* [RFC PATCH 0/2] gnttab: refactor locking for better scalability @ 2013-11-12 2:03 Matt Wilson 2013-11-12 2:03 ` [RFC PATCH 1/2] gnttab: lock the local grant table earlier in __gnttab_unmap_common() Matt Wilson 2013-11-12 2:03 ` [RFC PATCH 2/2] gnttab: refactor locking for better scalability Matt Wilson 0 siblings, 2 replies; 22+ messages in thread From: Matt Wilson @ 2013-11-12 2:03 UTC (permalink / raw) To: xen-devel Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Jan Beulich, Keir Fraser, Matt Wilson, Roger Pau Monné From: Matt Wilson <msw@amazon.com> As discussed in the Xen Developer Summit Storage Performance BoF, there is a lot of room for improvement in grant table locking. Anthony and I have been working on refactoring the locking over the past few weeks. The performance improvement is considerable and I'd like to hear from others if this approach is fundamentally wrong for some reason. The previous single spinlock per grant table is split into multiple locks. The heavily modified components of the grant table (the maptrack state and the active entries) are now protected by their own spinlocks. The remaining elements of the grant table are read-mostly, so I modified the main grant table lock to be a rwlock to improve concurrency. On the performance improvement: Without persistent grants, a domU with 24 VBDs plummbed to local HDDs in a streaming 2M write workload achieved 1,400 MB/sec before this change. Performance more than doubles with this patch, reaching 3,000 MB/sec before tuning and 3,600 MB/sec after adjusting event channel vCPU bindings. I included the previously posted patch to __gnttab_unmap_common() in the series since it makes a bit more sense in this context, and the follow on refactor patch is on top of it. DISCLAIMER: I ported this patch from a different Xen version earlier today, and I've only compile tested so far. In the original state we've pushed a lot of concurrent I/O through dom0 and haven't seen any stability issues. Matt Wilson (2): gnttab: lock the local grant table earlier in __gnttab_unmap_common() gnttab: refactor locking for better scalability docs/misc/grant-tables.txt | 56 +++++++- xen/arch/x86/mm.c | 4 +- xen/common/grant_table.c | 308 ++++++++++++++++++++++++++--------------- xen/include/xen/grant_table.h | 9 +- 4 files changed, 261 insertions(+), 116 deletions(-) -- 1.7.9.5 ^ permalink raw reply [flat|nested] 22+ messages in thread
* [RFC PATCH 1/2] gnttab: lock the local grant table earlier in __gnttab_unmap_common() 2013-11-12 2:03 [RFC PATCH 0/2] gnttab: refactor locking for better scalability Matt Wilson @ 2013-11-12 2:03 ` Matt Wilson 2013-11-12 2:03 ` [RFC PATCH 2/2] gnttab: refactor locking for better scalability Matt Wilson 1 sibling, 0 replies; 22+ messages in thread From: Matt Wilson @ 2013-11-12 2:03 UTC (permalink / raw) To: xen-devel Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Jan Beulich, Keir Fraser, Matt Wilson, Roger Pau Monné From: Matt Wilson <msw@amazon.com> Luckily today maptrack_limit never shrinks. But if at some point in the future this were to change, checking maptrack_limit without holding the grant table spinlock would no longer be safe. Cc: xen-devel@lists.xenproject.org Cc: Keir Fraser <keir@xen.org> Cc: Jan Beulich <jbeulich@suse.com> Reviewed-by: Andrew Cooper <andrew.cooper3@citrix.com> Reviewed-by: Anthony Liguori <aliguori@amazon.com> Signed-off-by: Matt Wilson <msw@amazon.com> --- v1->v2: * updated summary to use "local" instead of "left" --- xen/common/grant_table.c | 3 ++- 1 file changed, 2 insertions(+), 1 deletion(-) diff --git a/xen/common/grant_table.c b/xen/common/grant_table.c index 21c6a14..ef10ff4 100644 --- a/xen/common/grant_table.c +++ b/xen/common/grant_table.c @@ -842,15 +842,16 @@ __gnttab_unmap_common( op->frame = (unsigned long)(op->dev_bus_addr >> PAGE_SHIFT); + spin_lock(&lgt->lock); if ( unlikely(op->handle >= lgt->maptrack_limit) ) { + spin_unlock(&lgt->lock); gdprintk(XENLOG_INFO, "Bad handle (%d).\n", op->handle); op->status = GNTST_bad_handle; return; } op->map = &maptrack_entry(lgt, op->handle); - spin_lock(&lgt->lock); if ( unlikely(!op->map->flags) ) { -- 1.7.9.5 ^ permalink raw reply related [flat|nested] 22+ messages in thread
* [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 2:03 [RFC PATCH 0/2] gnttab: refactor locking for better scalability Matt Wilson 2013-11-12 2:03 ` [RFC PATCH 1/2] gnttab: lock the local grant table earlier in __gnttab_unmap_common() Matt Wilson @ 2013-11-12 2:03 ` Matt Wilson 2013-11-12 5:37 ` Keir Fraser 2013-11-12 9:26 ` Jan Beulich 1 sibling, 2 replies; 22+ messages in thread From: Matt Wilson @ 2013-11-12 2:03 UTC (permalink / raw) To: xen-devel Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Jan Beulich, Keir Fraser, Matt Wilson, Roger Pau Monné From: Matt Wilson <msw@amazon.com> This patch refactors grant table locking. It splits the previous single spinlock per grant table into multiple locks. The heavily modified components of the grant table (the maptrack state and the active entries) are now protected by their own spinlocks. The remaining elements of the grant table are read-mostly, so the main grant table lock is modified to be a rwlock to improve concurrency. Workloads with high grant table operation rates, especially map/unmap operations as used by blkback/blkfront when persistent grants are not supported, show marked improvement with these changes. A domU with 24 VBDs in a streaming 2M write workload achieved 1,400 MB/sec before this change. Performance more than doubles with this patch, reaching 3,000 MB/sec before tuning and 3,600 MB/sec after adjusting event channel vCPU bindings. Signed-off-by: Matt Wilson <msw@amazon.com> --- docs/misc/grant-tables.txt | 56 +++++++- xen/arch/x86/mm.c | 4 +- xen/common/grant_table.c | 309 ++++++++++++++++++++++++++--------------- xen/include/xen/grant_table.h | 9 +- 4 files changed, 261 insertions(+), 117 deletions(-) diff --git a/docs/misc/grant-tables.txt b/docs/misc/grant-tables.txt index 19db4ec..54bcba5 100644 --- a/docs/misc/grant-tables.txt +++ b/docs/misc/grant-tables.txt @@ -63,6 +63,7 @@ is complete. act->domid : remote domain being granted rights act->frame : machine frame being granted act->pin : used to hold reference counts + act->lock : spinlock used to serialize access to active entry state Map tracking ~~~~~~~~~~~~ @@ -74,7 +75,60 @@ is complete. matching map track entry is then removed, as if unmap had been invoked. These are not used by the transfer mechanism. map->domid : owner of the mapped frame - map->ref_and_flags : grant reference, ro/rw, mapped for host or device access + map->ref : grant reference + map->flags : ro/rw, mapped for host or device access + +******************************************************************************** + Locking + ~~~~~~~ + Xen uses several locks to serialize access to the internal grant table state. + + grant_table->lock : rwlock used to prevent readers from accessing + inconsistent grant table state such as current + version, partially initialized active table pages, + etc. + grant_table->maptrack_lock : spinlock used to protect the maptrack state + active_grant_entry->lock : spinlock used to serialize modifications to + active entries + + The primary lock for the grant table is a read/write spinlock. All + functions that access members of struct grant_table must acquire a + read lock around critical sections. Any modification to the members + of struct grant_table (e.g., nr_status_frames, nr_grant_frames, + active frames, etc.) must only be made if the write lock is + held. These elements are read-mostly, and read critical sections can + be large, which makes a rwlock a good choice. + + The maptrack state is protected by its own spinlock. Any access (read + or write) of struct grant_table members that have a "maptrack_" + prefix must be made while holding the maptrack lock. The maptrack + state can be rapidly modified under some workloads, and the critical + sections are very small, thus we use a spinlock to protect them. + + Active entries are obtained by calling active_entry_acquire(gt, ref). + This function returns a pointer to the active entry after locking its + spinlock. The caller must hold the rwlock for the grant table in + question before calling active_entry_acquire(). This is because the + grant table can be dynamically extended via gnttab_grow_table() while + a domain is running and each entry's spinlock must initialized before + it is used. Additionally, when the local domain is running + paravirtualized under iommu=strict mode, the mapcount() function + needs the active entries of the remote domain to be unchanged. Thus + the mapcount() function must be called with the remote table write + lock held, which prevents modifications to active entries when these + rules are observed. + + Once all access to the active entry is complete, release the lock by + calling active_entry_release(act). + + Summary of rules for locking: + active_entry_acquire() and active_entry_release() can only be + called when holding the relevant grant table's lock. I.e.: + read_lock(>->lock); + act = active_entry_acquire(gt, ref); + ... + active_entry_release(act); + read_unlock(>->lock); ******************************************************************************** diff --git a/xen/arch/x86/mm.c b/xen/arch/x86/mm.c index 43aaceb..bd7f331 100644 --- a/xen/arch/x86/mm.c +++ b/xen/arch/x86/mm.c @@ -4537,7 +4537,7 @@ static int xenmem_add_to_physmap_once( mfn = virt_to_mfn(d->shared_info); break; case XENMAPSPACE_grant_table: - spin_lock(&d->grant_table->lock); + write_lock(&d->grant_table->lock); if ( d->grant_table->gt_version == 0 ) d->grant_table->gt_version = 1; @@ -4560,7 +4560,7 @@ static int xenmem_add_to_physmap_once( mfn = virt_to_mfn(d->grant_table->shared_raw[idx]); } - spin_unlock(&d->grant_table->lock); + write_unlock(&d->grant_table->lock); break; case XENMAPSPACE_gmfn_range: case XENMAPSPACE_gmfn: diff --git a/xen/common/grant_table.c b/xen/common/grant_table.c index ef10ff4..7eb8839 100644 --- a/xen/common/grant_table.c +++ b/xen/common/grant_table.c @@ -141,10 +141,13 @@ struct active_grant_entry { in the page. */ unsigned length:16; /* For sub-page grants, the length of the grant. */ + spinlock_t lock; /* lock to protect access of this entry. + see docs/misc/grant-tables.txt for + locking protocol */ }; #define ACGNT_PER_PAGE (PAGE_SIZE / sizeof(struct active_grant_entry)) -#define active_entry(t, e) \ +#define active_entry_unlocked(t, e) \ ((t)->active[(e)/ACGNT_PER_PAGE][(e)%ACGNT_PER_PAGE]) static inline unsigned int @@ -166,6 +169,29 @@ nr_active_grant_frames(struct grant_table *gt) return num_act_frames_from_sha_frames(nr_grant_frames(gt)); } +static inline struct active_grant_entry * +active_entry_acquire(struct grant_table *t, grant_ref_t e) +{ + struct active_grant_entry *act; + +#ifndef NDEBUG + /* not perfect, but better than nothing for a debug build + * sanity check + */ + BUG_ON(!rw_is_locked(&t->lock)); +#endif + + act = &active_entry_unlocked(t, e); + spin_lock(&act->lock); + + return act; +} + +static inline void active_entry_release(struct active_grant_entry *act) +{ + spin_unlock(&act->lock); +} + /* Check if the page has been paged out, or needs unsharing. If rc == GNTST_okay, *page contains the page struct with a ref taken. Caller must do put_page(*page). @@ -206,30 +232,6 @@ static int __get_paged_frame(unsigned long gfn, unsigned long *frame, struct pag return rc; } -static inline void -double_gt_lock(struct grant_table *lgt, struct grant_table *rgt) -{ - if ( lgt < rgt ) - { - spin_lock(&lgt->lock); - spin_lock(&rgt->lock); - } - else - { - if ( lgt != rgt ) - spin_lock(&rgt->lock); - spin_lock(&lgt->lock); - } -} - -static inline void -double_gt_unlock(struct grant_table *lgt, struct grant_table *rgt) -{ - spin_unlock(&lgt->lock); - if ( lgt != rgt ) - spin_unlock(&rgt->lock); -} - static inline int __get_maptrack_handle( struct grant_table *t) @@ -245,10 +247,10 @@ static inline void put_maptrack_handle( struct grant_table *t, int handle) { - spin_lock(&t->lock); + spin_lock(&t->maptrack_lock); maptrack_entry(t, handle).ref = t->maptrack_head; t->maptrack_head = handle; - spin_unlock(&t->lock); + spin_unlock(&t->maptrack_lock); } static inline int @@ -260,7 +262,7 @@ get_maptrack_handle( struct grant_mapping *new_mt; unsigned int new_mt_limit, nr_frames; - spin_lock(&lgt->lock); + spin_lock(&lgt->maptrack_lock); while ( unlikely((handle = __get_maptrack_handle(lgt)) == -1) ) { @@ -289,12 +291,13 @@ get_maptrack_handle( nr_frames + 1); } - spin_unlock(&lgt->lock); + spin_unlock(&lgt->maptrack_lock); return handle; } -/* Number of grant table entries. Caller must hold d's grant table lock. */ +/* Number of grant table entries. Caller must hold d's grant table + read lock. */ static unsigned int nr_grant_entries(struct grant_table *gt) { ASSERT(gt->gt_version != 0); @@ -478,6 +481,12 @@ static int _set_status(unsigned gt_version, return _set_status_v2(domid, readonly, mapflag, shah, act, status); } +/* Count the number of mapped ro or rw entries tracked in the local + * grant table given a mfn from a remote domain. + * + * This function takes the maptrack lock from the local grant table and + * must be called with the remote grant table's write lock held. + */ static void mapcount( struct grant_table *lgt, struct domain *rd, unsigned long mfn, unsigned int *wrc, unsigned int *rdc) @@ -487,15 +496,19 @@ static void mapcount( *wrc = *rdc = 0; + spin_lock(&lgt->maptrack_lock); + for ( handle = 0; handle < lgt->maptrack_limit; handle++ ) { map = &maptrack_entry(lgt, handle); if ( !(map->flags & (GNTMAP_device_map|GNTMAP_host_map)) || map->domid != rd->domain_id ) continue; - if ( active_entry(rd->grant_table, map->ref).frame == mfn ) + if ( active_entry_unlocked(rd->grant_table, map->ref).frame == mfn ) (map->flags & GNTMAP_readonly) ? (*rdc)++ : (*wrc)++; } + + spin_unlock(&lgt->maptrack_lock); } /* @@ -517,7 +530,6 @@ __gnttab_map_grant_ref( struct page_info *pg = NULL; int rc = GNTST_okay; u32 old_pin; - u32 act_pin; unsigned int cache_flags; struct active_grant_entry *act = NULL; struct grant_mapping *mt; @@ -525,6 +537,7 @@ __gnttab_map_grant_ref( grant_entry_v2_t *sha2; grant_entry_header_t *shah; uint16_t *status; + bool_t write_lock_needed = 0; led = current; ld = led->domain; @@ -570,7 +583,14 @@ __gnttab_map_grant_ref( } rgt = rd->grant_table; - spin_lock(&rgt->lock); + + if ( !is_hvm_domain(ld) && need_iommu(ld) ) + write_lock_needed = 1; + + if ( write_lock_needed ) + write_lock(&rgt->lock); + else + read_lock(&rgt->lock); if ( rgt->gt_version == 0 ) PIN_FAIL(unlock_out, GNTST_general_error, @@ -580,7 +600,7 @@ __gnttab_map_grant_ref( if ( unlikely(op->ref >= nr_grant_entries(rgt))) PIN_FAIL(unlock_out, GNTST_bad_gntref, "Bad ref (%d).\n", op->ref); - act = &active_entry(rgt, op->ref); + act = active_entry_acquire(rgt, op->ref); shah = shared_entry_header(rgt, op->ref); if (rgt->gt_version == 1) { sha1 = &shared_entry_v1(rgt, op->ref); @@ -597,7 +617,7 @@ __gnttab_map_grant_ref( ((act->domid != ld->domain_id) || (act->pin & 0x80808080U) != 0 || (act->is_sub_page)) ) - PIN_FAIL(unlock_out, GNTST_general_error, + PIN_FAIL(act_release_out, GNTST_general_error, "Bad domain (%d != %d), or risk of counter overflow %08x, or subpage %d\n", act->domid, ld->domain_id, act->pin, act->is_sub_page); @@ -608,7 +628,7 @@ __gnttab_map_grant_ref( if ( (rc = _set_status(rgt->gt_version, ld->domain_id, op->flags & GNTMAP_readonly, 1, shah, act, status) ) != GNTST_okay ) - goto unlock_out; + goto act_release_out; if ( !act->pin ) { @@ -639,12 +659,9 @@ __gnttab_map_grant_ref( GNTPIN_hstr_inc : GNTPIN_hstw_inc; frame = act->frame; - act_pin = act->pin; cache_flags = (shah->flags & (GTF_PAT | GTF_PWT | GTF_PCD) ); - spin_unlock(&rgt->lock); - /* pg may be set, with a refcount included, from __get_paged_frame */ if ( !pg ) { @@ -719,8 +736,6 @@ __gnttab_map_grant_ref( goto undo_out; } - double_gt_lock(lgt, rgt); - if ( !is_hvm_domain(ld) && need_iommu(ld) ) { unsigned int wrc, rdc; @@ -730,21 +745,20 @@ __gnttab_map_grant_ref( /* We're not translated, so we know that gmfns and mfns are the same things, so the IOMMU entry is always 1-to-1. */ mapcount(lgt, rd, frame, &wrc, &rdc); - if ( (act_pin & (GNTPIN_hstw_mask|GNTPIN_devw_mask)) && + if ( (act->pin & (GNTPIN_hstw_mask|GNTPIN_devw_mask)) && !(old_pin & (GNTPIN_hstw_mask|GNTPIN_devw_mask)) ) { if ( wrc == 0 ) err = iommu_map_page(ld, frame, frame, IOMMUF_readable|IOMMUF_writable); } - else if ( act_pin && !old_pin ) + else if ( act->pin && !old_pin ) { if ( (wrc + rdc) == 0 ) err = iommu_map_page(ld, frame, frame, IOMMUF_readable); } if ( err ) { - double_gt_unlock(lgt, rgt); rc = GNTST_general_error; goto undo_out; } @@ -757,7 +771,11 @@ __gnttab_map_grant_ref( mt->ref = op->ref; mt->flags = op->flags; - double_gt_unlock(lgt, rgt); + active_entry_release(act); + if ( write_lock_needed ) + write_unlock(&rgt->lock); + else + read_unlock(&rgt->lock); op->dev_bus_addr = (u64)frame << PAGE_SHIFT; op->handle = handle; @@ -780,10 +798,6 @@ __gnttab_map_grant_ref( put_page(pg); } - spin_lock(&rgt->lock); - - act = &active_entry(rgt, op->ref); - if ( op->flags & GNTMAP_device_map ) act->pin -= (op->flags & GNTMAP_readonly) ? GNTPIN_devr_inc : GNTPIN_devw_inc; @@ -799,8 +813,14 @@ __gnttab_map_grant_ref( if ( !act->pin ) gnttab_clear_flag(_GTF_reading, status); + act_release_out: + active_entry_release(act); + unlock_out: - spin_unlock(&rgt->lock); + if ( write_lock_needed ) + write_unlock(&rgt->lock); + else + read_unlock(&rgt->lock); op->status = rc; put_maptrack_handle(lgt, handle); rcu_unlock_domain(rd); @@ -836,33 +856,33 @@ __gnttab_unmap_common( struct grant_table *lgt, *rgt; struct active_grant_entry *act; s16 rc = 0; + bool_t write_lock_needed = 0; ld = current->domain; lgt = ld->grant_table; op->frame = (unsigned long)(op->dev_bus_addr >> PAGE_SHIFT); - spin_lock(&lgt->lock); + read_lock(&lgt->lock); if ( unlikely(op->handle >= lgt->maptrack_limit) ) { - spin_unlock(&lgt->lock); + read_unlock(&lgt->lock); gdprintk(XENLOG_INFO, "Bad handle (%d).\n", op->handle); op->status = GNTST_bad_handle; return; } + read_unlock(&lgt->lock); op->map = &maptrack_entry(lgt, op->handle); if ( unlikely(!op->map->flags) ) { - spin_unlock(&lgt->lock); gdprintk(XENLOG_INFO, "Zero flags for handle (%d).