_more API, via merge commit 53fda7f7f9e8 ("Merge branch 'xmit_list'"), specifically via commit 7f2e870f2a4 ("net: Move main gso loop out of dev_hard_start_xmit() into helper.") allowing qdisc requeue of remaining list. And via commit ce93718fb7cd ("net: Don't keep around original SKB when we software segment GSO frames."). This patch allow further bulking of TSO/GSO packets together, when dequeueing from the qdisc. Testing: Measuring HoL (Head-of-Line) blocking for TSO and GSO, with netperf-wrapper. Bulking several TSO show no performance regressions (requeues were in the area 32 requeues/sec). Bulking several GSOs does show small regression or very small improvement (requeues were in the area 8000 requeues/sec). Using ixgbe 10Gbit/s with GSO bulking, we can measure some additional latency. Base-case, which is "normal" GSO bulking, sees varying high-prio queue delay between 0.38ms to 0.47ms. Bulking several GSOs together, result in a stable high-prio queue delay of 0.50ms. Using igb at 100Mbit/s with GSO bulking, shows an improvement. Base-case sees varying high-prio queue delay between 2.23ms to 2.35ms diff of 0.12ms corrosponding to 1500 bytes at 100Mbit/s. Bulking several GSOs together, result in a stable high-prio queue delay of 2.23ms. Signed-off-by: Florian Westphal <fw@strlen.de> Signed-off-by: Jesper Dangaard Brouer <brouer@redhat.com> Signed-off-by: Hannes Frederic Sowa <hannes@stressinduktion.org> Signed-off-by: Daniel Borkmann <dborkman@redhat.com> --- net/sched/sch_generic.c | 12 +++--------- 1 files changed, 3 insertions(+), 9 deletions(-) diff --git a/net/sched/sch_generic.c b/net/sched/sch_generic.c index c2e87e6..797ebef 100644 --- a/net/sched/sch_generic.c +++ b/net/sched/sch_generic.c @@ -63,10 +63,6 @@ static struct sk_buff *try_bulk_dequeue_skb(struct Qdisc *q, struct sk_buff *skb, *tail_skb = head_skb; while (bytelimit > 0) { - /* For now, don't bulk dequeue GSO (or GSO segmented) pkts */ - if (tail_skb->next || skb_is_gso(tail_skb)) - break; - skb = q->dequeue(q); if (!skb) break; @@ -76,11 +72,9 @@ static struct sk_buff *try_bulk_dequeue_skb(struct Qdisc *q, if (!skb) break; - /* "skb" can be a skb list after validate call above - * (GSO segmented), but it is okay to append it to - * current tail_skb->next, because next round will exit - * in-case "tail_skb->next" is a skb list. - */ + while (tail_skb->next) /* GSO list goto tail */ + tail_skb = tail_skb->next; + tail_skb->next = skb; tail_skb = skb; } ^ permalink raw reply related [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 2/2] qdisc: dequeue bulking also pickup GSO/TSO packets 2014-10-01 20:36 ` [net-next PATCH V6 2/2] qdisc: dequeue bulking also pickup GSO/TSO packets Jesper Dangaard Brouer @ 2014-10-02 14:35 ` Eric Dumazet 2014-10-02 14:38 ` Daniel Borkmann 0 siblings, 1 reply; 42+ messages in thread From: Eric Dumazet @ 2014-10-02 14:35 UTC (permalink / raw) To: Jesper Dangaard Brouer Cc: netdev, David S. Miller, Tom Herbert, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, toke On Wed, 2014-10-01 at 22:36 +0200, Jesper Dangaard Brouer wrote: > The TSO and GSO segmented packets already benefit from bulking > on their own. > > > Signed-off-by: Florian Westphal <fw@strlen.de> > Signed-off-by: Jesper Dangaard Brouer <brouer@redhat.com> > Signed-off-by: Hannes Frederic Sowa <hannes@stressinduktion.org> > Signed-off-by: Daniel Borkmann <dborkman@redhat.com> > --- > > net/sched/sch_generic.c | 12 +++--------- > 1 files changed, 3 insertions(+), 9 deletions(-) > > diff --git a/net/sched/sch_generic.c b/net/sched/sch_generic.c > index c2e87e6..797ebef 100644 > --- a/net/sched/sch_generic.c > +++ b/net/sched/sch_generic.c > @@ -63,10 +63,6 @@ static struct sk_buff *try_bulk_dequeue_skb(struct Qdisc *q, > struct sk_buff *skb, *tail_skb = head_skb; > > while (bytelimit > 0) { > - /* For now, don't bulk dequeue GSO (or GSO segmented) pkts */ > - if (tail_skb->next || skb_is_gso(tail_skb)) > - break; > - > skb = q->dequeue(q); > if (!skb) > break; > @@ -76,11 +72,9 @@ static struct sk_buff *try_bulk_dequeue_skb(struct Qdisc *q, > if (!skb) > break; > > - /* "skb" can be a skb list after validate call above > - * (GSO segmented), but it is okay to append it to > - * current tail_skb->next, because next round will exit > - * in-case "tail_skb->next" is a skb list. > - */ > + while (tail_skb->next) /* GSO list goto tail */ > + tail_skb = tail_skb->next; > + > tail_skb->next = skb; > tail_skb = skb; Thanks a lot guys. I am testing this patch set today. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 2/2] qdisc: dequeue bulking also pickup GSO/TSO packets 2014-10-02 14:35 ` Eric Dumazet @ 2014-10-02 14:38 ` Daniel Borkmann 0 siblings, 0 replies; 42+ messages in thread From: Daniel Borkmann @ 2014-10-02 14:38 UTC (permalink / raw) To: Eric Dumazet Cc: Jesper Dangaard Brouer, netdev, David S. Miller, Tom Herbert, Hannes Frederic Sowa, Florian Westphal, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, toke On 10/02/2014 04:35 PM, Eric Dumazet wrote: ... > Thanks a lot guys. I am testing this patch set today. That's great, thanks! ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-01 20:35 [net-next PATCH V6 0/2] qdisc: bulk dequeue support Jesper Dangaard Brouer 2014-10-01 20:35 ` [net-next PATCH V6 1/2] qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE Jesper Dangaard Brouer 2014-10-01 20:36 ` [net-next PATCH V6 2/2] qdisc: dequeue bulking also pickup GSO/TSO packets Jesper Dangaard Brouer @ 2014-10-02 14:42 ` Tom Herbert 2014-10-02 15:04 ` Eric Dumazet 2014-10-02 16:52 ` Florian Westphal 2014-10-03 19:38 ` David Miller 3 siblings, 2 replies; 42+ messages in thread From: Tom Herbert @ 2014-10-02 14:42 UTC (permalink / raw) To: Jesper Dangaard Brouer Cc: Linux Netdev List, David S. Miller, Eric Dumazet, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen On Wed, Oct 1, 2014 at 1:35 PM, Jesper Dangaard Brouer <brouer@redhat.com> wrote: > This patchset uses DaveM's recent API changes to dev_hard_start_xmit(), > from the qdisc layer, to implement dequeue bulking. > > Patch01: "qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE" > - Implement basic qdisc dequeue bulking > - This time, 100% relying on BQL limits, no magic safe-guard constants > > Patch02: "qdisc: dequeue bulking also pickup GSO/TSO packets" > - Extend bulking to bulk several GSO/TSO packets > - Seperate patch, as it introduce a small regression, see test section. > > We do have a patch03, which exports a userspace tunable as a BQL > tunable, that can byte-cap or disable the bulking/bursting. But we > could not agree on it internally, thus not sending it now. We > basically strive to avoid adding any new userspace tunable. > Unfortunately we probably still need something. If BQL were disabled (by setting BQL min_limit to infinity) then we'll always dequeue all the packets in the qdisc. Disabling BQL might be legitimate in deployment if say a bug is found in a device that prevents prompt transmit completions for some corner case. > > Testing patch01: > ================ > Demonstrating the performance improvement of qdisc dequeue bulking, is > tricky because the effect only "kicks-in" once the qdisc system have a > backlog. Thus, for a backlog to form, we need either 1) to exceed wirespeed > of the link or 2) exceed the capability of the device driver. > > For practical use-cases, the measureable effect of this will be a > reduction in CPU usage > > 01-TCP_STREAM: > -------------- > Testing effect for TCP involves disabling TSO and GSO, because TCP > already benefit from bulking, via TSO and especially for GSO segmented > packets. This patch view TSO/GSO as a seperate kind of bulking, and > avoid further bulking of these packet types. > > The measured perf diff benefit (at 10Gbit/s) for a single netperf > TCP_STREAM were 9.24% less CPU used on calls to _raw_spin_lock() > (mostly from sch_direct_xmit). > > If my E5-2695v2(ES) CPU is tuned according to: > http://netoptimizer.blogspot.dk/2014/04/basic-tuning-for-network-overload.html > Then it is possible that a single netperf TCP_STREAM, with GSO and TSO > disabled, can utilize all bandwidth on a 10Gbit/s link. This will > then cause a standing backlog queue at the qdisc layer. > > Trying to pressure the system some more CPU util wise, I'm starting > 24x TCP_STREAMs and monitoring the overall CPU utilization. This > confirms bulking saves CPU cycles when it "kicks-in". > > Tool mpstat, while stressing the system with netperf 24x TCP_STREAM, shows: > * Disabled bulking: sys:2.58% soft:8.50% idle:88.78% > * Enabled bulking: sys:2.43% soft:7.66% idle:89.79% > > 02-UDP_STREAM > ------------- > The measured perf diff benefit for UDP_STREAM were 6.41% less CPU used > on calls to _raw_spin_lock(). 24x UDP_STREAM with packet size -m 1472 (to > avoid sending UDP/IP fragments). > > 03-trafgen driver test > ---------------------- > The performance of the 10Gbit/s ixgbe driver is limited due to > updating the HW ring-queue tail-pointer on every packet. As > previously demonstrated with pktgen. > > Using trafgen to send RAW frames from userspace (via AF_PACKET), and > forcing it through qdisc path (with option --qdisc-path and -t0), > sending with 12 CPUs. > > I can demonstrate this driver layer limitation: > * 12.8 Mpps with no qdisc bulking > * 14.8 Mpps with qdisc bulking (full 10G-wirespeed) > > > Testing patch02: > ================ > Testing Bulking several GSO/TSO packets: > > Measuring HoL (Head-of-Line) blocking for TSO and GSO, with > netperf-wrapper. Bulking several TSO show no performance regressions > (requeues were in the area 32 requeues/sec for 10G while transmitting > approx 813Kpps). > > Bulking several GSOs does show small regression or very small > improvement (requeues were in the area 8000 requeues/sec, for 10G > while transmitting approx 813Kpps). > > Using ixgbe 10Gbit/s with GSO bulking, we can measure some additional > latency. Base-case, which is "normal" GSO bulking, sees varying > high-prio queue delay between 0.38ms to 0.47ms. Bulking several GSOs > together, result in a stable high-prio queue delay of 0.50ms. > > Corrosponding to: > (10000*10^6)*((0.50-0.47)/10^3)/8 = 37500 bytes > (10000*10^6)*((0.50-0.38)/10^3)/8 = 150000 bytes > 37500/1500 = 25 pkts > 150000/1500 = 100 pkts > > Using igb at 100Mbit/s with GSO bulking, shows an improvement. > Base-case sees varying high-prio queue delay between 2.23ms to 2.35ms > diff of 0.12ms corrosponding to 1500 bytes at 100Mbit/s. Bulking > several GSOs together, result in a stable high-prio queue delay of > 2.23ms. > > --- > > Jesper Dangaard Brouer (2): > qdisc: dequeue bulking also pickup GSO/TSO packets > qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE > > > include/net/sch_generic.h | 16 ++++++++++++++++ > net/sched/sch_generic.c | 40 ++++++++++++++++++++++++++++++++++++++-- > 2 files changed, 54 insertions(+), 2 deletions(-) > > -- ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-02 14:42 ` [net-next PATCH V6 0/2] qdisc: bulk dequeue support Tom Herbert @ 2014-10-02 15:04 ` Eric Dumazet 2014-10-02 15:24 ` [PATCH net-next] mlx4: add a new xmit_more counter Eric Dumazet 2014-10-02 15:27 ` [net-next PATCH V6 0/2] qdisc: bulk dequeue support Tom Herbert 2014-10-02 16:52 ` Florian Westphal 1 sibling, 2 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-02 15:04 UTC (permalink / raw) To: Tom Herbert, Amir Vadai Cc: Jesper Dangaard Brouer, Linux Netdev List, David S. Miller, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen On Thu, 2014-10-02 at 07:42 -0700, Tom Herbert wrote: > Unfortunately we probably still need something. If BQL were disabled > (by setting BQL min_limit to infinity) then we'll always dequeue all > the packets in the qdisc. Disabling BQL might be legitimate in > deployment if say a bug is found in a device that prevents prompt > transmit completions for some corner case. Unfortunately, there is nothing we can do if a ndo_start_xmit() function is buggy. For example, if a prior packet is queued on NIC TX ring (with xmit_more set to 1) Then following packet given to ndo_start_xmit() returns infamous NETDEV_TX_BUSY, we are screwed. mlx4 driver for example has this bug. Thats why I advocate we have no artifical limit : We are going to catch driver bugs sooner and fix them before xmit_more support is validated, for each driver that claims to support it. Amir, the problem with NETDEV_TX_BUSY in mlx4 need to be fixed. ^ permalink raw reply [flat|nested] 42+ messages in thread
