* Pyramid erasure codes and replica hinted recovery
@ 2014-01-10 23:40 Kyle Bader
2014-01-12 1:31 ` Loic Dachary
0 siblings, 1 reply; 7+ messages in thread
From: Kyle Bader @ 2014-01-10 23:40 UTC (permalink / raw)
To: ceph-devel
I've been researching what features might be necessary in Ceph to
build multi-site RADOS clusters, whether for purposes of scale or to
meet SLA requirements more stringent than is achievable with a single
datacenter. According to [1], "typical [datacenter] availability
estimates used in the industry range from 99.7% for tier II to 99.98
and 99.995% for tiers II and IV respectively". Combine the possibility
of border and/or core networking meltdown and it's all but impossible
to achieve a Ceph service SLA that requires 3-5 nines of availability
in a single facility.
When we start looking at multi-site network configurations we need to
make sure there is sufficient cluster level bandwidth for the
following activities:
1. Write fan-out from replication on ingest
2. Backfills from OSD recovery
3. Backfills from OSD remapping
Number 1 can be estimated based on historical usage with some
additional padding for traffic spikes. Recovery backfills can be
roughly estimated based on the size of the disk population in each
facility and the OSD annualized failure rate. Number 3 makes
multi-site configurations extremely challenging unless the
organization building the cluster is willing to pay 7 zeros for 5
nines.
Consider the following:
1x 16x40GbE switch with 8x used for access ports, 8x used for
inter-site (x4 10GbE breakout per port)
32x Ceph OSD nodes with a 10GbE cluster link (working out to ~3PB raw)
Topology:
[A]-----[B]
\ /
\ /
[C]
Since 40GbE is likely only an option if running over dark fiber,
non-blocking multi-site would require a total of 12 leased 10GbE
lines, 6 for 2:1, and 3 for 4:1. These lines will be extremely
stressed each and every time capacity is added to the cluster due to
the fact that pgs will be remapped and the OSD that is new to the PG
needing to be backfilled by the primary at another site (for 3x
replication). Erasure coding with regular MDS codes or even pyramid
codes will exhibit similar issues, as described in [2] and [3]. It
would be fantastic to see Ceph have a facility similar to what I
describe in this bug for replication:
http://tracker.ceph.com/issues/7114
For erasure coding, something similar to Facebook's LRC as described
in [2] would be advantageous. For example:
RS(8:4:2)
[k][k][k][k][k][k][k][k] -> [k][k][k][k][k][k][k][k][m][m][m][m]
Split over 3 sites
[k][k][k][k] [k][k][k][k] [k][k][k][k]
Generate 2 more parity units
[k][k][k][k][m][m] [k][k][k][k][m][m] [k][k][k][k][m][m]
Now if each *set* of units could be placed such that they share a
common ancestor in the CRUSH hierarchy then local unit sets from the
lower level of the pyramid could be remapped/recovered without
consuming inter-site bandwidth (maybe treat each set as a "replica"
instead of treating each individual unit as a "replica").
Thoughts?