\n", op->handle); op->status = GNTST_bad_handle; return; } dom = op->map->domid; - spin_unlock(&lgt->lock); if ( unlikely((rd = rcu_lock_domain_by_id(dom)) == NULL) ) { @@ -883,7 +903,6 @@ __gnttab_unmap_common( TRACE_1D(TRC_MEM_PAGE_GRANT_UNMAP, dom); rgt = rd->grant_table; - double_gt_lock(lgt, rgt); op->flags = op->map->flags; if ( unlikely(!op->flags) || unlikely(op->map->domid != dom) ) @@ -894,7 +913,16 @@ __gnttab_unmap_common( } op->rd = rd; - act = &active_entry(rgt, op->map->ref); + + if ( !is_hvm_domain(ld) && need_iommu(ld) ) + write_lock_needed = 1; + + if ( write_lock_needed ) + write_lock(&rgt->lock); + else + read_lock(&rgt->lock); + + act = active_entry_acquire(rgt, op->map->ref); if ( op->frame == 0 ) { @@ -903,7 +931,7 @@ __gnttab_unmap_common( else { if ( unlikely(op->frame != act->frame) ) - PIN_FAIL(unmap_out, GNTST_general_error, + PIN_FAIL(act_release_out, GNTST_general_error, "Bad frame number doesn't match gntref. (%lx != %lx)\n", op->frame, act->frame); if ( op->flags & GNTMAP_device_map ) @@ -922,7 +950,7 @@ __gnttab_unmap_common( if ( (rc = replace_grant_host_mapping(op->host_addr, op->frame, op->new_addr, op->flags)) < 0 ) - goto unmap_out; + goto act_release_out; ASSERT(act->pin & (GNTPIN_hstw_mask | GNTPIN_hstr_mask)); op->map->flags &= ~GNTMAP_host_map; @@ -945,7 +973,7 @@ __gnttab_unmap_common( if ( err ) { rc = GNTST_general_error; - goto unmap_out; + goto act_release_out; } } @@ -953,8 +981,15 @@ __gnttab_unmap_common( if ( !(op->flags & GNTMAP_readonly) ) gnttab_mark_dirty(rd, op->frame); + act_release_out: + active_entry_release(act); + + if ( write_lock_needed ) + write_unlock(&rgt->lock); + else + read_unlock(&rgt->lock); + unmap_out: - double_gt_unlock(lgt, rgt); op->status = rc; rcu_unlock_domain(rd); } @@ -984,12 +1019,12 @@ __gnttab_unmap_common_complete(struct gnttab_unmap_common *op) rcu_lock_domain(rd); rgt = rd->grant_table; - spin_lock(&rgt->lock); + read_lock(&rgt->lock); if ( rgt->gt_version == 0 ) goto unmap_out; - act = &active_entry(rgt, op->map->ref); + act = active_entry_acquire(rgt, op->map->ref); sha = shared_entry_header(rgt, op->map->ref); if ( rgt->gt_version == 1 ) @@ -1003,7 +1038,7 @@ __gnttab_unmap_common_complete(struct gnttab_unmap_common *op) * Suggests that __gntab_unmap_common failed early and so * nothing further to do */ - goto unmap_out; + goto act_release_out; } pg = mfn_to_page(op->frame); @@ -1027,7 +1062,7 @@ __gnttab_unmap_common_complete(struct gnttab_unmap_common *op) * Suggests that __gntab_unmap_common failed in * replace_grant_host_mapping() so nothing further to do */ - goto unmap_out; + goto act_release_out; } if ( !is_iomem_page(op->frame) ) @@ -1048,8 +1083,11 @@ __gnttab_unmap_common_complete(struct gnttab_unmap_common *op) if ( act->pin == 0 ) gnttab_clear_flag(_GTF_reading, status); + act_release_out: + active_entry_release(act); + unmap_out: - spin_unlock(&rgt->lock); + read_unlock(&rgt->lock); if ( put_handle ) { op->map->flags = 0; @@ -1235,13 +1273,16 @@ gnttab_unpopulate_status_frames(struct domain *d, struct grant_table *gt) gt->nr_status_frames = 0; } +/* Grow the grant table. The caller must hold the grant table's + * write lock before calling this function. + */ int gnttab_grow_table(struct domain *d, unsigned int req_nr_frames) { - /* d's grant table lock must be held by the caller */ + /* d's grant table write lock must be held by the caller */ struct grant_table *gt = d->grant_table; - unsigned int i; + unsigned int i, j; ASSERT(req_nr_frames <= max_nr_grant_frames); @@ -1256,6 +1297,10 @@ gnttab_grow_table(struct domain *d, unsigned int req_nr_frames) if ( (gt->active[i] = alloc_xenheap_page()) == NULL ) goto active_alloc_failed; clear_page(gt->active[i]); + for ( j = 0; j < ACGNT_PER_PAGE; j++ ) + { + spin_lock_init(>->active[i][j].lock); + } } /* Shared */ @@ -1343,7 +1388,7 @@ gnttab_setup_table( } gt = d->grant_table; - spin_lock(>->lock); + write_lock(>->lock); if ( gt->gt_version == 0 ) gt->gt_version = 1; @@ -1371,7 +1416,7 @@ gnttab_setup_table( } out3: - spin_unlock(>->lock); + write_unlock(>->lock); out2: rcu_unlock_domain(d); out1: @@ -1413,13 +1458,13 @@ gnttab_query_size( goto query_out_unlock; } - spin_lock(&d->grant_table->lock); + read_lock(&d->grant_table->lock); op.nr_frames = nr_grant_frames(d->grant_table); op.max_nr_frames = max_nr_grant_frames; op.status = GNTST_okay; - spin_unlock(&d->grant_table->lock); + read_unlock(&d->grant_table->lock); query_out_unlock: @@ -1445,7 +1490,7 @@ gnttab_prepare_for_transfer( union grant_combo scombo, prev_scombo, new_scombo; int retries = 0; - spin_lock(&rgt->lock); + read_lock(&rgt->lock); if ( rgt->gt_version == 0 ) { @@ -1496,11 +1541,11 @@ gnttab_prepare_for_transfer( scombo = prev_scombo; } - spin_unlock(&rgt->lock); + read_unlock(&rgt->lock); return 1; fail: - spin_unlock(&rgt->lock); + read_unlock(&rgt->lock); return 0; } @@ -1692,7 +1737,7 @@ gnttab_transfer( TRACE_1D(TRC_MEM_PAGE_GRANT_TRANSFER, e->domain_id); /* Tell the guest about its new page frame. */ - spin_lock(&e->grant_table->lock); + read_lock(&e->grant_table->lock); if ( e->grant_table->gt_version == 1 ) { @@ -1710,7 +1755,7 @@ gnttab_transfer( shared_entry_header(e->grant_table, gop.ref)->flags |= GTF_transfer_completed; - spin_unlock(&e->grant_table->lock); + read_unlock(&e->grant_table->lock); rcu_unlock_domain(e); @@ -1748,9 +1793,9 @@ __release_grant_for_copy( released_read = 0; released_write = 0; - spin_lock(&rgt->lock); + read_lock(&rgt->lock); - act = &active_entry(rgt, gref); + act = active_entry_acquire(rgt, gref); sha = shared_entry_header(rgt, gref); r_frame = act->frame; @@ -1789,7 +1834,8 @@ __release_grant_for_copy( released_read = 1; } - spin_unlock(&rgt->lock); + active_entry_release(act); + read_unlock(&rgt->lock); if ( td != rd ) { @@ -1847,7 +1893,7 @@ __acquire_grant_for_copy( *page = NULL; - spin_lock(&rgt->lock); + read_lock(&rgt->lock); if ( rgt->gt_version == 0 ) PIN_FAIL(unlock_out, GNTST_general_error, @@ -1857,7 +1903,7 @@ __acquire_grant_for_copy( PIN_FAIL(unlock_out, GNTST_bad_gntref, "Bad grant reference %ld\n", gref); - act = &active_entry(rgt, gref); + act = active_entry_acquire(rgt, gref); shah = shared_entry_header(rgt, gref); if ( rgt->gt_version == 1 ) { @@ -1885,7 +1931,7 @@ __acquire_grant_for_copy( if ( (rc = _set_status(rgt->gt_version, ldom, readonly, 0, shah, act, status) ) != GNTST_okay ) - goto unlock_out; + goto act_release_out; td = rd; trans_gref = gref; @@ -1916,17 +1962,25 @@ __acquire_grant_for_copy( PIN_FAIL(unlock_out_clear, GNTST_general_error, "transitive grant referenced bad domain %d\n", trans_domid); - spin_unlock(&rgt->lock); + + /* __acquire_grant_for_copy() could take the read lock on + the remote grant table (if rd == td), so we have to + drop the lock here and reacquire */ + active_entry_release(act); + read_unlock(&rgt->lock); rc = __acquire_grant_for_copy(td, trans_gref, rd->domain_id, readonly, &grant_frame, page, &trans_page_off, &trans_length, 0); - spin_lock(&rgt->lock); + read_lock(&rgt->lock); + act = active_entry_acquire(rgt, gref); + if ( rc != GNTST_okay ) { __fixup_status_for_copy_pin(act, status); + active_entry_release(act); + read_unlock(&rgt->lock); rcu_unlock_domain(td); - spin_unlock(&rgt->lock); return rc; } @@ -1938,7 +1992,8 @@ __acquire_grant_for_copy( { __fixup_status_for_copy_pin(act, status); rcu_unlock_domain(td); - spin_unlock(&rgt->lock); + active_entry_release(act); + read_unlock(&rgt->lock); put_page(*page); return __acquire_grant_for_copy(rd, gref, ldom, readonly, frame, page, page_off, length, @@ -2006,7 +2061,8 @@ __acquire_grant_for_copy( *length = act->length; *frame = act->frame; - spin_unlock(&rgt->lock); + active_entry_release(act); + read_unlock(&rgt->lock); return rc; unlock_out_clear: @@ -2017,8 +2073,11 @@ __acquire_grant_for_copy( if ( !act->pin ) gnttab_clear_flag(_GTF_reading, status); + act_release_out: + active_entry_release(act); + unlock_out: - spin_unlock(&rgt->lock); + read_unlock(&rgt->lock); return rc; } @@ -2192,7 +2251,7 @@ gnttab_set_version(XEN_GUEST_HANDLE_PARAM(gnttab_set_version_t) uop) if ( gt->gt_version == op.version ) goto out; - spin_lock(>->lock); + write_lock(>->lock); /* Make sure that the grant table isn't currently in use when we change the version number, except for the first 8 entries which are allowed to be in use (xenstore/xenconsole keeps them mapped). @@ -2201,7 +2260,7 @@ gnttab_set_version(XEN_GUEST_HANDLE_PARAM(gnttab_set_version_t) uop) { for ( i = GNTTAB_NR_RESERVED_ENTRIES; i < nr_grant_entries(gt); i++ ) { - act = &active_entry(gt, i); + act = &active_entry_unlocked(gt, i); if ( act->pin != 0 ) { gdprintk(XENLOG_WARNING, @@ -2278,7 +2337,7 @@ gnttab_set_version(XEN_GUEST_HANDLE_PARAM(gnttab_set_version_t) uop) gt->gt_version = op.version; out_unlock: - spin_unlock(>->lock); + write_unlock(>->lock); out: op.version = gt->gt_version; @@ -2334,7 +2393,7 @@ gnttab_get_status_frames(XEN_GUEST_HANDLE_PARAM(gnttab_get_status_frames_t) uop, op.status = GNTST_okay; - spin_lock(>->lock); + read_lock(>->lock); for ( i = 0; i < op.nr_frames; i++ ) { @@ -2343,7 +2402,7 @@ gnttab_get_status_frames(XEN_GUEST_HANDLE_PARAM(gnttab_get_status_frames_t) uop, op.status = GNTST_bad_virt_addr; } - spin_unlock(>->lock); + read_unlock(>->lock); out2: rcu_unlock_domain(d); out1: @@ -2389,10 +2448,11 @@ __gnttab_swap_grant_ref(grant_ref_t ref_a, grant_ref_t ref_b) { struct domain *d = rcu_lock_current_domain(); struct grant_table *gt = d->grant_table; - struct active_grant_entry *act; + struct active_grant_entry *act_a = NULL; + struct active_grant_entry *act_b = NULL; s16 rc = GNTST_okay; - spin_lock(>->lock); + read_lock(>->lock); /* Bounds check on the grant refs */ if ( unlikely(ref_a >= nr_grant_entries(d->grant_table))) @@ -2400,12 +2460,12 @@ __gnttab_swap_grant_ref(grant_ref_t ref_a, grant_ref_t ref_b) if ( unlikely(ref_b >= nr_grant_entries(d->grant_table))) PIN_FAIL(out, GNTST_bad_gntref, "Bad ref-b (%d).