* [PATCH net-next] mlx4: add a new xmit_more counter 2014-10-02 15:04 ` Eric Dumazet @ 2014-10-02 15:24 ` Eric Dumazet 2014-10-05 0:04 ` David Miller 2014-10-02 15:27 ` [net-next PATCH V6 0/2] qdisc: bulk dequeue support Tom Herbert 1 sibling, 1 reply; 42+ messages in thread From: Eric Dumazet @ 2014-10-02 15:24 UTC (permalink / raw) To: Amir Vadai Cc: Jesper Dangaard Brouer, TomHerbert, Linux Netdev List, David S. Miller, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen From: Eric Dumazet <edumazet@google.com> ethtool -S reports a new counter, tracking number of time doorbell was not triggered, because skb->xmit_more was set. $ ethtool -S eth0 | egrep "tx_packet|xmit_more" tx_packets: 2413288400 xmit_more: 666121277 I merged the tso_packet false sharing avoidance in this patch as well. Signed-off-by: Eric Dumazet <edumazet@google.com> --- drivers/net/ethernet/mellanox/mlx4/en_ethtool.c | 1 drivers/net/ethernet/mellanox/mlx4/en_port.c | 17 +++++++++----- drivers/net/ethernet/mellanox/mlx4/en_tx.c | 4 ++- drivers/net/ethernet/mellanox/mlx4/mlx4_en.h | 5 +++- 4 files changed, 19 insertions(+), 8 deletions(-) diff --git a/drivers/net/ethernet/mellanox/mlx4/en_ethtool.c b/drivers/net/ethernet/mellanox/mlx4/en_ethtool.c index 35ff2925110a..42c9f8b09a6e 100644 --- a/drivers/net/ethernet/mellanox/mlx4/en_ethtool.c +++ b/drivers/net/ethernet/mellanox/mlx4/en_ethtool.c @@ -112,6 +112,7 @@ static const char main_strings[][ETH_GSTRING_LEN] = { /* port statistics */ "tso_packets", + "xmit_more", "queue_stopped", "wake_queue", "tx_timeout", "rx_alloc_failed", "rx_csum_good", "rx_csum_none", "tx_chksum_offload", diff --git a/drivers/net/ethernet/mellanox/mlx4/en_port.c b/drivers/net/ethernet/mellanox/mlx4/en_port.c index c2cfb05e7290..0a0261d128b9 100644 --- a/drivers/net/ethernet/mellanox/mlx4/en_port.c +++ b/drivers/net/ethernet/mellanox/mlx4/en_port.c @@ -150,14 +150,19 @@ int mlx4_en_DUMP_ETH_STATS(struct mlx4_en_dev *mdev, u8 port, u8 reset) priv->port_stats.tx_chksum_offload = 0; priv->port_stats.queue_stopped = 0; priv->port_stats.wake_queue = 0; + priv->port_stats.tso_packets = 0; + priv->port_stats.xmit_more = 0; for (i = 0; i < priv->tx_ring_num; i++) { - stats->tx_packets += priv->tx_ring[i]->packets; - stats->tx_bytes += priv->tx_ring[i]->bytes; - priv->port_stats.tx_chksum_offload += priv->tx_ring[i]->tx_csum; - priv->port_stats.queue_stopped += - priv->tx_ring[i]->queue_stopped; - priv->port_stats.wake_queue += priv->tx_ring[i]->wake_queue; + const struct mlx4_en_tx_ring *ring = priv->tx_ring[i]; + + stats->tx_packets += ring->packets; + stats->tx_bytes += ring->bytes; + priv->port_stats.tx_chksum_offload += ring->tx_csum; + priv->port_stats.queue_stopped += ring->queue_stopped; + priv->port_stats.wake_queue += ring->wake_queue; + priv->port_stats.tso_packets += ring->tso_packets; + priv->port_stats.xmit_more += ring->xmit_more; } stats->rx_errors = be64_to_cpu(mlx4_en_stats->PCS) + diff --git a/drivers/net/ethernet/mellanox/mlx4/en_tx.c b/drivers/net/ethernet/mellanox/mlx4/en_tx.c index adedc47e947d..0c501253fdab 100644 --- a/drivers/net/ethernet/mellanox/mlx4/en_tx.c +++ b/drivers/net/ethernet/mellanox/mlx4/en_tx.c @@ -840,7 +840,7 @@ netdev_tx_t mlx4_en_xmit(struct sk_buff *skb, struct net_device *dev) * note that we already verified that it is linear */ memcpy(tx_desc->lso.header, skb->data, lso_header_size); - priv->port_stats.tso_packets++; + ring->tso_packets++; i = ((skb->len - lso_header_size) / skb_shinfo(skb)->gso_size) + !!((skb->len - lso_header_size) % skb_shinfo(skb)->gso_size); tx_info->nr_bytes = skb->len + (i - 1) * lso_header_size; @@ -910,6 +910,8 @@ netdev_tx_t mlx4_en_xmit(struct sk_buff *skb, struct net_device *dev) wmb(); iowrite32be(ring->doorbell_qpn, ring->bf.uar->map + MLX4_SEND_DOORBELL); + } else { + ring->xmit_more++; } } diff --git a/drivers/net/ethernet/mellanox/mlx4/mlx4_en.h b/drivers/net/ethernet/mellanox/mlx4/mlx4_en.h index 6a4fc2394cf2..84c9d5dbfa4f 100644 --- a/drivers/net/ethernet/mellanox/mlx4/mlx4_en.h +++ b/drivers/net/ethernet/mellanox/mlx4/mlx4_en.h @@ -279,6 +279,8 @@ struct mlx4_en_tx_ring { unsigned long tx_csum; unsigned long queue_stopped; unsigned long wake_queue; + unsigned long tso_packets; + unsigned long xmit_more; struct mlx4_bf bf; bool bf_enabled; bool bf_alloced; @@ -426,6 +428,7 @@ struct mlx4_en_pkt_stats { struct mlx4_en_port_stats { unsigned long tso_packets; + unsigned long xmit_more; unsigned long queue_stopped; unsigned long wake_queue; unsigned long tx_timeout; @@ -433,7 +436,7 @@ struct mlx4_en_port_stats { unsigned long rx_chksum_good; unsigned long rx_chksum_none; unsigned long tx_chksum_offload; -#define NUM_PORT_STATS 8 +#define NUM_PORT_STATS 9 }; struct mlx4_en_perf_stats { ^ permalink raw reply related [flat|nested] 42+ messages in thread
* Re: [PATCH net-next] mlx4: add a new xmit_more counter 2014-10-02 15:24 ` [PATCH net-next] mlx4: add a new xmit_more counter Eric Dumazet @ 2014-10-05 0:04 ` David Miller 0 siblings, 0 replies; 42+ messages in thread From: David Miller @ 2014-10-05 0:04 UTC (permalink / raw) To: eric.dumazet Cc: amirv, brouer, therbert, netdev, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke From: Eric Dumazet <eric.dumazet@gmail.com> Date: Thu, 02 Oct 2014 08:24:21 -0700 > From: Eric Dumazet <edumazet@google.com> > > ethtool -S reports a new counter, tracking number of time doorbell > was not triggered, because skb->xmit_more was set. > > $ ethtool -S eth0 | egrep "tx_packet|xmit_more" > tx_packets: 2413288400 > xmit_more: 666121277 > > I merged the tso_packet false sharing avoidance in this patch as well. > > Signed-off-by: Eric Dumazet <edumazet@google.com> Applied, thanks Eric. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-02 15:04 ` Eric Dumazet 2014-10-02 15:24 ` [PATCH net-next] mlx4: add a new xmit_more counter Eric Dumazet @ 2014-10-02 15:27 ` Tom Herbert 1 sibling, 0 replies; 42+ messages in thread From: Tom Herbert @ 2014-10-02 15:27 UTC (permalink / raw) To: Eric Dumazet Cc: Amir Vadai, Jesper Dangaard Brouer, Linux Netdev List, David S. Miller, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen On Thu, Oct 2, 2014 at 8:04 AM, Eric Dumazet <eric.dumazet@gmail.com> wrote: > On Thu, 2014-10-02 at 07:42 -0700, Tom Herbert wrote: > > >> Unfortunately we probably still need something. If BQL were disabled >> (by setting BQL min_limit to infinity) then we'll always dequeue all >> the packets in the qdisc. Disabling BQL might be legitimate in >> deployment if say a bug is found in a device that prevents prompt >> transmit completions for some corner case. > > > Unfortunately, there is nothing we can do if a ndo_start_xmit() function > is buggy. > I was referring more to device bugs not driver bugs. But even so, if a user hits a problem like this in the system, disabling something like BQL would probably be a better recourse than bringing their network down. Minimally we should at least test with BQL disabled, it might not be so horrible. I suppose in the worse case we're at least limited by the qdisc limit. > For example, if a prior packet is queued on NIC TX ring (with xmit_more > set to 1) > > Then following packet given to ndo_start_xmit() returns infamous > NETDEV_TX_BUSY, we are screwed. > > mlx4 driver for example has this bug. > > > Thats why I advocate we have no artifical limit : We are going to catch > driver bugs sooner and fix them before xmit_more support is validated, > for each driver that claims to support it. > > Amir, the problem with NETDEV_TX_BUSY in mlx4 need to be fixed. > > ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-02 14:42 ` [net-next PATCH V6 0/2] qdisc: bulk dequeue support Tom Herbert 2014-10-02 15:04 ` Eric Dumazet @ 2014-10-02 16:52 ` Florian Westphal 2014-10-02 17:32 ` Eric Dumazet 2014-10-02 17:35 ` Tom Herbert 1 sibling, 2 replies; 42+ messages in thread From: Florian Westphal @ 2014-10-02 16:52 UTC (permalink / raw) To: Tom Herbert Cc: Jesper Dangaard Brouer, Linux Netdev List, David S. Miller, Eric Dumazet, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen Tom Herbert <therbert@google.com> wrote: > On Wed, Oct 1, 2014 at 1:35 PM, Jesper Dangaard Brouer > <brouer@redhat.com> wrote: > > This patchset uses DaveM's recent API changes to dev_hard_start_xmit(), > > from the qdisc layer, to implement dequeue bulking. > > > > Patch01: "qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE" > > - Implement basic qdisc dequeue bulking > > - This time, 100% relying on BQL limits, no magic safe-guard constants > > > > Patch02: "qdisc: dequeue bulking also pickup GSO/TSO packets" > > - Extend bulking to bulk several GSO/TSO packets > > - Seperate patch, as it introduce a small regression, see test section. > > > > We do have a patch03, which exports a userspace tunable as a BQL > > tunable, that can byte-cap or disable the bulking/bursting. But we > > could not agree on it internally, thus not sending it now. We > > basically strive to avoid adding any new userspace tunable. > > > Unfortunately we probably still need something. If BQL were disabled > (by setting BQL min_limit to infinity) then we'll always dequeue all > the packets in the qdisc. Disabling BQL might be legitimate in > deployment if say a bug is found in a device that prevents prompt > transmit completions for some corner case. Hmm. Thats confusing. So you are saying to disable bql one should do cat limit_max > limit_min ? But thats not the same as having a bql-unaware driver. Seems to get same behavior as non-bql aware driver (where dql_avail always returns 0 since num_queued and adj_limit remain at 0) is to set echo 0 > limit_max ... which makes dql_avail() return 0, which then also turns off bulk dequeue. Confused, Florian ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-02 16:52 ` Florian Westphal @ 2014-10-02 17:32 ` Eric Dumazet 2014-10-02 17:35 ` Tom Herbert 1 sibling, 0 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-02 17:32 UTC (permalink / raw) To: Florian Westphal Cc: Tom Herbert, Jesper Dangaard Brouer, Linux Netdev List, David S. Miller, Hannes Frederic Sowa, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen On Thu, 2014-10-02 at 18:52 +0200, Florian Westphal wrote: > Tom Herbert <therbert@google.com> wrote: > > On Wed, Oct 1, 2014 at 1:35 PM, Jesper Dangaard Brouer > > <brouer@redhat.com> wrote: > > > This patchset uses DaveM's recent API changes to dev_hard_start_xmit(), > > > from the qdisc layer, to implement dequeue bulking. > > > > > > Patch01: "qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE" > > > - Implement basic qdisc dequeue bulking > > > - This time, 100% relying on BQL limits, no magic safe-guard constants > > > > > > Patch02: "qdisc: dequeue bulking also pickup GSO/TSO packets" > > > - Extend bulking to bulk several GSO/TSO packets > > > - Seperate patch, as it introduce a small regression, see test section. > > > > > > We do have a patch03, which exports a userspace tunable as a BQL > > > tunable, that can byte-cap or disable the bulking/bursting. But we > > > could not agree on it internally, thus not sending it now. We > > > basically strive to avoid adding any new userspace tunable. > > > > > Unfortunately we probably still need something. If BQL were disabled > > (by setting BQL min_limit to infinity) then we'll always dequeue all > > the packets in the qdisc. Disabling BQL might be legitimate in > > deployment if say a bug is found in a device that prevents prompt > > transmit completions for some corner case. > > Hmm. Thats confusing. > > So you are saying to disable bql one should do > > cat limit_max > limit_min ? > > But thats not the same as having a bql-unaware driver. > > Seems to get same behavior as non-bql aware driver (where > dql_avail always returns 0 since num_queued and adj_limit remain at 0) > is to set > > echo 0 > limit_max > > ... which makes dql_avail() return 0, which then also turns off bulk > dequeue. So Tom point is that we might have a BQL enabled driver, but for some reason admin wants to set limit_min to 10000000. Then the admin wants also to restrict the xmit_more batches to 13 packets. Then a debugging facility might be nice to have. What about adding 2 attributes : /sys/class/net/ethX/queues/tx-Y/xmit_more_inflight (live number of deferred frames on this TX queue, waiting a doorbell to