[1] http://www.morganclaypool.com/doi/abs/10.2200/S00516ED2V01Y201306CAC024
[2] http://arxiv.org/pdf/1301.3791.pdf
[3] https://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/36737.pdf
--
Kyle Bader - Inktank
Senior Solution Architect
^ permalink raw reply [flat|nested] 7+ messages in thread* Re: Pyramid erasure codes and replica hinted recovery 2014-01-10 23:40 Pyramid erasure codes and replica hinted recovery Kyle Bader @ 2014-01-12 1:31 ` Loic Dachary 2014-01-12 14:31 ` Kyle Bader 0 siblings, 1 reply; 7+ messages in thread From: Loic Dachary @ 2014-01-12 1:31 UTC (permalink / raw) To: Kyle Bader, ceph-devel [-- Attachment #1: Type: text/plain, Size: 5062 bytes --] On 11/01/2014 00:40, Kyle Bader wrote: > I've been researching what features might be necessary in Ceph to > build multi-site RADOS clusters, whether for purposes of scale or to > meet SLA requirements more stringent than is achievable with a single > datacenter. According to [1], "typical [datacenter] availability > estimates used in the industry range from 99.7% for tier II to 99.98 > and 99.995% for tiers II and IV respectively". Combine the possibility > of border and/or core networking meltdown and it's all but impossible > to achieve a Ceph service SLA that requires 3-5 nines of availability > in a single facility. > > When we start looking at multi-site network configurations we need to > make sure there is sufficient cluster level bandwidth for the > following activities: > > 1. Write fan-out from replication on ingest > 2. Backfills from OSD recovery > 3. Backfills from OSD remapping > > Number 1 can be estimated based on historical usage with some > additional padding for traffic spikes. Recovery backfills can be > roughly estimated based on the size of the disk population in each > facility and the OSD annualized failure rate. Number 3 makes > multi-site configurations extremely challenging unless the > organization building the cluster is willing to pay 7 zeros for 5 > nines. > > Consider the following: > > 1x 16x40GbE switch with 8x used for access ports, 8x used for > inter-site (x4 10GbE breakout per port) > 32x Ceph OSD nodes with a 10GbE cluster link (working out to ~3PB raw) > > Topology: > > [A]-----[B] > \ / > \ / > [C] > > Since 40GbE is likely only an option if running over dark fiber, > non-blocking multi-site would require a total of 12 leased 10GbE > lines, 6 for 2:1, and 3 for 4:1. These lines will be extremely > stressed each and every time capacity is added to the cluster due to > the fact that pgs will be remapped and the OSD that is new to the PG > needing to be backfilled by the primary at another site (for 3x > replication). Erasure coding with regular MDS codes or even pyramid > codes will exhibit similar issues, as described in [2] and [3]. It > would be fantastic to see Ceph have a facility similar to what I > describe in this bug for replication: > > http://tracker.ceph.com/issues/7114 > > For erasure coding, something similar to Facebook's LRC as described > in [2] would be advantageous. For example: > > RS(8:4:2) > > [k][k][k][k][k][k][k][k] -> [k][k][k][k][k][k][k][k][m][m][m][m] > > Split over 3 sites > > [k][k][k][k] [k][k][k][k] [k][k][k][k] > > Generate 2 more parity units > > [k][k][k][k][m][m] [k][k][k][k][m][m] [k][k][k][k][m][m] > > Now if each *set* of units could be placed such that they share a > common ancestor in the CRUSH hierarchy then local unit sets from the > lower level of the pyramid could be remapped/recovered without > consuming inter-site bandwidth (maybe treat each set as a "replica" > instead of treating each individual unit as a "replica"). > > Thoughts? If we had RS(6:3:3) 6 data chunks, 3 coding chunks, 3 local chunks, the following rule could be used to spread it over 3 datacenters: rule erasure_ruleset { ruleset 1 type erasure min_size 3 max_size 20 step set_chooseleaf_tries 5 step take root step choose indep 3 type datacenter step choose indep 4 type device step emit } crushtool -o /tmp/t.map --num_osds 500 --build node straw 10 datacenter straw 10 root straw 0 crushtool -d /tmp/t.map -o /tmp/t.txt # edit the ruleset as above crushtool -c /tmp/t.txt -o /tmp/t.map ; crushtool -i /tmp/t.map --show-bad-mappings --show-statistics --test --rule 1 --x 1 --num-rep 12 rule 1 (erasure_ruleset), x = 1..1, numrep = 12..12 CRUSH rule 1 x 1 [399,344,343,321,51,78,9,12,274,263,270,213] rule 1 (erasure_ruleset) num_rep 12 result size == 12: 1/1 399 is in datacenter 3, node 9, device 9 etc. It shows that the first four are in datacenter 3, the next in datacenter zero and the last four in datacenter 2. If the function calculating erasure code spreads local chunks evenly ( 321, 12, 213 for instance ), they will effectively be located as you suggest. Andreas may have a different view on this question though. In case 78 goes missing ( and assuming all other chunks are good ), it can be rebuilt with 512, 9, 12 only. However, if the primary driving the reconstruction is 270, data will need to cross datacenter boundaries. Would it be cheaper to elect a primary closest ( in the sense of get_common_ancestor_distance https://github.com/ceph/ceph/blob/master/src/crush/CrushWrapper.h#L487 ) to the OSD to be recovered ? Only Sam or David could give you an authoritative answer. Cheers > > [1] http://www.morganclaypool.com/doi/abs/10.2200/S00516ED2V01Y201306CAC024 > [2] http://arxiv.org/pdf/1301.3791.pdf > [3] https://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/36737.pdf > -- Loïc Dachary, Artisan Logiciel Libre [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 263 bytes --] ^ permalink raw reply [flat|nested] 7+ messages in thread
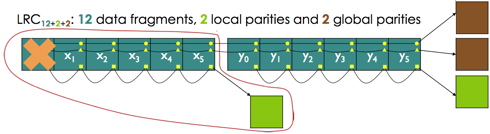
* Re: Pyramid erasure codes and replica hinted recovery 2014-01-12 1:31 ` Loic Dachary @ 2014-01-12 14:31 ` Kyle Bader 2014-01-12 19:37 ` Loic Dachary 0 siblings, 1 reply; 7+ messages in thread From: Kyle Bader @ 2014-01-12 14:31 UTC (permalink / raw) To: Loic Dachary; +Cc: ceph-devel > If we had RS(6:3:3) 6 data chunks, 3 coding chunks, 3 local chunks, the following rule could be used to spread it over 3 datacenters: > > rule erasure_ruleset { > ruleset 1 > type erasure > min_size 3 > max_size 20 > step set_chooseleaf_tries 5 > step take root > step choose indep 3 type datacenter > step choose indep 4 type device > step emit > } > > crushtool -o /tmp/t.map --num_osds 500 --build node straw 10 datacenter straw 10 root straw 0 > crushtool -d /tmp/t.map -o /tmp/t.txt # edit the ruleset as above > crushtool -c /tmp/t.txt -o /tmp/t.map ; crushtool -i /tmp/t.map --show-bad-mappings --show-statistics --test --rule 1 --x 1 --num-rep 12 > rule 1 (erasure_ruleset), x = 1..1, numrep = 12..12 > CRUSH rule 1 x 1 [399,344,343,321,51,78,9,12,274,263,270,213] > rule 1 (erasure_ruleset) num_rep 12 result size == 12: 1/1 > > 399 is in datacenter 3, node 9, device 9 etc. It shows that the first four are in datacenter 3, the next in datacenter zero and the last four in datacenter 2. > > If the function calculating erasure code spreads local chunks evenly ( 321, 12, 213 for instance ), they will effectively be located as you suggest. Andreas may have a different view on this question though. > > In case 78 goes missing ( and assuming all other chunks are good ), it can be rebuilt with 512, 9, 12 only. However, if the primary driving the reconstruction is 270, data will need to cross datacenter boundaries. Would it be cheaper to elect a primary closest ( in the sense of get_common_ancestor_distance https://github.com/ceph/ceph/blob/master/src/crush/CrushWrapper.h#L487 ) to the OSD to be recovered ? Only Sam or David could give you an authoritative answer. That scheme does work out, except I'm not sure how the recovering/remapped OSD can makes sure to read the local copies. I'll wait to hear what Sam and David have to say. That said, what do you think of this diagram of a 12,2,2: http://storagemojo.com/wp-content/uploads/2012/09/LRC_parity.PNG from [4] With a 12,2,2 LRC code the stripe is split into 12 units, those 12 units are used to generate 2 global parity units. The original 12 units are then split into 2 groups, and each group separately generates an additional local parity unit. Each group of 6 original units and 1 parity unit are passed through CRUSH for placement with a common ancestor (for local recovery). This would be low overhead, certainly less than a replicated, and be friendlier on inter-dc links during remapping and recovery. [4] http://storagemojo.com/2012/09/26/more-efficient-erasure-coding-in-windows-azure-storage/ -- Kyle Bader - Inktank Senior Solution Architect ^ permalink raw reply [flat|nested] 7+ messages in thread