\n", ref_b); - act = &active_entry(gt, ref_a); - if ( act->pin ) + act_a = active_entry_acquire(gt, ref_a); + if ( act_a->pin ) PIN_FAIL(out, GNTST_eagain, "ref a %ld busy\n", (long)ref_a); - act = &active_entry(gt, ref_b); - if ( act->pin ) + act_b = active_entry_acquire(gt, ref_b); + if ( act_b->pin ) PIN_FAIL(out, GNTST_eagain, "ref b %ld busy\n", (long)ref_b); if ( gt->gt_version == 1 ) @@ -2432,8 +2492,11 @@ __gnttab_swap_grant_ref(grant_ref_t ref_a, grant_ref_t ref_b) } out: - spin_unlock(>->lock); - + if ( act_b != NULL ) + active_entry_release(act_b); + if ( act_a != NULL ) + active_entry_release(act_a); + read_unlock(>->lock); rcu_unlock_domain(d); return rc; @@ -2452,7 +2515,18 @@ gnttab_swap_grant_ref(XEN_GUEST_HANDLE_PARAM(gnttab_swap_grant_ref_t) uop, return i; if ( unlikely(__copy_from_guest(&op, uop, 1)) ) return -EFAULT; - op.status = __gnttab_swap_grant_ref(op.ref_a, op.ref_b); + if ( unlikely(op.ref_a == op.ref_b) ) + { + /* noop, so avoid acquiring the same active entry + * twice in __gnttab_swap_grant_ref(), which would + * case a deadlock. + */ + op.status = GNTST_okay; + } + else + { + op.status = __gnttab_swap_grant_ref(op.ref_a, op.ref_b); + } if ( unlikely(__copy_field_to_guest(uop, &op, status)) ) return -EFAULT; guest_handle_add_offset(uop, 1); @@ -2614,13 +2688,14 @@ grant_table_create( struct domain *d) { struct grant_table *t; - int i; + int i, j; if ( (t = xzalloc(struct grant_table)) == NULL ) goto no_mem_0; /* Simple stuff. */ - spin_lock_init(&t->lock); + rwlock_init(&t->lock); + spin_lock_init(&t->maptrack_lock); t->nr_grant_frames = INITIAL_NR_GRANT_FRAMES; /* Active grant table. */ @@ -2633,6 +2708,10 @@ grant_table_create( if ( (t->active[i] = alloc_xenheap_page()) == NULL ) goto no_mem_2; clear_page(t->active[i]); + for ( j = 0; j < ACGNT_PER_PAGE; j++ ) + { + spin_lock_init(&t->active[i][j].lock); + } } /* Tracking of mapped foreign frames table */ @@ -2704,6 +2783,8 @@ gnttab_release_mappings( uint16_t *status; struct page_info *pg; + /* we don't take the table write lock because the domain + is dying */ BUG_ON(!d->is_dying); for ( handle = 0; handle < gt->maptrack_limit; handle++ ) @@ -2727,9 +2808,9 @@ gnttab_release_mappings( } rgt = rd->grant_table; - spin_lock(&rgt->lock); + read_lock(&rgt->lock); - act = &active_entry(rgt, ref); + act = active_entry_acquire(rgt, ref); sha = shared_entry_header(rgt, ref); if (rgt->gt_version == 1) status = &sha->flags; @@ -2787,7 +2868,8 @@ gnttab_release_mappings( if ( act->pin == 0 ) gnttab_clear_flag(_GTF_reading, status); - spin_unlock(&rgt->lock); + active_entry_release(act); + read_unlock(&rgt->lock); rcu_unlock_domain(rd); @@ -2805,7 +2887,12 @@ grant_table_destroy( if ( t == NULL ) return; - + + /* we don't take the table write lock because the + domain is dying. + */ + BUG_ON(!d->is_dying); + for ( i = 0; i < nr_grant_frames(t); i++ ) free_xenheap_page(t->shared_raw[i]); xfree(t->shared_raw); @@ -2835,7 +2922,7 @@ static void gnttab_usage_print(struct domain *rd) printk(" -------- active -------- -------- shared --------\n"); printk("[ref] localdom mfn pin localdom gmfn flags\n"); - spin_lock(>->lock); + write_lock(>->lock); if ( gt->gt_version == 0 ) goto out; @@ -2849,7 +2936,7 @@ static void gnttab_usage_print(struct domain *rd) uint16_t status; uint64_t frame; - act = &active_entry(gt, ref); + act = &active_entry_unlocked(gt, ref); if ( !act->pin ) continue; @@ -2884,7 +2971,7 @@ static void gnttab_usage_print(struct domain *rd) } out: - spin_unlock(>->lock); + write_unlock(>->lock); if ( first ) printk("grant-table for remote domain:%5d ... " diff --git a/xen/include/xen/grant_table.h b/xen/include/xen/grant_table.h index 5941191..bb2828b 100644 --- a/xen/include/xen/grant_table.h +++ b/xen/include/xen/grant_table.h @@ -84,8 +84,11 @@ struct grant_table { struct grant_mapping **maptrack; unsigned int maptrack_head; unsigned int maptrack_limit; - /* Lock protecting updates to active and shared grant tables. */ - spinlock_t lock; + /* Lock protecting the maptrack page list, head, and limit */ + spinlock_t maptrack_lock; + /* Lock protecting updates to grant table state (version, active + entry list, etc.) */ + rwlock_t lock; /* The defined versions are 1 and 2. Set to 0 if we don't know what version to use yet. */ unsigned gt_version; @@ -103,7 +106,7 @@ gnttab_release_mappings( struct domain *d); /* Increase the size of a domain's grant table. - * Caller must hold d's grant table lock. + * Caller must hold d's grant table write lock. */ int gnttab_grow_table(struct domain *d, unsigned int req_nr_frames); -- 1.7.9.5 ^ permalink raw reply related [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 2:03 ` [RFC PATCH 2/2] gnttab: refactor locking for better scalability Matt Wilson @ 2013-11-12 5:37 ` Keir Fraser 2013-11-12 7:18 ` Matt Wilson 2013-11-12 9:26 ` Jan Beulich 1 sibling, 1 reply; 22+ messages in thread From: Keir Fraser @ 2013-11-12 5:37 UTC (permalink / raw) To: Matt Wilson, xen-devel Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Jan Beulich, Matt Wilson, Roger Pau Monné On 12/11/2013 02:03, "Matt Wilson" <msw@linux.com> wrote: > + Locking > + ~~~~~~~ > + Xen uses several locks to serialize access to the internal grant table > state. > + > + grant_table->lock : rwlock used to prevent readers from accessing > + inconsistent grant table state such as current > + version, partially initialized active table > pages, > + etc. > + grant_table->maptrack_lock : spinlock used to protect the maptrack state > + active_grant_entry->lock : spinlock used to serialize modifications to > + active entries > + > + The primary lock for the grant table is a read/write spinlock. All > + functions that access members of struct grant_table must acquire a > + read lock around critical sections. Any modification to the members > + of struct grant_table (e.g., nr_status_frames, nr_grant_frames, > + active frames, etc.) must only be made if the write lock is > + held. These elements are read-mostly, and read critical sections can > + be large, which makes a rwlock a good choice. Is there any concern about writer starvation here? I know our spinlocks aren't 'fair' but our rwlocks are guaranteed to starve out writers if there is a steady continuous stream of readers. Perhaps we should write-bias our rwlock, or at least make that an option. We could get fancier but would probably hurt performance. Looks like great work however! -- Keir ^ permalink raw reply [flat|nested] 22+ messages in thread
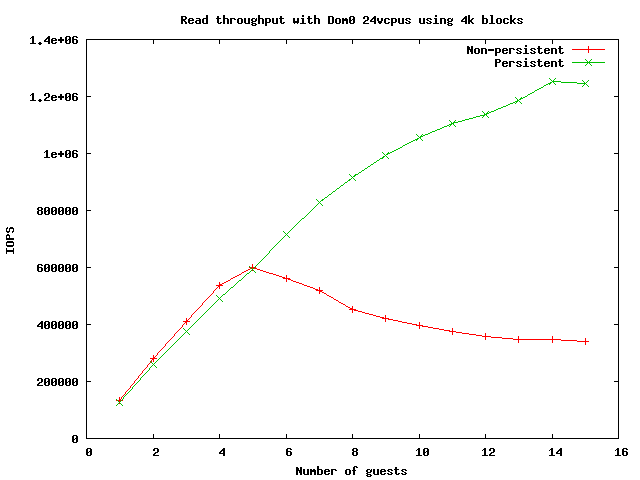
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 5:37 ` Keir Fraser @ 2013-11-12 7:18 ` Matt Wilson 2013-11-12 8:07 ` Keir Fraser 2013-11-12 14:52 ` Konrad Rzeszutek Wilk 0 siblings, 2 replies; 22+ messages in thread From: Matt Wilson @ 2013-11-12 7:18 UTC (permalink / raw) To: Keir Fraser Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Jan Beulich, xen-devel, Matt Wilson, Roger Pau Monné On Tue, Nov 12, 2013 at 05:37:08AM +0000, Keir Fraser wrote: > On 12/11/2013 02:03, "Matt Wilson" <msw@linux.com> wrote: > > > + Locking > > + ~~~~~~~ > > + Xen uses several locks to serialize access to the internal grant table > > state. > > + > > + grant_table->lock : rwlock used to prevent readers from accessing > > + inconsistent grant table state such as current > > + version, partially initialized active table > > pages, > > + etc. > > + grant_table->maptrack_lock : spinlock used to protect the maptrack state > > + active_grant_entry->lock : spinlock used to serialize modifications to > > + active entries > > + > > + The primary lock for the grant table is a read/write spinlock. All > > + functions that access members of struct grant_table must acquire a > > + read lock around critical sections. Any modification to the members > > + of struct grant_table (e.g., nr_status_frames, nr_grant_frames, > > + active frames, etc.) must only be made if the write lock is > > + held. These elements are read-mostly, and read critical sections can > > + be large, which makes a rwlock a good choice. > > Is there any concern about writer starvation here? I know our spinlocks > aren't 'fair' but our rwlocks are guaranteed to starve out writers if there > is a steady