kick the NIC) /sys/class/net/ethX/queues/tx-Y/xmit_more_limit (default to 8) ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-02 16:52 ` Florian Westphal 2014-10-02 17:32 ` Eric Dumazet @ 2014-10-02 17:35 ` Tom Herbert 1 sibling, 0 replies; 42+ messages in thread From: Tom Herbert @ 2014-10-02 17:35 UTC (permalink / raw) To: Florian Westphal Cc: Jesper Dangaard Brouer, Linux Netdev List, David S. Miller, Eric Dumazet, Hannes Frederic Sowa, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen On Thu, Oct 2, 2014 at 9:52 AM, Florian Westphal <fw@strlen.de> wrote: > Tom Herbert <therbert@google.com> wrote: >> On Wed, Oct 1, 2014 at 1:35 PM, Jesper Dangaard Brouer >> <brouer@redhat.com> wrote: >> > This patchset uses DaveM's recent API changes to dev_hard_start_xmit(), >> > from the qdisc layer, to implement dequeue bulking. >> > >> > Patch01: "qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE" >> > - Implement basic qdisc dequeue bulking >> > - This time, 100% relying on BQL limits, no magic safe-guard constants >> > >> > Patch02: "qdisc: dequeue bulking also pickup GSO/TSO packets" >> > - Extend bulking to bulk several GSO/TSO packets >> > - Seperate patch, as it introduce a small regression, see test section. >> > >> > We do have a patch03, which exports a userspace tunable as a BQL >> > tunable, that can byte-cap or disable the bulking/bursting. But we >> > could not agree on it internally, thus not sending it now. We >> > basically strive to avoid adding any new userspace tunable. >> > >> Unfortunately we probably still need something. If BQL were disabled >> (by setting BQL min_limit to infinity) then we'll always dequeue all >> the packets in the qdisc. Disabling BQL might be legitimate in >> deployment if say a bug is found in a device that prevents prompt >> transmit completions for some corner case. > > Hmm. Thats confusing. > > So you are saying to disable bql one should do > > cat limit_max > limit_min ? > echo max > limit_min echo max > limit_max "Disables" BQL by forcing the limit to be really big. > But thats not the same as having a bql-unaware driver. > Yes, that's true. This does not disable the accounting and limit check which is where a bug would manifest itself. > Seems to get same behavior as non-bql aware driver (where > dql_avail always returns 0 since num_queued and adj_limit remain at 0) > is to set > That doesn't work for BQL, if dql_avail returning zero means we can queue only one packet. > echo 0 > limit_max > > ... which makes dql_avail() return 0, which then also turns off bulk > dequeue. > > Confused, > Florian I withdraw my comment. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-01 20:35 [net-next PATCH V6 0/2] qdisc: bulk dequeue support Jesper Dangaard Brouer ` (2 preceding siblings ...) 2014-10-02 14:42 ` [net-next PATCH V6 0/2] qdisc: bulk dequeue support Tom Herbert @ 2014-10-03 19:38 ` David Miller 2014-10-03 20:57 ` Eric Dumazet 3 siblings, 1 reply; 42+ messages in thread From: David Miller @ 2014-10-03 19:38 UTC (permalink / raw) To: brouer Cc: netdev, therbert, eric.dumazet, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke From: Jesper Dangaard Brouer <brouer@redhat.com> Date: Wed, 01 Oct 2014 22:35:31 +0200 > This patchset uses DaveM's recent API changes to dev_hard_start_xmit(), > from the qdisc layer, to implement dequeue bulking. Series applied, thanks for all of your hard work! ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-03 19:38 ` David Miller @ 2014-10-03 20:57 ` Eric Dumazet 2014-10-03 21:56 ` David Miller 0 siblings, 1 reply; 42+ messages in thread From: Eric Dumazet @ 2014-10-03 20:57 UTC (permalink / raw) To: David Miller Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Fri, 2014-10-03 at 12:38 -0700, David Miller wrote: > From: Jesper Dangaard Brouer <brouer@redhat.com> > Date: Wed, 01 Oct 2014 22:35:31 +0200 > > > This patchset uses DaveM's recent API changes to dev_hard_start_xmit(), > > from the qdisc layer, to implement dequeue bulking. > > Series applied, thanks for all of your hard work! I thinks its possible to make all validate_xmit_skb() calls outside of qdisc lock. GSO segmentation of TX checksuming should not prevent other cpus from queueing other skbs in the qdisc. I will spend some time on this. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-03 20:57 ` Eric Dumazet @ 2014-10-03 21:56 ` David Miller 2014-10-03 21:57 ` Eric Dumazet 0 siblings, 1 reply; 42+ messages in thread From: David Miller @ 2014-10-03 21:56 UTC (permalink / raw) To: eric.dumazet Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke From: Eric Dumazet <eric.dumazet@gmail.com> Date: Fri, 03 Oct 2014 13:57:49 -0700 > On Fri, 2014-10-03 at 12:38 -0700, David Miller wrote: >> From: Jesper Dangaard Brouer <brouer@redhat.com> >> Date: Wed, 01 Oct 2014 22:35:31 +0200 >> >> > This patchset uses DaveM's recent API changes to dev_hard_start_xmit(), >> > from the qdisc layer, to implement dequeue bulking. >> >> Series applied, thanks for all of your hard work! > > > I thinks its possible to make all validate_xmit_skb() calls outside of > qdisc lock. I completely agree, and I sort of intended this to happen when I split all the code into that new function. GSO segmentation of TX checksuming should not prevent other > cpus from queueing other skbs in the qdisc. > > I will spend some time on this. Thanks! ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-03 21:56 ` David Miller @ 2014-10-03 21:57 ` Eric Dumazet 2014-10-03 22:15 ` Eric Dumazet 2014-10-03 22:31 ` [PATCH net-next] qdisc: validate skb without holding lock Eric Dumazet 0 siblings, 2 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-03 21:57 UTC (permalink / raw) To: David Miller Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Fri, 2014-10-03 at 14:56 -0700, David Miller wrote: > I completely agree, and I sort of intended this to happen when > I split all the code into that new function. > > GSO segmentation of TX checksuming should not prevent other > > cpus from queueing other skbs in the qdisc. > > > > I will spend some time on this. > > Thanks! I just did my first reboot, will make sure everything is working well before sending the patch ;) ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-03 21:57 ` Eric Dumazet @ 2014-10-03 22:15 ` Eric Dumazet 2014-10-03 22:19 ` Tom Herbert 2014-10-03 22:30 ` David Miller 2014-10-03 22:31 ` [PATCH net-next] qdisc: validate skb without holding lock Eric Dumazet 1 sibling, 2 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-03 22:15 UTC (permalink / raw) To: David Miller Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Fri, 2014-10-03 at 14:57 -0700, Eric Dumazet wrote: > On Fri, 2014-10-03 at 14:56 -0700, David Miller wrote: > > > I completely agree, and I sort of intended this to happen when > > I split all the code into that new function. > > > > GSO segmentation of TX checksuming should not prevent other > > > cpus from queueing other skbs in the qdisc. > > > > > > I will spend some time on this. > > > > Thanks! > > I just did my first reboot, will make sure everything is working well > before sending the patch ;) This is awesome... 40Gb rate, with TSO=on or TSO=off, it does not matter anymore. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-03 22:15 ` Eric Dumazet @ 2014-10-03 22:19 ` Tom Herbert 2014-10-03 22:56 ` Eric Dumazet 2014-10-03 22:30 ` David Miller 1 sibling, 1 reply; 42+ messages in thread From: Tom Herbert @ 2014-10-03 22:19 UTC (permalink / raw) To: Eric Dumazet Cc: David Miller, Jesper Dangaard Brouer, Linux Netdev List, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen On Fri, Oct 3, 2014 at 3:15 PM, Eric Dumazet <eric.dumazet@gmail.com> wrote: > On Fri, 2014-10-03 at 14:57 -0700, Eric Dumazet wrote: >> On Fri, 2014-10-03 at 14:56 -0700, David Miller wrote: >> >> > I completely agree, and I sort of intended this to happen when >> > I split all the code into that new function. >> > >> > GSO segmentation of TX checksuming should not prevent other >> > > cpus from queueing other skbs in the qdisc. >> > > >> > > I will spend some time on this. >> > >> > Thanks! >> >> I just did my first reboot, will make sure everything is working well >> before sending the patch ;) > > This is awesome... > > 40Gb rate, with TSO=on or TSO=off, it does not matter anymore. > This is with or without GSO? > > ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-03 22:19 ` Tom Herbert @ 2014-10-03 22:56 ` Eric Dumazet 0 siblings, 0 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-03 22:56 UTC (permalink / raw) To: Tom Herbert Cc: David Miller, Jesper Dangaard Brouer, Linux Netdev List, Hannes Frederic Sowa, Florian Westphal, Daniel Borkmann, Jamal Hadi Salim, Alexander Duyck, John Fastabend, Dave Taht, Toke Høiland-Jørgensen On Fri, 2014-10-03 at 15:19 -0700, Tom Herbert wrote: > On Fri, Oct 3, 2014 at 3:15 PM, Eric Dumazet <eric.dumazet@gmail.com> wrote: > > On Fri, 2014-10-03 at 14:57 -0700, Eric Dumazet wrote: > >> On Fri, 2014-10-03 at 14:56 -0700, David Miller wrote: > >> > >> > I completely agree, and I sort of intended this to happen when > >> > I split all the code into that new function. > >> > > >> > GSO segmentation of TX checksuming should not prevent other > >> > > cpus from queueing other skbs in the qdisc. > >> > > > >> > > I will spend some time on this. > >> > > >> > Thanks! > >> > >> I just did my first reboot, will make sure everything is working well > >> before sending the patch ;) > > > > This is awesome... > > > > 40Gb rate, with TSO=on or TSO=off, it does not matter anymore. > > > This is with or without GSO? GSO=on But with GSO off, I also get line rate, only spending more cpu. 25.05% [kernel] [k] copy_user_enhanced_fast_string 3.17% [kernel] [k] _raw_spin_lock 2.65% [kernel] [k] tcp_sendmsg 2.43% [kernel] [k] tcp_ack 2.08% [kernel] [k] __netif_receive_skb_core 1.88% [kernel] [k] menu_select 1.69% [kernel] [k] put_compound_page 1.50% [kernel] [k] flush_smp_call_function_queue 1.48% [kernel] [k] int_sqrt 1.43% [kernel] [k] call_function_single_interrupt 1.42% [kernel] [k] cpuidle_enter_state 1.21% perf [.] 0x00000000000353f2 1.10% [kernel] [k] tcp_init_tso_segs 1.05% [kernel] [k] memcpy 1.01% [kernel] [k] __skb_clone 0.91% [kernel] [k] irq_entries_start 0.84% [kernel] [k] get_nohz_timer_target 0.84% [kernel] [k] put_page 0.82% [kernel] [k] tcp_write_xmit 0.82% [kernel] [k] get_page_from_freelist 0.82% [kernel] [k] llist_reverse_order 0.80% [kernel] [k] native_sched_clock 0.79% [kernel] [k] cpu_startup_entry 0.78% [kernel] [k] kmem_cache_free The killer combination is GSO=off and TX=off, of course. 9.90% [kernel] [k] csum_partial_copy_generic 7.64% [kernel] [k] _raw_spin_lock 6.10% [kernel] [k] tcp_ack 5.11% [kernel] [k] __skb_clone 3.90% [kernel] [k] __alloc_skb 3.78% [kernel] [k] skb_release_data 3.45% [kernel] [k] csum_partial 3.17% [kernel] [k] __kfree_skb 3.07% [kernel] [k] skb_clone 2.44% [kernel] [k] __kmalloc_node_track_caller 2.26% [kernel] [k] tcp_init_tso_segs 2.25% [kernel] [k] kfree 1.98% [kernel] [k] pfifo_fast_dequeue 1.61% [kernel] [k] tcp_set_skb_tso_segs 1.45% [kernel] [k] kmem_cache_free ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [net-next PATCH V6 0/2] qdisc: bulk dequeue support 2014-10-03 22:15 ` Eric Dumazet 2014-10-03 22:19 ` Tom Herbert @ 2014-10-03 22:30 ` David Miller 1 sibling, 0 replies; 42+ messages in thread From: David Miller @ 2014-10-03 22:30 UTC (permalink / raw) To: eric.dumazet Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke From: Eric Dumazet <eric.dumazet@gmail.com> Date: Fri, 03 Oct 2014 15:15:35 -0700 > On Fri, 2014-10-03 at 14:57 -0700, Eric Dumazet wrote: >> On Fri, 2014-10-03 at 14:56 -0700, David Miller wrote: >> >> > I completely agree, and I sort of intended this to happen when >> > I split all the code into that new function. >> > >> > GSO segmentation of TX checksuming should not prevent other >> > > cpus from queueing other skbs in the qdisc. >> > > >> > > I will spend some time on this. >> > >> > Thanks! >> >> I just did my first reboot, will make sure everything is working well >> before sending the patch ;) > > This is awesome... > > 40Gb rate, with TSO=on or TSO=off, it does not matter anymore. Kick ass! ^ permalink raw reply [flat|nested] 42+ messages in thread