* Re: Pyramid erasure codes and replica hinted recovery 2014-01-12 14:31 ` Kyle Bader @ 2014-01-12 19:37 ` Loic Dachary 2014-01-13 2:35 ` Kyle Bader 0 siblings, 1 reply; 7+ messages in thread From: Loic Dachary @ 2014-01-12 19:37 UTC (permalink / raw) To: Kyle Bader; +Cc: ceph-devel [-- Attachment #1: Type: text/plain, Size: 3717 bytes --] On 12/01/2014 15:31, Kyle Bader wrote: >> If we had RS(6:3:3) 6 data chunks, 3 coding chunks, 3 local chunks, the following rule could be used to spread it over 3 datacenters: >> >> rule erasure_ruleset { >> ruleset 1 >> type erasure >> min_size 3 >> max_size 20 >> step set_chooseleaf_tries 5 >> step take root >> step choose indep 3 type datacenter >> step choose indep 4 type device >> step emit >> } >> >> crushtool -o /tmp/t.map --num_osds 500 --build node straw 10 datacenter straw 10 root straw 0 >> crushtool -d /tmp/t.map -o /tmp/t.txt # edit the ruleset as above >> crushtool -c /tmp/t.txt -o /tmp/t.map ; crushtool -i /tmp/t.map --show-bad-mappings --show-statistics --test --rule 1 --x 1 --num-rep 12 >> rule 1 (erasure_ruleset), x = 1..1, numrep = 12..12 >> CRUSH rule 1 x 1 [399,344,343,321,51,78,9,12,274,263,270,213] >> rule 1 (erasure_ruleset) num_rep 12 result size == 12: 1/1 >> >> 399 is in datacenter 3, node 9, device 9 etc. It shows that the first four are in datacenter 3, the next in datacenter zero and the last four in datacenter 2. >> >> If the function calculating erasure code spreads local chunks evenly ( 321, 12, 213 for instance ), they will effectively be located as you suggest. Andreas may have a different view on this question though. >> >> In case 78 goes missing ( and assuming all other chunks are good ), it can be rebuilt with 512, 9, 12 only. However, if the primary driving the reconstruction is 270, data will need to cross datacenter boundaries. Would it be cheaper to elect a primary closest ( in the sense of get_common_ancestor_distance https://github.com/ceph/ceph/blob/master/src/crush/CrushWrapper.h#L487 ) to the OSD to be recovered ? Only Sam or David could give you an authoritative answer. > There is a typo : "rebuilt with 51, 9, 12" > That scheme does work out, except I'm not sure how the > recovering/remapped OSD can makes sure to read the local copies. I'll > wait to hear what Sam and David have to say. That said, what do you > think of this diagram of a 12,2,2: > > http://storagemojo.com/wp-content/uploads/2012/09/LRC_parity.PNG from [4] > > With a 12,2,2 LRC code the stripe is split into 12 units, those 12 > units are used to generate 2 global parity units. The original 12 > units are then split into 2 groups, and each group separately > generates an additional local parity unit. Each group of 6 original > units and 1 parity unit are passed through CRUSH for placement with a > common ancestor (for local recovery). This would be low overhead, > certainly less than a replicated, and be friendlier on inter-dc links > during remapping and recovery. > > [4] http://storagemojo.com/2012/09/26/more-efficient-erasure-coding-in-windows-azure-storage/ > How is it different from what is described above ? There must be something I fail to understand. In the above example CRUSH rule 1 x 1 [399,344,343,321,51,78,9,12,274,263,270,213] would be datacenter 3 399 data 344 data 343 global parity 321 local parity datacenter 0 51 data 78 data 9 global parity 12 local parity datacenter 2 274 data 263 data 270 global parity 213 local parity If 9 is missing, recovery looks for the chunks that have the closest common ancestor, finds 51, 78, 12 and since there only is one missing chunk uses local parity chunk 12 to rebuild it. If 9 and 12 are missing, it needs all remaining data + global parity chunks to rebuild. In this example the overhead of erasure coding is high but increasing the number of data chunks reduces it. Cheers -- Loïc Dachary, Artisan Logiciel Libre [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 263 bytes --] ^ permalink raw reply [flat|nested] 7+ messages in thread