continuous stream of readers. Perhaps we should write-bias our > rwlock, or at least make that an option. We could get fancier but would > probably hurt performance. Yes, I'm a little concerned about writer starvation. But so far even in the presence of very frequent readers it seems like the infrequent writers are able to get the lock when they need to. However, I've not tested the iommu=strict path yet. I'm thinking that in that case there's just going to be frequent writers, so there's less risk of readers starving writers. For what it's worth, when mapcount() gets in the picture with persistent grants, I'd expect to see some pretty significant performance degradation for map/unmap operations. This was also observed in [1] under different circumstances. But right now I'm more curious about cache line bouncing between all the readers. I've not done any study of inter-arrival times for typical workloads (much less some more extreme workloads like we've been testing), but lock profiling of grant table operations when a spinlock was used showed some pretty long hold times, which should translate fairly well to decent rwlock performance. I'm by no means an expert in this area so I'm eager to hear the thoughts of others. I should also mention that some of the improvement I mentioned from 3,000 MB/s to 3,600 MB/s was due to avoiding the m2p override spinlock in dom0. > Looks like great work however! Thanks! I'm definitely interested to see some others' experience with these changes. I think that the double_gt_lock() caused a fair bit of contention on the local domain's grant table lock, which explains some of the poor performance with large numbers of vCPUs as seen in [2]. --msw [1] http://scholarship.rice.edu/bitstream/handle/1911/71683/RAM-THESIS.pdf [2] http://xenbits.xen.org/people/royger/persistent_grants/persistent_read24vcpus.png ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 7:18 ` Matt Wilson @ 2013-11-12 8:07 ` Keir Fraser 2013-11-12 9:18 ` Jan Beulich 2013-11-12 19:06 ` Matt Wilson 2013-11-12 14:52 ` Konrad Rzeszutek Wilk 1 sibling, 2 replies; 22+ messages in thread From: Keir Fraser @ 2013-11-12 8:07 UTC (permalink / raw) To: Matt Wilson Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Jan Beulich, xen-devel, Matt Wilson, Roger Pau Monné On 12/11/2013 07:18, "Matt Wilson" <msw@linux.com> wrote: >> Is there any concern about writer starvation here? I know our spinlocks >> aren't 'fair' but our rwlocks are guaranteed to starve out writers if there >> is a steady continuous stream of readers. Perhaps we should write-bias our >> rwlock, or at least make that an option. We could get fancier but would >> probably hurt performance. > > Yes, I'm a little concerned about writer starvation. But so far even > in the presence of very frequent readers it seems like the infrequent > writers are able to get the lock when they need to. However, I've not > tested the iommu=strict path yet. I'm thinking that in that case > there's just going to be frequent writers, so there's less risk of > readers starving writers. For what it's worth, when mapcount() gets in > the picture with persistent grants, I'd expect to see some pretty > significant performance degradation for map/unmap operations. This was > also observed in [1] under different circumstances. The average case isn't the only concern here, but also the worst case, which could maybe tie up a CPU for unbounded time. Could a malicious guest set up such a workload? I'm just thinking we don't want to end up with a DoS XSA on this down the line. :) > But right now I'm more curious about cache line bouncing between all > the readers. I've not done any study of inter-arrival times for > typical workloads (much less some more extreme workloads like we've > been testing), but lock profiling of grant table operations when a > spinlock was used showed some pretty long hold times, which should > translate fairly well to decent rwlock performance. I'm by no means an > expert in this area so I'm eager to hear the thoughts of others. In the read-heavy case the only improvement would be with the old Linux-style biglock (spinlock per CPU; writers must take all spinlocks), or working out a lock-free scheme for readers (perhaps making use of RCU). -- Keir > I should also mention that some of the improvement I mentioned from > 3,000 MB/s to 3,600 MB/s was due to avoiding the m2p override spinlock > in dom0. ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 8:07 ` Keir Fraser @ 2013-11-12 9:18 ` Jan Beulich 2013-11-12 13:42 ` Keir Fraser 2013-11-12 19:06 ` Matt Wilson 1 sibling, 1 reply; 22+ messages in thread From: Jan Beulich @ 2013-11-12 9:18 UTC (permalink / raw) To: Keir Fraser, Matt Wilson Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, xen-devel, roger.pau >>> On 12.11.13 at 09:07, Keir Fraser <keir.xen@gmail.com> wrote: > On 12/11/2013 07:18, "Matt Wilson" <msw@linux.com> wrote: > >>> Is there any concern about writer starvation here? I know our spinlocks >>> aren't 'fair' but our rwlocks are guaranteed to starve out writers if there >>> is a steady continuous stream of readers. Perhaps we should write-bias our >>> rwlock, or at least make that an option. We could get fancier but would >>> probably hurt performance. >> >> Yes, I'm a little concerned about writer starvation. But so far even >> in the presence of very frequent readers it seems like the infrequent >> writers are able to get the lock when they need to. However, I've not >> tested the iommu=strict path yet. I'm thinking that in that case >> there's just going to be frequent writers, so there's less risk of >> readers starving writers. For what it's worth, when mapcount() gets in >> the picture with persistent grants, I'd expect to see some pretty >> significant performance degradation for map/unmap operations. This was >> also observed in [1] under different circumstances. > > The average case isn't the only concern here, but also the worst case, which > could maybe tie up a CPU for unbounded time. Could a malicious guest set up > such a workload? I'm just thinking we don't want to end up with a DoS XSA on > this down the line. :) And indeed I think we should be making our rwlocks fair for writers before pushing in the change here; I've been meaning to get to this for a while, but other stuff continues to require attention. I'm also of the opinion that we should switch to ticket spinlocks. But of course, fairness for writers means that performance may drop again on the read paths, unless the write lock use is strictly limited to code paths not (normally) involved in I/O. Jan ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 9:18 ` Jan Beulich @ 2013-11-12 13:42 ` Keir Fraser 2013-11-12 13:58 ` Keir Fraser 0 siblings, 1 reply; 22+ messages in thread From: Keir Fraser @ 2013-11-12 13:42 UTC (permalink / raw) To: Jan Beulich, Matt Wilson Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, xen-devel, roger.pau On 12/11/2013 09:18, "Jan Beulich" <JBeulich@suse.com> wrote: >>>> On 12.11.13 at 09:07, Keir Fraser <keir.xen@gmail.com> wrote: >> On 12/11/2013 07:18, "Matt Wilson" <msw@linux.com> wrote: >> >>> Yes, I'm a little concerned about writer starvation. But so far even >>> in the presence of very frequent readers it seems like the infrequent >>> writers are able to get the lock when they need to. However, I've not >>> tested the iommu=strict path yet. I'm thinking that in that case >>> there's just going to be frequent writers, so there's less risk of >>> readers starving writers. For what it's worth, when mapcount() gets in >>> the picture with persistent grants, I'd expect to see some pretty >>> significant performance degradation for map/unmap operations. This was >>> also observed in [1] under different circumstances. >> >> The average case isn't the only concern here, but also the worst case, which >> could maybe tie up a CPU for unbounded time. Could a malicious guest set up >> such a workload? I'm just thinking we don't want to end up with a DoS XSA on >> this down the line. :) > > And indeed I think we should be making our rwlocks fair for writers > before pushing in the change here; I've been meaning to get to this > for a while, but other stuff continues to require attention. I'm also > of the opinion that we should switch to ticket spinlocks. Would queuing spinlocks (e.g. MCS locks) be even more preferable? Two atomic ops (cmpxchg) per critical region in the uncontended case. Each CPU spins on its own location so there's no cacheline carnage in the highly contended case (a problem with simple ticket spinlocks). And it builds on cmpxchg so the spinlock implementation has no arch-specific component (apart from cmpxchg, which we already have). I have a queue-based rwlock design too, does require a spinlock lock/unlock per rwlock op though (i.e., 4 atomic ops per critical region in the uncontended case). > But of course, fairness for writers means that performance may > drop again on the read paths, unless the write lock use is strictly > limited to code paths not (normally) involved in I/O. Yes indeed. Hence depending on other users of