* [PATCH net-next] qdisc: validate skb without holding lock 2014-10-03 21:57 ` Eric Dumazet 2014-10-03 22:15 ` Eric Dumazet @ 2014-10-03 22:31 ` Eric Dumazet 2014-10-03 22:36 ` David Miller 2014-10-04 3:59 ` [PATCH net-next] net: skb_segment() provides list head and tail Eric Dumazet 1 sibling, 2 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-03 22:31 UTC (permalink / raw) To: David Miller Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke From: Eric Dumazet <edumazet@google.com> Validation of skb can be pretty expensive : GSO segmentation and/or checksum computations. We can do this without holding qdisc lock, so that other cpus can queue additional packets. Trick is that requeued packets were already validated, so we carry a boolean so that sch_direct_xmit() can validate a fresh skb list, or directly use an old one. Tested on 40Gb NIC (8 TX queues) and 200 concurrent flows, 48 threads host. Turning TSO on or off had no effect on throughput, only few more cpu cycles. Lock contention on qdisc lock disappeared. Same if disabling TX checksum offload. Signed-off-by: Eric Dumazet <edumazet@google.com> --- include/linux/netdevice.h | 2 - include/net/pkt_sched.h | 2 - net/core/dev.c | 29 +++++++++++++++-- net/sched/sch_generic.c | 61 ++++++++++++++++-------------------- 4 files changed, 56 insertions(+), 38 deletions(-) diff --git a/include/linux/netdevice.h b/include/linux/netdevice.h index 9b7fbacb6296..910fb17ad148 100644 --- a/include/linux/netdevice.h +++ b/include/linux/netdevice.h @@ -2821,7 +2821,7 @@ int dev_set_mac_address(struct net_device *, struct sockaddr *); int dev_change_carrier(struct net_device *, bool new_carrier); int dev_get_phys_port_id(struct net_device *dev, struct netdev_phys_port_id *ppid); -struct sk_buff *validate_xmit_skb(struct sk_buff *skb, struct net_device *dev); +struct sk_buff *validate_xmit_skb_list(struct sk_buff *skb, struct net_device *dev); struct sk_buff *dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, struct netdev_queue *txq, int *ret); int __dev_forward_skb(struct net_device *dev, struct sk_buff *skb); diff --git a/include/net/pkt_sched.h b/include/net/pkt_sched.h index 8bbe626e9ece..e4b3c828c1c2 100644 --- a/include/net/pkt_sched.h +++ b/include/net/pkt_sched.h @@ -99,7 +99,7 @@ void qdisc_put_stab(struct qdisc_size_table *tab); void qdisc_warn_nonwc(const char *txt, struct Qdisc *qdisc); int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq, - spinlock_t *root_lock); + spinlock_t *root_lock, bool validate); void __qdisc_run(struct Qdisc *q); diff --git a/net/core/dev.c b/net/core/dev.c index e55c546717d4..1a90530f83ff 100644 --- a/net/core/dev.c +++ b/net/core/dev.c @@ -2655,7 +2655,7 @@ struct sk_buff *validate_xmit_vlan(struct sk_buff *skb, netdev_features_t featur return skb; } -struct sk_buff *validate_xmit_skb(struct sk_buff *skb, struct net_device *dev) +static struct sk_buff *validate_xmit_skb(struct sk_buff *skb, struct net_device *dev) { netdev_features_t features; @@ -2720,6 +2720,30 @@ out_null: return NULL; } +struct sk_buff *validate_xmit_skb_list(struct sk_buff *skb, struct net_device *dev) +{ + struct sk_buff *next, *head = NULL, *tail; + + while (skb) { + next = skb->next; + skb->next = NULL; + skb = validate_xmit_skb(skb, dev); + if (skb) { + struct sk_buff *end = skb; + + while (end->next) + end = end->next; + if (!head) + head = skb; + else + tail->next = skb; + tail = end; + } + skb = next; + } + return head; +} + static void qdisc_pkt_len_init(struct sk_buff *skb) { const struct skb_shared_info *shinfo = skb_shinfo(skb); @@ -2786,8 +2810,7 @@ static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q, qdisc_bstats_update(q, skb); - skb = validate_xmit_skb(skb, dev); - if (skb && sch_direct_xmit(skb, q, dev, txq, root_lock)) { + if (sch_direct_xmit(skb, q, dev, txq, root_lock, true)) { if (unlikely(contended)) { spin_unlock(&q->busylock); contended = false; diff --git a/net/sched/sch_generic.c b/net/sched/sch_generic.c index 797ebef73642..2b349a4de3c8 100644 --- a/net/sched/sch_generic.c +++ b/net/sched/sch_generic.c @@ -56,40 +56,34 @@ static inline int dev_requeue_skb(struct sk_buff *skb, struct Qdisc *q) return 0; } -static struct sk_buff *try_bulk_dequeue_skb(struct Qdisc *q, - struct sk_buff *head_skb, - int bytelimit) +static void try_bulk_dequeue_skb(struct Qdisc *q, + struct sk_buff *skb, + const struct netdev_queue *txq) { - struct sk_buff *skb, *tail_skb = head_skb; + int bytelimit = qdisc_avail_bulklimit(txq) - skb->len; while (bytelimit > 0) { - skb = q->dequeue(q); - if (!skb) - break; + struct sk_buff *nskb = q->dequeue(q); - bytelimit -= skb->len; /* covers GSO len */ - skb = validate_xmit_skb(skb, qdisc_dev(q)); - if (!skb) + if (!nskb) break; - while (tail_skb->next) /* GSO list goto tail */ - tail_skb = tail_skb->next; - - tail_skb->next = skb; - tail_skb = skb; + bytelimit -= nskb->len; /* covers GSO len */ + skb->next = nskb; + skb = nskb; } - - return head_skb; + skb->next = NULL; } /* Note that dequeue_skb can possibly return a SKB list (via skb->next). * A requeued skb (via q->gso_skb) can also be a SKB list. */ -static inline struct sk_buff *dequeue_skb(struct Qdisc *q) +static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate) { struct sk_buff *skb = q->gso_skb; const struct netdev_queue *txq = q->dev_queue; + *validate = true; if (unlikely(skb)) { /* check the reason of requeuing without tx lock first */ txq = skb_get_tx_queue(txq->dev, skb); @@ -98,21 +92,16 @@ static inline struct sk_buff *dequeue_skb(struct Qdisc *q) q->q.qlen--; } else skb = NULL; + /* skb in gso_skb were already validated */ + *validate = false; } else { if (!(q->flags & TCQ_F_ONETXQUEUE) || !netif_xmit_frozen_or_stopped(txq)) { - int bytelimit = qdisc_avail_bulklimit(txq); - skb = q->dequeue(q); - if (skb) { - bytelimit -= skb->len; - skb = validate_xmit_skb(skb, qdisc_dev(q)); - } if (skb && qdisc_may_bulk(q)) - skb = try_bulk_dequeue_skb(q, skb, bytelimit); + try_bulk_dequeue_skb(q, skb, txq); } } - return skb; } @@ -156,19 +145,24 @@ static inline int handle_dev_cpu_collision(struct sk_buff *skb, */ int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq, - spinlock_t *root_lock) + spinlock_t *root_lock, bool validate) { int ret = NETDEV_TX_BUSY; /* And release qdisc */ spin_unlock(root_lock); - HARD_TX_LOCK(dev, txq, smp_processor_id()); - if (!netif_xmit_frozen_or_stopped(txq)) - skb = dev_hard_start_xmit(skb, dev, txq, &ret); + /* Note that we validate skb (GSO, checksum, ...) outside of locks */ + if (validate) + skb = validate_xmit_skb_list(skb, dev); - HARD_TX_UNLOCK(dev, txq); + if (skb) { + HARD_TX_LOCK(dev, txq, smp_processor_id()); + if (!netif_xmit_frozen_or_stopped(txq)) + skb = dev_hard_start_xmit(skb, dev, txq, &ret); + HARD_TX_UNLOCK(dev, txq); + } spin_lock(root_lock); if (dev_xmit_complete(ret)) { @@ -217,9 +211,10 @@ static inline int qdisc_restart(struct Qdisc *q) struct net_device *dev; spinlock_t *root_lock; struct sk_buff *skb; + bool validate; /* Dequeue packet */ - skb = dequeue_skb(q); + skb = dequeue_skb(q, &validate); if (unlikely(!skb)) return 0; @@ -229,7 +224,7 @@ static inline int qdisc_restart(struct Qdisc *q) dev = qdisc_dev(q); txq = skb_get_tx_queue(dev, skb); - return sch_direct_xmit(skb, q, dev, txq, root_lock); + return sch_direct_xmit(skb, q, dev, txq, root_lock, validate); } void __qdisc_run(struct Qdisc *q) ^ permalink raw reply related [flat|nested] 42+ messages in thread
* Re: [PATCH net-next] qdisc: validate skb without holding lock 2014-10-03 22:31 ` [PATCH net-next] qdisc: validate skb without holding lock Eric Dumazet @ 2014-10-03 22:36 ` David Miller 2014-10-03 23:30 ` Eric Dumazet 2014-10-06 14:12 ` [PATCH net-next] qdisc: validate skb without holding lock Jesper Dangaard Brouer 2014-10-04 3:59 ` [PATCH net-next] net: skb_segment() provides list head and tail Eric Dumazet 1 sibling, 2 replies; 42+ messages in thread From: David Miller @ 2014-10-03 22:36 UTC (permalink / raw) To: eric.dumazet Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke From: Eric Dumazet <eric.dumazet@gmail.com> Date: Fri, 03 Oct 2014 15:31:07 -0700 > From: Eric Dumazet <edumazet@google.com> > > Validation of skb can be pretty expensive : > > GSO segmentation and/or checksum computations. > > We can do this without holding qdisc lock, so that other cpus > can queue additional packets. > > Trick is that requeued packets were already validated, so we carry > a boolean so that sch_direct_xmit() can validate a fresh skb list, > or directly use an old one. > > Tested on 40Gb NIC (8 TX queues) and 200 concurrent flows, 48 threads > host. > > Turning TSO on or off had no effect on throughput, only few more cpu > cycles. Lock contention on qdisc lock disappeared. > > Same if disabling TX checksum offload. > > Signed-off-by: Eric Dumazet <edumazet@google.com> Applied, thanks Eric! ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [PATCH net-next] qdisc: validate skb without holding lock 2014-10-03 22:36 ` David Miller @ 2014-10-03 23:30 ` Eric Dumazet 2014-10-07 7:34 ` Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) Jesper Dangaard Brouer 2014-10-06 14:12 ` [PATCH net-next] qdisc: validate skb without holding lock Jesper Dangaard Brouer 1 sibling, 1 reply; 42+ messages in thread From: Eric Dumazet @ 2014-10-03 23:30 UTC (permalink / raw) To: David Miller Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Fri, 2014-10-03 at 15:36 -0700, David Miller wrote: > Applied, thanks Eric! Thanks David Another problem we need to address is the quota in __qdisc_run() is no longer meaningfull, if each qdisc_restart() can pump many packets. An idea would be to use the bstats (or cpu_qstats if applicable) ^ permalink raw reply [flat|nested] 42+ messages in thread
* Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) 2014-10-03 23:30 ` Eric Dumazet @ 2014-10-07 7:34 ` Jesper Dangaard Brouer 2014-10-07 12:47 ` Eric Dumazet 0 siblings, 1 reply; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-07 7:34 UTC (permalink / raw) To: Eric Dumazet Cc: David Miller, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke, brouer On Fri, 03 Oct 2014 16:30:44 -0700 Eric Dumazet <eric.dumazet@gmail.com> wrote: > Another problem we need to address is the quota in __qdisc_run() > is no longer meaningfull, if each qdisc_restart() can pump many packets. I fully agree. My earlier "magic" packet limit was covering/pampering over this issue. > An idea would be to use the bstats (or cpu_qstats if applicable) Please elaborate some more, as I don't completely follow (feel free to show with a patch ;-)). -- Best regards, Jesper Dangaard Brouer MSc.CS, Sr. Network Kernel Developer at Red Hat Author of http://www.iptv-analyzer.org LinkedIn: http://www.linkedin.com/in/brouer ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) 2014-10-07 7:34 ` Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) Jesper Dangaard Brouer @ 2014-10-07 12:47 ` Eric Dumazet 2014-10-07 13:30 ` Jesper Dangaard Brouer 2014-10-08 17:38 ` Quota in __qdisc_run() John Fastabend 0 siblings, 2 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-07 12:47 UTC (permalink / raw) To: Jesper Dangaard Brouer Cc: David Miller, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Tue, 2014-10-07 at 09:34 +0200, Jesper Dangaard Brouer wrote: > On Fri, 03 Oct 2014 16:30:44 -0700 Eric Dumazet <eric.dumazet@gmail.com> wrote: > > > Another problem we need to address is the quota in __qdisc_run() > > is no longer meaningfull, if each qdisc_restart() can pump many packets. > > I fully agree. My earlier "magic" packet limit was covering/pampering > over this issue. Although quota was multiplied by 7 or 8 in worst case ? > > > An idea would be to use the bstats (or cpu_qstats if applicable) > > Please elaborate some more, as I don't completely follow (feel free to > show with a patch ;-)). > I was hoping John could finish the percpu stats before I do that. Problem with q->bstats.packets is that TSO packets with 45 MSS add 45 to this counter. Using a time quota would be better, but : jiffies is too big, and local_clock() might be too expensive. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) 2014-10-07 12:47 ` Eric Dumazet @ 2014-10-07 13:30 ` Jesper Dangaard Brouer 2014-10-07 14:43 ` Hannes Frederic Sowa 2014-10-08 17:38 ` Quota in __qdisc_run() John Fastabend 1 sibling, 1 reply; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-07 13:30 UTC (permalink / raw) To: Eric Dumazet Cc: David Miller, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke, brouer On Tue, 07 Oct 2014 05:47:18 -0700 Eric Dumazet <eric.dumazet@gmail.com> wrote: > On Tue, 2014-10-07 at 09:34 +0200, Jesper Dangaard Brouer wrote: > > On Fri, 03 Oct 2014 16:30:44 -0700 Eric Dumazet <eric.dumazet@gmail.com> wrote: > > > > > Another problem we need to address is the quota in __qdisc_run() > > > is no longer meaningfull, if each qdisc_restart() can pump many packets. > > > > I fully agree. My earlier "magic" packet limit was covering/pampering > > over this issue. > > Although quota was multiplied by 7 or 8 in worst case ? Yes, exactly not a very elegant solution ;-) > > > An idea would be to use the bstats (or cpu_qstats if applicable) > > > > Please elaborate some more, as I don't completely follow (feel free to > > show with a patch ;-)). > > > > I was hoping John could finish the percpu stats before I do that. > > Problem with q->bstats.packets is that TSO packets with 45 MSS add 45 to > this counter. > > Using a time quota would be better, but : jiffies is too big, and > local_clock() might be too expensive. Hannes hacked up this patch for me... (didn't finish testing) The basic idea is we want keep/restore the quota fairness between qdisc's , that we sort of broke with commit 5772e9a346 ("qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE"). We choose not to account for the number of packets inside the TSO/GSO packets ("skb_gso_segs"). As the previous fairness also had this "defect". You might view this as a short term solution, until you can fix it with your q->bstats.packets or time quota? [RFC PATCH] net_sched: restore quota limits after bulk dequeue --- a/net/sched/sch_generic.c +++ b/net/sched/sch_generic.c @@ -57,17 +57,19 @@ static inline int dev_requeue_skb(struct sk_buff *skb, struct Qdisc *q) static void try_bulk_dequeue_skb(struct Qdisc *q, struct sk_buff *skb, - const struct netdev_queue *txq) + const struct netdev_queue *txq, + int *quota) { int bytelimit = qdisc_avail_bulklimit(txq) - skb->len; - while (bytelimit > 0) { + while (bytelimit > 0 && *quota > 0) { struct sk_buff *nskb = q->dequeue(q); if (!nskb) break; bytelimit -= nskb->len; /* covers GSO len */ + --*quota; skb->next = nskb; skb = nskb; } @@ -77,7 +79,7 @@ static void try_bulk_dequeue_skb(struct Qdisc *q, /* Note that dequeue_skb can possibly return a SKB list (via skb->next). * A requeued skb (via q->gso_skb) can also be a SKB list. */ -static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate) +static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate, int *quota) { struct sk_buff *skb = q->gso_skb; const struct netdev_queue *txq = q->dev_queue; @@ -87,18 +89,25 @@ static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate) /* check the reason of requeuing without tx lock first */ txq = skb_get_tx_queue(txq->dev, skb); if (!netif_xmit_frozen_or_stopped(txq)) { + struct sk_buff *iskb = skb; + q->gso_skb = NULL; q->q.qlen--; - } else + do + --*quota; + while ((iskb = skb->next)); + } else { skb = NULL; + } /* skb in gso_skb were already validated */ *validate = false; } else { if (!(q->flags & TCQ_F_ONETXQUEUE) || !netif_xmit_frozen_or_stopped(txq)) { skb = q->dequeue(q); + --*quota; if (skb && qdisc_may_bulk(q)) - try_bulk_dequeue_skb(q, skb, txq); + try_bulk_dequeue_skb(q, skb, txq, quota); } } return skb; @@ -204,7 +213,7 @@ int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, * >0 - queue is not empty. * */ -static inline int qdisc_restart(struct Qdisc *q) +static inline int qdisc_restart(struct Qdisc *q, int *quota) { struct netdev_queue *txq; struct net_device *dev; @@ -213,7 +222,7 @@ static inline int qdisc_restart(struct Qdisc *q) bool validate; /* Dequeue packet */ - skb = dequeue_skb(q, &validate); + skb = dequeue_skb(q, &validate, quota); if (unlikely(!skb)) return 0; @@ -230,13 +239,13 @@ void __qdisc_run(struct Qdisc *q) { int quota = weight_p; - while (qdisc_restart(q)) { + while (qdisc_restart(q, "a)) { /* * Ordered by possible occurrence: Postpone processing if * 1. we've exceeded packet quota * 2. another process needs the CPU; */ - if (--quota <= 0 || need_resched()) { + if (quota <= 0 || need_resched()) { __netif_schedule(q); break; } ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) 2014-10-07 13:30 ` Jesper Dangaard Brouer @ 2014-10-07 14:43 ` Hannes Frederic Sowa 2014-10-07 15:01 ` Eric Dumazet 2014-10-07 15:26 ` Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) Jesper Dangaard Brouer 0 siblings, 2 replies; 42+ messages in thread From: Hannes Frederic Sowa @ 2014-10-07 14:43 UTC (permalink / raw) To: Jesper Dangaard Brouer, Eric Dumazet Cc: David Miller, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Tue, Oct 7, 2014, at 15:30, Jesper Dangaard Brouer wrote: > On Tue, 07 Oct 2014 05:47:18 -0700 > Eric Dumazet <eric.dumazet@gmail.com> wrote: > > > On Tue, 2014-10-07 at 09:34 +0200, Jesper Dangaard Brouer wrote: > > > On Fri, 03 Oct 2014 16:30:44 -0700 Eric Dumazet <eric.dumazet@gmail.com> wrote: > > > > > > > Another problem we need to address is the quota in __qdisc_run() > > > > is no longer meaningfull, if each qdisc_restart() can pump many packets. > > > > > > I fully agree. My earlier "magic" packet limit was covering/pampering > > > over this issue. > > > > Although quota was multiplied by 7 or 8 in worst case ? > > Yes, exactly not a very elegant solution ;-) > > > > > > An idea would be to use the bstats (or cpu_qstats if applicable) > > > > > > Please elaborate some more, as I don't completely follow (feel free to > > > show with a patch ;-)). > > > > > > > I was hoping John could finish the percpu stats before I do that. > > > > Problem with q->bstats.packets is that TSO packets with 45 MSS add 45 to > > this counter. > > > > Using a time quota would be better, but : jiffies is too big, and > > local_clock() might be too expensive. > > Hannes hacked up this patch for me... (didn't finish testing) > > The basic idea is we want keep/restore the quota fairness between > qdisc's , that we sort of broke with commit 5772e9a346 ("qdisc: bulk > dequeue support for qdiscs with TCQ_F_ONETXQUEUE"). > > We choose not to account for the number of packets inside the TSO/GSO > packets ("skb_gso_segs"). As the previous fairness also had this > "defect". > > You might view this as a short term solution, until you can fix it with > your q->bstats.packets or time quota? > > > [RFC PATCH] net_sched: restore quota limits after bulk dequeue > > --- a/net/sched/sch_generic.c > +++ b/net/sched/sch_generic.c > @@ -57,17 +57,19 @@ static inline int dev_requeue_skb(struct sk_buff > *skb, struct Qdisc *q) > > static void try_bulk_dequeue_skb(struct Qdisc *q, > struct sk_buff *skb, > - const struct netdev_queue *txq) > + const struct netdev_queue *txq, > + int *quota) > { > int bytelimit = qdisc_avail_bulklimit(txq) - skb->len; > > - while (bytelimit > 0) { > + while (bytelimit > 0 && *quota > 0) { > struct sk_buff *nskb = q->dequeue(q); > > if (!nskb) > break; > > bytelimit -= nskb->len; /* covers GSO len */ > + --*quota; > skb->next = nskb; > skb = nskb; > } > @@ -77,7 +79,7 @@ static void try_bulk_dequeue_skb(struct Qdisc *q, > /* Note that dequeue_skb can possibly return a SKB list (via skb->next). > * A requeued skb (via q->gso_skb) can also be a SKB list. > */ > -static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate) > +static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate, int > *quota) > { > struct sk_buff *skb = q->gso_skb; > const struct netdev_queue *txq = q->dev_queue; > @@ -87,18 +89,25 @@ static struct sk_buff *dequeue_skb(struct Qdisc *q, > bool *validate) > /* check the reason of requeuing without tx lock first */ > txq = skb_get_tx_queue(txq->dev, skb); > if (!netif_xmit_frozen_or_stopped(txq)) { > + struct sk_buff *iskb = skb; > + > q->gso_skb = NULL; > q->q.qlen--; > - } else > + do > + --*quota; > + while ((iskb = skb->next)); This needs to be: do ... while ((iskb = iskb->next)) Bye, Hannes ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) 2014-10-07 14:43 ` Hannes Frederic Sowa @ 2014-10-07 15:01 ` Eric Dumazet 2014-10-07 15:06 ` Eric Dumazet 2014-10-07 17:19 ` Quota in __qdisc_run() David Miller 2014-10-07 15:26 ` Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) Jesper Dangaard Brouer 1 sibling, 2 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-07 15:01 UTC (permalink / raw) To: Hannes Frederic Sowa Cc: Jesper Dangaard Brouer, David Miller, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Tue, 2014-10-07 at 16:43 +0200, Hannes Frederic Sowa wrote: > This needs to be: > > do > ... > while ((iskb = iskb->next)) I do not feel needed to break the bulk dequeue at precise quota boundary. These quotas are advisory, and bql prefers to get its full budget for appropriate feedback from TX completion. Quota was a packet quota, which was quite irrelevant if segmentation had to be done, so I would just let the dequeue be done so that we benefit from optimal xmit_more. diff --git a/net/sched/sch_generic.c b/net/sched/sch_generic.c index 2b349a4de3c8e3491fad210a9400d26bda5b52fe..581ba0dcc2474f325d1c0b3e1dc957648f11992f 100644 --- a/net/sched/sch_generic.c +++ b/net/sched/sch_generic.c @@ -58,7 +58,8 @@ static inline int dev_requeue_skb(struct sk_buff *skb, struct Qdisc *q) static void try_bulk_dequeue_skb(struct Qdisc *q, struct sk_buff *skb, - const struct netdev_queue *txq) + const struct netdev_queue *txq, + int *packets) { int bytelimit = qdisc_avail_bulklimit(txq) - skb->len; @@ -71,6 +72,7 @@ static void try_bulk_dequeue_skb(struct Qdisc *q, bytelimit -= nskb->len; /* covers GSO len */ skb->next = nskb; skb = nskb; + (*packets)++; } skb->next = NULL; } @@ -78,11 +80,13 @@ static void try_bulk_dequeue_skb(struct Qdisc *q, /* Note that dequeue_skb can possibly return a SKB list (via skb->next). * A requeued skb (via q->gso_skb) can also be a SKB list. */ -static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate) +static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate, + int *packets) { struct sk_buff *skb = q->gso_skb; const struct netdev_queue *txq = q->dev_queue; + *packets = 1; /* yes, this might be not accurate, only if BQL is wrong */ *validate = true; if (unlikely(skb)) { /* check the reason of requeuing without tx lock first */ @@ -99,7 +103,7 @@ static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate) !netif_xmit_frozen_or_stopped(txq)) { skb = q->dequeue(q); if (skb && qdisc_may_bulk(q)) - try_bulk_dequeue_skb(q, skb, txq); + try_bulk_dequeue_skb(q, skb, txq, packets); } } return skb; @@ -205,7 +209,7 @@ int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, * >0 - queue is not empty. * */ -static inline int qdisc_restart(struct Qdisc *q) +static inline int qdisc_restart(struct Qdisc *q, int *packets) { struct netdev_queue *txq; struct net_device *dev; @@ -214,7 +218,7 @@ static inline int qdisc_restart(struct Qdisc *q) bool validate; /* Dequeue packet */ - skb = dequeue_skb(q, &validate); + skb = dequeue_skb(q, &validate, packets); if (unlikely(!skb)) return 0; @@ -230,14 +234,16 @@ static inline int qdisc_restart(struct Qdisc *q) void __qdisc_run(struct Qdisc *q) { int quota = weight_p; + int packets; - while (qdisc_restart(q)) { + while (qdisc_restart(q, &packets)) { /* * Ordered by possible occurrence: Postpone processing if * 1. we've exceeded packet quota * 2. another process needs the CPU; */ - if (--quota <= 0 || need_resched()) { + quota -= packets; + if (quota <= 0 || need_resched()) { __netif_schedule(q); break; } ^ permalink raw reply related [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) 2014-10-07 15:01 ` Eric Dumazet @ 2014-10-07 15:06 ` Eric Dumazet 2014-10-07 17:19 ` Quota in __qdisc_run() David Miller 1 sibling, 0 replies; 42+ messages in thread From: Eric Dumazet @ 2014-10-07 15:06 UTC (permalink / raw) To: Hannes Frederic Sowa Cc: Jesper Dangaard Brouer, David Miller, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Tue, 2014-10-07 at 08:01 -0700, Eric Dumazet wrote: > Quota was a packet quota, which was quite irrelevant if segmentation had > to be done, so I would just let the dequeue be done so that we benefit > from optimal xmit_more. And it also is better to allow receiver to get full LRO/GRO aggregation, if we do not break GSO train in multiple parts. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() 2014-10-07 15:01 ` Eric Dumazet 2014-10-07 15:06 ` Eric Dumazet @ 2014-10-07 17:19 ` David Miller 2014-10-07 17:32 ` Eric Dumazet 2014-10-07 18:03 ` Jesper Dangaard Brouer 1 sibling, 2 replies; 42+ messages in thread From: David Miller @ 2014-10-07 17:19 UTC (permalink / raw) To: eric.dumazet Cc: hannes, brouer, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke From: Eric Dumazet <eric.dumazet@gmail.com> Date: Tue, 07 Oct 2014 08:01:20 -0700 > On Tue, 2014-10-07 at 16:43 +0200, Hannes Frederic Sowa wrote: > >> This needs to be: >> >> do >> ... >> while ((iskb = iskb->next)) > > I do not feel needed to break the bulk dequeue at precise quota > boundary. These quotas are advisory, and bql prefers to get its full > budget for appropriate feedback from TX completion. > > Quota was a packet quota, which was quite irrelevant if segmentation had > to be done, so I would just let the dequeue be done so that we benefit > from optimal xmit_more. Yes, this makes sense, do a full qdisc_restart() cycle without boundaries, then check how much quota was used afterwards to guard the outermost loop. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() 2014-10-07 17:19 ` Quota in __qdisc_run() David Miller @ 2014-10-07 17:32 ` Eric Dumazet 2014-10-07 18:37 ` Jesper Dangaard Brouer 2014-10-07 18:03 ` Jesper Dangaard Brouer 1 sibling, 1 reply; 42+ messages in thread From: Eric Dumazet @ 2014-10-07 17:32 UTC (permalink / raw) To: David Miller Cc: hannes, brouer, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Tue, 2014-10-07 at 13:19 -0400, David Miller wrote: > Yes, this makes sense, do a full qdisc_restart() cycle without boundaries, > then check how much quota was used afterwards to guard the outermost loop. I am testing this, and also am testing the xmit_more patch for I40E. Will send patches today. Thanks ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() 2014-10-07 17:32 ` Eric Dumazet @ 2014-10-07 18:37 ` Jesper Dangaard Brouer 2014-10-07 20:07 ` Jesper Dangaard Brouer 0 siblings, 1 reply; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-07 18:37 UTC (permalink / raw) To: Eric Dumazet Cc: David Miller, hannes, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke, brouer On Tue, 07 Oct 2014 10:32:12 -0700 Eric Dumazet <eric.dumazet@gmail.com> wrote: > On Tue, 2014-10-07 at 13:19 -0400, David Miller wrote: > > > Yes, this makes sense, do a full qdisc_restart() cycle without boundaries, > > then check how much quota was used afterwards to guard the outermost loop. > > I am testing this, and also am testing the xmit_more patch for I40E. Check, I'm also testing both yours and Hannes patch. Results at: http://people.netfilter.org/hawk/qdisc/measure18_restore_quota_fairness/ http://people.netfilter.org/hawk/qdisc/measure19_restore_quota_erics/ http://people.netfilter.org/hawk/qdisc/measure20_no_quota_baseline_at_git_02c0fc1/ -- Best regards, Jesper Dangaard Brouer MSc.CS, Sr. Network Kernel Developer at Red Hat Author of http://www.iptv-analyzer.org LinkedIn: http://www.linkedin.com/in/brouer ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() 2014-10-07 18:37 ` Jesper Dangaard Brouer @ 2014-10-07 20:07 ` Jesper Dangaard Brouer 0 siblings, 0 replies; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-07 20:07 UTC (permalink / raw) To: Jesper Dangaard Brouer Cc: Eric Dumazet, David Miller, hannes, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Tue, 7 Oct 2014 20:37:00 +0200 Jesper Dangaard Brouer <brouer@redhat.com> wrote: > On Tue, 07 Oct 2014 10:32:12 -0700 > Eric Dumazet <eric.dumazet@gmail.com> wrote: > > > On Tue, 2014-10-07 at 13:19 -0400, David Miller wrote: > > > > > Yes, this makes sense, do a full qdisc_restart() cycle without boundaries, > > > then check how much quota was used afterwards to guard the outermost loop. > > > > I am testing this, and also am testing the xmit_more patch for I40E. > > Check, I'm also testing both yours and Hannes patch. > > Results at: > http://people.netfilter.org/hawk/qdisc/measure18_restore_quota_fairness/ > http://people.netfilter.org/hawk/qdisc/measure19_restore_quota_erics/ > http://people.netfilter.org/hawk/qdisc/measure20_no_quota_baseline_at_git_02c0fc1/ These tests are with ixgbe with a single TXQ, in-order to measure the effect of HoL, by taking advantage of the high prio queue of pfifo_fast. (Cmdline trick for a single TXQ: "ethtool -L eth4 combined 1") In case GSO=off TSO=off, Hannes "wins" with 0.04ms http://people.netfilter.org/hawk/qdisc/measure19_restore_quota_erics/compare_rr_latency_eric_vs_hannes_NoneXSO.png which I guess we should not be concerned with. In case GSO=on TSO=off, the diff is max 0.01ms (to Hannes advantage ;-)) Notice the extreme zoom level: http://people.netfilter.org/hawk/qdisc/measure19_restore_quota_erics/compare_rr_latency_eric_vs_hannes_GSO.png In case GSO=on TSO=on, there are some spikes, where Eric's version have the highest spike. http://people.netfilter.org/hawk/qdisc/measure19_restore_quota_erics/compare_rr_latency_eric_vs_hannes_TSO.png Again nothing we should worry about. Thus, guess we can safely go with Eric's solution, even-thought Hannes version consistently shows less HoL blocking and less sever spikes, as the difference is so small. I'm ACKing Eric's version... We do need this patch, as can be seen by the baseline test at git commit 02c0fc1. Where some bandwidth unfairness to the UDP flows happens, but only in the case GSO=off TSO=off (others are fine). http://people.netfilter.org/hawk/qdisc/measure20_no_quota_baseline_at_git_02c0fc1/NoneXSO_10Gbit_base_02c0fc1_bandwidth_totals_unfairness.png Kind of strange, but it went away in the two quota tests. -- Best regards, Jesper Dangaard Brouer MSc.CS, Sr. Network Kernel Developer at Red Hat Author of http://www.iptv-analyzer.org LinkedIn: http://www.linkedin.com/in/brouer ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() 2014-10-07 17:19 ` Quota in __qdisc_run() David Miller 2014-10-07 17:32 ` Eric Dumazet @ 2014-10-07 18:03 ` Jesper Dangaard Brouer 2014-10-07 19:10 ` Eric Dumazet 1 sibling, 1 reply; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-07 18:03 UTC (permalink / raw) To: David Miller Cc: eric.dumazet, hannes, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke, brouer On Tue, 07 Oct 2014 13:19:38 -0400 (EDT) David Miller <davem@davemloft.net> wrote: > From: Eric Dumazet <eric.dumazet@gmail.com> > Date: Tue, 07 Oct 2014 08:01:20 -0700 > > > On Tue, 2014-10-07 at 16:43 +0200, Hannes Frederic Sowa wrote: > > > >> This needs to be: > >> > >> do > >> ... > >> while ((iskb = iskb->next)) > > > > I do not feel needed to break the bulk dequeue at precise quota > > boundary. These quotas are advisory, and bql prefers to get its full > > budget for appropriate feedback from TX completion. > > > > Quota was a packet quota, which was quite irrelevant if segmentation had > > to be done, so I would just let the dequeue be done so that we benefit > > from optimal xmit_more. > > Yes, this makes sense, do a full qdisc_restart() cycle without boundaries, > then check how much quota was used afterwards to guard the outermost loop. According to my measurements, at 10Gbit/s TCP_STREAM test the BQL limit is 381528 bytes / 1514 = 252 packets, that will (potentially) be bulk dequeued at once (with your version of the patch). It seems to have the potential to exceed the weight_p(64) quite a lot. And with e.g. TX ring size 512, we also also challenge the drivers at this early adoption phase of tailptr writes. Just saying... -- Best regards, Jesper Dangaard Brouer MSc.CS, Sr. Network Kernel Developer at Red Hat Author of http://www.iptv-analyzer.org LinkedIn: http://www.linkedin.com/in/brouer ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() 2014-10-07 18:03 ` Jesper Dangaard Brouer @ 2014-10-07 19:10 ` Eric Dumazet 2014-10-07 19:34 ` Jesper Dangaard Brouer 0 siblings, 1 reply; 42+ messages in thread From: Eric Dumazet @ 2014-10-07 19:10 UTC (permalink / raw) To: Jesper Dangaard Brouer Cc: David Miller, hannes, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On Tue, 2014-10-07 at 20:03 +0200, Jesper Dangaard Brouer wrote: > According to my measurements, at 10Gbit/s TCP_STREAM test the BQL limit > is 381528 bytes / 1514 = 252 packets, that will (potentially) be bulk > dequeued at once (with your version of the patch). > That's because you use a single queue maybe ? In reality, 10Gbe NIC are used in multiqueue mode ... Here we have limits around 2 TSO packets. Even with only 4 tx queues I have : # sar -n DEV 3 3 |grep eth1 12:05:19 PM eth1 147217.67 809066.67 9488.71 1196207.78 0.00 0.00 0.00 12:05:22 PM eth1 145958.00 807822.33 9407.48 1194366.73 0.00 0.00 0.00 12:05:25 PM eth1 147502.33 804739.33 9507.26 1189804.23 0.00 0.00 0.33 Average: eth1 146892.67 807209.44 9467.82 1193459.58 0.00 0.00 0.11 grep . /sys/class/net/eth1/queues/tx*/byte_queue_limits/{inflight,limit} /sys/class/net/eth1/queues/tx-0/byte_queue_limits/inflight:115064 /sys/class/net/eth1/queues/tx-1/byte_queue_limits/inflight:0 /sys/class/net/eth1/queues/tx-2/byte_queue_limits/inflight:0 /sys/class/net/eth1/queues/tx-3/byte_queue_limits/inflight:0 /sys/class/net/eth1/queues/tx-0/byte_queue_limits/limit:102952 /sys/class/net/eth1/queues/tx-1/byte_queue_limits/limit:124148 /sys/class/net/eth1/queues/tx-2/byte_queue_limits/limit:102952 /sys/class/net/eth1/queues/tx-3/byte_queue_limits/limit:136260 > It seems to have the potential to exceed the weight_p(64) quite a lot. > And with e.g. TX ring size 512, we also also challenge the drivers at > this early adoption phase of tailptr writes. Just saying... > Yep, but remind we want to squeeze bugs out of the drivers, then add additional knobs later. Whatever limit we choose in core networking stack (being 64 packets for example), hardware might have different constraints that need to be taken care of in the driver. ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() 2014-10-07 19:10 ` Eric Dumazet @ 2014-10-07 19:34 ` Jesper Dangaard Brouer 0 siblings, 0 replies; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-07 19:34 UTC (permalink / raw) To: Eric Dumazet Cc: David Miller, hannes, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke, brouer On Tue, 07 Oct 2014 12:10:15 -0700 Eric Dumazet <eric.dumazet@gmail.com> wrote: > On Tue, 2014-10-07 at 20:03 +0200, Jesper Dangaard Brouer wrote: > > > According to my measurements, at 10Gbit/s TCP_STREAM test the BQL limit > > is 381528 bytes / 1514 = 252 packets, that will (potentially) be bulk > > dequeued at once (with your version of the patch). > > > > That's because you use a single queue maybe ? No, I just double checked. I was using a single netperf TCP_STREAM with GRO=off TSO=off. > Here we have limits around 2 TSO packets. Which should be approx 128k Just tested with GRO=on TSO=on single TCP_STREAM, which is weird as I should hit your 2xTSO limit right, and inflight shows 408780. And I do have (which I guess is the 2xTSO): /proc/sys/net/ipv4/tcp_limit_output_bytes:131072 $ grep -H . /sys/class/net/eth4/queues/tx-*/byte_queue_limits/{inflight,limit} /sys/class/net/eth4/queues/tx-0/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-10/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-11/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-1/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-2/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-3/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-4/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-5/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-6/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-7/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-8/byte_queue_limits/inflight:408780 /sys/class/net/eth4/queues/tx-9/byte_queue_limits/inflight:0 /sys/class/net/eth4/queues/tx-0/byte_queue_limits/limit:340848 /sys/class/net/eth4/queues/tx-10/byte_queue_limits/limit:340650 /sys/class/net/eth4/queues/tx-11/byte_queue_limits/limit:367902 /sys/class/net/eth4/queues/tx-1/byte_queue_limits/limit:272520 /sys/class/net/eth4/queues/tx-2/byte_queue_limits/limit:204390 /sys/class/net/eth4/queues/tx-3/byte_queue_limits/limit:162856 /sys/class/net/eth4/queues/tx-4/byte_queue_limits/limit:158314 /sys/class/net/eth4/queues/tx-5/byte_queue_limits/limit:136260 /sys/class/net/eth4/queues/tx-6/byte_queue_limits/limit:140802 /sys/class/net/eth4/queues/tx-7/byte_queue_limits/limit:152258 /sys/class/net/eth4/queues/tx-8/byte_queue_limits/limit:340650 /sys/class/net/eth4/queues/tx-9/byte_queue_limits/limit:340650 Strange... > Even with only 4 tx queues I