* Re: Pyramid erasure codes and replica hinted recovery 2014-01-12 19:37 ` Loic Dachary @ 2014-01-13 2:35 ` Kyle Bader 2014-01-13 8:38 ` Loic Dachary 0 siblings, 1 reply; 7+ messages in thread From: Kyle Bader @ 2014-01-13 2:35 UTC (permalink / raw) To: Loic Dachary; +Cc: ceph-devel > How is it different from what is described above? There must be something I fail to understand. No misunderstanding on your part, on second look that does achieve the desired placement. Could you please help walk me through the following scenarios: Can data or local parity chunks that have been lost (erasures) be recovered locally, with no inter-dc backfill traffic? Global parity chunks that are lost require reading....6x data or global parity chunks (effectively 1x the original write)? Would placement groups containing a data or local parity chunk that have been remapped backfill from the local chunk (member of previous acting set)? Thanks! -- Kyle Bader - Inktank Senior Solution Architect ^ permalink raw reply [flat|nested] 7+ messages in thread
* Re: Pyramid erasure codes and replica hinted recovery 2014-01-13 2:35 ` Kyle Bader @ 2014-01-13 8:38 ` Loic Dachary 2014-01-13 11:15 ` Andreas Joachim Peters 0 siblings, 1 reply; 7+ messages in thread From: Loic Dachary @ 2014-01-13 8:38 UTC (permalink / raw) To: Kyle Bader; +Cc: ceph-devel [-- Attachment #1: Type: text/plain, Size: 1986 bytes --] On 13/01/2014 03:35, Kyle Bader wrote: >> How is it different from what is described above? There must be something I fail to understand. > > No misunderstanding on your part, on second look that does achieve the > desired placement. Could you please help walk me through the following > scenarios: > > Can data or local parity chunks that have been lost (erasures) be > recovered locally, with no inter-dc backfill traffic? If the primary happens to be located in the same data enter as the lost chunk and the layout is as described previously, then it will be recovered without the need for inter-dc traffic. If the primary is not in the same datacenter, it may be possible to move it to the datacenter where the lost chunk is located. When the primary OSD is lost, another must be chosen. It would be nice to change the primary not only when it is lost but also when doing so helps recovery. > Global parity chunks that are lost require reading....6x data or > global parity chunks (effectively 1x the original write)? From the point of view of recovery, global parity chunks are treated in the same way as data chunks. If you have RS(6,3,3), you will need to read 6 chunks out of 9 ( 6 data chunks + 3 global parity chunks ) to be able to recover from the loss of 2 or 3 chunks ( data or parity, it does not matter ). In other words, to recover from the loss of more chunks than local parity allows, you need to read 1x the original write. > Would placement groups containing a data or local parity chunk that > have been remapped backfill from the local chunk (member of previous > acting set)? David is working on multiple backfill at the moment https://github.com/ceph/ceph/pull/931 and will have a definitive answer. The data flows from the primary OSD to the OSDs supporting the other chunks there is no peer-to-peer communication between the OSDs participating in a placement group. Cheers -- Loïc Dachary, Artisan Logiciel Libre [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 263 bytes --] ^ permalink raw reply [flat|nested] 7+ messages in thread
* RE: Pyramid erasure codes and replica hinted recovery 2014-01-13 8:38 ` Loic Dachary @ 2014-01-13 11:15 ` Andreas Joachim Peters 0 siblings, 0 replies; 7+ messages in thread From: Andreas Joachim Peters @ 2014-01-13 11:15 UTC (permalink / raw) To: Loic Dachary, Kyle Bader; +Cc: ceph-devel@vger.kernel.org Hi all, few points from my side: In the case of three data centers to protect against 1 out of 3 failing data centers one has to fulfill 2M=K e.g. (12,6) K=12 M=6 kkkkmm kkkkmm kkkkmm Then one can add three local parities to optimize data center local failures kkkkmml kkkkmml kkkkmml (12:6:(6:1)) => 175% space overhead (6:3:(6:1)) => 200% space overhead (18:9:(6:1)) => 166% space overhead ... so if you boost K it converges to 150% space overhead but if K/3 is too big the traffic overhead for reconstruction is getting high. Since we have a systematic code it is important with respect to CPU requirements to distinguish K,M stripes on the global level e.g. for 3 data centers K and M should