rwlock, just letting a writer set its flag and wait for in-flight readers to drain might be sufficient for now. -- Keir > Jan > ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 13:42 ` Keir Fraser @ 2013-11-12 13:58 ` Keir Fraser 2013-11-12 14:11 ` Jan Beulich 0 siblings, 1 reply; 22+ messages in thread From: Keir Fraser @ 2013-11-12 13:58 UTC (permalink / raw) To: Jan Beulich, Matt Wilson Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, xen-devel, roger.pau On 12/11/2013 13:42, "Keir Fraser" <keir.xen@gmail.com> wrote: >> And indeed I think we should be making our rwlocks fair for writers >> before pushing in the change here; I've been meaning to get to this >> for a while, but other stuff continues to require attention. I'm also >> of the opinion that we should switch to ticket spinlocks. > > Would queuing spinlocks (e.g. MCS locks) be even more preferable? Two atomic > ops (cmpxchg) per critical region in the uncontended case. Each CPU spins on > its own location so there's no cacheline carnage in the highly contended > case (a problem with simple ticket spinlocks). And it builds on cmpxchg so > the spinlock implementation has no arch-specific component (apart from > cmpxchg, which we already have). > > I have a queue-based rwlock design too, does require a spinlock lock/unlock > per rwlock op though (i.e., 4 atomic ops per critical region in the > uncontended case). Actually MCS has a multi-reader extension we could use, or there is another alternative by Krieger et al. My own design was intended to build on pthread primitives and wouldn't be as good as the existing solutions in the literature for purely spinning waiters. -- Keir ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 13:58 ` Keir Fraser @ 2013-11-12 14:11 ` Jan Beulich 2013-11-12 14:24 ` Keir Fraser 0 siblings, 1 reply; 22+ messages in thread From: Jan Beulich @ 2013-11-12 14:11 UTC (permalink / raw) To: Keir Fraser Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, Matt Wilson, xen-devel, roger.pau >>> On 12.11.13 at 14:58, Keir Fraser <keir.xen@gmail.com> wrote: > On 12/11/2013 13:42, "Keir Fraser" <keir.xen@gmail.com> wrote: > >>> And indeed I think we should be making our rwlocks fair for writers >>> before pushing in the change here; I've been meaning to get to this >>> for a while, but other stuff continues to require attention. I'm also >>> of the opinion that we should switch to ticket spinlocks. >> >> Would queuing spinlocks (e.g. MCS locks) be even more preferable? Two atomic >> ops (cmpxchg) per critical region in the uncontended case. Each CPU spins on >> its own location so there's no cacheline carnage in the highly contended >> case (a problem with simple ticket spinlocks). And it builds on cmpxchg so >> the spinlock implementation has no arch-specific component (apart from >> cmpxchg, which we already have). >> >> I have a queue-based rwlock design too, does require a spinlock lock/unlock >> per rwlock op though (i.e., 4 atomic ops per critical region in the >> uncontended case). > > Actually MCS has a multi-reader extension we could use, or there is another > alternative by Krieger et al. My own design was intended to build on pthread > primitives and wouldn't be as good as the existing solutions in the > literature for purely spinning waiters. Sounds nice - are you going to spend time on implementing this then? Jan ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 14:11 ` Jan Beulich @ 2013-11-12 14:24 ` Keir Fraser 2013-11-12 15:09 ` Felipe Franciosi 2014-06-20 20:54 ` Konrad Rzeszutek Wilk 0 siblings, 2 replies; 22+ messages in thread From: Keir Fraser @ 2013-11-12 14:24 UTC (permalink / raw) To: Jan Beulich Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, Matt Wilson, xen-devel, roger.pau On 12/11/2013 14:11, "Jan Beulich" <JBeulich@suse.com> wrote: >>>> On 12.11.13 at 14:58, Keir Fraser <keir.xen@gmail.com> wrote: >> On 12/11/2013 13:42, "Keir Fraser" <keir.xen@gmail.com> wrote: >> >>>> And indeed I think we should be making our rwlocks fair for writers >>>> before pushing in the change here; I've been meaning to get to this >>>> for a while, but other stuff continues to require attention. I'm also >>>> of the opinion that we should switch to ticket spinlocks. >>> >>> Would queuing spinlocks (e.g. MCS locks) be even more preferable? Two atomic >>> ops (cmpxchg) per critical region in the uncontended case. Each CPU spins on >>> its own location so there's no cacheline carnage in the highly contended >>> case (a problem with simple ticket spinlocks). And it builds on cmpxchg so >>> the spinlock implementation has no arch-specific component (apart from >>> cmpxchg, which we already have). >>> >>> I have a queue-based rwlock design too, does require a spinlock lock/unlock >>> per rwlock op though (i.e., 4 atomic ops per critical region in the >>> uncontended case). >> >> Actually MCS has a multi-reader extension we could use, or there is another >> alternative by Krieger et al. My own design was intended to build on pthread >> primitives and wouldn't be as good as the existing solutions in the >> literature for purely spinning waiters. > > Sounds nice - are you going to spend time on implementing this then? Yes I'll look into it. Amazon's benchmarking of grant-table throughput will be a good testbed for performance of a different lock implementation. -- Keir > Jan > ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 14:24 ` Keir Fraser @ 2013-11-12 15:09 ` Felipe Franciosi 2014-06-20 20:54 ` Konrad Rzeszutek Wilk 1 sibling, 0 replies; 22+ messages in thread From: Felipe Franciosi @ 2013-11-12 15:09 UTC (permalink / raw) To: 'Keir Fraser', Jan Beulich Cc: Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, Matt Wilson, xen-devel@lists.xenproject.org, Roger Pau Monne We are very excited to see progress in this area following up from the discussions we had at the BoF. I will be happy to benchmark these patches in our environment as well. Thanks, Felipe -----Original Message----- From: Keir Fraser [mailto:keir.xen@gmail.com] Sent: 12 November 2013 14:25 To: Jan Beulich Cc: Anthony Liguori; Matt Wilson; Andrew Cooper; David Vrabel; Felipe Franciosi; Roger Pau Monne; Matt Wilson; xen-devel@lists.xenproject.org; Konrad Rzeszutek Wilk Subject: Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability <...> > Sounds nice - are you going to spend time on implementing this then? Yes I'll look into it. Amazon's benchmarking of grant-table throughput will be a good testbed for performance of a different lock implementation. -- Keir > Jan > ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 14:24 ` Keir Fraser 2013-11-12 15:09 ` Felipe Franciosi @ 2014-06-20 20:54 ` Konrad Rzeszutek Wilk 2014-06-20 21:18 ` Matt Wilson 1 sibling, 1 reply; 22+ messages in thread From: Konrad Rzeszutek Wilk @ 2014-06-20 20:54 UTC (permalink / raw) To: Keir Fraser Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, Jan Beulich, David Vrabel, Matt Wilson, Matt Wilson, xen-devel, roger.pau On Tue, Nov 12, 2013 at 02:24:50PM +0000, Keir Fraser wrote: > On 12/11/2013 14:11, "Jan Beulich" <JBeulich@suse.com> wrote: > > >>>> On 12.11.13 at 14:58, Keir Fraser <keir.xen@gmail.com> wrote: > >> On 12/11/2013 13:42, "Keir Fraser" <keir.xen@gmail.com> wrote: > >> > >>>> And indeed I think we should be making our rwlocks fair for writers > >>>> before pushing in the change here; I've been meaning to get to this > >>>> for a while, but other stuff continues to require attention. I'm also > >>>> of the opinion that we should switch to ticket spinlocks. > >>> > >>> Would queuing spinlocks (e.g. MCS locks) be even more preferable? Two atomic > >>> ops (cmpxchg) per critical region in the uncontended case. Each CPU spins on > >>> its own location so there's no cacheline carnage in the highly contended > >>> case (a problem with simple ticket spinlocks). And it builds on cmpxchg so > >>> the spinlock implementation has no arch-specific component (apart from > >>> cmpxchg, which we already have). > >>> > >>> I have a queue-based rwlock design too, does require a spinlock lock/unlock > >>> per rwlock op though (i.e., 4 atomic ops per critical region in the > >>> uncontended case). > >> > >> Actually MCS has a multi-reader extension we could use, or there is another > >> alternative by Krieger et al. My own design was intended to build on pthread > >> primitives and wouldn't be as good as the existing solutions in the > >> literature for purely spinning waiters. > > > > Sounds nice - are you going to spend time on implementing this then? > > Yes I'll look into it. Amazon's benchmarking of grant-table throughput will > be a good testbed for performance of a different lock implementation. ping? > > -- Keir > > > Jan > > > > > > _______________________________________________ > Xen-devel mailing list > Xen-devel@lists.xen.org > http://lists.xen.org/xen-devel ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2014-06-20 20:54 ` Konrad Rzeszutek Wilk @ 2014-06-20 21:18 ` Matt Wilson 0 siblings, 0 replies; 22+ messages in thread From: Matt Wilson @ 2014-06-20 21:18 UTC (permalink / raw) To: Konrad