have : > > # sar -n DEV 3 3 |grep eth1 > 12:05:19 PM eth1 147217.67 809066.67 9488.71 1196207.78 0.00 0.00 0.00 > 12:05:22 PM eth1 145958.00 807822.33 9407.48 1194366.73 0.00 0.00 0.00 > 12:05:25 PM eth1 147502.33 804739.33 9507.26 1189804.23 0.00 0.00 0.33 > Average: eth1 146892.67 807209.44 9467.82 1193459.58 0.00 0.00 0.11 > > > grep . /sys/class/net/eth1/queues/tx*/byte_queue_limits/{inflight,limit} > /sys/class/net/eth1/queues/tx-0/byte_queue_limits/inflight:115064 > /sys/class/net/eth1/queues/tx-1/byte_queue_limits/inflight:0 > /sys/class/net/eth1/queues/tx-2/byte_queue_limits/inflight:0 > /sys/class/net/eth1/queues/tx-3/byte_queue_limits/inflight:0 > /sys/class/net/eth1/queues/tx-0/byte_queue_limits/limit:102952 > /sys/class/net/eth1/queues/tx-1/byte_queue_limits/limit:124148 > /sys/class/net/eth1/queues/tx-2/byte_queue_limits/limit:102952 > /sys/class/net/eth1/queues/tx-3/byte_queue_limits/limit:136260 Guess this is okay, 115064 / 1514 = 76 pkts which is closer to the 64 weight_p. > > It seems to have the potential to exceed the weight_p(64) quite a lot. > > And with e.g. TX ring size 512, we also also challenge the drivers at > > this early adoption phase of tailptr writes. Just saying... > > > > Yep, but remind we want to squeeze bugs out of the drivers, then add > additional knobs later. Okay, for squeezing out bugs, then I understand this more aggressive bulking strategy. I'm all in then! > Whatever limit we choose in core networking stack (being 64 packets for > example), hardware might have different constraints that need to be > taken care of in the driver. -- Best regards, Jesper Dangaard Brouer MSc.CS, Sr. Network Kernel Developer at Red Hat Author of http://www.iptv-analyzer.org LinkedIn: http://www.linkedin.com/in/brouer ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) 2014-10-07 14:43 ` Hannes Frederic Sowa 2014-10-07 15:01 ` Eric Dumazet @ 2014-10-07 15:26 ` Jesper Dangaard Brouer 1 sibling, 0 replies; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-07 15:26 UTC (permalink / raw) To: Hannes Frederic Sowa Cc: Eric Dumazet, David Miller, netdev, therbert, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke, brouer On Tue, 07 Oct 2014 16:43:33 +0200 Hannes Frederic Sowa <hannes@stressinduktion.org> wrote: > On Tue, Oct 7, 2014, at 15:30, Jesper Dangaard Brouer wrote: [...] > > > > The basic idea is we want keep/restore the quota fairness between > > qdisc's , that we sort of broke with commit 5772e9a346 ("qdisc: bulk > > dequeue support for qdiscs with TCQ_F_ONETXQUEUE"). > > [...] > > This needs to be: > > do > ... > while ((iskb = iskb->next)) Check, testing with this update, now. My netperf-wrapper test with GSO=off TSO=off, looks much more stable at keeping the 10G link fully utilized. Before, without this patch, I could not get stable results at 10G with GSO=off TSO=off. Think this really does address the fairness (I didn't think I would be able to measure it). The other cases (GSO=on,TSO=off) and (GSO=on,TSO=on) looks the same. -- Best regards, Jesper Dangaard Brouer MSc.CS, Sr. Network Kernel Developer at Red Hat Author of http://www.iptv-analyzer.org LinkedIn: http://www.linkedin.com/in/brouer ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: Quota in __qdisc_run() 2014-10-07 12:47 ` Eric Dumazet 2014-10-07 13:30 ` Jesper Dangaard Brouer @ 2014-10-08 17:38 ` John Fastabend 1 sibling, 0 replies; 42+ messages in thread From: John Fastabend @ 2014-10-08 17:38 UTC (permalink / raw) To: Eric Dumazet Cc: Jesper Dangaard Brouer, David Miller, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke On 10/07/2014 05:47 AM, Eric Dumazet wrote: > On Tue, 2014-10-07 at 09:34 +0200, Jesper Dangaard Brouer wrote: >> On Fri, 03 Oct 2014 16:30:44 -0700 Eric Dumazet <eric.dumazet@gmail.com> wrote: >> >>> Another problem we need to address is the quota in __qdisc_run() >>> is no longer meaningfull, if each qdisc_restart() can pump many packets. >> >> I fully agree. My earlier "magic" packet limit was covering/pampering >> over this issue. > > Although quota was multiplied by 7 or 8 in worst case ? > >> >>> An idea would be to use the bstats (or cpu_qstats if applicable) >> >> Please elaborate some more, as I don't completely follow (feel free to >> show with a patch ;-)). >> > > I was hoping John could finish the percpu stats before I do that. What stats are you referring to? I assume the remaining stats in the xmit path mostly in sch_generic.c? By the way I need to do another review of the classifier code paths but I believe we could drop the ingress qdisc lock now (finally)... Also some clean up in sch_generic.c could help this. Notes for myself mostly, dev_requeue_skb() can be a void its return value is always 0 the users of handle_dev_cpu_collision and sch_direct_xmit don't use the qlen for anything returning any positive integer looks like it would work. Thanks, John -- John Fastabend Intel Corporation ^ permalink raw reply [flat|nested] 42+ messages in thread
* Re: [PATCH net-next] qdisc: validate skb without holding lock 2014-10-03 22:36 ` David Miller 2014-10-03 23:30 ` Eric Dumazet @ 2014-10-06 14:12 ` Jesper Dangaard Brouer 1 sibling, 0 replies; 42+ messages in thread From: Jesper Dangaard Brouer @ 2014-10-06 14:12 UTC (permalink / raw) To: David Miller Cc: eric.dumazet, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend, dave.taht, toke, brouer On Fri, 03 Oct 2014 15:36:45 -0700 (PDT) David Miller <davem@davemloft.net> wrote: > From: Eric Dumazet <eric.dumazet@gmail.com> > Date: Fri, 03 Oct 2014 15:31:07 -0700 > > > From: Eric Dumazet <edumazet@google.com> > > > > Validation of skb can be pretty expensive : > > > > GSO segmentation and/or checksum computations. > > > > We can do this without holding qdisc lock, so that other cpus > > can queue additional packets. > > [...] > > > > Turning TSO on or off had no effect on throughput, only few more cpu > > cycles. Lock contention on qdisc lock disappeared. This is good work! Lock contention significantly reduced! My 10G tests just 2x 10G netperf TCP_STREAM shows: With GSO=off TSO=off, _raw_spin_lock is now only at perf top#13 with 1.44% (80% from qdisc calls, 60% is from __dev_queue_xmit and 20% from sch_direct_xmit) (before with qdisc bulking is was 2.66%). The "show off" case is GSO=on TSO=off, where raw_spin_lock is now only at perf top#26 with 0.85% and only 54.74% comes from qdisc calls (52.07% sch_direct_xmit and 2.67% __dev_queue_xmit). This is some significant improvements to the kernels xmit layer, me very happy!!! :-))) Thanks everyone! -- Best regards, Jesper Dangaard Brouer MSc.CS, Sr. Network Kernel Developer at Red Hat Author of http://www.iptv-analyzer.org LinkedIn: http://www.linkedin.com/in/brouer ^ permalink raw reply [flat|nested] 42+ messages in thread
* [PATCH net-next] net: skb_segment() provides list head and tail 2014-10-03 22:31 ` [PATCH net-next] qdisc: validate skb without holding lock Eric Dumazet 2014-10-03 22:36 ` David Miller @ 2014-10-04 3:59 ` Eric Dumazet 2014-10-06 4:38 ` David Miller 1 sibling, 1 reply; 42+ messages in thread From: Eric Dumazet @ 2014-10-04 3:59 UTC (permalink / raw) To: David Miller Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend From: Eric Dumazet <edumazet@google.com> Its unfortunate we have to walk again skb list to find the tail after segmentation, even if data is probably hot in cpu caches. skb_segment() can store the tail of the list into segs->prev, and validate_xmit_skb_list() can immediately get the tail. Signed-off-by: Eric Dumazet <edumazet@google.com> --- net/core/dev.c | 27 +++++++++++++++------------ net/core/skbuff.c | 5 +++++ 2 files changed, 20 insertions(+), 12 deletions(-) diff --git a/net/core/dev.c b/net/core/dev.c index 1a90530f83ff..7d5691cc1f47 100644 --- a/net/core/dev.c +++ b/net/core/dev.c @@ -2724,22 +2724,25 @@ struct sk_buff *validate_xmit_skb_list(struct sk_buff *skb, struct net_device *d { struct sk_buff *next, *head = NULL, *tail; - while (skb) { + for (; skb != NULL; skb = next) { next = skb->next; skb->next = NULL; + + /* in case skb wont be segmented, point to itself */ + skb->prev = skb; + skb = validate_xmit_skb(skb, dev); - if (skb) { - struct sk_buff *end = skb; + if (!skb) + continue; - while (end->next) - end = end->next; - if (!head) - head = skb; - else - tail->next = skb; - tail = end; - } - skb = next; + if (!head) + head = skb; + else + tail->next = skb; + /* If skb was segmented, skb->prev points to + * the last segment. If not, it still contains skb. + */ + tail = skb->prev; } return head; } diff --git a/net/core/skbuff.c b/net/core/skbuff.c index a0b312fa3047..06b57ec91f32 100644 --- a/net/core/skbuff.c +++ b/net/core/skbuff.c @@ -3083,6 +3083,11 @@ perform_csum_check: } } while ((offset += len) < head_skb->len); + /* Some callers want to get the end of the list. + * Put it in segs->prev to avoid walking the list. + * (see validate_xmit_skb_list() for example) + */ + segs->prev = tail; return segs; err: ^ permalink raw reply related [flat|nested] 42+ messages in thread
* Re: [PATCH net-next] net: skb_segment() provides list head and tail 2014-10-04 3:59 ` [PATCH net-next] net: skb_segment() provides list head and tail Eric Dumazet @ 2014-10-06 4:38 ` David Miller 0 siblings, 0 replies; 42+ messages in thread From: David Miller @ 2014-10-06 4:38 UTC (permalink / raw) To: eric.dumazet Cc: brouer, netdev, therbert, hannes, fw, dborkman, jhs, alexander.duyck, john.r.fastabend From: Eric Dumazet <eric.dumazet@gmail.com> Date: Fri, 03 Oct 2014 20:59:19 -0700 > From: Eric Dumazet <edumazet@google.com> > > Its unfortunate we have to walk again skb list to find the tail > after segmentation, even if data is probably hot in cpu caches. > > skb_segment() can store the tail of the list into segs->prev, > and validate_xmit_skb_list() can immediately get the tail. > > Signed-off-by: Eric Dumazet <edumazet@google.com> Applied, thanks Eric. ^ permalink raw reply [flat|nested] 42+ messages in thread
end of thread, other threads:[~2014-10-08 17:39 UTC | newest] Thread overview: 42+ messages (download: mbox.gz follow: Atom feed -- links below jump to the message on this page -- 2014-10-01 20:35 [net-next PATCH V6 0/2] qdisc: bulk dequeue support Jesper Dangaard Brouer 2014-10-01 20:35 ` [net-next PATCH V6 1/2] qdisc: bulk dequeue support for qdiscs with TCQ_F_ONETXQUEUE Jesper Dangaard Brouer 2014-10-01 20:36 ` [net-next PATCH V6 2/2] qdisc: dequeue bulking also pickup GSO/TSO packets Jesper Dangaard Brouer 2014-10-02 14:35 ` Eric Dumazet 2014-10-02 14:38 ` Daniel Borkmann 2014-10-02 14:42 ` [net-next PATCH V6 0/2] qdisc: bulk dequeue support Tom Herbert 2014-10-02 15:04 ` Eric Dumazet 2014-10-02 15:24 ` [PATCH net-next] mlx4: add a new xmit_more counter Eric Dumazet 2014-10-05 0:04 ` David Miller 2014-10-02 15:27 ` [net-next PATCH V6 0/2] qdisc: bulk dequeue support Tom Herbert 2014-10-02 16:52 ` Florian Westphal 2014-10-02 17:32 ` Eric Dumazet 2014-10-02 17:35 ` Tom Herbert 2014-10-03 19:38 ` David Miller 2014-10-03 20:57 ` Eric Dumazet 2014-10-03 21:56 ` David Miller 2014-10-03 21:57 ` Eric Dumazet 2014-10-03 22:15 ` Eric Dumazet 2014-10-03 22:19 ` Tom Herbert 2014-10-03 22:56 ` Eric Dumazet 2014-10-03 22:30 ` David Miller 2014-10-03 22:31 ` [PATCH net-next] qdisc: validate skb without holding lock Eric Dumazet 2014-10-03 22:36 ` David Miller 2014-10-03 23:30 ` Eric Dumazet 2014-10-07 7:34 ` Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) Jesper Dangaard Brouer 2014-10-07 12:47 ` Eric Dumazet 2014-10-07 13:30 ` Jesper Dangaard Brouer 2014-10-07 14:43 ` Hannes Frederic Sowa 2014-10-07 15:01 ` Eric Dumazet 2014-10-07 15:06 ` Eric Dumazet 2014-10-07 17:19 ` Quota in __qdisc_run() David Miller 2014-10-07 17:32 ` Eric Dumazet 2014-10-07 18:37 ` Jesper Dangaard Brouer 2014-10-07 20:07 ` Jesper Dangaard Brouer 2014-10-07 18:03 ` Jesper Dangaard Brouer 2014-10-07 19:10 ` Eric Dumazet 2014-10-07 19:34 ` Jesper Dangaard Brouer 2014-10-07 15:26 ` Quota in __qdisc_run() (was: qdisc: validate skb without holding lock) Jesper Dangaard Brouer 2014-10-08 17:38 ` Quota in __qdisc_run() John Fastabend 2014-10-06 14:12 ` [PATCH net-next] qdisc: validate skb without holding lock Jesper Dangaard Brouer 2014-10-04 3:59 ` [PATCH net-next] net: skb_segment() provides list head and tail Eric Dumazet 2014-10-06 4:38 ` David Miller
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox; as well as URLs for NNTP newsgroup(s).