be divisible by 3 e.g. (8:4) is not. In the current BPC implementation the global RS stripes are not included into the parity computation, however if M is high they should be included to optimize the traffic. We should have an option to specify this or to select automatically the best strategy. For (6:3:(3:1)) the traffic is the same if global stripes are included in local parity, for (8:4:(4:1)) it is better not to include global stripes, for (12:6:(6:1))) it is better to include them. In the current implementation we can only use simple parity as local parity (k:1) , it is not possible to use something like RS(4:2) as local parity. In my opinion there is no need to add this feature since the probability having a double disk failure within the repair period of a single disk failure is extremely low and if it happens it is acceptable to use global reconstruction instead of adding more space requirements for additional local stripes. I am not 100% sure but from your conversation I understand that recovery is done on a primary OSD which is quite unfortunate with respect to local parities. The volume is reduced but locality is not given anymore ... Cheers Andreas. ________________________________________ From: ceph-devel-owner@vger.kernel.org [ceph-devel-owner@vger.kernel.org] on behalf of Loic Dachary [loic@dachary.org] Sent: 13 January 2014 09:38 To: Kyle Bader Cc: ceph-devel@vger.kernel.org Subject: Re: Pyramid erasure codes and replica hinted recovery On 13/01/2014 03:35, Kyle Bader wrote: >> How is it different from what is described above? There must be something I fail to understand. > > No misunderstanding on your part, on second look that does achieve the > desired placement. Could you please help walk me through the following > scenarios: > > Can data or local parity chunks that have been lost (erasures) be > recovered locally, with no inter-dc backfill traffic? If the primary happens to be located in the same data enter as the lost chunk and the layout is as described previously, then it will be recovered without the need for inter-dc traffic. If the primary is not in the same datacenter, it may be possible to move it to the datacenter where the lost chunk is located. When the primary OSD is lost, another must be chosen. It would be nice to change the primary not only when it is lost but also when doing so helps recovery. > Global parity chunks that are lost require reading....6x data or > global parity chunks (effectively 1x the original write)? From the point of view of recovery, global parity chunks are treated in the same way as data chunks. If you have RS(6,3,3), you will need to read 6 chunks out of 9 ( 6 data chunks + 3 global parity chunks ) to be able to recover from the loss of 2 or 3 chunks ( data or parity, it does not matter ). In other words, to recover from the loss of more chunks than local parity allows, you need to read 1x the original write. > Would placement groups containing a data or local parity chunk that > have been remapped backfill from the local chunk (member of previous > acting set)? David is working on multiple backfill at the moment https://github.com/ceph/ceph/pull/931 and will have a definitive answer. The data flows from the primary OSD to the OSDs supporting the other chunks there is no peer-to-peer communication between the OSDs participating in a placement group. Cheers -- Loïc Dachary, Artisan Logiciel Libre -- To unsubscribe from this list: send the line "unsubscribe ceph-devel" in the body of a message to majordomo@vger.kernel.org More majordomo info at http://vger.kernel.org/majordomo-info.html ^ permalink raw reply [flat|nested] 7+ messages in thread
end of thread, other threads:[~2014-01-13 11:15 UTC | newest] Thread overview: 7+ messages (download: mbox.gz follow: Atom feed -- links below jump to the message on this page -- 2014-01-10 23:40 Pyramid erasure codes and replica hinted recovery Kyle Bader 2014-01-12 1:31 ` Loic Dachary 2014-01-12 14:31 ` Kyle Bader 2014-01-12 19:37 ` Loic Dachary 2014-01-13 2:35 ` Kyle Bader 2014-01-13 8:38 ` Loic Dachary 2014-01-13 11:15 ` Andreas Joachim Peters
This is an external index of several public inboxes, see mirroring instructions on how to clone and mirror all data and code used by this external index.
{kind=link}