Rzeszutek Wilk Cc: Felipe Franciosi, Jan Beulich, Andrew Cooper, Keir Fraser, David Vrabel, Anthony Liguori, xen-devel, Matt Wilson, roger.pau On Fri, Jun 20, 2014 at 04:54:15PM -0400, Konrad Rzeszutek Wilk wrote: > On Tue, Nov 12, 2013 at 02:24:50PM +0000, Keir Fraser wrote: > > On 12/11/2013 14:11, "Jan Beulich" <JBeulich@suse.com> wrote: > > > > >>>> On 12.11.13 at 14:58, Keir Fraser <keir.xen@gmail.com> wrote: > > >> On 12/11/2013 13:42, "Keir Fraser" <keir.xen@gmail.com> wrote: > > >> > > >>>> And indeed I think we should be making our rwlocks fair for writers > > >>>> before pushing in the change here; I've been meaning to get to this > > >>>> for a while, but other stuff continues to require attention. I'm also > > >>>> of the opinion that we should switch to ticket spinlocks. > > >>> > > >>> Would queuing spinlocks (e.g. MCS locks) be even more preferable? Two atomic > > >>> ops (cmpxchg) per critical region in the uncontended case. Each CPU spins on > > >>> its own location so there's no cacheline carnage in the highly contended > > >>> case (a problem with simple ticket spinlocks). And it builds on cmpxchg so > > >>> the spinlock implementation has no arch-specific component (apart from > > >>> cmpxchg, which we already have). > > >>> > > >>> I have a queue-based rwlock design too, does require a spinlock lock/unlock > > >>> per rwlock op though (i.e., 4 atomic ops per critical region in the > > >>> uncontended case). > > >> > > >> Actually MCS has a multi-reader extension we could use, or there is another > > >> alternative by Krieger et al. My own design was intended to build on pthread > > >> primitives and wouldn't be as good as the existing solutions in the > > >> literature for purely spinning waiters. > > > > > > Sounds nice - are you going to spend time on implementing this then? > > > > Yes I'll look into it. Amazon's benchmarking of grant-table throughput will > > be a good testbed for performance of a different lock implementation. > > ping? Ooph. Sorry, I've not had any time to work on this since posting last year. Has there been any other discussion about a new locking primitive? Konrad, are you looking for someone to rebase and break up the proposed patch as is? --msw ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 8:07 ` Keir Fraser 2013-11-12 9:18 ` Jan Beulich @ 2013-11-12 19:06 ` Matt Wilson 1 sibling, 0 replies; 22+ messages in thread From: Matt Wilson @ 2013-11-12 19:06 UTC (permalink / raw) To: Keir Fraser Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Jan Beulich, xen-devel, Matt Wilson, Roger Pau Monné On Tue, Nov 12, 2013 at 08:07:03AM +0000, Keir Fraser wrote: > On 12/11/2013 07:18, "Matt Wilson" <msw@linux.com> wrote: > > >> Is there any concern about writer starvation here? I know our spinlocks > >> aren't 'fair' but our rwlocks are guaranteed to starve out writers if there > >> is a steady continuous stream of readers. Perhaps we should write-bias our > >> rwlock, or at least make that an option. We could get fancier but would > >> probably hurt performance. > > > > Yes, I'm a little concerned about writer starvation. But so far even > > in the presence of very frequent readers it seems like the infrequent > > writers are able to get the lock when they need to. However, I've not > > tested the iommu=strict path yet. I'm thinking that in that case > > there's just going to be frequent writers, so there's less risk of > > readers starving writers. For what it's worth, when mapcount() gets in > > the picture with persistent grants, I'd expect to see some pretty > > significant performance degradation for map/unmap operations. This was > > also observed in [1] under different circumstances. > > The average case isn't the only concern here, but also the worst case, which > could maybe tie up a CPU for unbounded time. Could a malicious guest set up > such a workload? I'm just thinking we don't want to end up with a DoS XSA on > this down the line. :) Indeed. > > But right now I'm more curious about cache line bouncing between all > > the readers. I've not done any study of inter-arrival times for > > typical workloads (much less some more extreme workloads like we've > > been testing), but lock profiling of grant table operations when a > > spinlock was used showed some pretty long hold times, which should > > translate fairly well to decent rwlock performance. I'm by no means an > > expert in this area so I'm eager to hear the thoughts of others. > > In the read-heavy case the only improvement would be with the old > Linux-style biglock (spinlock per CPU; writers must take all spinlocks), or > working out a lock-free scheme for readers (perhaps making use of RCU). > > -- Keir > > > I should also mention that some of the improvement I mentioned from > > 3,000 MB/s to 3,600 MB/s was due to avoiding the m2p override spinlock > > in dom0. > > ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 7:18 ` Matt Wilson 2013-11-12 8:07 ` Keir Fraser @ 2013-11-12 14:52 ` Konrad Rzeszutek Wilk 2013-11-12 15:04 ` David Vrabel 1 sibling, 1 reply; 22+ messages in thread From: Konrad Rzeszutek Wilk @ 2013-11-12 14:52 UTC (permalink / raw) To: Matt Wilson Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, Keir Fraser, David Vrabel, Jan Beulich, xen-devel, Matt Wilson, Roger Pau Monné > I should also mention that some of the improvement I mentioned from > 3,000 MB/s to 3,600 MB/s was due to avoiding the m2p override spinlock > in dom0. Could you post said patch please? I presume its pretty simple but I would like the credit to go to you guys. ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 14:52 ` Konrad Rzeszutek Wilk @ 2013-11-12 15:04 ` David Vrabel 2013-11-12 16:53 ` Anthony Liguori 0 siblings, 1 reply; 22+ messages in thread From: David Vrabel @ 2013-11-12 15:04 UTC (permalink / raw) To: Konrad Rzeszutek Wilk Cc: Felipe Franciosi, Anthony Liguori, Matt Wilson, Keir Fraser, Jan Beulich, Andrew Cooper, xen-devel, Matt Wilson, Roger Pau Monné On 12/11/13 14:52, Konrad Rzeszutek Wilk wrote: >> I should also mention that some of the improvement I mentioned from >> 3,000 MB/s to 3,600 MB/s was due to avoiding the m2p override spinlock >> in dom0. > > Could you post said patch please? I presume its pretty simple but > I would like the credit to go to you guys. Roger already posted it. https://lkml.org/lkml/2013/11/5/121 I think we're just waiting for a repost with a more detailed commit message. David ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 15:04 ` David Vrabel @ 2013-11-12 16:53 ` Anthony Liguori 0 siblings, 0 replies; 22+ messages in thread From: Anthony Liguori @ 2013-11-12 16:53 UTC (permalink / raw) To: David Vrabel Cc: Felipe Franciosi, Anthony Liguori, Matt Wilson, Keir Fraser, Jan Beulich, Andrew Cooper, xen-devel, Matt Wilson, Roger Pau Monné On Tue, Nov 12, 2013 at 7:04 AM, David Vrabel <david.vrabel@citrix.com> wrote: > On 12/11/13 14:52, Konrad Rzeszutek Wilk wrote: >>> I should also mention that some of the improvement I mentioned from >>> 3,000 MB/s to 3,600 MB/s was due to avoiding the m2p override spinlock >>> in dom0. >> >> Could you post said patch please? I presume its pretty simple but >> I would like the credit to go to you guys. > > Roger already posted it. > > https://lkml.org/lkml/2013/11/5/121 > > I think we're just waiting for a repost with a more detailed commit message. Roger's patch isn't correct. It doesn't actually restore the previous mfn because it's storing the new mfn in page private not the old one. I have a patch that I'll post this afternoon. Regards, Anthony Liguori > David > > _______________________________________________ > Xen-devel mailing list > Xen-devel@lists.xen.org > http://lists.xen.org/xen-devel ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 2:03 ` [RFC PATCH 2/2] gnttab: refactor locking for better scalability Matt Wilson 2013-11-12 5:37 ` Keir Fraser @ 2013-11-12 9:26 ` Jan Beulich 2013-11-12 17:58 ` Matt Wilson 1 sibling, 1 reply; 22+ messages in thread From: Jan Beulich @ 2013-11-12 9:26 UTC (permalink / raw) To: Matt Wilson Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, xen-devel, Keir Fraser, roger.pau >>> On 12.11.13 at 03:03, Matt Wilson <msw@linux.com> wrote: > From: Matt Wilson <msw@amazon.com> > > This patch refactors grant table locking. It splits the previous > single spinlock per grant table into multiple locks. The heavily > modified components of the grant table (the maptrack state and the > active entries) are now protected by their own spinlocks. The > remaining elements of the grant table are read-mostly, so the main > grant table lock is modified to be a rwlock to improve concurrency. > > Workloads with high grant table operation rates, especially map/unmap > operations as used by blkback/blkfront when persistent grants are not > supported, show marked improvement with these changes. A domU with 24 > VBDs in a streaming 2M write workload achieved 1,400 MB/sec before > this change. Performance more than doubles with this patch, reaching > 3,000 MB/sec before tuning and 3,600 MB/sec after adjusting event > channel vCPU