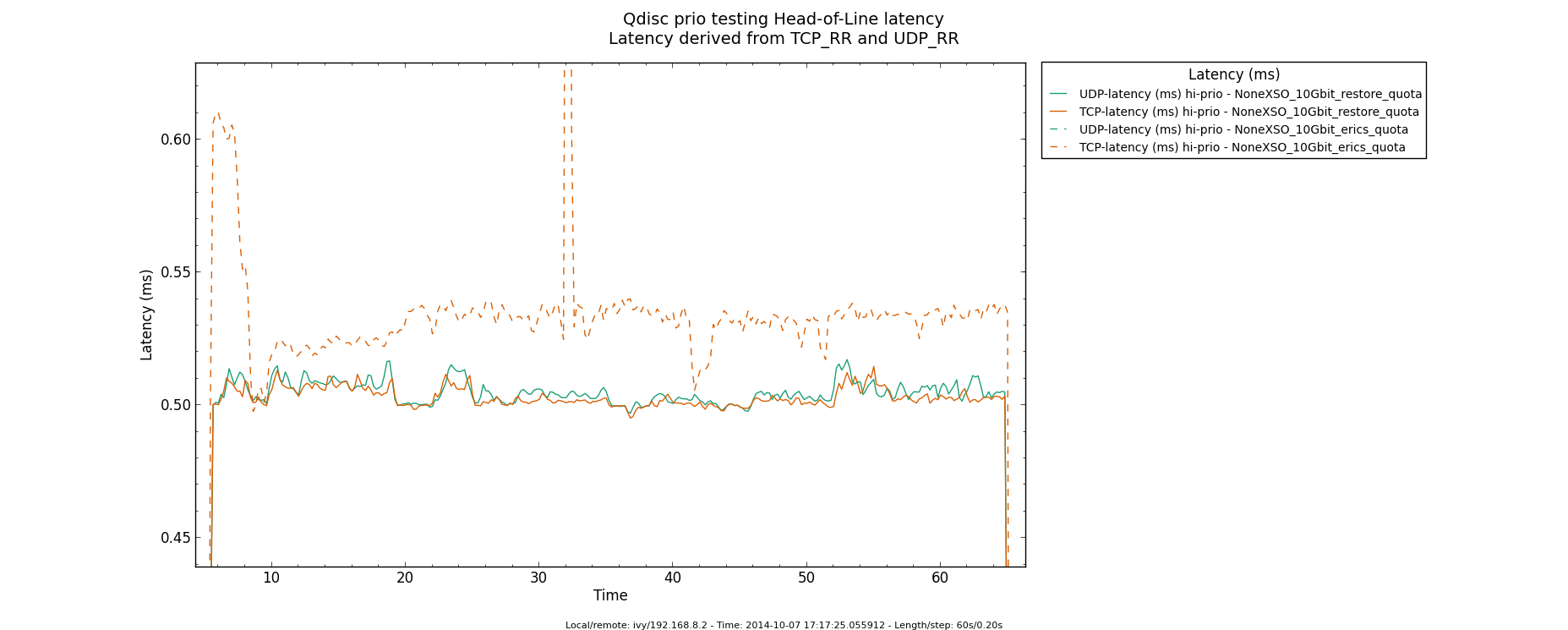{kind=link}
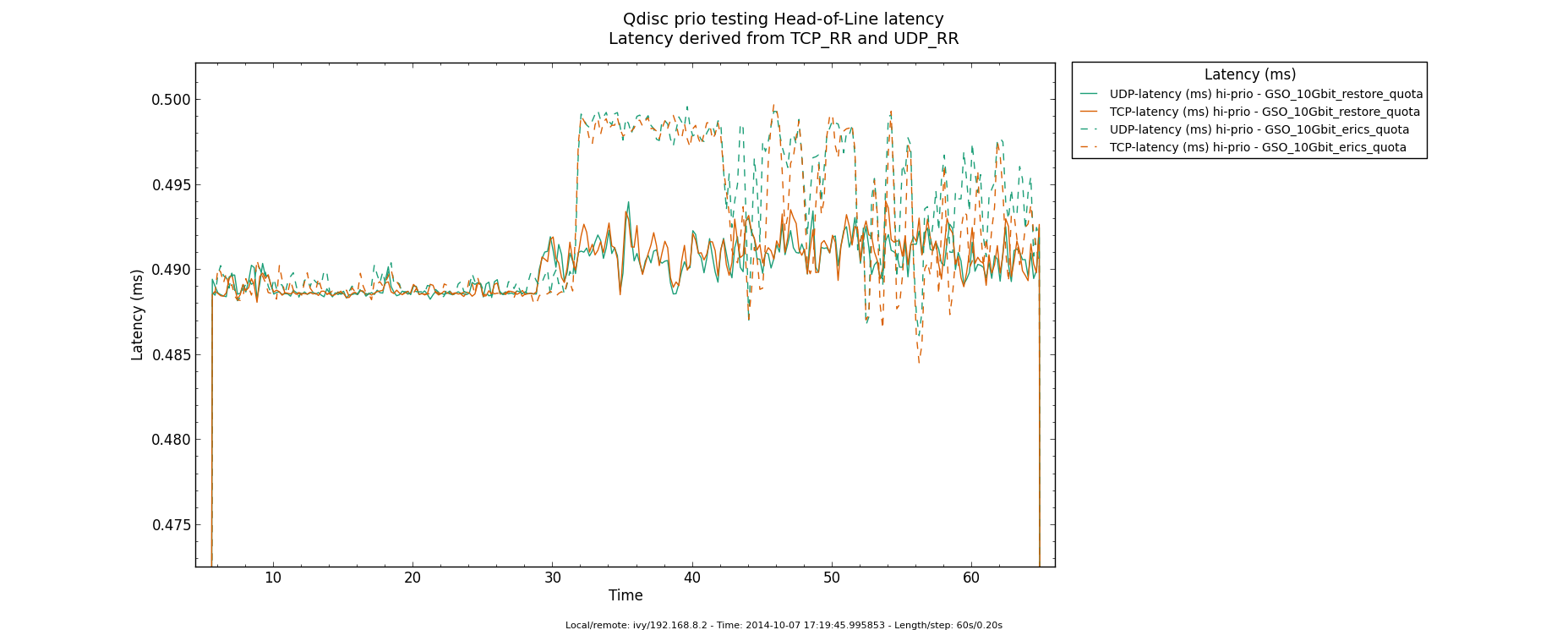{kind=link}
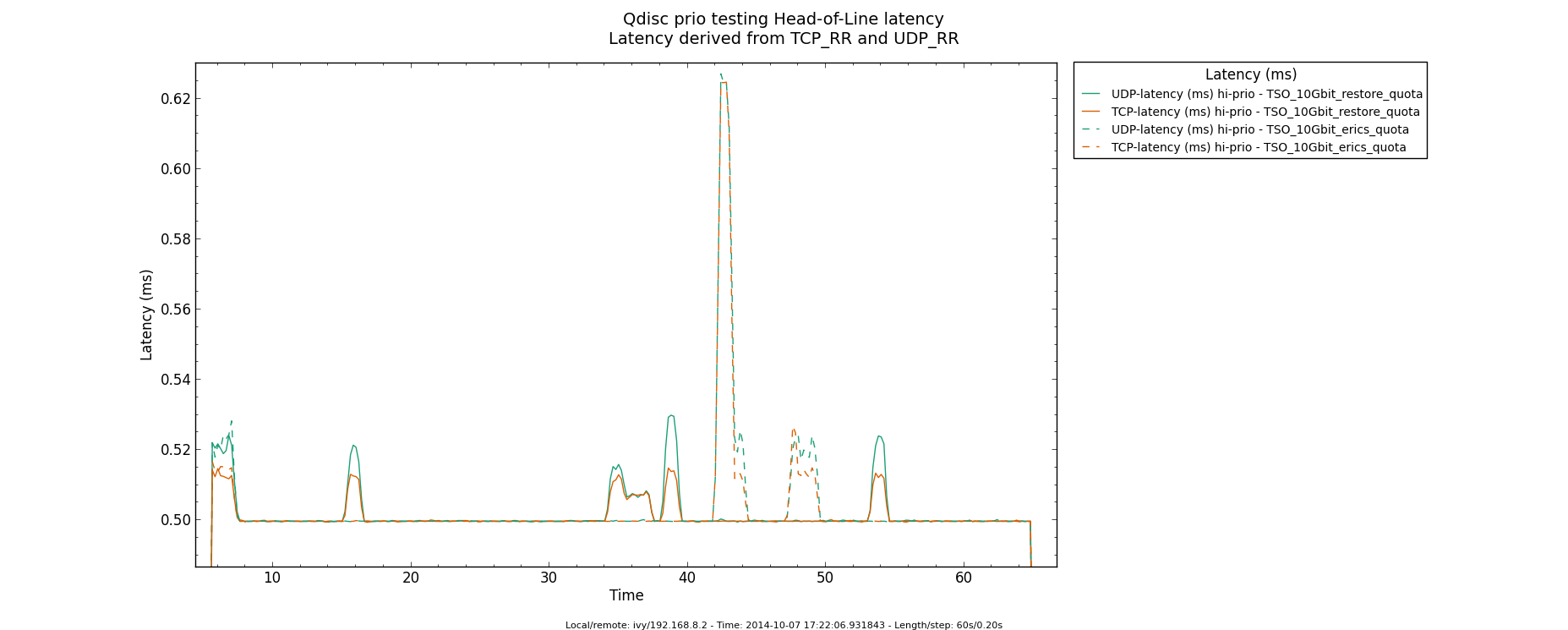{kind=link}
{kind=link}