bindings. > > Signed-off-by: Matt Wilson <msw@amazon.com> I will have to take a thorough second look at this, but considering its size - would it be possible to split out the conversion of the main lock to an rw one into a third patch? Correctness of the second one wouldn't suffer from this. And I'd also suggest converting all the maptrack_ fields into a separate sub-structure named maptrack. That'd not only guarantee things to be kept together, but may also allow passing the address of the sub-structure as argument to one or another helper function instead of the full structure's, thus making it more clear what such a function actually acts upon (and in particular what it does _not_ touch). Jan ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 9:26 ` Jan Beulich @ 2013-11-12 17:58 ` Matt Wilson 2013-11-13 7:39 ` Jan Beulich 0 siblings, 1 reply; 22+ messages in thread From: Matt Wilson @ 2013-11-12 17:58 UTC (permalink / raw) To: Jan Beulich Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, xen-devel, Keir Fraser, roger.pau On Tue, Nov 12, 2013 at 09:26:28AM +0000, Jan Beulich wrote: > >>> On 12.11.13 at 03:03, Matt Wilson <msw@linux.com> wrote: > > From: Matt Wilson <msw@amazon.com> > > > > This patch refactors grant table locking. It splits the previous > > single spinlock per grant table into multiple locks. The heavily > > modified components of the grant table (the maptrack state and the > > active entries) are now protected by their own spinlocks. The > > remaining elements of the grant table are read-mostly, so the main > > grant table lock is modified to be a rwlock to improve concurrency. > > > > Workloads with high grant table operation rates, especially map/unmap > > operations as used by blkback/blkfront when persistent grants are not > > supported, show marked improvement with these changes. A domU with 24 > > VBDs in a streaming 2M write workload achieved 1,400 MB/sec before > > this change. Performance more than doubles with this patch, reaching > > 3,000 MB/sec before tuning and 3,600 MB/sec after adjusting event > > channel vCPU bindings. > > > > Signed-off-by: Matt Wilson <msw@amazon.com> > > I will have to take a thorough second look at this, but considering > its size - would it be possible to split out the conversion of the main > lock to an rw one into a third patch? Correctness of the second one > wouldn't suffer from this. Yes, I figured that there would be a request to break this up. I'll have to think hard for each change to make sure that nothing breaks (e.g., deadlock scenarios) for each step along the way. But this is a useful exercise. It should be possible to first add the separate locking for maptrack, followed by fine grained locking for active entries, then finally moving the main grant table lock to a rwlock (or some other locking primitive should one become available). > And I'd also suggest converting all the maptrack_ fields into a > separate sub-structure named maptrack. That'd not only guarantee > things to be kept together, but may also allow passing the address > of the sub-structure as argument to one or another helper function > instead of the full structure's, thus making it more clear what such a > function actually acts upon (and in particular what it does _not_ > touch). I agree. Do you have any thoughts on padding the spinlock out to a cache line to avoid false sharing of the other elements? The maptrack critical sections are extremely short, so there might not be any real need for this. I've not done any measurement of maptrack spinlock contention with this change yet. I vaguely remember Anthony doing some measurement on an early PoC version that didn't show contention. It's probably a premature optimization... --msw ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability 2013-11-12 17:58 ` Matt Wilson @ 2013-11-13 7:39 ` Jan Beulich 0 siblings, 0 replies; 22+ messages in thread From: Jan Beulich @ 2013-11-13 7:39 UTC (permalink / raw) To: Matt Wilson Cc: Felipe Franciosi, Anthony Liguori, Andrew Cooper, David Vrabel, Matt Wilson, xen-devel, Keir Fraser, roger.pau >>> On 12.11.13 at 18:58, Matt Wilson <msw@linux.com> wrote: > Do you have any thoughts on padding the spinlock out to a > cache line to avoid false sharing of the other elements? Wouldn't that be counter productive? Once you need to acquire the lock, you need ownership on the line anyway, and hence it seems desirable to have the other elements in the same cache line. Unless of course there are significant parts here that are read-mostly (but I concluded from your use of a spin lock rather than an rw one that there generally are modifications done when holding the lock). What we may want to push out of it are elements outside the maptrack sub-structure. Jan ^ permalink raw reply [flat|nested] 22+ messages in thread
* Re: [RFC PATCH 2/2] gnttab: refactor locking for better scalability @ 2014-06-21 0:13 Konrad Rzeszutek Wilk 0 siblings, 0 replies; 22+ messages in thread From: Konrad Rzeszutek Wilk @ 2014-06-21 0:13 UTC (permalink / raw) To: Matt Wilson Cc: Felipe Franciosi, Matt Wilson, andrew.cooper3, Jan Beulich, Keir Fraser, David Vrabel, Anthony Liguori, Konrad Rzeszutek Wilk, xen-devel, roger.pau On Jun 20, 2014 5:18 PM, Matt Wilson <msw@linux.com> wrote: > > On Fri, Jun 20, 2014 at 04:54:15PM -0400, Konrad Rzeszutek Wilk wrote: > > On Tue, Nov 12, 2013 at 02:24:50PM +0000, Keir Fraser wrote: > > > On 12/11/2013 14:11, "Jan Beulich" <JBeulich@suse.com> wrote: > > > > > > >>>> On 12.11.13 at 14:58, Keir Fraser <keir.xen@gmail.com> wrote: > > > >> On 12/11/2013 13:42, "Keir Fraser" <keir.xen@gmail.com> wrote: > > > >> > > > >>>> And indeed I think we should be making our rwlocks fair for writers > > > >>>> before pushing in the change here; I've been meaning to get to this > > > >>>> for a while, but other stuff continues to require attention. I'm also > > > >>>> of the opinion that we should switch to ticket spinlocks. > > > >>> > > > >>> Would queuing spinlocks (e.g. MCS locks) be even more preferable? Two atomic > > > >>> ops (cmpxchg) per critical region in the uncontended case. Each CPU spins on > > > >>> its own location so there's no cacheline carnage in the highly contended > > > >>> case (a problem with simple ticket spinlocks). And it builds on cmpxchg so > > > >>> the spinlock implementation has no arch-specific component (apart from > > > >>> cmpxchg, which we already have). > > > >>> > > > >>> I have a queue-based rwlock design too, does require a spinlock lock/unlock > > > >>> per rwlock op though (i.e., 4 atomic ops per critical region in the > > > >>> uncontended case). > > > >> > > > >> Actually MCS has a multi-reader extension we could use, or there is another > > > >> alternative by Krieger et al. My own design was intended to build on pthread > > > >> primitives and wouldn't be as good as the existing solutions in the > > > >> literature for purely spinning waiters. > > > > > > > > Sounds nice - are you going to spend time on implementing this then? > > > > > > Yes I'll look into it. Amazon's benchmarking of grant-table throughput will > > > be a good testbed for performance of a different lock implementation. > > > > ping? > > Ooph. Sorry, I've not had any time to work on this since posting last > year. Has there been any other discussion about a new locking > primitive? > My recollection from this thread is that we are waiting for Keir for MCS + multireader extension patches. Especially as I was reviewing the proposed qspinlocks (MCS variant for Linux) and everything is fresh in my mind. > Konrad, are you looking for someone to rebase and break up the > proposed patch as is? > > --msw > > _______________________________________________ > Xen-devel mailing list > Xen-devel@lists.xen.org > http://lists.xen.org/xen-devel ^ permalink raw reply [flat|nested] 22+ messages in thread
end of thread, other threads:[~2014-06-21 0:14 UTC | newest] Thread overview: 22+ messages (download: mbox.gz follow: Atom feed -- links below jump to the message on this page -- 2013-11-12 2:03 [RFC PATCH 0/2] gnttab: refactor locking for better scalability Matt Wilson 2013-11-12 2:03 ` [RFC PATCH 1/2] gnttab: lock the local grant table earlier in __gnttab_unmap_common() Matt Wilson 2013-11-12 2:03 ` [RFC PATCH 2/2] gnttab: refactor locking for better scalability Matt Wilson 2013-11-12 5:37 ` Keir Fraser 2013-11-12 7:18 ` Matt Wilson 2013-11-12 8:07 ` Keir Fraser 2013-11-12 9:18 ` Jan Beulich 2013-11-12 13:42 ` Keir Fraser 2013-11-12 13:58 ` Keir Fraser 2013-11-12 14:11 ` Jan Beulich 2013-11-12 14:24 ` Keir Fraser 2013-11-12 15:09 ` Felipe Franciosi 2014-06-20 20:54 ` Konrad Rzeszutek Wilk 2014-06-20 21:18 ` Matt Wilson 2013-11-12 19:06 ` Matt Wilson 2013-11-12 14:52 ` Konrad Rzeszutek Wilk 2013-11-12 15:04 ` David Vrabel 2013-11-12 16:53 ` Anthony Liguori 2013-11-12 9:26 ` Jan Beulich 2013-11-12 17:58 ` Matt Wilson 2013-11-13 7:39 ` Jan Beulich -- strict thread matches above, loose matches on Subject: below -- 2014-06-21 0:13 Konrad Rzeszutek Wilk
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox; as well as URLs for NNTP newsgroup(s).
{kind=link}